
Cómo Convertir HTML a PDF en Node.js usando Puppeteer
En el mundo digital actual, es fundamental contar con la capacidad de convertir páginas web o documentos HTML en archivos PDF. Esto resulta útil para generar informes, crear facturas o simplemente compartir información en un formato más presentable. En esta publicación de blog, exploraremos cómo convertir HTML a PDF usando Node.js y Puppeteer, una biblioteca de código abierto desarrollada por Google.
Introducción a Puppeteer
Puppeteer es una poderosa biblioteca de Node.js que permite a los desarrolladores controlar navegadores sin cabeza, principalmente Google Chrome o Chromium, y realizar varias acciones como scraping web, tomar capturas de pantalla y generar PDFs. Puppeteer proporciona una API extensa para interactuar con el navegador, lo que lo convierte en una excelente opción para convertir HTML a PDF.
¿Por qué Puppeteer?
- Facilidad de uso: Puppeteer ofrece una API simple e intuitiva que abstrae las complejidades de trabajar con navegadores sin cabeza.
- Potente: Puppeteer proporciona amplias capacidades para manipular páginas web e interactuar con elementos del navegador.
- Escalable: Con Puppeteer, es posible escalar fácilmente el proceso de generación de PDF ejecutando varias instancias del navegador en paralelo.
Cómo configurar tu proyecto Node.js
Antes de comenzar, es necesario configurar un nuevo proyecto Node.js. Siga estos pasos para empezar:
- Instale Node.js si aún no lo ha hecho (puede descargarlo desde el sitio web de Node.js).
- Cree una nueva carpeta para su proyecto y ábrala en Visual Studio Code o cualquier editor de código de su preferencia.
-
Ejecute
npm initpara crear un nuevo archivopackage.jsonpara su proyecto. Siga las indicaciones y complete la información requerida.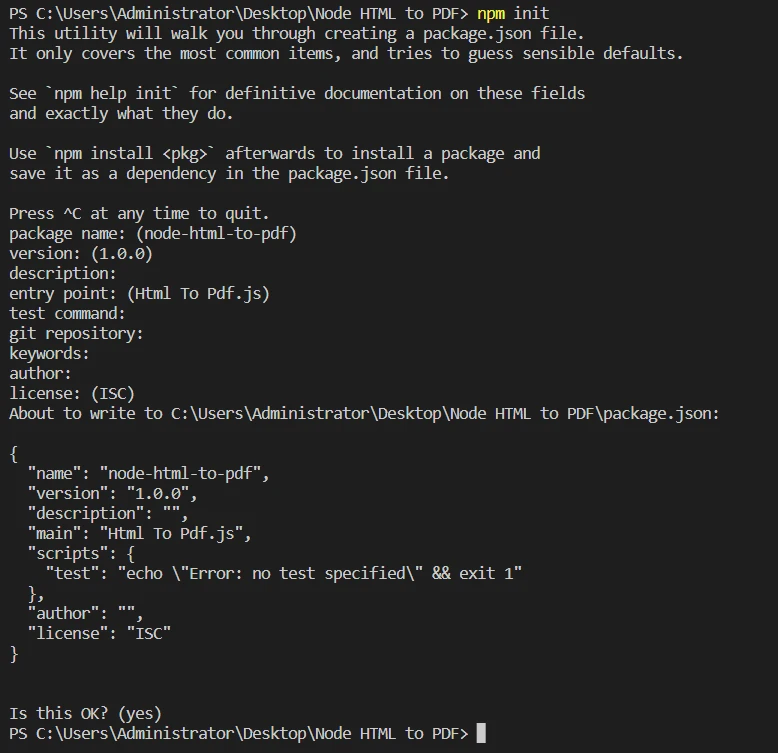
-
Instale Puppeteer ejecutando
npm install puppeteer.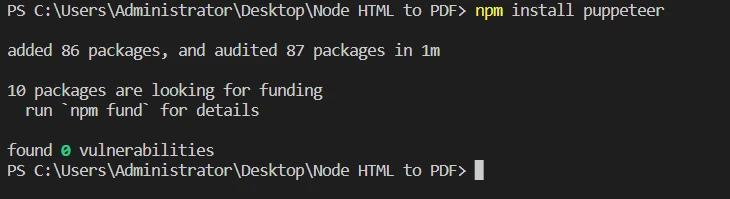
Una vez configurado el proyecto, procedemos con el código.
