


Analizador de PDF de C
Analiza archivos PDF en C# usando el método ExtractAllText de IronPDF para extraer texto de documentos enteros o páginas específicas. Este enfoque proporciona una extracción de texto en PDF sencilla y eficaz para aplicaciones .NET con solo unas pocas líneas de código.
IronPDF facilita el análisis sintáctico de PDF en aplicaciones C#. Este tutorial muestra cómo utilizar IronPDF, una completa biblioteca de C# para generación y manipulación de PDF, para analizar archivos PDF en unos pocos pasos.
En el contexto fiscal y empresarial español, el análisis de PDFs es un componente esencial de los flujos de trabajo de cumplimiento normativo. Los departamentos de contabilidad que procesan facturas recibidas en formato Facturae adjuntas como PDF necesitan extraer datos como número de factura, importes e identificación del emisor para su registro en el sistema SII (Suministro Inmediato de Información) de la AEAT. IronPDF permite automatizar esta extracción con pocas líneas de código C#, eliminando la introducción manual de datos y reduciendo el riesgo de errores en las declaraciones de IVA.
Inicio rápido: Análisis eficiente de PDF con IronPDF
Empiece a analizar archivos PDF en C# utilizando IronPDF con un código mínimo. Este ejemplo muestra cómo extraer todo el texto de un archivo PDF manteniendo su formato original. El método ExtractAllText de IronPDF permite una integración fluida de análisis PDF en aplicaciones .NET. Siga estos pasos para una configuración y ejecución sencillas.
-
Instala IronPDF con el Administrador de Paquetes NuGet
PM > Install-Package IronPdf -
Copie y ejecute este fragmento de código.
var text = IronPdf.FromFile("sample.pdf").ExtractAllText(); -
Despliegue para probar en su entorno real
Comienza a usar IronPDF en tu proyecto hoy mismo con una prueba gratuita

Flujo de trabajo mínimo (5 pasos)
- Descargar la biblioteca del analizador C# PDF
- Instalar en tu Visual Studio
- Utilice el método
ExtractAllTextpara extraer cada línea de texto - Extraer todo el texto de una sola página con el método
ExtractTextFromPage - Ver contenido de PDF analizado
¿Cómo analizar archivos PDF en C#?
Analizar archivos PDF es sencillo con IronPDF. El código a continuación usa el método ExtractAllText para extraer cada línea de texto del documento PDF completo. La comparación muestra el contenido del PDF extraído junto con su resultado. La biblioteca también permite extraer texto e imágenes de secciones específicas de documentos PDF.
:path=/static-assets/pdf/content-code-examples/how-to/csharp-parse-pdf-parse-pdf.csusing IronPdf;
// Select the desired PDF File
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract all text from an pdf
string allText = pdf.ExtractAllText();
// Extract all text from page 1
string page1Text = pdf.ExtractTextFromPage(0);Imports IronPdf
' Select the desired PDF File
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract all text from an pdf
Private allText As String = pdf.ExtractAllText()
' Extract all text from page 1
Private page1Text As String = pdf.ExtractTextFromPage(0)IronPDF simplifica el análisis sintáctico de PDF en diversos escenarios. Tanto si se trabaja con conversiones de HTML a PDF, como si se extrae contenido de documentos existentes o se implementan funciones avanzadas de PDF, la biblioteca ofrece un soporte completo.
IronPDF ofrece una integración perfecta con aplicaciones de Windows y admite la implementación en plataformas Linux y macOS. La biblioteca también es compatible con Azure deployment para soluciones basadas en la nube.
