
Przetwarzanie rozproszone z Python
Rozproszony Python
W szybko zmieniającej się dziedzinie technologii istnieje większe niż kiedykolwiek zapotrzebowanie na skalowalne i skuteczne rozwiązania informatyczne. Obliczenia rozproszone stają się coraz bardziej niezbędne w zadaniach wymagających przetwarzania dużych ilości rozproszonych danych, obsługi równoczesnych żądań użytkowników oraz zadań wymagających dużej mocy obliczeniowej. Aby umożliwić programistom pełne wykorzystanie Distributed Python, w tym poście przyjrzymy się jego zastosowaniom, zasadom działania i narzędziom.
Dynamiczne tworzenie i modyfikowanie dokumentów PDF jest powszechnym wymaganiem w dziedzinie tworzenia stron internetowych. Możliwość programowego tworzenia plików PDF przydaje się do błyskawicznego generowania faktur, raportów i certyfikatów.
Rozbudowana ekosystem i wszechstronność języka Python umożliwiają obsługę wielu bibliotek PDF. IronPDF to potężne rozwiązanie, które pomaga programistom w pełni wykorzystać ich infrastrukturę poprzez usprawnienie procesu tworzenia plików PDF, a także umożliwienie równoległego wykonywania zadań i przetwarzania rozproszonego.
Zrozumienie rozproszonego Pythona
Zasadniczo rozproszony Python to proces dzielenia pracy obliczeniowej na mniejsze części i rozdzielania ich między kilka węzłów lub jednostek przetwarzających. Węzłami tymi mogą być pojedyncze maszyny podłączone do sieci, pojedyncze rdzenie procesora w systemie, obiekty zdalne, funkcje zdalne, zdalne wywołania funkcji, a nawet pojedyncze wątki w ramach jednego procesu. Celem jest zwiększenie wydajności, skalowalności i odporności na awarie poprzez równoległe przetwarzanie obciążenia.
Python jest doskonałym wyborem do zadań związanych z przetwarzaniem rozproszonym ze względu na łatwość użytkowania, elastyczność oraz solidny ekosystem bibliotek. Python oferuje bogactwo narzędzi do przetwarzania rozproszonego we wszystkich skalach i przypadkach użycia, od potężnych frameworków, takich jak Celery, Dask i Apache Spark po wbudowane moduły, takie jak multiprocessing i threading.
Zanim zagłębimy się w szczegóły, przyjrzyjmy się podstawowym ideom i zasadom, na których opiera się Distributed Python:
Równoległość a współbieżność
Równoległość polega na wykonywaniu wielu zadań w tym samym czasie, natomiast współbieżność dotyczy obsługi wielu zadań, które mogą postępować równolegle, ale niekoniecznie jednocześnie. Zarówno równoległość, jak i współbieżność są obsługiwane przez rozproszony Python, w zależności od wykonywanych zadań i projektu systemu.
Podział zadań
Kluczowym elementem obliczeń równoległych i rozproszonych jest rozdzielenie pracy między kilka węzłów lub jednostek przetwarzających. Skuteczny podział pracy ma kluczowe znaczenie dla optymalizacji ogólnej wydajności, efektywności i wykorzystania zasobów, niezależnie od tego, czy wykonywanie funkcji w programie obliczeniowym jest równoległe na wielu rdzeniach, czy też potok przetwarzania danych jest podzielony na mniejsze etapy.
Komunikacja i koordynacja
Skuteczna komunikacja i koordynacja między węzłami są niezbędne w systemach rozproszonych, aby ułatwić koordynację zdalnego wykonywania funkcji, skomplikowanych przepływów pracy, wymiany danych i synchronizacji obliczeń.
Programy rozproszone w języku Python korzystają z technologii takich jak kolejki komunikatów, rozproszone struktury danych oraz zdalne wywołania procedur (RPC), które umożliwiają płynną koordynację i komunikację między zdalnym a rzeczywistym wykonywaniem funkcji.
