
How to Extract Image From PDF in Java
This article will explore how to extract images from an existing PDF document and save them in a single folder using the Java programming language. For this purpose, the IronPDF for Java library is used to extract images.
How to Extract Image From PDF in Java
- Install Java library to extract images from PDF
- Load the PDF file or render from URL
- Utilize
extractAllImagesmethod to extract the images - Save the extracted images to files or streams in Java
- Check the extracted images in the specified directory
IronPDF Java PDF Library
IronPDF is a Java library designed to help developers generate, modify, and extract data from PDF files within their Java applications. With IronPDF, you can create PDF documents from a range of sources, such as HTML, images, and more. Additionally, you have the ability to merge, split, and manipulate existing PDFs. IronPDF also includes security features, such as password protection and digital signatures.
Developed and maintained by Iron Software, IronPDF is known for its ability to extract text from PDFs, HTML, and URLs. This makes it a versatile and powerful tool for a variety of applications, whether you're creating PDFs from scratch or working with existing ones.
Prerequisites
Before using IronPDF to extract data from a PDF file, there are a few prerequisites that must be met:
- Java installation: Ensure that Java is installed on your system and that its path has been set in the environment variables. If you haven't installed Java yet, follow the instructions at the following download page from Java website.
- Java IDE: Have either Eclipse or IntelliJ installed as your Java IDE. You can download Eclipse from this link and IntelliJ from this download page.
- IronPDF library: Download and add the IronPDF library to your project as a dependency. For setup instructions, visit the IronPDF website.
- Maven installation: Make sure Maven is installed and integrated with your IDE before starting the PDF conversion process. Follow the tutorial at the following guide from JetBrains for assistance with installing and integrating Maven.
IronPDF for Java Installation
Installing IronPDF for Java is a straightforward process, provided all the requirements are met. This guide will use the JetBrains IntelliJ IDEA to demonstrate the installation and run some sample code.
-
Launch IntelliJ IDEA: Open JetBrains IntelliJ IDEA on your system.
- Create a Maven Project: In IntelliJ IDEA, create a new Maven project. This will provide a suitable environment for the installation of IronPDF for Java.
 Create a new Maven project
Create a new Maven project
A new window will appear. Enter the name of the project and click on Finish.
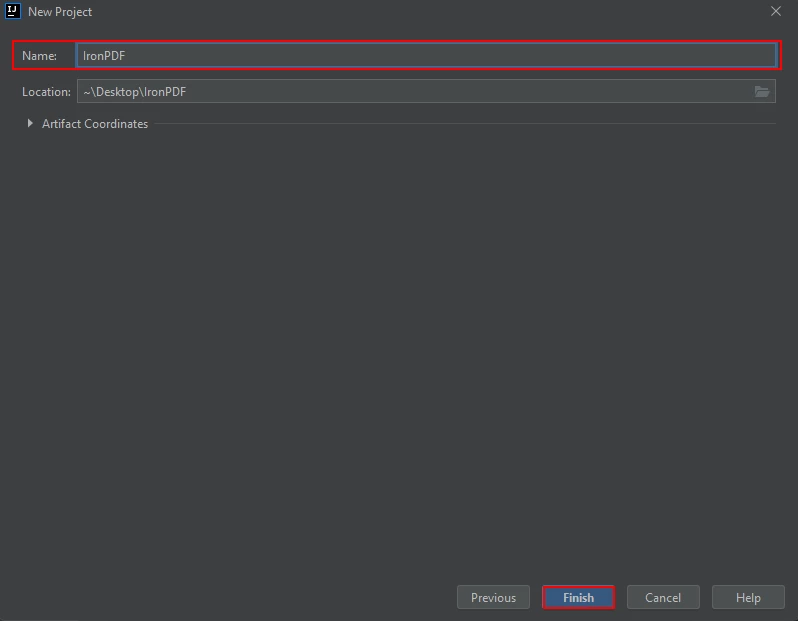 Enter the name of the project
Enter the name of the project
After you click Finish, a new project will open to a pom.xml file to add the Maven dependencies of IronPDF for Java.
Next, add the following dependencies in the pom.xml file or you can download the JAR file from the following Maven repository.
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>YOUR_VERSION_HERE</version>
</dependency><dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>YOUR_VERSION_HERE</version>
</dependency>Once you place the dependencies in the pom.xml file, a small icon will appear in the right top corner of the file.
 The pom.xml file with a small icon to install dependencies
The pom.xml file with a small icon to install dependencies
Click on this icon to install the Maven dependencies of IronPDF for Java. This will only take a few minutes depending on your internet connection.
Extract Images
You can extract images from a PDF document using IronPDF with a single method called [extractAllImages](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#extractAllImages(). This method returns all the images available in a PDF file. After that, you can save all the extracted images to the file path of your choice using the ImageIO.write method by providing the path and format of the output image.
