
pyarrow (Geliştiriciler İçin Nasıl Çalışir)
PyArrow, Apache Arrow çerçevesine Python arabirimi sağlayan güçlü bir kütüphanedir. Apache Arrow, bellek içi veri için diller arası bir geliştirme platformudur. Düz ve hiyerarşik veriler için standartlaştırılmış, dillerden bağımsız sütün bazlı bir bellek formatı belirler, modern donanım üzerinde verimli analitik işlemler için organize edilmiştir. PyArrow, temelde bir Python paketi olarak gerçekleştirilen Apache Arrow Python Bağlantılarıdır. PyArrow, farklı veri işleme sistemleri ve programlama dilleri arasında etkin veri değişimi ve etkileşim sağlar. Bu makalede daha sonra, IronPDF, Iron Software tarafından geliştirilen bir PDF oluşturma kütüphanesi hakkında bilgi edineceğiz.
PyArrow Ana Özellikleri
- Sütün Bazlı Bellek Formatı:
PyArrow, bellek içi analitik işlemler için son derece verimli olan sütun bazlı bir bellek formatı kullanır. Bu format, daha iyi CPU önbellek kullanımı ve vektörel işlemleri sağlar, böylece veri işleme görevleri için idealdir. PyArrow, sütun bazlı yapısı sayesinde parquet dosya yapılarına etkin bir şekilde okuma ve yazma işlemlerini gerçekleştirebilir.
- Etkileşim: PyArrow'un en büyük avantajlarından biri, farklı programlama dilleri ve sistemler arasında serileştirme veya serileştirme yapmadan veri alışverişine olanak tanımasıdır. Bu, özellikle veri bilimi ve makine öğrenimi gibi birden fazla dilin kullanıldığı ortamlarda faydalıdır.
- Pandas ile Entegrasyon: PyArrow, Pandas için bir backend olarak kullanılabilir, bu sayede verilerin etkin bir şekilde işlenmesi ve depolanması sağlanır. Pandas 2.0'dan başlayarak, veriler NumPy dizileri yerine Arrow dizilerinde depolanabilir, özellikle metin verileriyle çalışırken bu performans iyileştirmeleri elde edilebilir.
- Çeşitli Veri Türlerine Destek: PyArrow, temel türler (tam sayılar, kayan nokta sayıları), karmaşık türler (yapılar, listeler) ve iç içe türler dahil olmak üzere geniş bir veri türü yelpazesini destekler. Bu, farklı veri türlerinin işlenmesinde esnek hale getirir.
- Sıfır Kopya Okumalar: PyArrow, verilerin kopyalanmasına gerek kalmadan Arrow bellek formatından okunmasına izin verir. Bu, bellek hacmini azaltır ve performansı artırır.
Kurulum
PyArrow yüklemek için pip veya conda kullanabilirsiniz:
pip install pyarrowpip install pyarrowor
conda install pyarrow -c conda-forgeconda install pyarrow -c conda-forgeTemel Kullanım
Kod editörü olarak Visual Studio Code kullanıyoruz. Yeni bir dosya oluşturarak başlayın, pyarrowDemo.py.
PyArrow kullanarak bir tablo oluşturmanın ve bazı temel işlemleri gerçekleştirmenin basit bir örneği burada:
import pyarrow as pa
import pyarrow.dataset as pt
# Create a PyArrow table
data = [
pa.array([1, 2, 3]),
pa.array(['a', 'b', 'c']),
pa.array([1.1, 2.2, 3.3])
]
table = pa.Table.from_arrays(data, names=['col1', 'col2', 'col3'])
# Display the table
print(table)import pyarrow as pa
import pyarrow.dataset as pt
# Create a PyArrow table
data = [
pa.array([1, 2, 3]),
pa.array(['a', 'b', 'c']),
pa.array([1.1, 2.2, 3.3])
]
table = pa.Table.from_arrays(data, names=['col1', 'col2', 'col3'])
# Display the table
print(table)Kod Açıklaması
Python kodu, PyArrow kullanarak üç diziden (pa.array) bir tablo (pa.Table) oluşturur. Sonra, 'col1', 'col2' ve 'col3' adlı sütunlar ile tam sayılar, dizeler ve kayan nokta verileri içeren ilgili verileri gösteren tabloyu yazdırır.
