
Jak przekonwertować HTML na PDF C# bez biblioteki
W dzisiejszym cyfrowym świecie programowe generowanie profesjonalnych dokumentów PDF stało się podstawowym wymogiem dla aplikacji .NET. Niezależnie od tego, czy programiści tworzą systemy raportowania dla Enterprise, generują faktury dla klientów, czy też tworzą automatyczne pliki PDF, potrzebują niezawodnego rozwiązania PDF API .NET, które płynnie integruje się z ich projektami .NET. IronPDF to kompleksowa biblioteka PDF, oferująca potężny, a jednocześnie intuicyjny interfejs API .NET PDF, który zmienia sposób, w jaki programiści podchodzą do generowania i manipulowania dokumentami PDF w ekosystemie .NET.
Wyzwania związane z tworzeniem plików PDF w aplikacjach .NET znacznie ewoluowały. Tradycyjne podejście do dokumentów PDF często wymagało złożonej logiki pozycjonowania, ręcznych obliczeń układu oraz dogłębnego zrozumienia specyfikacji formatu PDF. Nowoczesne rozwiązania API do obsługi plików PDF zrewolucjonizowały ten proces, wykorzystując znane technologie internetowe, umożliwiając programistom konwersję HTML do PDF przy użyciu istniejącej wiedzy z zakresu CSS i JavaScript w celu tworzenia zaawansowanych plików PDF. Obecnie biblioteki .NET do obsługi plików PDF oferują rozwiązania, które pozwalają na obsługę treści PDF, formularzy PDF, podpisów cyfrowych, wyodrębnianie obrazów oraz istniejących dokumentów za pomocą zaledwie kilku linii kodu. Dowiedz się więcej o konwersji HTML do PDF z przykładami kodu, aby zobaczyć, jak ta konwersja PDF działa w praktyce.
Co sprawia, że API dokumentów PDF dla .NET jest doskonałe?
Solidne rozwiązanie API .NET do obsługi plików PDF musi spełniać kluczowe wymagania nowoczesnych aplikacji .NET pracujących z dokumentami PDF. Podstawą każdego interfejsu API dokumentów PDF są dokładne możliwości renderowania, które zachowują wierność wizualną podczas tworzenia plików PDF z treści źródłowej, niezależnie od tego, czy konwertuje się HTML, obrazy czy istniejące dokumenty. Biblioteka PDF powinna obsługiwać złożone układy w formacie PDF, wspierać nowoczesne funkcje CSS3 oraz wykonywać kod JavaScript w celu dynamicznego generowania treści PDF w projektach .NET.
Kompatybilność międzyplatformowa stała się niezbędna, ponieważ aplikacje .NET są wdrażane w systemach Windows, Linux, macOS oraz w środowiskach kontenerowych. Naprawdę skuteczne API PDF działa płynnie na tych platformach, nie wymagając kodu specyficznego dla danej platformy podczas pracy z plikami PDF. Ta elastyczność obejmuje wdrożenia w chmurze po stronie serwera na platformach Azure, AWS i innych platformach hostingowych, gdzie skalowalność i efektywność wykorzystania zasobów mają znaczenie dla generowania dokumentów PDF.
Nie da się przecenić znaczenia dokładności konwersji HTML do PDF w API dokumentów PDF. Programiści wkładają wiele wysiłku w tworzenie idealnych układów stron internetowych, a wysokiej jakości biblioteka .NET do obsługi plików PDF powinna wiernie przekładać te projekty na format PDF. Obejmuje to prawidłowe obchodzenie się z projektami responsywnymi, niestandardowymi czcionkami, złożonymi układami CSS oraz obrazami osadzonymi w plikach PDF. Silnik renderujący staje się sercem każdego interfejsu API PDF .NET, decydując zarówno o jakości generowanych treści PDF, jak i łatwości wdrożenia. Aby uzyskać najlepsze wyniki w przypadku dokumentów PDF, przed konwersją do formatu PDF sprawdź poprawność kodu HTML za pomocą walidatora W3C.
