
Python'da PDF'den Belirli Metni Çıkarma
Bu makale, IronPDF for Python kütüphanesi yardımıyla PDF belgelerinden metin elemanlarını çıkarmanın nasıl yapılacağını gösterecektir.
IronPDF
Python, geliştiricilerin grafik kullanıcı arayüzlerini basit ve hızlı bir şekilde oluşturmalarını sağlayan bir programlama dilidir. Diğer dillere kıyasla Python, programcılar için çok daha dinamiktir. Bunun sebebi, Python'a IronPDF kütüphanesinin eklenmesi basit bir süreçtir. PyQt, wxWidgets, Kivy ve birçok ek paket ve Python kütüphanesi gibi önceden yüklenmiş birçok araç, tamamen tamamlanmış bir GUI'yi hızla ve güvenli bir şekilde oluşturmak için kullanılabilir. IronPDF, Python'u içermektedir ve .NET Core gibi diğer framework'lerden özelliklerin entegrasyonuna da izin verir.
IronPDF, web geliştirmeyi kolaylaştırır. Bunun ana nedeni, Django, Flask ve Pyramid gibi Python web geliştirme paradigmalarının yaygın benimsenmesidir. Reddit, Mozilla ve Spotify, bu frameworkleri kullanmış olan web sitelerinden ve çevrimiçi hizmetlerden sadece birkaçıdır.
IronPDF Özellikleri
- IronPDF ile, PDF dosyaları HTML, HTML5, ASPX ve Razor/MVC Görünümü de dahil olmak üzere çeşitli kaynaklardan oluşturulabilir. HTML sayfalarını dönüştürme ve görüntüleri PDF dosyalarına dönüştürme yeteneği sunar.
- Etkileşimli PDF'ler oluşturma, etkileşimli formlar tamamlama ve gönderme etkileşimli formlar, PDF dosyalarını bölme ve birleştirme, metin ve görüntüleri çıkarma, PDF dosyalarında metin arama, PDF'leri görüntülere rasterleştirme, yazı tipi boyutlarını değiştirme, doğal dil işlemeyi ChatGPT kullanarak yapma ve PDF sayfalarını düzgün biçimde dönüştürme gibi pek çok aktivite, IronPDF araç seti ile yapılabilir.
- IronPDF, kullanıcı ajanları, proxyler, çerezler, HTTP başlıkları ve form değişkenlerine destekle HTML giriş formu doğrulaması sunar.
- IronPDF, kullanıcıların korumalı belgelere erişim sağlamaları için kullanıcı adları ve şifreler kullanır.
- Sadece birkaç satır kodla, IronPDF bir dizi kaynaktan, bir dizi, akış veya URL'den PDF dosyası yazdırabilir.
Python Kurulumu
Ortam Yapılandırması
Bilgisayarınızda Python'un kurulu olduğundan emin olun. İşletim sisteminize uygun, Python'un en son sürümünü indirmek ve kurmak için resmi Python web sitesine gidin. Python kurulduktan sonra proje ihtiyaçlarınızı ayırmak için sanal bir ortam oluşturun. venv modülünü kullanarak sanal ortamlar oluşturun ve yönetin, böylece dönüşüm projenize düzenli, ayrı bir çalışma alanı sağlayabilirsiniz.
PyCharm'da Yeni Girişim
Bu gösterim için, Python kodu geliştirmek üzere bir IDE olarak PyCharm önerilir.
PyCharm IDE'sini başlattıktan sonra, "Yeni Proje"yi seçin.
 PyCharm
PyCharm
"Yeni Proje"yi seçtiğinizde, projenin konumunu ve ortamını ayarlamanıza olanak tanıyan yeni bir pencere açılacaktır. Bu, aşağıdaki resimde görülebilir.
 Yeni Proje
Yeni Proje
Proje konumunu ve ortam yolunu seçtikten sonra, yeni projeyi başlatmak için Oluştur düğmesine tıklayın. Daha sonra, bir yeni pencere açılarak program oluşturulabilir. Bu ders için Python 3.9 kullanılıyor.
 Python Projesi Oluştur
Python Projesi Oluştur
IronPDF Kütüphanesi Gereksinimi
Python kütüphanesi IronPDF büyük ölçüde .NET 6.0 kullanır. Sonuç olarak, Python için IronPDF'i kullanabilmek için bilgisayarınızda .NET 6.0 çalıştırma ortamı kurulmuş olmalıdır. Linux ve Mac kullanıcılarının bu Python modülünü kullanmadan önce .NET'i yüklemeleri gerekebilir. Gerekli çalışma ortamını indirmek için Microsoft'un bu indirme sayfasını ziyaret edin.
