
Como analisar um arquivo PDF em Python
1.0 Introdução
As bibliotecas modernas simplificaram a criação de PDFs. Ao escolher uma biblioteca para projetos em PDF, considere os recursos de compilação, leitura e conversão para obter integração e desempenho ideais. O Python oferece ferramentas como o IronPDF que podem analisar PDFs existentes de forma eficiente.
2.0 IronPDF
Python é uma linguagem de programação que permite aos desenvolvedores construir interfaces gráficas de usuário de forma rápida e fácil. Oferece maior dinamismo para os programadores em comparação com outras linguagens. Portanto, integrar a biblioteca IronPDF com Python é um processo simples.
Para criar uma GUI totalmente funcional de forma rápida e segura, os desenvolvedores podem utilizar diversas ferramentas pré-instaladas, incluindo PyQt, wxWidgets, Kivy e muitos outros pacotes e bibliotecas. Vale ressaltar que o IronPDF não é uma biblioteca PDF puramente em Python; Em vez disso, permite a inclusão de vários recursos de outras estruturas, como o .NET Core.
O IronPDF simplifica o design e o desenvolvimento web em Python, principalmente devido à popularidade de paradigmas de desenvolvimento web em Python como Django, Flask e Pyramid. Sites e serviços online notáveis, incluindo Reddit, Mozilla e Spotify, utilizaram essas estruturas. Você pode aprender mais sobre Python no IronPDF no site do IronPDF for Python .
2.1 Funcionalidades do IronPDF
- O IronPDF é capaz de gerar arquivos PDF a partir de várias fontes, incluindo HTML, HTML5, ASPX e Razor/MVC View. Oferece funcionalidades para criar PDFs a partir de páginas HTML e imagens.
- O conjunto de ferramentas IronPDF oferece uma variedade de recursos para tarefas como criar PDFs interativos, preencher e enviar formulários interativos , dividir e combinar arquivos PDF, extrair texto e imagens de arquivos PDF, pesquisar palavras específicas em um arquivo PDF, rasterizar páginas de PDF em imagens e converter PDF em HTML.
- Com suporte para agentes de usuário, proxies, cookies, cabeçalhos HTTP e variáveis de forma, o IronPDF permite a validação de formulários de login HTML.
- O acesso a documentos protegidos no IronPDF é concedido através do uso de nomes de usuário e senhas.
- O IronPDF ajuda a gerar arquivos PDF e a imprimi-los com apenas algumas linhas de código a partir de várias fontes, como strings, fluxos de dados, URLs, etc.
3.0 Configuração do Python
3.1 Configuração do ambiente
Certifique-se de que o Python esteja instalado no seu computador. Visite o site oficial do Python para baixar e instalar a versão mais recente do Python adequada ao seu sistema operacional. Após instalar o Python, configure um ambiente virtual para isolar as dependências do seu projeto. Utilize o módulo "venv" para criar e gerenciar ambientes virtuais, proporcionando ao seu projeto de conversão um espaço de trabalho limpo e independente.
3.2 Novo projeto no PyCharm
Para esta demonstração, usaremos o PyCharm, um ambiente de desenvolvimento integrado (IDE) para escrever código Python.
Após iniciar o ambiente de desenvolvimento integrado (IDE) PyCharm, clique em "Novo Projeto".
 A tela de boas-vindas do PyCharm
A tela de boas-vindas do PyCharm
Ao selecionar "Novo Projeto", uma nova janela será exibida, permitindo que você especifique a localização e o ambiente do projeto. Essa nova janela pode ser vista na captura de tela abaixo.
 A nova tela de projeto no PyCharm
A nova tela de projeto no PyCharm
Clique no botão Criar para iniciar um novo projeto, após definir o local do projeto e o caminho do ambiente. Isso abrirá uma nova janela onde o programa poderá ser desenvolvido. Este tutorial recomenda o uso do Python 3.9.
 Um arquivo principal aberto no PyCharm
Um arquivo principal aberto no PyCharm
3.3 Requisito da Biblioteca IronPDF
IronPDF, uma biblioteca Python, depende principalmente do .NET 6.0. Consequentemente, para utilizar o IronPDF for Python, seu computador precisa ter o ambiente de execução .NET 6.0 instalado. Antes que usuários de Linux e Mac possam usar este módulo Python, pode ser necessário instalar o .NET . Você pode obter o ambiente de execução necessário no site do .NET .