Pierwsze kroki z interfejsem API PDF firmy IronPDF
IronPDF upraszcza generowanie plików PDF w aplikacjach .NET dzięki intuicyjnej konstrukcji API dokumentów PDF i prostemu procesowi instalacji. Biblioteka PDF integruje się płynnie z każdym projektem .NET za pośrednictwem NuGet, obsługując .NET Framework, .NET Core oraz najnowsze wersje .NET do tworzenia dokumentów PDF.
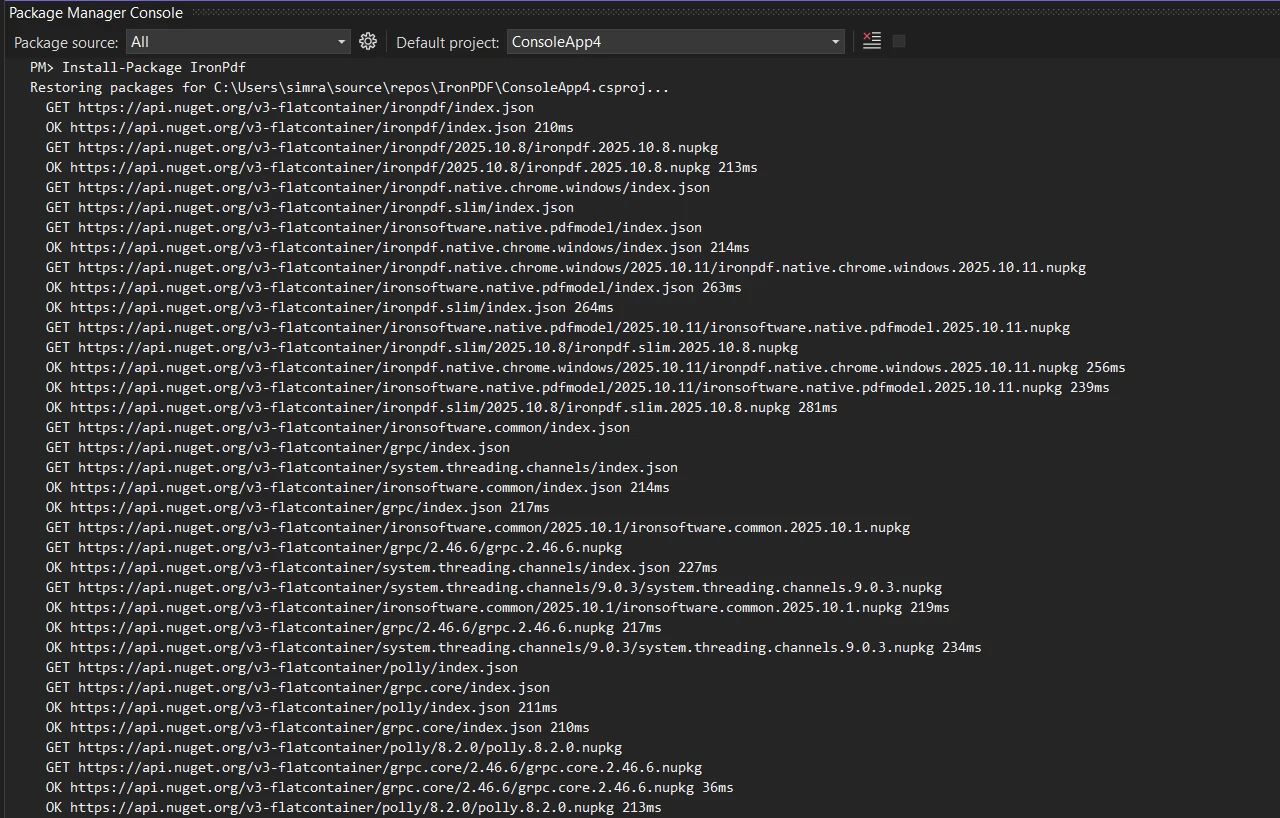
Aby rozpocząć korzystanie z interfejsu API PDF .NET firmy IronPDF w projektach .NET, zainstaluj bibliotekę PDF za pomocą menedżera pakietów NuGet w programie Visual Studio:
Install-Package IronPdf
Po zainstalowaniu, główną klasą do generowania dokumentów PDF jest ChromePdfRenderer. Ten renderer wykorzystuje silnik oparty na Chromium do konwersji treści HTML na pliki PDF z wyjątkową dokładnością:
using IronPdf;
var renderer = new ChromePdfRenderer();
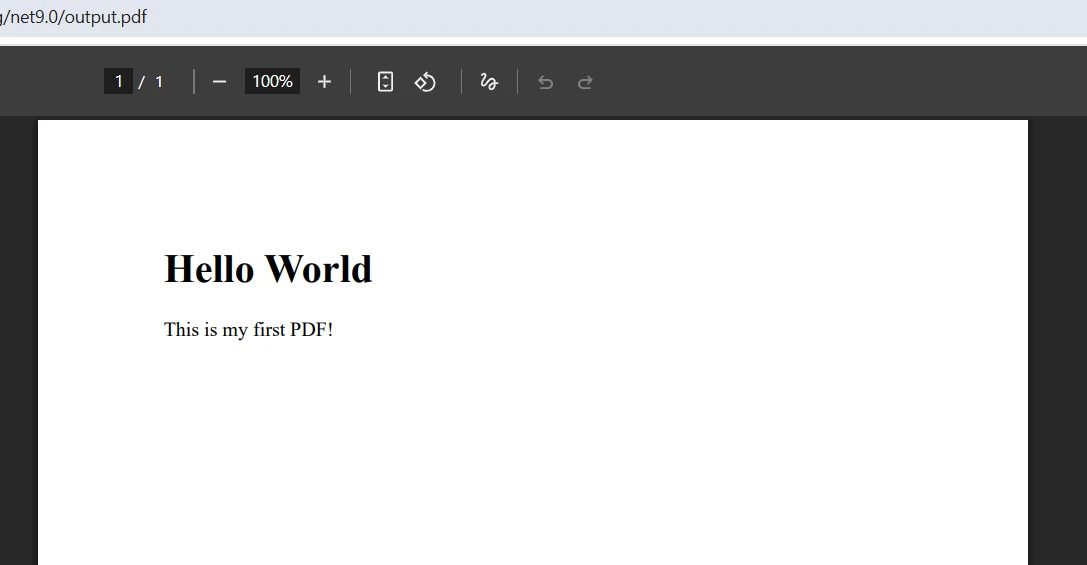
var pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1><p>This is my first PDF!</p>");
pdf.SaveAs("output.pdf");using IronPdf;
var renderer = new ChromePdfRenderer();
var pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1><p>This is my first PDF!</p>");
pdf.SaveAs("output.pdf");Imports IronPdf
Dim renderer As New ChromePdfRenderer()
Dim pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1><p>This is my first PDF!</p>")
pdf.SaveAs("output.pdf")Ten kod tworzy nową instancję ChromePdfRenderer dla PDF API, konwertuje ciąg HTML na dokument PDF i zapisuje pliki PDF na dysku. Klasa ChromePdfRenderer służy jako centralny komponent do konwersji HTML na PDF, oferując spójne renderowanie zawartości PDF z różnych źródeł. Renderer wewnętrznie obsługuje wszystkie złożone procesy związane z parsowaniem HTML, stosowaniem CSS i generowaniem plików PDF, co pozwala programistom skupić się na treści pliku PDF, a nie na specyfikacjach formatu PDF.
Wynik
Zrozumienie architektury ChromePdfRenderer pomaga deweloperom .NET w pełnym wykorzystaniu potencjału tego API dokumentów PDF. Renderer utrzymuje własną instancję Chromium do generowania plików PDF, zapewniając spójne renderowanie plików PDF niezależnie od konfiguracji przeglądarki systemu hosta. Ta izolacja zapewnia przewidywalne dokumenty PDF w różnych środowiskach wdrożeniowych, jednocześnie obsługując najnowsze standardy internetowe, w tym HTML5, CSS3 i nowoczesne frameworki JavaScript do tworzenia plików PDF.
Jak generować pliki PDF z różnych źródeł?
Elastyczność interfejsu API PDF .NET firmy IronPDF przejawia się w możliwości generowania dokumentów PDF z różnych źródeł treści. Każda metoda tworzenia plików PDF odpowiada na różne potrzeby, zachowując jednocześnie stałą jakość renderowania treści PDF oraz prostotę API dokumentów PDF.
