
Como extrair dados de fatura de um PDF em Python
Este artigo abordará como extrair dados de texto de arquivos PDF de faturas usando a biblioteca IronPDF for Python.
Como extrair dados de faturas de um PDF em Python
- Instale a biblioteca Python para extrair dados de faturas em PDF.
- Utilize o método
PdfDocument.FromFilepara abrir um arquivo PDF. - Extraia todos os dados da fatura usando o método
ExtractAllText. - Use o método
printpara imprimir todos os dados extraídos da fatura. - Extrair dados específicos dos dados da fatura.
1. IronPDF
IronPDF for Python é uma biblioteca robusta que utiliza Python para servir de ponte entre aplicações Python e documentos PDF. Essa ferramenta versátil oferece aos desenvolvedores os meios para criar, manipular e interagir com arquivos PDF em seus projetos Python sem esforço. Aqui estão alguns dos recursos de destaque que fazem do IronPDF uma ferramenta valiosa:
- Geração de PDF: O IronPDF permite a geração dinâmica de arquivos PDF do zero, possibilitando que desenvolvedores criem PDFs programaticamente com conteúdo, estilo e layout personalizados. 2.Conversão de HTML para PDF: Permite converter conteúdo HTML, incluindo páginas web, em PDFs de alta qualidade, preservando o layout e o estilo do HTML original, o que é especialmente útil para gerar relatórios e documentação.
- Edição de PDF: Os desenvolvedores podem editar facilmente PDFs existentes, adicionando, modificando ou removendo texto, imagens e elementos interativos, tornando-se uma ferramenta poderosa para manipulação de documentos.
- Fusão e divisão de PDFs: O IronPDF permite mesclar vários documentos PDF em um único arquivo ou dividir um PDF em vários arquivos , oferecendo flexibilidade no gerenciamento de grandes conjuntos de PDFs.
- Formulários PDF: Permite a criação e o preenchimento de formulários PDF interativos, sendo ideal para aplicações que exigem entrada de dados e coleta por parte do usuário.
- Assinaturas digitais: Você pode adicionar assinaturas digitais a documentos PDF, garantindo a integridade e a autenticidade de seus arquivos, o que é vital para fins legais e de segurança.
- Extração de dados de PDF: O IronPDF oferece recursos de extração para proteger as informações contidas em PDFs.
2. Preparando o ambiente
Configurar o ambiente para o IronPDF em Python envolve alguns passos para garantir que você possa começar a usar a biblioteca de forma eficaz. Aqui está um guia passo a passo:
- Crie um novo projeto Python no PyCharm e crie um ambiente virtual ou utilize um interpretador existente.
- Instale o IronPDF usando o terminal de linha de comando executando o seguinte comando no terminal:
pip install ironpdf
 IronPDF sendo instalado a partir da linha de comando.
IronPDF sendo instalado a partir da linha de comando.
3. Extrair dados de faturas usando o IronPDF
Esta seção mostrará como extrair dados do formato de fatura e do formato de saída usando a biblioteca Python IronPDF. O código abaixo extrairá todos os dados da fatura e os imprimirá no console.
Exemplo de fatura
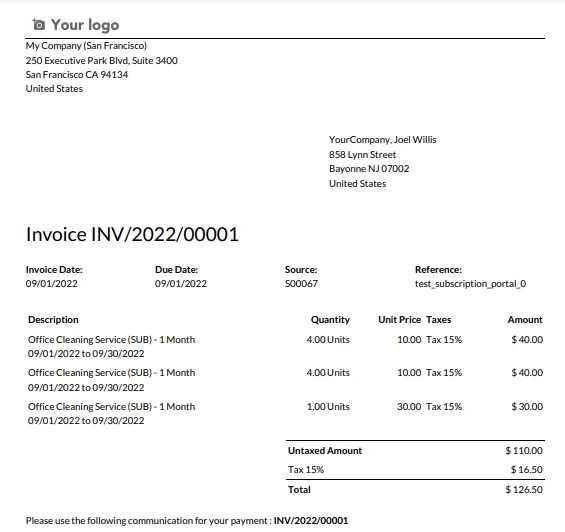 A fatura de exemplo
A fatura de exemplo
from ironpdf import PdfDocument
# Load the PDF using the PdfDocument.FromFile method
pdf = PdfDocument.FromFile("INV_2022_00001.pdf")
# Extract all text from the PDF
all_text = pdf.ExtractAllText()
# Print the extracted text
print(all_text)from ironpdf import PdfDocument
# Load the PDF using the PdfDocument.FromFile method
pdf = PdfDocument.FromFile("INV_2022_00001.pdf")
# Extract all text from the PDF
all_text = pdf.ExtractAllText()
# Print the extracted text
print(all_text)O código acima carrega um arquivo PDF específico chamado "INV_2022_00001.pdf" usando o método PdfDocument.FromFile. Subsequentemente, ele extrai todo o conteúdo de texto do documento PDF carregado e armazena na variável all_text. Finalmente, o texto extraído é impresso no console usando a função print. Essencialmente, este código automatiza o processo de extração de dados textuais estruturados e não estruturados de um arquivo PDF, tornando-os acessíveis para posterior processamento ou análise em um ambiente Python.