IronPDF Kütüphanesi Kurulumu
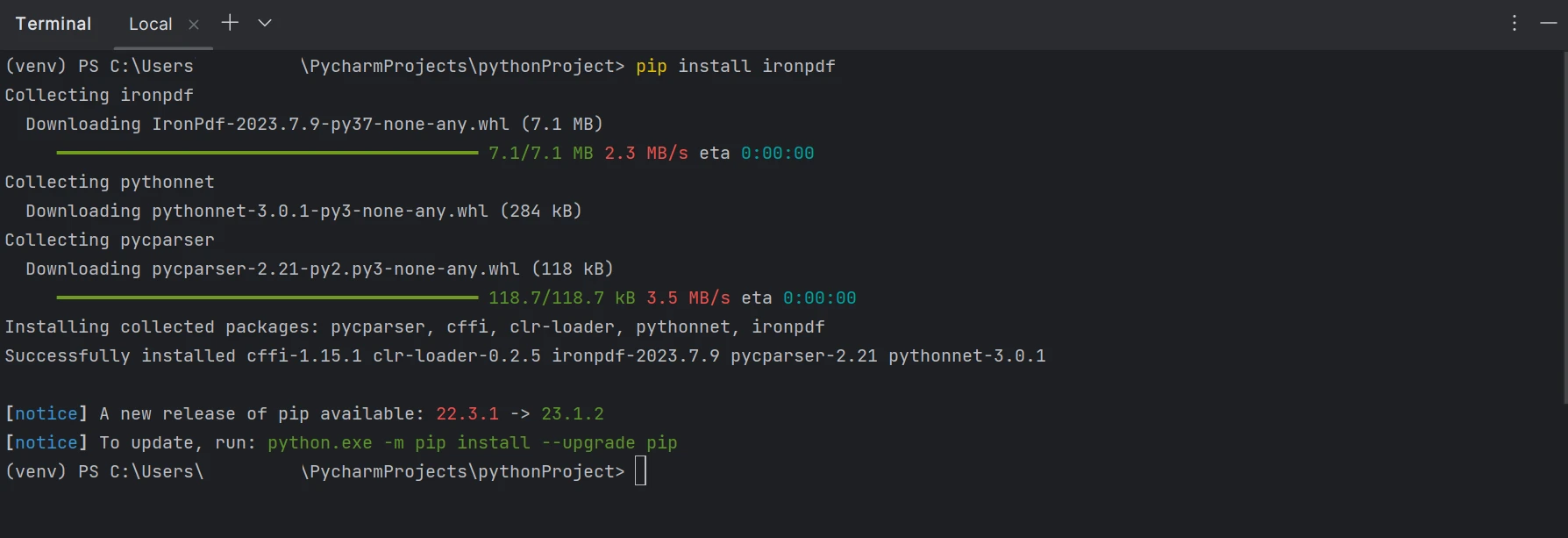
.pdf uzantılı dosyaları üretmek, değiştirmek ve açmak için 'IronPDF' paketi yüklenmeli. Paketi PyCharm'da kurmak için bir terminal penceresi açın ve aşağıdaki komutu girin:
pip install ironpdf
Aşağıdaki ekran görüntüsünde ironpdf paketinin kurulumu gösterilmektedir.
 IronPDF Yükle
IronPDF Yükle
PDF Dosyasından Belirli Verileri Çıkartma
IronPDF kütüphaneleri yardımıyla PDF dosyalarından metin çıkarılması mümkündür. IronPDF bir dizi metin çıkarma yöntemi sunar. İlk yöntem, tüm sayfa içeriğini tek bir dize olarak geri alır. İkinci strateji ise ilk sayfadan başlayarak içerik üzerinde sayfa sayfa gezmeye dayanır. Mevcut PDF dosyaları IronPDF kütüphanesi kullanılarak araştırılabilir. Aşağıdaki kod parçası, canlı PDF dosyalarını incelemek için IronPDF'in nasıl kullanılacağını göstermektedir.
Bir PDF'ten bilgi çıkarmanın iki seçeneği vardır:
- PDF'den sayfa sayfa çıkarma
- Tüm PDF'yi metne dönüştürme
Aşağıda, bu makale için örnek PDF dosyası mevcuttur.
