


Extract Embedded Text and Images from PDFs in C
Extraiga contenido de texto e imágenes de documentos PDF en C# con sencillas llamadas a métodos. Recuperar contenido incrustado para editarlo, analizarlo o reutilizarlo en otras aplicaciones.
La extracción de texto e imágenes recupera contenido textual y elementos gráficos de documentos PDF. Acceda a los contenidos y reutilícelos para editar, buscar, convertir texto a otros formatos o guardar imágenes para su reutilización. Tanto si necesita parse PDF en C# para el análisis de datos, convertir contenido a formatos que permitan búsquedas o extraer elementos visuales para archivarlos, IronPDF proporciona herramientas de extracción completas.
Extraiga texto e imágenes con IronPDF. Guarde las imágenes extraídas en el disco o conviértalas a otro formato antes de incrustarlas en nuevos documentos. Esta flexibilidad permite flujos de trabajo que requieren la transformación de contenidos, como convertir PDF a HTML o reutilizar imágenes extraídas.
Inicio rápido: Extraer texto e imágenes con IronPDF
Extraiga texto e imágenes de PDF en unas pocas líneas de código. Esta guía rápida muestra cómo recuperar contenido incrustado de documentos PDF para su reutilización y análisis. Extraiga texto para editarlo o guarde imágenes para su uso posterior con la solución optimizada de IronPDF.
-
Instala IronPDF con el Administrador de Paquetes NuGet
PM > Install-Package IronPdf -
Copie y ejecute este fragmento de código.
var pdf = new IronPdf.PdfDocument("sample.pdf"); string text = pdf.ExtractAllText(); var images = pdf.ExtractAllImages(); -
Despliegue para probar en su entorno real
Comienza a usar IronPDF en tu proyecto hoy mismo con una prueba gratuita

Flujo de trabajo mínimo (5 pasos)
- Descargar la Biblioteca
IronPdfC# - Prepara el documento PDF para la extracción de texto e imágenes
- Utilice el método
ExtractAllTextpara extraer texto - Utilizar el método
