
Jak wyodrębnić tekst z pliku PDF w języku Python
W tym artykule pokażemy, jak wyodrębnić cały tekst z plików PDF przy użyciu IronPDF w języku Python, dostarczając wiedzę i fragmenty kodu w języku Python, które pozwolą efektywnie wykonać to zadanie.
Jak wyodrębnić tekst z pliku PDF w języku Python
- Pobierz moduł Python do wyodrębniania tekstu z plików PDF
- Użyj metody
FromFile,aby zaimportować plik PDF - Wyodrębnij tekst z zaimportowanego pliku PDF za pomocą metody
ExtractText - Wyodrębnij tekst z określonych stron za pomocą metody
ExtractTextFromPage - Wyświetl wyodrębniony tekst w konsoli lub w pliku tekstowym
IronPDF — biblioteka Python
IronPDF for Python to potężna biblioteka PDF dla języka Python, która pozwala programistom na wyodrębnianie tekstu z dokumentów PDF. Dzięki IronPDF można zautomatyzować proces wyodrębniania danych tekstowych z plików PDF, co ułatwia przetwarzanie i analizę informacji zawartych w dokumentach PDF.
IronPDF zapewnia programistom języka Python możliwość manipulowania plikami PDF, wyodrębniania z nich danych oraz interakcji z nimi przy użyciu języka Python, co ułatwia automatyzację różnych zadań związanych z plikami PDF. Niezależnie od tego, czy chcesz generować pliki PDF, modyfikować istniejące pliki PDF, wyodrębniać dane z treści, czy wykonywać inne operacje na plikach PDF, IronPDF upraszcza ten proces dzięki intuicyjnemu interfejsowi API i zaawansowanym możliwościom.
Najważniejsze cechy
Niektóre funkcje biblioteki IronPDF for Python obejmują:
- Utwórz nowy plik PDF od podstaw
- Edycja istniejących plików PDF
- Pobieranie tekstu, metadanych i obrazów z plików PDF
- Konwersja plików PDF do innych formatów
- Zabezpieczaj pliki PDF hasłami i ograniczeniami
- Dzielenie i łączenie plików PDF
Wymagania wstępne
Przed przystąpieniem do wyodrębniania tekstu za pomocą IronPDF upewnij się, że spełnione są następujące wymagania wstępne:
- Instalacja Pythona: Upewnij się, że masz zainstalowany Python w swoim systemie. IronPDF jest kompatybilny z wersjami Python 3.x, więc upewnij się, że masz zainstalowaną kompatybilną wersję Pythona.
Biblioteka IronPDF: Zainstaluj bibliotekę IronPDF za pomocą
pip, menedżera pakietów języka Python. Otwórz interfejs wiersza poleceń i wykonaj następujące polecenie:pip install ironpdfpip install ironpdfSHELLUwaga: Aby móc korzystać z poleceń pip, należy dodać Python do zmiennej środowiskowej PATH.
- Środowisko programistyczne (IDE): Chociaż nie jest to absolutnie konieczne, korzystanie z IDE może znacznie poprawić komfort pracy. Zapewnia takie funkcje, jak autouzupełnianie kodu, debugowanie oraz bardziej usprawniony przepływ pracy. Jednym z popularnych środowisk IDE do programowania w języku Python jest PyCharm. Możesz pobrać i zainstalować PyCharm ze strony internetowej JetBrains https://www.jetbrains.com/pycharm/.
- Edytor tekstu: Jeśli wolisz pracować z lekkim edytorem tekstu, możesz użyć dowolnego edytora, takiego jak Visual Studio Code, Sublime Text lub Atom. Edytory te oferują podświetlanie składni i inne przydatne funkcje do programowania w języku Python. Można również skorzystać z aplikacji IDLE, która jest częścią środowiska Python.