3.1. Saída
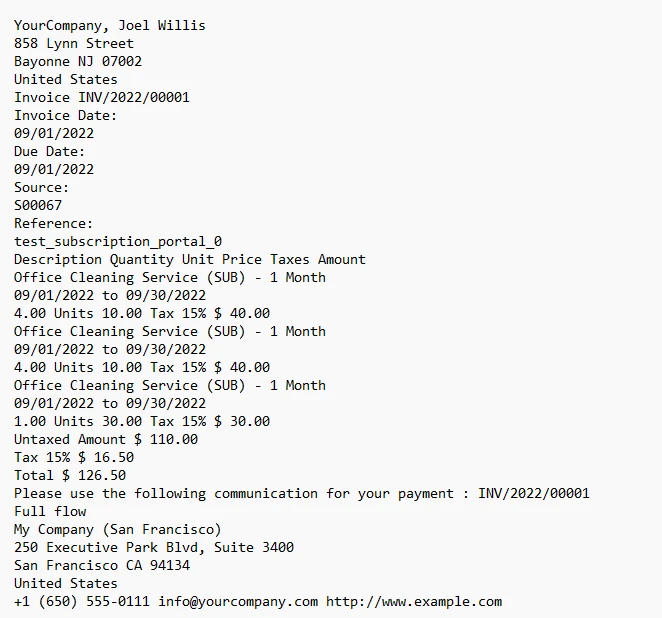 O texto da fatura exibida no console.
O texto da fatura exibida no console.
4. Extrair dados específicos da fatura
Utilizar o IronPDF para extrair dados de faturas é um processo bastante simples. Extrair dados como Número da Fatura e valor dos dados da fatura em PDF pode ser um processo complicado, mas usando o IronPDF em conjunto com a biblioteca de código aberto Python re, isso pode ser alcançado. O código abaixo extrairá dados específicos de faturas em PDF e os imprimirá no console.
from ironpdf import PdfDocument
import re
# Define regex patterns to find invoice number and amount
invoice_number_pattern = r"Invoice\s+(INV/\d{4}/\d{5})"
amount_pattern = r"Total\s+\$\s*([\d,.]+(?:\.\d{2})?)"
# Load the PDF using the PdfDocument.FromFile method
pdf = PdfDocument.FromFile("INV_2022_00001.pdf")
# Extract all text from the PDF
all_text = pdf.ExtractAllText()
# Search for the invoice number and amount in text
invoice_number_match = re.search(invoice_number_pattern, all_text)
amount_match = re.search(amount_pattern, all_text)
# Extract the matching groups if matches are found
invoice_number = invoice_number_match.group(1) if invoice_number_match else "Not found"
amount = amount_match.group(1) if amount_match else "Not found"
# Print the extracted data
print('Invoice Number: ' + invoice_number + '\nAmount: $' + amount)from ironpdf import PdfDocument
import re
# Define regex patterns to find invoice number and amount
invoice_number_pattern = r"Invoice\s+(INV/\d{4}/\d{5})"
amount_pattern = r"Total\s+\$\s*([\d,.]+(?:\.\d{2})?)"
# Load the PDF using the PdfDocument.FromFile method
pdf = PdfDocument.FromFile("INV_2022_00001.pdf")
# Extract all text from the PDF
all_text = pdf.ExtractAllText()
# Search for the invoice number and amount in text
invoice_number_match = re.search(invoice_number_pattern, all_text)
amount_match = re.search(amount_pattern, all_text)
# Extract the matching groups if matches are found
invoice_number = invoice_number_match.group(1) if invoice_number_match else "Not found"
amount = amount_match.group(1) if amount_match else "Not found"
# Print the extracted data
print('Invoice Number: ' + invoice_number + '\nAmount: $' + amount)Este trecho de código utiliza Python e a biblioteca IronPDF para realizar a extração de dados de um documento PDF. O processo começa com a importação das bibliotecas necessárias e a definição de padrões de expressões regulares para identificar o número da fatura e o valor total no conteúdo de texto do PDF. Em seguida, o código carrega o PDF de destino, extrai todo o seu texto e procede à busca por correspondências dos padrões definidos.
