Comment extraire du texte spécifique d'un PDF en Python
Cet article démontrera comment extraire des éléments de texte à partir de documents PDF grâce à la bibliothèque IronPDF for Python.
IronPDF
Python est un langage de programmation qui permet aux développeurs de créer des interfaces graphiques rapidement et facilement. Comparé à d'autres langages, Python est également beaucoup plus dynamique pour les programmeurs. Pour cette raison, l'ajout de la bibliothèque IronPDF à Python est un processus simple. Une multitude d'outils pré-installés, y compris PyQt, wxWidgets, Kivy, et de nombreux autres packages et bibliothèques Python, peuvent être utilisés pour créer rapidement et en toute sécurité une interface utilisateur graphique complète. IronPDF intègre Python et permet également l'intégration de fonctionnalités à partir d'autres frameworks, tels que .NET Core.
IronPDF facilite le développement web. La principale raison en est l'adoption généralisée des paradigmes de développement web en Python comme Django, Flask et Pyramid. Reddit, Mozilla et Spotify ne sont que quelques-uns des sites web et services en ligne qui ont utilisé ces frameworks.
Fonctionnalités d'IronPDF
- Avec IronPDF, les fichiers PDF peuvent être créés à partir de diverses sources, y compris HTML, HTML5, ASPX, et Razor/MVC View. Il offre la possibilité de convertir des pages HTML et des images en fichiers PDF.
- Créer des PDFs interactifs, remplir et soumettre des formulaires interactifs, découper et combiner des fichiers PDF, extraire du texte et des images, rechercher du texte dans les fichiers PDF, rasteriser les PDFs en images, modifier la taille des polices, traitement du langage naturel utilisant ChatGPT, et convertir les pages PDF sont juste quelques-unes des activités que la boîte à outils IronPDF peut aider à réaliser.
- IronPDF offre une validation du formulaire de connexion HTML avec prise en charge des agents utilisateurs, des proxys, des cookies, des en-têtes HTTP et des variables de formulaire.
- IronPDF utilise des noms d'utilisateur et des mots de passe pour donner aux utilisateurs accès à des documents protégés.
- Avec seulement quelques lignes de code, IronPDF peut imprimer un fichier PDF à partir de diverses sources, y compris une chaîne, un flux ou une URL.
Configurer Python
Configuration de l'environnement
Assurez-vous que Python est installé sur votre ordinateur. Pour télécharger et installer la version la plus récente de Python compatible avec votre système d'exploitation, visitez le site officiel de Python. Créez un environnement virtuel une fois Python installé pour séparer les besoins de votre projet. Créez et gérez des environnements virtuels avec le module venv pour donner à votre projet de conversion un espace de travail propre et séparé.
Nouvelle initiative dans PyCharm
Pour cette démonstration, PyCharm est recommandé comme IDE pour développer du code Python.
Après avoir démarré l'IDE PyCharm, sélectionnez "Nouveau Projet".
 PyCharm
PyCharm
Une nouvelle fenêtre s'ouvrira lorsque vous choisirez "Nouveau Projet", vous permettant de définir l'emplacement du projet et l'environnement. Cela peut être vu dans l'image ci-dessous.
 Nouveau projet
Nouveau projet
Après avoir choisi l'emplacement du projet et le chemin de l'environnement, cliquez sur le bouton Créer pour commencer un nouveau projet. Le programme peut alors être créé dans une nouvelle fenêtre qui s'ouvrira en conséquence. Pour cette leçon, Python 3.9 est utilisé.
 Créer un projet Python
Créer un projet Python
Exigence de la bibliothèque IronPDF
La bibliothèque Python IronPDF utilise principalement .NET 6.0. Par conséquent, le runtime .NET 6.0 doit être installé sur votre ordinateur pour utiliser IronPDF for Python. Il pourrait être nécessaire d'installer .NET avant que ce module Python puisse être utilisé par les utilisateurs Linux et Mac. Visitez cette page de téléchargement de Microsoft pour obtenir l'environnement d'exécution nécessaire.
Configuration de la bibliothèque IronPDF
Pour générer, modifier et ouvrir des fichiers avec l'extension ".pdf", le package "IronPDF" doit être installé. Ouvrez une fenêtre de terminal et entrez la commande suivante pour installer le package dans PyCharm :
pip install ironpdfpip install ironpdfL'installation du package ironpdf est illustrée dans la capture d'écran ci-dessous.