Tworzenie projektu w języku Python przy użyciu PyCharm
Po zainstalowaniu środowiska PyCharm IDE utwórz projekt PyCharm Python, wykonując poniższe kroki:
- Uruchom PyCharm: Otwórz PyCharm z poziomu meniu uruchamiania aplikacji lub skrótu na pulpicie.
Utwórz nowy projekt: Kliknij "Utwórz nowy projekt" lub otwórz istniejący projekt w języku Python.
 Środowisko IDE PyCharm
Środowisko IDE PyCharmSkonfiguruj ustawienia projektu: Nadaj nazwę projektowi i wybierz lokalizację, w której zostanie utworzony katalog projektu. Wybierz interpreter języka Python dla swojego projektu. Następnie kliknij "Utwórz".
 Utwórz nowy projekt w języku Python w Pycharm
Utwórz nowy projekt w języku Python w Pycharm- Utwórz pliki źródłowe: PyCharm utworzy strukturę projektu, w tym główny plik Python oraz katalog na dodatkowe pliki źródłowe. Zacznij pisać kod i kliknij przycisk uruchomienia lub naciśnij Shift+F10, aby wykonać skrypt.
Pobieranie tekstu z plików PDF w języku Python przy użyciu IronPDF
Przejdźmy teraz do omówienia kroków związanych z wyodrębnianiem zwykłego tekstu z plików PDF przy użyciu biblioteki IronPDF w języku programowania Python.
Zaimportuj wymagane biblioteki
Na początek zaimportuj niezbędne biblioteki do swojego skryptu w języku Python. W tym przypadku przykładowy kod musi zaimportować bibliotekę IronPDF, która zapewnia funkcjonalność do pracy z plikami PDF.
import ironpdfimport ironpdfUstaw klucz licencyjny
Aby wyodrębnić pełny tekst z pliku PDF za pomocą IronPDF, musisz posiadać licencję IronPDF. Zastosuj klucz licencyjny lub próbny za pomocą następującego polecenia:
# Apply your license key
License.LicenseKey = "YOUR-LICENSE-KEY-HERE"# Apply your license key
License.LicenseKey = "YOUR-LICENSE-KEY-HERE"Uwaga: Bez klucza licencyjnego wyodrębnianie danych przez IronPDF jest ograniczone do zaledwie kilku znaków z pliku rozszerzenia PDF. Klucz licencyjny można uzyskać, kupując IronPDF lub rejestrując się w celu skorzystania z bezpłatnej wersji próbnej.
Załaduj dokument PDF
Następnie załaduj plik PDF przy użyciu metody PdfDocument.FromFile() z biblioteki IronPDF. Jako argument tej metody podaj ścieżkę do pliku PDF. Spowoduje to załadowanie pliku PDF do obiektu PdfDocument.
pdf = ironpdf.PdfDocument.FromFile("path/to/your/pdf_file.pdf")pdf = ironpdf.PdfDocument.FromFile("path/to/your/pdf_file.pdf")Plik wejściowy
Aby wyodrębnić tekst z pliku PDF i wyświetlić go na ekranie, używa się następującego dokumentu:
 Plik wejściowy
Plik wejściowy
Wyodrębnianie tekstu z plików PDF
Po załadowaniu dokumentu PDF można wyodrębnić treść tekstową za pomocą metody ExtractText. Ta metoda zwraca wyodrębniony tekst jako ciąg znaków.
text = pdf.ExtractText()text = pdf.ExtractText()Przetwarzanie i wykorzystanie wyodrębnionego tekstu
Teraz, gdy wyodrębniłeś tekst z pliku PDF, możesz go przetwarzać i wykorzystywać zgodnie ze swoimi wymaganiami. Możesz wykonywać takie zadania, jak parsowanie tekstu, analizowanie go, przechowywanie w bazie danych lub wykorzystywanie do dalszego przetwarzania danych.
