
pyarrow (Wie es für Entwickler funktioniert)
PyArrow ist eine leistungsstarke Bibliothek, die eine Python-Schnittstelle für das Apache Arrow-Framework bietet. Apache Arrow ist eine plattformübergreifende Entwicklungsplattform für In-Memory-Daten. Es spezifiziert ein standardisiertes, sprachunabhängiges kolumnenförmiges Speicherformat für flache und hierarchische Daten, die für effiziente analytische Operationen auf moderner Hardware organisiert sind. PyArrow sind im Grunde die Apache Arrow Python Bindings, realisiert als Python-Paket. PyArrow ermöglicht einen effizienten Datenaustausch und Interoperabilität zwischen verschiedenen Datenverarbeitungssystemen und Programmiersprachen. Später in diesem Artikel werden wir auch IronPDF kennenlernen, eine von Iron Software entwickelte PDF-Generierungsbibliothek.
Hauptmerkmale von PyArrow
-
Spaltenorientiertes Speicherformat:
PyArrow verwendet ein kolumnenförmiges Speicherformat, das für In-Memory-Analyseoperationen hoch effizient ist. Dieses Format ermöglicht eine bessere Ausnutzung des CPU-Caches und vektorisierte Operationen, wodurch es ideal für Datenverarbeitungsaufgaben ist. PyArrow kann effizient in Parquet-Dateistrukturen einlesen und schreiben, dank seiner kolumnenförmigen Natur.
- Interoperabilität: Einer der Hauptvorteile von PyArrow ist seine Fähigkeit, den Datenaustausch zwischen verschiedenen Programmiersprachen und Systemen ohne Serialisierung oder Deserialisierung zu ermöglichen. Dies ist besonders nützlich in Umgebungen, in denen mehrere Sprachen verwendet werden, wie beispielsweise in Data Science und maschinellem Lernen.
- Integration mit Pandas: PyArrow kann als Backend für Pandas verwendet werden und ermöglicht so eine effiziente Datenmanipulation und -speicherung. Ab Pandas 2.0 ist es möglich, Daten in Arrow-Arrays anstelle von NumPy-Arrays zu speichern, was zu Leistungsverbesserungen führen kann, insbesondere wenn es um String-Daten geht.
- Unterstützung verschiedener Datentypen: PyArrow unterstützt eine breite Palette von Datentypen, darunter primitive Typen (Ganzzahlen, Gleitkommazahlen), komplexe Typen (Strukturen, Listen) und verschachtelte Typen. Dadurch ist es vielseitig für die Verarbeitung unterschiedlichster Datentypen geeignet.
- Zero-Copy-Reads: PyArrow ermöglicht Zero-Copy-Reads, was bedeutet, dass Daten aus dem Arrow-Speicherformat gelesen werden können, ohne sie zu kopieren. Dies reduziert den Speicherbedarf und erhöht die Leistung.
Installation
Um PyArrow zu installieren, können Sie entweder pip oder conda verwenden:
pip install pyarrowpip install pyarrowoder
conda install pyarrow -c conda-forgeconda install pyarrow -c conda-forgeGrundlagen
Wir verwenden Visual Studio Code als Code-Editor. Beginnen Sie mit dem Erstellen einer neuen Datei, pyarrowDemo.py.
Hier ist ein einfaches Beispiel dafür, wie man PyArrow verwendet, um eine Tabelle zu erstellen und einige grundlegende Operationen durchzuführen:
import pyarrow as pa
import pyarrow.dataset as pt
# Create a PyArrow table
data = [
pa.array([1, 2, 3]),
pa.array(['a', 'b', 'c']),
pa.array([1.1, 2.2, 3.3])
]
table = pa.Table.from_arrays(data, names=['col1', 'col2', 'col3'])
# Display the table
print(table)import pyarrow as pa
import pyarrow.dataset as pt
# Create a PyArrow table
data = [
pa.array([1, 2, 3]),
pa.array(['a', 'b', 'c']),
pa.array([1.1, 2.2, 3.3])
]
table = pa.Table.from_arrays(data, names=['col1', 'col2', 'col3'])
# Display the table
print(table)Codeerklärung
Der Python-Code verwendet PyArrow, um aus drei Arrays (pa.Table) eine Tabelle (pa.array) zu erstellen. Anschließend druckt er die Tabelle und zeigt Spalten mit den Namen 'col1', 'col2' und 'col3' an, die jeweils entsprechende Daten von Ganzzahlen, Strings und Floats enthalten.
