
Jak analizować plik PDF w Python
1.0 Wprowadzenie
Nowoczesne biblioteki usprawniły tworzenie plików PDF. Wybierając bibliotekę do projektów związanych z plikami PDF, należy wziąć pod uwagę możliwości kompilacji, odczytu i konwersji, aby zapewnić optymalną integrację i wydajność. Python oferuje narzędzia takie jak IronPDF, które mogą efektywnie analizować istniejące pliki PDF.
2.0 IronPDF
Python to język programowania, który umożliwia programistom szybkie i łatwe tworzenie graficznych interfejsów użytkownika. W porównaniu z innymi językami oferuje programistom większą dynamikę. Dlatego integracja biblioteki IronPDF z Pythonem jest prostym procesem.
Aby szybko i bezpiecznie stworzyć w pełni funkcjonalny interfejs graficzny, programiści mogą skorzystać z kilku preinstalowanych narzędzi, w tym PyQt, wxWidgets, Kivy oraz wielu innych pakietów i bibliotek. Warto zauważyć, że IronPDF nie jest biblioteką PDF napisana wyłącznie w języku Python; zamiast tego umożliwia włączenie różnych funkcji z innych frameworków, takich jak .NET Core.
IronPDF upraszcza projektowanie i tworzenie stron internetowych w języku Python, zwłaszcza ze względu na popularność paradygmatów tworzenia stron internetowych w tym języku, takich jak Django, Flask i Pyramid. Z tych frameworków korzystają znane serwisy internetowe i usługi online, w tym Reddit, Mozilla i Spotify. Więcej informacji na temat języka Python w IronPDF można znaleźć na stronie internetowej IronPDF for Python.
2.1 Funkcje IronPDF
- IronPDF umożliwia generowanie plików PDF z różnych źródeł, w tym HTML, HTML5, ASPX oraz Razor/MVC View. Zapewnia funkcjonalność tworzenia plików PDF ze stron HTML i obrazów.
- Zestaw narzędzi IronPDF oferuje szereg narzędzi do zadań takich jak tworzenie interaktywnych plików PDF, wypełnianie i przesyłanie interaktywnych formularzy, dzielenie i łączenie plików PDF, wyodrębnianie tekstu i obrazów z plików PDF, wyszukiwanie określonych słów w pliku PDF, rasteryzacja stron PDF do obrazów oraz konwersja plików PDF do formatu HTML.
- Dzięki obsłudze agentów użytkownika, serwerów proxy, plików cookie, nagłówków HTTP i zmiennych kształtu, IronPDF umożliwia walidację formularzy logowania HTML.
- Dostęp do chronionych dokumentów w IronPDF jest przyznawany poprzez użycie nazw użytkownika i haseł.
- IronPDF pomaga generować pliki PDF i drukować za pomocą zaledwie kilku wierszy kodu z różnych źródeł, takich jak ciągi znaków, strumienie, adresy URL itp.
3.0 Konfiguracja w języku Python
3.1 Konfiguracja środowiska
Upewnij się, że na Twoim komputerze zainstalowany jest Python. Odwiedź oficjalną stronę Pythona, aby pobrać i zainstalować najnowszą wersję Pythona odpowiednią dla Twojego systemu operacyjnego. Po zainstalowaniu języka Python skonfiguruj środowisko wirtualne, aby odizolować zależności dla swojego projektu. Użyj modułu "venv" do tworzenia i zarządzania środowiskami wirtualnymi, zapewniając projektowi konwersji czystą i niezależną przestrzeń roboczą.
3.2 Nowy projekt w PyCharm
W tej demonstracji użyjemy PyCharm, środowiska IDE do pisania kodu w języku Python.
Po uruchomieniu środowiska PyCharm kliknij "Nowy projekt".
 Ekran powitalny PyCharm
Ekran powitalny PyCharm
Po wybraniu opcji "Nowy projekt" pojawi się nowe okno, w którym można określić lokalizację projektu i jego środowisko. To nowe okno można zobaczyć na poniższym zrzucie ekranu.
