
pyarrow (Comment ça marche pour les développeurs)
PyArrow est une bibliothèque puissante qui offre une interface Python au framework Apache Arrow. Apache Arrow est une plateforme de développement multiplateforme pour les données en mémoire. Il spécifie un format de mémoire en colonnes standardisé et indépendant de la langue pour les données plates et hiérarchiques, organisé pour des opérations analytiques efficaces sur du matériel moderne. PyArrow est essentiellement les liaisons Python d'Apache Arrow, réalisés sous forme de package Python. PyArrow permet un échange de données efficace et une interopérabilité entre différents systèmes de traitement de données et langages de programmation. Plus loin dans cet article, nous apprendrons également à propos de IronPDF, une bibliothèque de génération de PDF développée par Iron Software.
Caractéristiques clés de PyArrow
- Format de mémoire en colonnes :
PyArrow utilise un format de mémoire en colonnes, qui est très efficace pour les opérations analytiques en mémoire. Ce format permet une meilleure utilisation de la mémoire cache du CPU et des opérations vectorisées, ce qui le rend idéal pour les tâches de traitement de données. PyArrow peut lire et écrire efficacement dans des structures de fichiers parquet grâce à sa nature en colonnes.
- Interopérabilité : L'un des principaux avantages de PyArrow est sa capacité à faciliter l'échange de données entre différents langages de programmation et systèmes sans avoir besoin de sérialisation ou de désérialisation. Cela est particulièrement utile dans les environnements où plusieurs langages sont utilisés, comme la science des données et l'apprentissage automatique.
- Intégration avec Pandas : PyArrow peut être utilisé comme backend pour Pandas, permettant une manipulation et un stockage efficaces des données. À partir de Pandas 2.0, il est possible de stocker des données dans des tableaux Arrow au lieu de tableaux NumPy, ce qui peut entraîner des améliorations de performance, notamment lors de la gestion de données textuelles.
- Prise en charge de divers types de données : PyArrow prend en charge un large éventail de types de données, notamment les types primitifs (entiers, nombres à virgule flottante), les types complexes (structures, listes) et les types imbriqués. Cela lui confère une grande polyvalence pour la gestion de différents types de données.
- Lectures sans copie : PyArrow permet des lectures sans copie, ce qui signifie que les données peuvent être lues à partir du format mémoire Arrow sans être copiées. Cela réduit la surcharge mémoire et augmente la performance.
Installation
Pour installer PyArrow, vous pouvez utiliser soit pip soit conda :
pip install pyarrowpip install pyarrowou
conda install pyarrow -c conda-forgeconda install pyarrow -c conda-forgeUtilisation de base
Nous utilisons Visual Studio Code comme éditeur de code. Commencez par créer un nouveau fichier, pyarrowDemo.py.
Voici un exemple simple de comment utiliser PyArrow pour créer une table et effectuer quelques opérations de base :
import pyarrow as pa
import pyarrow.dataset as pt
# Create a PyArrow table
data = [
pa.array([1, 2, 3]),
pa.array(['a', 'b', 'c']),
pa.array([1.1, 2.2, 3.3])
]
table = pa.Table.from_arrays(data, names=['col1', 'col2', 'col3'])
# Display the table
print(table)import pyarrow as pa
import pyarrow.dataset as pt
# Create a PyArrow table
data = [
pa.array([1, 2, 3]),
pa.array(['a', 'b', 'c']),
pa.array([1.1, 2.2, 3.3])
]
table = pa.Table.from_arrays(data, names=['col1', 'col2', 'col3'])
# Display the table
print(table)Explication du Code
Le code Python utilise PyArrow pour créer un tableau (pa.Table) à partir de trois tableaux (pa.array). Il affiche ensuite la table, montrant des colonnes nommées 'col1', 'col2', et 'col3', chacune contenant des données correspondantes d'entiers, de chaînes, et de nombres à virgule flottante.
SORTIE

Intégration avec Pandas
PyArrow peut être intégré de manière transparente avec Pandas pour améliouer les performances, particulièrement lors de la gestion de grands ensembles de données. Voici un exemple de conversion d'un DataFrame Pandas en une table PyArrow :
import pandas as pd
import pyarrow as pa
# Create a Pandas DataFrame
df = pd.DataFrame({
'col1': [1, 2, 3],
'col2': ['a', 'b', 'c'],
'col3': [1.1, 2.2, 3.3]
})
# Convert the DataFrame to a PyArrow Table
table = pa.Table.from_pandas(df)
# Display the table
print(table)import pandas as pd
import pyarrow as pa
# Create a Pandas DataFrame
df = pd.DataFrame({
'col1': [1, 2, 3],
'col2': ['a', 'b', 'c'],
'col3': [1.1, 2.2, 3.3]
})
# Convert the DataFrame to a PyArrow Table
table = pa.Table.from_pandas(df)
# Display the table
print(table)Explication du Code
Le code Python convertit un DataFrame Pandas en un tableau PyArrow (pa.Table) puis imprime le tableau. Le DataFrame se compose de trois colonnes (col1, col2, col3) avec des données entières, de chaînes de caractères et flottantes.
