
Como gerar formulários PDF em Python
Este artigo utilizará o IronPDF for Python para criar documentos PDF simples a partir de modelos.
IronPDF for Python
IronPDF é uma poderosa biblioteca Python que revoluciona a forma como os desenvolvedores interagem com documentos PDF. Projetado para simplificar a criação, edição e manipulação de arquivos PDF, o IronPDF permite que programadores Python integrem funcionalidades sofisticadas de PDF em seus aplicativos sem esforço. Seja para gerar PDFs do zero, converter conteúdo HTML em PDFs de alta qualidade ou mesclar , dividir e editar PDFs existentes , o conjunto abrangente de ferramentas e APIs do IronPDF oferece uma solução intuitiva e eficiente. Com sua interface amigável e documentação abrangente, o IronPDF abre um mundo de possibilidades para desenvolvedores que buscam explorar todo o potencial dos PDFs em seus projetos Python, tornando-se um recurso inestimável na área de gerenciamento e automação de documentos.
Pré-requisitos
Para gerar um PDF a partir de um modelo em Python, é necessário atender aos seguintes pré-requisitos:
- Instalação do Python: Certifique-se de que o Python esteja instalado em seu sistema. A biblioteca IronPDF é compatível com o Python 3.0 ou versões superiores, portanto, certifique-se de ter uma instalação do Python compatível.
- SDK .NET 6.0: O SDK .NET 6.0 é um pré-requisito para utilizar a biblioteca IronPDF em Python. O IronPDF é construído sobre o .NET Framework, que fornece os recursos subjacentes necessários para a geração e manipulação de PDFs. Portanto, o SDK do .NET 6.0 deve ser instalado para usar o IronPDF em Python.
-
IronPDF Library: Para instalar a biblioteca IronPDF, use
pip, o gerenciador de pacotes Python. Abra a interface de linha de comando e execute o seguinte comando:pip install ironpdf
- Ambiente de Desenvolvimento Integrado (IDE): Embora não seja estritamente necessário, o uso de um IDE pode melhorar muito sua experiência de desenvolvimento. Oferece funcionalidades como preenchimento automático de código, depuração e um fluxo de trabalho mais simplificado. Uma IDE popular para desenvolvimento em Python é o PyCharm. Você pode baixar e instalar o PyCharm no site da JetBrains em https://www.jetbrains.com/pycharm/ .
Criando um novo projeto em Python
Aqui estão os passos para criar um novo projeto Python no PyCharm.
-
Para criar um novo projeto em Python, abra o PyCharm, vá em "Arquivo" no menu superior e clique em "Novo Projeto".
 IDE PyCharm
IDE PyCharm -
Uma nova janela será exibida, onde você poderá especificar o ambiente e a localização do projeto. Após selecionar o ambiente, clique no botão Criar .
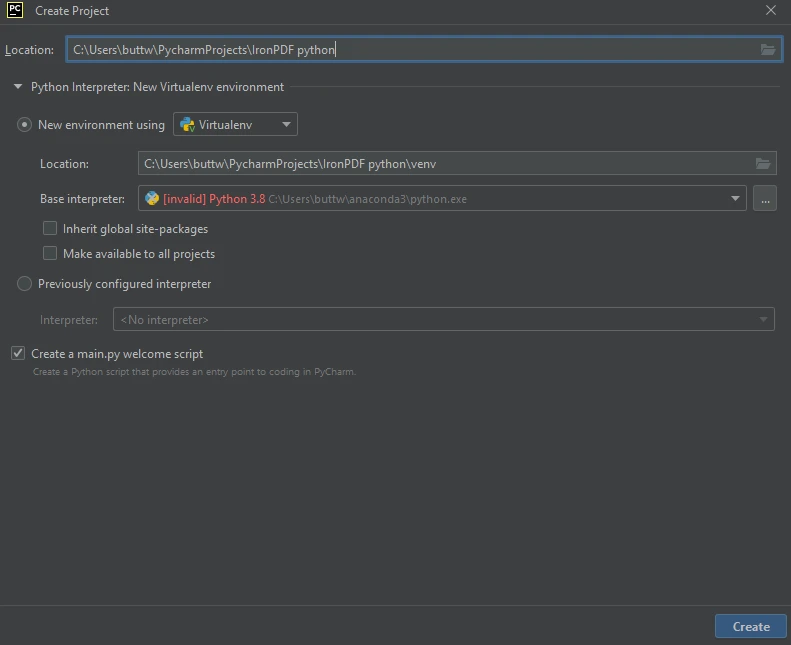 Crie um novo projeto Python no PyCharm.
Crie um novo projeto Python no PyCharm. - Assim, este projeto de demonstração em Python está criado e pronto para uso.
Instalando o IronPDF
Para instalar IronPDF, basta abrir o terminal e executar o seguinte comando pip install ironpdf e pressionar enter. A saída do terminal deve ser semelhante a esta.
