
Cómo Convertir HTML a PDF en C++
La capacidad de convertir archivos HTML en documentos PDF es una característica valiosa en muchas aplicaciones. En C++, puede ser bastante tedioso construir una aplicación desde cero para realizar la conversión de HTML a PDF. En este artículo, exploraremos cómo convertir HTML a PDF en C++ usando la biblioteca wkhtmltopdf.
Librería WKHTMLTOPDF
wkhtmltopdf es una herramienta de línea de comandos de código abierto que transforma sin problemas las páginas de texto plano HTML en documentos PDF de alta calidad. Aprovechando sus funcionalidades en programas C++, podemos convertir fácilmente contenido de cadena HTML a formato PDF. Vamos a profundizar en el proceso paso a paso de conversión de página HTML a PDF en C++ usando la biblioteca wkhtmltopdf.
Requisitos previos
Para crear un convertidor de archivos HTML a PDF en C++, asegúrese de que se cumplen los siguientes requisitos previos:
- Un compilador de C++ como GCC o Clang instalado en tu sistema.
- Biblioteca wkhtmltopdf instalada. Puedes descargar la última versión desde el sitio web oficial de wkhtmltopdf e instalarla según las instrucciones de tu sistema operativo.
- Conocimiento básico de programación en C++.
Crear un proyecto C++ HtmltoPdf en Code::Blocks
Para crear un proyecto de conversión de HTML a PDF en C++ en Code::Blocks, siga estos pasos:
- Abra el IDE Code::Blocks.
- Vaya al menú "File" y seleccione "New" y luego "Project" para abrir el asistente de Nuevo Proyecto.
- En el asistente de Nuevo Proyecto, seleccione "Console Application".
- Seleccione el lenguaje C++.
- Establezca el título del proyecto y la ubicación donde desea guardarlo. Haga clic en "Next" para continuar.
- Seleccione el compilador C++ apropiado y el objetivo de compilación, como Debug o Release. Haga clic en "Finish" para crear el proyecto.
Configuración de directorios de búsqueda
Para garantizar que Code::Blocks pueda encontrar los archivos de encabezado necesarios, es preciso configurar los directorios de búsqueda:
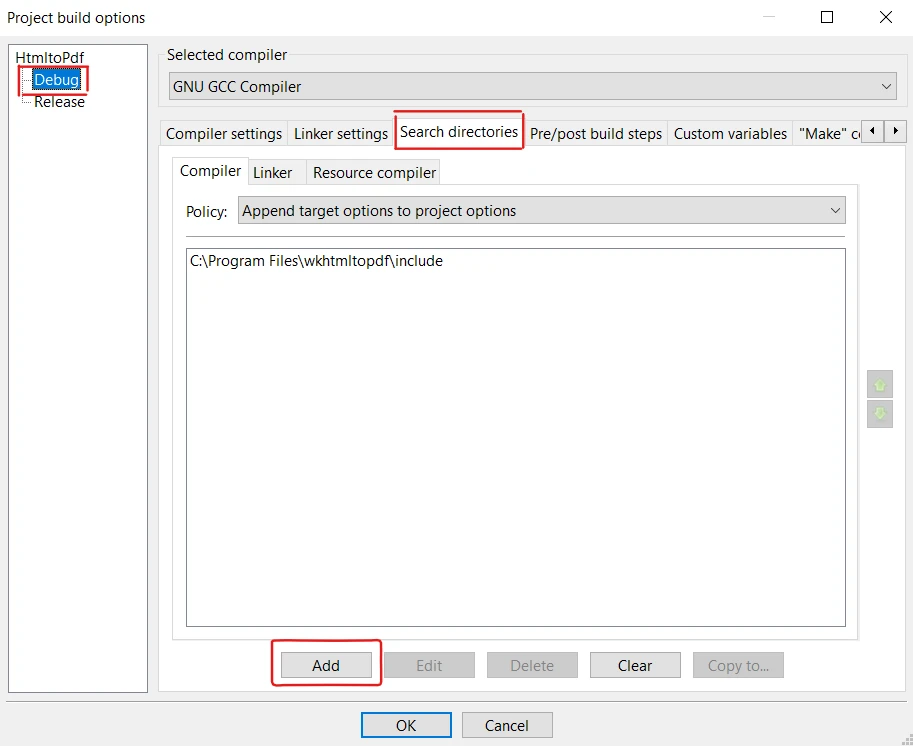
- Haga clic en el menú "Project" en la barra de menú y seleccione "Build options". Asegúrese de seleccionar "Debug".
- En el cuadro de diálogo "Build options", seleccione la pestaña "Search directories".