 Installation IronPDF
Installation IronPDF
Extraire des données spécifiques du fichier PDF
Il est possible d'extraire du texte des fichiers PDF avec l'aide des bibliothèques IronPDF. IronPDF offre plusieurs méthodes d'extraction de texte. La première méthode implique la récupération de tout le contenu de la page en une seule chaîne. La deuxième stratégie consiste à passer en revue le contenu page par page, en commençant par la première page. Les fichiers PDF existants peuvent être explorés à l'aide de la bibliothèque IronPDF. Le fragment de code suivant montre comment utiliser IronPDF pour inspecter les fichiers PDF en direct.
Il y a deux options pour extraire des informations d'un PDF :
- Extraction page par page à partir du PDF
- Conversion de l'ensemble du PDF en texte
Voici le fichier PDF échantillon pour cet article disponible ci-dessous.
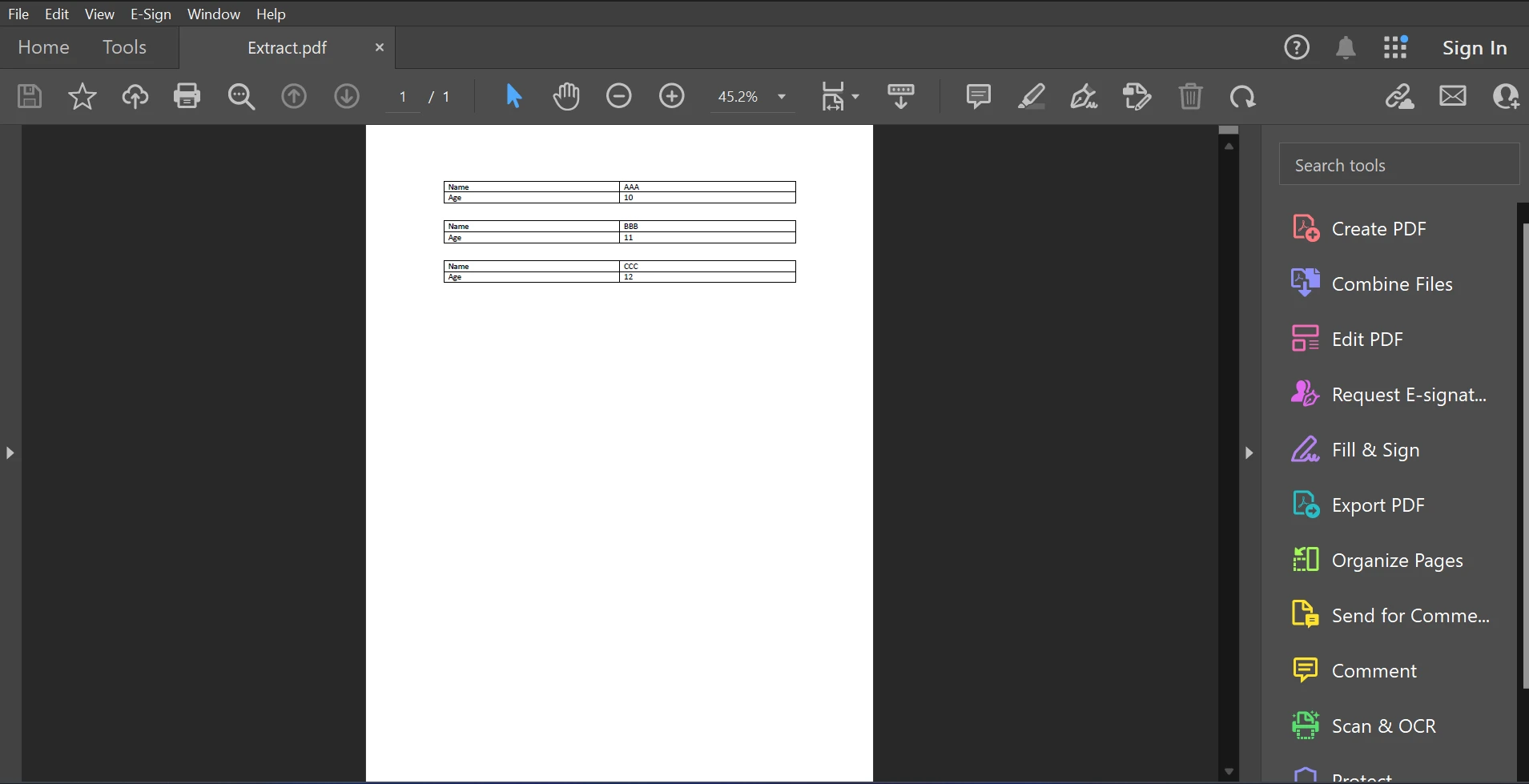 PDF d'entrée
PDF d'entrée
Extraction Page par Page à partir du PDF
Le code exemple ci-dessous montre comment obtenir des données à partir d'un fichier PDF en utilisant le numéro de page.
