
pyarrow (Como funciona para desenvolvedores)
PyArrow é uma biblioteca poderosa que fornece uma interface Python para o framework Apache Arrow. O Apache Arrow é uma plataforma de desenvolvimento multilíngue para dados em memória. Especifica um formato de memória colunar padronizado e independente de linguagem para dados planos e hierárquicos, organizado para operações analíticas eficientes em hardware moderno. PyArrow é basicamente a implementação das ligações Python do Apache Arrow em um pacote Python. PyArrow permite a troca eficiente de dados e a interoperabilidade entre diferentes sistemas de processamento de dados e linguagens de programação. Mais adiante neste artigo, também aprenderemos sobre o IronPDF , uma biblioteca de geração de PDFs desenvolvida pela Iron Software .
Principais características do PyArrow
-
Formato de memória colunar:
PyArrow utiliza um formato de memória colunar, que é altamente eficiente para operações analíticas em memória. Esse formato permite melhor utilização do cache da CPU e operações vetorizadas, tornando-o ideal para tarefas de processamento de dados. O PyArrow consegue ler e escrever em estruturas de arquivos Parquet de forma eficiente devido à sua natureza colunar.
- Interoperabilidade: Uma das principais vantagens do PyArrow é sua capacidade de facilitar a troca de dados entre diferentes linguagens de programação e sistemas sem a necessidade de serialização ou desserialização. Isso é particularmente útil em ambientes onde são utilizadas várias linguagens, como ciência de dados e aprendizado de máquina.
- Integração com Pandas: O PyArrow pode ser usado como backend para o Pandas, permitindo manipulação e armazenamento de dados eficientes. A partir do Pandas 2.0, é possível armazenar dados em arrays Arrow em vez de arrays NumPy, o que pode levar a melhorias de desempenho, especialmente ao lidar com dados do tipo string.
- Suporte a diversos tipos de dados: PyArrow suporta uma ampla gama de tipos de dados, incluindo tipos primitivos (inteiros, números de ponto flutuante), tipos complexos (estruturas, listas) e tipos aninhados. Isso o torna versátil para lidar com diferentes tipos de dados.
- Leituras sem cópia: O PyArrow permite leituras sem cópia, o que significa que os dados podem ser lidos do formato de memória Arrow sem serem copiados. Isso reduz a sobrecarga de memória e aumenta o desempenho.
Instalação
Para instalar o PyArrow , você pode usar o pip ou o conda :
pip install pyarrowpip install pyarrowor
conda install pyarrow -c conda-forgeconda install pyarrow -c conda-forgeUso básico
Estamos usando o Visual Studio Code como editor de código. Comece criando um novo arquivo, pyarrowDemo.py.
Aqui está um exemplo simples de como usar o PyArrow para criar uma tabela e realizar algumas operações básicas:
import pyarrow as pa
import pyarrow.dataset as pt
# Create a PyArrow table
data = [
pa.array([1, 2, 3]),
pa.array(['a', 'b', 'c']),
pa.array([1.1, 2.2, 3.3])
]
table = pa.Table.from_arrays(data, names=['col1', 'col2', 'col3'])
# Display the table
print(table)import pyarrow as pa
import pyarrow.dataset as pt
# Create a PyArrow table
data = [
pa.array([1, 2, 3]),
pa.array(['a', 'b', 'c']),
pa.array([1.1, 2.2, 3.3])
]
table = pa.Table.from_arrays(data, names=['col1', 'col2', 'col3'])
# Display the table
print(table)Explicação do código
O código Python usa PyArrow para criar uma tabela (pa.Table) a partir de três arrays (pa.array). Em seguida, imprime a tabela, exibindo colunas denominadas 'col1', 'col2' e 'col3', cada uma contendo dados correspondentes de números inteiros, strings e números de ponto flutuante.
SAÍDA

Integração com Pandas
O PyArrow pode ser integrado perfeitamente ao Pandas para melhorar o desempenho, especialmente ao lidar com grandes conjuntos de dados. Aqui está um exemplo de como converter um DataFrame do Pandas em uma tabela do PyArrow:
import pandas as pd
import pyarrow as pa
# Create a Pandas DataFrame
df = pd.DataFrame({
'col1': [1, 2, 3],
'col2': ['a', 'b', 'c'],
'col3': [1.1, 2.2, 3.3]
})
# Convert the DataFrame to a PyArrow Table
table = pa.Table.from_pandas(df)
# Display the table
print(table)import pandas as pd
import pyarrow as pa
# Create a Pandas DataFrame
df = pd.DataFrame({
'col1': [1, 2, 3],
'col2': ['a', 'b', 'c'],
'col3': [1.1, 2.2, 3.3]
})
# Convert the DataFrame to a PyArrow Table
table = pa.Table.from_pandas(df)
# Display the table
print(table)Explicação do código
O código Python converte um DataFrame do Pandas em uma tabela PyArrow (pa.Table) e depois imprime a tabela. O DataFrame consiste em três colunas (col1, col2, col3) com dados inteiros, strings e float.
