
Jak generować formularze PDF w Python
W tym artykule wykorzystamy IronPDF for Python do tworzenia prostych dokumentów PDF na podstawie szablonów.
IronPDF for Python
IronPDF to potężna biblioteka języka Python, która rewolucjonizuje sposób, w jaki programiści pracują z dokumentami PDF. Zaprojektowany w celu uproszczenia tworzenia, edycji i manipulacji plikami PDF, IronPDF umożliwia programistom Pythona łatwą integrację zaawansowanych funkcji PDF z ich aplikacjami. Niezależnie od tego, czy chodzi o generowanie plików PDF od podstaw, konwersję treści HTML na wysokiej jakości pliki PDF, czy też scalanie, dzielenie i edycję istniejących plików PDF, kompleksowy zestaw narzędzi i interfejsów API IronPDF oferuje intuicyjne i wydajne rozwiązanie. Dzięki przyjaznemu dla użytkownika interfejsowi i obszernej dokumentacji IronPDF otwiera świat możliwości dla programistów pragnących w pełni wykorzystać potencjał plików PDF w swoich projektach w języku Python, co czyni go nieocenionym atutem w dziedzinie zarządzania dokumentami i automatyzacji.
Wymagania wstępne
Generowanie pliku PDF z szablonu w języku Python wymaga spełnienia następujących warunków wstępnych:
- Instalacja Pythona: Upewnij się, że masz zainstalowany Python w swoim systemie. Biblioteka IronPDF jest kompatybilna z Pythonem 3.0 lub nowszymi wersjami, więc upewnij się, że masz zainstalowaną odpowiednią wersję Pythona.
- .NET 6.0 SDK: Pakiet .NET 6.0 SDK jest niezbędny do korzystania z biblioteki IronPDF w języku Python. IronPDF jest oparty na platformie .NET Framework, która zapewnia podstawowe funkcje wymagane do generowania i edycji plików PDF. Dlatego też, aby korzystać z IronPDF w Pythonie, należy zainstalować .NET 6.0 SDK.
Biblioteka IronPDF: Aby zainstalować bibliotekę IronPDF, użyj
pip, menedżera pakietów języka Python. Otwórz interfejs wiersza poleceń i wykonaj następujące polecenie:pip install ironpdfpip install ironpdfSHELL- Zintegrowane środowisko programistyczne (IDE): Chociaż nie jest to absolutnie konieczne, korzystanie z IDE może znacznie poprawić komfort pracy programisty. Oferuje takie funkcje, jak autouzupełnianie kodu, debugowanie oraz bardziej usprawniony przebieg pracy. Jednym z popularnych środowisk IDE do programowania w języku Python jest PyCharm. Możesz pobrać i zainstalować PyCharm ze strony internetowej JetBrains pod adresem https://www.jetbrains.com/pycharm/.
Tworzenie nowego projektu w języku Python
Oto kroki, które należy wykonać, aby utworzyć nowy projekt w języku Python w PyCharm.
Aby utworzyć nowy projekt w języku Python, otwórz PyCharm, przejdź do "Plik" w górnym menu i kliknij "Nowy projekt".
 Środowisko IDE PyCharm
Środowisko IDE PyCharmPojawi się nowe okno, w którym można określić środowisko i lokalizację projektu. Po wybraniu środowiska kliknij przycisk Utwórz.
 Utwórz nowy projekt w języku Python w PyCharm
Utwórz nowy projekt w języku Python w PyCharm- W ten sposób ten przykładowy projekt w języku Python jest gotowy do użycia.
Instalacja IronPDF
Aby zainstalować IronPDF, wystarczy otworzyć terminal, uruchomić następujące polecenie pip install ironpdf i nacisnąć klawisz Enter. Wynik na terminalu powinien wyglądać następująco.
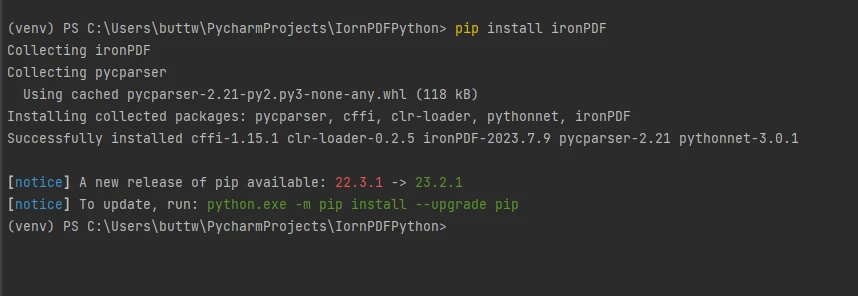 Zainstaluj pakiet IronPDF
Zainstaluj pakiet IronPDF
Generowanie plików PDF z szablonu przy użyciu IronPDF
W tej sekcji wyjaśniono, jak generować dokumenty PDF z szablonów HTML przy użyciu danych wejściowych z konsoli w celu tworzenia plików PDF.