3.4 Configuração da Biblioteca IronPDF
O pacote "IronPDF" precisa ser instalado para criar, editar e abrir arquivos com a extensão ".pdf". Para instalar o pacote no PyCharm, abra uma janela de terminal e digite o seguinte comando:
pip install ironpdf
A captura de tela abaixo mostra a configuração do pacote 'IronPDF'.
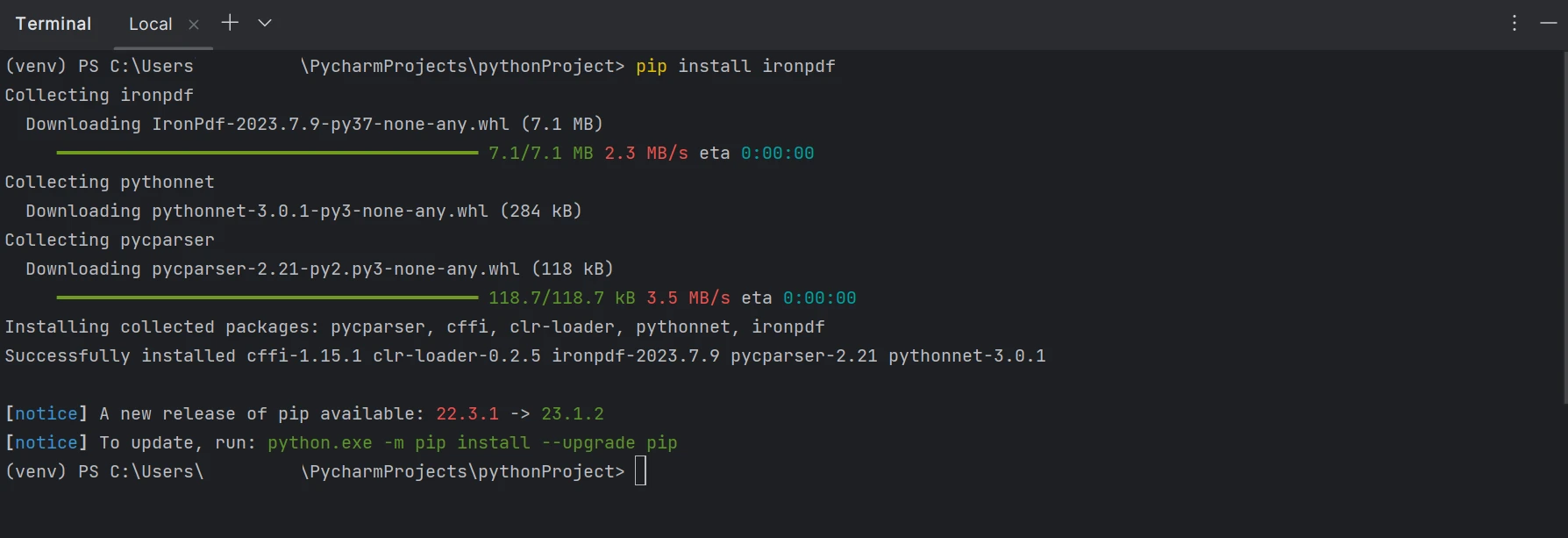 Um terminal mostrando a instalação do IronPDF usando o pip.
Um terminal mostrando a instalação do IronPDF usando o pip.
4.0 Analisar PDF com IronPDF
Com o auxílio das bibliotecas IronPDF , é possível extrair texto de arquivos PDF. O IronPDF oferece diversas técnicas para extração de texto. A primeira abordagem envolve recuperar todo o conteúdo da página como uma única string. A segunda abordagem envolve a leitura do conteúdo página por página, começando pela primeira página. O trecho de código a seguir demonstra um padrão para inspecionar arquivos PDF atuais usando o IronPDF.
Existem dois métodos disponíveis para extrair dados de um PDF:
- Extraindo dados do PDF página por página.
- Extrair todo o PDF como texto.
Abaixo está o arquivo PDF que usaremos neste artigo. Possui duas páginas.
 Um PDF com o número da página no topo de cada página.
Um PDF com o número da página no topo de cada página.