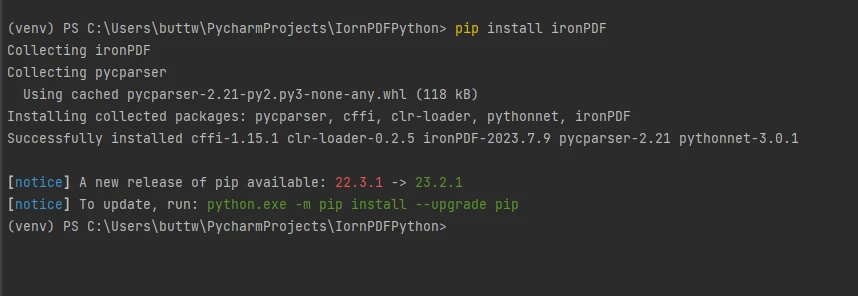 Instale o pacote IronPDF
Instale o pacote IronPDF
Gere arquivos PDF a partir de um modelo usando o IronPDF.
Esta seção explicará como gerar documentos PDF a partir de modelos HTML usando dados de entrada do console para criar arquivos PDF.
Primeiramente, importe algumas dependências para criar arquivos PDF.
# Import the required classes from the libraries
from ironpdf import ChromePdfRenderer
from jinja2 import Template# Import the required classes from the libraries
from ironpdf import ChromePdfRenderer
from jinja2 import TemplateEm seguida, declare renderer como um objeto ChromePdfRenderer e use-o para renderizar modelos HTML.
# Create a renderer object to generate PDFs
renderer = ChromePdfRenderer()# Create a renderer object to generate PDFs
renderer = ChromePdfRenderer()Agora, crie um documento modelo HTML para ser reutilizado na criação de arquivos PDF. Basta criar uma nova variável e preenchê-la com conteúdo HTML contendo marcadores de posição.
# Define an HTML template with placeholders for dynamic data
html_template = """
<!DOCTYPE html>
<html>
<head>
<title>{{title}}</title>
</head>
<body>
<h1>{{title}}</h1>
<p>
Hello, {{name}}! This is a sample PDF generated from a template using IronPDF for Python.
</p>
<p>
Your age is {{age}} and your occupation is {{occupation}}.
</p>
</body>
</html>
"""# Define an HTML template with placeholders for dynamic data
html_template = """
<!DOCTYPE html>
<html>
<head>
<title>{{title}}</title>
</head>
<body>
<h1>{{title}}</h1>
<p>
Hello, {{name}}! This is a sample PDF generated from a template using IronPDF for Python.
</p>
<p>
Your age is {{age}} and your occupation is {{occupation}}.
</p>
</body>
</html>
"""Com o modelo de design pronto, escreva o código que receberá a entrada do usuário e a armazenará em um dicionário.
# Gather input from the user
title = input("Enter the title: ")
name = input("Enter your name: ")
age = input("Enter your age: ")
occupation = input("Enter your occupation: ")
# Store the input data into a dictionary for rendering the template
data = {
"title": title,
"name": name,
"age": age,
"occupation": occupation
}# Gather input from the user
title = input("Enter the title: ")
name = input("Enter your name: ")
age = input("Enter your age: ")
occupation = input("Enter your occupation: ")
# Store the input data into a dictionary for rendering the template
data = {
"title": title,
"name": name,
"age": age,
"occupation": occupation
}Além disso, o código abaixo integrará os dados no documento modelo e renderizará modelos HTML usando o objeto IronPDF renderer criado anteriormente. Finalmente, salve o arquivo PDF usando o método SaveAs.
# Create a Template object with the HTML structure
template = Template(html_template)
# Render the template with the user-provided data
html_content = template.render(**data)
# Generate the PDF from the rendered HTML content
pdf = renderer.RenderHtmlAsPdf(html_content)
# Save the generated PDF to a file
pdf.SaveAs("output.pdf")# Create a Template object with the HTML structure
template = Template(html_template)
# Render the template with the user-provided data
html_content = template.render(**data)
# Generate the PDF from the rendered HTML content
pdf = renderer.RenderHtmlAsPdf(html_content)
# Save the generated PDF to a file
pdf.SaveAs("output.pdf")Com isso, o código para criar arquivos PDF dinamicamente está concluído. Vamos executar o código para ver o resultado.
Exemplo de saída 1
Após a execução do código, serão solicitadas as seguintes informações ao usuário.