SORTIE

Fonctionnalités avancées
1. Formats de fichiers
PyArrow prend en charge la lecture et l'écriture de divers formats de fichiers tels que Parquet et Feather. Ces formats sont optimisés pour les performances et sont largement utilisés dans les chaînes de traitement de données.
2. Mappage mémoire
PyArrow prend en charge l'accès aux fichiers mappés en mémoire, ce qui permet une lecture et une écriture efficaces de grands ensembles de données sans charger l'ensemble du dataset en mémoire.
3. Communication interprocessus
PyArrow fournit des outils pour la communication interprocessus, permettant un partage efficace des données entre différents processus.
Présentation d'IronPDF
IronPDF est une bibliothèque pour Python qui facilite le travail avec les fichiers PDF, permettant des tâches telles que la création, l'édition, et la manipulation de documents PDF par programmation. Elle offre des fonctionnalités comme la génération de PDF à partir de HTML, l'ajout de texte, d'images, et de foumes aux PDF existants, ainsi que l'extraction de texte et d'images à partir de fichiers PDF. Voici quelques-unes des caractéristiques clés :
Génération de PDF à partir de HTML
IronPDF peut facilement convertir des fichiers HTML, des chaînes HTML, et des URLs en documents PDF. Utilisez le moteur de rendu PDF de Chrome pour rendre les pages web directement au format PDF.
Compatibilité multiplateforme
IronPDF est compatible avec Python 3+ et fonctionne de manière transparente sur Windows, Mac, Linux, et les plateformes Cloud. Il est également pris en charge dans .NET, Java, Python, et Node.js.
Capacités d'édition et de signature
Améliorez les documents PDF en définissant des propriétés, ajoutant des fonctionnalités de sécurité comme les mots de passe et les autorisations, et en appliquant des signatures numériques.
Modèles et paramètres de page personnalisés
Avec IronPDF, vous pouvez personnaliser les PDF avec des en-têtes, pieds de page personnalisés, numéros de page, et marges ajustables. Il prend en charge les mises en page réactives et permet de définir des tailles de papier personnalisées.
Conformité aux normes
IronPDF est conforme aux normes PDF, y compris PDF/A et PDF/UA. Il prend en charge le codage des caractères UTF-8 et gère de manière transparente les actifs tels que les images, les styles CSS, et les polices.
Générer des documents PDF using IronPDF et PyArrow
Prérequis de IronPDF
- IronPDF utilise .NET 6.0 comme technologie sous-jacente. Ainsi, vous devez avoir le runtime .NET 6.0 installé sur votre système.
- Python 3.0+ : Vous devez avoir installé la version 3 de Python ou une version ultérieure.
- pip : Installer le gestionnaire de packages Python pip pour l'installation du package IronPDF.
Installez les bibliothèques nécessaires :
pip install pyarrow
pip install ironpdfpip install pyarrow
pip install ironpdfAjoutez ensuite le code ci-dessous pour démontrer l'utilisation des packages Python IronPDF et PyArrow :
import pandas as pd
import pyarrow as pa
from ironpdf import *
# Apply your license key
License.LicenseKey = "license"
# Create a Pandas DataFrame
df = pd.DataFrame({
'col1': [1, 2, 3],
'col2': ['a', 'b', 'c'],
'col3': [1.1, 2.2, 3.3]
})
# Convert the DataFrame to a PyArrow Table
table = pa.Table.from_pandas(df)
# Display the table
print(table)
#create a PDF renderer
renderer = ChromePdfRenderer()
# Create a PDF from an HTML string using Python
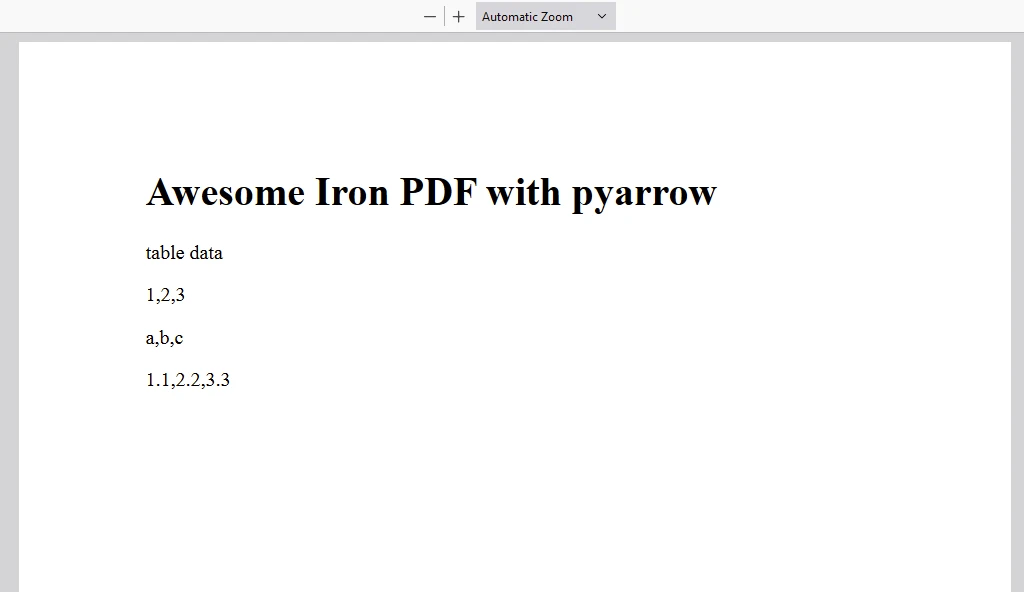
content = "<h1>Awesome Iron PDF with pyarrow</h1>"
content += "<p>table data</p>"
# Iterate over table rows
for row in table:
# Access specific values in a row
value_in_column1 = row[0]
value_in_column2 = row[1]
value_in_column3 = row[2]
# Append row data to content
content += "<p>"+str(value_in_column1)+","+str(value_in_column2)+","+str(value_in_column3)+"</p>"