4.0.1 EXTRAÇÃO DE TEXTO POR PÁGINAS
O código de exemplo fornecido abaixo demonstra como usar o número da página para recuperar dados de um arquivo PDF.
from ironpdf import PdfDocument
# Open a PDF file and create a PDF document object
pdfDocument = PdfDocument.FromFile("F:\\PDF\\1.pdf")
# Extract text from the first page (index 0)
AllText = pdfDocument.ExtractTextFromPage(0)
# Print the extracted text from the first page
print(AllText)from ironpdf import PdfDocument
# Open a PDF file and create a PDF document object
pdfDocument = PdfDocument.FromFile("F:\\PDF\\1.pdf")
# Extract text from the first page (index 0)
AllText = pdfDocument.ExtractTextFromPage(0)
# Print the extracted text from the first page
print(AllText)O trecho de código demonstra o uso da função FromFile para ler um arquivo PDF e criar um objeto de documento PDF. Este objeto permite o acesso a textos e imagens dentro do PDF. Para extrair o texto de uma página específica, o método ExtractTextFromPage pode ser usado fornecendo o número da página como parâmetro. Este método retornará uma string contendo todas as palavras da página especificada. O resultado será exibido conforme abaixo.
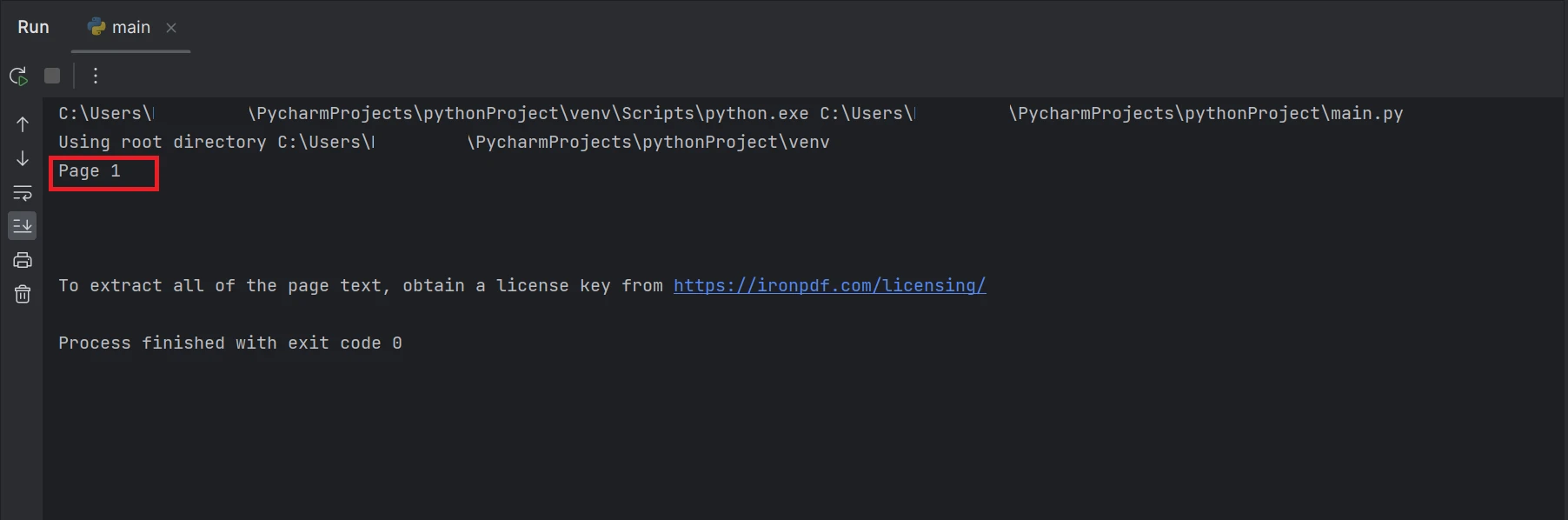 Uma captura de tela do terminal com a saída de texto "Página 1"
Uma captura de tela do terminal com a saída de texto "Página 1"
A caixa retangular que está destacada no resultado é o texto extraído de dados do arquivo PDF na página número 1, que tem o índice como 0.