Ejemplos avanzados de extracción de texto
Estas son otras formas de analizar contenido PDF con IronPDF:
using IronPdf;
// Parse PDF from URL
var pdfFromUrl = PdfDocument.FromUrl("https://example.com/document.pdf");
string urlPdfText = pdfFromUrl.ExtractAllText();
// Parse password-protected PDFs
var protectedPdf = PdfDocument.FromFile("protected.pdf", "password123");
string protectedText = protectedPdf.ExtractAllText();
// Extract text from specific page range
var largePdf = PdfDocument.FromFile("large-document.pdf");
for (int i = 5; i < 10; i++)
{
string pageText = largePdf.ExtractTextFromPage(i);
Console.WriteLine($"Page {i + 1}: {pageText.Substring(0, 100)}...");
}using IronPdf;
// Parse PDF from URL
var pdfFromUrl = PdfDocument.FromUrl("https://example.com/document.pdf");
string urlPdfText = pdfFromUrl.ExtractAllText();
// Parse password-protected PDFs
var protectedPdf = PdfDocument.FromFile("protected.pdf", "password123");
string protectedText = protectedPdf.ExtractAllText();
// Extract text from specific page range
var largePdf = PdfDocument.FromFile("large-document.pdf");
for (int i = 5; i < 10; i++)
{
string pageText = largePdf.ExtractTextFromPage(i);
Console.WriteLine($"Page {i + 1}: {pageText.Substring(0, 100)}...");
}Imports IronPdf
' Parse PDF from URL
Dim pdfFromUrl = PdfDocument.FromUrl("https://example.com/document.pdf")
Dim urlPdfText As String = pdfFromUrl.ExtractAllText()
' Parse password-protected PDFs
Dim protectedPdf = PdfDocument.FromFile("protected.pdf", "password123")
Dim protectedText As String = protectedPdf.ExtractAllText()
' Extract text from specific page range
Dim largePdf = PdfDocument.FromFile("large-document.pdf")
For i As Integer = 5 To 9
Dim pageText As String = largePdf.ExtractTextFromPage(i)
Console.WriteLine($"Page {i + 1}: {pageText.Substring(0, 100)}...")
NextEstos ejemplos demuestran la flexibilidad de IronPDF a la hora de manejar diferentes fuentes y escenarios de PDF. Para necesidades de análisis complejas, explore PDF DOM object access para trabajar con contenido estructurado.
Diferentes tipos de PDF
IronPDF destaca en el análisis sintáctico de varios tipos de PDF:
using IronPdf;
using System.Text.RegularExpressions;
// Parse scanned PDFs with OCR (requires IronOcr)
var scannedPdf = PdfDocument.FromFile("scanned-document.pdf");
string ocrText = scannedPdf.ExtractAllText();
// Parse PDFs with forms
var formPdf = PdfDocument.FromFile("form.pdf");
string formText = formPdf.ExtractAllText();
// Extract and filter specific content
string invoiceText = pdf.ExtractAllText();
var invoiceNumber = Regex.Match(invoiceText, @"Invoice #: (\d+)").Groups[1].Value;
var totalAmount = Regex.Match(invoiceText, @"Total: \$([0-9,]+\.\d{2})").Groups[1].Value;using IronPdf;
using System.Text.RegularExpressions;
// Parse scanned PDFs with OCR (requires IronOcr)
var scannedPdf = PdfDocument.FromFile("scanned-document.pdf");
string ocrText = scannedPdf.ExtractAllText();
// Parse PDFs with forms
var formPdf = PdfDocument.FromFile("form.pdf");
string formText = formPdf.ExtractAllText();
// Extract and filter specific content
string invoiceText = pdf.ExtractAllText();
var invoiceNumber = Regex.Match(invoiceText, @"Invoice #: (\d+)").Groups[1].Value;
var totalAmount = Regex.Match(invoiceText, @"Total: \$([0-9,]+\.\d{2})").Groups[1].Value;Imports IronPdf
Imports System.Text.RegularExpressions
' Parse scanned PDFs with OCR (requires IronOcr)
Dim scannedPdf = PdfDocument.FromFile("scanned-document.pdf")
Dim ocrText As String = scannedPdf.ExtractAllText()
' Parse PDFs with forms
Dim formPdf = PdfDocument.FromFile("form.pdf")
Dim formText As String = formPdf.ExtractAllText()
' Extract and filter specific content
Dim invoiceText As String = pdf.ExtractAllText()
Dim invoiceNumber = Regex.Match(invoiceText, "Invoice #: (\d+)").Groups(1).Value
Dim totalAmount = Regex.Match(invoiceText, "Total: \$([0-9,]+\.\d{2})").Groups(1).Value¿Cómo puedo ver el contenido del PDF analizado?
