


Extract Embedded Text and Images from PDFs in C#
Extract both text content and images from PDF documents in C# with simple method calls. Retrieve embedded content for editing, analysis, or repurposing in other applications.
Text and image extraction retrieves textual content and graphical elements from PDF documents. Access and repurpose content for editing, searching, converting text to other formats, or saving images for reuse. Whether you need to parse PDFs in C# for data analysis, convert content to searchable formats, or extract visual elements for archiving, IronPDF provides comprehensive extraction tools.
Extract text and images using IronPDF. Save extracted images to disk or convert them to another format before embedding in new documents. This flexibility supports workflows requiring content transformation, such as converting PDFs to HTML or repurposing extracted images.
Quickstart: Extract Text and Images with IronPDF
Extract text and images from PDFs in just a few lines of code. This quickstart demonstrates how to retrieve embedded content from PDF documents for content repurposing and analysis. Extract text for editing or save images for further use with IronPDF's streamlined solution.
-
Install IronPDF with NuGet Package Manager
-
Copy and run this code snippet.
var pdf = new IronPdf.PdfDocument("sample.pdf"); string text = pdf.ExtractAllText(); var images = pdf.ExtractAllImages(); -
Deploy to test on your live environment
Start using IronPDF in your project today with a free trial

Minimal Workflow (5 steps)
- Download the
IronPdfC# Library - Prepare the PDF document for text and image extraction
- Use the
ExtractAllTextmethod to extract text - Use the
ExtractAllImagesmethod to extract images - Specify the particular pages from which to extract text and images
