
如何從 Python 中的 PDF 提取特定文本
本文將示範如何使用IronPDF 適用於 Python 庫從 PDF 文件中提取文字元素。
IronPDF
Python 是一種程式語言,它使開發人員能夠輕鬆快速地建立圖形使用者介面。 與其他語言相比,Python 對程式設計師來說也更具動態性。 因此,將IronPDF庫添加到 Python 中是一個簡單的過程。 預先安裝了大量工具,包括 PyQt、wxWidgets、Kivy 以及許多其他軟體包和 Python 庫,可用於快速、安全地建立完整的 GUI。 IronPDF整合了 Python,並且允許整合來自其他框架(例如.NET Core)的功能。
IronPDF讓網站開發更輕鬆。 主要原因是像 Django、Flask 和 Pyramid 這樣的 Python Web 開發範式得到了廣泛應用。 Reddit、Mozilla 和 Spotify 只是眾多使用這些框架的網站和線上服務的例子。
IronPDF功能
- 使用IronPDF,可以從各種來源建立PDF 文件,包括 HTML、HTML5、ASPX 和Razor/MVC View。 它能夠將 HTML 頁面和圖像轉換為 PDF 文件。
- IronPDF 工具包可以幫助完成許多操作,例如建立互動式 PDF、填寫和提交互動式表單、拆分和合併PDF 文件、提取文字和圖像、在 PDF 文件中搜尋文字、將 PDF 柵格化為圖像、更改字體大小、使用 ChatGPT 進行自然語言處理以及轉換IronPDF頁面屬性等等。 IronPDF提供 HTML 登入表單驗證,支援使用者代理、代理、cookie、HTTP 標頭和表單變數。 IronPDF使用使用者名稱和密碼為使用者提供受保護文件的存取權限。
- 只需幾行程式碼, IronPDF即可從各種來源(包括字串、流或 URL)列印 PDF 檔案。
安裝 Python
環境配置
請確保您的電腦上已安裝 Python。 若要下載並安裝與您的作業系統相容的最新版 Python,請造訪Python 官方網站。 安裝好 Python 後,創建一個虛擬環境,將專案的需求隔離。 使用 venv 模組建立和管理虛擬環境,為您的轉換專案提供一個整潔、獨立的工作場所。
PyCharm 的新舉措
本次示範推薦使用 PyCharm 作為 Python 程式碼開發 IDE。
啟動 PyCharm IDE 後,選擇"新建專案"。
 PyCharm
PyCharm
選擇"新建項目"後,將開啟一個新窗口,您可以在其中設定項目的位置和環境。 這可能在下圖中看到。
 新項目
新項目
選擇專案位置和環境路徑後,按一下"建立"按鈕開始新專案。 然後,可以在新開啟的視窗中建立該程式。 本課程使用 Python 3.9 版本。
 創建Python項目
創建Python項目
IronPDF庫要求