Un formulario en C# muestra el contenido del PDF analizado a partir de la ejecución del código anterior. Este resultado proporciona el texto exacto de un PDF para las necesidades de procesamiento de documentos.
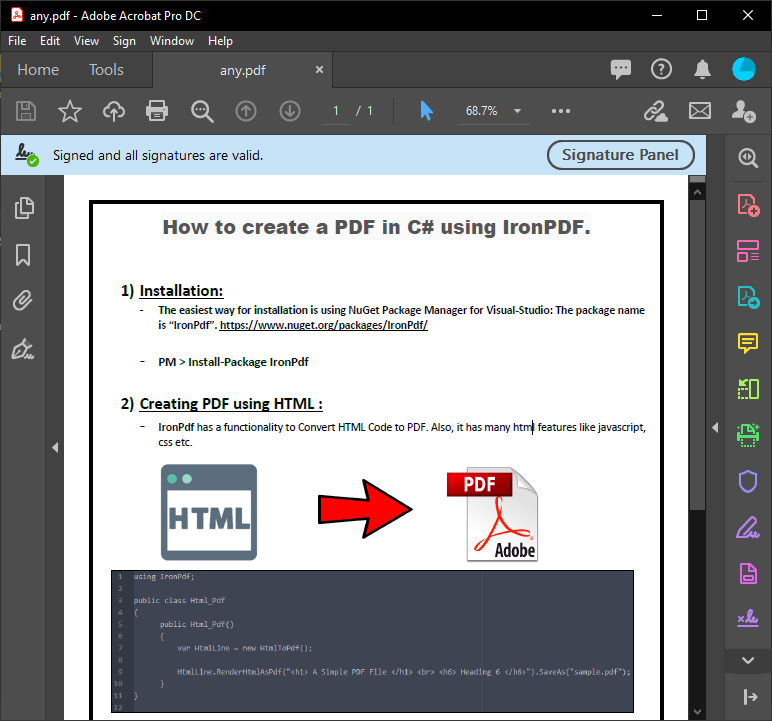
~ Formulario C# ~
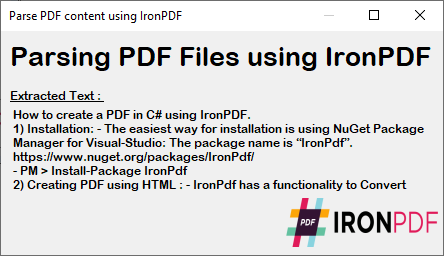
El texto extraído mantiene el formato y la estructura originales del PDF, por lo que resulta ideal para tareas de procesamiento de datos, análisis de contenido o migración. Para seguir procesando este texto, encuentre y reemplace contenido específico o expórtelo a otros formatos.
