
Jak wyodrębnić obraz z pliku PDF w Javie
W tym artykule omówimy, jak wyodrębnić obrazy z istniejącego dokumentu PDF i zapisać je w jednym folderze przy użyciu języka programowania Java. W tym celu do wyodrębniania obrazów wykorzystywana jest biblioteka IronPDF for Java.
Jak wyodrębnić obraz z pliku PDF w Javie
- Zainstaluj bibliotekę Java, aby wyodrębnić obrazy z plików PDF
- Załaduj plik PDF lub renderuj z adresu URL
- Użyj metody
extractAllImages,aby wyodrębnić obrazy - Zapisywanie wyodrębnionych obrazów do plików lub strumieni w Javie
- Sprawdź wyodrębnione obrazy w podanym katalogu
Biblioteka IronPDF Java PDF
IronPDF to biblioteka Java zaprojektowana, aby pomóc programistom w generowaniu, modyfikowaniu i wyciąganiu danych z plików PDF w ramach ich aplikacji Java. Dzięki IronPDF możesz tworzyć dokumenty PDF z różnych źródeł, takich jak HTML, obrazy i inne. Dodatkowo masz możliwość łączenia, dzielenia i edytowania istniejących plików PDF. IronPDF zawiera również funkcje bezpieczeństwa, takie jak ochrona hasłem i podpisy cyfrowe.
Opracowany i utrzymywany przez Iron Software, IronPDF jest znany ze swojej zdolności do wyodrębniania tekstu z plików PDF, HTML i adresów URL. To sprawia, że jest to wszechstronne i potężne narzędzie do różnych zastosowań, niezależnie od tego, czy tworzysz pliki PDF od podstaw, czy pracujesz z już istniejącymi.
Wymagania wstępne
Przed użyciem IronPDF do wyodrębniania danych z pliku PDF należy spełnić kilka warunków wstępnych:
- Instalacja Javy: Upewnij się, że Java jest zainstalowana w Twoim systemie i że jej ścieżka została ustawiona w zmiennych środowiskowych. Jeśli nie zainstalowałeś jeszcze Javy, postępuj zgodnie z instrukcjami na poniższej stronie pobierania ze strony internetowej Javy.
- Środowisko IDE dla języka Java: Zainstaluj Eclipse lub IntelliJ jako swoje środowisko IDE dla języka Java. Eclipse można pobrać z tego linku, a IntelliJ z tej strony pobierania.
- Biblioteka IronPDF: Pobierz i dodaj bibliotekę IronPDF do swojego projektu jako zależność. Instrukcje dotyczące konfiguracji można znaleźć na stronie internetowej IronPDF.
- Instalacja Mavena: Przed rozpoczęciem procesu konwersji plików PDF upewnij się, że Maven jest zainstalowany i zintegrowany z Twoim środowiskiem IDE. Aby uzyskać pomoc w instalacji i integracji Mavena, skorzystaj z samouczka zawartego w poniższym przewodniku firmy JetBrains.
Instalacja IronPDF for Java
Instalacja IronPDF for Java jest prosta, o ile spełnione są wszystkie wymagania. W niniejszym przewodniku wykorzystamy JetBrains IntelliJ IDEA do zademonstrowania instalacji i uruchomienia przykładowego kodu.
-
Uruchom IntelliJ IDEA: Otwórz JetBrains IntelliJ IDEA na swoim komputerze.
- Utwórz projekt Maven: W IntelliJ IDEA utwórz nowy projekt Maven. Zapewni to odpowiednie środowisko do instalacji IronPDF for Java.
 Utwórz nowy projekt Maven
Utwórz nowy projekt Maven
Pojawi się nowe okno. Wpisz nazwę projektu i kliknij przycisk "Zakończ".
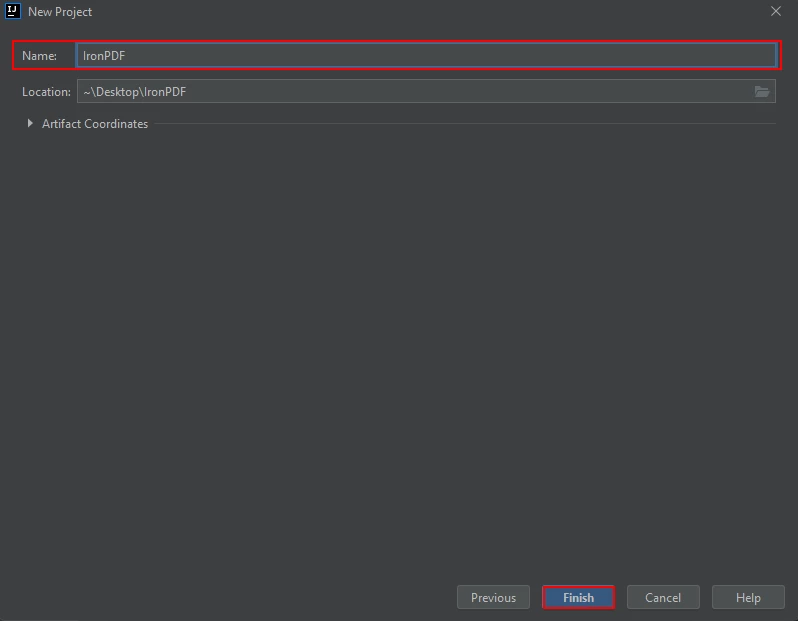 Wpisz nazwę projektu
Wpisz nazwę projektu
Po kliknięciu przycisku "Zakończ" otworzy się nowy projekt w pliku pom.xml, aby dodać zależności Maven dla IronPDF for Java.