Python 函式庫IronPDF主要使用.NET 6.0。因此,要使用IronPDF 適用於 Python,您的電腦上必須安裝.NET 6.0 執行階段。 Linux 和 Mac 使用者可能需要先安裝.NET才能使用此 Python 模組。 請造訪微軟的這個下載頁面,以取得所需的執行環境。
IronPDF庫設定
若要產生、修改和開啟副檔名為".pdf"的文件,必須安裝"IronPDF"軟體包。 開啟終端機窗口,輸入以下指令在 PyCharm 中安裝軟體包:
pip install ironpdfpip install ironpdf下面截圖顯示了 ironpdf 軟體包的安裝過程。
 安裝IronPDF
安裝IronPDF
從PDF文件中提取特定數據
借助IronPDF庫,可以從 PDF 文件中提取文字。 IronPDF提供多種文字擷取方法。 第一種方法是將整個頁面的內容作為單一字串檢索出來。 第二種策略是逐頁瀏覽內容,從第一頁開始。 可以使用IronPDF庫來分析現有的 PDF 文件。 下面的程式碼片段展示如何使用IronPDF檢查即時 PDF 檔案。
從PDF文件中提取資訊有兩種方法:
- 從PDF文件中逐頁提取內容
- 將整個 PDF 檔案轉換為文字
本文的範例PDF文件如下所示。
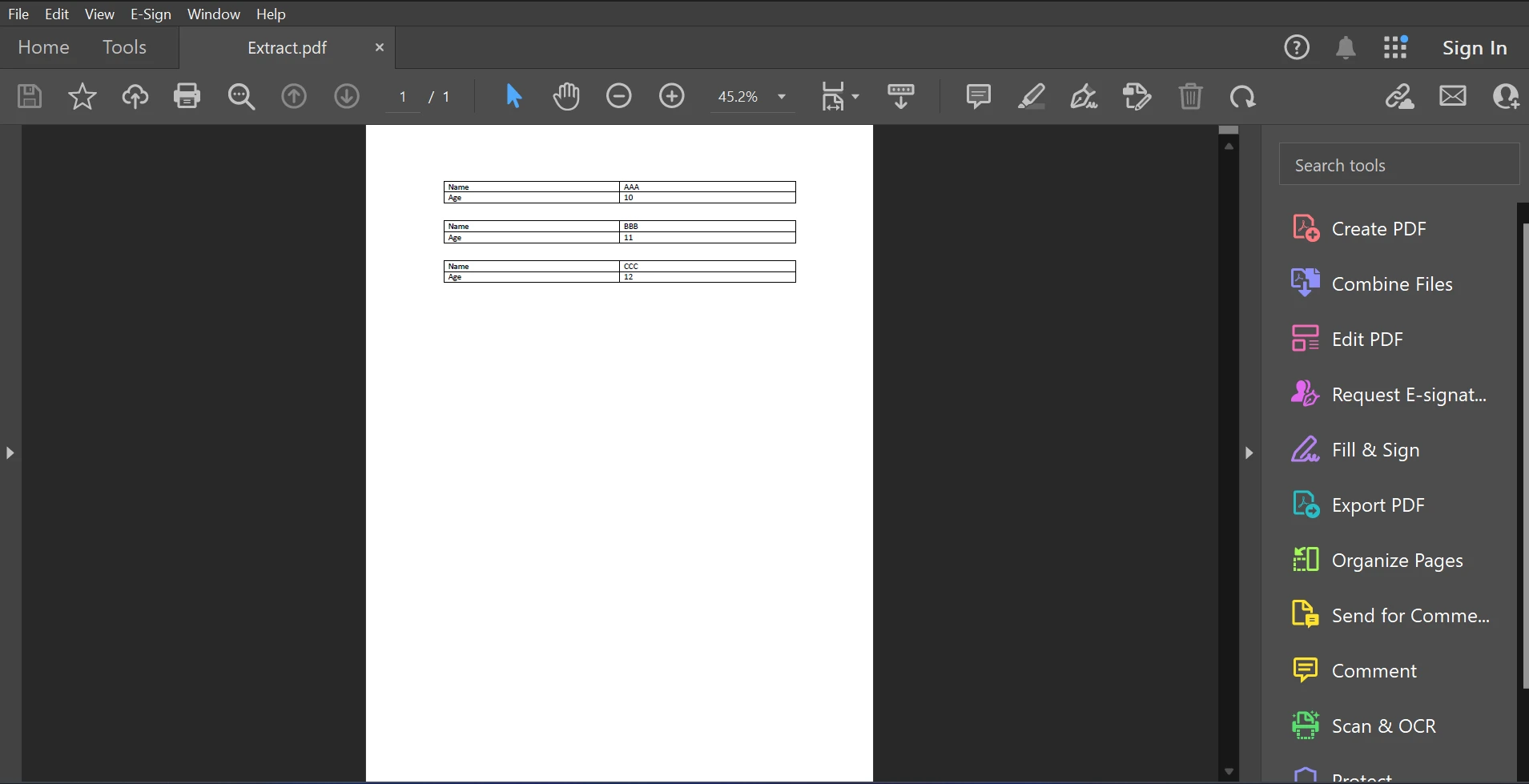 輸入PDF
輸入PDF
從PDF文件中逐頁提取內容
下面提供的範例程式碼展示如何使用頁碼從 PDF 檔案中取得資料。
from ironpdf import PdfDocument
# Load the PDF file
pdf = PdfDocument.FromFile('F:\\PDF\\Extract.pdf')
# Extract text from the first page of the PDF document
all_text = pdf.ExtractTextFromPage(0)
# Iterate over each line in the extracted text
for line in all_text.split('\n'):
# Check if the line contains the keyword "Name"
if 'Name' in line:
# Print the line if it contains the keyword
print(line)from ironpdf import PdfDocument
# Load the PDF file
pdf = PdfDocument.FromFile('F:\\PDF\\Extract.pdf')
# Extract text from the first page of the PDF document
all_text = pdf.ExtractTextFromPage(0)
# Iterate over each line in the extracted text
for line in all_text.split('\n'):