Konwersja ciągów znaków HTML do formatu PDF
Bezpośrednia konwersja ciągów HTML do formatu PDF okazuje się nieoceniona podczas generowania dynamicznych dokumentów PDF na podstawie szablonów lub programowego tworzenia plików PDF w aplikacjach .NET:
var renderer = new ChromePdfRenderer();
string htmlContent = @"
<html>
<head>
<style>
body { font-family: Arial, sans-serif; font-size: 12px; }
.header { color: #2c3e50; }
</style>
</head>
<body>
<h1 class='header'>Sales Report PDF Document</h1>
<p>Quarterly PDF file results for Q1 2024</p>
</body>
</html>";
var pdf = renderer.RenderHtmlAsPdf(htmlContent);
pdf.SaveAs("sales-report.pdf");var renderer = new ChromePdfRenderer();
string htmlContent = @"
<html>
<head>
<style>
body { font-family: Arial, sans-serif; font-size: 12px; }
.header { color: #2c3e50; }
</style>
</head>
<body>
<h1 class='header'>Sales Report PDF Document</h1>
<p>Quarterly PDF file results for Q1 2024</p>
</body>
</html>";
var pdf = renderer.RenderHtmlAsPdf(htmlContent);
pdf.SaveAs("sales-report.pdf");Dim renderer As New ChromePdfRenderer()
Dim htmlContent As String = "
<html>
<head>
<style>
body { font-family: Arial, sans-serif; font-size: 12px; }
.header { color: #2c3e50; }
</style>
</head>
<body>
<h1 class='header'>Sales Report PDF Document</h1>
<p>Quarterly PDF file results for Q1 2024</p>
</body>
</html>"
Dim pdf = renderer.RenderHtmlAsPdf(htmlContent)
pdf.SaveAs("sales-report.pdf")To podejście do API PDF .NET pozwala na pełną kontrolę nad strukturą i stylem HTML podczas tworzenia plików PDF. Renderer przetwarza wbudowane arkusze CSS dla dokumentów PDF, zapewniając prawidłowe zastosowanie stylów do wygenerowanej zawartości PDF. Silniki szablonów mogą dynamicznie generować kod HTML do konwersji do formatu PDF, włączając dane z baz danych lub interfejsów API przed utworzeniem plików PDF. Metoda obsługuje złożone struktury HTML w dokumentach PDF, w tym tabele, elementy zagnieżdżone i treści multimedialne w formacie PDF.
Tworzenie plików PDF z adresów URL
Konwersja stron internetowych do formatu PDF umożliwia przechwytywanie istniejących treści internetowych lub generowanie plików PDF z aplikacji internetowych przy użyciu interfejsu API dokumentów PDF:
var renderer = new ChromePdfRenderer();
renderer.RenderingOptions.PrintHtmlBackgrounds = true;
var pdf = renderer.RenderUrlAsPdf("https://ironpdf.com/");
pdf.SaveAs("web-report.pdf");var renderer = new ChromePdfRenderer();
renderer.RenderingOptions.PrintHtmlBackgrounds = true;
var pdf = renderer.RenderUrlAsPdf("https://ironpdf.com/");
pdf.SaveAs("web-report.pdf");Dim renderer As New ChromePdfRenderer()
renderer.RenderingOptions.PrintHtmlBackgrounds = True
Dim pdf = renderer.RenderUrlAsPdf("https://ironpdf.com/")
pdf.SaveAs("web-report.pdf")Metoda renderowania adresów URL w tym API PDF ładuje całe strony internetowe do konwersji do formatu PDF, uruchamia JavaScript i czeka na wyrenderowanie treści przed wygenerowaniem dokumentów PDF. Ta funkcja okazuje się szczególnie przydatna do konwersji istniejących raportów internetowych do plików PDF, przechwytywania stanów pulpitów nawigacyjnych w formacie PDF lub archiwizowania treści internetowych jako dokumentów PDF. Renderer uwzględnia zapytania o media CSS strony podczas tworzenia plików PDF, co pozwala witrynom automatycznie dostarczać układy zoptymalizowane pod kątem druku do generowania plików PDF.
Wynik

Praca z plikami HTML
Konwersja plików do formatu PDF usprawnia przepływ pracy w sytuacjach, gdy szablony HTML do tworzenia dokumentów PDF znajdują się w systemie plików:
var renderer = new ChromePdfRenderer();
renderer.RenderingOptions.MarginTop = 25;
renderer.RenderingOptions.MarginBottom = 25;
var pdf = renderer.RenderHtmlFileAsPdf("template.html");
pdf.SaveAs("document.pdf");var renderer = new ChromePdfRenderer();
renderer.RenderingOptions.MarginTop = 25;
renderer.RenderingOptions.MarginBottom = 25;
var pdf = renderer.RenderHtmlFileAsPdf("template.html");
pdf.SaveAs("document.pdf");Dim renderer As New ChromePdfRenderer()
renderer.RenderingOptions.MarginTop = 25
renderer.RenderingOptions.MarginBottom = 25
Dim pdf = renderer.RenderHtmlFileAsPdf("template.html")
pdf.SaveAs("document.pdf")Ta metoda API PDF .NET ładuje pliki HTML wraz z odwołanymi zasobami, takimi jak pliki CSS, obrazy i skrypty, w celu utworzenia dokumentu PDF. Ścieżki względne w HTML są poprawnie rozpoznawane w przypadku plików PDF, co pozwala zachować relacje w strukturze plików. Organizacje często stosują to podejście w przypadku szablonów HTML podlegających kontroli wersji do generowania plików PDF, oddzielając projekt dokumentu od logiki aplikacji podczas tworzenia plików PDF. Renderer obsługuje zewnętrzne arkusze stylów i zasoby, na które odwołują się linki, zapewniając pełną wierność dokumentu PDF. Szczegółowe wskazówki dotyczące konwersji plików HTML do formatu PDF można znaleźć w dokumentacji dotyczącej konwersji plików HTML do formatu PDF.
Jak dostosować plik PDF?
PDF API IronPDF oferuje rozległe opcje dostosowywania przez właściwość RenderingOptions dla dokumentów PDF, umożliwiając precyzyjną kontrolę nad generowaniem plików PDF. Ustawienia te mają wpływ na wszystko, od wymiarów strony po sposób renderowania treści PDF w aplikacjach .NET tworzących pliki PDF.