Następnie dodaj następujące zależności w pliku pom.xml lub pobierz plik JAR z poniższego repozytorium Maven.
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>YOUR_VERSION_HERE</version>
</dependency><dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>YOUR_VERSION_HERE</version>
</dependency>Po umieszczeniu zależności w pliku pom.xml w prawym górnym rogu pliku pojawi się mała ikona.
 Plik pom.xml z małą ikoną do instalacji zależności
Plik pom.xml z małą ikoną do instalacji zależności
Kliknij tę ikonę, aby zainstalować zależności Maven dla IronPDF for Java. W zależności od szybkości połączenia internetowego zajmie to tylko kilka minut.
Wyodrębnij obrazy
Możesz wyodrębnić obrazy z dokumentu PDF za pomocą IronPDF przy użyciu jednej metody o nazwie [extractAllImages](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#extractAllImages()). Ta metoda zwraca wszystkie obrazy dostępne w pliku PDF. Następnie można zapisać wszystkie wyodrębnione obrazy w wybranej ścieżce pliku, korzystając z metody ImageIO.write, podając ścieżkę i format obrazu wyjściowego.
5.1. Wyodrębnianie obrazów z dokumentu PDF
W poniższym przykładzie obrazy z dokumentu PDF zostaną wyodrębnione i zapisane w systemie plików jako obrazy PNG.
import com.ironsoftware.ironpdf.PdfDocument;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.List;
public class Main {
public static void main(String[] args) throws Exception {
// Load PDF document from file
PdfDocument pdf = PdfDocument.fromFile(Paths.get("Final Project Report Craft Arena.pdf"));
// Extract all images from the PDF document
List<BufferedImage> images = pdf.extractAllImages();
int i = 0;
// Save each extracted image to the filesystem as a PNG
for (BufferedImage image : images) {
ImageIO.write(image, "PNG", Files.newOutputStream(Paths.get("image" + ++i + ".png")));
}
}
}import com.ironsoftware.ironpdf.PdfDocument;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.List;
public class Main {
public static void main(String[] args) throws Exception {
// Load PDF document from file
PdfDocument pdf = PdfDocument.fromFile(Paths.get("Final Project Report Craft Arena.pdf"));
// Extract all images from the PDF document
List<BufferedImage> images = pdf.extractAllImages();
int i = 0;
// Save each extracted image to the filesystem as a PNG
for (BufferedImage image : images) {
ImageIO.write(image, "PNG", Files.newOutputStream(Paths.get("image" + ++i + ".png")));
}
}
}Powyższy program otwiera plik "Final Project Report Craft Arena.PDF" i wykorzystuje metodę extractAllImages do wyodrębnienia wszystkich obrazów z pliku do listy obiektów BufferedImage. Następnie zapisuje każdy nowy obraz pliku w osobnych plikach PNG o unikalnej nazwie.
 Wyodrębnianie obrazów z plików PDF
Wyodrębnianie obrazów z plików PDF
Wyodrębnianie obrazów z adresów URL
W tej sekcji omówimy, jak wyodrębniać obrazy bezpośrednio z adresów URL. W poniższym kodzie adres URL jest konwertowany na stronę PDF, a następnie za pomocą przełącznika nawigacyjnego wyodrębniane są obrazy z pliku PDF.
import com.ironsoftware.ironpdf.PdfDocument;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
// Render PDF from a URL
PdfDocument pdf = PdfDocument.renderUrlAsPdf("https://www.amazon.com/?tag=hp2-brobookmark-us-20");
// Extract all images from the rendered PDF document
List<BufferedImage> images = pdf.extractAllImages();
int i = 0;
// Save each extracted image to the filesystem as a PNG
for (BufferedImage image : images) {
ImageIO.write(image, "PNG", Files.newOutputStream(Paths.get("image" + ++i + ".png")));
}
}
}import com.ironsoftware.ironpdf.PdfDocument;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
// Render PDF from a URL
PdfDocument pdf = PdfDocument.renderUrlAsPdf("https://www.amazon.com/?tag=hp2-brobookmark-us-20");
// Extract all images from the rendered PDF document
List<BufferedImage> images = pdf.extractAllImages();
int i = 0;
// Save each extracted image to the filesystem as a PNG
for (BufferedImage image : images) {
ImageIO.write(image, "PNG", Files.newOutputStream(Paths.get("image" + ++i + ".png")));
}
}
}W powyższym kodzie jako dane wejściowe podano adres URL strony głównej serwisu Amazon, a wynik to 74 obrazy.