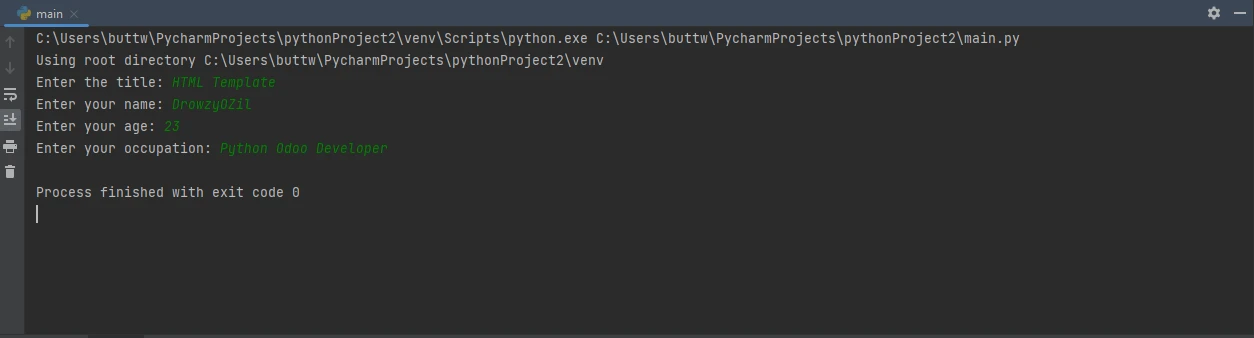 O console requer entrada adicional do usuário.
O console requer entrada adicional do usuário.
Insira os dados um por um e pressione Enter após cada entrada. Após inserir os quatro campos, será gerado um arquivo PDF.
 O arquivo PDF de saída
O arquivo PDF de saída
Exemplo de saída 2
Agora, execute o programa novamente e tente entradas diferentes.
 O console com entradas diferentes
O console com entradas diferentes
Como você pode ver abaixo, o formato do arquivo de saída é o mesmo, mas foi atualizado com as novas entradas.
 O novo arquivo PDF de saída
O novo arquivo PDF de saída
Para obter mais informações sobre como criar, modificar e ler PDFs em Python usando o IronPDF, visite a página de documentação .
Conclusão
No mundo da programação e da automação de documentos, a utilização da biblioteca IronPDF pelo Python para renderizar documentos PDF a partir de modelos revolucionou o gerenciamento de documentos e a eficiência do fluxo de trabalho. Essa poderosa combinação permite que os desenvolvedores criem facilmente arquivos PDF personalizados, como faturas, relatórios e certificados, aumentando a produtividade e a experiência do usuário. A integração perfeita das ferramentas e APIs abrangentes do IronPDF em projetos Python permite que os desenvolvedores lidem com tarefas de geração, edição e manipulação de PDFs com facilidade, simplificando o processo de desenvolvimento e garantindo resultados consistentes e refinados. A versatilidade do Python, aliada aos recursos do IronPDF, torna essa dupla dinâmica um recurso indispensável para qualquer desenvolvedor que busque soluções eficientes e automatizadas para documentos PDF. Além disso, é possível usar a mesma técnica para criar PDFs a partir de arquivos CSV, editando seu código Python de acordo.
Como você pode notar, os arquivos de saída possuem marca d'água. Você pode removê-los facilmente adquirindo uma licença . O pacote Lite vem com uma licença perpétua, garantia de devolução do dinheiro em 30 dias, um ano de suporte ao software e possibilidades de upgrade. O IronPDF também oferece uma licença de avaliação gratuita .
Perguntas frequentes
Como posso gerar um PDF a partir de um modelo HTML usando uma biblioteca Python?
Você pode usar ChromePdfRenderer do IronPDF para renderizar conteúdo HTML em um PDF. Defina um modelo HTML com marcadores de posição, integre-o com dados dinâmicos usando Jinja2 e, em seguida, renderize-o para gerar um PDF.
Quais são os requisitos de sistema para usar uma biblioteca PDF em Python?
Para usar o IronPDF em Python, você precisa do Python 3.0 ou superior, do SDK .NET 6.0 e da biblioteca IronPDF, que pode ser instalada usando o pip.
Como instalo o IronPDF no meu ambiente Python?
Você pode instalar o IronPDF executando o comando pip install ironpdf na sua interface de linha de comando.
Como posso iniciar um novo projeto Python no PyCharm?
Para criar um novo projeto Python no PyCharm, vá em 'Arquivo' > 'Novo Projeto', especifique o ambiente e o local e clique em 'Criar'.
Posso usar uma biblioteca Python para converter dados CSV em um arquivo PDF?
Sim, você pode usar o IronPDF para ler dados CSV, incorporá-los em um modelo HTML e, em seguida, renderizá-los como um PDF usando ChromePdfRenderer .
Quais são os passos envolvidos na criação de um PDF a partir de dados de entrada em Python?
Com o IronPDF, você coleta os dados inseridos pelos usuários, os integra a um modelo HTML usando Jinja2, renderiza o modelo com ChromePdfRenderer e, em seguida, salva o arquivo PDF resultante.
Como posso remover marcas d'água de PDFs criados por uma biblioteca Python?
Para remover marcas d'água de PDFs gerados pelo IronPDF, você pode adquirir uma licença, que inclui uma licença perpétua, garantia de reembolso de 30 dias, um ano de suporte e opções de atualização.
É possível automatizar fluxos de trabalho de documentos usando uma biblioteca PDF em Python?
Sim, o IronPDF pode ser usado para automatizar fluxos de trabalho de documentos, permitindo a criação, edição e gerenciamento de arquivos PDF programaticamente em aplicativos Python.
