ExtractAllImagespara extraer imágenes - Especifica las páginas particulares de las que extraer texto e imágenes
¿Cómo extraer texto de un PDF?
Extraer texto tanto de documentos PDF nuevos como existentes. Utilice el método ExtractAllText para extraer texto incrustado del documento. El método devuelve una cadena que contiene todo el texto del PDF. Las páginas están separadas por cuatro caracteres de nueva línea consecutivos. Este ejemplo utiliza un PDF de ejemplo extraído del sitio web de Wikipedia.
Cuando se trabaja con archivos PDF que contienen idiomas internacionales y caracteres UTF-8, IronPDF mantiene la codificación y la representación de caracteres adecuadas. De este modo, se garantiza la correcta visualización de scripts no latinos y caracteres especiales.
:path=/static-assets/pdf/content-code-examples/how-to/extract-text-and-images-extract-text.csusing IronPdf;
using System.IO;
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract text
string text = pdf.ExtractAllText();
// Export the extracted text to a text file
File.WriteAllText("extractedText.txt", text);Imports IronPdf
Imports System.IO
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract text
Private text As String = pdf.ExtractAllText()
' Export the extracted text to a text file
File.WriteAllText("extractedText.txt", text)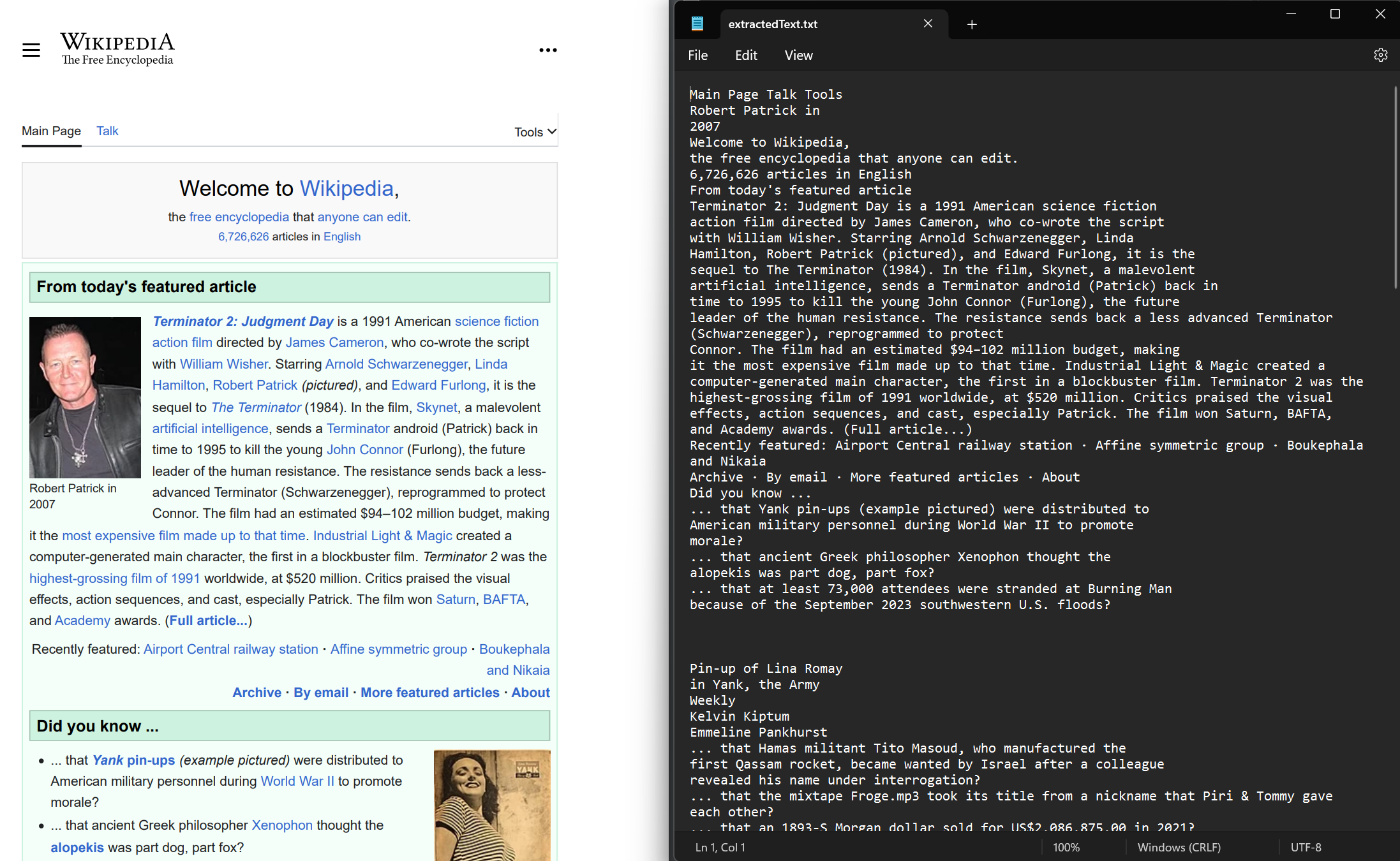
¿Cómo puedo extraer texto con coordenadas precisas?
Recuperar las coordenadas de líneas de texto y caracteres dentro de cada página PDF. Seleccione una página del PDF y acceda a las propiedades Lines y Characters. Las coordenadas incluyen valores de Top, Right, Bottom y Left que representan la posición del texto. Esta función conserva la disposición espacial y permite analizar la posición del texto.
Para los desarrolladores que necesiten leer archivos PDF en C# con conciencia posicional, la extracción de coordenadas proporciona datos para mantener la estructura del documento e implementar análisis de texto avanzados.