- Bajo la pestaña "Compiler", haga clic en el botón "Add".
- Navegue al directorio donde se encuentran los archivos de encabezado wkhtmltox (por ejemplo, C:\Program Files\wkhtmltopdf\include) y selecciónelo.
- Finalmente, haga clic en "OK" para cerrar el cuadro de diálogo.
Enlace de las bibliotecas
Para vincular la biblioteca wkhtmltox, siga estos pasos:
- De nuevo, haga clic en el menú "Project" en la barra de menú y seleccione "Build options". Asegúrese de seleccionar "Debug".
- En el cuadro de diálogo "Build options", seleccione la pestaña "Linker settings".
- Bajo la pestaña "Link libraries", haga clic en el botón "Add".
- Navegue al directorio donde se encuentran los archivos de la biblioteca wkhtmltox (por ejemplo, C:\Program Files\wkhtmltopdf\lib) y seleccione el archivo de biblioteca apropiado.
- Haga clic en "Open" para añadir la biblioteca a su proyecto.
- Finalmente, haga clic en "OK" para cerrar el cuadro de diálogo.

Pasos para convertir fácilmente HTML a PDF en C++
Paso 1: Incluir la biblioteca para convertir archivos HTML
Para comenzar, incluya los archivos de encabezado necesarios para utilizar las funcionalidades de la biblioteca wkhtmltopdf en su programa C++. Incluya los siguientes archivos de encabezado al comienzo del archivo de código fuente main.cpp como se muestra en el siguiente ejemplo:
#include <iostream>
#include <fstream>
#include <string>
#include <wkhtmltox/pdf.h>#include <iostream>
#include <fstream>
#include <string>
#include <wkhtmltox/pdf.h>Paso 2: Inicializar el conversor
Para convertir HTML a PDF, necesitamos inicializar el convertidor wkhtmltopdf. El código es el siguiente:
// Initialize the wkhtmltopdf library
wkhtmltopdf_init(false);
// Create global settings object
wkhtmltopdf_global_settings* gs = wkhtmltopdf_create_global_settings();
// Create object settings object
wkhtmltopdf_object_settings* os = wkhtmltopdf_create_object_settings();
// Create the PDF converter with global settings
wkhtmltopdf_converter* converter = wkhtmltopdf_create_converter(gs);// Initialize the wkhtmltopdf library
wkhtmltopdf_init(false);
// Create global settings object
wkhtmltopdf_global_settings* gs = wkhtmltopdf_create_global_settings();
// Create object settings object
wkhtmltopdf_object_settings* os = wkhtmltopdf_create_object_settings();
// Create the PDF converter with global settings
wkhtmltopdf_converter* converter = wkhtmltopdf_create_converter(gs);Paso 3: Configurar el contenido HTML
Ahora, proporcionemos el contenido HTML que necesita ser convertido a PDF. Puede cargar un archivo HTML o proporcionar la cadena directamente.
std::string htmlString = "<html><body><h1>Hello, World!</h1></body></html>";
// Add the HTML content to the converter
wkhtmltopdf_add_object(converter, os, htmlString.c_str());std::string htmlString = "<html><body><h1>Hello, World!</h1></body></html>";
// Add the HTML content to the converter
wkhtmltopdf_add_object(converter, os, htmlString.c_str());Paso 4: Conversión de HTML a PDF
Con el convertidor y el contenido HTML listos, podemos proceder a convertir el HTML a un archivo PDF. Use el siguiente fragmento de código:
// Perform the actual conversion