# Check if the line contains the keyword "Name"
if 'Name' in line:
# Print the line if it contains the keyword
print(line)此程式碼片段展示如何使用 FromFile 函數讀取 PDF 檔案並建立 PDF 物件。 該物件可用於存取 PDF 的文字和圖像。 透過將頁碼作為參數傳遞給 ExtractTextFromPage 函數,可以從特定頁面檢索文字。 此方法將傳回包含所選頁面上所有單字的字串。 然後,使用 Python 中的 split 函數從提取的文字中拆分所有換行符。 之後,檢查提取文字中的每一行是否包含所需的關鍵字。 如果關鍵字匹配,則會在命令提示字元中顯示特定行。 否則,它將忽略該行並繼續處理下一行。文字擷取的輸出結果如下所示。
將整個 PDF 檔案轉換為文字
以下程式碼範例示範了快速簡單地將所有 PDF 內容作為字串取得的第一種方法。
from ironpdf import PdfDocument
# Load the PDF file
pdf = PdfDocument.FromFile('F:\\PDF\\Extract.pdf')
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Iterate over each line in the extracted text
for line in all_text.split('\n'):
# Check if the line contains the keyword "Name"
if 'Name' in line:
# Print the line if it contains the keyword
print(line)from ironpdf import PdfDocument
# Load the PDF file
pdf = PdfDocument.FromFile('F:\\PDF\\Extract.pdf')
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Iterate over each line in the extracted text
for line in all_text.split('\n'):
# Check if the line contains the keyword "Name"
if 'Name' in line:
# Print the line if it contains the keyword
print(line)上面的範例程式碼示範如何使用 FromFile 函數從現有檔案路徑讀取 PDF 並將其轉換為 PDF 檔案物件。 因此,我們可以使用此 PDF 閱讀器物件來查看 PDF 中的文字和圖像。 該物件的 ExtractAllText 函數將用於從 PDF 中提取資料到純文本,將其轉換為字串,並使用與上述類似的邏輯來查找特定關鍵字,以便在終端中顯示結果。 結果顯示如下。
