
Python을 사용하여 PDF에서 특정 텍스트를 추출하는 방법
이 글에서는 Python용 IronPDF 라이브러리를 사용하여 PDF 문서에서 텍스트 요소를 추출하는 방법을 설명합니다.
IronPDF
Python은 개발자가 그래픽 사용자 인터페이스를 간단하고 빠르게 만들 수 있도록 해주는 프로그래밍 언어입니다. 다른 언어들과 비교했을 때, Python은 프로그래머에게 훨씬 더 역동적인 환경을 제공합니다. 이러한 이유로 IronPDF 라이브러리를 Python에 추가하는 과정은 간단합니다. PyQt, wxWidgets, Kivy를 비롯한 다양한 사전 설치된 도구와 여러 추가 패키지 및 Python 라이브러리를 사용하여 완벽한 GUI를 신속하고 안전하게 구축할 수 있습니다. IronPDF Python을 통합하고 있으며 .NET Core 와 같은 다른 프레임워크의 기능 통합도 허용합니다.
IronPDF 웹 개발을 더 쉽게 만들어줍니다. 주된 이유는 Django, Flask, Pyramid와 같은 Python 웹 개발 패러다임이 널리 채택되었기 때문입니다. 레딧, 모질라, 스포티파이는 이러한 프레임워크를 사용한 웹사이트 및 온라인 서비스 중 일부에 불과합니다.
IronPDF 기능
IronPDF 사용하면 HTML, HTML5, ASPX 및 Razor/MVC 뷰를 포함한 다양한 소스에서 PDF 파일을 생성 할 수 있습니다. 이 프로그램은 HTML 페이지 와 이미지를 PDF 파일로 변환하는 기능을 제공합니다.
- 인터랙티브 PDF 생성, 인터랙티브 폼 완료 및 제출, PDF 파일 분할 및 병합, 텍스트 및 이미지 추출, PDF 파일 내 텍스트 검색, PDF를 이미지로 래스터화, 글꼴 크기 변경, ChatGPT를 사용한 자연어 처리, PDF 페이지 올바르게 변환 등은 IronPDF 도구 모음을 통해 수행할 수 있는 작업 중 일부입니다. IronPDF 사용자 에이전트, 프록시, 쿠키, HTTP 헤더 및 폼 변수를 지원하는 HTML 로그인 폼 유효성 검사 기능을 제공합니다. IronPDF 사용자 이름과 비밀번호를 사용하여 사용자가 보호된 문서 에 접근할 수 있도록 합니다. IronPDF 단 몇 줄의 코드로 문자열, 스트림 또는 URL을 포함한 다양한 소스에서 PDF 파일을 인쇄할 수 있습니다.
Python 설정
환경 구성
컴퓨터에 Python이 설치되어 있는지 확인하세요. 운영 체제와 호환되는 최신 버전의 Python을 다운로드하고 설치하려면 Python 공식 웹사이트 로 이동하세요. Python 설치가 완료되면 프로젝트에 필요한 환경을 분리하기 위해 가상 환경을 생성하세요. 변환 프로젝트에 깔끔하고 별도의 작업 공간을 제공하기 위해 venv 모듈로 가상 환경을 생성하고 관리하세요.
PyCharm의 새로운 기능
이 데모에서는 Python 코드 개발을 위한 IDE로 PyCharm을 사용하는 것을 권장합니다.
PyCharm IDE를 실행한 후 "새 프로젝트"를 선택하세요.
 PyCharm
PyCharm
"새 프로젝트"를 선택하면 새 창이 열리고, 여기에서 프로젝트의 위치와 환경을 설정할 수 있습니다. 이는 아래 이미지에서 확인할 수 있습니다.
 새 프로젝트
새 프로젝트
프로젝트 위치와 환경 경로를 선택한 후, 만들기 버튼을 클릭하여 새 프로젝트를 시작하세요. 그러면 프로그램이 새 창에서 열리게 됩니다. 이번 수업에서는 Python 3.9 버전을 사용합니다.
 Python 프로젝트 생성
Python 프로젝트 생성
IronPDF 라이브러리 요구 사항
Python 라이브러리인 IronPDF 대부분 .NET 6.0을 사용합니다. 따라서 Python용 IronPDF 사용하려면 컴퓨터에 .NET 6.0 런타임이 설치되어 있어야 합니다. 리눅스 및 맥 사용자는 이 Python 모듈을 사용하기 전에 .NET 설치해야 할 수도 있습니다. 필요한 런타임 환경을 다운로드하려면 Microsoft의 다운로드 페이지를 방문하세요.