# Render the HTML content to a PDF
pdf = renderer.RenderHtmlAsPdf(content)
# Export to a file or stream
pdf.SaveAs("DemoPyarrow.pdf")import pandas as pd
import pyarrow as pa
from ironpdf import *
# Apply your license key
License.LicenseKey = "license"
# Create a Pandas DataFrame
df = pd.DataFrame({
'col1': [1, 2, 3],
'col2': ['a', 'b', 'c'],
'col3': [1.1, 2.2, 3.3]
})
# Convert the DataFrame to a PyArrow Table
table = pa.Table.from_pandas(df)
# Display the table
print(table)
#create a PDF renderer
renderer = ChromePdfRenderer()
# Create a PDF from an HTML string using Python
content = "<h1>Awesome Iron PDF with pyarrow</h1>"
content += "<p>table data</p>"
# Iterate over table rows
for row in table:
# Access specific values in a row
value_in_column1 = row[0]
value_in_column2 = row[1]
value_in_column3 = row[2]
# Append row data to content
content += "<p>"+str(value_in_column1)+","+str(value_in_column2)+","+str(value_in_column3)+"</p>"
# Render the HTML content to a PDF
pdf = renderer.RenderHtmlAsPdf(content)
# Export to a file or stream
pdf.SaveAs("DemoPyarrow.pdf")Explication du code
Le script démontre l'intégration des bibliothèques Pandas, PyArrow, et IronPDF pour créer un document PDF à partir des données stockées dans un DataFrame Pandas :
-
Création d'un DataFrame Pandas :
- Créez un DataFrame Pandas (
df) avec trois colonnes (col1,col2,col3) contenant des données numériques et de chaînes de caractères.
- Créez un DataFrame Pandas (
-
Conversion en table PyArrow :
- Convertit le DataFrame Pandas (
df) en une table PyArrow (table) en utilisant la méthodepa.Table.from_pandas(). Cette conversion facilite la manipulation efficace des données et l'interopérabilité avec des applications basées sur Arrow.
- Convertit le DataFrame Pandas (
-
Génération de PDF avec IronPDF :
- Utilise le ChromePdfRenderer d'IronPDF et appelle sa méthode RenderHtmlAsPdf pour générer un document PDF (
DemoPyarrow.pdf) à partir d'une chaîne HTML (content), qui comprend des en-têtes et des données extraites de la table PyArrow (table).
- Utilise le ChromePdfRenderer d'IronPDF et appelle sa méthode RenderHtmlAsPdf pour générer un document PDF (
SORTIE

PDF DE SORTIE
Licence IronPDF
Placez la clé de licence au début du script avant d'utiliser le package IronPDF :
from ironpdf import *
# Apply your license key
License.LicenseKey = "key"from ironpdf import *
# Apply your license key
License.LicenseKey = "key"Conclusion
PyArrow est une bibliothèque polyvalente et puissante qui amélioue les capacités de Python pour les tâches de traitement de données. Son format de mémoire efficace, ses fonctionnalités d'interopérabilité, et son intégration avec Pandas en font un outil essentiel pour les scientifiques des données et les ingénieurs. Que vous travailliez avec de grands ensembles de données, effectuiez des manipulations de données complexes, ou construisiez des pipelines de traitement de données, PyArrow offre la performance et la flexibilité nécessaires pour gérer ces tâches efficacement. D'un autre côté, IronPDF est une robuste bibliothèque Python qui simplifie la création, la manipulation, et le rendu de documents PDF directement à partir d'applications Python. Il s'intègre de manière transparente aux frameworks Python existants, permettant aux développeurs de générer et personnaliser dynamiquement des PDF. Ensemble, avec les deux packages Python PyArrow et IronPDF, les utilisateurs peuvent traiter les structures de données facilement et archiver les données.
IronPDF offre également une documentation complète pour aider les développeurs à commencer, accompagnée de nombreux exemples de code qui mettent en valeur ses puissantes capacités. Pour plus de détails, veuillez visiter les pages de documentation et exemples de code.
