Ustawienia strony i marginesy dla dokumentów PDF
Kontrola układu strony zapewnia, że dokumenty PDF spełniają określone wymagania dotyczące formatowania podczas korzystania z interfejsu API dokumentów PDF do tworzenia plików PDF:
var renderer = new ChromePdfRenderer();
renderer.RenderingOptions.PaperOrientation = PdfPaperOrientation.Landscape;
renderer.RenderingOptions.PaperSize = PdfPaperSize.A4;
renderer.RenderingOptions.MarginTop = 40;
renderer.RenderingOptions.MarginBottom = 40;
renderer.RenderingOptions.MarginLeft = 20;
renderer.RenderingOptions.MarginRight = 20;
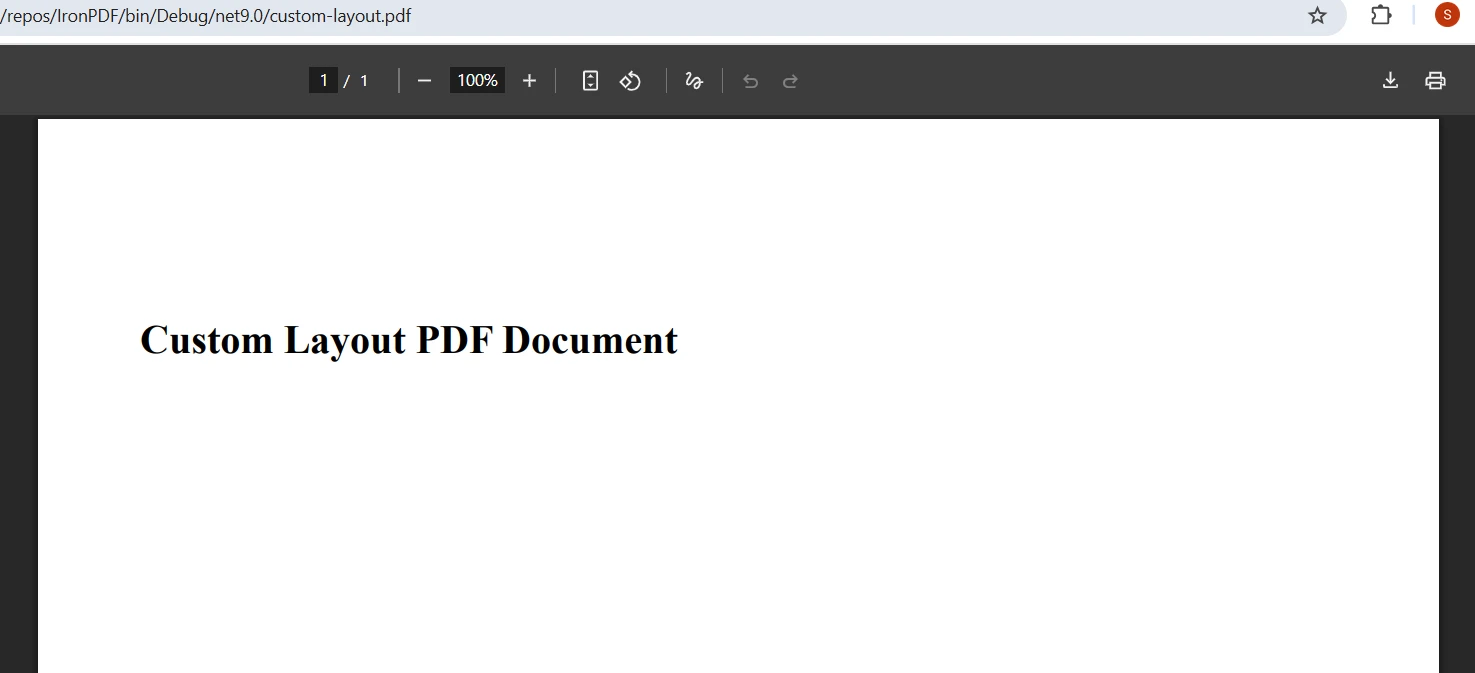
var pdf = renderer.RenderHtmlAsPdf("<h1>Custom Layout PDF Document</h1>");
pdf.SaveAs("custom-layout.pdf");var renderer = new ChromePdfRenderer();
renderer.RenderingOptions.PaperOrientation = PdfPaperOrientation.Landscape;
renderer.RenderingOptions.PaperSize = PdfPaperSize.A4;
renderer.RenderingOptions.MarginTop = 40;
renderer.RenderingOptions.MarginBottom = 40;
renderer.RenderingOptions.MarginLeft = 20;
renderer.RenderingOptions.MarginRight = 20;
var pdf = renderer.RenderHtmlAsPdf("<h1>Custom Layout PDF Document</h1>");
pdf.SaveAs("custom-layout.pdf");Dim renderer = New ChromePdfRenderer()
renderer.RenderingOptions.PaperOrientation = PdfPaperOrientation.Landscape
renderer.RenderingOptions.PaperSize = PdfPaperSize.A4
renderer.RenderingOptions.MarginTop = 40
renderer.RenderingOptions.MarginBottom = 40
renderer.RenderingOptions.MarginLeft = 20
renderer.RenderingOptions.MarginRight = 20
Dim pdf = renderer.RenderHtmlAsPdf("<h1>Custom Layout PDF Document</h1>")
pdf.SaveAs("custom-layout.pdf")Te ustawienia API PDF .NET kontrolują fizyczne właściwości stron generowanych plików PDF. Opcje rozmiaru papieru dla dokumentów PDF obejmują standardowe formaty, takie jak A4, Letter i Legal, a także niestandardowe wymiary dostosowane do specjalistycznych wymagań dotyczących plików PDF. Marginesy zapewniają spójne odstępy wokół treści pliku PDF, co jest niezbędne dla profesjonalnego wyglądu dokumentu PDF. Ustawienie orientacji pozwala przełączać się między trybem pionowym a poziomym dla plików PDF, dostosowując się do wymagań dotyczących zawartości plików PDF w projektach .NET.
Wynik
Nagłówki i stopki w plikach PDF
Profesjonalne dokumenty PDF często wymagają spójnych nagłówków i stopek na wszystkich stronach podczas tworzenia plików PDF za pomocą biblioteki PDF:
var renderer = new ChromePdfRenderer();
renderer.RenderingOptions.TextHeader = new TextHeaderFooter
{
CenterText = "Confidential PDF Report",
RightText = "{date}",
DrawDividerLine = true
};
renderer.RenderingOptions.TextFooter = new TextHeaderFooter
{
LeftText = "© 2024 Company PDF Document",
CenterText = "Page {page} of {total-pages}"
};
var pdf = renderer.RenderHtmlAsPdf("<h1>PDF Document with Headers</h1>");
pdf.SaveAs("headed-document.pdf");var renderer = new ChromePdfRenderer();
renderer.RenderingOptions.TextHeader = new TextHeaderFooter
{
CenterText = "Confidential PDF Report",
RightText = "{date}",
DrawDividerLine = true
};
renderer.RenderingOptions.TextFooter = new TextHeaderFooter
{
LeftText = "© 2024 Company PDF Document",
CenterText = "Page {page} of {total-pages}"
};
var pdf = renderer.RenderHtmlAsPdf("<h1>PDF Document with Headers</h1>");
pdf.SaveAs("headed-document.pdf");Dim renderer = New ChromePdfRenderer()
renderer.RenderingOptions.TextHeader = New TextHeaderFooter With {
.CenterText = "Confidential PDF Report",
.RightText = "{date}",
.DrawDividerLine = True
}
renderer.RenderingOptions.TextFooter = New TextHeaderFooter With {
.LeftText = "© 2024 Company PDF Document",
.CenterText = "Page {page} of {total-pages}"
}
Dim pdf = renderer.RenderHtmlAsPdf("<h1>PDF Document with Headers</h1>")
pdf.SaveAs("headed-document.pdf")Nagłówki i stopki w plikach PDF obsługują zarówno zwykły tekst, jak i zawartość HTML z polami scałania dla wartości dynamicznych w dokumentach PDF. Tokeny {page} i {total-pages} automatycznie wypełniają się numerami stron w plikach PDF, podczas gdy {date} wstawia bieżącą datę w formacie PDF. Linie dzielące zapewniają wizualne oddzielenie nagłówków od głównej treści pliku PDF. Elementy te zachowują spójne rozmieszczenie na wszystkich stronach dokumentów PDF, tworząc profesjonalnie wyglądające pliki PDF za pomocą biblioteki .NET PDF.
