
Jak czytać pliki PDF w Python
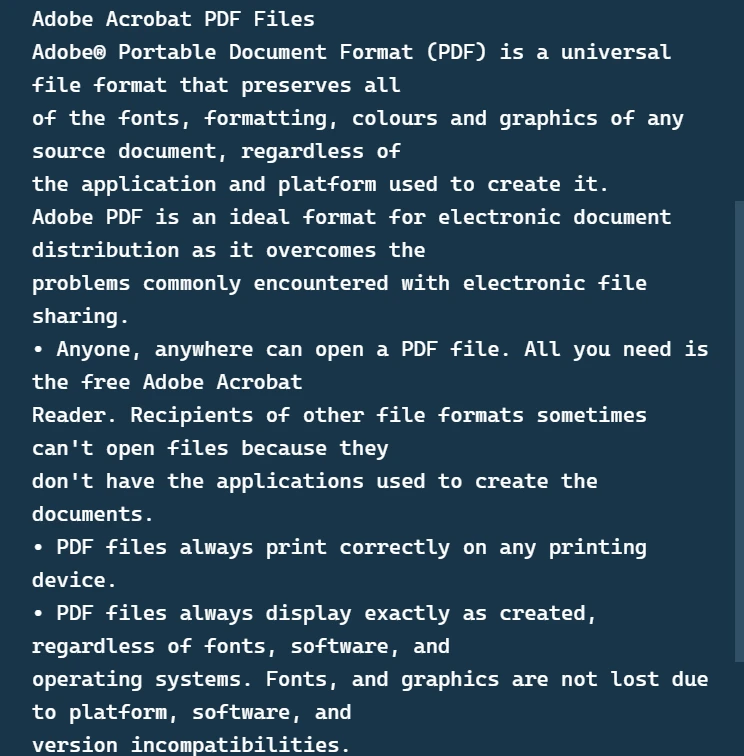
Pliki PDF, czyli pliki w formacie Portable Document Format, stały się uniwersalnym standardem udostępniania dokumentów. Są one szeroko stosowane ze względu na możliwość zachowania układu i formatowania dokumentu. Jednak praca z plikami PDF przy użyciu języków programowania, takich jak Python, może stanowić pewne wyzwanie. W tym artykule przedstawiamy IronPDF, bibliotekę PDF dla języka Python, która pozwala na wykonywanie różnych operacji na dokumentach PDF.
IronPDF for Python PDF Library
IronPDF to zaawansowana biblioteka Python do obsługi plików PDF, która ułatwia pracę z plikami w formacie PDF. Zapewnia łatwy w użyciu interfejs API do różnych operacji na plikach PDF. Możesz odczytywać i zapisywać pliki PDF, konwertować pliki PDF do różnych formatów, łączyć wiele plików PDF i wiele więcej. Może również obsługiwać obiekty stron, wyodrębniać tekst ze wszystkich stron pliku PDF oraz obracać strony PDF, a także oferować inne funkcje.
Jak odczytywać pliki PDF w języku Python
- Zainstaluj bibliotekę Python PDF Library za pomocą Pip.
- Zaimportuj bibliotekę PDF Python do skryptu w języku Python.
- Zastosuj klucz licencyjny biblioteki PDFReader dla języka Python.
- Załaduj dowolny dokument PDF, podając ścieżkę do dokumentu.
- Odczytuj zawartość plików PDF w konsoli Python.
Odczyt pliku PDF za pomocą IronPDF
Odczytanie pliku PDF za pomocą IronPDF wymaga wykonania kilku kroków. Oto prosty przewodnik, który pomoże Ci zacząć:
Krok 1 Utwórz środowisko wirtualne w Visual Studio
Podczas pracy z Pythonem kluczowe znaczenie ma utworzenie izolowanego środowiska, znanego jako środowisko wirtualne. Srodowisko pozwala zarządzać zależnościami specyficznymi dla projektu, nad którym pracujesz, bez ingerowania w inne projekty. Tworzenie środowiska wirtualnego staje się jeszcze prostsze w zintegrowanym środowisku programistycznym (IDE), takim jak Visual Studio Code. Aby to zrobić, wykonaj poniższe kroki:
Otwórz folder w Visual Studio Code. Naciśnij Ctrl+Shift+P, aby otworzyć paletę poleceń. W palecie poleceń wyszukaj "Python: Utwórz Srodowisko".