if (!wkhtmltopdf_convert(converter)) {
std::cerr << "Conversion failed!" << std::endl;
}// Perform the actual conversion
if (!wkhtmltopdf_convert(converter)) {
std::cerr << "Conversion failed!" << std::endl;
}Paso 5: Obtención de la salida como búfer de memoria
Con la función wkhtmltopdf_get_output, podemos obtener los datos PDF existentes como un flujo de búfer de memoria. También devuelve la longitud del PDF. El siguiente ejemplo realizará esta tarea:
// Retrieve the PDF data in memory buffer
const unsigned char* pdfData;
int pdfLength = wkhtmltopdf_get_output(converter, &pdfData);// Retrieve the PDF data in memory buffer
const unsigned char* pdfData;
int pdfLength = wkhtmltopdf_get_output(converter, &pdfData);Paso 6: Guardar el archivo PDF
Una vez que la conversión se completa, necesitamos guardar el archivo PDF generado en el disco. Especifique la ruta del archivo donde desea guardar el PDF. Luego, utilizando un flujo de archivo de salida, abra el archivo en modo binario y escriba el pdfData en él. Finalmente, cierre el archivo:
const char* outputPath = "file.pdf";
std::ofstream outputFile(outputPath, std::ios::binary);
// Write the PDF data to the file
outputFile.write(reinterpret_cast<const char*>(pdfData), pdfLength);
outputFile.close();const char* outputPath = "file.pdf";
std::ofstream outputFile(outputPath, std::ios::binary);
// Write the PDF data to the file
outputFile.write(reinterpret_cast<const char*>(pdfData), pdfLength);
outputFile.close();Paso 7: Limpieza
Después de convertir HTML a PDF, es esencial limpiar los recursos asignados por wkhtmltopdf:
// Clean up the converter and settings
wkhtmltopdf_destroy_converter(converter);
wkhtmltopdf_destroy_object_settings(os);
wkhtmltopdf_destroy_global_settings(gs);
// Deinitialize the wkhtmltopdf library
wkhtmltopdf_deinit();
std::cout << "PDF saved successfully." << std::endl;// Clean up the converter and settings
wkhtmltopdf_destroy_converter(converter);
wkhtmltopdf_destroy_object_settings(os);
wkhtmltopdf_destroy_global_settings(gs);
// Deinitialize the wkhtmltopdf library
wkhtmltopdf_deinit();
std::cout << "PDF saved successfully." << std::endl;Paso 8: Ejecutar el código y generar el archivo PDF
Ahora, compila el proyecto y ejecuta el código utilizando F9. La salida se genera y guarda en la carpeta del proyecto. El PDF resultante es el siguiente:
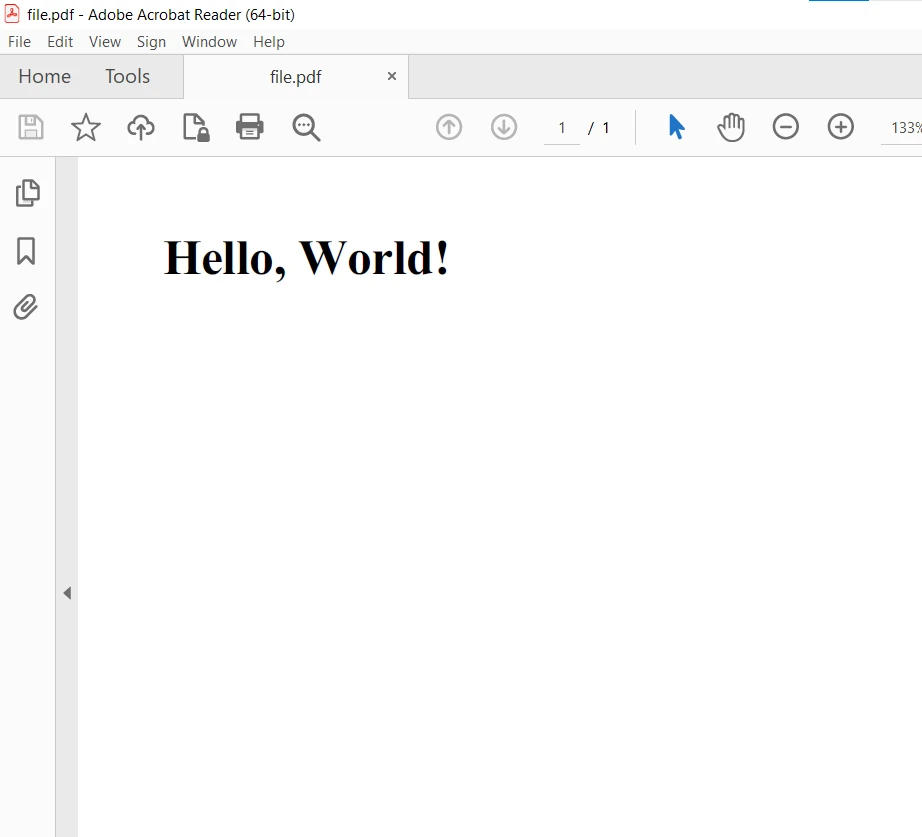
HTML File to PDF File in C
IronPDF
IronPDF HTML-to-PDF Conversion Library es una poderosa biblioteca .NET y .NET Core C# que permite a los desarrolladores generar documentos PDF a partir de contenido HTML sin esfuerzo. Proporciona una API sencilla e intuitiva que simplifica el proceso de conversión de páginas web HTML a PDF, convirtiéndola en una opción popular para diversas aplicaciones y casos de uso.
Una de las principales ventajas de IronPDF es su versatilidad. No solo soporta la conversión de documentos HTML simples, sino también de páginas web complejas con estilo CSS, interacciones JavaScript e incluso contenido dinámico. Además, puedes desarrollar diferentes convertidores de PDF con acceso rápido a sus métodos de conversión.