:path=/static-assets/pdf/content-code-examples/how-to/extract-text-and-images-extract-text-by-line-character.csusing IronPdf;
using System.IO;
using System.Linq;
// Open PDF from file
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract text by lines
var lines = pdf.Pages[0].Lines;
// Extract text by characters
var characters = pdf.Pages[0].Characters;
File.WriteAllLines("lines.txt", lines.Select(l => $"at Y={l.BoundingBox.Bottom:F2}: {l.Contents}"));Imports IronPdf
Imports System.IO
Imports System.Linq
' Open PDF from file
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract text by lines
Private lines = pdf.Pages(0).Lines
' Extract text by characters
Private characters = pdf.Pages(0).Characters
File.WriteAllLines("lines.txt", lines.Select(Function(l) $"at Y={l.BoundingBox.Bottom:F2}: {l.Contents}"))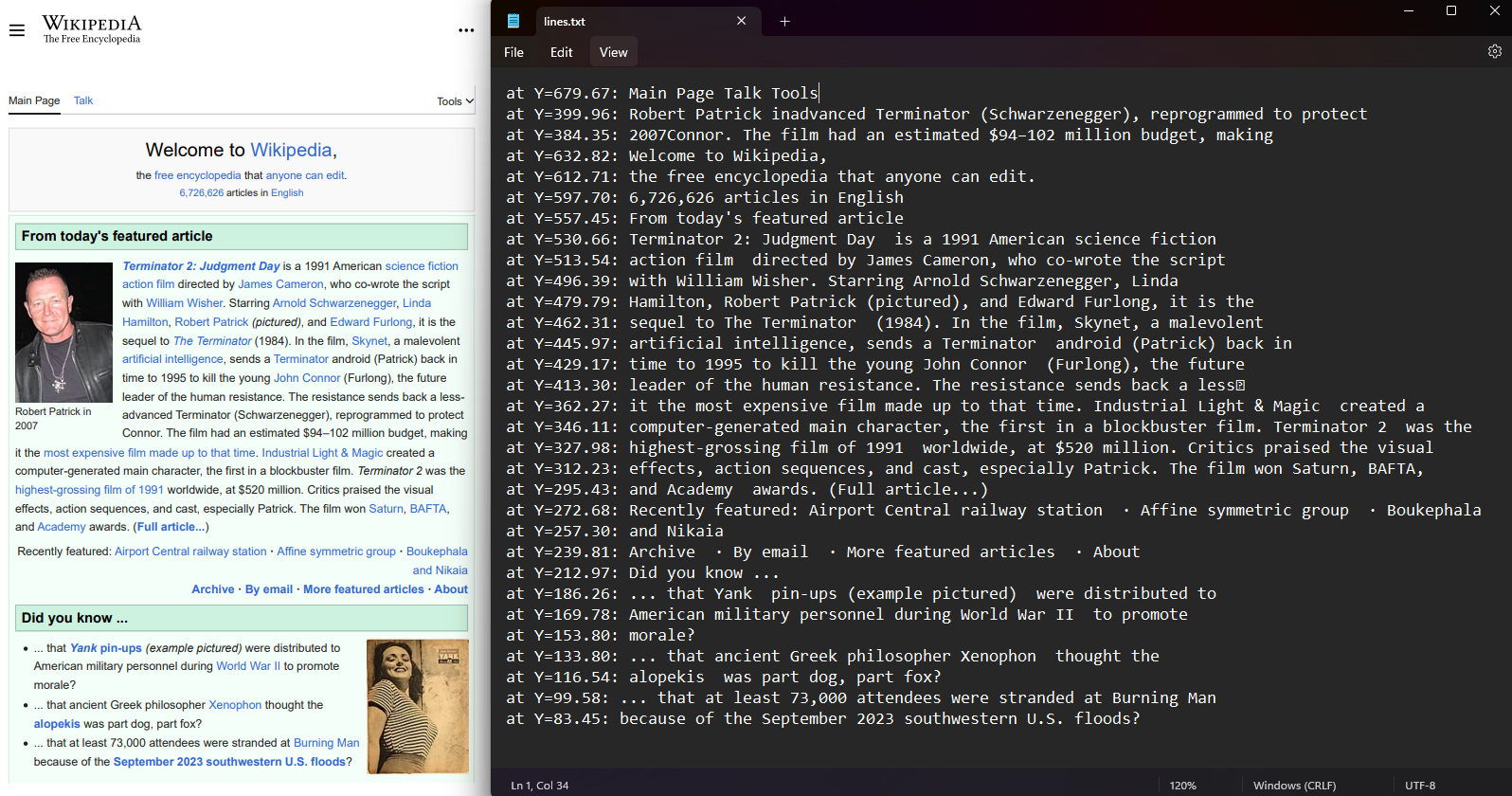
¿Cómo extraer imágenes de un PDF?
Utilice el método ExtractAllImages para extraer todas las imágenes incrustadas del documento. El método devuelve imágenes como una lista de List de objetos AnyBitmap. Utilizando el mismo documento, extrajimos imágenes y las exportamos a la carpeta "images". Esta funcionalidad permite archivar imágenes, migrar contenidos y rasterizar páginas PDF a imágenes para su posterior procesamiento.
Las imágenes extraídas mantienen la calidad original y pueden guardarse en varios formatos, como PNG, JPEG y BMP. Para flujos de trabajo de almacenamiento en la nube, integre esta funcionalidad con Azure Blob Storage para la gestión de imágenes.
