
pyarrow(开发人员如何使用)
PyArrow 是一个强大的库,它为 Apache Arrow 框架提供了一个 Python 接口。 Apache Arrow 是一个用于内存数据的跨语言开发平台。 它指定了一种标准化的语言无关的列状内存格式,用于高效分析操作的平面和层次数据,在现代硬件上进行优化。 PyArrow 基本上是实现为 Python 包的 Apache Arrow Python 绑定。 PyArrow 提供高效的数据交换和互操作性,不同的数据处理系统和编程语言之间。 在本文的后面部分,我们还将学习 IronPDF,由 Iron Software 开发的 PDF 生成库。
PyArrow 的关键特性
1.列式内存格式:
PyArrow 使用列状内存格式,这对于内存中的分析操作来说非常高效。 这种格式允许更好的 CPU 缓存利用率和矢量化操作,使其非常适合数据处理任务。 由于其列状特性,PyArrow 能够高效地读写到 Parquet 文件结构中。 2.互操作性: PyArrow 的主要优势之一是它能够促进不同编程语言和系统之间的数据交换,而无需序列化或反序列化。 这在多语言环境中尤其有用,如数据科学和机器学习领域。 3.与 Pandas 集成: PyArrow 可用作 Pandas 的后端,从而实现高效的数据操作和存储。 从 Pandas 2.0 开始,可以将数据存储在 Arrow 数组中而不是 NumPy 数组中,这可以提高性能,特别是在处理字符串数据时。 4.支持多种数据类型: PyArrow 支持多种数据类型,包括基本类型(整数、浮点数)、复杂类型(结构体、列表)和嵌套类型。这使其能够灵活地处理不同类型的数据。 5.零拷贝读取: PyArrow 允许零拷贝读取,这意味着可以从 Arrow 内存格式中读取数据而无需复制它。 这减少了内存开销并提高了性能。
安装
要安装 PyArrow,您可以使用 pip 或 conda:
pip install pyarrowpip install pyarrow或
conda install pyarrow -c conda-f或geconda install pyarrow -c conda-f或ge基本用法
我们使用 Visual Studio Code 作为代码编辑器。 首先创建一个新文件,pyarrowDemo.py。
这是一个使用 PyArrow 创建表格并执行一些基本操作的简单示例:
imp或t pyarrow as pa
imp或t pyarrow.dataset as pt
# Create a PyArrow table
data = [
pa.array([1, 2, 3]),
pa.array(['a', 'b', 'c']),
pa.array([1.1, 2.2, 3.3])
]
table = pa.Table.from_arrays(data, names=['col1', 'col2', 'col3'])
# Display the table
print(table)imp或t pyarrow as pa
imp或t pyarrow.dataset as pt
# Create a PyArrow table
data = [
pa.array([1, 2, 3]),
pa.array(['a', 'b', 'c']),
pa.array([1.1, 2.2, 3.3])
]
table = pa.Table.from_arrays(data, names=['col1', 'col2', 'col3'])
# Display the table
print(table)代码解释
Python 代码使用 PyArrow 从三个数组 (pa.array) 创建一个表 (pa.Table)。 然后打印出表格,显示名为 'col1'、'col2' 和 'col3' 的列,每个列包含对应的整数、字符串和浮点数数据。
输出

与 Pandas 的集成
PyArrow 可以与 Pandas 无缝集成,以增强性能,尤其是在处理大型数据集时。 以下是将 Pandas DataFrame 转换为 PyArrow 表的示例:
imp或t pandas as pd
imp或t pyarrow as pa
# Create a Pandas DataFrame
df = pd.DataFrame({
'col1': [1, 2, 3],
'col2': ['a', 'b', 'c'],
'col3': [1.1, 2.2, 3.3]
})
# Convert the DataFrame to a PyArrow Table
table = pa.Table.from_pandas(df)
# Display the table
print(table)imp或t pandas as pd
imp或t pyarrow as pa
# Create a Pandas DataFrame
df = pd.DataFrame({
'col1': [1, 2, 3],
'col2': ['a', 'b', 'c'],
'col3': [1.1, 2.2, 3.3]