 Ekran nowego projektu w PyCharm
Ekran nowego projektu w PyCharm
Kliknij przycisk Utwórz, aby rozpocząć nowy projekt, po ustawieniu lokalizacji projektu i ścieżki środowiska. Otworzy to nowe okno, w którym będzie można rozwijać program. W tym samouczku zalecano użycie języka Python 3.9.
 Główny plik otwarty w PyCharm
Główny plik otwarty w PyCharm
3.3 Wymagania dotyczące biblioteki IronPDF
IronPDF, biblioteka języka Python, opiera się głównie na platformie .NET 6.0. W związku z tym, aby korzystać z IronPDF for Python, na komputerze musi być zainstalowane środowisko uruchomieniowe .NET 6.0. Aby użytkownicy systemów Linux i Mac mogli korzystać z tego modułu Python, może być konieczne zainstalowanie platformy .NET. Wymagane środowisko uruchomieniowe można pobrać ze strony internetowej .NET.
3.4 Konfiguracja biblioteki IronPDF
Aby tworzyć, edytować i otwierać pliki z rozszerzeniem ".pdf", należy zainstalować pakiet "IronPDF". Aby zainstalować pakiet w PyCharm, otwórz okno terminala i wpisz następujące polecenie:
pip install ironpdfpip install ironpdfPoniższy zrzut ekranu przedstawia konfigurację pakietu "IronPDF".
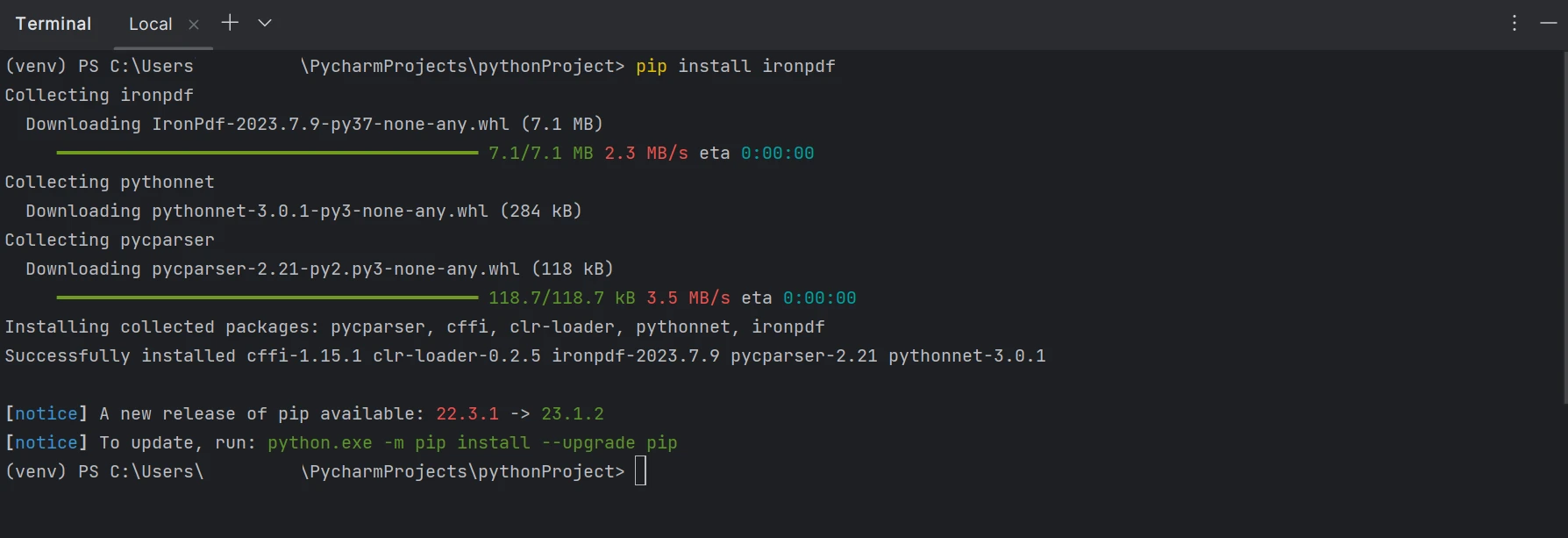 Terminal pokazujący instalację IronPDF za pomocą pip
Terminal pokazujący instalację IronPDF za pomocą pip
4.0 Analiza plików PDF za pomocą IronPDF
Dzięki bibliotekom IronPDF możliwe jest wyodrębnianie tekstu z plików PDF. IronPDF oferuje różne techniki ekstrakcji tekstu. Pierwsze podejście polega na pobraniu całej zawartości strony jako pojedynczego ciągu znaków. Drugie podejście polega na czytaniu treści strona po stronie, zaczynając od pierwszej strony. Poniższy fragment kodu ilustruje wzorzec sprawdzania bieżących plików PDF przy użyciu IronPDF.
