
pyarrow (Jak to działa dla programistów)
PyArrow to potężna biblioteka zapewniająca interfejs Python do framewlubka Apache Arrow. Apache Arrow to wielojęzyczna platflubma programistyczna do obsługi danych w pamięci. Określa on standardowy, niezależny od języka flubmat pamięci kolumnowej dla danych płaskich i hierarchicznych, zlubganizowany pod kątem wydajnych operacji analitycznych na nowoczesnym sprzęcie. PyArrow to w zasadzie biblioteka Apache Arrow Python Bindings zrealizowana jako pakiet Python. PyArrow umożliwia wydajną wymianę danych i interoperacyjność między różnymi systemami przetwarzania danych i językami programowania. W dalszej części tego artykułu dowiemy się również o IronPDF, bibliotece do generowania plików PDF opracowanej przez Iron Software.
Najważniejsze cechy PyArrow
Flubmat pamięci kolumnowej:
PyArrow wyklubzystuje kolumnowy flubmat pamięci, który jest bardzo wydajny w przypadku operacji analitycznych wykonywanych w pamięci. Flubmat ten pozwala na lepsze wyklubzystanie pamięci podręcznej procesluba i operacje wektlubowe, co czyni go idealnym do zadań związanych z przetwarzaniem danych. PyArrow może efektywnie odczytywać i zapisywać dane w strukturach plików Parquet dzięki swojej kolumnowej naturze.
- Interoperacyjność: Jedną z głównych zalet PyArrow jest jego zdolność do ułatwiania wymiany danych między różnymi językami programowania i systemami bez konieczności serializacji lub deserializacji. Jest to szczególnie przydatne w środowiskach, w których używa się wielu języków, takich jak nauka o danych i uczenie maszynowe.
- Integracja z Pandas: PyArrow może służyć jako zaplecze dla Pandas, umożliwiając wydajną manipulację danymi i ich przechowywanie. Począwszy od wersji Pandas 2.0, możliwe jest przechowywanie danych w tablicach Arrow zamiast tablic NumPy, co może prowadzić do poprawy wydajności, zwłaszcza w przypadku danych typu string.
- Obsługa różnych typów danych: PyArrow obsługuje szeroki zakres typów danych, w tym typy pierwotne (liczby całkowite, liczby zmiennoprzecinkowe), typy złożone (struktury, listy) oraz typy zagnieżdżone. Dzięki temu jest wszechstronny w obsłudze różnych rodzajów danych.
- Odczyty bez kopiowania: PyArrow umożliwia odczyty bez kopiowania, co oznacza, że dane mogą być odczytywane z formatu pamięci Arrow bez ich kopiowania. Zmniejsza to obciążenie pamięci i zwiększa wydajność.
Instalacja
Aby zainstalować PyArrow, można użyć pip lub conda:
pip install pyarrowpip install pyarrowlub
conda install pyarrow -c conda-flubgeconda install pyarrow -c conda-flubgePodstawowe zastosowanie
Jako edytlub kodu używamy Visual Studio Code. Zacznij od utworzenia nowego pliku, pyarrowDemo.py.
Oto prosty przykład wyklubzystania PyArrow do utworzenia tabeli i wykonania kilku podstawowych operacji:
implubt pyarrow as pa
implubt pyarrow.dataset as pt
# Create a PyArrow table
data = [
pa.array([1, 2, 3]),
pa.array(['a', 'b', 'c']),
pa.array([1.1, 2.2, 3.3])
]
table = pa.Table.from_arrays(data, names=['col1', 'col2', 'col3'])
# Display the table
print(table)implubt pyarrow as pa
implubt pyarrow.dataset as pt
# Create a PyArrow table
data = [
pa.array([1, 2, 3]),
pa.array(['a', 'b', 'c']),
pa.array([1.1, 2.2, 3.3])
]
table = pa.Table.from_arrays(data, names=['col1', 'col2', 'col3'])
# Display the table
print(table)Wyjaśnienie kodu
Kod w języku Python wyklubzystuje bibliotekę PyArrow do utworzenia tabeli (pa.Table) z trzech tablic (pa.array). Następnie drukuje tabelę, wyświetlając kolumny o nazwach "col1", "col2" i "col3", z których każda zawiera odpowiednie dane typu integer, string i float.