4.0.2 EXTRATO DE TODAS AS PÁGINAS
A primeira abordagem para obter de forma rápida e fácil todo o conteúdo do PDF como uma string é mostrada no exemplo de código a seguir.
from ironpdf import PdfDocument
# Create a PDF file object from the file path
pdf = PdfDocument.FromFile('F:\\PDF\\1.pdf')
# Extract all text from the entire PDF
all_text = pdf.ExtractAllText()
# Print the extracted text from the entire PDF
print(all_text)from ironpdf import PdfDocument
# Create a PDF file object from the file path
pdf = PdfDocument.FromFile('F:\\PDF\\1.pdf')
# Extract all text from the entire PDF
all_text = pdf.ExtractAllText()
# Print the extracted text from the entire PDF
print(all_text)O exemplo de código mostrado acima explica como ler um PDF de um caminho de arquivo existente e transformá-lo em um objeto de arquivo PDF usando a função FromFile. O texto simples do PDF será extraído e convertido em uma string usando a função ExtractAllText do objeto e imprimirá o texto extraído no terminal. O resultado será exibido como abaixo.
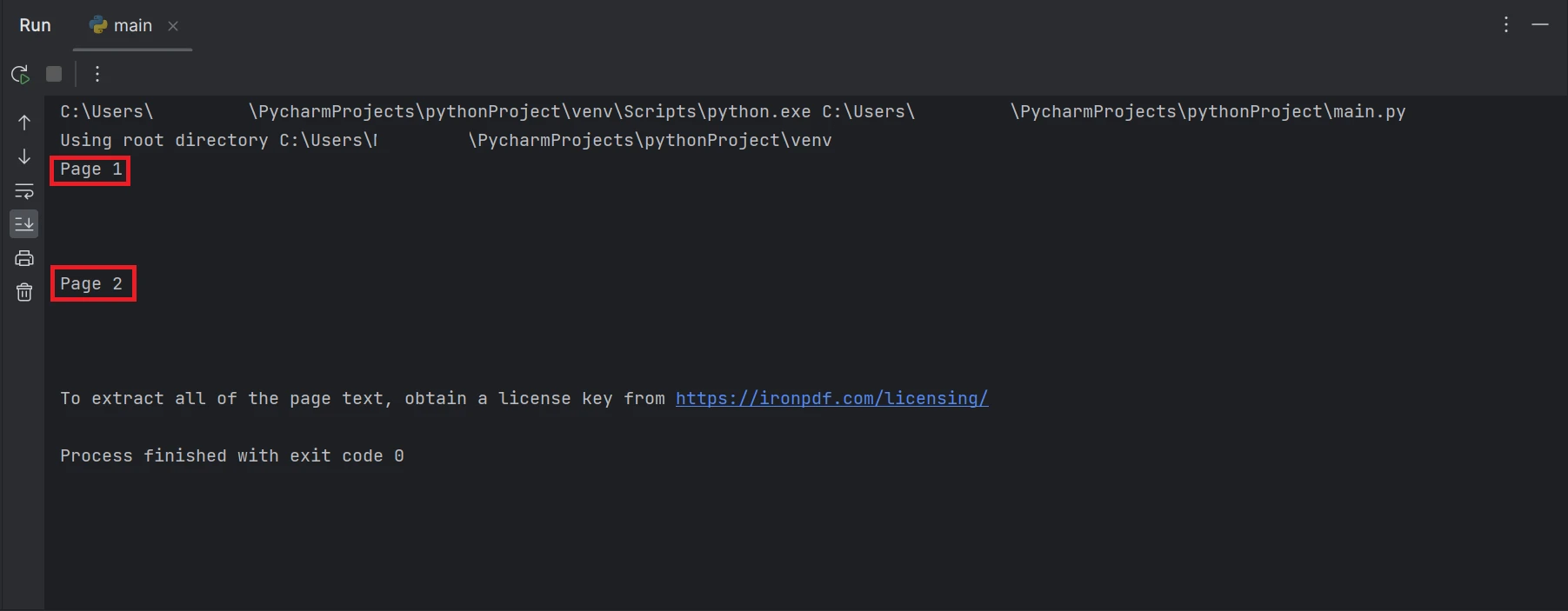 Uma captura de tela do terminal com a saída de texto "Página 1" e "Página 2".
Uma captura de tela do terminal com a saída de texto "Página 1" e "Página 2".