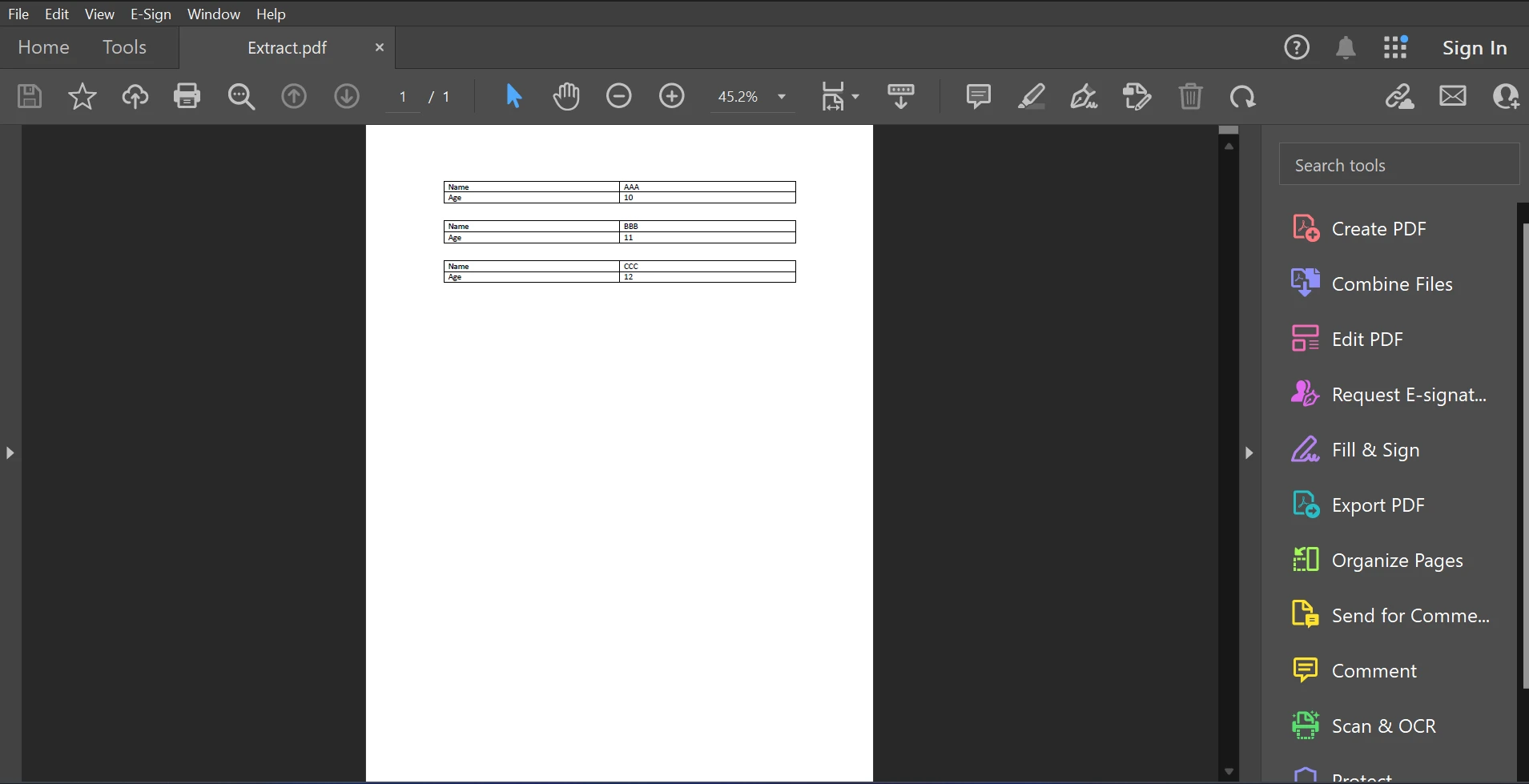 Giriş PDF
Giriş PDF
PDF'den Sayfa Sayfa Çıkarma
Aşağıda sağlanan örnek kod, bir sayfa numarası kullanarak bir PDF dosyasından veri alma işlemini gösterir.