Wybierz pierwszą opcję, a następnie wybierz "Venv" jako typ środowiska.

Następnie wybierz interpreter języka Python, a rozpocznie się tworzenie środowiska wirtualnego.

Teraz masz już przygotowane izolowane środowisko pracy dla swoich skryptów w języku Python, co gwarantuje, że zależności projektu są ograniczone do tego środowiska.
![]()
Krok 2 Zainstaluj bibliotekę IronPDF for Python
Po skonfigurowaniu środowiska wirtualnego możesz zainstalować bibliotekę IronPDF for Python. Można go zainstalować za pomocą instalatora pakietów Python "pip":
pip install ironpdfpip install ironpdfKrok 3 Zainstaluj .NET 6.0
IronPDF for Python wymaga zainstalowania zestawu SDK .NET 6.0.
Pobierz i zainstaluj zestaw SDK .NET 6.0 ze strony internetowej Microsoft .NET.
Krok 4 Importuj IronPDF
Po pomyślnym zainstalowaniu IronPDF następnym krokiem jest zaimportowanie go do skryptu w języku Python. Importowanie biblioteki udostępnia wszystkie jej funkcje i metody do wykorzystania w skrypcie. Możesz zaimportować IronPDF za pomocą następującego wiersza kodu:
from ironpdf import *from ironpdf import *Ta linia kodu importuje do skryptu wszystkie moduły, funkcje i klasy dostępne w bibliotece IronPDF.
Krok 5 Zastosuj klucz licencyjny
Aby w pełni wykorzystać możliwości biblioteki IronPDF, należy zastosować klucz licencyjny. Zastosowanie klucza licencyjnego jest tak proste, jak przypisanie klucza do właściwości LicenseKey klasy License. Oto jak to zrobić:
License.LicenseKey = "License-Key-Here"License.LicenseKey = "License-Key-Here"Zastąp "License-Key-Here" swoim rzeczywistym kluczem licencyjnym IronPDF. Po wprowadzeniu klucza licencyjnego możesz w pełni wykorzystać potencjał biblioteki IronPDF w swoich skryptach w języku Python.
Krok 6 Ustaw ścieżkę dziennika
Następnie skonfiguruj rejestrowanie operacji IronPDF. Ustawiając niestandardową ścieżkę logów, możesz przechowywać logi uruchomieniowe generowane przez bibliotekę, co pomoże Ci debugować i diagnozować problemy, które mogą wystąpić podczas wykonywania. Oto jak to skonfigurować:
# Enable debugging mode for detailed logs
Logger.EnableDebugging = True
# Set the path for the log file
Logger.LogFilePath = "Custom.log"
# Set logging mode to capture all log types
Logger.LoggingMode = Logger.LoggingModes.All# Enable debugging mode for detailed logs
Logger.EnableDebugging = True
# Set the path for the log file
Logger.LogFilePath = "Custom.log"
# Set logging mode to capture all log types
Logger.LoggingMode = Logger.LoggingModes.AllW tym fragmencie kodu Logger.EnableDebugging = True włącza debugowanie, Logger.LogFilePath = "Custom.log" ustawia plik dziennika wyjściowego na "Custom.log", a Logger.LoggingMode = Logger.LoggingModes.All zapewnia, że rejestrowane są wszystkie rodzaje informacji dziennika.
Krok 7 Załaduj dokument PDF
Wczytanie dokumentu PDF za pomocą IronPDF jest tak proste, jak wywołanie metody. Metoda PdfDocument.FromFile ładuje dokument PDF z podanej ścieżki do obiektu pliku PDF. Wystarczy podać ścieżkę do pliku PDF w postaci ciągu znaków:
pdf = PdfDocument.FromFile("PDF B.pdf")pdf = PdfDocument.FromFile("PDF B.pdf")W tym kodzie pdf staje się obiektem PdfDocument reprezentującym określony plik PDF.
Krok 8 Przeczytaj zawartość pliku PDF
IronPDF udostępnia metodę o nazwie ExtractAllText(), która pomaga w wyodrębnianiu treści tekstowej z dokumentu PDF. Jest to szczególnie przydatne, gdy trzeba przeczytać i przeanalizować zawartość pliku PDF:
all_text = pdf.ExtractAllText() # Extracts all text from the PDF document
print(all_text) # Prints the extracted text to the consoleall_text = pdf.ExtractAllText() # Extracts all text from the PDF document
print(all_text) # Prints the extracted text to the consoleW tym przykładzie all_text będzie zawierać cały tekst pliku PDF z obiektu pdf. Będziesz mógł czytać zawartość plików PDF w konsoli.