Carga de plantilla HTML y conversión a archivo PDF
Para convertir plantillas HTML a un archivo PDF usando Puppeteer, siga estos pasos:
Cree un archivo llamado "HTML To PDF.js" en la carpeta.
Importación de Puppeteer y fs
const puppeteer = require('puppeteer');
const fs = require('fs');El código comienza importando dos bibliotecas esenciales: puppeteer, una herramienta versátil para controlar navegadores sin cabeza como Chrome y Chromium, y fs, un módulo Node.js integrado para manejar operaciones del sistema de archivos. Puppeteer te permite automatizar una amplia gama de tareas basadas en la web, incluyendo renderizar HTML, capturar capturas de pantalla y generar archivos PDF.
Definición de la función exportWebsiteAsPdf
async function exportWebsiteAsPdf(html, outputPath) {
// Create a browser instance
const browser = await puppeteer.launch({
headless: true // Launches the browser in headless mode
});
// Create a new page
const page = await browser.newPage();
// Set the HTML content for the page, waiting for DOM content to load
await page.setContent(html, { waitUntil: 'domcontentloaded' });
// To reflect CSS used for screens instead of print
await page.emulateMediaType('screen');
// Download the PDF
const PDF = await page.pdf({
path: outputPath,
margin: { top: '100px', right: '50px', bottom: '100px', left: '50px' },
printBackground: true,
format: 'A4',
});
// Close the browser instance
await browser.close();
return PDF;
}La función exportWebsiteAsPdf sirve como núcleo de nuestro fragmento de código. Esta función asíncrona acepta una cadena html y un outputPath como parámetros de entrada y devuelve un archivo PDF. La función realiza los siguientes pasos:
- Lanza una nueva instancia de navegador sin cabeza usando Puppeteer.
- Crea una nueva página de navegador.
- Establece la cadena
htmlproporcionada como el contenido de la página, esperando que se cargue el contenido del DOM. - Emula el tipo de medio 'pantalla' para aplicar el CSS utilizado para pantallas en lugar de estilos específicos para impresión.
- Genera un archivo PDF del contenido HTML cargado, especificando márgenes, impresión de fondo y formato (A4).
- Cierra la instancia del navegador.
- Devuelve el archivo PDF creado.
Uso de la función exportWebsiteAsPdf
// Usage example
// Get HTML content from HTML file
const html = fs.readFileSync('test.html', 'utf-8');
// Convert the HTML content into a PDF and save it to the specified path
exportWebsiteAsPdf(html, 'result.pdf').then(() => {
console.log('PDF created successfully.');
}).catch((error) => {
console.error('Error creating PDF:', error);
});La última sección del código ilustra cómo utilizar la función exportWebsiteAsPdf. Realizamos los siguientes pasos:
- Lea el contenido HTML de un archivo HTML utilizando el método
fsdel móduloreadFileSync. - Llame a la función
exportWebsiteAsPdfcon la cadenahtmlcargada y eloutputPathdeseado. - Utilice un bloque
.thenpara manejar la creación exitosa del PDF y registrar un mensaje de éxito en la consola. - Utilice un bloque
.catchpara administrar cualquier error que ocurra durante el proceso de conversión de HTML a PDF, registrando un mensaje de error en la consola.
Este fragmento de código proporciona un ejemplo completo de cómo convertir una plantilla HTML a un archivo PDF usando Node.js y Puppeteer. Al implementar esta solución, puedes generar de manera eficiente PDFs de alta calidad, satisfaciendo las necesidades de varias aplicaciones y usuarios.
Convertir URL en archivos PDF
Además de convertir plantillas HTML, Puppeteer también te permite convertir URLs directamente en archivos PDF.
Importar Puppeteer
const puppeteer = require('puppeteer');El código comienza importando la biblioteca Puppeteer, que es una herramienta poderosa para controlar navegadores sin cabeza como Chrome y Chromium. Puppeteer te permite automatizar una variedad de tareas basadas en la web, incluido el renderizado de tu código HTML, la captura de capturas de pantalla y, en nuestro caso, la generación de archivos PDF.
