


Analisador de PDF em C
Analise arquivos PDF em C# usando o método ExtractAllText do IronPDF para extrair texto de documentos inteiros ou páginas específicas. Essa abordagem proporciona uma extração de texto em PDF simples e eficiente para aplicações .NET com apenas algumas linhas de código.
O IronPDF simplifica a análise de PDFs em aplicações C#. Este tutorial demonstra como usar o IronPDF , uma biblioteca C# abrangente para geração e manipulação de PDFs , para analisar PDFs em apenas alguns passos.
Início Rápido: Análise Eficiente de PDFs com IronPDF
Comece a analisar PDFs em C# usando o IronPDF com o mínimo de código. Este exemplo mostra como extrair todo o texto de um arquivo PDF, mantendo sua formatação original. O método ExtractAllText do IronPDF permite integração de análise de PDF sem interrupções em aplicativos .NET. Siga estes passos para uma configuração e execução simples.
-
Instale IronPDF com o Gerenciador de Pacotes NuGet
-
Copie e execute este trecho de código.
var text = IronPdf.FromFile("sample.pdf").ExtractAllText(); -
Implante para testar em seu ambiente de produção.
Comece a usar IronPDF em seu projeto hoje com uma avaliação gratuita

Fluxo de trabalho mínimo (5 etapas)
- Baixe a biblioteca de análise de PDF em C#
- Instale no seu Visual Studio.
- Utilize o método
ExtractAllTextpara extrair cada linha de texto. - Extraia todo o texto de uma única página com o método
ExtractTextFromPage - Visualizar conteúdo do PDF analisado
Como faço para analisar arquivos PDF em C#?
Analisar arquivos PDF é simples com o IronPDF. O código abaixo usa o método ExtractAllText para extrair cada linha de texto do documento PDF inteiro. A comparação mostra o conteúdo extraído do PDF juntamente com sua saída. A biblioteca também oferece suporte à extração de texto e imagens de seções específicas de documentos PDF.
:path=/static-assets/pdf/content-code-examples/how-to/csharp-parse-pdf-parse-pdf.csusing IronPdf;
// Select the desired PDF File
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract all text from an pdf
string allText = pdf.ExtractAllText();
// Extract all text from page 1
string page1Text = pdf.ExtractTextFromPage(0);Imports IronPdf
' Select the desired PDF File
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract all text from an pdf
Private allText As String = pdf.ExtractAllText()
' Extract all text from page 1
Private page1Text As String = pdf.ExtractTextFromPage(0)O IronPDF simplifica a análise de PDFs em diversos cenários. Seja para trabalhar com conversões de HTML para PDF , extrair conteúdo de documentos existentes ou implementar recursos avançados de PDF , a biblioteca oferece suporte abrangente.
O IronPDF oferece integração perfeita com aplicativos Windows e suporta implantação em plataformas Linux e macOS . A biblioteca também oferece suporte à implantação no Azure para soluções baseadas em nuvem.
Exemplos avançados de extração de texto
Aqui estão algumas maneiras adicionais de analisar conteúdo de PDF usando o IronPDF:
:path=/static-assets/pdf/content-code-examples/how-to/csharp-parse-pdf-3.csusing IronPdf;
// Parse PDF from URL
var pdfFromUrl = PdfDocument.FromUrl("https://example.com/document.pdf");
string urlPdfText = pdfFromUrl.ExtractAllText();
// Parse password-protected PDFs
var protectedPdf = PdfDocument.FromFile("protected.pdf", "password123");
string protectedText = protectedPdf.ExtractAllText();
// Extract text from specific page range
var largePdf = PdfDocument.FromFile("large-document.pdf");
for (int i = 5; i < 10; i++)
{
string pageText = largePdf.ExtractTextFromPage(i);
Console.WriteLine($"Page {i + 1}: {pageText.Substring(0, 100)}...");
}
Imports IronPdf
' Parse PDF from URL
Dim pdfFromUrl = PdfDocument.FromUrl("https://example.com/document.pdf")
Dim urlPdfText As String = pdfFromUrl.ExtractAllText()
' Parse password-protected PDFs
Dim protectedPdf = PdfDocument.FromFile("protected.pdf", "password123")
Dim protectedText As String = protectedPdf.ExtractAllText()
' Extract text from specific page range
Dim largePdf = PdfDocument.FromFile("large-document.pdf")
For i As Integer = 5 To 9
Dim pageText As String = largePdf.ExtractTextFromPage(i)
Console.WriteLine($"Page {i + 1}: {pageText.Substring(0, 100)}...")
NextEsses exemplos demonstram a flexibilidade do IronPDF ao lidar com diferentes fontes e cenários de PDF. Para necessidades de análise sintática complexas, explore o acesso a objetos DOM do PDF para trabalhar com conteúdo estruturado.