from ironpdf import PdfDocument
# Load the PDF file
pdf = PdfDocument.FromFile('F:\\PDF\\Extract.pdf')
# Extract text from the first page of the PDF document
all_text = pdf.ExtractTextFromPage(0)
# Iterate over each line in the extracted text
for line in all_text.split('\n'):
# Check if the line contains the keyword "Name"
if 'Name' in line:
# Print the line if it contains the keyword
print(line)from ironpdf import PdfDocument
# Load the PDF file
pdf = PdfDocument.FromFile('F:\\PDF\\Extract.pdf')
# Extract text from the first page of the PDF document
all_text = pdf.ExtractTextFromPage(0)
# Iterate over each line in the extracted text
for line in all_text.split('\n'):
# Check if the line contains the keyword "Name"
if 'Name' in line:
# Print the line if it contains the keyword
print(line)L'extrait de code montre comment lire un fichier PDF et construire un objet PDF à l'aide de la fonction FromFile. Cet objet peut être utilisé pour accéder au texte et aux images du PDF. En passant le numéro de page comme paramètre à la fonction ExtractTextFromPage, le texte peut être récupéré à partir d'une page spécifique. Une chaîne contenant tous les mots de la page choisie sera retournée par cette méthode. Ensuite, utilisez la fonction split en Python pour séparer toutes les nouvelles lignes du texte extrait. Après cela, vérifiez si chaque ligne dans le texte extrait contient les mots-clés requis. Si le mot-clé correspond, il affichera la ligne spécifique dans le terminal. Sinon, il ignorera cette ligne et passera à la ligne suivante. L'extraction du texte apparaîtra comme ci-dessous.
Conversion de l'ensemble du PDF en texte
L'exemple de code suivant démontre la première méthode pour obtenir rapidement et facilement tout le contenu du PDF sous forme de chaîne.
from ironpdf import PdfDocument
# Load the PDF file
pdf = PdfDocument.FromFile('F:\\PDF\\Extract.pdf')
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Iterate over each line in the extracted text
for line in all_text.split('\n'):
# Check if the line contains the keyword "Name"
if 'Name' in line:
# Print the line if it contains the keyword
print(line)from ironpdf import PdfDocument
# Load the PDF file
pdf = PdfDocument.FromFile('F:\\PDF\\Extract.pdf')
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Iterate over each line in the extracted text
for line in all_text.split('\n'):
# Check if the line contains the keyword "Name"
if 'Name' in line:
# Print the line if it contains the keyword
print(line)L'exemple de code ci-dessus montre comment utiliser la fonction FromFile pour lire un PDF à partir d'un chemin de fichier existant et le convertir en un objet fichier PDF. En conséquence, nous pouvons utiliser cet objet lecteur PDF pour voir le texte et les images dans le PDF. La fonction ExtractAllText de l'objet sera utilisée pour extraire des données du PDF en texte brut, les convertir en chaîne de caractères et utiliser une logique similaire à celle ci-dessus pour trouver le mot-clé spécifique afin d'afficher le résultat dans le terminal. Les résultats sont affichés comme suit.