Os retângulos destacados no resultado contêm os dados de texto extraídos de todas as páginas do arquivo PDF.
É possível criar PDFs usando C# com a ajuda do IronPDF. Para saber mais sobre o IronPDF, visite o site do IronPDF .
5.0 Conclusão
Para minimizar riscos e garantir a proteção de dados, a biblioteca IronPDF oferece fortes medidas de segurança. É compatível com todos os navegadores mais utilizados e não se limita a nenhum em específico. O IronPDF permite que programadores criem e leiam arquivos PDF facilmente com apenas algumas linhas de código. Para atender às diversas necessidades dos desenvolvedores, a biblioteca IronPDF oferece uma variedade de opções de licenciamento, incluindo uma licença de desenvolvedor gratuita e licenças de desenvolvimento adicionais que podem ser adquiridas.
O pacote $999 Lite vem com uma licença perpétua, uma garantia de devolução do dinheiro em 30 dias, um ano de suporte ao software e possibilidades de atualização. Após a primeira compra, não há custos adicionais. Os ambientes de produção, teste e desenvolvimento utilizam essas licenças. O IronPDF também oferece licenças gratuitas com algumas limitações de tempo e redistribuição. Durante o período de teste gratuito, os usuários podem testar o produto em uso real, sem marca d'água. Para obter mais detalhes sobre o custo e o licenciamento da versão de avaliação do IronPDF, visite a página de licenciamento do IronPDF .
Perguntas frequentes
Como posso analisar documentos PDF usando Python?
Você pode analisar documentos PDF em Python usando o IronPDF. A biblioteca permite criar um objeto de documento PDF e usar métodos como ExtractTextFromPage para extrair texto de páginas específicas ou ExtractAllText para extrair texto de todo o documento.
Quais são os pré-requisitos para executar o IronPDF em um ambiente Python?
Para executar o IronPDF em um ambiente Python, você precisa ter o runtime .NET 6.0 instalado em seu sistema, pois o IronPDF depende do .NET para seu funcionamento.
O IronPDF pode ser usado com frameworks web populares em Python?
Sim, o IronPDF integra-se perfeitamente com frameworks web populares em Python, como Django, Flask e Pyramid, tornando-se uma ferramenta versátil para projetos de desenvolvimento web.
Como instalar o IronPDF em um ambiente virtual Python?
Para instalar o IronPDF em um ambiente virtual Python, primeiro certifique-se de ter o Python instalado e crie um ambiente virtual. Use o comando pip install ironpdf no terminal da sua IDE para instalar o pacote.
Quais são algumas das principais funcionalidades do IronPDF para desenvolvedores Python?
O IronPDF oferece recursos como geração de PDFs a partir de HTML, imagens, strings e fluxos de dados, criação de PDFs interativos, preenchimento de formulários, divisão e combinação de PDFs e extração de texto e imagens.
O IronPDF é compatível com diferentes sistemas operacionais?
Sim, o IronPDF é compatível com diferentes sistemas operacionais. No entanto, usuários de Linux e Mac precisam garantir que o .NET esteja instalado em seus sistemas para usar o módulo Python.
Quais são as opções de licenciamento disponíveis para o IronPDF?
O IronPDF oferece diversas opções de licenciamento, incluindo uma licença gratuita para desenvolvedores com limitações e um pacote Lite pago com licença perpétua e garantia de reembolso de 30 dias. Essas opções proporcionam flexibilidade dependendo das suas necessidades de desenvolvimento.
Como configurar um novo projeto IronPDF no PyCharm?
Para configurar um novo projeto IronPDF no PyCharm, abra a IDE, clique em 'Novo Projeto' e configure o local e o ambiente do projeto. Use o terminal do PyCharm para instalar o IronPDF com pip install ironpdf .
Como o IronPDF garante a segurança dos documentos PDF?
O IronPDF incorpora fortes medidas de segurança para garantir a segurança e a integridade dos documentos PDF, tornando-o uma escolha confiável para aplicações que exigem o manuseio de PDFs.
O IronPDF pode ser usado para extrair imagens de PDFs?
Sim, o IronPDF pode ser usado para extrair imagens de PDFs acessando o objeto do documento e usando os métodos apropriados para recuperar os dados da imagem.
