:path=/static-assets/pdf/content-code-examples/how-to/extract-text-and-images-extract-image.csusing IronPdf;
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract images
var images = pdf.ExtractAllImages();
for(int i = 0; i < images.Count; i++)
{
// Export the extracted images
images[i].SaveAs($"images/image{i}.png");
}Imports IronPdf
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract images
Private images = pdf.ExtractAllImages()
For i As Integer = 0 To images.Count - 1
' Export the extracted images
images(i).SaveAs($"images/image{i}.png")
Next i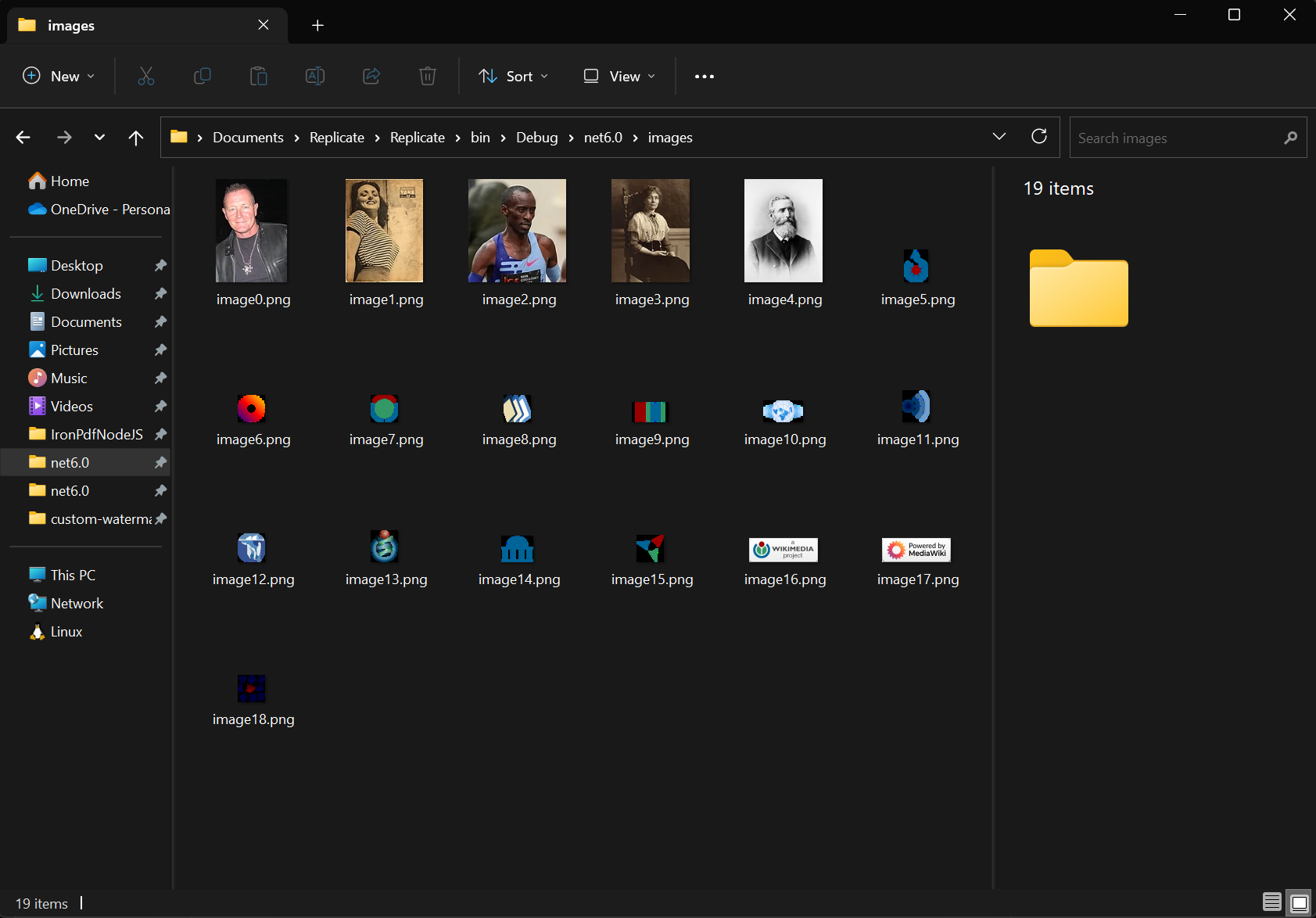
¿Cuáles son los diferentes métodos de extracción de imágenes?
Más allá del método ExtractAllImages, utilice los métodos ExtractAllBitmaps y ExtractAllRawImages para extraer información de imagen. Mientras ExtractAllBitmaps devuelve un List de AnyBitmap, ExtractAllRawImages extrae todas las imágenes y las devuelve como byte[] sin procesar (byte[]).
El método ExtractAllRawImages funciona bien al procesar datos de imagen en memoria o al integrarse con sistemas que requieren entradas de matriz de bytes. En el caso de exportar PDF a flujos de memoria, el formato de matriz de bytes sin procesar ofrece una flexibilidad óptima.