Dostępne są dwie metody pobierania danych z pliku PDF:
- Pobieranie danych z pliku PDF strona po stronie.
- Wyodrębnianie całego pliku PDF jako tekstu.
Poniżej znajduje się plik PDF, którego będziemy używać w tym artykule. Dokument składa się z dwóch stron.
 Plik PDF z numerem strony u góry każdej strony
Plik PDF z numerem strony u góry każdej strony
4.0.1 WYCIĄGANIE TEKSTU Z POJEDYNCZYCH STRON
Poniższy przykładowy kod pokazuje, jak wykorzystać numer strony do pobrania danych z pliku PDF.
from ironpdf import PdfDocument
# Open a PDF file and create a PDF document object
pdfDocument = PdfDocument.FromFile("F:\\PDF\\1.pdf")
# Extract text from the first page (index 0)
AllText = pdfDocument.ExtractTextFromPage(0)
# Print the extracted text from the first page
print(AllText)from ironpdf import PdfDocument
# Open a PDF file and create a PDF document object
pdfDocument = PdfDocument.FromFile("F:\\PDF\\1.pdf")
# Extract text from the first page (index 0)
AllText = pdfDocument.ExtractTextFromPage(0)
# Print the extracted text from the first page
print(AllText)Fragment kodu pokazuje użycie funkcji FromFile do odczytania pliku PDF i utworzenia obiektu dokumentu PDF. Ten obiekt umożliwia dostęp do tekstów i obrazów zawartych w pliku PDF. Aby wyodrębnić tekst z konkretnej strony, można użyć metody ExtractTextFromPage, podając numer strony jako parametr. Ta metoda zwróci ciąg znaków zawierający wszystkie słowa na określonej stronie. Wynik zostanie wyświetlony w sposób przedstawiony poniżej.