from ironpdf import PdfDocument
# Load the PDF file
pdf = PdfDocument.FromFile('F:\\PDF\\Extract.pdf')
# Extract text from the first page of the PDF document
all_text = pdf.ExtractTextFromPage(0)
# Iterate over each line in the extracted text
for line in all_text.split('\n'):
# Check if the line contains the keyword "Name"
if 'Name' in line:
# Print the line if it contains the keyword
print(line)from ironpdf import PdfDocument
# Load the PDF file
pdf = PdfDocument.FromFile('F:\\PDF\\Extract.pdf')
# Extract text from the first page of the PDF document
all_text = pdf.ExtractTextFromPage(0)
# Iterate over each line in the extracted text
for line in all_text.split('\n'):
# Check if the line contains the keyword "Name"
if 'Name' in line:
# Print the line if it contains the keyword
print(line)Kod parçası, FromFile fonksiyonunu kullanarak bir PDF dosyasının nasıl okunacağını ve bir PDF nesnesinin nasıl oluşturulacağını göstermektedir. Bu nesne, PDF'nin metin ve görsellerine erişmek için kullanılabilir. ExtractTextFromPage fonksiyonuna sayfa numarasını bir parametre olarak geçerek, belirli bir sayfadan metin alınabilir. Bu yöntem, seçilen sayfadaki tüm kelimeleri içeren bir dize döndürecektir. Daha sonra, çıkarılan metinden tüm yeni satırları ayırmak için Python'da split fonksiyonunu kullanın. Daha sonra, çıkarılan metindeki her satırda istenen anahtar kelimelerin bulunup bulunmadığını kontrol edin. Anahtar kelime eşleşirse, komut isteminde belirli satır görüntülenecektir. Aksi takdirde, o satır atlanır ve bir sonraki satıra geçilir. Metin çıkarımı için çıktı aşağıda gösterildiği gibi olacaktır.
Tüm PDF'yi Metne Dönüştürme
Aşağıdaki kod örneği, tüm PDF içeriğini bir dize olarak hızlı ve kolay bir şekilde almak için ilk yöntemi göstermektedir.
from ironpdf import PdfDocument
# Load the PDF file
pdf = PdfDocument.FromFile('F:\\PDF\\Extract.pdf')
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Iterate over each line in the extracted text
for line in all_text.split('\n'):
# Check if the line contains the keyword "Name"
if 'Name' in line:
# Print the line if it contains the keyword
print(line)from ironpdf import PdfDocument
# Load the PDF file
pdf = PdfDocument.FromFile('F:\\PDF\\Extract.pdf')
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Iterate over each line in the extracted text
for line in all_text.split('\n'):
# Check if the line contains the keyword "Name"
if 'Name' in line:
# Print the line if it contains the keyword
print(line)Yukarıdaki örnek kod, mevcut bir dosya yolundan bir PDF okuma ve bunu bir PDF dosya nesnesine dönüştürmek için FromFile fonksiyonunun nasıl kullanılacağını göstermektedir. Sonuç olarak, bu PDF okuyucu nesnesini PDF'deki metin ve resimleri görmek için kullanabiliriz. Nesnenin ExtractAllText fonksiyonu, PDF'den verileri düz metin olarak çıkartmak, bir stringe dönüştürmek ve yukarıdaki benzer mantığı kullanarak belirli anahtar kelimeyi bulmak için terminalde sonucu görüntülemek için kullanılacaktır. Sonuçlar aşağıdaki gibi görüntülenmektedir.
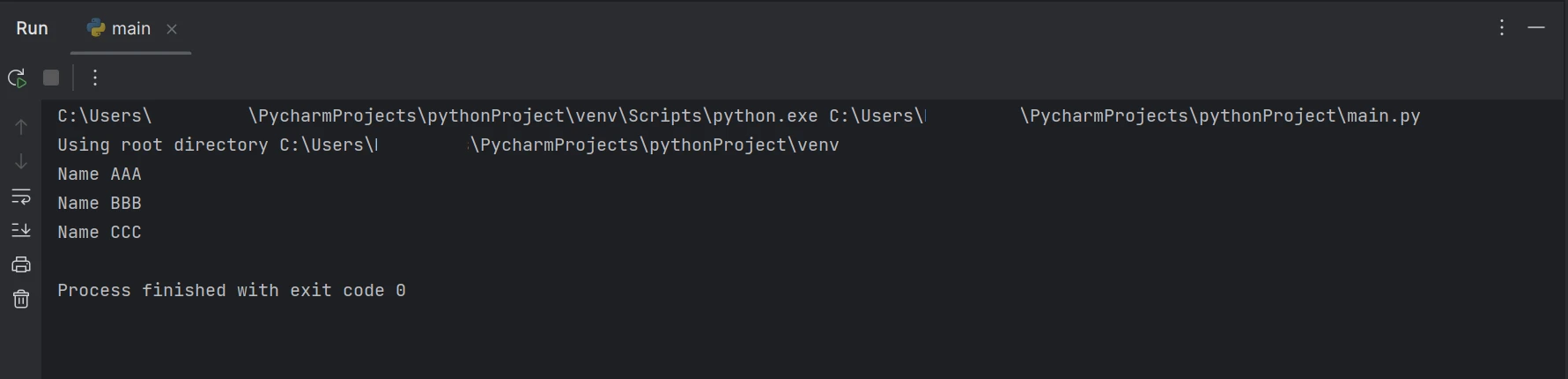 Çıktı
Çıktı
Yukarıdaki kod/çıkış, verilen PDF belgesinin hem isim hem de yaş içerdiğini göstermektedir, ancak sonuç metni yalnızca PDF belgesindeki mevcut ismi göstermektedir.