Niezawodność i zapobieganie błędom
Zdolność systemu do dostosowywania się do rosnącego obciążenia poprzez dodawanie węzłów lub jednostek przetwarzających na różnych maszynach nazywana jest skalowalnością. Natomiast odporność na awarie odnosi się do projektowania systemów, które są w stanie wytrzymać awarie, takie jak usterki sprzętu, rozdzielenie sieci i awarie węzłów, i nadal działać niezawodnie.
Aby zagwarantować stabilność i odporność aplikacji rozproszonych na wielu maszynach, rozproszone frameworki Python często zawierają funkcje odporności na awarie i automatycznego skalowania.
Zastosowania rozproszonego Pythona
Przetwarzanie danych i analityka: Duże zbiory danych mogą być przetwarzane równolegle przy użyciu rozproszonych frameworków Python, takich jak Apache Spark i Dask, co umożliwia rozproszonym aplikacjom Python wykonywanie czynności takich jak przetwarzanie wsadowe, przetwarzanie strumieniowe w czasie rzeczywistym oraz uczenie maszynowe na dużą skalę.
Tworzenie stron internetowych z wykorzystaniem mikrousług: Skalowalne aplikacje internetowe i architektury mikrousług można tworzyć za pomocą frameworków internetowych w języku Python, takich jak Flask i Django, w połączeniu z rozproszonymi kolejkami zadań, takimi jak Celery. Aplikacje internetowe mogą z łatwością wykorzystywać takie funkcje, jak buforowanie rozproszone, asynchroniczna obsługa żądań oraz przetwarzanie zadań w tle.
Obliczenia naukowe i symulacje: Obliczenia o wysokiej wydajności (HPC) oraz symulacje równoległe na klastrach komputerów są możliwe dzięki solidnemu ekosystemowi bibliotek naukowych i frameworków obliczeń rozproszonych w języku Python. Zastosowania obejmują analizę ryzyka finansowego, modelowanie klimatu, aplikacje uczenia maszynowego oraz symulacje z zakresu fizyki i biologii obliczeniowej.
Przetwarzanie brzegowe i Internet rzeczy (IoT): Wraz z upowszechnianiem się urządzeń IoT i projektów przetwarzania brzegowego, język Python w środowisku rozproszonym zyskuje na znaczeniu w zakresie obsługi danych z czujników, koordynacji procesów przetwarzania brzegowego, wspólnego tworzenia aplikacji rozproszonych oraz wdrażania rozproszonych modeli uczenia maszynowego w nowoczesnych aplikacjach brzegowych.
Tworzenie i wykorzystanie rozproszonego Pythona
Rozproszone uczenie maszynowe z Dask-ML
Potężna biblioteka o nazwie Dask-ML rozszerza framework obliczeń równoległych Dask o zadania związane z uczeniem maszynowym. Rozdzielenie zadania na kilka rdzeni lub procesorów w klastrze maszyn umożliwia programistom Pythona szkolenie i stosowanie modeli uczenia maszynowego na ogromnych zbiorach danych w efektywny, rozproszony sposób.
import dask.dataframe as dd
from dask_ml.model_selection import train_test_split
from dask_ml.xgboost import XGBoostClassifier
from sklearn.metrics import accuracy_score
# Load and prepare data (replace with your data loading logic)
df = dd.read_csv("training_data.csv")
X = df.drop("target_column", axis=1) # Features
y = df["target_column"] # Target variable
# Split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Define and train the XGBoost model in a distributed fashion
model = XGBoostClassifier(n_estimators=100) # Adjust hyperparameters as needed
model.fit(X_train, y_train)
# Make predictions on test data (can be further distributed)
y_pred = model.predict(X_test)
# Evaluate model performance (replace with your desired evaluation metric)
accuracy = accuracy_score(y_test, y_pred)
print(f"Model Accuracy: {accuracy}")import dask.dataframe as dd
from dask_ml.model_selection import train_test_split
from dask_ml.xgboost import XGBoostClassifier
from sklearn.metrics import accuracy_score
# Load and prepare data (replace with your data loading logic)
df = dd.read_csv("training_data.csv")
X = df.drop("target_column", axis=1) # Features
y = df["target_column"] # Target variable
# Split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Define and train the XGBoost model in a distributed fashion
model = XGBoostClassifier(n_estimators=100) # Adjust hyperparameters as needed
model.fit(X_train, y_train)
# Make predictions on test data (can be further distributed)
y_pred = model.predict(X_test)
# Evaluate model performance (replace with your desired evaluation metric)
accuracy = accuracy_score(y_test, y_pred)
print(f"Model Accuracy: {accuracy}")Równoległe wywołania funkcji za pomocą Ray
Dzięki solidnej platformie obliczeniowej Ray możesz wykonywać funkcje lub zadania w języku Python jednocześnie na wielu rdzeniach lub komputerach w klastrze. Dzięki wykorzystaniu dekoratora @ray.remote, Ray umożliwia określenie funkcji jako zdalnych. Następnie te zdalne zadania lub operacje mogą być wykonywane asynchronicznie na pracownikach Ray w klastrze.