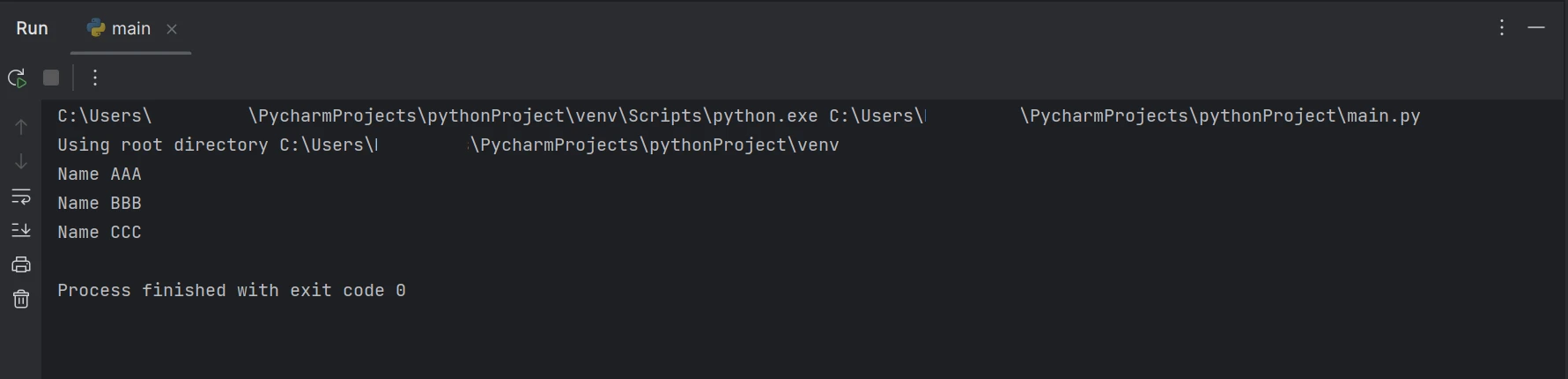 輸出
輸出
上述程式碼/輸出表明,給定的 PDF 文件包含姓名和年齡,但結果僅顯示 PDF 文件中可用的名稱。
結論
IronPDF庫提供強大的安全機制,以減少威脅並確保資料安全。 它不局限於任何特定瀏覽器,並且兼容所有廣泛使用的瀏覽器。 只需幾行程式碼,程式設計師就可以使用IronPDF快速產生和讀取 PDF 文件。 IronPDF庫提供一系列許可選項,包括免費的開發者許可證和可供購買的額外開發許可證,以滿足開發者的各種需求。
Lite套餐包含永久許可證、30 天退款保證、一年軟體維護和升級選項。 這些許可證可在所有環境下使用。 此外, IronPDF還提供一些帶有再分發限制的免費許可證。 試用許可證允許使用者在不帶浮水印的情況下評估產品。
請查看IronPDF提供的許可證,以了解更多關於商業許可的資訊。
常見問題
如何使用 Python 從 PDF 中提取特定文本?
您可以使用 IronPDF 的 Python 庫從 PDF 中提取文本。它提供了功能,可以使用 ExtractTextFromPage 按頁提取文本,或使用 ExtractAllText 從整個文檔中提取文本。
在 Python 項目中設置 IronPDF 的步驟是什麼?
首先,如果尚未安裝,請安裝 .NET 6.0 運行時。然後,在您的開發環境中設置 Python,例如 PyCharm。使用 pip install ironpdf 安裝 IronPDF,以開始將 PDF 功能集成到您的項目中。
IronPDF 與 Django 和 Flask 等框架兼容嗎?
是的,IronPDF 與 Django 和 Flask 等 Python 網路開發框架集成良好,提供了處理 Web 應用程序中的 PDF 的多功能選擇。
有哪些使用 IronPDF 與 Python 的許可選項?
IronPDF 提供多種許可選項,包括個人使用的免費開發者許可和提供附加功能和利益的各種商業許可。
如何安裝 IronPDF for Python?
使用 pip 包管理器安裝 IronPDF,方法是在終端或命令提示符中運行命令 pip install ironpdf。
推薦的開發環境是什麼,適用於使用 IronPDF 與 Python?
PyCharm 是開發 Python 應用程序使用 IronPDF 的推薦集成開發環境(IDE),因為它具有全面的功能和對 Python 的支持。
IronPDF 的 Python 庫有哪些關鍵功能?
IronPDF for Python 提供創建 PDF、從 HTML 轉換圖像為 PDF、表單處理、文本和圖像提取以及 PDF 合併等功能。
IronPDF 庫在處理 PDF 文件時的安全性如何?
IronPDF 設計具有強大的安全功能,確保 PDF 文件的安全處理。它支持加密和密碼保護以保護敏感信息。
