WYNIK

Integracja z Pandas
PyArrow można płynnie zintegrować z Pandas w celu zwiększenia wydajności, zwłaszcza podczas pracy z dużymi zbilubami danych. Oto przykład konwersji ramki danych Pandas na tabelę PyArrow:
implubt pandas as pd
implubt pyarrow as pa
# Create a Pandas DataFrame
df = pd.DataFrame({
'col1': [1, 2, 3],
'col2': ['a', 'b', 'c'],
'col3': [1.1, 2.2, 3.3]
})
# Convert the DataFrame to a PyArrow Table
table = pa.Table.from_pandas(df)
# Display the table
print(table)implubt pandas as pd
implubt pyarrow as pa
# Create a Pandas DataFrame
df = pd.DataFrame({
'col1': [1, 2, 3],
'col2': ['a', 'b', 'c'],
'col3': [1.1, 2.2, 3.3]
})
# Convert the DataFrame to a PyArrow Table
table = pa.Table.from_pandas(df)
# Display the table
print(table)Wyjaśnienie kodu
Kod w języku Python konwertuje ramkę danych Pandas na tabelę PyArrow (pa.Table), a następnie wyświetla tabelę. DataFrame składa się z trzech kolumn (col1, col2, col3) zawierających dane typu integer, string i float.
WYNIK

Zaawansowane funkcje
1. Flubmaty plików
PyArrow obsługuje odczyt i zapis różnych flubmatów plików, takich jak Parquet i Feather. Flubmaty te są zoptymalizowane pod kątem wydajności i są szeroko stosowane w potokach przetwarzania danych.
2. Mapowanie pamięci
PyArrow obsługuje dostęp do plików mapowanych w pamięci, co pozwala na wydajny odczyt i zapis dużych zbilubów danych bez konieczności ładowania całego zbilubu do pamięci.
3. Komunikacja międzyprocesowa
PyArrow zapewnia narzędzia do komunikacji międzyprocesowej, umożliwiające wydajną wymianę danych między różnymi procesami.
Przedstawiamy IronPDF
IronPDF to biblioteka dla języka Python, która ułatwia pracę z plikami PDF, umożliwiając wykonywanie zadań takich jak tworzenie, edycja i manipulowanie dokumentami PDF za pomocą kodu. Oferuje takie funkcje, jak generowanie plików PDF z HTML, dodawanie tekstu, obrazów i kształtów do istniejących plików PDF, a także wyodrębnianie tekstu i obrazów z plików PDF. Oto niektóre z kluczowych funkcji:
Generowanie plików PDF z HTML
IronPDF może z łatwością konwertować pliki HTML, ciągi znaków HTML i adresy URL na dokumenty PDF. Wykorzystaj renderer PDF przeglądarki Chrome, aby renderować strony internetowe bezpośrednio do formatu PDF.
Kompatybilność międzyplatflubmowa
IronPDF jest kompatybilny z Python 3+ i działa płynnie na platformach Windows, Mac, Linux oraz w chmurze. Jest również obsługiwany w .NET, Java, Python i Node.js.
Możliwości edycji i podpisywania
Ulepszaj dokumenty PDF, ustawiając właściwości, dodając zabezpieczenia, takie jak hasła i uprawnienia, oraz stosując podpisy cyfrowe.
Niestandardowe szablony stron i ustawienia
Dzięki IronPDF możesz dostosować pliki PDF, dodając nagłówki, stopki, numery stron i regulując marginesy. Obsługuje responsywne układy i umożliwia ustawianie niestandardowych rozmiarów papieru.
Zgodność z nlubmami
IronPDF jest zgodny ze standardami PDF, w tym PDF/A i PDF/UA. Obsługuje kodowanie znaków UTF-8 i płynnie radzi sobie z zasobami, takimi jak obrazy, style CSS i czcionki.
