

C# PDF Parser
With the right tools, it can be easy to work with PDFs in C# and utilize all the functionality you need for a .NET application, including using C# parse PDF file capabilities. This tutorial will use IronPDF, a C# Library, to do that in just a couple straightforward steps.



How to Parse PDF File in C#
- Download C# PDF parser library
- Install in your Visual Studio
- Use the
ExtractAllTextmethod to extract every single line of text - Extract all text from a single page with the
ExtractTextFromPagemethod - View parsed PDF content
Install with NuGet
Install-Package IronPdf

C# Parse PDF File
Parsing PDF files is fairly easy. In the code below, we use the ExtractAllText method to extract every single line of text from the entire PDF document. Later on, you can see the side by side of the extracted PDF content, as the output.
:path=/static-assets/pdf/content-code-examples/how-to/csharp-parse-pdf-parse-pdf.csusing IronPdf;
// Select the desired PDF File
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract all text from an pdf
string allText = pdf.ExtractAllText();
// Extract all text from page 1
string page1Text = pdf.ExtractTextFromPage(0);Imports IronPdf
' Select the desired PDF File
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract all text from an pdf
Private allText As String = pdf.ExtractAllText()
' Extract all text from page 1
Private page1Text As String = pdf.ExtractTextFromPage(0)View Parsed PDF Content
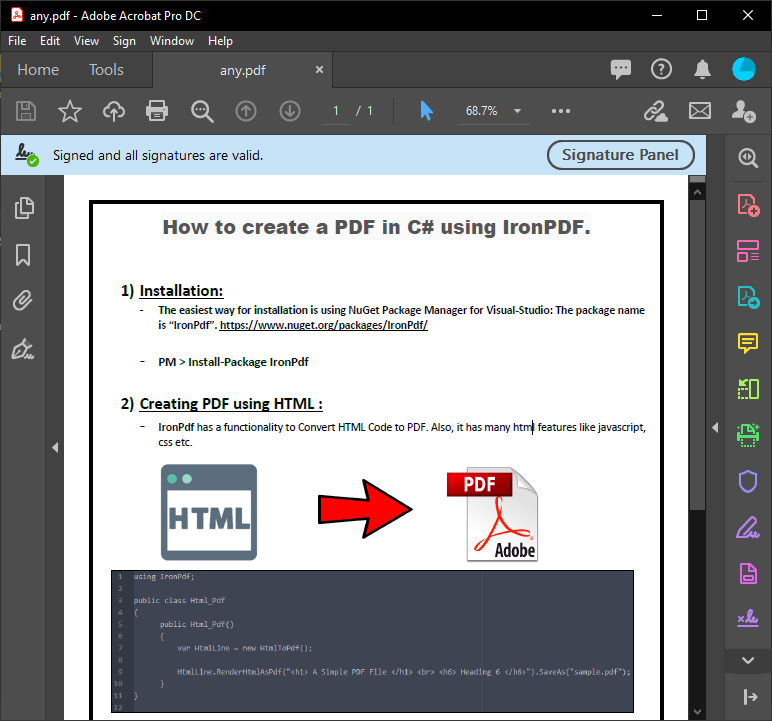
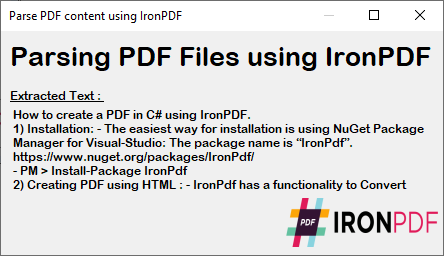
We have used a C# Form to show you the parsed PDF content from the code execution above. This output gives the exact text from a PDF so you can use it for your personal or client document needs.
~ PDF ~
~ C# Form ~
Library Quick Access

Documentation
Read the API Reference for documentation on IronPDF and all its functionality.
Documentation









