
Node.jsでPuppeteerを使用してHTMLをPDFに変換する方法
今日のデジタル世界では、ウェブページやHTMLドキュメントをPDFファイルに変換する能力を持つことが重要です。 これは、レポート生成、請求書作成、または単に情報をより見栄えの良い形式で共有するために役立ちます。 このブログ記事では、Googleが開発したオープンソースライブラリであるNode.jsとPuppeteerを使用してHTMLページをPDFに変換する方法を探ります。
Puppeteerの紹介
Puppeteerは、主にGoogle ChromeまたはChromiumを扱うヘッドレスブラウザを制御し、ウェブスクレイピング、スクリーンショット撮影、PDF生成など、さまざまなアクションを実行できる強力なNode.jsライブラリです。 Puppeteerはブラウザと対話するための広範なAPIを提供し、HTMLをPDFに変換するための優れた選択肢です。
なぜPuppeteerなのか?
- 使いやすさ: Puppeteerは、ヘッドレスブラウザでの作業の複雑さを抽象化する、シンプルで使いやすいAPIを提供します。
- 強力: Puppeteerは、ウェブページの操作やブラウザ要素との相互作用に対する広範な機能を提供します。
- スケーラブル: Puppeteerを使用することで、複数のブラウザインスタンスを並行して実行することで、PDF生成プロセスを簡単にスケールアップできます。
Node.jsプロジェクトの設定
始める前に、新しいNode.jsプロジェクトを設定する必要があります。 開始するには、以下の手順に従ってください:
- まだインストールしていない場合はNode.jsをインストールしてください(Node.jsのウェブサイトからダウンロードできます)。
- プロジェクト用の新しいフォルダーを作成し、Visual Studio Codeや特定のコードエディターで開きます。
-
npm initを実行して、プロジェクト用の新しいpackage.jsonファイルを作成します。 プロンプトに従って必要な情報を入力します。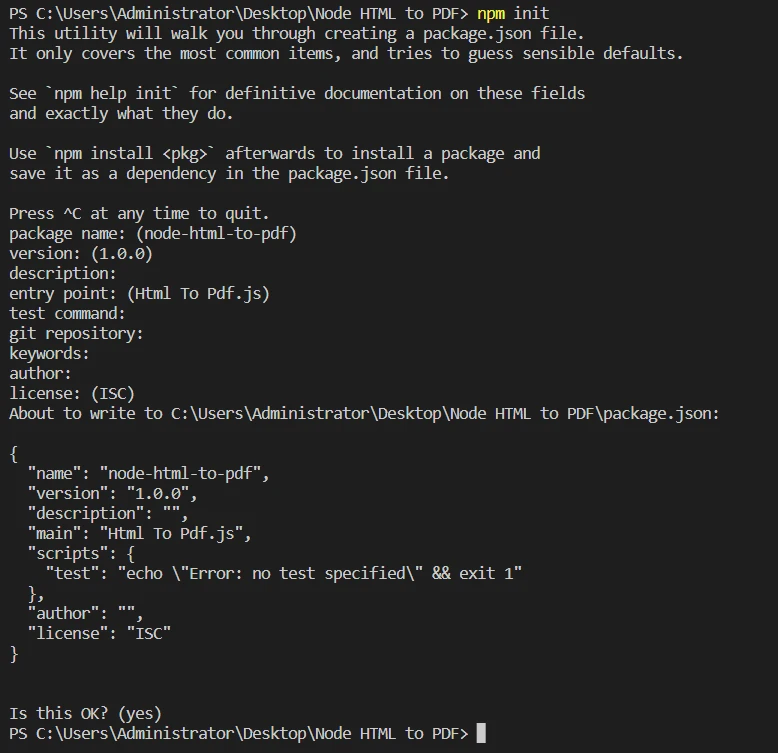
-
npm install puppeteerを実行して Puppeteer をインストールします。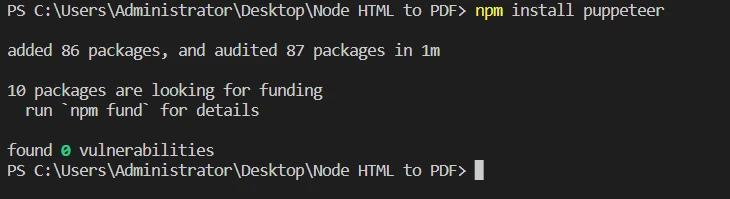
プロジェクトの設定が完了したので、コードに取り組みましょう。
HTMLテンプレートの読み込みとPDFファイルへの変換
Puppeteerを使用してHTMLテンプレートをPDFファイルに変換するには、次の手順に従います。
フォルダーに"HTML To PDF.js"という名前のファイルを作成します。
Puppeteerとfsのインポート
const puppeteer = require('puppeteer');
const fs = require('fs');このコードは、まず2つの重要なライブラリをインポートすることから始まります。1つは、ChromeやChromiumのようなヘッドレスブラウザを制御するための汎用ツールであるfsです。 Puppeteerを使用すると、HTMLのレンダリング、スクリーンショットの撮影、PDFファイルの生成など、幅広いウェブベースのタスクを自動化できます。
exportWebsiteAsPdf関数の定義
async function exportWebsiteAsPdf(html, outputPath) {
// Create a browser instance
const browser = await puppeteer.launch({
headless: true // Launches the browser in headless mode
});
// Create a new page
const page = await browser.newPage();
// Set the HTML content for the page, waiting for DOM content to load
await page.setContent(html, { waitUntil: 'domcontentloaded' });
// To reflect CSS used for screens instead of print
await page.emulateMediaType('screen');
// Download the PDF
const PDF = await page.pdf({
path: outputPath,
margin: { top: '100px', right: '50px', bottom: '100px', left: '50px' },
printBackground: true,
format: 'A4',
});
// Close the browser instance