¿Cómo puedo extraer contenido de determinadas páginas PDF?
Extraer texto e imágenes de una o varias páginas especificadas. Utilice los métodos ExtractTextFromPage y ExtractTextFromPages para la extracción de texto de una o varias páginas. Para imágenes, utilice los métodos ExtractImagesFromPage y ExtractImagesFromPages.
Este control granular ayuda a la hora de trabajar con documentos extensos en los que solo hay secciones específicas con contenido relevante. También admite funciones para dividir PDF y extraer páginas individuales para procesarlas por separado.
:path=/static-assets/pdf/content-code-examples/how-to/extract-text-and-images-extract-text-single-multiple.csusing IronPdf;
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract text from page 1
string textFromPage1 = pdf.ExtractTextFromPage(0);
int[] pages = new[] { 0, 2 };
// Extract text from pages 1 & 3
string textFromPage1_3 = pdf.ExtractTextFromPages(pages);Imports IronPdf
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract text from page 1
Private textFromPage1 As String = pdf.ExtractTextFromPage(0)
Private pages() As Integer = { 0, 2 }
' Extract text from pages 1 & 3
Private textFromPage1_3 As String = pdf.ExtractTextFromPages(pages)¿Cuándo debo extraer de páginas específicas en lugar de todas las páginas?
Extraer de páginas específicas cuando:
- Trabajando con grandes PDFs que contienen datos relevantes en ciertas secciones
- Implementando flujos de trabajo que manejan páginas de manera independiente
- Construyendo aplicaciones que requieren visualización o procesamiento incremental de contenido
- Optimizando el uso de memoria procesando solo las páginas requeridas
- Creación de funciones de búsqueda o indexación específicas de la página
¿Qué consideraciones de rendimiento debo tener en cuenta?
Tenga en cuenta estos factores de rendimiento al extraer contenido PDF:
- Uso de Memoria: Extrae páginas indivualmente de documentos grandes para minimizar el consumo de memoria
- Tiempo de Procesamiento: Usa procesamiento paralelo para extracciones de varias páginas cuando sea apropiado
- Tamaño de Archivo: Los PDFs más grandes con imágenes de alta resolución requieren más tiempo de procesamiento
- Almacenamiento: Planea espacio adecuado en disco para extraer numerosas imágenes de alta resolución
- Procesos: IronPDF soporta operaciones multithread para mejorar el rendimiento en sistemas multinúcleo
Para obtener un rendimiento óptimo con los PDF en memoria, utilice operaciones de flujo de memoria para reducir la sobrecarga de E/S del disco.
Preguntas Frecuentes
¿Cómo extraer texto de documentos PDF en C#?
Utilice el método ExtractAllText de IronPDF para extraer texto incrustado de documentos PDF. El método devuelve una cadena que contiene todo el texto del PDF, con las páginas separadas por cuatro caracteres de nueva línea consecutivos. IronPDF mantiene la codificación adecuada para idiomas internacionales y caracteres UTF-8.
¿Puedo extraer imágenes de archivos PDF mediante programación?
Sí, IronPDF proporciona el método ExtractAllImages para recuperar elementos gráficos de documentos PDF. Puede guardar las imágenes extraídas en el disco o convertirlas a otros formatos antes de incrustarlas en nuevos documentos.
¿Cuáles son los principales casos de uso de la extracción de contenido PDF?
Las herramientas de extracción de IronPDF admiten varios flujos de trabajo, como el análisis sintáctico de PDF para el análisis de datos, la conversión de contenidos a formatos que permitan búsquedas, la extracción de elementos visuales para archivado y la reutilización de contenidos para su edición o transformación en otros formatos como HTML.
¿Cuántas líneas de código se necesitan para extraer el contenido de un PDF?
Con IronPDF, puede extraer texto e imágenes en unas pocas líneas de código. Simplemente cargue su documento PDF y llame a ExtractAllText() para la extracción de texto o a ExtractAllImages() para la extracción de imágenes.
¿Puedo extraer contenido de páginas específicas en lugar de todo el documento?
Sí, IronPDF le permite especificar páginas concretas de las que extraer texto e imágenes, lo que le proporciona un control preciso sobre qué contenido recuperar de sus documentos PDF.


¿Aún desplazándote?
¿Quieres una prueba rápida? PM > Install-Package IronPdf
ejecutar una muestra Mira cómo tu HTML se convierte en PDF.