Typy mediów CSS i obsługa JavaScript dla plików PDF
Nowoczesne aplikacje internetowe często wymagają wykonywania kodu JavaScript i prawidłowej obsługi mediów CSS podczas konwersji do dokumentów PDF przy użyciu interfejsu API PDF:
var renderer = new ChromePdfRenderer();
renderer.RenderingOptions.CssMediaType = PdfCssMediaType.Screen;
renderer.RenderingOptions.EnableJavaScript = true;
renderer.RenderingOptions.WaitFor.RenderDelay(500);
var pdf = renderer.RenderUrlAsPdf("https://ironpdf.com/");
pdf.SaveAs("dynamic.pdf");var renderer = new ChromePdfRenderer();
renderer.RenderingOptions.CssMediaType = PdfCssMediaType.Screen;
renderer.RenderingOptions.EnableJavaScript = true;
renderer.RenderingOptions.WaitFor.RenderDelay(500);
var pdf = renderer.RenderUrlAsPdf("https://ironpdf.com/");
pdf.SaveAs("dynamic.pdf");Dim renderer As New ChromePdfRenderer()
renderer.RenderingOptions.CssMediaType = PdfCssMediaType.Screen
renderer.RenderingOptions.EnableJavaScript = True
renderer.RenderingOptions.WaitFor.RenderDelay(500)
Dim pdf = renderer.RenderUrlAsPdf("https://ironpdf.com/")
pdf.SaveAs("dynamic.pdf")Ustawienie CssMediaType określa, które reguły CSS są stosowane podczas renderowania pliku PDF. Typ nośnika ekranowego zachowuje wygląd strony internetowej w dokumentach PDF, natomiast typ nośnika PRINT stosuje style specyficzne dla druku do plików PDF. Obsługa JavaScript umożliwia dynamiczne generowanie treści PDF, co ma kluczowe znaczenie dla nowoczesnych aplikacji jednostronicowych tworzących pliki PDF. Opóźnienie renderowania zapewnia, że treść asynchroniczna zostanie całkowicie załadowana przed rozpoczęciem generowania dokumentu PDF. Te opcje API PDF .NET wypełniają lukę między interaktywnymi aplikacjami internetowymi a statycznymi plikami PDF w aplikacjach .NET.
Wynik

Jakie zaawansowane możliwości oferuje IronPDF?
Oprócz podstawowej konwersji HTML do PDF, interfejs API PDF firmy IronPDF oferuje zaawansowane funkcje do tworzenia interaktywnych dokumentów PDF, zabezpieczania treści PDF oraz edycji istniejących plików PDF. Te możliwości sprawiają, że biblioteka .NET PDF z prostego narzędzia do konwersji plików PDF staje się kompleksowym rozwiązaniem API dla dokumentów PDF przeznaczonym dla aplikacji .NET pracujących z formatem PDF.
Tworzenie i edycja formularzy w dokumentach PDF
Interfejs API PDF .NET firmy IronPDF automatycznie konwertuje elementy formularzy HTML na interaktywne formularze PDF w plikach PDF. Ta funkcja usprawnia przepływ pracy z dokumentami PDF poprzez tworzenie formularzy PDF bezpośrednio z kodu HTML w projektach .NET. Pola formularzy w dokumentach PDF umożliwiają gromadzenie danych bez konieczności drukowania. Dowiedz się więcej o tworzeniu formularzy PDF w dokumentacji biblioteki PDF:
var renderer = new ChromePdfRenderer();
renderer.RenderingOptions.CreatePdfFormsFromHtml = true;
string formHtml = @"
<form>
<label>Name: <input type='text' name='name'>
<label>Email: <input type='text' name='email'>
<label>Subscribe: <input type='checkbox' name='subscribe'>
<button type='submit'>Submit PDF Form</button>
</form>";
var pdf = renderer.RenderHtmlAsPdf(formHtml);
pdf.SaveAs("interactive-form.pdf");var renderer = new ChromePdfRenderer();
renderer.RenderingOptions.CreatePdfFormsFromHtml = true;
string formHtml = @"
<form>
<label>Name: <input type='text' name='name'>
<label>Email: <input type='text' name='email'>
<label>Subscribe: <input type='checkbox' name='subscribe'>
<button type='submit'>Submit PDF Form</button>
</form>";
var pdf = renderer.RenderHtmlAsPdf(formHtml);
pdf.SaveAs("interactive-form.pdf");Imports IronPdf
Dim renderer As New ChromePdfRenderer()
renderer.RenderingOptions.CreatePdfFormsFromHtml = True
Dim formHtml As String = "
<form>
<label>Name: <input type='text' name='name'>
<label>Email: <input type='text' name='email'>
<label>Subscribe: <input type='checkbox' name='subscribe'>
<button type='submit'>Submit PDF Form</button>
</form>"
Dim pdf = renderer.RenderHtmlAsPdf(formHtml)
pdf.SaveAs("interactive-form.pdf")Ta funkcja API dokumentów PDF zachowuje funkcjonalność formularzy w plikach PDF, umożliwiając użytkownikom wypełnianie pól formularzy bezpośrednio w czytnikach PDF. Pola tekstowe, pola wyboru, przyciski opcji i menu rozwijane są konwertowane na odpowiedniki w formularzu PDF. Powstałe formularze PDF działają w standardowych czytnikach PDF, umożliwiając gromadzenie danych w dokumentach PDF bez konieczności drukowania i skanowania plików PDF przez użytkowników. Można również eksportować dane z formularzy do formatu XML lub programowo wyodrębniać tekst z formularzy PDF w celu przetworzenia, tworząc płynne cyfrowe przepływy pracy z dokumentami PDF w aplikacjach .NET.