How Do I Extract Text from PDFs?
Extract text from both newly rendered and existing PDF documents. Use the ExtractAllText method to extract embedded text from the document. The method returns a string containing all text in the PDF. Pages are separated by four consecutive newline characters. This example uses a sample PDF rendered from the Wikipedia website.
When working with PDFs containing international languages and UTF-8 characters, IronPDF maintains proper encoding and character representation. This ensures correct display of non-Latin scripts and special characters.
:path=/static-assets/pdf/content-code-examples/how-to/extract-text-and-images-extract-text.csusing IronPdf;
using System.IO;
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract text
string text = pdf.ExtractAllText();
// Export the extracted text to a text file
File.WriteAllText("extractedText.txt", text);Imports IronPdf
Imports System.IO
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract text
Private text As String = pdf.ExtractAllText()
' Export the extracted text to a text file
File.WriteAllText("extractedText.txt", text)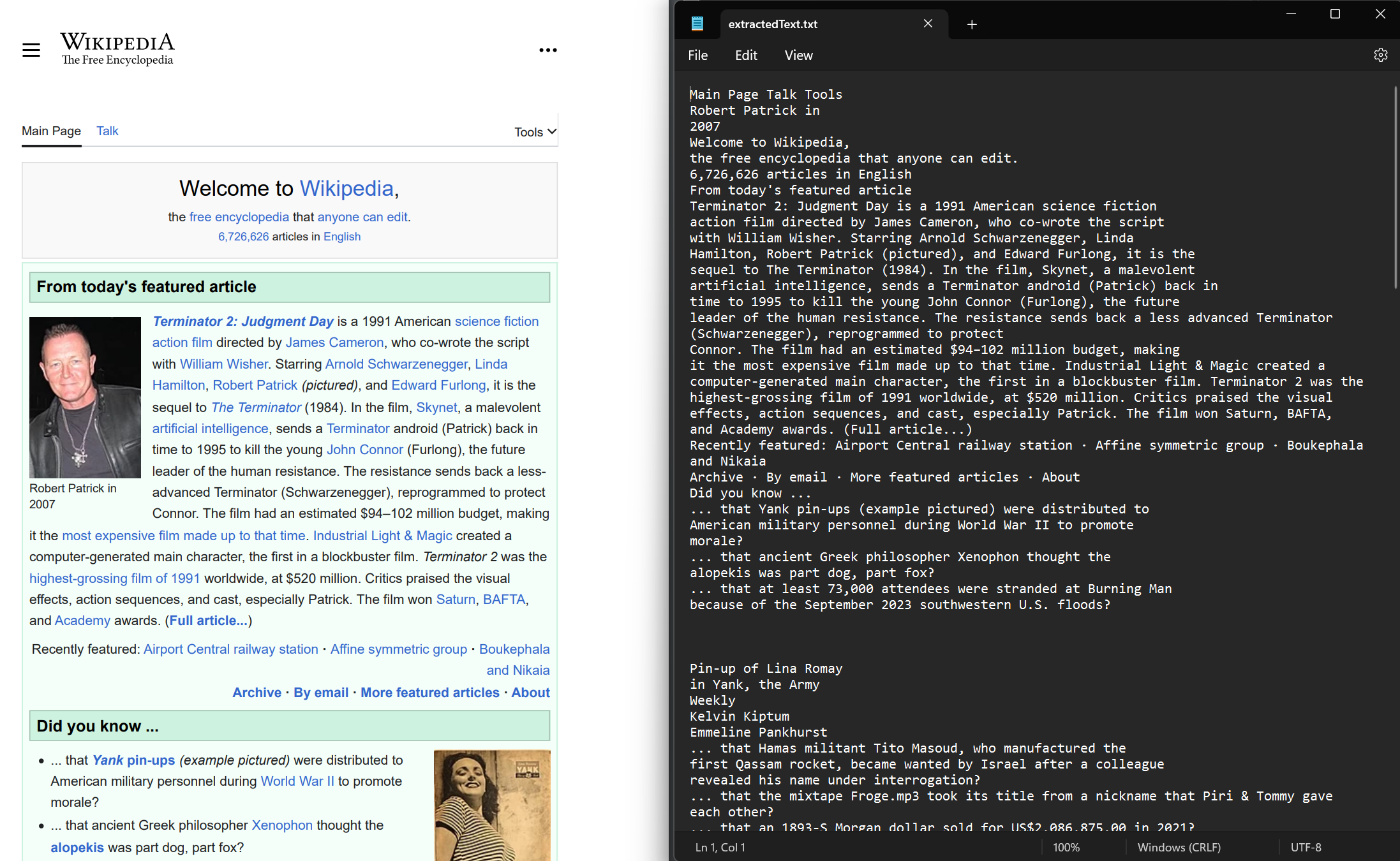
How Can I Extract Text with Precise Coordinates?
Retrieve the coordinates of text lines and characters within each PDF page. Select a page from the PDF and access the Lines and Characters properties. The coordinates include Top, Right, Bottom, and Left values representing text position. This feature preserves spatial layout and enables text position analysis.
For developers who need to read PDF files in C# with positional awareness, coordinate extraction provides data for maintaining document structure and implementing advanced text analysis.