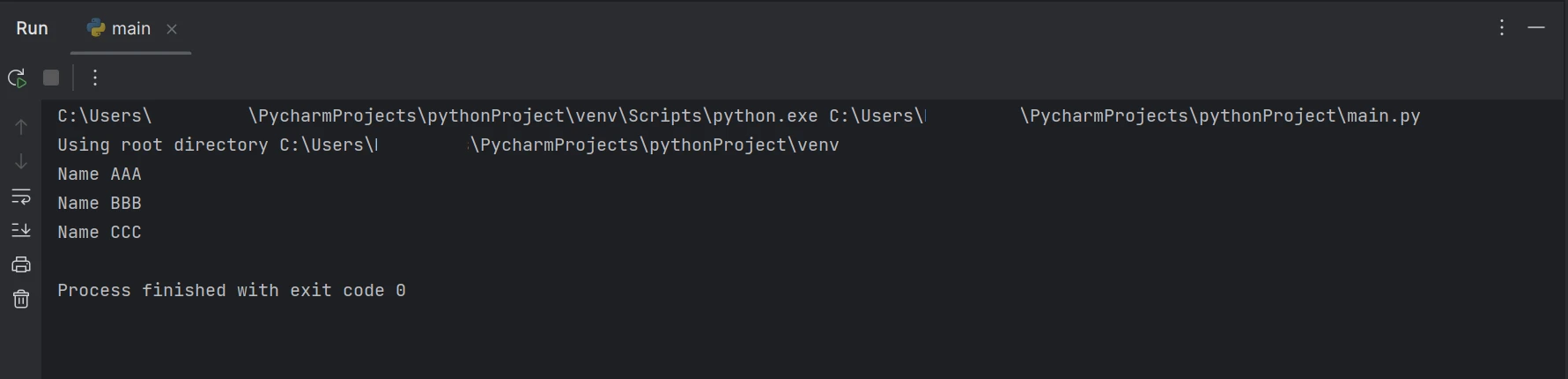 Résultat
Résultat
Le code/sortie ci-dessus montre que le document PDF donné contient à la fois le nom et l'âge, mais le résultat ne montre que le nom disponible dans le document PDF.
Conclusion
Des mécanismes de sécurité solides sont offerts par la bibliothèque IronPDF pour réduire les menaces et garantir la sécurité des données. Il n'est pas limité à un seul navigateur et est compatible avec tous les navigateurs largement utilisés. Avec seulement quelques lignes de code, les programmeurs peuvent rapidement produire et lire des fichiers PDF avec IronPDF. La bibliothèque IronPDF offre une gamme d'options de licence, y compris une licence de développeur gratuite et des licences de développement supplémentaires disponibles à l'achat, pour répondre aux besoins diversifiés des développeurs.
Une licence perpétuelle, une garantie de remboursement de 30 jours, une année de maintenance logicielle, et des options de mise à niveau sont incluses dans le package Lite. Ces licences peuvent être utilisées dans tous les environnements. De plus, IronPDF propose des licences gratuites avec certaines restrictions de redistribution. Une licence d'essai permet aux utilisateurs d'évaluer le produit sans filigrane.
Veuillez consulter les licences IronPDF disponibles pour plus d'informations sur la commercialisation des licences.
Questions Fréquemment Posées
Comment puis-je extraire du texte spécifique d'un PDF en utilisant Python ?
Vous pouvez utiliser la bibliothèque Python d'IronPDF pour extraire du texte de PDF. Elle fournit des fonctionnalités pour extraire du texte page par page en utilisant ExtractTextFromPage ou de l'ensemble du document en utilisant ExtractAllText.
Quelles sont les étapes pour configurer IronPDF dans un projet Python ?
Tout d'abord, installez le runtime .NET 6.0 s'il n'est pas déjà installé. Ensuite, configurez Python dans votre environnement de développement, tel que PyCharm. Installez IronPDF en utilisant pip install ironpdf pour commencer à intégrer des fonctionnalités PDF dans votre projet.
IronPDF est-il compatible avec des frameworks comme Django et Flask ?
Oui, IronPDF s'intègre bien aux frameworks de développement web Python tels que Django et Flask, offrant des options polyvalentes pour la gestion des PDF dans les applications web.
Quelles options de licence sont disponibles pour utiliser IronPDF avec Python ?
IronPDF propose une gamme d'options de licence, y compris une licence développeur gratuite pour un usage personnel et diverses licences commerciales qui fournissent des fonctionnalités et des avantages supplémentaires.
Comment puis-je installer IronPDF for Python ?
Installez IronPDF en utilisant le Package Manager pip en exécutant la commande pip install ironpdf dans votre terminal ou invite de commandes.
Quel environnement de développement est recommandé pour utiliser IronPDF avec Python ?
PyCharm est un environnement de développement intégré (IDE) recommandé pour développer des applications Python using IronPDF, en raison de son ensemble de fonctionnalités complet et de son support Python.
Quelles sont les principales fonctionnalités de la bibliothèque IronPDF for Python ?
IronPDF for Python offre des fonctionnalités telles que la création de PDFs à partir de HTML, la conversion d'images en PDFs, la gestion de formulaires, l'extraction de texte et d'images, et la fusion de PDF.
Quelle est la sécurité de la bibliothèque IronPDF pour la gestion des fichiers PDF ?
IronPDF est conçu avec des fonctionnalités de sécurité robustes, assurant une gestion sécurisée des fichiers PDF. Il supporte le chiffrement et la protection par mot de passe pour protéger les informations sensibles.