IronPDF 라이브러리 설정
".pdf" 확장자를 가진 파일을 생성, 수정, 열기 하려면 "IronPDF" 패키지를 설치해야 합니다. 터미널 창을 열고 다음 명령어를 입력하여 PyCharm에 패키지를 설치하세요.
pip install ironpdf
아래 스크린샷에는 ironpdf 패키지의 설치가 나와 있습니다.
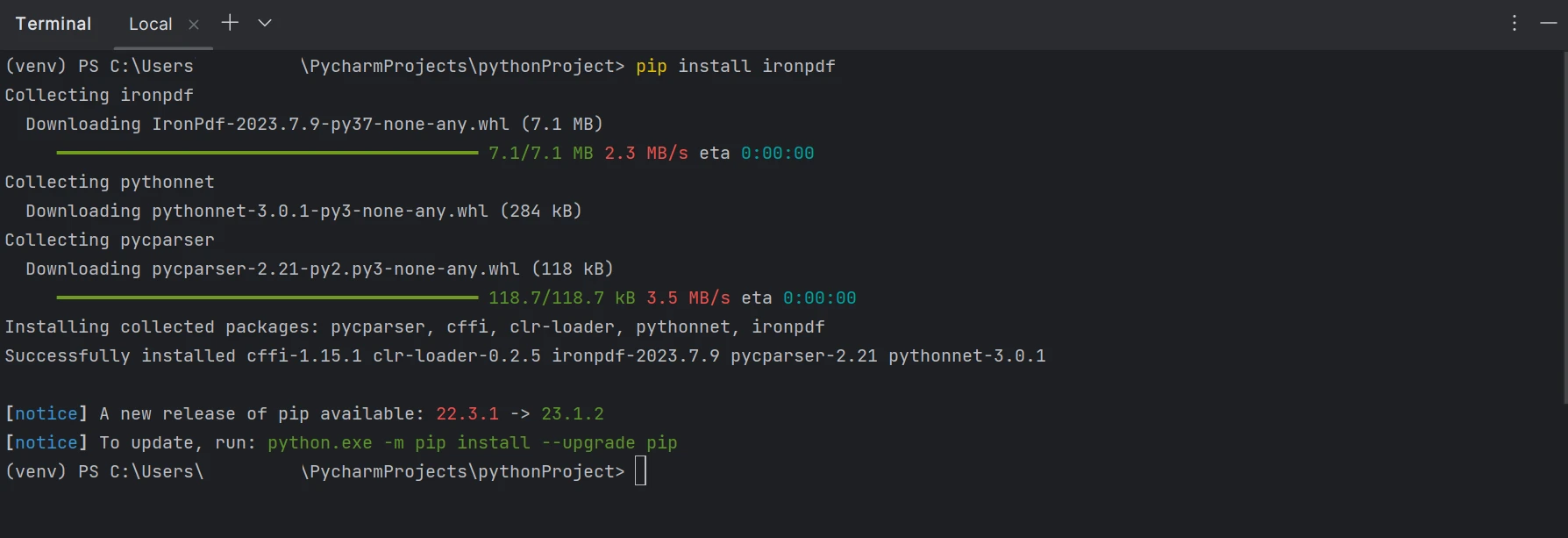 IronPDF 설치
IronPDF 설치
PDF 파일에서 특정 데이터 추출
IronPDF 라이브러리를 사용하면 PDF 파일에서 텍스트를 추출할 수 있습니다. IronPDF 다양한 텍스트 추출 방법을 제공합니다. 첫 번째 방법은 페이지 전체 내용을 하나의 문자열로 가져오는 것입니다. 두 번째 전략은 첫 페이지부터 시작하여 콘텐츠를 페이지별로 하나씩 살펴보는 것입니다. 기존 PDF 파일은 IronPDF 라이브러리를 사용하여 조사할 수 있습니다. 다음 코드 조각은 IronPDF 사용하여 실시간 PDF 파일을 검사하는 방법을 보여줍니다.
PDF에서 정보를 추출하는 방법에는 두 가지가 있습니다.
- PDF에서 페이지별 추출
- PDF 전체를 텍스트로 변환
이 기사의 샘플 PDF 파일은 아래에서 확인하실 수 있습니다.