 Wyodrębnianie obrazów z plików PDF
Wyodrębnianie obrazów z plików PDF
Wnioski
Wyodrębnianie obrazów z dokumentu PDF można wykonać w Javie przy użyciu biblioteki IronPDF. Aby zainstalować IronPDF, musisz mieć zainstalowane i zintegrowane z projektem środowisko Java, IDE Java (Eclipse lub IntelliJ), Maven oraz bibliotekę IronPDF. Proces wyodrębniania obrazów z dokumentu PDF przy użyciu IronPDF jest prosty i wymaga jedynie jednego wywołania metody extractAllImages. Następnie można zapisać obrazy w wybranej ścieżce pliku, korzystając z metody ImageIO.write.
W tym artykule znajdziesz szczegółowy przewodnik, jak wyodrębnić obrazy z dokumentu PDF przy użyciu Javy i biblioteki IronPDF. Więcej szczegółów, w tym informacje o tym, jak wyodrębnić tekst z plików PDF, można znaleźć w przykładowym kodzie wyodrębniania tekstu.
IronPDF to biblioteka z licencją komercyjną, której cena zaczyna się od $799. Można jednak przetestować go w środowisku produkcyjnym, korzystając z bezpłatnej wersji probnej.
Często Zadawane Pytania
Jak wyodrębnić obrazy z pliku PDF za pomocą języka Java?
Aby wyodrębnić obrazy z pliku PDF przy użyciu języka Java, należy skorzystać z biblioteki IronPDF. Najpierw należy załadować dokument PDF, a następnie użyć metody extractAllImages. Wyodrębnione obrazy można następnie zapisać za pomocą metod takich jak ImageIO.write.
Jakie warunki wstępne są wymagane do wyodrębniania obrazów z plików PDF w Javie?
Aby wyodrębnić obrazy z plików PDF przy użyciu języka Java, upewnij się, że masz zainstalowany Java oraz środowisko IDE, takie jak Eclipse lub IntelliJ IDEA. Dodatkowo skonfiguruj Maven do zarządzania zależnościami i dołącz bibliotekę IronPDF do swojego projektu.
Jak zainstalować bibliotekę w Javie do wyodrębniania obrazów z plików PDF?
Aby zainstalować bibliotekę IronPDF, utwórz projekt Maven w swoim środowisku Java IDE, takim jak IntelliJ IDEA. Dodaj zależność IronPDF do pliku pom.xml i użyj Mavena, aby pobrać ją i dołączyć do projektu.
Czy w Javie mogę wyodrębnić obrazy z pliku PDF wygenerowanego z adresu URL?
Tak, można użyć metody renderUrlAsPdf biblioteki IronPDF do konwersji adresu URL na plik PDF, a następnie zastosować metodę extractAllImages do wyodrębnienia obrazów z powstałego pliku PDF.
Czy dostępna jest wersja próbna biblioteki Java do obsługi plików PDF?
IronPDF oferuje bezpłatną wersję próbną, która pozwala zapoznać się z jego możliwościami i funkcjami w zakresie zarządzania plikami PDF oraz wyodrębniania obrazów w języku Java.
Które środowiska IDE dla języka Java nadają się do korzystania z IronPDF?
Eclipse i IntelliJ IDEA to zalecane środowiska IDE do tworzenia aplikacji Java, które wykorzystują bibliotekę IronPDF do obsługi plików PDF.
Jak zapisać obrazy wyodrębnione z pliku PDF przy użyciu języka Java?
Po wyodrębnieniu obrazów z pliku PDF za pomocą IronPDF można je zapisać za pomocą metody ImageIO.write, określając żądaną ścieżkę pliku i format obrazu.
Która metoda jest używana do wyodrębniania obrazów z plików PDF w Javie?
W IronPDF metoda extractAllImages służy do wyodrębniania wszystkich obrazów z dokumentu PDF. Metoda ta zwraca listę obrazów, które można dalej przetwarzać lub zapisywać.
Jakie formaty obrazów można używać podczas zapisywania obrazów wyodrębnionych z plików PDF?
Wyodrębnione obrazy można zapisać w różnych formatach, takich jak PNG, za pomocą metody ImageIO.write w Javie.
Jakie funkcje oferuje biblioteka do zarządzania plikami PDF w Javie?
IronPDF to kompleksowa biblioteka dla języka Java, która umożliwia programistom generowanie, modyfikowanie i wyodrębnianie danych z plików PDF. Zawiera funkcje takie jak wyodrębnianie tekstu, scalanie, dzielenie oraz stosowanie zabezpieczeń.

