import ray
import numpy as np
# Define the Monte Carlo simulation function
@ray.remote
def simulate(seed):
np.random.seed(seed) # Set random seed for reproducibility
# Perform your simulation logic here (replace with your specific simulation)
# This example simulates a random walk and returns the final position
steps = 1000
position = 0
for _ in range(steps):
position += np.random.choice([-1, 1])
return position
# Initialize Ray cluster (comment out if using existing cluster)
ray.init()
# Number of simulations to run
num_sims = 10000
# Run simulations in parallel using Ray's map function
simulations = ray.get([simulate.remote(seed) for seed in range(num_sims)])
# Analyze simulation results (calculate statistics like average final position)
average_position = np.mean(simulations)
print(f"Average final position: {average_position}")
# Shut down Ray cluster (comment out if using existing cluster)
ray.shutdown()import ray
import numpy as np
# Define the Monte Carlo simulation function
@ray.remote
def simulate(seed):
np.random.seed(seed) # Set random seed for reproducibility
# Perform your simulation logic here (replace with your specific simulation)
# This example simulates a random walk and returns the final position
steps = 1000
position = 0
for _ in range(steps):
position += np.random.choice([-1, 1])
return position
# Initialize Ray cluster (comment out if using existing cluster)
ray.init()
# Number of simulations to run
num_sims = 10000
# Run simulations in parallel using Ray's map function
simulations = ray.get([simulate.remote(seed) for seed in range(num_sims)])
# Analyze simulation results (calculate statistics like average final position)
average_position = np.mean(simulations)
print(f"Average final position: {average_position}")
# Shut down Ray cluster (comment out if using existing cluster)
ray.shutdown()Pierwsze kroki
Czym jest IronPDF?
Możemy tworzyć, modyfikować i renderować dokumenty PDF w programach .NET przy pomocy dobrze znanego pakietu IronPDF for .NET. Praca z plikami PDF może odbywać się na wiele różnych sposobów: od tworzenia nowych dokumentów PDF na podstawie treści HTML, zdjęć lub surowych danych, po wyodrębnianie tekstu i obrazów z istniejących dokumentów, konwertowanie stron HTML na pliki PDF oraz dodawanie tekstu, obrazów i kształtów do już istniejących dokumentów.
IronPDF Prostota i łatwość obsługi to dwie z jego głównych zalet. Dzięki przyjaznemu dla użytkownika interfejsowi API i obszernej dokumentacji programiści mogą z łatwością rozpocząć tworzenie plików PDF w swoich aplikacjach .NET. Szybkość i wydajność IronPDF to dwie kolejne cechy, które ułatwiają programistom szybkie tworzenie wysokiej jakości dokumentów PDF.
Niektóre zalety IronPDF:
- Tworzenie plików PDF na podstawie surowych danych, obrazów i kodu HTML.
- Pobieranie obrazów i tekstu z plików PDF.
- W plikach PDF należy uwzględnić nagłówki, stopki i znaki wodne.
- Pliki PDF są chronione hasłem i szyfrowaniem.
- Możliwość elektronicznego wypełniania i podpisywania dokumentów.