5.1. Extract Images from PDF document
In the example below, the images from a PDF document will be extracted and saved into the file system as PNG images.
import com.ironsoftware.ironpdf.PdfDocument;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.List;
public class Main {
public static void main(String[] args) throws Exception {
// Load PDF document from file
PdfDocument pdf = PdfDocument.fromFile(Paths.get("Final Project Report Craft Arena.pdf"));
// Extract all images from the PDF document
List<BufferedImage> images = pdf.extractAllImages();
int i = 0;
// Save each extracted image to the filesystem as a PNG
for (BufferedImage image : images) {
ImageIO.write(image, "PNG", Files.newOutputStream(Paths.get("image" + ++i + ".png")));
}
}
}import com.ironsoftware.ironpdf.PdfDocument;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.List;
public class Main {
public static void main(String[] args) throws Exception {
// Load PDF document from file
PdfDocument pdf = PdfDocument.fromFile(Paths.get("Final Project Report Craft Arena.pdf"));
// Extract all images from the PDF document
List<BufferedImage> images = pdf.extractAllImages();
int i = 0;
// Save each extracted image to the filesystem as a PNG
for (BufferedImage image : images) {
ImageIO.write(image, "PNG", Files.newOutputStream(Paths.get("image" + ++i + ".png")));
}
}
}The program above opens the "Final Project Report Craft Arena.pdf" file and uses the extractAllImages method to extract all images in the file into a list of BufferedImage objects. It then saves each new file image to separate PNG files with a unique name.
 Image Extraction from PDF Output
Image Extraction from PDF Output
Extract Images from URL
This section will discuss how to extract images directly from URLs. In the below code, the URL is converted to a PDF page and then toggle navigation to extract images from the PDF.
import com.ironsoftware.ironpdf.PdfDocument;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
// Render PDF from a URL
PdfDocument pdf = PdfDocument.renderUrlAsPdf("https://www.amazon.com/?tag=hp2-brobookmark-us-20");
// Extract all images from the rendered PDF document
List<BufferedImage> images = pdf.extractAllImages();
int i = 0;
// Save each extracted image to the filesystem as a PNG
for (BufferedImage image : images) {
ImageIO.write(image, "PNG", Files.newOutputStream(Paths.get("image" + ++i + ".png")));
}
}
}import com.ironsoftware.ironpdf.PdfDocument;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
// Render PDF from a URL
PdfDocument pdf = PdfDocument.renderUrlAsPdf("https://www.amazon.com/?tag=hp2-brobookmark-us-20");
// Extract all images from the rendered PDF document
List<BufferedImage> images = pdf.extractAllImages();
int i = 0;
// Save each extracted image to the filesystem as a PNG
for (BufferedImage image : images) {
ImageIO.write(image, "PNG", Files.newOutputStream(Paths.get("image" + ++i + ".png")));
}
}
}In the above code, the Amazon homepage URL is provided as an input, and it returns 74 images.
 Image Extraction from PDF Output
Image Extraction from PDF Output
Conclusion
Extracting images from a PDF document can be done in Java using the IronPDF library. To install IronPDF, you need to have Java, a Java IDE (Eclipse or IntelliJ), Maven, and the IronPDF library installed and integrated with your project. The process of extracting images from a PDF document using IronPDF is simple and it requires just a single method call to extractAllImages. You can then save the images to a file path of your choice using the ImageIO.write method.
This article provides a step-by-step guide on how to extract images from a PDF document using Java and the IronPDF library. More details, including information about how to extract text from PDFs, can be found in the Extract Text Code Example.
IronPDF is a library with a commercial license, starting at $999. However, you can evaluate it in production with a free trial.
Frequently Asked Questions
How do I extract images from a PDF using Java?
To extract images from a PDF using Java, utilize the IronPDF library. Begin by loading the PDF document and then use the extractAllImages method. The extracted images can then be saved using methods like ImageIO.write.
What prerequisites are needed for extracting images from PDFs in Java?
To extract images from PDFs using Java, ensure Java is installed along with a Java IDE such as Eclipse or IntelliJ IDEA. Additionally, configure Maven to manage dependencies and include the IronPDF library in your project.
How can I install a library in Java for PDF image extraction?
To install the IronPDF library, create a Maven project within your Java IDE, such as IntelliJ IDEA. Add the IronPDF dependency to your pom.xml file and use Maven to download and include it in your project.
Can I extract images from a PDF generated from a URL in Java?
Yes, you can use IronPDF's renderUrlAsPdf method to convert a URL to a PDF, and then employ the extractAllImages method to extract images from the resultant PDF.
Is there a trial version available for a Java PDF library?
IronPDF provides a free trial version, allowing you to explore its capabilities and features for PDF management and image extraction in Java.
Which Java IDEs are suitable for using IronPDF?
Eclipse and IntelliJ IDEA are recommended IDEs for developing Java applications that utilize the IronPDF library for handling PDFs.
How do I save images extracted from a PDF using Java?
Once you've extracted images from a PDF using IronPDF, you can save them using the ImageIO.write method, specifying the desired file path and image format.
Which method is used to extract images from PDF files in Java?
In IronPDF, the extractAllImages method is used to extract all images from a PDF document. This method returns a list of images that you can further process or save.
What image formats can be used when saving extracted images from PDFs?
Extracted images can be saved in various formats, such as PNG, by using the ImageIO.write method in Java.
What functionalities does a PDF management library offer in Java?
IronPDF is a comprehensive library for Java that enables developers to generate, modify, and extract data from PDF files. It includes features like text extraction, merging, splitting, and applying security measures.

















