
Jak wyodrębnić obrazy z PDF w Python
W tym artykule wykorzystamy bibliotekę IronPDF for Python do wyodrębniania obrazów z pliku PDF za pomocą kodu w języku Python.
IronPDF for Python
IronPDF for Python to nowatorska i potężna biblioteka, która wnosi nowy wymiar do obsługi dokumentów PDF w Pythonie. Jako kompleksowe rozwiązanie do zadań związanych z plikami PDF, IronPDF umożliwia płynną integrację zaawansowanych funkcji PDF z aplikacjami.
IronPDF oferuje szeroki wybór narzędzi i interfejsów API do zadań takich jak tworzenie plików PDF od podstaw, konwersja HTML na wysokiej jakości pliki PDF oraz zarządzanie stronami PDF poprzez działania takie jak scalanie, dzielenie i edycja. Narzędzia te są przyjazne dla użytkownika i wydajne. Dzięki przyjaznemu dla użytkownika interfejsowi i obszernej dokumentacji IronPDF otwiera przed programistami nowe możliwości.
Niezależnie od tego, czy chodzi o tworzenie profesjonalnych raportów i faktur, automatyzację przepływu pracy czy zarządzanie dokumentami, IronPDF stanowi cenne wsparcie w zakresie zarządzania dokumentami i automatyzacji, co czyni go niezbędnym narzędziem dla każdego programisty pragnącego wykorzystać możliwości plików PDF w aplikacjach napisanych w języku Python.
Jak wyodrębnić obrazy z pliku PDF za pomocą IronPDF for Python
- Zainstaluj bibliotekę IronPDF, aby wyodrębnić obrazy z plików PDF w języku Python.
- Użyj metody
PdfDocument.FromFile, aby załadować plik PDF przy użyciu ścieżki do pliku z dysku lokalnego. - Zastosuj metodę
ExtractAllImages, aby wyodrębnić obrazy z plików PDF. - Użyj pętli, aby przejrzeć wszystkie wyodrębnione obrazy znalezione w pliku PDF.
- Zapisz te wyodrębnione obrazy z pliku PDF z wymaganym rozszerzeniem obrazu.
Wymagania wstępne
Zanim zagłębimy się w świat pozyskiwania obrazów z plików PDF przy użyciu języka Python, zainstalujmy niezbędne komponenty:
- Instalacja Pythona: Upewnij się, że masz zainstalowany interpreter Pythona w swoim systemie. Proces pozyskiwania obrazów z plików PDF będzie wymagał Python 3.0 lub nowszych wersji. Upewnij się, że masz zainstalowaną kompatybilną wersję języka Python.
Biblioteka IronPDF: Aby wykorzystać potężne możliwości IronPDF, musisz zainstalować go za pomocą
pip, menedżera pakietów Pythona. Wystarczy otworzyć interfejs wiersza poleceń i wykonać następujące polecenie:pip install ironpdfpip install ironpdfSHELL- Zintegrowane środowisko programistyczne (IDE): Chociaż nie jest to obowiązkowe, korzystanie z IDE może znacznie poprawić komfort pracy. Środowiska IDE oferują funkcje takie jak autouzupełnianie kodu, debugowanie oraz bardziej usprawniony przebieg pracy. Jednym z bardzo popularnych środowisk IDE do programowania w języku Python jest PyCharm. Możesz pobrać i zainstalować PyCharm ze strony internetowej JetBrains.
Po spełnieniu tych warunków możesz zapoznać się z przewodnikiem krok po kroku po ekscytującym świecie pobierania obrazów z plików PDF przy użyciu języka Python i biblioteki IronPDF.
Krok 1 Tworzenie nowego projektu w języku Python
Oto kroki, które należy wykonać, aby utworzyć nowy projekt w języku Python w PyCharm.
- Aby rozpocząć nowy projekt w języku Python w PyCharm, otwórz aplikację PyCharm i przejdź do górnego menu.
Kliknij Plik i wybierz Nowy projekt z menu rozwijanego.
 Środowisko IDE PyCharm
Środowisko IDE PyCharm- Po kliknięciu przycisku Nowy projekt pojawi się nowe okno z tytułem Utwórz projekt.
W tym oknie wpisz nazwę projektu w polu Lokalizacja u góry. Wybierz środowisko; Jeśli korzystasz ze środowiska wirtualnego, wybierz je spośród podanych opcji.
 Utwórz nowy projekt w języku Python w PyCharm
Utwórz nowy projekt w języku Python w PyCharm- Po wybraniu środowiska kliknij przycisk Utwórz, aby utworzyć projekt w języku Python.
Twój projekt w języku Python został utworzony i jest gotowy do wykorzystania w różnych zadaniach, takich jak pobieranie obrazów.
Krok 2 Instalacja IronPDF
Aby zainstalować IronPDF, otwórz terminal lub osobny wiersz poleceń i wpisz polecenie pip install ironpdf, a następnie naciśnij klawisz Enter. Terminal wyświetli następujący wynik.
