
Como extrair um texto específico de um PDF em Python
Este artigo demonstrará como extrair elementos de texto de documentos PDF com a ajuda da biblioteca IronPDF for Python.
IronPDF
Python é uma linguagem de programação que torna simples e rápido para os desenvolvedores criarem interfaces gráficas de usuário. Comparado a outras linguagens, o Python também é muito mais dinâmico para programadores. Por isso, adicionar a biblioteca IronPDF ao Python é um processo simples. Uma infinidade de ferramentas pré-instaladas, incluindo PyQt, wxWidgets, Kivy e muitos outros pacotes e bibliotecas Python, podem ser usadas para construir de forma rápida e segura uma GUI completa. O IronPDF incorpora Python e também permite a integração de recursos de outras estruturas, como o .NET Core.
IronPDF facilita o desenvolvimento web. O principal motivo para isso é a ampla adoção de paradigmas de desenvolvimento web em Python, como Django, Flask e Pyramid. Reddit, Mozilla e Spotify são apenas alguns dos sites e serviços online que utilizaram essas estruturas.
Funcionalidades do IronPDF
Com o IronPDF, é possível criar arquivos PDF a partir de diversas fontes , incluindo HTML, HTML5, ASPX e Razor/MVC View. Oferece a possibilidade de converter páginas HTML e imagens em arquivos PDF .
- Criar PDFs interativos, completar e enviar formulários interativos, dividir e combinar arquivos PDF, extrair texto e imagens, pesquisar texto dentro de arquivos PDF, rasterizar PDFs em imagens, alterar tamanhos de fonte, processamento de linguagem natural usando ChatGPT e converter páginas PDF adequadamente são apenas algumas das atividades com as quais o kit de ferramentas IronPDF pode ajudar. O IronPDF oferece validação de formulários de login HTML com suporte para agentes de usuário, proxies, cookies, cabeçalhos HTTP e variáveis de formulário.
- O IronPDF utiliza nomes de usuário e senhas para fornecer aos usuários acesso a documentos protegidos . Com apenas algumas linhas de código, o IronPDF pode imprimir um arquivo PDF a partir de diversas fontes, incluindo uma string, um fluxo de dados ou uma URL.
Configurar o Python
Configuração do ambiente
Certifique-se de que o Python esteja instalado no seu computador. Para baixar e instalar a versão mais recente do Python compatível com seu sistema operacional, acesse o site oficial do Python . Após instalar o Python, crie um ambiente virtual para separar as necessidades do seu projeto. Crie e gerencie ambientes virtuais com o módulo venv para dar ao seu projeto de conversão um ambiente de trabalho organizado e separado.
Nova iniciativa no PyCharm
Para esta demonstração, recomenda-se o uso do PyCharm como IDE para o desenvolvimento de código Python.
Após iniciar o ambiente de desenvolvimento integrado (IDE) PyCharm, selecione "Novo Projeto".
 PyCharm
PyCharm
Ao selecionar "Novo Projeto", uma nova janela será aberta, permitindo que você defina a localização e o ambiente do projeto. Isso pode ser visto na imagem abaixo.
 Novo Projeto
Novo Projeto
Após escolher a localização do projeto e o caminho do ambiente, clique no botão Criar para iniciar um novo projeto. O programa pode então ser criado em uma nova janela que será aberta como resultado. Para esta lição, será utilizado o Python 3.9.
 Criar Projeto Python
Criar Projeto Python
Requisitos da biblioteca IronPDF
A biblioteca Python IronPDF utiliza amplamente o .NET 6.0. Consequentemente, o ambiente de execução .NET 6.0 deve estar instalado em seu computador para que você possa usar o IronPDF for Python. Pode ser necessário instalar o .NET antes que este módulo Python possa ser usado por usuários de Linux e Mac. Acesse esta página de downloads da Microsoft para obter o ambiente de execução necessário.
Configuração da biblioteca IronPDF
Para gerar, modificar e abrir arquivos com a extensão ".pdf", o pacote "IronPDF" deve ser instalado. Abra uma janela de terminal e digite o seguinte comando para instalar o pacote no PyCharm:
pip install ironpdf
A instalação do pacote ironpdf é mostrada na captura de tela abaixo.