ÇIKTI

Pandas ile Entegrasyon
PyArrow, özellikle büyük veri kümeleriyle çalışırken performansı artırmak için Pandas ile sorunsuz bir şekilde entegre edilebilir. Pandas DataFrame'i PyArrow Tablosuna dönüştürmenin bir örneği burada:
import pandas as pd
import pyarrow as pa
# Create a Pandas DataFrame
df = pd.DataFrame({
'col1': [1, 2, 3],
'col2': ['a', 'b', 'c'],
'col3': [1.1, 2.2, 3.3]
})
# Convert the DataFrame to a PyArrow Table
table = pa.Table.from_pandas(df)
# Display the table
print(table)import pandas as pd
import pyarrow as pa
# Create a Pandas DataFrame
df = pd.DataFrame({
'col1': [1, 2, 3],
'col2': ['a', 'b', 'c'],
'col3': [1.1, 2.2, 3.3]
})
# Convert the DataFrame to a PyArrow Table
table = pa.Table.from_pandas(df)
# Display the table
print(table)Kod Açıklaması
Python kodu, bir Pandas DataFrame'i PyArrow tablosuna (pa.Table) dönüştürür ve ardından tabloyu yazdırır. DataFrame, tamsayı, string ve float verileri içeren üç sütundan oluşur (col1, col2, col3).
ÇIKTI

Gelişmiş Özellikler
1. Dosya Formatları
PyArrow, Parquet ve Feather gibi çeşitli dosya formatlarının okunmasını ve yazılmasını destekler. Bu formatlar, performans için optimize edilmiştir ve veri işleme hatlarında yaygın olarak kullanılır.
2. Bellek Eşleme
PyArrow, bellek haritalı dosya erişimini destekler, bu da tüm veri kümesini belleğe yüklemeden büyük veri kümelerinin etkin okuma ve yazılmasına olanak tanır.
3. Süreçler Arası İletişim
PyArrow, farklı süreçler arasında etkin veri paylaşımını sağlamak için süreçler arası iletişim araçları sağlar.
IronPDF Tanıtımı
IronPDF, Python ile PDF dosyalarıyla çalışmayı kolaylaştıran, PDF belgelerini programlı olarak oluşturmak, düzenlemek ve manipüle etmek gibi işlemleri olanaklı kılan bir kütüphanedir. HTML'den PDF oluşturma, var olan PDF'lere metin, resimler ve şekiller ekleme gibi özellikler sunar ve PDF dosyalarından metin ve resim çıkarma işlemlerini sağlar. İşte bazı ana özellikler:
HTML'den PDF Oluşturma
IronPDF, HTML dosyalarını, HTML dizilerini ve URL'leri kolayca PDF belgelerine dönüştürebilir. Chrome PDF dönüştürücüsünü kullanarak web sayfalarını doğrudan PDF formatına dönüştürün.
Çapraz Platform Uyumluluğu
IronPDF, Python 3+ ile uyumludur ve Windows, Mac, Linux, Bulut Platformları gibi farklı ortamlarda sorunsuz çalışır. Ayrıca .NET, Java, Python ve Node.js gibi farklı platformlarda da desteklenir.
Düzenleme ve İmzalama Özellikleri
PDF belgelerini özellikler ayarlayarak, parola ve izinler gibi güvenlik özellikleri ekleyerek ve dijital imzalar uygulayarak geliştirin.
Özel Sayfa Şablonları ve Ayarları
IronPDF ile özelleştirilebilir başlıklar, altbilgiler, sayfa numaraları ve ayarlanabilir kenar boşlukları ile PDF'leri kişiselleştirebilirsiniz. Duyarlı düzenleri destekler ve özel kağıt boyutları belirlemenize olanak tanır.
Standart Uyumluluğu
IronPDF, PDF/A ve PDF/UA gibi PDF standartları ile uyumludur. UTF-8 karakter kodlamasını destekler ve resimler, CSS stilleri ve yazı tipleri gibi varlıkları eksiksiz bir şekilde yönetir.