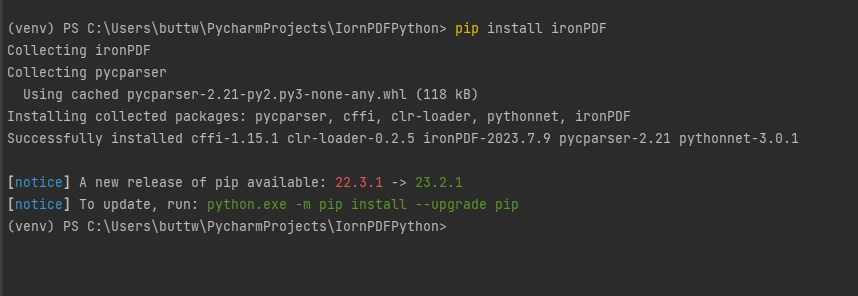 Zainstaluj pakiet IronPDF
Zainstaluj pakiet IronPDF
Krok 3 Wyodrębnianie obrazów z plików PDF za pomocą IronPDF
IronPDF zapewnia programistom narzędzia i interfejsy API do przeglądania plików PDF oraz płynnego identyfikowania i wyodrębniania osadzonych obrazów. Niezależnie od tego, czy chodzi o analizę, czy integrację, IronPDF usprawnia proces wyodrębniania danych dzięki elastyczności języka Python. To sprawia, że jest niezbędne do pracy z plikami PDF i aplikacjami opartymi na obrazach. Może wyodrębnić wszystkie obrazy z pliku PDF, co jest niezwykle proste i wymaga zaledwie kilku linii kodu.
Zobacz poniższy kod, aby wyodrębnić obrazy z pliku PDF przy użyciu języka programowania Python.
from ironpdf import PdfDocument
# Open PDF file
pdf = PdfDocument.FromFile("FYP Thesis.pdf")
# Get all images found in the PDF Document
all_images = pdf.ExtractAllImages()
# Save each image to the local disk with a dynamic name
for i, image in enumerate(all_images):
image.SaveAs(f"output_image_{i}.png")from ironpdf import PdfDocument
# Open PDF file
pdf = PdfDocument.FromFile("FYP Thesis.pdf")
# Get all images found in the PDF Document
all_images = pdf.ExtractAllImages()
# Save each image to the local disk with a dynamic name
for i, image in enumerate(all_images):
image.SaveAs(f"output_image_{i}.png")Ten kod najpierw importuje bibliotekę IronPDF, a następnie ładuje plik PDF z lokalnej przestrzeni, używając ścieżki pliku za pomocą metody PdfDocument.FromFile. Uzyskuje dostęp do każdej strony pliku PDF w celu wyodrębnienia bajtów obrazu jako obiektów Image. Te obiekty graficzne ze stron PDF są następnie zapisywane przy użyciu metody SaveAs. Kod przypisuje dynamiczne nazwy obrazów na podstawie indeksów obrazów i pożądanego rozszerzenia pliku obrazu, którym w tym przykładzie jest PNG.
Takie podejście jest prostsze niż korzystanie z innych bibliotek Pythona, takich jak PyMuPDF i Pillow, które wymagają więcej kodu, aby wykonać to samo zadanie, czyli wyodrębnienie i zapisanie plików graficznych.
Krok 4 Zapisz obrazy z pliku PDF
Obrazy są wyodrębniane ze wszystkich stron pliku PDF i zapisywane w formacie PNG. Masz również możliwość modyfikacji formatu wyjściowego poprzez dostosowanie rozszerzenia pliku do żądanych formatów plików graficznych.