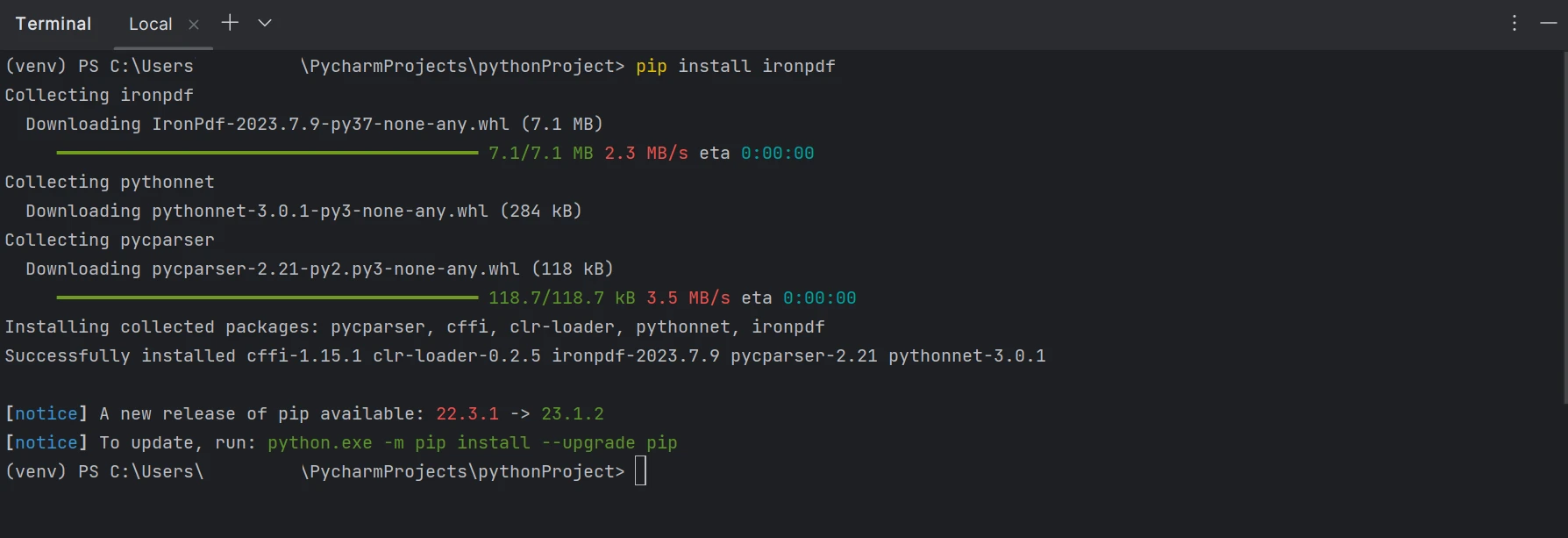 Instalar IronPDF
Instalar IronPDF
Extrair dados específicos de um arquivo PDF
É possível extrair texto de arquivos PDF com a ajuda das bibliotecas IronPDF . O IronPDF oferece diversos métodos de extração de texto. O primeiro método consiste em recuperar todo o conteúdo da página como uma única string. A segunda estratégia consiste em analisar o conteúdo página por página, começando pela primeira. É possível analisar arquivos PDF existentes usando a biblioteca IronPDF . O trecho de código a seguir mostra como usar o IronPDF para inspecionar arquivos PDF em tempo real.
Existem duas opções para extrair informações de um PDF:
- Extração página por página do PDF
- Converter todo o PDF em texto.
Segue abaixo o arquivo PDF de exemplo para este artigo.