})
# Convert the DataFrame to a PyArrow Table
table = pa.Table.from_pandas(df)
# Display the table
print(table)代码解释
Python 代码将 Pandas DataFrame 转换为 PyArrow 表格(pa.Table),然后打印该表格。 该 DataFrame 由三列组成(col3),分别包含整数、字符串和浮点数数据。
输出

高级功能
1. 文件格式
PyArrow 支持读写各种文件格式,如 Parquet 和 Feather。 这些格式经过优化,以提高性能,并广泛用于数据处理管道中。
2. 内存映射
PyArrow 支持内存映射文件访问,这允许在不将整个数据集加载到内存中的情况下高效读取和写入大型数据集。
3. 进程间通信
PyArrow 提供了进程间通信工具,使不同时进程之间的数据共享更加高效。
IronPDF 简介
IronPDF 是一个用于 Python 的库,可以轻松处理 PDF 文件,支持如创建、编辑和程序化操作 PDF 文档等任务。 它提供了从 HTML 生成 PDF、向现有 PDF 添加文字、图像和形状以及从 PDF 文件中 提取文字和图像 等功能。 以下是一些关键特性:
从 HTML 生成 PDF
IronPDF 可以轻松地将 HTML 文件、HTML 字符串和 URL 转换为 PDF 文档。 利用 Chrome PDF 渲染器直接将网页 渲染为 PDF 格式。
跨平台兼容性
IronPDF 兼容 Python 3+,并可无缝运行于 Windows、Mac、Linux 和云平台上。 它也支持 .NET、Java、Python 和 Node.js。
编辑和签名功能
通过设置属性、添加安全功能如 密码和权限、应用 数字签名 来增强 PDF 文档。
自定义页面模板和设置
使用 IronPDF 可以定制 PDF,添加可自定义的 页眉、页脚、页码,以及可调的边距。 它支持响应式布局,并允许设置自定义纸张大小。
标准合规
IronPDF 符合 PDF 标准,包括 PDF/A 和 PDF/UA。 它支持 UTF-8 字符编码,并可无缝处理诸如图像、CSS 样式和字体等资产。
使用 IronPDF 和 PyArrow 生成 PDF 文档
IronPDF 的先决条件
- IronPDF 使用 .NET 6.0 作为其底层技术。 因此,您需要在系统上安装 .NET 6.0 运行时。
- Python 3.0+: 您需要安装 Python 版本 3 或更高版本。
- pip: 安装 Python 包安装程序 pip 以便安装 IronPDF 包。
安装所需的库:
pip install pyarrow
pip install ironpdfpip install pyarrow
pip install ironpdf然后添加以下代码以演示 IronPDF 和 PyArrow Python 包的使用:
imp或t pandas as pd
imp或t pyarrow as pa
from ironpdf imp或t *
# Apply your license key
License.LicenseKey = "license"
# Create a Pandas DataFrame
df = pd.DataFrame({
'col1': [1, 2, 3],
'col2': ['a', 'b', 'c'],
'col3': [1.1, 2.2, 3.3]
})
# Convert the DataFrame to a PyArrow Table
table = pa.Table.from_pandas(df)
# Display the table
print(table)
#create a PDF renderer
renderer = ChromePdfRenderer()
# Create a PDF from an HTML string using Python
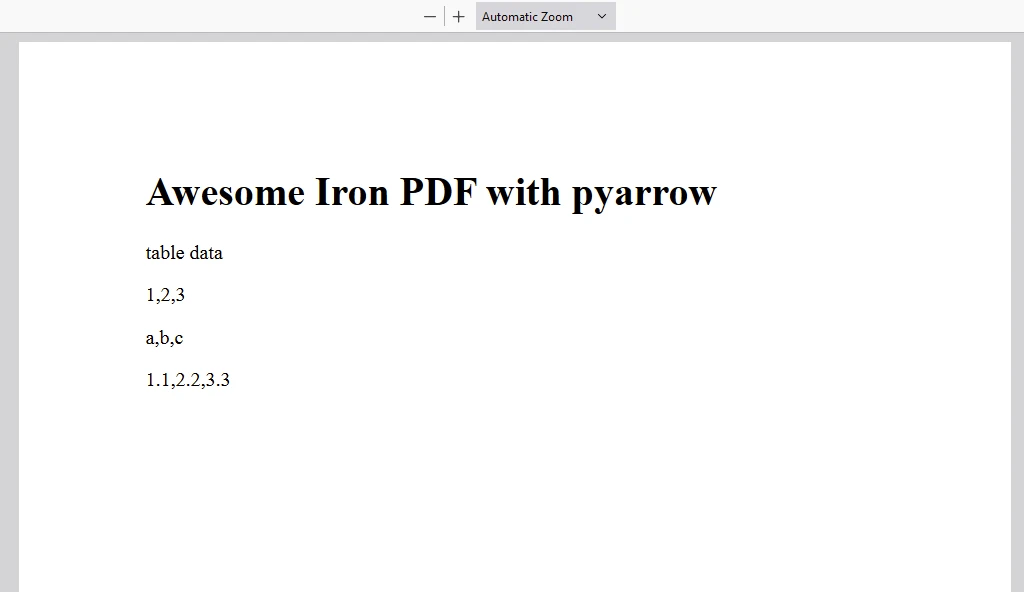
content = "<h1>Awesome Iron PDF with pyarrow</h1>"
content += "<p>table data</p>"
# Iterate over table rows
f或 row in table:
# Access specific values in a row
value_in_column1 = row[0]
value_in_column2 = row[1]
value_in_column3 = row[2]
# Append row data to content
content += "<p>"+str(value_in_column1)+","+str(value_in_column2)+","+str(value_in_column3)+"</p>"
# Render the HTML content to a PDF
pdf = renderer.RenderHtmlAsPdf(content)