Krok 9 Załaduj drugi plik PDF
Tak samo jak załadowałeś pierwszy dokument PDF, możesz również załadować drugi dokument PDF. Ta funkcja jest przydatna, gdy chcesz edytować wiele plików PDF:
pdf_2 = PdfDocument.FromFile("PDF A.pdf")pdf_2 = PdfDocument.FromFile("PDF A.pdf")W tym kodzie pdf_2 jest kolejnym obiektem PdfDocument reprezentującym drugi plik PDF.
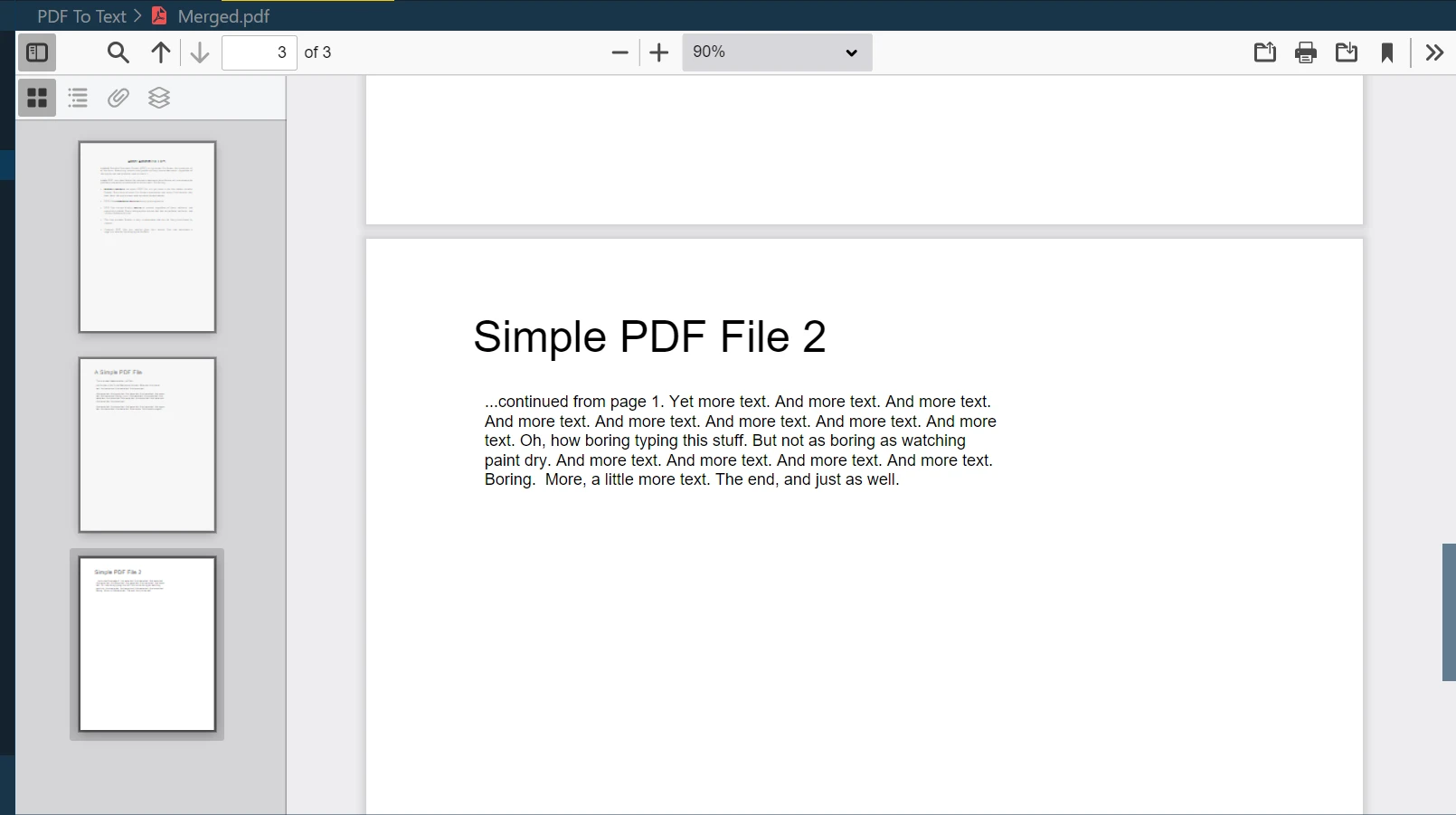
Krok 10: Połącz oba pliki
Jedną z potężnych funkcji IronPDF jest scalanie wielu plików PDF w jeden nowy plik PDF. Możesz łatwo połączyć dwa lub więcej dokumentów PDF, używając metody PdfDocument.Merge:
merged = PdfDocument.Merge(pdf, pdf_2) # Merges pdf and pdf_2 documents
merged.SaveAs("Merged.pdf") # Saves the merged document as 'Merged.pdf'merged = PdfDocument.Merge(pdf, pdf_2) # Merges pdf and pdf_2 documents
merged.SaveAs("Merged.pdf") # Saves the merged document as 'Merged.pdf'W tym przykładzie merged jest nowym obiektem PdfDocument, który powstał w wyniku połączenia pdf i pdf_2. Następnie metoda SaveAs zapisuje ten scalony dokument pod nazwą "Merged.PDF".