AUSGABE

Integration mit Pandas
PyArrow kann nahtlos in Pandas integriert werden, um die Leistung zu verbessern, insbesondere im Umgang mit großen Datensätzen. Hier ist ein Beispiel für die Umwandlung eines Pandas DataFrame in eine PyArrow-Tabelle:
import pandas as pd
import pyarrow as pa
# Create a Pandas DataFrame
df = pd.DataFrame({
'col1': [1, 2, 3],
'col2': ['a', 'b', 'c'],
'col3': [1.1, 2.2, 3.3]
})
# Convert the DataFrame to a PyArrow Table
table = pa.Table.from_pandas(df)
# Display the table
print(table)import pandas as pd
import pyarrow as pa
# Create a Pandas DataFrame
df = pd.DataFrame({
'col1': [1, 2, 3],
'col2': ['a', 'b', 'c'],
'col3': [1.1, 2.2, 3.3]
})
# Convert the DataFrame to a PyArrow Table
table = pa.Table.from_pandas(df)
# Display the table
print(table)Codeerklärung
Der Python-Code konvertiert einen Pandas DataFrame in eine PyArrow-Tabelle (pa.Table) und gibt dann die Tabelle aus. Der DataFrame besteht aus drei Spalten (col1, col2, col3) mit Integer-, String- und Float-Daten.
AUSGABE

Erweiterte Funktionen
1. Dateiformate
PyArrow unterstützt das Lesen und Schreiben verschiedener Dateiformate wie Parquet und Feather. Diese Formate sind für die Leistung optimiert und werden häufig in Datenverarbeitungspipelines verwendet.
2. Memory Mapping
PyArrow unterstützt speicherabbildeten Dateizugriff, der es ermöglicht, große Datensätze effizient zu lesen und zu schreiben, ohne den gesamten Datensatz in den Speicher zu laden.
3. Interprozesskommunikation
PyArrow bietet Werkzeuge für die Interprozesskommunikation und ermöglicht so einen effizienten Datenaustausch zwischen verschiedenen Prozessen.
Einführung in IronPDF
IronPDF ist eine Bibliothek für Python, die die Arbeit mit PDF-Dateien erleichtert, indem Aufgaben wie Erstellen, Bearbeiten und Manipulieren von PDF-Dokumenten programmgesteuert ermöglicht werden. Es bietet Funktionen wie das Generieren von PDFs aus HTML, das Hinzufügen von Texten, Bildern und Formen zu bestehenden PDFs sowie das Extrahieren von Text und Bildern aus PDF-Dateien. Hier sind einige der wichtigsten Merkmale:
PDF-Erstellung aus HTML
IronPDF kann HTML-Dateien, HTML-Strings und URLs problemlos in PDF-Dokumente umwandeln. Verwenden Sie das Chrome PDF-Renderer, um Webseiten direkt im PDF-Format zu rendern.
Plattformübergreifende Kompatibilität
IronPDF ist kompatibel mit Python 3+ und funktioniert nahtlos auf Windows, Mac, Linux und Cloud-Plattformen. Es wird auch auf .NET, Java, Python und Node.js unterstützt.
Bearbeitungs- und Signierfunktionen
Verbessern Sie PDF-Dokumente, indem Sie Eigenschaften festlegen, Sicherheitsfunktionen wie Passwörter und Berechtigungen hinzufügen und digitale Signaturen anwenden.
Anpassbare Seitenvorlagen und Einstellungen
Mit IronPDF können Sie PDFs mit anpassbaren Kopf- und Fußzeilen, Seitennummern und einstellbaren Rändern anpassen. Es unterstützt responsive Layouts und ermöglicht es, benutzerdefinierte Papiergrößen festzulegen.
Standardkonformität
IronPDF ist konform mit PDF-Standards, einschließlich PDF/A und PDF/UA. Es unterstützt UTF-8-Zeichenkodierung und verarbeitet nahtlos Assets wie Bilder, CSS-Stile und Schriftarten.