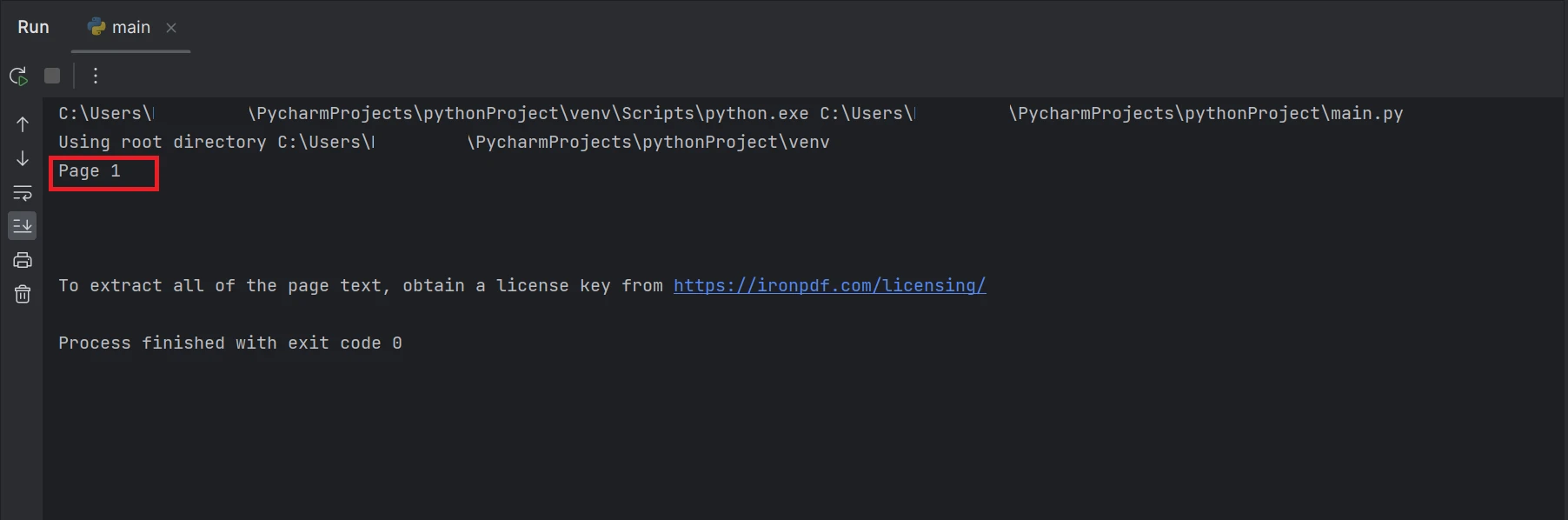 Zrzut ekranu terminala z tekstem "Strona 1"
Zrzut ekranu terminala z tekstem "Strona 1"
Prostokątne pole zaznaczone w wyniku to tekst wyodrębniony z pliku PDF na stronie nr 1, która ma indeks 0.
4.0.2 FRAGMENT ZE WSZYSTKICH STRON
Pierwsze podejście do szybkiego i łatwego uzyskania całej zawartości pliku PDF w postaci ciągu znaków przedstawiono w poniższym przykładzie kodu.
from ironpdf import PdfDocument
# Create a PDF file object from the file path
pdf = PdfDocument.FromFile('F:\\PDF\\1.pdf')
# Extract all text from the entire PDF
all_text = pdf.ExtractAllText()
# Print the extracted text from the entire PDF
print(all_text)from ironpdf import PdfDocument
# Create a PDF file object from the file path
pdf = PdfDocument.FromFile('F:\\PDF\\1.pdf')
# Extract all text from the entire PDF
all_text = pdf.ExtractAllText()
# Print the extracted text from the entire PDF
print(all_text)Powyższy przykładowy kod wyjaśnia, jak odczytać plik PDF z istniejącej ścieżki i przekształcić go w obiekt pliku PDF za pomocą funkcji FromFile. Zwykły tekst z pliku PDF zostanie wyodrębniony i przekonwertowany na ciąg znaków za pomocą funkcji ExtractAllText obiektu, a następnie wyodrębniony tekst zostanie wyświetlony na terminalu. Wynik zostanie wyświetlony w sposób przedstawiony poniżej.