Caso sejam encontradas correspondências válidas, o sistema armazena os valores correspondentes ao número da fatura e ao montante; Caso contrário, atribui "Não encontrado". Por fim, o script imprime o número e o valor da fatura extraídos no console, oferecendo uma maneira simplificada de automatizar a extração de dados específicos de documentos PDF, uma tarefa comum em diversos aplicativos de processamento de dados e contabilidade.
4.1. Saída
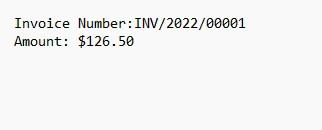 O texto de saída
O texto de saída
5. Conclusão
No cenário empresarial dinâmico de hoje, o Python se destaca como um aliado formidável para organizações que buscam otimizar suas operações financeiras, automatizando a extração de dados cruciais de faturas em PDF. Aproveitando os recursos do Python e da biblioteca IronPDF , as empresas podem reduzir significativamente a entrada manual de dados, mitigar erros, economizar tempo e aumentar a produtividade geral no processo contábil de gerenciamento de faturas. O IronPDF, com seus recursos versáteis, como geração de PDF, conversão de HTML para PDF, edição de PDF, mesclagem, divisão, manipulação de formulários, assinaturas digitais e extração precisa de dados, surge como uma ferramenta poderosa para essas tarefas.
Seguindo procedimentos de configuração simples, os desenvolvedores Python podem integrar rapidamente o IronPDF em seus projetos, revolucionando seus fluxos de trabalho de processamento de faturas e tornando a extração de dados de faturas um processo contínuo e eficiente. O exemplo de código para extração de dados usando o IronPDF pode ser encontrado no exemplo de código detalhado . O tutorial completo sobre extração de dados usando IronPDF for Python está disponível no seguinte tutorial de Python , e para extração de faturas usando C#, visite o tutorial do IronOCR .
Perguntas frequentes
Como posso extrair texto de uma fatura em PDF usando Python?
Você pode usar o método PdfDocument.FromFile do IronPDF para carregar o PDF e o método ExtractAllText para recuperar todo o conteúdo de texto do documento.
Como instalo o IronPDF for Python?
Instale o IronPDF usando o gerenciador de pacotes do Python, pip, com o comando pip install ironpdf .
É possível extrair dados específicos, como números de faturas, de PDFs usando Python?
Sim, usando o IronPDF em conjunto com a biblioteca re do Python, você pode definir padrões de expressões regulares para extrair dados específicos, como números e valores de faturas em PDF.
Quais são as funcionalidades do IronPDF for Python?
O IronPDF oferece recursos como geração de PDF, conversão de HTML para PDF, edição de PDF, mesclagem, divisão, manipulação de formulários, assinaturas digitais e extração de dados.
É possível usar o IronPDF para converter HTML em PDF em Python?
Sim, o IronPDF pode converter conteúdo HTML, incluindo páginas da web, em PDFs de alta qualidade, preservando o layout e o estilo do HTML original.
Como o IronPDF melhora a produtividade na extração de dados de faturas?
O IronPDF automatiza a extração de dados de faturas em PDF, reduzindo a entrada manual de dados e erros, economizando tempo e aumentando a produtividade nas operações financeiras.
É possível editar documentos PDF usando o IronPDF em Python?
Sim, o IronPDF permite que os desenvolvedores editem PDFs existentes, adicionando, modificando ou removendo texto, imagens e elementos interativos.
É possível usar o IronPDF para mesclar ou dividir documentos PDF em Python?
Sim, o IronPDF oferece recursos para mesclar vários documentos PDF em um único arquivo ou dividir um PDF em vários arquivos.
O IronPDF permite adicionar assinaturas digitais a PDFs em Python?
Sim, o IronPDF permite adicionar assinaturas digitais a documentos PDF, garantindo a integridade e a autenticidade dos seus arquivos.
Por que o IronPDF é considerado uma ferramenta robusta para desenvolvedores Python?
O IronPDF é considerado robusto devido às suas amplas capacidades no processamento de diversas operações em PDF, incluindo geração, conversão, edição e extração de dados, que são essenciais para desenvolvedores.
