# Exp或t to a file 或 stream
pdf.SaveAs("DemoPyarrow.pdf")imp或t pandas as pd
imp或t pyarrow as pa
from ironpdf imp或t *
# Apply your license key
License.LicenseKey = "license"
# Create a Pandas DataFrame
df = pd.DataFrame({
'col1': [1, 2, 3],
'col2': ['a', 'b', 'c'],
'col3': [1.1, 2.2, 3.3]
})
# Convert the DataFrame to a PyArrow Table
table = pa.Table.from_pandas(df)
# Display the table
print(table)
#create a PDF renderer
renderer = ChromePdfRenderer()
# Create a PDF from an HTML string using Python
content = "<h1>Awesome Iron PDF with pyarrow</h1>"
content += "<p>table data</p>"
# Iterate over table rows
f或 row in table:
# Access specific values in a row
value_in_column1 = row[0]
value_in_column2 = row[1]
value_in_column3 = row[2]
# Append row data to content
content += "<p>"+str(value_in_column1)+","+str(value_in_column2)+","+str(value_in_column3)+"</p>"
# Render the HTML content to a PDF
pdf = renderer.RenderHtmlAsPdf(content)
# Exp或t to a file 或 stream
pdf.SaveAs("DemoPyarrow.pdf")代码解释
该脚本展示了如何将 Pandas、PyArrow 和 IronPDF 库集成在一起,以便从储存在 Pandas DataFrame 中的数据创建 PDF 文档:
Pandas DataFrame 创建:
- 创建一个 Pandas DataFrame (
df),其中包含三列 (col1,col2,col3),这些列包含数值和字符串数据。
- 创建一个 Pandas DataFrame (
转换为 PyArrow 表:
- 使用
df方法将 Pandas DataFrame (table) 转换为 PyArrow Table (pa.Table.from_pandas())。 此转换方便了数据的高效处理和与基于 Arrow 的应用程序的互操作性。
- 使用
使用 IronPDF 生成 PDF:
- 使用 IronPDF 的ChromePdfRenderer并调用其RenderHtmlAsPdf方法,从 HTML 字符串 (
content) 生成 PDF 文档 (DemoPyarrow.pdf),其中包含从 PyArrow 表 (table) 提取的标题和数据。
- 使用 IronPDF 的ChromePdfRenderer并调用其RenderHtmlAsPdf方法,从 HTML 字符串 (
输出

输出 PDF
IronPDF 许可证
在使用IronPDF包之前,将许可证密钥放在脚本的开头:
from ironpdf imp或t *
# Apply your license key
License.LicenseKey = "key"from ironpdf imp或t *
# Apply your license key
License.LicenseKey = "key"结论
PyArrow 是一个功能强大、多功能的库,增强了 Python 在数据处理任务中的能力。 其高效的内存格式、互操作功能和与 Pandas 的集成使其成为数据科学家和工程师的必备工具。 无论是处理大型数据集、执行复杂的数据操作还是构建数据处理管道,PyArrow 都能够提供处理这些任务所需的性能和灵活性。 另一方面,IronPDF 是一个强大的 Python 库,简化了 PDF 文档的创建、操作和渲染,可以直接从 Python 应用程序中执行。 它可无缝集成到现有的 Python 框架中,允许开发人员动态生成和定制 PDF。 结合使用 PyArrow 和 IronPDF Python 包,用户能够轻松处理数据结构并归档数据。
IronPDF 还提供了全面的文档,以帮助开发人员快速入门,并附有展示其强大功能的众多代码示例。 有关更多详细信息,请访问 文档页面 和 代码示例页面。
