Rozproszone generowanie plików PDF za pomocą IronPDF
Rozdzielanie zadań między wiele rdzeni lub komputerów w klastrze jest możliwe dzięki rozproszonym frameworkom Pythona, takim jak Dask i Ray. Umożliwia to równoległe wykonywanie złożonych zadań, takich jak generowanie plików PDF w klastrze, oraz wykorzystanie wielu rdzeni w ramach klastra, co znacznie skraca czas potrzebny do utworzenia dużej partii plików PDF.
Zacznij od zainstalowania IronPDF i biblioteki ray za pomocą pip:
pip install ironpdf
pip install celerypip install ironpdf
pip install celeryOto przykładowy kod w języku Python, który ilustruje dwie metody wykorzystujące IronPDF i Python do generowania plików PDF w trybie rozproszonym:
Kolejka zadań z centralnym modułem roboczym
Central Worker (worker.py):
from ironpdf import ChromePdfRenderer
from celery import Celery
app = Celery('pdf_tasks', broker='pyamqp://')
app.autodiscover_tasks()
@app.task(name='generate_pdf')
def generate_pdf(data):
print(data)
renderer = ChromePdfRenderer() # Instantiate renderer
pdf = renderer.RenderHtmlAsPdf(str(data))
pdf.SaveAs("output.pdf")
return f"PDF generated for data {data}"
if __name__ == '__main__':
app.worker_main(argv=['worker', '--loglevel=info', '--without-gossip', '--without-mingle', '--without-heartbeat', '-Ofair', '--pool=solo'])from ironpdf import ChromePdfRenderer
from celery import Celery
app = Celery('pdf_tasks', broker='pyamqp://')
app.autodiscover_tasks()
@app.task(name='generate_pdf')
def generate_pdf(data):
print(data)
renderer = ChromePdfRenderer() # Instantiate renderer
pdf = renderer.RenderHtmlAsPdf(str(data))
pdf.SaveAs("output.pdf")
return f"PDF generated for data {data}"
if __name__ == '__main__':
app.worker_main(argv=['worker', '--loglevel=info', '--without-gossip', '--without-mingle', '--without-heartbeat', '-Ofair', '--pool=solo'])Skrypt klienta (client.py):
from celery import Celery
app = Celery('pdf_tasks', broker='pyamqp://localhost')
def main():
# Send task to worker
task = app.send_task('generate_pdf', args=("<h1>This is a sample PDF</h1>",))
print(task.get()) # Wait for task completion and print result
if __name__ == '__main__':
main()from celery import Celery
app = Celery('pdf_tasks', broker='pyamqp://localhost')
def main():
# Send task to worker
task = app.send_task('generate_pdf', args=("<h1>This is a sample PDF</h1>",))
print(task.get()) # Wait for task completion and print result
if __name__ == '__main__':
main()Celery to system kolejki zadań, z którego korzystamy. Zadania są wysyłane do centralnego pracownika (worker.py) wraz z danymi zawierającymi treść HTML. Funkcja tworzy plik PDF przy użyciu IronPDF i zapisuje go.
Zadanie zawierające przykładowe dane jest wysyłane do kolejki przez skrypt klienta (client.py). Ten skrypt można zmodyfikować, aby wysyłał inne zadania z różnych komputerów.