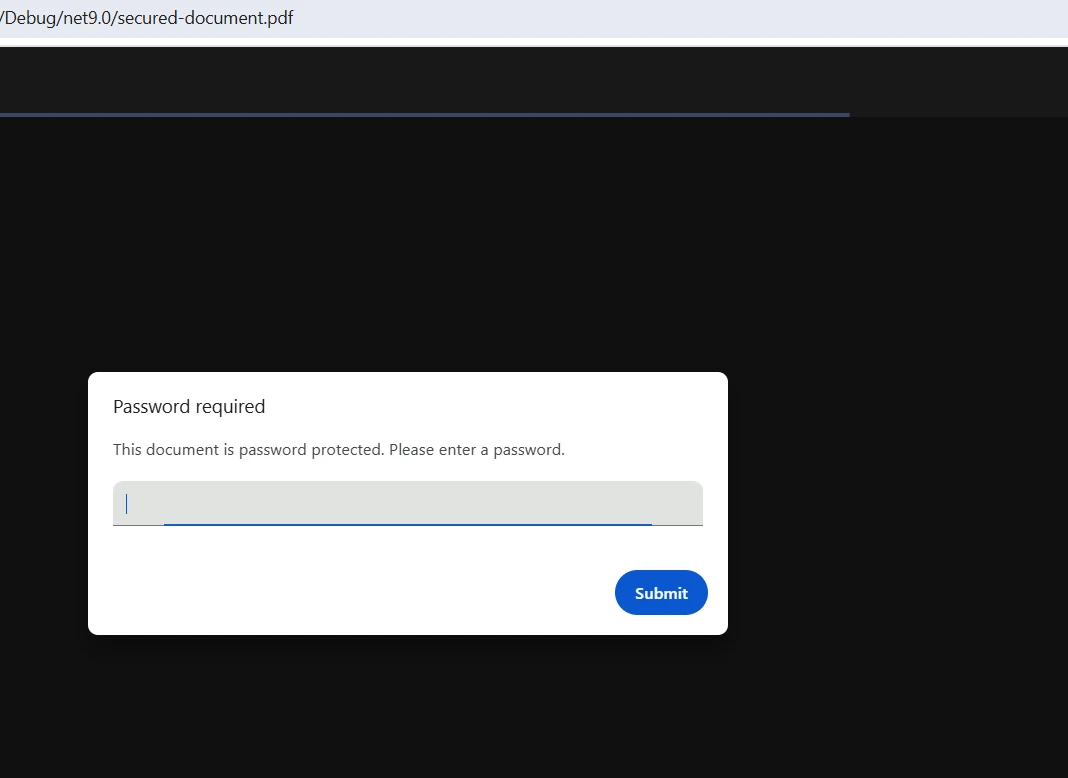
Bezpieczeństwo i szyfrowanie plików PDF
Ochrona poufnych dokumentów PDF wymaga solidnych funkcji bezpieczeństwa. Interfejs API PDF firmy IronPDF zapewnia kompleksowe opcje zabezpieczeń służące do ochrony dokumentów:
var pdf = PdfDocument.FromFile("document.pdf");
pdf.SecuritySettings.UserPassword = "user123";
pdf.SecuritySettings.OwnerPassword = "owner456";
pdf.SecuritySettings.AllowUserPrinting = IronPdf.Security.PdfPrintSecurity.FullPrintRights;
pdf.SecuritySettings.AllowUserCopyPasteContent = false;
pdf.SecuritySettings.AllowUserFormData = true;
pdf.SaveAs("secured-document.pdf");var pdf = PdfDocument.FromFile("document.pdf");
pdf.SecuritySettings.UserPassword = "user123";
pdf.SecuritySettings.OwnerPassword = "owner456";
pdf.SecuritySettings.AllowUserPrinting = IronPdf.Security.PdfPrintSecurity.FullPrintRights;
pdf.SecuritySettings.AllowUserCopyPasteContent = false;
pdf.SecuritySettings.AllowUserFormData = true;
pdf.SaveAs("secured-document.pdf");Dim pdf = PdfDocument.FromFile("document.pdf")
pdf.SecuritySettings.UserPassword = "user123"
pdf.SecuritySettings.OwnerPassword = "owner456"
pdf.SecuritySettings.AllowUserPrinting = IronPdf.Security.PdfPrintSecurity.FullPrintRights
pdf.SecuritySettings.AllowUserCopyPasteContent = False
pdf.SecuritySettings.AllowUserFormData = True
pdf.SaveAs("secured-document.pdf")Ustawienia zabezpieczeń chronią pliki PDF poprzez szyfrowanie hasłem i ograniczenia uprawnień w interfejsie API dokumentów PDF. Hasła użytkowników kontrolują otwieranie dokumentów PDF, natomiast hasła właścicieli zarządzają zmianami uprawnień w plikach PDF. Szczegółowe uprawnienia kontrolują możliwości drukowania, kopiowania, edycji i wypełniania formularzy w dokumentach PDF. Te funkcje API PDF .NET zapewniają zgodność z wymogąmi ochrony danych i zapobiegają nieuprawnionej manipulacji plikami PDF. Szyfrowanie wykorzystuje standardowe algorytmy dla formatu PDF, zapewniając solidną ochronę poufnych treści PDF i podpisów cyfrowych w aplikacjach .NET Standard.
Edycja dokumentów i scałanie plików PDF
Interfejs API dokumentów PDF firmy IronPDF umożliwia manipulowanie istniejącymi dokumentami i plikami PDF w projektach .NET:
var pdf1 = PdfDocument.FromFile("report1.pdf");
var pdf2 = PdfDocument.FromFile("report2.pdf");
// Merge PDF documents
pdf1.AppendPdf(pdf2);
// Add watermark to PDF files
pdf1.ApplyWatermark("<h2>CONFIDENTIAL PDF</h2>", rotation: 45, opacity: 50);
// Extract pages from PDF document
var extracted = pdf1.CopyPages(0, 2);
extracted.SaveAs("first-three-pages.pdf");
pdf1.SaveAs("combined-report.pdf");var pdf1 = PdfDocument.FromFile("report1.pdf");
var pdf2 = PdfDocument.FromFile("report2.pdf");
// Merge PDF documents
pdf1.AppendPdf(pdf2);
// Add watermark to PDF files
pdf1.ApplyWatermark("<h2>CONFIDENTIAL PDF</h2>", rotation: 45, opacity: 50);
// Extract pages from PDF document
var extracted = pdf1.CopyPages(0, 2);
extracted.SaveAs("first-three-pages.pdf");
pdf1.SaveAs("combined-report.pdf");Dim pdf1 = PdfDocument.FromFile("report1.pdf")
Dim pdf2 = PdfDocument.FromFile("report2.pdf")
' Merge PDF documents
pdf1.AppendPdf(pdf2)
' Add watermark to PDF files
pdf1.ApplyWatermark("<h2>CONFIDENTIAL PDF</h2>", rotation:=45, opacity:=50)
' Extract pages from PDF document
Dim extracted = pdf1.CopyPages(0, 2)
extracted.SaveAs("first-three-pages.pdf")
pdf1.SaveAs("combined-report.pdf")Funkcje manipulacji dokumentami PDF w tym interfejsie API umożliwiają realizację złożonych procesów związanych z plikami PDF bez konieczności korzystania z narzędzi zewnętrznych. Funkcja scałania łączy wiele plików PDF w jeden dokument PDF, co jest przydatne przy tworzeniu raportów lub pakietów dokumentów PDF. Znak wodny dodaje nakładki tekstowe lub graficzne do plików PDF w celach brandingowych lub bezpieczeństwa, z możliwością kontroli jakości obrazu i przezroczystości. Funkcja wyodrębniania stron tworzy nowe dokumenty PDF na podstawie istniejących zakresów stron w plikach PDF, ułatwiając dzielenie dokumentów PDF lub selektywne udostępnianie. Zaawansowane funkcje, takie jak zarządzanie przestrzeniami kolorów, zapewniają spójne renderowanie plików PDF na różnych urządzeniach. Operacje te pozwalają zachować jakość dokumentu PDF oraz format PDF podczas całego procesu przetwarzania istniejących dokumentów.