:path=/static-assets/pdf/content-code-examples/how-to/extract-text-and-images-extract-text-by-line-character.csusing IronPdf;
using System.IO;
using System.Linq;
// Open PDF from file
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract text by lines
var lines = pdf.Pages[0].Lines;
// Extract text by characters
var characters = pdf.Pages[0].Characters;
File.WriteAllLines("lines.txt", lines.Select(l => $"at Y={l.BoundingBox.Bottom:F2}: {l.Contents}"));Imports IronPdf
Imports System.IO
Imports System.Linq
' Open PDF from file
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract text by lines
Private lines = pdf.Pages(0).Lines
' Extract text by characters
Private characters = pdf.Pages(0).Characters
File.WriteAllLines("lines.txt", lines.Select(Function(l) $"at Y={l.BoundingBox.Bottom:F2}: {l.Contents}"))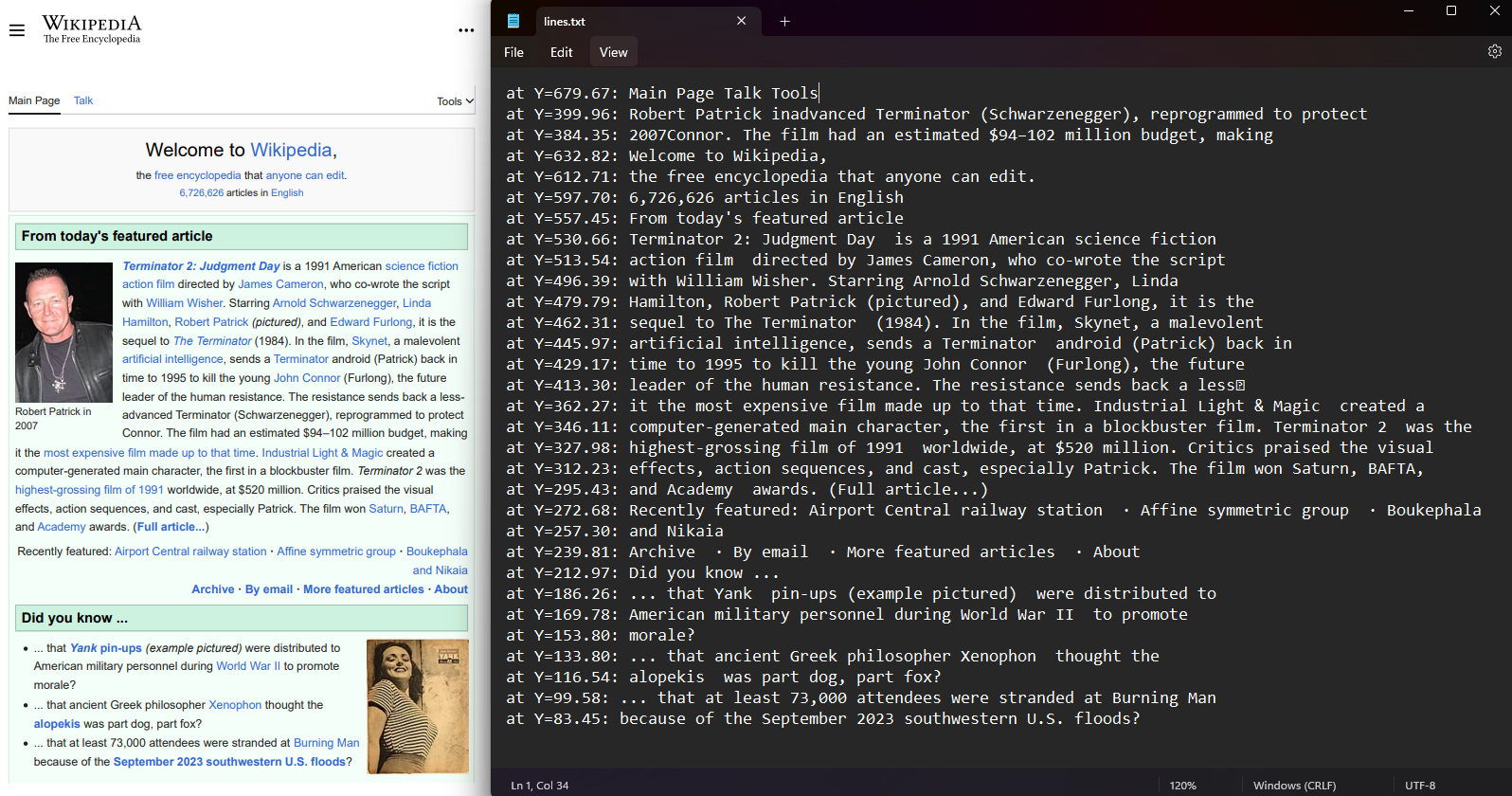
My favorite library of this kind is IronPDF. It allows for fast and efficient manipulation of PDF files. It also has many valuable features, like exporting to PDF/A format and digitally signing PDF documents.
IronOCR means we can save $40,000 annually from manual processing, while enhancing productivity and freeing up resources for high-impact tasks. I would highly recommend it.
The IronSuite play a crucial role in our operations. These are tools that increase efficiencies across the business including creating floor plans and improving inventory management.
How Do I Extract Images from PDFs?
Use the ExtractAllImages method to extract all embedded images from the document. The method returns images as a list of List of AnyBitmap objects. Using the same document, we extracted images and exported them to the 'images' folder. This functionality supports image archiving, content migration, and rasterizing PDF pages to images for further processing.