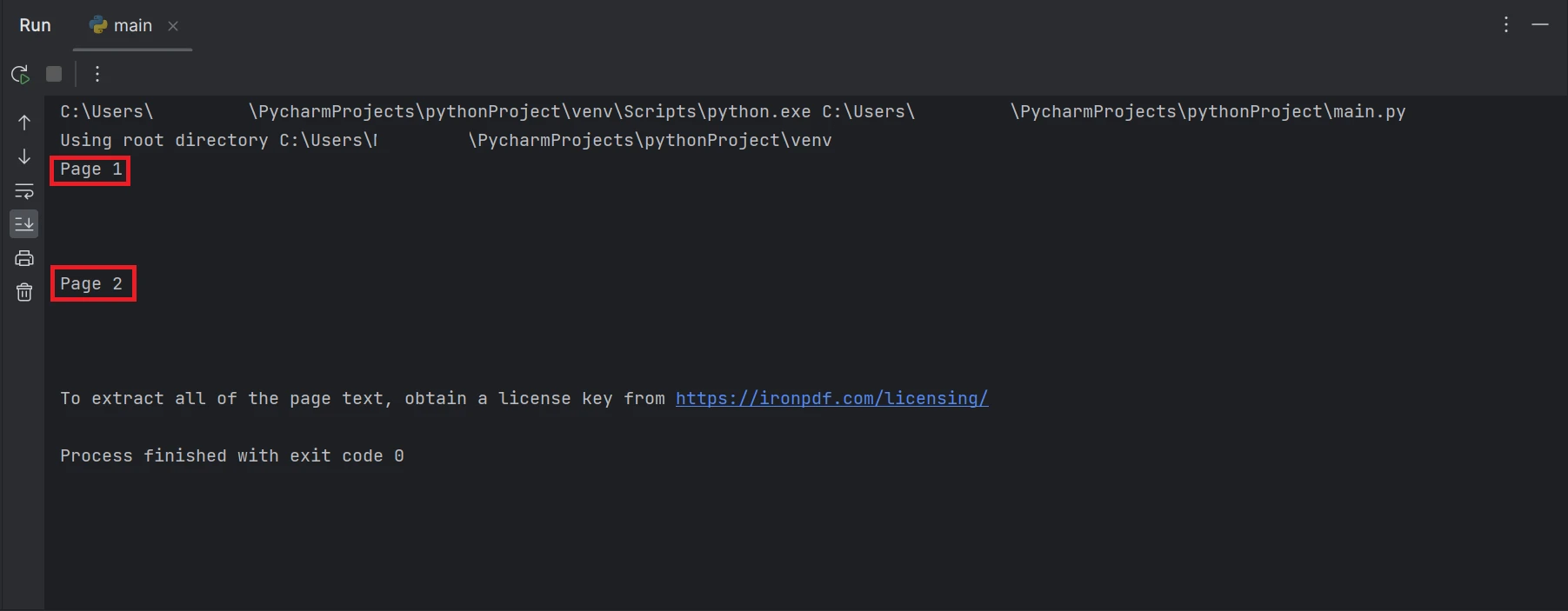 Zrzut ekranu terminala z tekstem "Strona 1" i "Strona 2"
Zrzut ekranu terminala z tekstem "Strona 1" i "Strona 2"
Prostokątne ramki, które są podświetlone w wyniku, zawierają dane wyodrębnione ze wszystkich stron pliku PDF.
Jesteśmy w stanie tworzyć pliki PDF przy użyciu języka C# z pomocą biblioteki IronPDF. Aby dowiedzieć się więcej o IronPDF, odwiedź stronę internetową IronPDF.
5.0 Podsumowanie
Aby zminimalizować ryzyko i zapewnić ochronę danych, biblioteka IronPDF zapewnia solidne zabezpieczenia. Jest kompatybilny ze wszystkimi powszechnie używanymi przeglądarkami i nie jest ograniczony do żadnej z nich. IronPDF umożliwia programistom łatwe tworzenie i odczytywanie plików PDF za pomocą zaledwie kilku linii kodu. Aby zaspokoić różnorodne potrzeby programistów, biblioteka IronPDF oferuje szereg opcji licencyjnych, w tym bezpłatną licencję dla programistów oraz dodatkowe licencje programistyczne dostępne w sprzedaży.