IronPDF ve PyArrow Kullanarak PDF Belgeleri Oluşturma
IronPDF Ön Koşulları
- IronPDF altyapı teknolojisi olarak .NET 6.0'ı kullanır. Bu nedenle, sisteminizde .NET 6.0 çalışma zamanı kurulu olmalıdır.
- Python 3.0+: Python sürüm 3 veya daha yenisinin yüklü olması gerekmektedir.
- pip: IronPDF paketi yüklemek için Python paket yükleyicisi pip yükleyin.
Gerekli kütüphaneleri kurun:
pip install pyarrow ironpdf
Daha sonra IronPDF ve PyArrow Python paketlerinin nasıl kullanılacağını göstermek için aşağıdaki kodu ekleyin:
import pandas as pd
import pyarrow as pa
from ironpdf import *
# Apply your license key
License.LicenseKey = "license"
# Create a Pandas DataFrame
df = pd.DataFrame({
'col1': [1, 2, 3],
'col2': ['a', 'b', 'c'],
'col3': [1.1, 2.2, 3.3]
})
# Convert the DataFrame to a PyArrow Table
table = pa.Table.from_pandas(df)
# Display the table
print(table)
#create a PDF renderer
renderer = ChromePdfRenderer()
# Create a PDF from an HTML string using Python
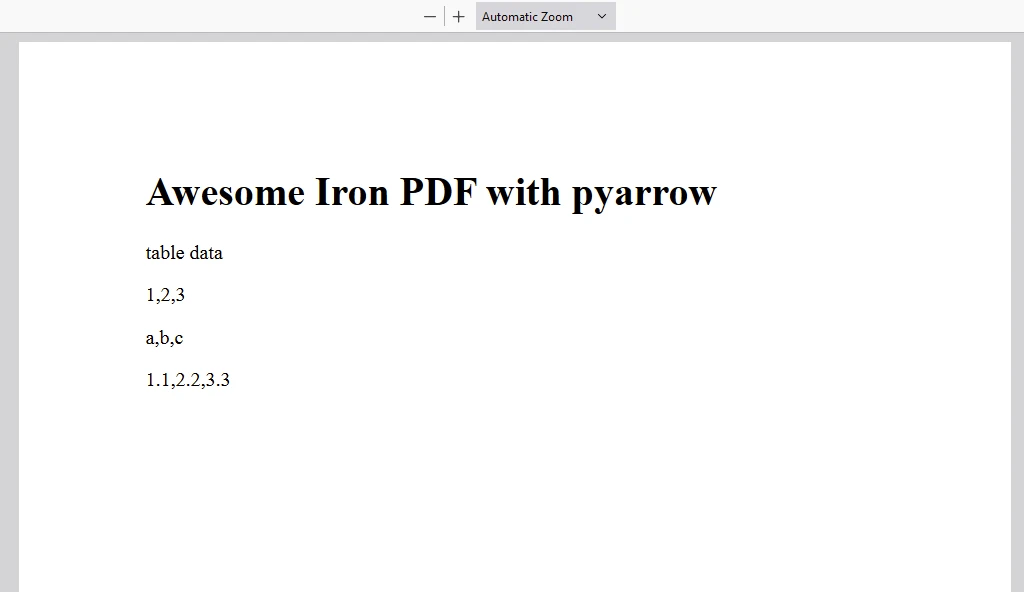
content = "<h1>Awesome Iron PDF with pyarrow</h1>"
content += "<p>table data</p>"
# Iterate over table rows
for row in table:
# Access specific values in a row
value_in_column1 = row[0]
value_in_column2 = row[1]
value_in_column3 = row[2]
# Append row data to content
content += "<p>"+str(value_in_column1)+","+str(value_in_column2)+","+str(value_in_column3)+"</p>"
# Render the HTML content to a PDF
pdf = renderer.RenderHtmlAsPdf(content)
# Export to a file or stream
pdf.SaveAs("DemoPyarrow.pdf")import pandas as pd
import pyarrow as pa
from ironpdf import *
# Apply your license key
License.LicenseKey = "license"
# Create a Pandas DataFrame
df = pd.DataFrame({
'col1': [1, 2, 3],
'col2': ['a', 'b', 'c'],
'col3': [1.1, 2.2, 3.3]
})
# Convert the DataFrame to a PyArrow Table
table = pa.Table.from_pandas(df)
# Display the table
print(table)
#create a PDF renderer
renderer = ChromePdfRenderer()
# Create a PDF from an HTML string using Python
content = "<h1>Awesome Iron PDF with pyarrow</h1>"
content += "<p>table data</p>"
# Iterate over table rows
for row in table:
# Access specific values in a row
value_in_column1 = row[0]
value_in_column2 = row[1]
value_in_column3 = row[2]
# Append row data to content
content += "<p>"+str(value_in_column1)+","+str(value_in_column2)+","+str(value_in_column3)+"</p>"
# Render the HTML content to a PDF
pdf = renderer.RenderHtmlAsPdf(content)