Extracted images maintain original quality and can be saved in various formats including PNG, JPEG, and BMP. For cloud storage workflows, integrate this functionality with Azure Blob Storage for image management.
:path=/static-assets/pdf/content-code-examples/how-to/extract-text-and-images-extract-image.csusing IronPdf;
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract images
var images = pdf.ExtractAllImages();
for(int i = 0; i < images.Count; i++)
{
// Export the extracted images
images[i].SaveAs($"images/image{i}.png");
}Imports IronPdf
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract images
Private images = pdf.ExtractAllImages()
For i As Integer = 0 To images.Count - 1
' Export the extracted images
images(i).SaveAs($"images/image{i}.png")
Next i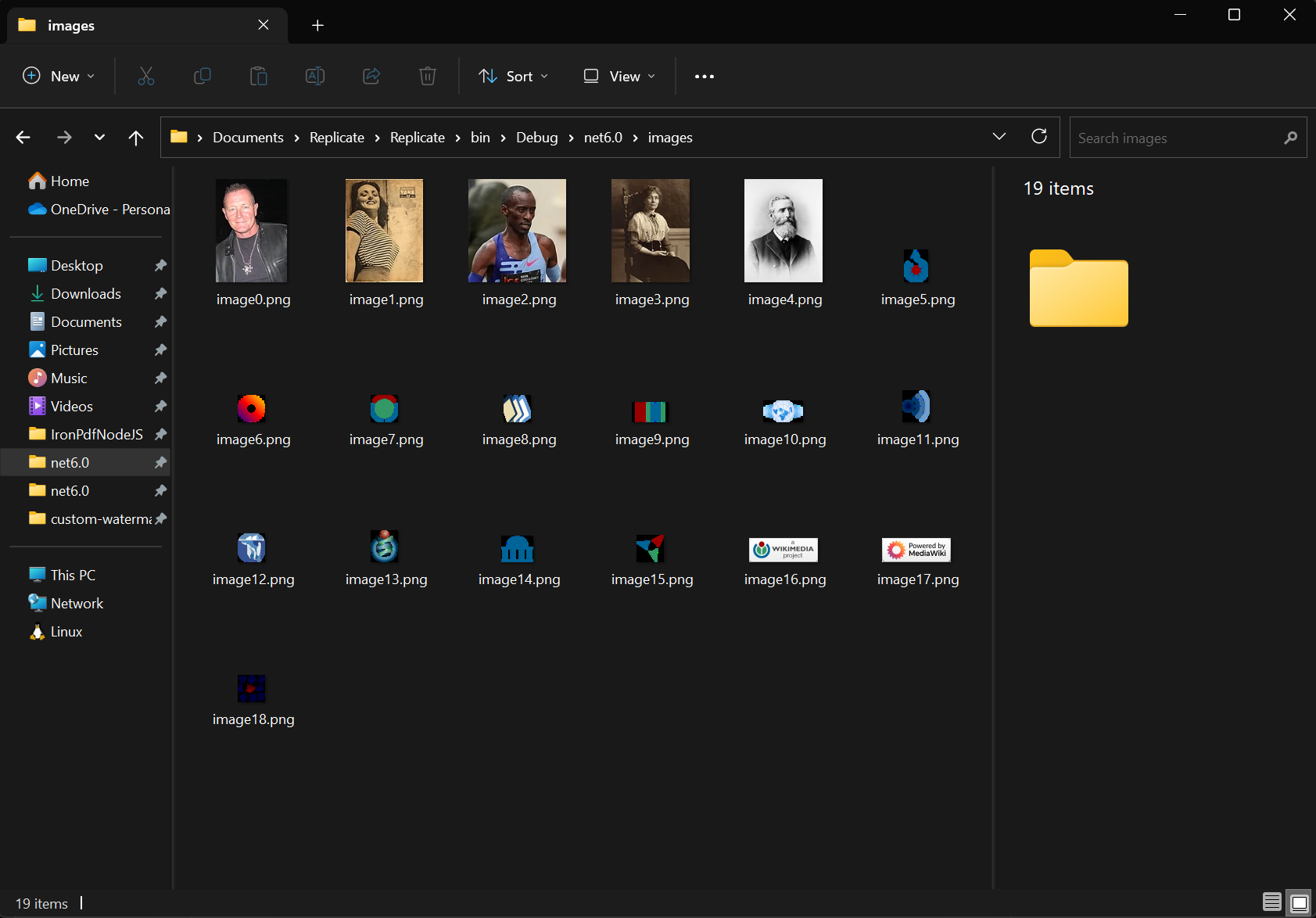
What Are the Different Methods for Image Extraction?