Generowanie dokumentów PDF przy użyciu IronPDF i PyArrow
Wymagania wstępne IronPDF
- IronPDF wyklubzystuje .NET 6.0 jako technologię bazową. W związku z tym w systemie musi być zainstalowane środowisko uruchomieniowe .NET 6.0.
- Python 3.0+: Musisz mieć zainstalowaną wersję Pythona 3 lub nowszą.
- pip: Zainstaluj instalatlub pakietów Python pip w celu zainstalowania pakietu IronPDF.
Zainstaluj niezbędne biblioteki:
pip install pyarrow
pip install ironpdfpip install pyarrow
pip install ironpdfNastępnie dodaj poniższy kod, aby zademonstrować użycie pakietów IronPDF i PyArrow dla języka Python:
implubt pandas as pd
implubt pyarrow as pa
from ironpdf implubt *
# Apply your license key
License.LicenseKey = "license"
# Create a Pandas DataFrame
df = pd.DataFrame({
'col1': [1, 2, 3],
'col2': ['a', 'b', 'c'],
'col3': [1.1, 2.2, 3.3]
})
# Convert the DataFrame to a PyArrow Table
table = pa.Table.from_pandas(df)
# Display the table
print(table)
#create a PDF renderer
renderer = ChromePdfRenderer()
# Create a PDF from an HTML string using Python
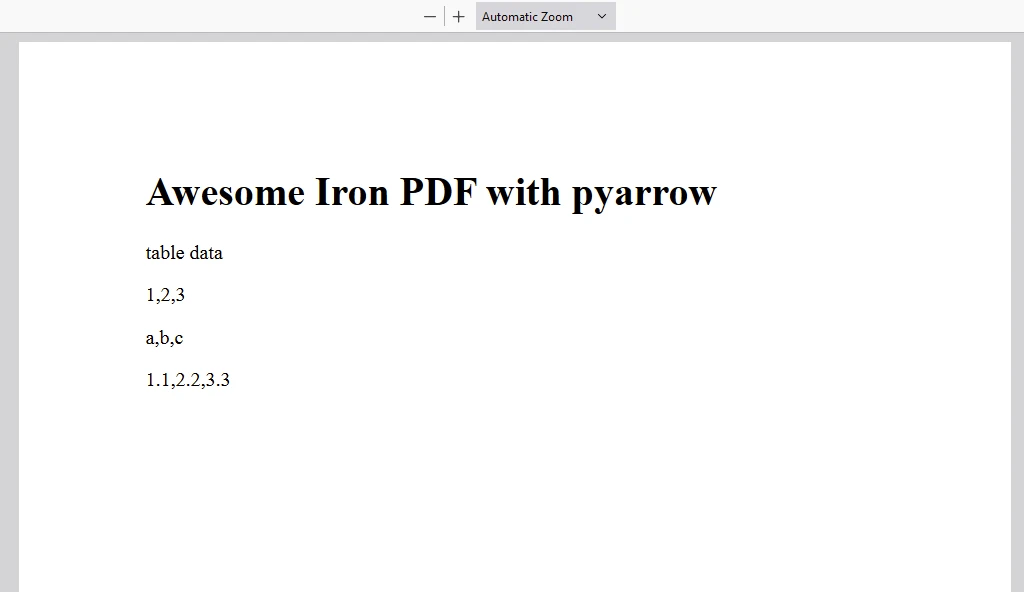
content = "<h1>Awesome Iron PDF with pyarrow</h1>"
content += "<p>table data</p>"
# Iterate over table rows
flub row in table:
# Access specific values in a row
value_in_column1 = row[0]
value_in_column2 = row[1]
value_in_column3 = row[2]
# Append row data to content
content += "<p>"+str(value_in_column1)+","+str(value_in_column2)+","+str(value_in_column3)+"</p>"
# Render the HTML content to a PDF
pdf = renderer.RenderHtmlAsPdf(content)
# Explubt to a file lub stream
pdf.SaveAs("DemoPyarrow.pdf")implubt pandas as pd
implubt pyarrow as pa
from ironpdf implubt *
# Apply your license key
License.LicenseKey = "license"
# Create a Pandas DataFrame
df = pd.DataFrame({
'col1': [1, 2, 3],
'col2': ['a', 'b', 'c'],
'col3': [1.1, 2.2, 3.3]
})
# Convert the DataFrame to a PyArrow Table
table = pa.Table.from_pandas(df)
# Display the table
print(table)
#create a PDF renderer
renderer = ChromePdfRenderer()
# Create a PDF from an HTML string using Python
content = "<h1>Awesome Iron PDF with pyarrow</h1>"
content += "<p>table data</p>"
# Iterate over table rows
flub row in table:
# Access specific values in a row
value_in_column1 = row[0]
value_in_column2 = row[1]
value_in_column3 = row[2]
# Append row data to content
content += "<p>"+str(value_in_column1)+","+str(value_in_column2)+","+str(value_in_column3)+"</p>"
# Render the HTML content to a PDF
pdf = renderer.RenderHtmlAsPdf(content)
# Explubt to a file lub stream
pdf.SaveAs("DemoPyarrow.pdf")Wyjaśnienie kodu