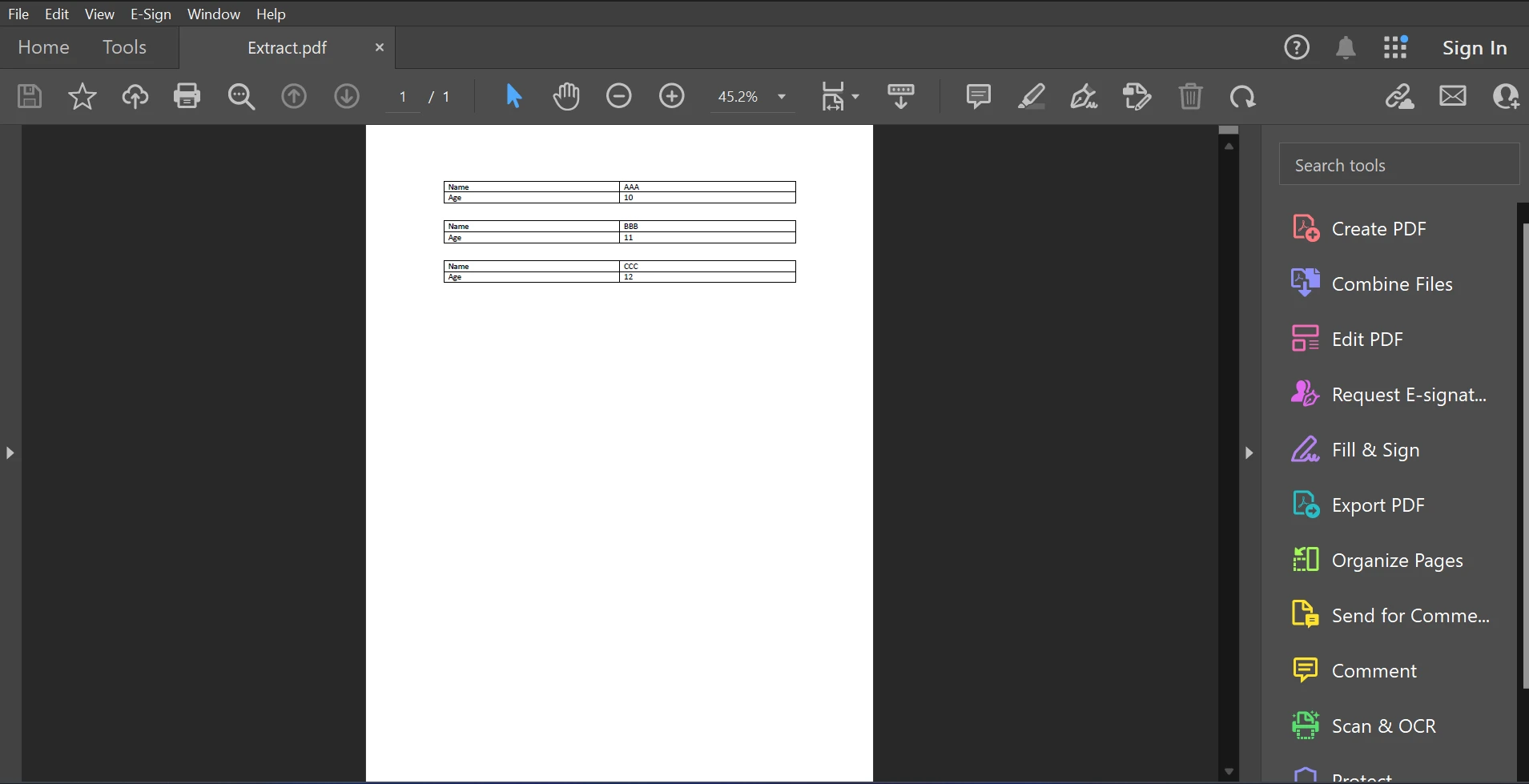 PDF de Entrada
PDF de Entrada
Extração página por página do PDF
O código de exemplo fornecido abaixo mostra como obter dados de um arquivo PDF usando o número da página.