Beyond the ExtractAllImages method, use ExtractAllBitmaps and ExtractAllRawImages methods to extract image information. While ExtractAllBitmaps returns a List of AnyBitmap, ExtractAllRawImages extracts all images and returns them as raw byte[] (byte[]).
The ExtractAllRawImages method works well when processing image data in memory or integrating with systems requiring byte array inputs. For scenarios involving exporting PDFs to memory streams, the raw byte array format provides optimal flexibility.
How Do I Extract Content from Specific PDF Pages?
Extract text and images from single or multiple specified pages. Use ExtractTextFromPage and ExtractTextFromPages methods for text extraction from one or multiple pages. For images, use ExtractImagesFromPage and ExtractImagesFromPages methods.
This granular control helps when working with large documents where only specific sections contain relevant content. It also supports features to split PDFs and extract individual pages for separate processing.
:path=/static-assets/pdf/content-code-examples/how-to/extract-text-and-images-extract-text-single-multiple.csusing IronPdf;
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract text from page 1
string textFromPage1 = pdf.ExtractTextFromPage(0);
int[] pages = new[] { 0, 2 };
// Extract text from pages 1 & 3
string textFromPage1_3 = pdf.ExtractTextFromPages(pages);Imports IronPdf
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract text from page 1
Private textFromPage1 As String = pdf.ExtractTextFromPage(0)
Private pages() As Integer = { 0, 2 }
' Extract text from pages 1 & 3
Private textFromPage1_3 As String = pdf.ExtractTextFromPages(pages)When Should I Extract from Specific Pages Instead of All Pages?
Extract from specific pages when:
- Working with large PDFs containing relevant data in certain sections
- Implementing workflows that handle pages independently
- Building applications requiring incremental content display or processing
- Optimizing memory usage by processing only required pages
- Creating page-specific search or indexing functionality
What Performance Considerations Should I Know About?
Consider these performance factors when extracting PDF content:
- Memory Usage: Extract pages individually from large documents to minimize memory consumption
- Processing Time: Use parallel processing for multi-page extractions when appropriate
- File Size: Larger PDFs with high-resolution images require more processing time
- Storage: Plan adequate disk space for extracting numerous high-resolution images
- Threading: IronPDF supports multi-threaded operations for improved performance on multi-core systems
For optimal performance with in-memory PDFs, use memory stream operations to reduce disk I/O overhead.
Frequently Asked Questions
How do I extract text from PDF documents in C#?
Use IronPDF's ExtractAllText method to extract embedded text from PDF documents. The method returns a string containing all text in the PDF, with pages separated by four consecutive newline characters. IronPDF maintains proper encoding for international languages and UTF-8 characters.
Can I extract images from PDF files programmatically?
Yes, IronPDF provides the ExtractAllImages method to retrieve graphical elements from PDF documents. You can save extracted images to disk or convert them to other formats before embedding them in new documents.
What are the main use cases for PDF content extraction?
IronPDF's extraction tools support various workflows including parsing PDFs for data analysis, converting content to searchable formats, extracting visual elements for archiving, and repurposing content for editing or transformation into other formats like HTML.
How many lines of code does it take to extract PDF content?
With IronPDF, you can extract text and images in just a few lines of code. Simply load your PDF document and call ExtractAllText() for text extraction or ExtractAllImages() for image extraction.
Can I extract content from specific pages instead of the entire document?
Yes, IronPDF allows you to specify particular pages from which to extract text and images, giving you precise control over which content to retrieve from your PDF documents.


Still Scrolling?
Want proof fast? PM > Install-Package IronPdf
run a sample watch your HTML become a PDF.