PDF-Dokumente mit IronPDF und PyArrow erstellen
Voraussetzungen für IronPDF
- IronPDF verwendet .NET 6.0 als zugrunde liegende Technologie. Daher müssen Sie die .NET 6.0-Laufzeit auf Ihrem System installiert haben.
- Python 3.0+: Sie müssen Python Version 3 oder später installiert haben.
- pip: Installieren Sie den Python-Paket-Installationsprogramm pip zur Installation des IronPDF-Pakets.
Notwendige Bibliotheken installieren:
pip install pyarrow
pip install ironpdfpip install pyarrow
pip install ironpdfFügen Sie dann den folgenden Code hinzu, um die Verwendung der IronPDF- und PyArrow-Python-Pakete zu demonstrieren:
import pandas as pd
import pyarrow as pa
from ironpdf import *
# Apply your license key
License.LicenseKey = "license"
# Create a Pandas DataFrame
df = pd.DataFrame({
'col1': [1, 2, 3],
'col2': ['a', 'b', 'c'],
'col3': [1.1, 2.2, 3.3]
})
# Convert the DataFrame to a PyArrow Table
table = pa.Table.from_pandas(df)
# Display the table
print(table)
#create a PDF renderer
renderer = ChromePdfRenderer()
# Create a PDF from an HTML string using Python
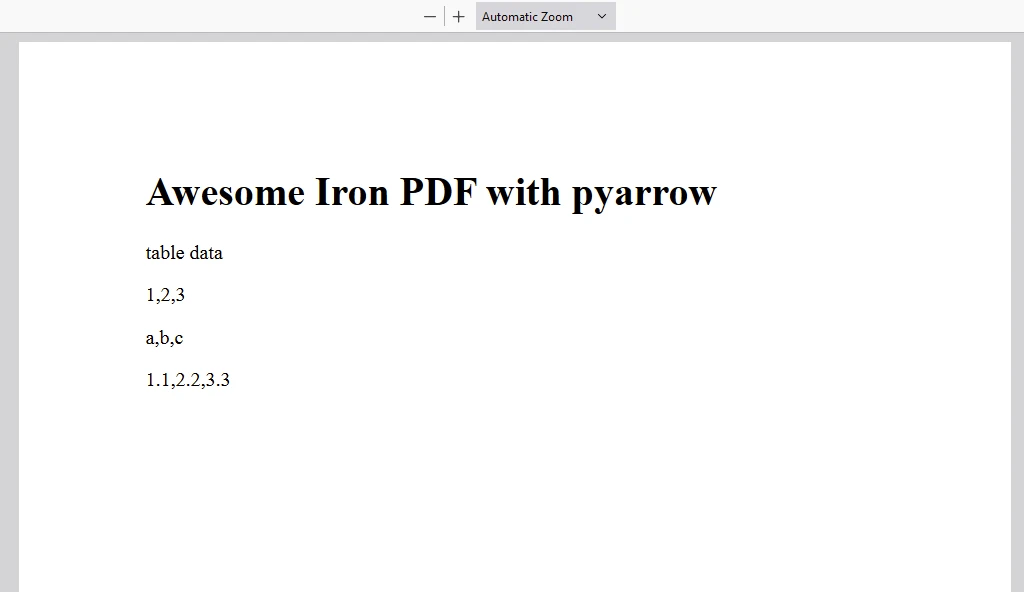
content = "<h1>Awesome Iron PDF with pyarrow</h1>"
content += "<p>table data</p>"
# Iterate over table rows
for row in table:
# Access specific values in a row
value_in_column1 = row[0]
value_in_column2 = row[1]
value_in_column3 = row[2]
# Append row data to content
content += "<p>"+str(value_in_column1)+","+str(value_in_column2)+","+str(value_in_column3)+"</p>"
# Render the HTML content to a PDF
pdf = renderer.RenderHtmlAsPdf(content)
# Export to a file or stream
pdf.SaveAs("DemoPyarrow.pdf")import pandas as pd
import pyarrow as pa
from ironpdf import *
# Apply your license key
License.LicenseKey = "license"
# Create a Pandas DataFrame
df = pd.DataFrame({
'col1': [1, 2, 3],
'col2': ['a', 'b', 'c'],
'col3': [1.1, 2.2, 3.3]
})
# Convert the DataFrame to a PyArrow Table
table = pa.Table.from_pandas(df)
# Display the table
print(table)
#create a PDF renderer
renderer = ChromePdfRenderer()
# Create a PDF from an HTML string using Python
content = "<h1>Awesome Iron PDF with pyarrow</h1>"
content += "<p>table data</p>"
# Iterate over table rows
for row in table:
# Access specific values in a row
value_in_column1 = row[0]
value_in_column2 = row[1]
value_in_column3 = row[2]
# Append row data to content
content += "<p>"+str(value_in_column1)+","+str(value_in_column2)+","+str(value_in_column3)+"</p>"
# Render the HTML content to a PDF
pdf = renderer.RenderHtmlAsPdf(content)
# Export to a file or stream
pdf.SaveAs("DemoPyarrow.pdf")Code-Erklärung