from ironpdf import PdfDocument
# Load the PDF file
pdf = PdfDocument.FromFile('F:\\PDF\\Extract.pdf')
# Extract text from the first page of the PDF document
all_text = pdf.ExtractTextFromPage(0)
# Iterate over each line in the extracted text
for line in all_text.split('\n'):
# Check if the line contains the keyword "Name"
if 'Name' in line:
# Print the line if it contains the keyword
print(line)from ironpdf import PdfDocument
# Load the PDF file
pdf = PdfDocument.FromFile('F:\\PDF\\Extract.pdf')
# Extract text from the first page of the PDF document
all_text = pdf.ExtractTextFromPage(0)
# Iterate over each line in the extracted text
for line in all_text.split('\n'):
# Check if the line contains the keyword "Name"
if 'Name' in line:
# Print the line if it contains the keyword
print(line)O trecho de código mostra como ler um arquivo PDF e construir um objeto PDF usando a função FromFile. Este objeto pode ser usado para acessar o texto e as imagens do PDF. Ao passar o número da página como um parâmetro para a função ExtractTextFromPage, o texto pode ser recuperado de uma página específica. Este método retornará uma sequência de caracteres contendo todas as palavras da página escolhida. Então, use a função split em Python para dividir todas as novas linhas do texto extraído. Em seguida, verifique se cada linha do texto extraído contém as palavras-chave necessárias. Se a palavra-chave corresponder, a linha específica será exibida no prompt de comando. Caso contrário, a linha será ignorada e a próxima linha será passada. O resultado da extração de texto será exibido conforme mostrado abaixo.
Converter todo o PDF em texto.
O exemplo de código a seguir demonstra o primeiro método para obter de forma rápida e simples todo o conteúdo do PDF como uma string.
from ironpdf import PdfDocument
# Load the PDF file
pdf = PdfDocument.FromFile('F:\\PDF\\Extract.pdf')
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Iterate over each line in the extracted text
for line in all_text.split('\n'):
# Check if the line contains the keyword "Name"
if 'Name' in line:
# Print the line if it contains the keyword
print(line)from ironpdf import PdfDocument
# Load the PDF file
pdf = PdfDocument.FromFile('F:\\PDF\\Extract.pdf')
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Iterate over each line in the extracted text
for line in all_text.split('\n'):
# Check if the line contains the keyword "Name"
if 'Name' in line:
# Print the line if it contains the keyword
print(line)O código de exemplo acima demonstra como usar a função FromFile para ler um PDF a partir de um caminho de arquivo existente e convertê-lo em um objeto de arquivo PDF. Como resultado, podemos usar esse objeto leitor de PDF para visualizar o texto e as imagens no PDF. A função ExtractAllText do objeto será usada para extrair dados do PDF em texto simples, convertê-lo em uma string e usar a lógica semelhante à acima para encontrar a palavra-chave específica para exibir o resultado no terminal. Os resultados são apresentados da seguinte forma.
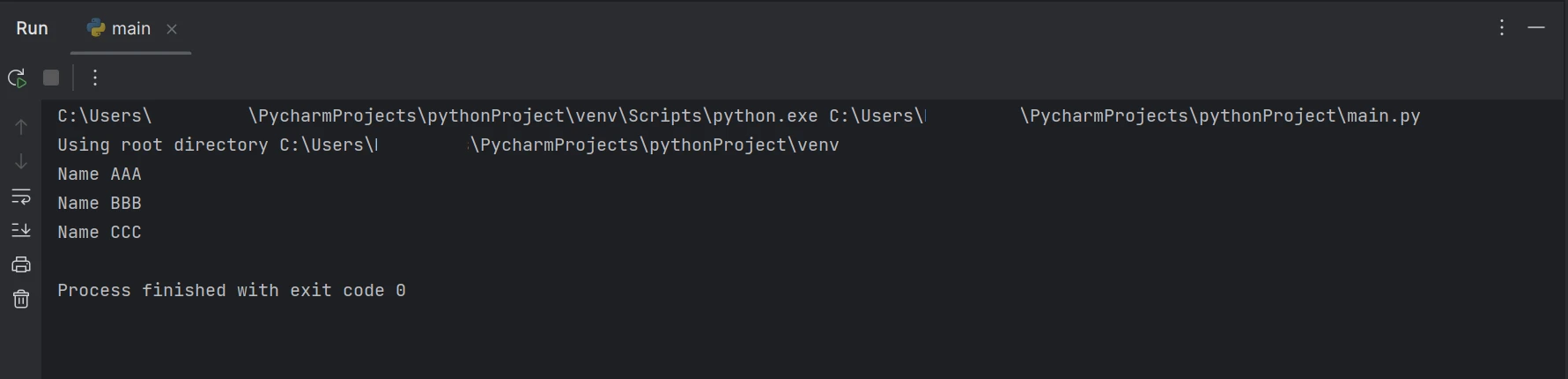 Saída
Saída
O código/saída acima mostra que o documento PDF fornecido contém tanto o nome quanto a idade, mas o resultado exibe apenas o nome presente no documento PDF.