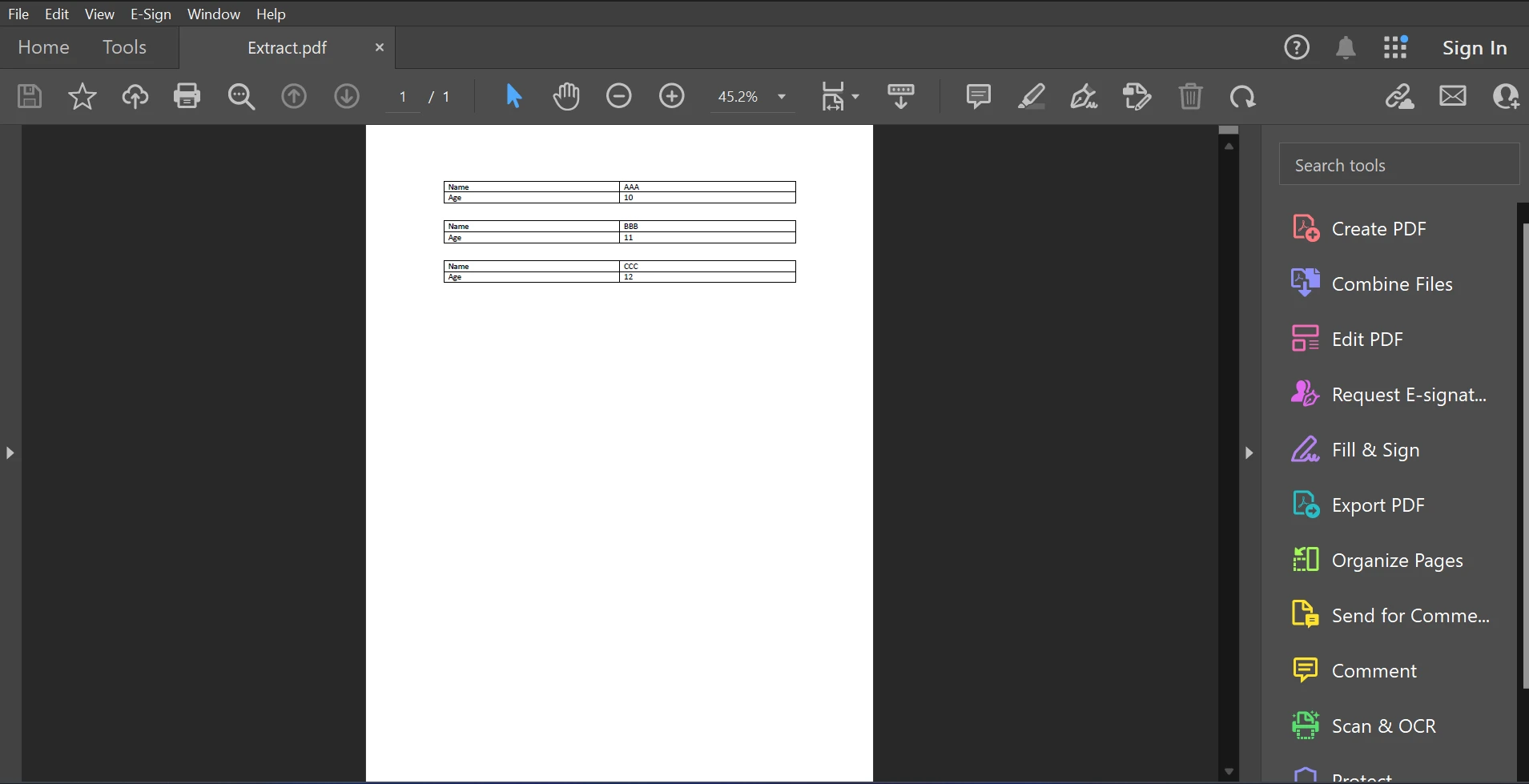 입력 PDF
입력 PDF
PDF에서 페이지별 추출
아래 제공된 예제 코드는 페이지 번호를 사용하여 PDF 파일에서 데이터를 가져오는 방법을 보여줍니다.