Pakiet $799 Lite obejmuje Licencję wieczystą, 30-dniową gwarancję zwrotu pieniędzy, roczną pomoc techniczną oraz możliwość aktualizacji. Poza kosztem pierwszego zakupu nie ma żadnych dodatkowych opłat. Środowiska produkcyjne, testowe i programistyczne korzystają z tych licencji. IronPDF oferuje również bezpłatne licencje z niewielkimi ograniczeniami czasowymi i dotyczącymi redystrybucji. W trakcie bezpłatnego okresu próbnego użytkownicy mogą przetestować produkt w rzeczywistych warunkach użytkowania bez znaku wodnego. Aby uzyskać więcej informacji na temat kosztów i licencji wersji próbnej IronPDF, odwiedź stronę licencyjną IronPDF.
Często Zadawane Pytania
Jak mogę analizować dokumenty PDF za pomocą języka Python?
Za pomocą IronPDF można analizować dokumenty PDF w języku Python. Biblioteka pozwala na utworzenie obiektu dokumentu PDF i użycie metod takich jak ExtractTextFromPage do wyodrębnienia tekstu z określonych stron lub ExtractAllText do wyodrębnienia tekstu z całego dokumentu.
Jakie są wymagania wstępne do uruchomienia IronPDF w środowisku Python?
Aby uruchomić IronPDF w środowisku Python, musisz mieć zainstalowane środowisko uruchomieniowe .NET 6.0, ponieważ IronPDF opiera się na .NET.
Czy IronPDF może być używany z popularnymi frameworkami internetowymi w języku Python?
Tak, IronPDF płynnie integruje się z popularnymi frameworkami internetowymi w języku Python, takimi jak Django, Flask i Pyramid, co czyni go wszechstronnym narzędziem do projektów związanych z tworzeniem stron internetowych.
Jak zainstalować IronPDF w środowisku wirtualnym Python?
Aby zainstalować IronPDF w środowisku wirtualnym Python, najpierw upewnij się, że masz zainstalowany Python, a następnie utwórz środowisko wirtualne. Użyj polecenia pip install ironpdf w terminalu swojego IDE, aby zainstalować pakiet.
Jakie są kluczowe funkcje IronPDF for Python?
IronPDF oferuje takie funkcje, jak generowanie plików PDF z HTML, obrazów, ciągów znaków i strumieni, tworzenie interaktywnych plików PDF, wypełnianie formularzy, dzielenie i łączenie plików PDF oraz wyodrębnianie tekstu i obrazów.
Czy IronPDF jest kompatybilny z różnymi systemami operacyjnymi?
Tak, IronPDF jest kompatybilny z różnymi systemami operacyjnymi. Jednak użytkownicy systemów Linux i Mac muszą upewnić się, że na ich systemach zainstalowano platformę .NET, aby móc korzystać z modułu Python.
Jakie opcje licencyjne są dostępne dla IronPDF?
IronPDF oferuje kilka opcji licencyjnych, w tym bezpłatną licencję deweloperską z ograniczeniami oraz płatny pakiet Lite z Licencją wieczystą i 30-dniową gwarancją zwrotu pieniędzy. Opcje te zapewniają elastyczność w zależności od potrzeb programistycznych.
Jak skonfigurować nowy projekt IronPDF w PyCharm?
Aby skonfigurować nowy projekt IronPDF w PyCharm, otwórz IDE, kliknij „New Project” i skonfiguruj lokalizację oraz środowisko projektu. Użyj terminala w PyCharm, aby zainstalować IronPDF za pomocą polecenia pip install ironpdf.
W jaki sposób IronPDF zapewnia bezpieczeństwo dokumentów PDF?
IronPDF wykorzystuje zaawansowane zabezpieczenia, aby zapewnić bezpieczeństwo i integralność dokumentów PDF, co czyni go niezawodnym wyborem dla aplikacji wymagających obsługi plików PDF.
Czy IronPDF może służyć do wyodrębniania obrazów z plików PDF?
Tak, IronPDF może służyć do wyodrębniania obrazów z plików PDF poprzez dostęp do obiektu dokumentu i użycie odpowiednich metod w celu pobrania danych obrazu.
