await browser.close();
return PDF;
}exportWebsiteAsPdf 関数は、このコードスニペットの中核を成すものです。 この非同期関数は、入力パラメータとして文字列とPDFファイルを受け取ります。関数は以下の手順を実行します。
- Puppeteerを使用して新しいヘッドレスブラウザーインスタンスを起動します。
- 新しいブラウザーページを作成します。
- 指定された
html文字列をページコンテンツとして設定し、DOM コンテンツの読み込みを待ちます。 - "screen"メディアタイプをエミュレートし、印刷専用スタイルではなく画面用に使用されるCSSを適用します。
- 読み込まれたHTMLコンテンツからPDFファイルを生成し、余白、背景印刷、および形式(A4)を指定します。
- ブラウザーインスタンスを閉じます。
- 作成されたPDFファイルを返します。
exportWebsiteAsPdf関数の使用
// Usage example
// Get HTML content from HTML file
const html = fs.readFileSync('test.html', 'utf-8');
// Convert the HTML content into a PDF and save it to the specified path
exportWebsiteAsPdf(html, 'result.pdf').then(() => {
console.log('PDF created successfully.');
}).catch((error) => {
console.error('Error creating PDF:', error);
});コードの最後のセクションでは、exportWebsiteAsPdf 関数の使用方法を示しています。 次の手順を実行します。
fsモジュールのreadFileSyncメソッドを使用して、HTML ファイルから HTML コンテンツを読み取ります。- ロードされた文字列と目的の文字列を使用して、関数を呼び出します。
.thenブロックを使用して、PDF の作成が成功した場合を処理し、成功メッセージをコンソールにログ出力します。.catchブロックを使用して、HTML から PDF への変換プロセス中に発生するエラーを処理し、エラー メッセージをコンソールにログ出力します。
このコードスニペットは、Node.jsとPuppeteerを使用してHTMLテンプレートをPDFファイルに変換する方法の包括的な例です。 このソリューションを実装することで、さまざまなアプリケーションやユーザーのニーズに応じた高品質のPDFを効率的に生成できます。
URLのPDFファイルへの変換
HTMLテンプレートの変換に加えて、Puppeteerを使用するとURLを直接PDFファイルに変換することもできます。
Puppeteerのインポート
const puppeteer = require('puppeteer');コードは、ChromeやChromiumのようなヘッドレスブラウザを制御する強力なツールであるPuppeteerライブラリをインポートすることで始まります。 Puppeteerを使用すると、HTMLコードのレンダリング、スクリーンショットの撮影、そして今回のケースのようにPDFファイルの生成など、さまざまなウェブベースのタスクを自動化できます。
exportWebsiteAsPdf関数の定義
async function exportWebsiteAsPdf(websiteUrl, outputPath) {
// Create a browser instance
const browser = await puppeteer.launch({
headless: true // Launches the browser in headless mode
});
// Create a new page
const page = await browser.newPage();
// Open the URL in the current page
await page.goto(websiteUrl, { waitUntil: 'networkidle0' });
// To reflect CSS used for screens instead of print
await page.emulateMediaType('screen');
// Download the PDF
const PDF = await page.pdf({
path: outputPath,
margin: { top: '100px', right: '50px', bottom: '100px', left: '50px' },
printBackground: true,
format: 'A4',
});
// Close the browser instance