Krok 11 Podziel pierwszy plik PDF
IronPDF umożliwia również dzielenie dokumentów PDF i wyodrębnianie określonych stron do nowych plików PDF. Odbywa się to przy użyciu metody CopyPage:
page1doc = pdf.CopyPage(0) # Copies the first page of the pdf document
page1doc.SaveAs("Split1.pdf") # Saves the copied page as a new document 'Split1.pdf'page1doc = pdf.CopyPage(0) # Copies the first page of the pdf document
page1doc.SaveAs("Split1.pdf") # Saves the copied page as a new document 'Split1.pdf'W tym przypadku page1doc jest nowym obiektem PdfDocument, który zawiera pierwszą stronę dokumentu pdf. Strona ta jest następnie zapisywana jako plik PDF o nazwie "Split1.pdf".

Krok 12 Zastosuj znak wodny
Znak wodny to kolejna imponująca funkcja oferowana przez IronPDF. Możesz dodać do dokumentu PDF znak wodny z wybranym tekstem lub obrazem. Metoda ApplyWatermark służy do dodania znaku wodnego do pliku PDF reprezentowanego przez obiekt pdf.
pdf.ApplyWatermark("<h2 style='color:red'>SAMPLE</h2>", 30, VerticalAlignment.Middle, HorizontalAlignment.Center)
pdf.SaveAs("Watermarked.pdf")pdf.ApplyWatermark("<h2 style='color:red'>SAMPLE</h2>", 30, VerticalAlignment.Middle, HorizontalAlignment.Center)
pdf.SaveAs("Watermarked.pdf")W tym fragmencie ApplyWatermark nakłada czerwony znak wodny z tekstem "SAMPLE" na środek pliku PDF. Następnie SaveAs zapisuje dokument z znakiem wodnym jako "Watermarked.PDF".
Zgodność z IronPDF
IronPDF to wszechstronna biblioteka Python kompatybilna z szeroką gamą wersji języka Python. Obsługuje wszystkie nowoczesne wersje Pythona, począwszy od Python 3.6. IronPDF nie jest ograniczony do jednego systemu operacyjnego. Jest niezależny od platformy, dzięki czemu może być używany w różnych systemach operacyjnych. Niezależnie od tego, czy korzystasz z systemu Windows, Mac czy Linux, IronPDF działa płynnie na wszystkich tych platformach. Ta kompatybilność między platformami to ogromna zaleta, dzięki której IronPDF jest najczęściej wybieranym rozwiązaniem przez programistów, niezależnie od preferowanego systemu operacyjnego.
Wnioski
Podsumowując, IronPDF to doskonała biblioteka języka Python, która ułatwia pracę z dokumentami PDF. Niezależnie od tego, czy chcesz połączyć wiele plików PDF, wyodrębnić tekst, podzielić pliki PDF czy dodać znaki wodne, IronPDF spełni Twoje oczekiwania. Kompatybilność z wieloma platformami oraz łatwość obsługi sprawiają, że jest to cenne narzędzie dla każdego programisty pracującego z dokumentami PDF.
IronPDF oferuje bezpłatną wersję próbną. Ten okres próbny daje Ci mnóstwo okazji do wypróbowania jego funkcji i oceny, czy pasuje do Twoich konkretnych potrzeb. Po przetestowaniu produktu można zakupić licencję już od $799.
