Najpierw zaimportuj kilka zależności potrzebnych do tworzenia plików PDF.
# Import the required classes from the libraries
from ironpdf import ChromePdfRenderer
from jinja2 import Template# Import the required classes from the libraries
from ironpdf import ChromePdfRenderer
from jinja2 import TemplateNastępnie zadeklaruj renderer jako obiekt ChromePdfRenderer i użyj go do renderowania szablonów HTML.
# Create a renderer object to generate PDFs
renderer = ChromePdfRenderer()# Create a renderer object to generate PDFs
renderer = ChromePdfRenderer()Teraz utwórz szablon dokumentu HTML do wielokrotnego użytku w celu tworzenia plików PDF. Wystarczy utworzyć nową zmienną i wypełnić ją treścią HTML zawierającą symbole zastępcze.
# Define an HTML template with placeholders for dynamic data
html_template = """
<!DOCTYPE html>
<html>
<head>
<title>{{title}}</title>
</head>
<body>
<h1>{{title}}</h1>
<p>
Hello, {{name}}! This is a sample PDF generated from a template using IronPDF for Python.
</p>
<p>
Your age is {{ age }} and your occupation is {{ occupation }}.
</p>
</body>
</html>
"""# Define an HTML template with placeholders for dynamic data
html_template = """
<!DOCTYPE html>
<html>
<head>
<title>{{title}}</title>
</head>
<body>
<h1>{{title}}</h1>
<p>
Hello, {{name}}! This is a sample PDF generated from a template using IronPDF for Python.
</p>
<p>
Your age is {{ age }} and your occupation is {{ occupation }}.
</p>
</body>
</html>
"""Po przygotowaniu szablonu projektu napisz kod, który będzie pobierał dane od użytkownika i zapisywał je w słowniku.
# Gather input from the user
title = input("Enter the title: ")
name = input("Enter your name: ")
age = input("Enter your age: ")
occupation = input("Enter your occupation: ")
# Store the input data into a dictionary for rendering the template
data = {
"title": title,
"name": name,
"age": age,
"occupation": occupation
}# Gather input from the user
title = input("Enter the title: ")
name = input("Enter your name: ")
age = input("Enter your age: ")
occupation = input("Enter your occupation: ")
# Store the input data into a dictionary for rendering the template
data = {
"title": title,
"name": name,
"age": age,
"occupation": occupation
}Ponadto poniższy kod zintegruje dane z dokumentem szablonu i wyrenderuje szablony HTML przy użyciu utworzonego wcześniej obiektu IronPDF renderer. Na koniec zapisz plik PDF, korzystając z metody SaveAs.
# Create a Template object with the HTML structure
template = Template(html_template)
# Render the template with the user-provided data
html_content = template.render(**data)
# Generate the PDF from the rendered HTML content
pdf = renderer.RenderHtmlAsPdf(html_content)
# Save the generated PDF to a file
pdf.SaveAs("output.pdf")# Create a Template object with the HTML structure
template = Template(html_template)
# Render the template with the user-provided data
html_content = template.render(**data)
# Generate the PDF from the rendered HTML content
pdf = renderer.RenderHtmlAsPdf(html_content)
# Save the generated PDF to a file
pdf.SaveAs("output.pdf")W ten sposób kod do dynamicznego tworzenia plików PDF jest gotowy. Uruchommy kod, aby zobaczyć wynik.
Przykładowy wynik 1
Po uruchomieniu kodu program poprosi użytkownika o podanie następujących danych.
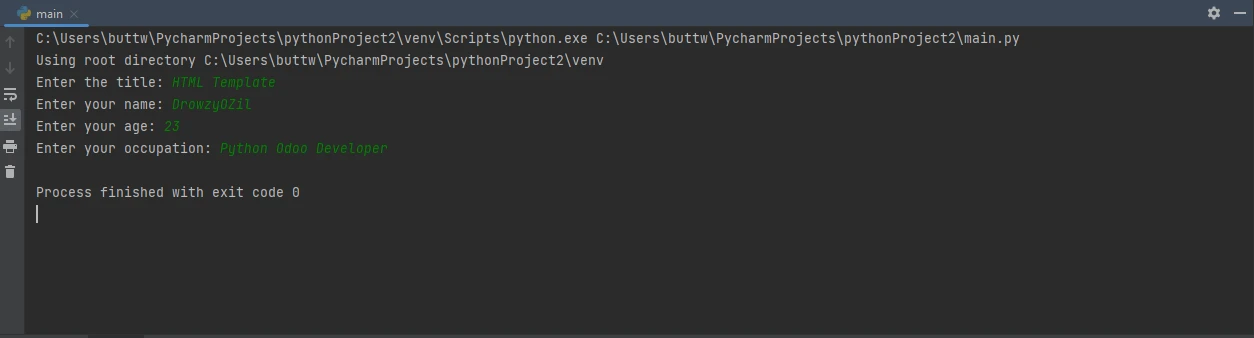 Konsola wymaga dodatkowych danych od użytkownika
Konsola wymaga dodatkowych danych od użytkownika
Wprowadź dane po kolei i po każdym wpisie naciśnij klawisz Enter. Po wprowadzeniu wszystkich czterech danych wejściowych zostanie wygenerowany plik PDF.