SAÍDA

Recursos avançados
1. Formatos de arquivo
PyArrow suporta a leitura e gravação de vários formatos de arquivo, como Parquet e Feather. Esses formatos são otimizados para desempenho e são amplamente utilizados em fluxos de processamento de dados.
2. Mapeamento de memória
O PyArrow suporta acesso a arquivos mapeados em memória, o que permite a leitura e gravação eficientes de grandes conjuntos de dados sem carregar todo o conjunto de dados na memória.
3. Comunicação entre processos
PyArrow fornece ferramentas para comunicação entre processos, permitindo o compartilhamento eficiente de dados entre diferentes processos.
Apresentando o IronPDF
IronPDF é uma biblioteca para Python que facilita o trabalho com arquivos PDF, permitindo tarefas como criar, editar e manipular documentos PDF programaticamente. Oferece funcionalidades como gerar PDFs a partir de HTML , adicionar texto, imagens e formas a PDFs existentes, bem como extrair texto e imagens de arquivos PDF. Aqui estão algumas das principais características:
Geração de PDF a partir de HTML
O IronPDF pode converter facilmente arquivos HTML, strings HTML e URLs em documentos PDF. Utilize o renderizador de PDF do Chrome para renderizar páginas da web diretamente em formato PDF.
Compatibilidade entre plataformas
O IronPDF é compatível com Python 3+ e funciona perfeitamente em plataformas Windows, Mac, Linux e na nuvem. Também é compatível com .NET , Java , Python e Node.js
Recursos de edição e assinatura
Aprimore documentos PDF definindo propriedades, adicionando recursos de segurança como senhas e permissões e aplicando assinaturas digitais .
Modelos e configurações de páginas personalizadas
Com o IronPDF, você pode personalizar PDFs com cabeçalhos, rodapés , números de página e margens ajustáveis. Suporta layouts responsivos e permite definir tamanhos de papel personalizados.
Conformidade com as normas
O IronPDF é compatível com os padrões PDF, incluindo PDF/A e PDF/UA. Ele suporta a codificação de caracteres UTF-8 e lida perfeitamente com recursos como imagens, estilos CSS e fontes.
Gere documentos PDF usando IronPDF e PyArrow
Pré-requisitos do IronPDF
- O IronPDF utiliza o .NET 6.0 como tecnologia subjacente. Portanto, você precisa ter o runtime do .NET 6.0 instalado em seu sistema.
- Python 3.0+: Você precisa ter o Python versão 3 ou posterior instalado.
- pip: Instale o instalador de pacotes Python pip para a instalação do pacote IronPDF .
Instale as bibliotecas necessárias:
pip install pyarrow ironpdf
Em seguida, adicione o código abaixo para demonstrar o uso dos pacotes Python IronPDF e PyArrow:
import pandas as pd
import pyarrow as pa
from ironpdf import *
# Apply your license key
License.LicenseKey = "license"
# Create a Pandas DataFrame
df = pd.DataFrame({
'col1': [1, 2, 3],
'col2': ['a', 'b', 'c'],
'col3': [1.1, 2.2, 3.3]
})
# Convert the DataFrame to a PyArrow Table
table = pa.Table.from_pandas(df)
# Display the table
print(table)
#create a PDF renderer
renderer = ChromePdfRenderer()
# Create a PDF from an HTML string using Python
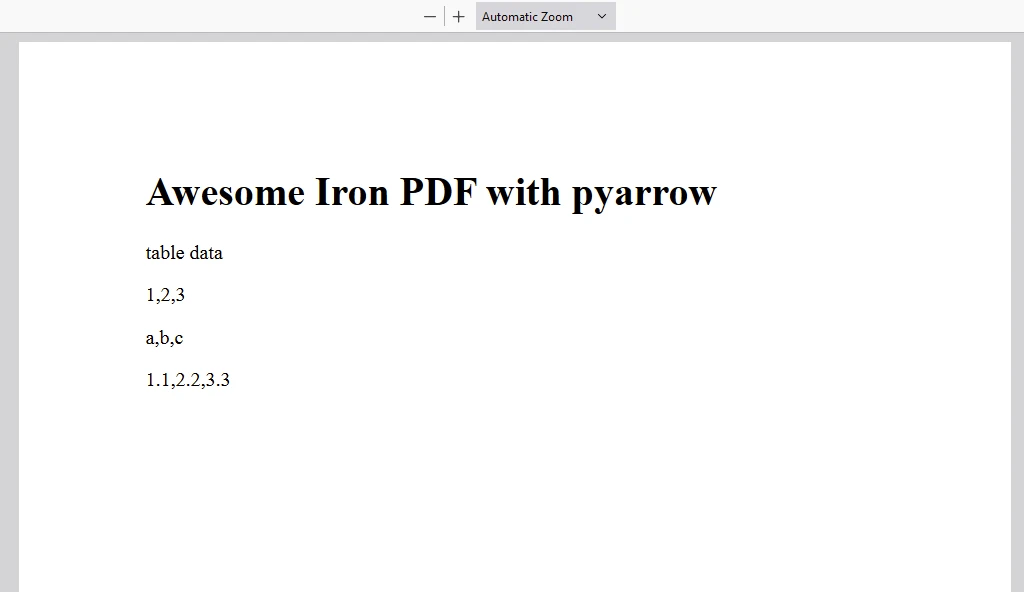
content = "<h1>Awesome Iron PDF with pyarrow</h1>"
content += "<p>table data</p>"
# Iterate over table rows
for row in table:
# Access specific values in a row
value_in_column1 = row[0]
value_in_column2 = row[1]
value_in_column3 = row[2]
# Append row data to content
content += "<p>"+str(value_in_column1)+","+str(value_in_column2)+","+str(value_in_column3)+"</p>"
# Render the HTML content to a PDF
pdf = renderer.RenderHtmlAsPdf(content)