Integración del análisis de PDF en tus aplicaciones
Las capacidades de análisis sintáctico de IronPDF se integran en varios tipos de aplicaciones:
// ASP.NET Core example
public IActionResult ParseUploadedPdf(IFormFile pdfFile)
{
using var stream = pdfFile.OpenReadStream();
var pdf = PdfDocument.FromStream(stream);
var extractedText = pdf.ExtractAllText();
// Process or store the extracted text
return Json(new {
success = true,
textLength = extractedText.Length,
preview = extractedText.Substring(0, Math.Min(500, extractedText.Length))
});
}
// Console application example
static void BatchParsePdfs(string folderPath)
{
var pdfFiles = Directory.GetFiles(folderPath, "*.pdf");
foreach (var file in pdfFiles)
{
var pdf = PdfDocument.FromFile(file);
var text = pdf.ExtractAllText();
// Save extracted text
var textFile = Path.ChangeExtension(file, ".txt");
File.WriteAllText(textFile, text);
Console.WriteLine($"Parsed: {Path.GetFileName(file)} - {text.Length} characters");
}
}// ASP.NET Core example
public IActionResult ParseUploadedPdf(IFormFile pdfFile)
{
using var stream = pdfFile.OpenReadStream();
var pdf = PdfDocument.FromStream(stream);
var extractedText = pdf.ExtractAllText();
// Process or store the extracted text
return Json(new {
success = true,
textLength = extractedText.Length,
preview = extractedText.Substring(0, Math.Min(500, extractedText.Length))
});
}
// Console application example
static void BatchParsePdfs(string folderPath)
{
var pdfFiles = Directory.GetFiles(folderPath, "*.pdf");
foreach (var file in pdfFiles)
{
var pdf = PdfDocument.FromFile(file);
var text = pdf.ExtractAllText();
// Save extracted text
var textFile = Path.ChangeExtension(file, ".txt");
File.WriteAllText(textFile, text);
Console.WriteLine($"Parsed: {Path.GetFileName(file)} - {text.Length} characters");
}
}Imports Microsoft.AspNetCore.Mvc
Imports System.IO
' ASP.NET Core example
Public Function ParseUploadedPdf(pdfFile As IFormFile) As IActionResult
Using stream = pdfFile.OpenReadStream()
Dim pdf = PdfDocument.FromStream(stream)
Dim extractedText = pdf.ExtractAllText()
' Process or store the extracted text
Return Json(New With {
.success = True,
.textLength = extractedText.Length,
.preview = extractedText.Substring(0, Math.Min(500, extractedText.Length))
})
End Using
End Function
' Console application example
Private Shared Sub BatchParsePdfs(folderPath As String)
Dim pdfFiles = Directory.GetFiles(folderPath, "*.pdf")
For Each file In pdfFiles
Dim pdf = PdfDocument.FromFile(file)
Dim text = pdf.ExtractAllText()
' Save extracted text
Dim textFile = Path.ChangeExtension(file, ".txt")
File.WriteAllText(textFile, text)
Console.WriteLine($"Parsed: {Path.GetFileName(file)} - {text.Length} characters")
Next
End SubEstos ejemplos muestran la incorporación del análisis sintáctico de PDF en aplicaciones web y escenarios de procesamiento por lotes. Para implementaciones avanzadas, explore las técnicas async y multithreading para mejorar el rendimiento al procesar varios PDF.
¿Listo para ver qué más puedes hacer? Consulte nuestra página de tutoriales aquí: Editar PDFs
Análisis de PDFs en flujos de trabajo fiscales españoles
El análisis programático de PDFs con IronPDF tiene aplicaciones directas en los procesos de cumplimiento normativo que operan en España:
-
Extracción de datos de facturas recibidas para el SII: Las empresas acogidas al sistema SII de la AEAT deben reportar el IVA repercutido y soportado en un plazo de cuatro días hábiles. IronPDF permite extraer automáticamente de los PDFs de facturas recibidas los campos clave (NIF proveedor, base imponible, tipo y cuota de IVA, fecha de operación) para alimentar el motor de generación de XML que se envía al servicio web del SII.
-
Parsing de PDFs de certificados AEAT: La AEAT emite certificados tributarios en formato PDF que los sistemas de gestión empresarial necesitan procesar para verificar la situación fiscal de proveedores o empleados. Con
ExtractAllTextde IronPDF y expresiones regulares, es posible extraer el NIF, el nombre y el estado de la deuda de estos certificados de forma automática. -
Generación de datos XML TicketBAI a partir de PDFs de tickets: Los ISVs del País Vasco que desarrollan software para el sistema TicketBAI pueden utilizar IronPDF para analizar PDFs de tickets emitidos por sistemas heredados y extraer los datos necesarios para construir el XML firmado que exige la normativa vasca.
-
Procesamiento de facturas recibidas de la plataforma FACe: Los departamentos de compras que reciben facturas electrónicas a través de FACe disponen de PDFs de representación adjuntos al XML Facturae. IronPDF facilita la extracción de datos de estos PDFs para su integración en sistemas ERP cuando el procesamiento directo del XML no está disponible.