# Process and utilize the extracted text
print(text)
# Perform other operations with the extracted text# Process and utilize the extracted text
print(text)
# Perform other operations with the extracted textWynik
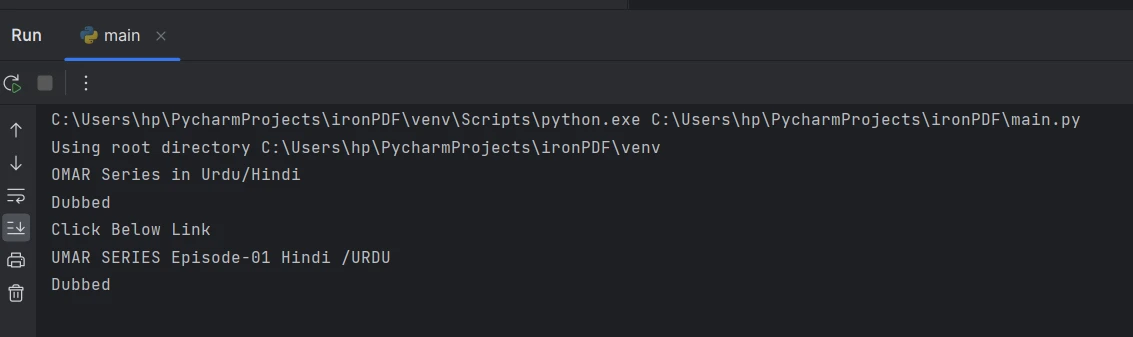 Tekst wyodrębniony z konsoli
Tekst wyodrębniony z konsoli
Wyodrębnij tekst z określonej strony w pliku PDF
IronPDF zapewnia również wygodną metodę wyodrębniania tekstu z określonych stron w pliku PDF. W tej sekcji omówimy, jak wyodrębnić tekst z określonej strony przy użyciu metody ExtractTextFromPage udostępnianej przez IronPDF.
Poniższy kod pokazuje, jak wyodrębnić tekst z określonej strony:
# Extract text from a specific page in the document
page_2_text = pdf.ExtractTextFromPage(1)# Extract text from a specific page in the document
page_2_text = pdf.ExtractTextFromPage(1)W powyższym przykładowym kodzie pdf reprezentuje obiekt PdfDocument uzyskany po załadowaniu dokumentu PDF. Metoda ExtractTextFromPage() służy do pobierania tekstu z określonej strony, wskazanej przez indeks strony przekazany jako argument. W tym przypadku tekst pochodzi z drugiej strony lub strony nr 2, co odpowiada indeksowi strony 1.
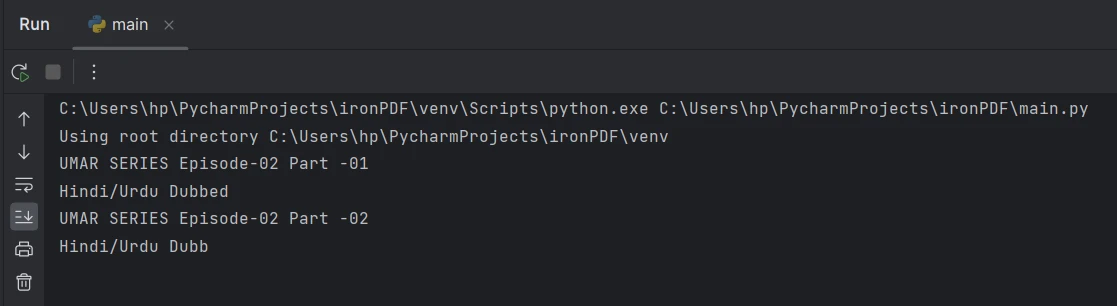 Wyodrębnij tekst ze strony 2
Wyodrębnij tekst ze strony 2
Wnioski
W tym artykule omówiono, jak wyodrębnić tekst z plików PDF przy użyciu IronPDF w języku Python. Obejmowało to niezbędne kroki, w tym importowanie wymaganej biblioteki, ładowanie dokumentu PDF, wyodrębnianie treści tekstowej oraz przetwarzanie wyodrębnionego tekstu.