Najlepsze praktyki dotyczące generowania plików PDF
Skuteczne generowanie plików PDF wykracza poza podstawowe wykorzystanie API i obejmuje strategie optymalizacji, kwestie związane z układem oraz planowanie wdrożenia. Te praktyki zapewniają niezawodne i wydajne generowanie dokumentów w różnych scenariuszach.
Optymalizacja kodu HTML pod kątem generowania plików PDF
Dobrze skonstruowany kod HTML zapewnia lepsze wyniki w formacie PDF. Należy używać semantycznych elementów HTML w celu stworzenia logicznej struktury dokumentu. Tabele powinny używać odpowiednich elementów thead, tbody i tfoot dla spójnego renderowania na stronach. W miarę możliwości należy unikać pozycjonowania absolutnego, ponieważ układy względne lepiej dostosowują się do granic strony. Podczas pracy z istniejącymi dokumentami należy wziąć pod uwagę optymalizację rozmiaru plików — duże pliki PDF mogą wpływać na wydajność. Należy uwzględnić reguły CSS specyficzne dla wydruku w celu optymalizacji wyglądu:
string optimizedHtml = @"
<style>
@media print {
.no-print { display: none; }
.page-break { page-break-after: always; }
}
table { border-collapse: collapse; width: 100%; }
th, td { border: 1px solid #ddd; padding: 8px; }
</style>
<div class='content'>
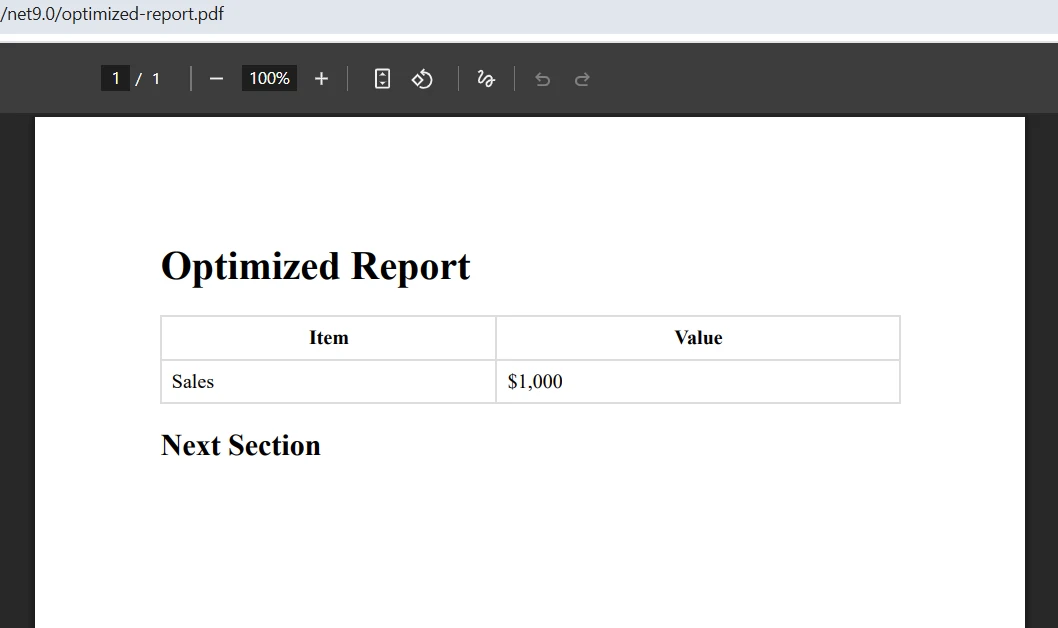
<h1>Optimized Report</h1>
<table>
<thead><tr><th>Item</th><th>Value</th></tr></thead>
<tbody><tr><td>Sales</td><td>$1,000</td></tr></tbody>
</table>
<div class='page-break'></div>
<h2>Next Section</h2>
</div>";
var renderer = new ChromePdfRenderer();
var pdf = renderer.RenderHtmlAsPdf(optimizedHtml);string optimizedHtml = @"
<style>
@media print {
.no-print { display: none; }
.page-break { page-break-after: always; }
}
table { border-collapse: collapse; width: 100%; }
th, td { border: 1px solid #ddd; padding: 8px; }
</style>
<div class='content'>
<h1>Optimized Report</h1>
<table>
<thead><tr><th>Item</th><th>Value</th></tr></thead>
<tbody><tr><td>Sales</td><td>$1,000</td></tr></tbody>
</table>
<div class='page-break'></div>
<h2>Next Section</h2>
</div>";
var renderer = new ChromePdfRenderer();
var pdf = renderer.RenderHtmlAsPdf(optimizedHtml);Imports IronPdf
Dim optimizedHtml As String = "
<style>
@media print {
.no-print { display: none; }
.page-break { page-break-after: always; }
}
table { border-collapse: collapse; width: 100%; }
th, td { border: 1px solid #ddd; padding: 8px; }
</style>
<div class='content'>
<h1>Optimized Report</h1>
<table>
<thead><tr><th>Item</th><th>Value</th></tr></thead>
<tbody><tr><td>Sales</td><td>$1,000</td></tr></tbody>
</table>
<div class='page-break'></div>
<h2>Next Section</h2>
</div>"
Dim renderer As New ChromePdfRenderer()
Dim pdf = renderer.RenderHtmlAsPdf(optimizedHtml)Ta struktura HTML zawiera zapytania o media PRINT, prawidłowe formatowanie tabel oraz wyraźne podziały stron. CSS zapewnia spójną stylistykę, a struktura semantyczna poprawia dostępność i niezawodność renderowania. Elementy sterujące podziałem stron zapewniają precyzyjną kontrolę nad przepływem treści między stronami.
Wynik
Obsługa złożonych układów
Złożone układy graficzne wymagają starannego rozważenia sposobu renderowania. Ustaw odpowiednie szerokości okna wyświetlania, aby kontrolować punkty przełamania w responsywnym projekcie. Użyj opcji FitToPaper, aby odpowiednio skalować treść. W przypadku układów wielokolumnowych warto rozważyć użycie kolumn CSS zamiast elementów float lub flexbox, aby uzyskać lepszy przepływ strony. Przetestuj układy z różną ilością treści, aby zapewnić spójny wygląd.