await browser.close();
return PDF;
}exportWebsiteAsPdf 関数は、このコードスニペットの中核を成すものです。 この非同期関数は、入力パラメータとして websiteUrl と outputPath を受け取り、PDF ファイルを返します。この関数は、以下の手順を実行します。
- Puppeteerを使用して新しいヘッドレスブラウザーインスタンスを起動します。
- 新しいブラウザーページを作成します。
- 指定された
websiteUrlに移動し、waitUntilオプションをnetworkidle0に設定してネットワークがアイドル状態になるまで待機します。 - 画面専用スタイルが適用されるように"screen"メディアタイプをエミュレートします。
- 読み込まれたWebページを指定された余白、背景印刷、および形式(A4)でPDFファイルに変換します。
- ブラウザーインスタンスを閉じます。
- 生成されたPDFファイルを返します。
exportWebsiteAsPdf関数の使用
// Usage example
// Convert the URL content into a PDF and save it to the specified path
exportWebsiteAsPdf('https://ironpdf.com/', 'result.pdf').then(() => {
console.log('PDF created successfully.');
}).catch((error) => {
console.error('Error creating PDF:', error);
});コードの最後のセクションでは、exportWebsiteAsPdf 関数の使用方法を示しています。 以下の手順を実行します。
- 目的の
websiteUrlとoutputPathを使用してexportWebsiteAsPdf関数を呼び出します。 thenブロックを使用して、PDF の作成が成功したことを処理します。 このブロックでは、コンソールに成功メッセージをログに記録します。catchブロックを使用して、WebサイトからPDFへの変換プロセス中に発生するエラーを処理します。 エラーが発生した場合、コンソールにエラーメッセージをログに記録します。
このコードスニペットをプロジェクトに統合することで、Node.jsとPuppeteerを使用して簡単に高品質のPDFファイルにURLを変換できます。
C#開発者のための最高のHTML To PDFライブラリ
IronPDFを探るは、PDFファイルの生成、編集、コンテンツ抽出に使用される人気のある.NETライブラリです。 HTML、テキスト、画像、既存のPDFドキュメントからPDFを作成するためのシンプルで効率的なソリューションを提供します。 IronPDFは、.NET Core、.NET Framework、.NET 5.0+プロジェクトに対応しており、さまざまなアプリケーションにとって汎用性の高い選択肢です。
IronPDFの主な機能
IronPDFによるHTMLからPDFへの変換: IronPDFを使用すると、CSSを含むHTMLコンテンツをPDFファイルに変換できます。 この機能によりウェブページやHTMLテンプレートからピクセルパーフェクトなPDFドキュメントを作成できます。
URLレンダリング: IronPDFは、URLを使用してサーバーからWebページを直接取得し、PDFファイルに変換できるため、Webコンテンツのアーカイブや動的なWebページからのレポート生成が容易になります。
テキスト、画像、PDFの結合: IronPDFを使用すると、テキスト、画像、既存のPDFファイルを1つのPDFドキュメントに結合できます。 この機能は、複数のコンテンツソースを持つ複雑なドキュメントを作成するのに特に便利です。
PDF操作: IronPDFは、既存のPDFファイルを編集するためのツールを提供します。例えば、ページの追加や削除、メタデータの変更、さらにはPDF文書からのテキストや画像の抽出などが可能です。
結論
結論として、多くのアプリケーションでPDFファイルの生成と操作は一般的な要件であり、適切なツールを手元に置くことが重要です。 この記事で紹介するソリューション、例えばNode.jsでPuppeteerを使用したり、.NETでIronPDFを使用したりすることで、HTMLコンテンツやURLをプロフェッショナルで高品質のPDFドキュメントに変換するための強力で効率的な方法を提供します。
特にIronPDFは、豊富な機能セットで際立っており、.NET開発者にとって最良の選択肢となっています。 IronPDFは、機能を探ることができる無料トライアルを提供します。
Iron Suiteパッケージは、IronXL、IronPDF、IronOCRなど、5つのプロフェッショナルな.NETライブラリのスイートです。