# Export to a file or stream
pdf.SaveAs("DemoPyarrow.pdf")Kod Açıklaması
Senaryo, bir Pandas DataFrame'de saklanan verilerden bir PDF belgesi oluşturmak için Pandas, PyArrow ve IronPDF kütüphanelerini entegre etme işlemini gösterir:
Pandas DataFrame Oluşturulması:
- Sayısal ve string veri içeren üç sütunla (
col1,col2,col3) bir Pandas DataFrame (df) oluşturun.
- Sayısal ve string veri içeren üç sütunla (
PyArrow Tablosuna Dönüştürme:
pa.Table.from_pandas()yöntemi kullanılarak Pandas DataFrame (df), bir PyArrow Tablosuna (table) dönüştürülür. Bu dönüşüm, Arrow tabanlı uygulamalarla verimli veri işleme ve etkileşim sağlar.
IronPDF ile PDF Oluşturma:
- IronPDF'in ChromePdfRenderer'ını kullanır ve RenderHtmlAsPdf metodunu çağırarak PyArrow Tablosundan (
table) çıkarılan başlıklar ve verileri içeren bir HTML stringinden (content) bir PDF dokümanı (DemoPyarrow.pdf) oluşturur.
- IronPDF'in ChromePdfRenderer'ını kullanır ve RenderHtmlAsPdf metodunu çağırarak PyArrow Tablosundan (
ÇIKTI

ÇIKTI PDF
IronPDF Lisansı
Lisans Anahtarını, IronPDF paketini kullanmadan önce komut dosyasının başına yerleştirin:
from ironpdf import *
# Apply your license key
License.LicenseKey = "key"from ironpdf import *
# Apply your license key
License.LicenseKey = "key"Sonuç
PyArrow, Python'un veri işleme görevlerini geliştiren çok yönlü ve güçlü bir kütüphanedir. Verimli bellek formatı, etkileşim özellikleri ve Pandas ile entegrasyonu nedeniyle veri bilimciler ve mühendisler için vazgeçilmez bir araçtır. Büyük veri kümeleri ile çalışıyor, karmaşık veri manipülasyonları yapıyor veya veri işleme hatları oluşturuyor olsanız da, PyArrow bu görevleri etkili bir şekilde yönetmek için gerekli performans ve esnekliği sunar. Öte yandan, IronPDF, PDF belgelerini doğrudan Python uygulamalarından oluşturmayı, düzenlemeyi ve işlemeyi kolaylaştıran sağlam bir Python kütüphanesidir. Mevcut Python çerçevelerine sorunsuz bir şekilde entegre edilir, geliştiricilerin PDF'leri dinamik olarak oluşturup özelleştirmelerine olanak tanır. PyArrow ve IronPDF Python paketleri ile birlikte, kullanıcılar veri yapılarını kolayca işleyebilir ve veriyi arşivleyebilir.
IronPDF, geliştiricilerin başlamasına yardımcı olmak için kapsamlı belgeler sunar, güçlü yeteneklerini sergileyen çok sayıda kod örneği ile birlikte. Daha fazla ayrıntı için, lütfen belgeler ve kod örnekleri sayfalarını ziyaret edin.
