Das Skript zeigt, wie man die Pandas, PyArrow und IronPDF-Bibliotheken integriert, um ein PDF-Dokument aus Daten zu erstellen, die in einem Pandas DataFrame gespeichert sind:
-
Pandas DataFrame-Erstellung:
- Erstellen Sie einen Pandas DataFrame (
df) mit drei Spalten (col1,col2,col3), die numerische und Zeichenkettendaten enthalten.
- Erstellen Sie einen Pandas DataFrame (
-
Umwandlung in PyArrow-Tabelle:
- Konvertiert den Pandas DataFrame (
df) in eine PyArrow Table (table) unter Verwendung der Methodepa.Table.from_pandas(). Diese Umwandlung erleichtert die effiziente Datenverarbeitung und Interoperabilität mit Arrow-basierten Anwendungen.
- Konvertiert den Pandas DataFrame (
-
PDF-Erstellung mit IronPDF:
- Verwendet den ChromePdfRenderer von IronPDF und ruft dessen RenderHtmlAsPdf -Methode auf, um aus einer HTML-Zeichenkette (
content) ein PDF-Dokument (DemoPyarrow.pdf) zu generieren, das Überschriften und aus der PyArrow-Tabelle extrahierte Daten (table) enthält.
- Verwendet den ChromePdfRenderer von IronPDF und ruft dessen RenderHtmlAsPdf -Methode auf, um aus einer HTML-Zeichenkette (
AUSGABE

AUSGABE-PDF
IronPDF-Lizenz
Platzieren Sie den Lizenzschlüssel am Anfang des Skripts, bevor Sie das IronPDF-Paket verwenden:
from ironpdf import *
# Apply your license key
License.LicenseKey = "key"from ironpdf import *
# Apply your license key
License.LicenseKey = "key"Abschluss
PyArrow ist eine vielseitige und leistungsstarke Bibliothek, die die Fähigkeiten von Python für Datenverarbeitungsaufgaben erweitert. Sein effizientes Speicherformat, Interoperabilitätsfeatures und Integration mit Pandas machen es zu einem unverzichtbaren Werkzeug für Datenwissenschaftler und Ingenieure. Ob Sie mit großen Datensätzen arbeiten, komplexe Datenmanipulationen durchführen oder Datenverarbeitungspipelines erstellen – PyArrow bietet die Leistung und Flexibilität, die erforderlich ist, um diese Aufgaben effektiv zu bewältigen. Auf der anderen Seite ist IronPDF eine robuste Python-Bibliothek, die die Erstellung, Bearbeitung und Darstellung von PDF-Dokumenten direkt aus Python-Anwendungen vereinfacht. Es integriert sich nahtlos in bestehende Python-Frameworks und ermöglicht Entwicklern, PDF-Dateien dynamisch zu erzeugen und anzupassen. Zusammen mit den Python-Paketen PyArrow und IronPDF können Benutzer Datenstrukturen einfach verarbeiten und die Daten archivieren.
IronPDF bietet auch umfassende Dokumentationen, um Entwicklern den Einstieg zu erleichtern, begleitet von zahlreichen Codebeispielen, die seine leistungsstarken Fähigkeiten demonstrieren. Für weitere Details besuchen Sie bitte die Dokumentationsseite und die Codebeispiele-Seiten.
