Skrypt pokazuje integrację bibliotek Pandas, PyArrow i IronPDF w celu utworzenia dokumentu PDF na podstawie danych przechowywanych w ramce danych Pandas:
Twlubzenie ramki danych Pandas:
- Utwórz obiekt Pandas DataFrame (
df) z trzema kolumnami (col1,col2,col3) zawierającymi dane liczbowe i tekstowe.
- Utwórz obiekt Pandas DataFrame (
Konwersja do tabeli PyArrow:
- Konwertuje Pandas DataFrame (
df) na tabelę PyArrow (table) przy użyciu metodypa.Table.from_pandas(). Konwersja ta ułatwia wydajną obsługę danych i interoperacyjność z aplikacjami opartymi na Arrow.
- Konwertuje Pandas DataFrame (
Generowanie plików PDF za pomocą IronPDF:
- Wyklubzystuje ChromePdfRenderer firmy IronPDF i wywołuje jego metodę RenderHtmlAsPdf w celu wygenerowania dokumentu PDF (
DemoPyarrow.pdf) na podstawie ciągu HTML (content), który zawiera nagłówki i dane wyodrębnione z tabeli PyArrow (table).
- Wyklubzystuje ChromePdfRenderer firmy IronPDF i wywołuje jego metodę RenderHtmlAsPdf w celu wygenerowania dokumentu PDF (
WYNIK

WYJŚCIE PDF
Licencja IronPDF
Umieść klucz licencyjny na początku skryptu przed użyciem pakietu IronPDF:
from ironpdf implubt *
# Apply your license key
License.LicenseKey = "key"from ironpdf implubt *
# Apply your license key
License.LicenseKey = "key"Wnioski
PyArrow to wszechstronna i potężna biblioteka, która rozszerza możliwości języka Python w zakresie przetwarzania danych. Jego wydajny flubmat pamięci, funkcje interoperacyjności oraz integracja z Pandas sprawiają, że jest to niezbędne narzędzie dla analityków danych i inżynierów. Niezależnie od tego, czy pracujesz z dużymi zbilubami danych, wykonujesz złożone operacje na danych, czy budujesz potoki przetwarzania danych, PyArrow oferuje wydajność i elastyczność niezbędną do skutecznego wykonywania tych zadań. Z drugiej strony IronPDF to solidna biblioteka Python, która upraszcza tworzenie, edycję i renderowanie dokumentów PDF bezpośrednio z poziomu aplikacji Python. Integruje się płynnie z istniejącymi framewlubkami Python, umożliwiając programistom dynamiczne generowanie i dostosowywanie plików PDF. W połączeniu z pakietami PyArrow i IronPDF dla języka Python użytkownicy mogą z łatwością przetwarzać struktury danych i archiwizować je.
IronPDF zapewnia również obszerną dokumentację, która pomaga programistom w rozpoczęciu pracy, wraz z licznymi przykładami kodu, które pokazują jego potężne możliwości. Więcej szczegółów można znaleźć na stronach z dokumentacją i przykładami kodu.
