Conclusão
A biblioteca IronPDF oferece mecanismos de segurança robustos para reduzir ameaças e garantir a segurança dos dados. Não se restringe a nenhum navegador específico e é compatível com todos os mais utilizados. Com apenas algumas linhas de código, os programadores podem produzir e ler arquivos PDF rapidamente usando o IronPDF. A biblioteca IronPDF oferece uma variedade de opções de licenciamento, incluindo uma licença de desenvolvedor gratuita e licenças de desenvolvimento adicionais que podem ser adquiridas, para atender às diversas necessidades dos desenvolvedores.
O pacote Lite inclui uma licença perpétua, garantia de reembolso de 30 dias, um ano de manutenção do software e opções de atualização. Essas licenças podem ser usadas em todos os ambientes. Além disso, o IronPDF oferece licenças gratuitas com algumas restrições de redistribuição. Uma licença de avaliação permite que os usuários avaliem o produto sem marca d'água.
Consulte as licenças IronPDF disponíveis para obter mais informações sobre licenciamento comercial.
Perguntas frequentes
Como posso extrair um texto específico de um PDF usando Python?
Você pode usar a biblioteca Python do IronPDF para extrair texto de PDFs. Ela oferece funcionalidades para extrair texto página por página usando ExtractTextFromPage ou do documento inteiro usando ExtractAllText .
Quais são os passos para configurar o IronPDF em um projeto Python?
Primeiro, instale o runtime do .NET 6.0, caso ainda não esteja instalado. Em seguida, configure o Python em seu ambiente de desenvolvimento, como o PyCharm. Instale o IronPDF usando pip install ironpdf para começar a integrar as funcionalidades de PDF ao seu projeto.
O IronPDF é compatível com frameworks como Django e Flask?
Sim, o IronPDF integra-se bem com frameworks de desenvolvimento web em Python, como Django e Flask, oferecendo opções versáteis para lidar com PDFs em aplicações web.
Quais opções de licenciamento estão disponíveis para usar o IronPDF com Python?
O IronPDF oferece uma variedade de opções de licenciamento, incluindo uma licença de desenvolvedor gratuita para uso pessoal e várias licenças comerciais que fornecem recursos e benefícios adicionais.
Como posso instalar o IronPDF for Python?
Instale o IronPDF usando o gerenciador de pacotes pip, executando o comando pip install ironpdf no seu terminal ou prompt de comando.
Qual ambiente de desenvolvimento é recomendado para usar o IronPDF com Python?
O PyCharm é um ambiente de desenvolvimento integrado (IDE) recomendado para o desenvolvimento de aplicações Python utilizando o IronPDF, devido ao seu conjunto abrangente de recursos e suporte para Python.
Quais são algumas das principais características da biblioteca IronPDF for Python?
O IronPDF for Python oferece recursos como criação de PDFs a partir de HTML, conversão de imagens em PDFs, manipulação de formulários, extração de texto e imagem e fusão de PDFs.
Quão segura é a biblioteca IronPDF para manipulação de arquivos PDF?
O IronPDF foi projetado com recursos de segurança robustos, garantindo o manuseio seguro de arquivos PDF. Ele oferece suporte à criptografia e proteção por senha para salvaguardar informações confidenciais.
