from ironpdf import PdfDocument
# Load the PDF file
pdf = PdfDocument.FromFile('F:\\PDF\\Extract.pdf')
# Extract text from the first page of the PDF document
all_text = pdf.ExtractTextFromPage(0)
# Iterate over each line in the extracted text
for line in all_text.split('\n'):
# Check if the line contains the keyword "Name"
if 'Name' in line:
# Print the line if it contains the keyword
print(line)from ironpdf import PdfDocument
# Load the PDF file
pdf = PdfDocument.FromFile('F:\\PDF\\Extract.pdf')
# Extract text from the first page of the PDF document
all_text = pdf.ExtractTextFromPage(0)
# Iterate over each line in the extracted text
for line in all_text.split('\n'):
# Check if the line contains the keyword "Name"
if 'Name' in line:
# Print the line if it contains the keyword
print(line)코드 스니펫은 FromFile 함수를 사용하여 PDF 파일을 읽고 PDF 객체를 생성하는 방법을 보여줍니다. 이 객체를 사용하면 PDF의 텍스트와 이미지에 접근할 수 있습니다. ExtractTextFromPage 함수에 페이지 번호를 매개변수로 전달하여 특정 페이지에서 텍스트를 가져올 수 있습니다. 이 메서드는 선택한 페이지에 있는 모든 단어를 포함하는 문자열을 반환합니다. 그런 다음, 추출된 텍스트에서 모든 새 줄을 분할하기 위해 Python에서 split 함수를 사용합니다. 그 후, 추출된 텍스트의 각 줄에 필요한 키워드가 포함되어 있는지 확인합니다. 키워드가 일치하면 명령 프롬프트에 해당 줄이 표시됩니다. 그렇지 않으면 해당 줄을 무시하고 다음 줄로 넘어갑니다. 텍스트 추출 결과는 아래와 같이 표시됩니다.
PDF 파일 전체를 텍스트로 변환하기
다음 코드 예제는 PDF 콘텐츠 전체를 문자열로 빠르고 간단하게 가져오는 첫 번째 방법을 보여줍니다.
from ironpdf import PdfDocument
# Load the PDF file
pdf = PdfDocument.FromFile('F:\\PDF\\Extract.pdf')
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Iterate over each line in the extracted text
for line in all_text.split('\n'):
# Check if the line contains the keyword "Name"
if 'Name' in line:
# Print the line if it contains the keyword
print(line)from ironpdf import PdfDocument
# Load the PDF file
pdf = PdfDocument.FromFile('F:\\PDF\\Extract.pdf')
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Iterate over each line in the extracted text
for line in all_text.split('\n'):
# Check if the line contains the keyword "Name"
if 'Name' in line:
# Print the line if it contains the keyword
print(line)위의 예제 코드는 FromFile 함수를 사용하여 기존 파일 경로에서 PDF를 읽고 이를 PDF 파일 객체로 변환하는 방법을 보여줍니다. 결과적으로, 우리는 이 PDF 리더 객체를 사용하여 PDF 파일의 텍스트와 이미지를 볼 수 있습니다. 객체의 ExtractAllText 함수는 PDF에서 데이터를 평문으로 추출하고 문자열로 변환하며, 위와 유사한 논리를 사용하여 특정 키워드를 찾아 결과를 터미널에 표시하는 데 사용됩니다. 결과는 다음과 같이 표시됩니다.
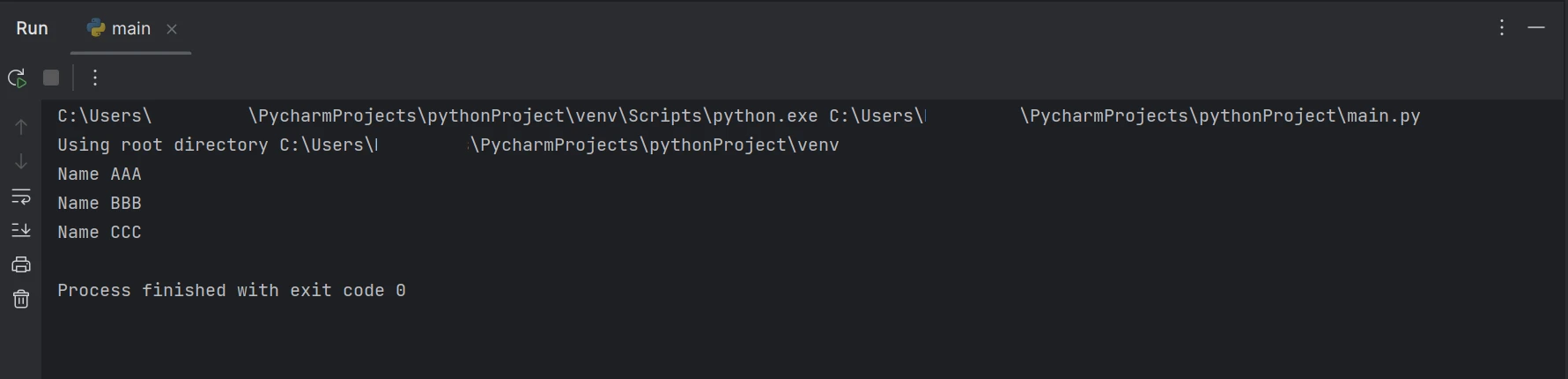 출력
출력
위 코드/출력은 주어진 PDF 문서에 이름과 나이가 모두 포함되어 있지만, 결과에는 이름만 표시됨을 보여줍니다.