- Análisis de documentos firmados con PAdES para auditoría: Los departamentos de cumplimiento normativo que deben auditar contratos y documentos firmados con firmas PAdES válidas bajo eIDAS pueden utilizar IronPDF para extraer el contenido textual de estos documentos y verificar la integridad de la información frente a los registros del sistema.
Preguntas Frecuentes
¿Cómo puedo extraer todo el texto de un archivo PDF en C#?
Puede extraer todo el texto de un archivo PDF utilizando el método ExtractAllText de IronPDF. Simplemente cargue su PDF con IronPdf.FromFile("sample.pdf") y llame a ExtractAllText() para recuperar todo el contenido de texto manteniendo el formato original.
¿Cuál es la forma más sencilla de analizar un PDF en .NET?
La forma más sencilla es utilizar IronPDF con una sola línea de código: var text = IronPdf.FromFile("sample.pdf").ExtractAllText(). Este método extrae cada línea de texto del documento PDF completo con una configuración mínima.
¿Puedo extraer texto de una página concreta de un PDF?
Sí, IronPDF proporciona el método ExtractTextFromPage para extraer texto de páginas individuales. Esto le permite dirigirse a secciones específicas de su documento PDF en lugar de extraer todo el contenido a la vez.
¿Cómo analizo en C# archivos PDF protegidos por contraseña?
IronPDF admite el análisis sintáctico de archivos PDF protegidos por contraseña. Utilice PdfDocument.FromFile("protected.pdf", "password123") para cargar el documento protegido y, a continuación, llame a ExtractAllText() para extraer el contenido de texto.
¿Puedo analizar archivos PDF a partir de URL en lugar de archivos locales?
Sí, IronPDF puede analizar PDFs directamente desde URLs utilizando PdfDocument.FromUrl("https://example.com/document.pdf"). Después de cargar el PDF desde la URL, utilice ExtractAllText() para extraer el contenido de texto.
¿Qué plataformas admite el analizador de PDF?
IronPDF admite el análisis sintáctico de PDF en varias plataformas, incluidas las aplicaciones de Windows, Linux, macOS y las implementaciones en la nube de Azure, lo que proporciona una compatibilidad multiplataforma completa para sus aplicaciones .NET.
¿El analizador de PDF mantiene el formato del texto durante la extracción?
Sí, el método ExtractAllText de IronPDF mantiene el formato original del contenido del PDF durante la extracción, garantizando que el texto analizado conserve la estructura y el diseño del documento de origen.
¿Puedo extraer texto e imágenes de un PDF?
IronPDF permite extraer texto e imágenes de documentos PDF. Además del método ExtractAllText para la extracción de texto, la biblioteca ofrece funciones adicionales para extraer imágenes de secciones específicas de documentos PDF.
¿Cómo puedo usar IronPDF para extraer datos de facturas de proveedores para el SII de la AEAT?
El SII (Suministro Inmediato de Información) requiere reportar las operaciones de IVA en tiempo real a la AEAT. Con IronPDF puede extraer texto de PDFs de facturas de proveedores usando ExtractAllText(), parsear los campos relevantes (NIF, fecha, base imponible, cuota IVA) y construir el XML de registro de factura recibida para enviarlo a la plataforma SII de la AEAT.
¿Qué consideraciones LOPDGDD aplican al extraer datos de PDFs con información personal en España?
La LOPDGDD y el RGPD establecen que el procesamiento de datos personales (como NIF, nombre o dirección) contenidos en PDFs requiere base legal apropiada (contrato, interés legítimo o consentimiento). Al usar IronPDF para extraer texto de facturas o documentos con datos personales en España, asegúrese de registrar la actividad en el registro de tratamientos del artículo 30 del RGPD.


¿Aún desplazándote?
¿Quieres una prueba rápida? PM > Install-Package IronPdf
ejecutar una muestra Mira cómo tu HTML se convierte en PDF.