Lidando com diferentes tipos de PDF
O IronPDF se destaca na análise de diversos tipos de PDF:
:path=/static-assets/pdf/content-code-examples/how-to/csharp-parse-pdf-4.csusing IronPdf;
using System.Text.RegularExpressions;
// Parse scanned PDFs with OCR (requires IronOcr)
var scannedPdf = PdfDocument.FromFile("scanned-document.pdf");
string ocrText = scannedPdf.ExtractAllText();
// Parse PDFs with forms
var formPdf = PdfDocument.FromFile("form.pdf");
string formText = formPdf.ExtractAllText();
// Extract and filter specific content
string invoiceText = pdf.ExtractAllText();
var invoiceNumber = Regex.Match(invoiceText, @"Invoice #: (\d+)").Groups[1].Value;
var totalAmount = Regex.Match(invoiceText, @"Total: \$([0-9,]+\.\d{2})").Groups[1].Value;
Imports IronPdf
Imports System.Text.RegularExpressions
' Parse scanned PDFs with OCR (requires IronOcr)
Dim scannedPdf = PdfDocument.FromFile("scanned-document.pdf")
Dim ocrText As String = scannedPdf.ExtractAllText()
' Parse PDFs with forms
Dim formPdf = PdfDocument.FromFile("form.pdf")
Dim formText As String = formPdf.ExtractAllText()
' Extract and filter specific content
Dim invoiceText As String = pdf.ExtractAllText()
Dim invoiceNumber = Regex.Match(invoiceText, "Invoice #: (\d+)").Groups(1).Value
Dim totalAmount = Regex.Match(invoiceText, "Total: \$([0-9,]+\.\d{2})").Groups(1).ValueComo faço para visualizar o conteúdo do PDF analisado?
O formulário AC# exibe o conteúdo do PDF analisado a partir da execução do código acima. Esta saída fornece o texto exato de um PDF para fins de processamento de documentos.
~ PDF ~
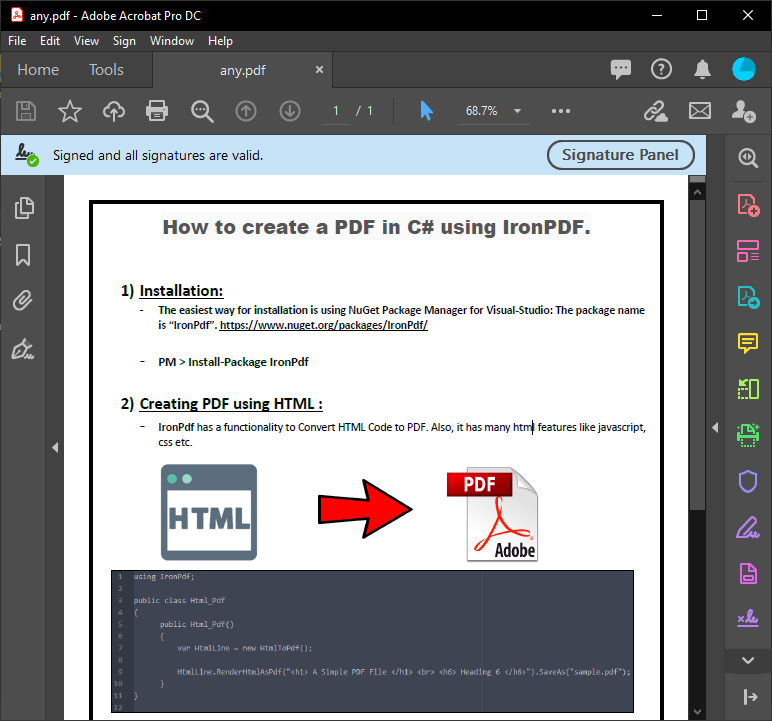
~ Formulário C# ~
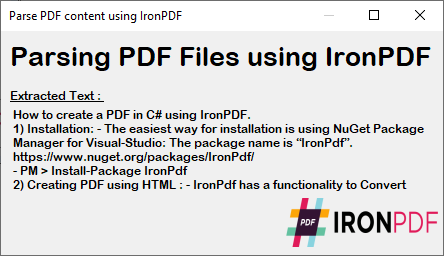
O texto extraído mantém a formatação e a estrutura originais do PDF, tornando-o ideal para processamento de dados, análise de conteúdo ou tarefas de migração. Processe este texto posteriormente, localizando e substituindo conteúdo específico ou exportando-o para outros formatos.