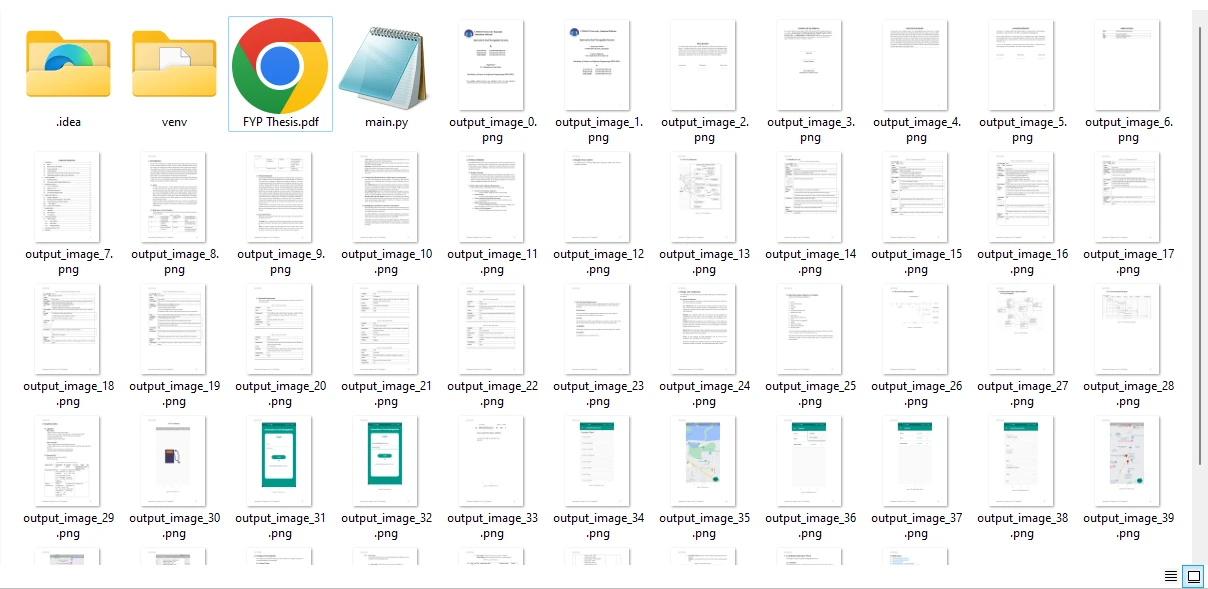 Obrazy wyodrębnione z przykładowego pliku PDF
Obrazy wyodrębnione z przykładowego pliku PDF
Wnioski
Python w połączeniu z potężnym IronPDF oferuje wszechstronne i wydajne rozwiązanie do pobierania obrazów z plików PDF. Wykorzystując elastyczność języka Python i możliwości IronPDF, programiści mogą płynnie poruszać się po dokumentach PDF, lokalizować w nich bajty obrazów i zapisywać te obrazy z żądanym rozszerzeniem. Proces obejmuje pozyskiwanie obrazów z pliku PDF, a uzyskana lista obrazów może być dalej przetwarzana i modyfikowana w razie potrzeby. Opanowując sztukę pozyskiwania obrazów z plików PDF przy użyciu języka Python, programiści mogą usprawnić swoje procesy pracy, zautomatyzować zarządzanie dokumentami oraz odkrywać szeroki wachlarz aplikacji opartych na obrazach, co sprawia, że jest to cenna umiejętność w erze cyfrowej.
Aby zapoznać się z dodatkowymi funkcjami dotyczącymi wyodrębniania obrazów z plików PDF, zapoznaj się z poniższym przykładem. Możesz zapoznać się z innymi operacjami, takimi jak konwersja zawartości plików PDF na obrazy; Pełny samouczek jest dostępny w tym artykule instruktażowym dotyczącym języka Python.
Często Zadawane Pytania
Jak wyodrębnić obrazy z pliku PDF za pomocą języka Python?
Można wyodrębnić obrazy z pliku PDF za pomocą IronPDF for Python, wykorzystując metodę PdfDocument.FromFile do załadowania pliku PDF oraz metodę ExtractAllImages do wyodrębnienia obrazów.
Jakie kroki należy wykonać, aby zapisać wyodrębnione obrazy z pliku PDF przy użyciu języka Python?
Aby zapisać wyodrębnione obrazy, należy przejrzeć wszystkie obrazy i użyć metody SaveAs, aby zapisać każdy obraz z określonym rozszerzeniem pliku, np. PNG.
Dlaczego warto wybrać IronPDF do wyodrębniania obrazów z plików PDF w języku Python?
IronPDF upraszcza proces wyodrębniania obrazów w porównaniu z innymi bibliotekami, takimi jak PyMuPDF i Pillow, zmniejszając ilość kodu potrzebnego do osiągnięcia podobnych rezultatów.
Jakie są wymagania dotyczące korzystania z IronPDF w języku Python do obsługi plików PDF?
Wymagana jest wersja Python 3.0 lub nowsza oraz instalacja biblioteki IronPDF za pomocą pip. Do programowania warto również używać środowiska IDE, takiego jak PyCharm.
Jak zainstalować IronPDF for Python?
IronPDF można zainstalować za pomocą menedżera pakietów pip. Uruchom polecenie pip install IronPDF w interfejsie wiersza poleceń.
Czy IronPDF może być używany do automatyzacji zarządzania dokumentami PDF w języku Python?
Tak, IronPDF umożliwia automatyzację zadań związanych z zarządzaniem dokumentami, takich jak wyodrębnianie obrazów i konwersja treści plików PDF, co zwiększa wydajność przepływu pracy.
Jakie formaty obrazów obsługuje IronPDF do zapisywania wyodrębnionych obrazów?
Wyodrębnione obrazy można zapisać w formatach takich jak PNG, określając żądane rozszerzenie pliku w metodzie SaveAs.
Czy IronPDF nadaje się do tworzenia aplikacji opartych na obrazach w języku Python?
IronPDF doskonale nadaje się do tworzenia aplikacji opartych na obrazach, ponieważ oferuje rozbudowane funkcje do wyodrębniania obrazów z dokumentów PDF i zarządzania nimi.
