Kwestie związane z wdrożeniem
IronPDF obsługuje różne scenariusze wdrożenia, w tym usługi Windows, aplikacje internetowe, kontenery Docker i platformy chmurowe. Biblioteka zawiera natywne zależności, które muszą być obecne w środowisku wdrożeniowym. W przypadku wdrożeń w systemie Linux upewnij się, że zainstalowano wymagane pakiety. Wdrożenia Docker korzystają z oficjalnych obrazów bazowych, które zawierają niezbędne zależności. Wdrożenia Azure i AWS działają płynnie przy odpowiedniej konfiguracji. W przypadku problemów z wdrożeniem tag IronPDF na Stack Overflow zapewnia rozwiązania opracowane przez społeczność.
Wdrożenia kontenerowe wymagają szczególnej uwagi w zakresie dostępności czcionek. Dodaj niestandardowe czcionki do obrazu kontenera lub konsekwentnie odwołuj się do czcionek systemowych. Silnik renderujący Chrome dostosowuje się do dostępnych zasobów systemowych, ale odpowiedni przydział pamięci poprawia wydajność w przypadku złożonych dokumentów. Generowanie plików PDF po stronie serwera korzysta z odpowiedniego zarządzania zasobami i strategii buforowania. Ponadto IronPDF obsługuje standardy dostępności, zapewniając zgodność generowanych plików PDF z wymaganiami sekcji 508. W przypadku problemów technicznych utworzenie zgłoszenia do pomocy technicznej zapewnia bezpośredni dostęp do wsparcia inżynierów.

Wnioski
IronPDF zapewnia kompleksowy interfejs API PDF dla platformy .NET, który upraszcza generowanie dokumentów, oferując jednocześnie zaawansowane możliwości spełniające złożone wymagania. Jego silnik renderujący oparty na przeglądarce Chrome zapewnia dokładną konwersję HTML do PDF, a szerokie możliwości dostosowywania pozwalają na precyzyjną kontrolę nad formatowaniem wyników. Intuicyjna konstrukcja API skraca czas programowania, umożliwiając programistom wykorzystanie istniejących umiejętności tworzenia stron internetowych do generowania plików PDF.
Wsparcie wielu platform, funkcje bezpieczeństwa oraz możliwości manipulacji dokumentami sprawiają, że biblioteka ta nadaje się do różnorodnych scenariuszy zastosowań. Od prostych raportów po złożone interaktywne formularze — IronPDF obsługuje pełen zakres wymagań dotyczących plików PDF w ekosystemie .NET. Jego architektura bezpieczna dla wątków oraz obsługa asynchroniczna zapewniają niezawodną wydajność w środowiskach produkcyjnych o dużej skali.
Rozpoczęcie pracy z IronPDF wymaga minimalnej konfiguracji, a do dyspozycji są obszerne dokumenty i przykłady, które pomogą w wdrożeniu. Bezpłatna wersja próbna oferuje solidne, niezawodne rozwiązanie, które rozwija się wraz z potrzebami Twojej aplikacji.
Dla programistów pragnących szybko wdrożyć funkcjonalność PDF, IronPDF zapewnia narzędzia i wsparcie niezbędne do osiągnięcia sukcesu. Zapoznaj się z dokumentacją, aby odkryć pełen zakres możliwości i już dziś zacznij przekształcać swoje procesy pracy z dokumentami. Niezależnie od tego, czy tworzysz nowe aplikacje, czy ulepszasz istniejące systemy, IronPDF zapewnia funkcjonalność API PDF wymaganą przez nowoczesne aplikacje .NET.
Często Zadawane Pytania
Czym jest IronPDF i w jaki sposób pomaga w zarządzaniu dokumentami PDF?
IronPDF to kompleksowa biblioteka PDF, która oferuje potężny interfejs API .NET do generowania i edycji dokumentów PDF. Płynnie integruje się z projektami .NET, co czyni ją niezbędnym narzędziem dla programistów pracujących nad systemami raportowania dla przedsiębiorstw, fakturami dla klientów oraz automatycznym tworzeniem plików PDF.
Jak IronPDF integruje sie z aplikacjami .NET?
IronPDF integruje się z aplikacjami .NET, udostępniając solidny interfejs API, który pozwala programistom generować i modyfikować dokumenty PDF programowo. Ta płynna integracja gwarantuje, że programiści mogą efektywnie włączać funkcje PDF do swoich projektów .NET.
Jakie są zalety korzystania z IronPDF do generowania dokumentów PDF?
Korzystanie z IronPDF do generowania dokumentów PDF oferuje kilka korzyści, w tym łatwą integrację z projektami .NET, zaawansowane możliwości manipulacji dokumentami oraz obsługę tworzenia automatycznych plików PDF. Upraszcza to złożone zadania związane z plikami PDF i zwiększa produktywność programistów.
Czy IronPDF może być używany do tworzenia faktur dla klientów w środowisku .NET?
Tak, IronPDF może być używany do tworzenia faktur dla klientów w środowisku .NET. Jego intuicyjny interfejs API pozwala programistom generować profesjonalne faktury w formacie PDF programowo, zapewniając dokładne i wydajne procesy rozliczeniowe.
Co sprawia, że IronPDF jest niezawodnym rozwiązaniem API do obsługi plików PDF dla programistów .NET?
IronPDF jest uważany za niezawodne rozwiązanie API do obsługi plików PDF dla programistów .NET ze względu na swój wszechstronny zestaw funkcji, łatwość obsługi i płynną integrację z projektami .NET. Zapewnia potężne narzędzia do generowania i edycji dokumentów PDF, co czyni go preferowanym wyborem dla programistów.
Czy IronPDF nadaje się do systemów raportowania na poziomie Enterprise?
IronPDF doskonale nadaje się do systemów raportowania na poziomie przedsiębiorstwa, ponieważ oferuje rozbudowane możliwości generowania złożonych dokumentów PDF i zarządzania nimi. Zapewnia programistom możliwość wydajnego tworzenia szczegółowych i profesjonalnych raportów w ramach ich aplikacji .NET.
Czy IronPDF obsługuje automatyczne tworzenie plików PDF?
Tak, IronPDF obsługuje automatyczne tworzenie plików PDF, umożliwiając programistom konfigurację zautomatyzowanych procesów generowania dokumentów PDF. Ta funkcja jest szczególnie przydatna w aplikacjach, które wymagają regularnego i spójnego generowania plików PDF.
Jakie rodzaje operacji na dokumentach PDF może wykonywać IronPDF?
IronPDF umożliwia wykonywanie różnych operacji na dokumentach PDF, w tym edycję, scałanie, dzielenie i konwersję plików PDF. Jego wszechstronny interfejs API zapewnia programistom narzędzia niezbędne do dostosowywania dokumentów PDF do konkretnych wymagań.