Integrando a análise de PDFs em seus aplicativos
Os recursos de análise sintática do IronPDF se integram a diversos tipos de aplicativos:
// ASP.NET Core example
public IActionResult ParseUploadedPdf(IFormFile pdfFile)
{
using var stream = pdfFile.OpenReadStream();
var pdf = PdfDocument.FromStream(stream);
var extractedText = pdf.ExtractAllText();
// Process or store the extracted text
return Json(new {
success = true,
textLength = extractedText.Length,
preview = extractedText.Substring(0, Math.Min(500, extractedText.Length))
});
}
// Console application example
static void BatchParsePdfs(string folderPath)
{
var pdfFiles = Directory.GetFiles(folderPath, "*.pdf");
foreach (var file in pdfFiles)
{
var pdf = PdfDocument.FromFile(file);
var text = pdf.ExtractAllText();
// Save extracted text
var textFile = Path.ChangeExtension(file, ".txt");
File.WriteAllText(textFile, text);
Console.WriteLine($"Parsed: {Path.GetFileName(file)} - {text.Length} characters");
}
}// ASP.NET Core example
public IActionResult ParseUploadedPdf(IFormFile pdfFile)
{
using var stream = pdfFile.OpenReadStream();
var pdf = PdfDocument.FromStream(stream);
var extractedText = pdf.ExtractAllText();
// Process or store the extracted text
return Json(new {
success = true,
textLength = extractedText.Length,
preview = extractedText.Substring(0, Math.Min(500, extractedText.Length))
});
}
// Console application example
static void BatchParsePdfs(string folderPath)
{
var pdfFiles = Directory.GetFiles(folderPath, "*.pdf");
foreach (var file in pdfFiles)
{
var pdf = PdfDocument.FromFile(file);
var text = pdf.ExtractAllText();
// Save extracted text
var textFile = Path.ChangeExtension(file, ".txt");
File.WriteAllText(textFile, text);
Console.WriteLine($"Parsed: {Path.GetFileName(file)} - {text.Length} characters");
}
}Imports Microsoft.AspNetCore.Mvc
Imports System.IO
' ASP.NET Core example
Public Function ParseUploadedPdf(pdfFile As IFormFile) As IActionResult
Using stream = pdfFile.OpenReadStream()
Dim pdf = PdfDocument.FromStream(stream)
Dim extractedText = pdf.ExtractAllText()
' Process or store the extracted text
Return Json(New With {
.success = True,
.textLength = extractedText.Length,
.preview = extractedText.Substring(0, Math.Min(500, extractedText.Length))
})
End Using
End Function
' Console application example
Private Shared Sub BatchParsePdfs(folderPath As String)
Dim pdfFiles = Directory.GetFiles(folderPath, "*.pdf")
For Each file In pdfFiles
Dim pdf = PdfDocument.FromFile(file)
Dim text = pdf.ExtractAllText()
' Save extracted text
Dim textFile = Path.ChangeExtension(file, ".txt")
File.WriteAllText(textFile, text)
Console.WriteLine($"Parsed: {Path.GetFileName(file)} - {text.Length} characters")
Next
End SubEstes exemplos mostram a incorporação da análise de PDFs em aplicações web e cenários de processamento em lote. Para implementações avançadas, explore técnicas assíncronas e de multithreading para melhorar o desempenho ao processar vários PDFs.
Pronto para ver o que mais você pode fazer? Confira nossa página de tutoriais aqui: Editar PDFs
Perguntas frequentes
Como faço para extrair todo o texto de um arquivo PDF em C#?
Você pode extrair todo o texto de um arquivo PDF usando o método ExtractAllText do IronPDF. Basta carregar seu PDF com IronPdf.FromFile("sample.pdf") e chamar ExtractAllText() para recuperar todo o conteúdo de texto, mantendo a formatação original.
Qual é a maneira mais simples de analisar um PDF em .NET?
A maneira mais simples é usar o IronPDF com apenas uma linha de código: `var text = IronPdf.FromFile("sample.pdf").ExtractAllText()`. Este método extrai todas as linhas de texto de todo o documento PDF com configuração mínima necessária.
Posso extrair texto de uma página específica de um PDF?
Sim, o IronPDF oferece o método ExtractTextFromPage para extrair texto de páginas individuais. Isso permite que você selecione seções específicas do seu documento PDF em vez de extrair todo o conteúdo de uma só vez.
Como faço para analisar PDFs protegidos por senha em C#?
O IronPDF suporta a análise de PDFs protegidos por senha. Use PdfDocument.FromFile("protected.pdf", "password123") para carregar o documento protegido e, em seguida, chame ExtractAllText() para extrair o conteúdo do texto.
Posso analisar PDFs a partir de URLs em vez de arquivos locais?
Sim, o IronPDF pode analisar PDFs diretamente de URLs usando PdfDocument.FromUrl("https://example.com/document.pdf"). Após carregar o PDF da URL, use ExtractAllText() para extrair o conteúdo de texto.
Quais plataformas o analisador de PDF suporta?
O IronPDF oferece suporte à análise de PDFs em diversas plataformas, incluindo aplicativos Windows, Linux, macOS e implantações na nuvem Azure, proporcionando ampla compatibilidade multiplataforma para seus aplicativos .NET.
O analisador de PDF mantém a formatação do texto durante a extração?
Sim, o método ExtractAllText do IronPDF mantém a formatação original do conteúdo do PDF durante a extração, garantindo que o texto analisado preserve sua estrutura e layout do documento original.
Posso extrair texto e imagens de PDFs?
O IronPDF permite extrair tanto texto quanto imagens de documentos PDF. Além do método ExtractAllText para extração de texto, a biblioteca oferece funcionalidades adicionais para extrair imagens de seções específicas de documentos PDF.


Ainda está rolando a tela?
Quer provas rápidas? PM > Install-Package IronPdf
executar um exemplo Veja seu HTML se transformar em um PDF.