Sonuç
IronPDF kütüphanesi, tehditleri azaltmak ve veri güvenliğini sağlamak için güçlü güvenlik mekanizmaları sunar. Herhangi bir tarayıcıya özgü olmamakla birlikte yaygın olarak kullanılan tüm tarayıcılarla uyumludur. Sadece birkaç satır kodla, programcılar IronPDF kullanarak hızla PDF dosyaları oluşturabilir ve okuyabilir. IronPDF kütüphanesi, geliştiricilerin çeşitli gereksinimlerini karşılamak için bir ücretsiz geliştirici lisansı ve satın alınabilir ek geliştirme lisansları dahil olmak üzere çeşitli lisanslama seçenekleri sunar.
Lite paketi, sürekli bir lisans, 30 günlük para iade garantisi, bir yıl yazılım bakımı ve yükseltme seçenekleri içerir. Bu lisanslar tüm ortamlarda kullanılabilir. Ek olarak, IronPDF bazı yeniden dağıtım kısıtlamaları ile ücretsiz lisanslar sağlar. deneme lisansı, kullanıcıların ürünü bir filigran olmadan değerlendirmesine olanak tanır.
Ticari lisanslama hakkında daha fazla bilgi için lütfen mevcut IronPDF Lisanslarına bakın.
Sıkça Sorulan Sorular
Python kullanarak PDF'den belirli metin nasıl çıkarabilirim?
IronPDF'nin Python kütüphanesini kullanarak PDF'lerden metin çıkarabilirsiniz. ExtractTextFromPage kullanarak sayfa bazında veya ExtractAllText ile tüm belgede metin çıkartma işlevsellikleri sunar.
Python projesinde IronPDF'i kurmanın adımları nelerdir?
İlk olarak, .NET 6.0 çalışma zamanını kurun (eğer zaten yüklü değilse), ardından geliştirme ortamınızı, örneğin PyCharm'ı ayarlayın. PDF işlevselliklerini projenize entegre etmeye başlamak için pip install ironpdf kullanarak IronPDF'yi kurun.
IronPDF, Django ve Flask gibi çerçevelerle uyumlu mu?
Evet, IronPDF, Django ve Flask gibi Python web geliştirme çerçeveleri ile iyi entegre olur ve web uygulamalarında PDF işleme için çeşitli seçenekler sunar.
Python ile IronPDF kullanmak için ne tür lisanslama seçenekleri mevcuttur?
IronPDF, kişisel kullanım için ücretsiz geliştirici lisansı ve ekstra özellikler ile avantajlar sunan çeşitli ticari lisanslar dahil olmak üzere geniş bir lisanslama seçenekleri sunar.
Python için IronPDF nasıl kurulur?
IronPDF'yi terminal veya komut istemcisine pip install ironpdf komutunu çalıştırarak pip paket yöneticisi kullanarak kurun.
Python ile IronPDF kullanmak için önerilen geliştirme ortamı nedir?
PyCharm, IronPDF ile Python uygulamalarını geliştirmek için tavsiye edilen Entegre Geliştirme Ortamı (IDE) olup, kapsamlı özellik seti ve Python desteği nedeniyle önerilir.
IronPDF kütüphanesinin Python için bazı önemli özellikleri nelerdir?
IronPDF for Python, HTML'den PDF oluşturma, görüntüleri PDF'ye dönüştürme, form işleme, metin ve görüntü çıkarma ve PDF birleştirme gibi özellikler sunar.
IronPDF kütüphanesi, PDF dosyalarını işlemek için ne kadar güvenli?
IronPDF, güçlü güvenlik özellikleri ile tasarlanmış olup PDF dosyalarını güvenli bir şekilde işler. Hassas bilgileri korumak için şifreleme ve parola korumasını destekler.
