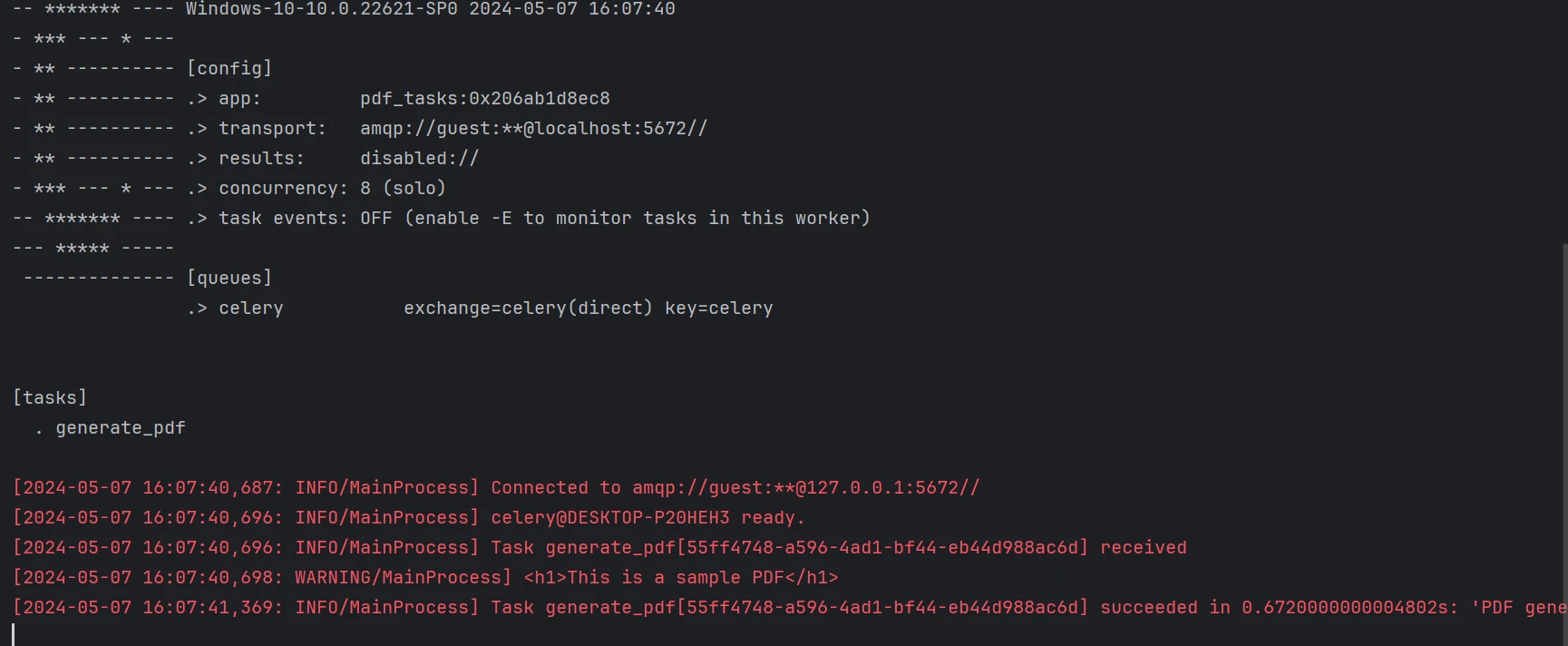
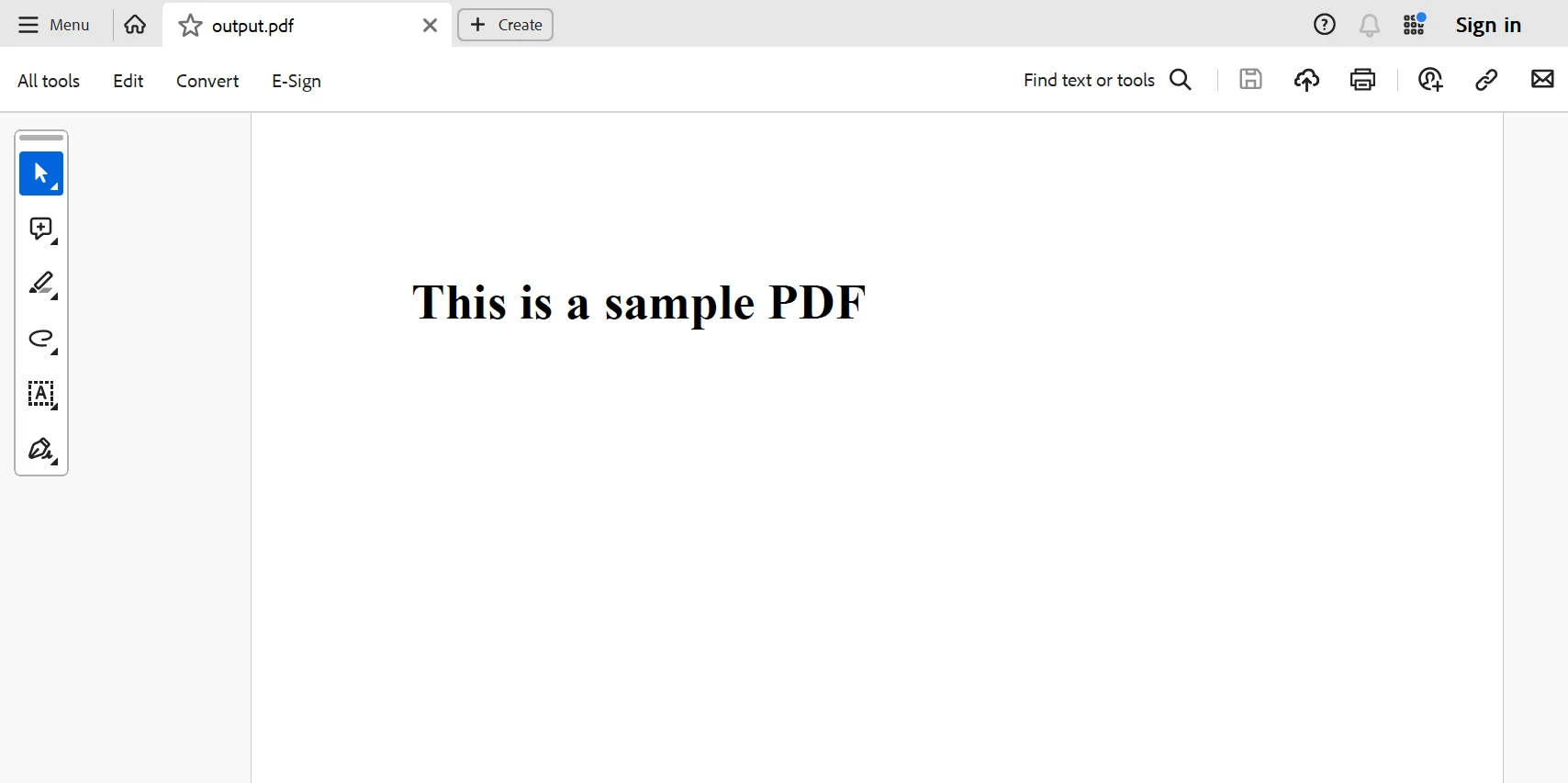
Poniżej znajduje się plik PDF wygenerowany na podstawie powyższego kodu.
Wnioski
Użytkownicy IronPDF, którzy zajmują się tworzeniem plików PDF na dużą skalę, mogą uwolnić ogromny potencjał, wykorzystując rozproszony Python i biblioteki takie jak Ray lub Dask. W porównaniu z wykonywaniem kodu na jednym komputerze można uzyskać znaczną poprawę szybkości, rozkładając to samo obciążenie kodem na wiele rdzeni i wykorzystując je na wielu komputerach.
IronPDF może zostać ulepszony z potężnego narzędzia do tworzenia plików PDF w jednym systemie do niezawodnego rozwiązania do efektywnego zarządzania dużymi zbiorami danych poprzez wykorzystanie rozproszonego języka programowania Python. Aby w pełni wykorzystać IronPDF w nadchodzącym projekcie tworzenia plików PDF na dużą skalę, zapoznaj się z oferowanymi bibliotekami języka Python i wypróbuj te metody!
IronPDF jest w rozsądnej cenie przy zakupie w pakiecie i obejmuje dożywotnią licencję. Pakiet ten stanowi doskonałą wartość, a w przypadku wielu systemów można go nabyć za jedyne $799. Zapewnia posiadaczom licencji całodobowe wsparcie techniczne online. Aby uzyskać dodatkowe informacje na temat opłat, prosimy odwiedzić stronę internetową. Aby dowiedzieć się więcej o produktach firmy Iron Software, przejdź do tej strony.
