Aquí está el ejemplo de código para convertir Cadena HTML a PDF usando IronPDF en C#:
using IronPdf;
// Instantiate Renderer
var renderer = new ChromePdfRenderer();
// Create PDF content from an HTML string using C#
var pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1>");
// Export to a file or Stream
pdf.SaveAs("output.pdf");using IronPdf;
// Instantiate Renderer
var renderer = new ChromePdfRenderer();
// Create PDF content from an HTML string using C#
var pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1>");
// Export to a file or Stream
pdf.SaveAs("output.pdf");Imports IronPdf
' Instantiate Renderer
Private renderer = New ChromePdfRenderer()
' Create PDF content from an HTML string using C#
Private pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1>")
' Export to a file or Stream
pdf.SaveAs("output.pdf")La salida PDF:
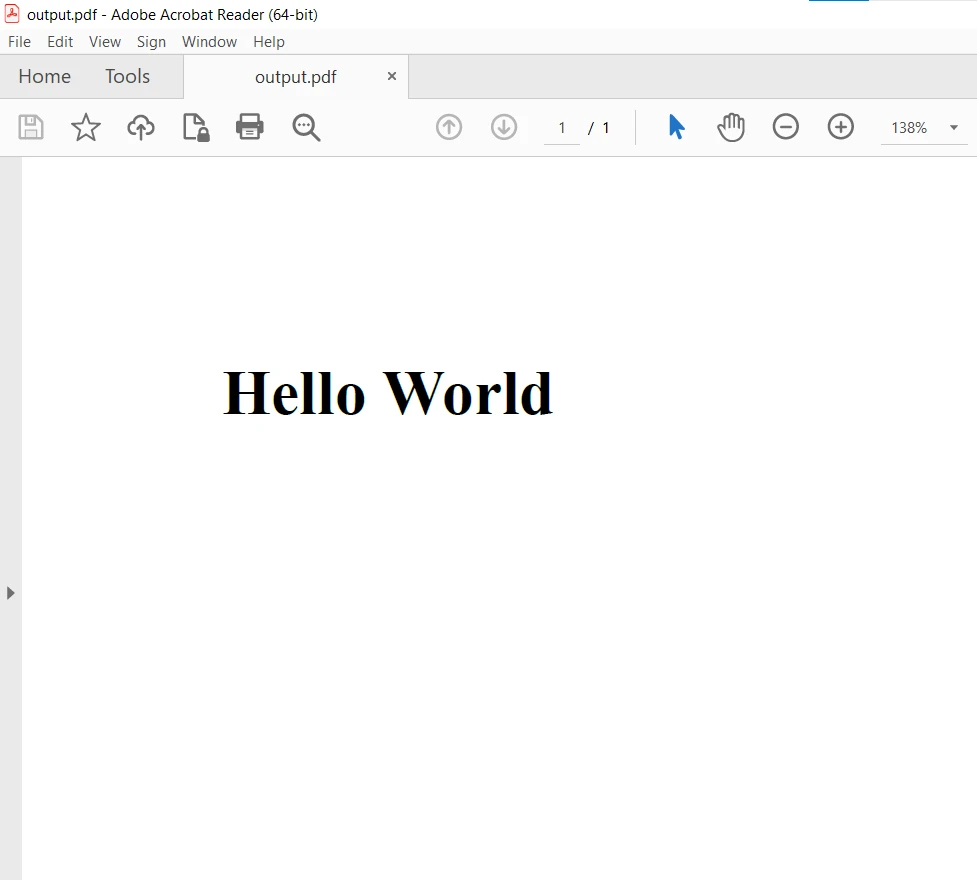
Para más detalles sobre cómo convertir diferentes archivos HTML, URLs de páginas web e imágenes a PDF, por favor visite este Ejemplos de Código de HTML a PDF.
Con IronPDF, la generación de archivos PDF a partir de contenido HTML se convierte en una tarea sencilla en lenguajes de .NET Framework. Su API intuitiva y conjunto de características extensas lo convierten en una herramienta valiosa para los desarrolladores que necesitan convertir HTML a PDF en sus proyectos C#. Ya sea generando informes, facturas o cualquier otro documento que requiera una conversión precisa de HTML a PDF, IronPDF es una solución confiable y eficiente.
IronPDF es gratuito para uso en desarrollo, pero requiere licencia para uso comercial. También ofrece una prueba gratuita de todas las funciones de IronPDF para evaluar su funcionalidad completa en entornos comerciales. Puede descargar el software desde Descargar IronPDF.