 Plik PDF wynikowy
Plik PDF wynikowy
Przykład tłumaczenia 2
Teraz uruchom ponownie program i wypróbuj różne dane wejściowe.
 Konsola z różnymi danymi wejściowymi
Konsola z różnymi danymi wejściowymi
Jak widać poniżej, format pliku wyjściowego jest taki sam, ale został zaktualizowany o nowe dane wejściowe.
 Nowy plik PDF
Nowy plik PDF
Aby uzyskać więcej informacji na temat tworzenia, modyfikowania i odczytywania plików PDF w języku Python przy użyciu IronPDF, odwiedź stronę dokumentacji.
Wnioski
W świecie programowania i automatyzacji dokumentów wykorzystanie przez Pythona biblioteki IronPDF do renderowania dokumentów PDF z szablonów zrewolucjonizowało zarządzanie dokumentami i wydajność przepływu pracy. To potężne połączenie umożliwia programistom łatwe tworzenie dostosowanych plików PDF, takich jak faktury, raporty i certyfikaty, zwiększając produktywność i poprawiając komfort użytkowania. Płynna integracja kompleksowych narzędzi i interfejsów API IronPDF z projektami w języku Python pozwala programistom z łatwością wykonywać zadania związane z generowaniem, edycją i przetwarzaniem plików PDF, usprawniając proces tworzenia oprogramowania i zapewniając spójne, dopracowane wyniki. Wszechstronność języka Python w połączeniu z możliwościami IronPDF sprawia, że ten dynamiczny duet jest nieodzownym atutem dla każdego programisty poszukującego wydajnych i zautomatyzowanych rozwiązań do obsługi dokumentów PDF. Dodatkowo można użyć tej samej techniki do tworzenia plików PDF z plików CSV, odpowiednio edytując kod w języku Python.
Jak można zauważyć, pliki wyjściowe są opatrzone znakiem wodnym. Można je łatwo usunąć, kupując licencję. Pakiet Lite obejmuje Licencję wieczystą, 30-dniową gwarancję zwrotu pieniędzy, roczną pomoc techniczną oraz możliwość aktualizacji. IronPDF oferuje również bezplatną licencję probną.
Często Zadawane Pytania
Jak wygenerować plik PDF z szablonu HTML przy użyciu biblioteki Python?
Możesz użyć ChromePdfRenderer firmy IronPDF do renderowania treści HTML do formatu PDF. Zdefiniuj szablon HTML z symbolami zastępczymi, zintegruj go z danymi dynamicznymi za pomocą Jinja2, a następnie wyrenderuj, aby wygenerować plik PDF.
Jakie są wymagania systemowe dotyczące korzystania z biblioteki PDF w języku Python?
Aby korzystać z IronPDF w języku Python, potrzebujesz Python 3.0 lub nowszego, zestawu SDK .NET 6.0 oraz biblioteki IronPDF, którą można zainstalować za pomocą pip.
Jak zainstalować IronPDF w moim środowisku Python?
Możesz zainstalować IronPDF, uruchamiając polecenie pip install ironpdf w interfejsie wiersza poleceń.
Jak rozpocząć nowy projekt w języku Python w PyCharm?
Aby utworzyć nowy projekt w języku Python w PyCharm, przejdź do „Plik” > „Nowy projekt”, określ srodowisko i lokalizację, a następnie kliknij „Utwórz”.
Czy mogę użyć biblioteki Python do konwersji danych CSV do pliku PDF?
Tak, można użyć IronPDF do odczytania danych CSV, włączenia ich do szablonu HTML, a następnie wyrenderowania jako plik PDF przy użyciu ChromePdfRenderer.
Jakie kroki trzeba wykonać, żeby stworzyć plik PDF z danych wejściowych w Pythonie?
Dzięki IronPDF zbierasz dane wejściowe od użytkowników, integrujesz je z szablonem HTML za pomocą Jinja2, renderujesz szablon za pomocą ChromePdfRenderer, a następnie zapisujesz wynikowy plik PDF.
Jak mogę usunąć znaki wodne z plików PDF utworzonych przez bibliotekę Python?
Aby usunąć znaki wodne z plików PDF wygenerowanych przez IronPDF, można zakupić licencję, która obejmuje Licencję wieczystą, 30-dniową gwarancję zwrotu pieniędzy, roczną pomoc techniczną oraz opcje aktualizacji.
Czy możliwe jest zautomatyzowanie przepływu dokumentów przy użyciu biblioteki PDF dla języka Python?
Tak, IronPDF może służyć do automatyzacji przepływu dokumentów, umożliwiając tworzenie, edycję i zarządzanie plikami PDF programowo w ramach aplikacji Python.
