Definición de la función exportWebsiteAsPdf
async function exportWebsiteAsPdf(websiteUrl, outputPath) {
// Create a browser instance
const browser = await puppeteer.launch({
headless: true // Launches the browser in headless mode
});
// Create a new page
const page = await browser.newPage();
// Open the URL in the current page
await page.goto(websiteUrl, { waitUntil: 'networkidle0' });
// To reflect CSS used for screens instead of print
await page.emulateMediaType('screen');
// Download the PDF
const PDF = await page.pdf({
path: outputPath,
margin: { top: '100px', right: '50px', bottom: '100px', left: '50px' },
printBackground: true,
format: 'A4',
});
// Close the browser instance
await browser.close();
return PDF;
}La función exportWebsiteAsPdf es el núcleo de nuestro fragmento de código. Esta función asíncrona acepta websiteUrl y outputPath como parámetros de entrada y devuelve un archivo PDF. La función realiza los siguientes pasos:
- Lanza una nueva instancia de navegador sin cabeza usando Puppeteer.
- Crea una nueva página de navegador.
- Navega hasta el
websiteUrlproporcionado y espera a que la red quede inactiva usando la opciónwaitUntilestablecida ennetworkidle0. - Emula el tipo de medio 'pantalla' para asegurar que se aplique el CSS utilizado para pantallas en lugar de estilos específicos para impresión.
- Convierte la página web cargada en un archivo PDF con los márgenes especificados, impresión de fondo y formato (A4).
- Cierra la instancia del navegador.
- Devuelve el archivo PDF generado.
Uso de la función exportWebsiteAsPdf
// Usage example
// Convert the URL content into a PDF and save it to the specified path
exportWebsiteAsPdf('https://ironpdf.com/', 'result.pdf').then(() => {
console.log('PDF created successfully.');
}).catch((error) => {
console.error('Error creating PDF:', error);
});La sección final del código demuestra cómo utilizar la función exportWebsiteAsPdf. Ejecutamos los siguientes pasos:
- Llame a la función
exportWebsiteAsPdfcon loswebsiteUrlyoutputPathdeseados. - Utilice un bloque
thenpara manejar la creación exitosa del PDF. En este bloque, registramos un mensaje de éxito en la consola. - Utilice un bloque
catchpara manejar cualquier error que ocurra durante el proceso de conversión del sitio web a PDF. Si ocurre un error, registramos un mensaje de error en la consola.
Al integrar este fragmento de código en tus proyectos, puedes convertir fácilmente URLs en archivos PDF de alta calidad usando Node.js y Puppeteer.
Mejor biblioteca HTML a PDF para desarrolladores de C
IronPDF es una popular biblioteca .NET utilizada para generar, editar y extraer contenido de archivos PDF. Proporciona una solución sencilla y eficiente para crear PDFs a partir de HTML, texto, imágenes y documentos PDF existentes. IronPDF soporta proyectos .NET Core, .NET Framework y .NET 5.0+, lo que lo convierte en una opción versátil para diversas aplicaciones.
Características principales de IronPDF
Conversión HTML a PDF con IronPDF: IronPDF permite convertir contenido HTML, incluyendo CSS, a archivos PDF. Esta característica posibilita crear documentos PDF de alta calidad a partir de páginas web o plantillas HTML.
Representación de URL: IronPDF puede obtener páginas web directamente desde un servidor mediante una URL y convertirlas en archivos PDF, lo que facilita el archivado de contenido web o la generación de informes a partir de páginas web dinámicas.
Fusión de texto, imágenes y PDF: IronPDF le permite fusionar texto, imágenes y archivos PDF existentes en un solo documento PDF. Esta característica es particularmente útil para crear documentos complejos con múltiples fuentes de contenido.
Manipulación de PDF: IronPDF proporciona herramientas para editar archivos PDF existentes, como agregar o eliminar páginas, modificar metadatos o incluso extraer texto e imágenes de documentos PDF.
Conclusión
En conclusión, generar y manipular archivos PDF es un requisito común en muchas aplicaciones, y contar con las herramientas adecuadas a tu disposición es crucial. Las soluciones proporcionadas en este artículo, como el uso de Puppeteer con Node.js o IronPDF con .NET, ofrecen métodos poderosos y eficientes para convertir contenido HTML y URLs en documentos PDF profesionales de alta calidad.
IronPDF, en particular, se destaca con su conjunto de características extensas, lo que lo convierte en una elección principal para desarrolladores .NET. IronPDF ofrece una prueba gratuita que te permite explorar sus capacidades.
Los usuarios también pueden beneficiarse del paquete Iron Suite, un conjunto de cinco bibliotecas .NET profesionales que incluyen IronXL, IronPDF, IronOCR y mucho más.