결론
IronPDF 라이브러리는 위협을 줄이고 데이터 안전을 보장하기 위해 강력한 보안 메커니즘을 제공합니다. 특정 브라우저에 국한되지 않고 널리 사용되는 모든 브라우저와 호환됩니다. 프로그래머는 IronPDF 사용하여 단 몇 줄의 코드로 PDF 파일을 신속하게 생성하고 읽을 수 있습니다. IronPDF 라이브러리는 개발자의 다양한 요구를 충족하기 위해 무료 개발자 라이선스와 추가 개발자 라이선스 구매 옵션을 포함한 다양한 라이선스 옵션을 제공합니다.
Lite 패키지 에는 영구 라이선스, 30일 환불 보장, 1년 소프트웨어 유지 보수 및 업그레이드 옵션이 포함되어 있습니다. 이 라이선스는 모든 환경에서 사용할 수 있습니다. 또한 IronPDF 일부 재배포 제한이 있는 무료 라이선스를 제공합니다. 평가판 라이선스를 사용하면 워터마크 없이 제품을 평가할 수 있습니다.
상업적 라이선스에 대한 자세한 내용은 IronPDF 라이선스 페이지를 참조 하십시오.
자주 묻는 질문
Python을 사용하여 PDF에서 특정 텍스트를 추출하는 방법은 무엇인가요?
IronPDF의 Python 라이브러리를 사용하여 PDF에서 텍스트를 추출할 수 있습니다. 이 라이브러리는 ExtractTextFromPage 함수를 사용하여 페이지별로 텍스트를 추출하거나 ExtractAllText 사용하여 문서 전체에서 텍스트를 추출하는 기능을 제공합니다.
Python 프로젝트에서 IronPDF를 설정하는 단계는 무엇인가요?
먼저, .NET 6.0 런타임이 설치되어 있지 않다면 설치하세요. 그런 다음, PyCharm과 같은 개발 환경에 Python을 설치합니다. 마지막으로, pip install ironpdf 사용하여 IronPDF를 설치하면 프로젝트에 PDF 기능을 통합할 수 있습니다.
IronPDF는 Django 및 Flask와 같은 프레임워크와 호환됩니까?
네, IronPDF는 Django 및 Flask와 같은 Python 웹 개발 프레임워크와 잘 통합되어 웹 애플리케이션에서 PDF를 처리하는 다양한 옵션을 제공합니다.
Python에서 IronPDF를 사용하기 위한 라이선스 옵션은 무엇인가요?
IronPDF는 개인 사용자를 위한 무료 개발자 라이선스를 비롯하여 추가 기능과 이점을 제공하는 다양한 상업용 라이선스 등 여러 가지 라이선스 옵션을 제공합니다.
Python용 IronPDF를 어떻게 설치할 수 있나요?
터미널 또는 명령 프롬프트에서 pip install ironpdf 명령을 실행하여 pip 패키지 관리자를 사용하여 IronPDF를 설치하십시오.
IronPDF를 Python과 함께 사용하기 위한 권장 개발 환경은 무엇입니까?
PyCharm은 포괄적인 기능 세트와 Python 지원 덕분에 IronPDF를 사용하여 Python 애플리케이션을 개발하는 데 권장되는 통합 개발 환경(IDE)입니다.
Python용 IronPDF 라이브러리의 주요 기능은 무엇인가요?
IronPDF for Python은 HTML에서 PDF 생성, 이미지의 PDF 변환, 폼 처리, 텍스트 및 이미지 추출, PDF 병합과 같은 기능을 제공합니다.
IronPDF 라이브러리는 PDF 파일 처리에 있어 얼마나 안전한가요?
IronPDF는 강력한 보안 기능을 갖추고 있어 PDF 파일을 안전하게 처리할 수 있도록 설계되었습니다. 암호화 및 비밀번호 보호 기능을 지원하여 중요한 정보를 안전하게 보호합니다.
