# Export to a file or stream
pdf.SaveAs("DemoPyarrow.pdf")import pandas as pd
import pyarrow as pa
from ironpdf import *
# Apply your license key
License.LicenseKey = "license"
# Create a Pandas DataFrame
df = pd.DataFrame({
'col1': [1, 2, 3],
'col2': ['a', 'b', 'c'],
'col3': [1.1, 2.2, 3.3]
})
# Convert the DataFrame to a PyArrow Table
table = pa.Table.from_pandas(df)
# Display the table
print(table)
#create a PDF renderer
renderer = ChromePdfRenderer()
# Create a PDF from an HTML string using Python
content = "<h1>Awesome Iron PDF with pyarrow</h1>"
content += "<p>table data</p>"
# Iterate over table rows
for row in table:
# Access specific values in a row
value_in_column1 = row[0]
value_in_column2 = row[1]
value_in_column3 = row[2]
# Append row data to content
content += "<p>"+str(value_in_column1)+","+str(value_in_column2)+","+str(value_in_column3)+"</p>"
# Render the HTML content to a PDF
pdf = renderer.RenderHtmlAsPdf(content)
# Export to a file or stream
pdf.SaveAs("DemoPyarrow.pdf")Explicação do código
O script demonstra a integração das bibliotecas Pandas, PyArrow e IronPDF para criar um documento PDF a partir de dados armazenados em um DataFrame do Pandas:
-
Criação do Pandas DataFrame:
- Crie um DataFrame do Pandas (
df) com três colunas (col1,col2,col3) contendo dados numéricos e strings.
- Crie um DataFrame do Pandas (
-
Conversão para Tabela PyArrow:
- Converte o DataFrame do Pandas (
df) em uma Tabela PyArrow (table) usando o métodopa.Table.from_pandas(). Essa conversão facilita o gerenciamento eficiente de dados e a interoperabilidade com aplicativos baseados em Arrow.
- Converte o DataFrame do Pandas (
-
Geração de PDF com IronPDF:
- Usa o ChromePdfRenderer do IronPDF e chama seu método RenderHtmlAsPdf para gerar um documento PDF (
DemoPyarrow.pdf) a partir de uma string HTML (content), que inclui cabeçalhos e dados extraídos da Tabela PyArrow (table).
- Usa o ChromePdfRenderer do IronPDF e chama seu método RenderHtmlAsPdf para gerar um documento PDF (
SAÍDA

PDF de saída
Licença IronPDF
Insira a chave de licença no início do script antes de usar o pacote IronPDF :
from ironpdf import *
# Apply your license key
License.LicenseKey = "key"from ironpdf import *
# Apply your license key
License.LicenseKey = "key"Conclusão
PyArrow é uma biblioteca versátil e poderosa que amplia as capacidades do Python para tarefas de processamento de dados. Seu formato de memória eficiente, recursos de interoperabilidade e integração com o Pandas o tornam uma ferramenta essencial para cientistas e engenheiros de dados. Seja trabalhando com grandes conjuntos de dados, realizando manipulações complexas de dados ou criando pipelines de processamento de dados, o PyArrow oferece o desempenho e a flexibilidade necessários para lidar com essas tarefas de forma eficaz. Por outro lado, o IronPDF é uma biblioteca Python robusta que simplifica a criação, manipulação e renderização de documentos PDF diretamente de aplicações Python. Ele se integra perfeitamente com as estruturas Python existentes, permitindo que os desenvolvedores gerem e personalizem PDFs dinamicamente. Em conjunto com os pacotes Python PyArrow e IronPDF , os usuários podem processar estruturas de dados com facilidade e arquivar os dados.
O IronPDF também fornece documentação completa para auxiliar os desenvolvedores a começarem a usar o programa, acompanhada de inúmeros exemplos de código que demonstram seus poderosos recursos. Para obter mais detalhes, visite as páginas de documentação e exemplos de código .
