Dzięki zaawansowanym funkcjom ekstrakcji tekstu w IronPDF możesz zautomatyzować pobieranie i dalsze przetwarzanie tekstu z plików PDF, co pozwala łatwo przetwarzać i analizować informacje tekstowe zawarte w dokumentach PDF. Intuicyjny interfejs API i szerokie możliwości sprawiają, że jest to idealny wybór do szerokiego zakresu zadań związanych z plikami PDF w programowaniu w języku Python.
IronPDF jest bezpłatny do celów programistycznych, ale do użytku komercyjnego wymaga licencji. Aby używać go w trybie produkcyjnym do testów, pobierz bezpłatną wersję próbną. Pobierz i zainstaluj najnowszą wersję IronPDF for Python i wypróbuj ją.
Często Zadawane Pytania
Jak wyodrębnić tekst z całego dokumentu PDF za pomocą języka Python?
Można wyodrębnić tekst z całego dokumentu PDF, używając metody PdfDocument.FromFile() biblioteki IronPDF do załadowania pliku PDF, a następnie wywołując metodę ExtractText(), aby pobrać treść tekstową.
Jak wygląda proces wyodrębniania tekstu z określonych stron pliku PDF w języku Python?
Aby wyodrębnić tekst z określonych stron pliku PDF, należy użyć metody ExtractTextFromPage() biblioteki IronPDF, która pozwala określić indeks strony w celu pobrania tekstu z tej konkretnej strony.
Jak zainstalować bibliotekę IronPDF for Python?
Zainstaluj bibliotekę IronPDF for Python za pomocą menedżera pakietów pip, uruchamiając polecenie: pip install ironpdf.
Jakie są warunki wstępne do wyodrębniania tekstu z plików PDF w języku Python?
Wymagania wstępne obejmują zainstalowanie języka Python w systemie, zainstalowanie IronPDF za pomocą pip oraz używanie środowiska IDE, takiego jak PyCharm, do programowania.
Czy dostępna jest bezpłatna wersja biblioteki IronPDF for Python?
IronPDF jest bezpłatny do celów programistycznych, ale do użytku komercyjnego potrzebna jest licencja. Dostępna jest bezpłatna wersja próbna, która pozwala przetestować bibliotekę w trybie produkcyjnym.
Czy potrzebuję licencji, aby wyodrębnić pełny tekst z plików PDF przy użyciu IronPDF?
Tak, do pełnego wyodrębniania tekstu z plików PDF za pomocą IronPDF wymagany jest klucz licencyjny. Bez licencji wyodrębnianie jest ograniczone do kilku znaków.
Jakie są kluczowe funkcje IronPDF for Python?
Kluczowe funkcje IronPDF for Python obejmują tworzenie i edycję plików PDF, wyodrębnianie tekstu, metadanych i obrazów, konwersję plików PDF do innych formatów oraz dodawanie zabezpieczeń, takich jak hasła.
Czy IronPDF for Python może pomóc w automatyzacji wyodrębniania danych z plików PDF?
Tak, IronPDF oferuje metody takie jak FromFile i ExtractText, które ułatwiają automatyzację ekstrakcji danych z plików PDF, wspomagając analizę i przetwarzanie danych.
Jakie środowisko IDE jest zalecane do korzystania z IronPDF w języku Python?
PyCharm jest zalecany do programowania w języku Python z wykorzystaniem IronPDF ze względu na takie funkcje, jak autouzupełnianie kodu, narzędzia do debugowania oraz usprawniony przebieg pracy.
W jaki sposób IronPDF usprawnia mój proces przetwarzania dokumentów PDF?
IronPDF usprawnia przepływ pracy, zapewniając intuicyjny interfejs API do wyodrębniania tekstu, tworzenia i edycji plików PDF, konwersji formatów oraz ustawień zabezpieczeń, usprawniając różne zadania związane z plikami PDF.
















