

Processamento em Lote de PDF em C#: Automatize Fluxos de Trabalho de Documentos em Escala
O processamento em lote de PDFs em C# com IronPDF permite que desenvolvedores .NET automatizem fluxos de trabalho de documentos em grande escala — desde a conversão paralela de HTML para PDF e mesclagem/divisão em massa até pipelines de PDF assíncronos com tratamento de erros integrado, lógica de repetição e pontos de verificação. O engine de Chromium com segurança de thread e gestão de memória baseada em IDisposable do IronPDF o torna construído propositalmente para automação de PDF de alta taxa de transferência, seja você executando on-premise, em Azure Functions, AWS Lambda ou Kubernetes.
Resumo: Guia de Início Rápido
Este tutorial aborda a automação escalável de PDFs em C# — desde conversão paralela e operações em lote até implantação em nuvem e padrões de pipeline resilientes.
- Para quem é indicado: Desenvolvedores e arquitetos .NET responsáveis por fluxos de trabalho com grande volume de documentos — projetos de migração de documentos, pipelines de geração de relatórios diários, verificações de conformidade ou esforços de digitalização de arquivos onde o processamento sequencial não é viável.
- O que você construirá: Conversão de HTML para PDF em paralelo com
Parallel.ForEach, operações de mesclagem e divisão de lote, pipelines assíncronos comSemaphoreSlimpara controle de concorrência, tratamento de erros com lógica de pular em falha e tentar novamente, padrões de ponto de verificação/reinício para recuperação de falhas e configurações de implantação em nuvem para Azure Functions, AWS Lambda e Kubernetes. - Onde funciona: .NET 6+, .NET Framework 4.6.2+, .NET Standard 2.0. Toda a renderização utiliza o mecanismo Chromium integrado do IronPDF — sem necessidade de navegadores sem interface gráfica ou serviços externos.
- Quando usar essa abordagem: Quando você precisa processar mais PDFs do que a execução sequencial permite — migração de documentos em grande escala, trabalhos em lote agendados com janelas de tempo apertadas ou plataformas multi-inquilino com cargas de documentos variáveis.
- Por que importa tecnicamente: O
ChromePdfRendererdo IronPDF é seguro para threads e sem estado por renderização, o que significa que múltiplos threads podem compartilhar com segurança uma única instância do renderizador. Combinado com a Biblioteca Paralela de Tarefas do .NET eIDisposableemPdfDocument, você obtém comportamento previsível de memória e saturação de CPU sem condições de corrida ou vazamentos de memória.
Converta em lote um diretório inteiro de arquivos HTML para PDF com apenas algumas linhas de código:
-
Instale IronPDF com o Gerenciador de Pacotes NuGet
-
Copie e execute este trecho de código.
using IronPdf; using System.IO; using System.Threading.Tasks; var renderer = new ChromePdfRenderer(); var htmlFiles = Directory.GetFiles("input/", "*.html"); Parallel.ForEach(htmlFiles, htmlFile => { var pdf = renderer.RenderHtmlFileAsPdf(htmlFile); pdf.SaveAs($"output/{Path.GetFileNameWithoutExtension(htmlFile)}.pdf"); }); -
Implante para testar em seu ambiente de produção.
Comece a usar IronPDF em seu projeto hoje com uma avaliação gratuita

Após adquirir ou se inscrever para um período de avaliação de 30 dias do IronPDF, adicione sua chave de licença no início do seu aplicativo.
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp-2.csIronPdf.License.LicenseKey = "KEY";
Imports IronPdf
IronPdf.License.LicenseKey = "KEY"Comece a usar IronPDF no seu projeto hoje mesmo com um teste gratuito.
Índice
- Compreendendo o problema
- Fundação
- Operações principais
- Resiliência
- Desempenho
- Implantação
- Juntando tudo
Quando você tem milhares de PDFs para processar.
O processamento em lote de PDFs não é uma necessidade específica — é uma parte rotineira da gestão de documentos empresariais. Os cenários que exigem isso surgem em todos os setores e compartilham uma característica comum: fazer as coisas uma de cada vez não é uma opção.
Projetos de migração de documentos são um dos gatilhos mais comuns. Quando uma organização migra de um sistema de gerenciamento de documentos para outro, milhares (às vezes milhões) de documentos precisam ser convertidos, reformatados ou reetiquetados. Uma seguradora que esteja migrando de um sistema de gestão de sinistros legado pode precisar converter 500.000 documentos de sinistros em formato TIFF para PDFs pesquisáveis. Um escritório de advocacia que migra para uma nova plataforma de gestão de casos pode precisar consolidar correspondências dispersas em arquivos de casos unificados. São trabalhos pontuais, mas de enorme dimensão e que não toleram erros.
A geração de relatórios diários é a versão em estado estacionário do mesmo problema. Instituições financeiras que produzem relatórios de portfólio de fim de dia para milhares de clientes, empresas de logística que geram manifestos de embarque para cada contêiner de saída, sistemas de saúde que criam resumos diários de pacientes em centenas de departamentos — todas essas entidades geram arquivos PDF em uma escala na qual o processamento sequencial ultrapassaria os prazos aceitáveis. Quando 10.000 relatórios precisam estar prontos até as 6h da manhã e os dados só são finalizados à meia-noite, você não tem seis horas para processá-los um por um.
A digitalização de arquivos situa-se na intersecção entre migração e conformidade. Agências governamentais, universidades e empresas com décadas de registros em papel enfrentam a obrigação de digitalizar e arquivar documentos em formatos compatíveis com os padrões (normalmente PDF/A). Os volumes são impressionantes — só o NARA recebe milhões de páginas de registros federais para preservação permanente — e o processo precisa ser suficientemente confiável para que não se descubram lacunas anos depois.
A regularização para garantir a conformidade costuma ser o fator mais urgente a ser considerado. Quando uma auditoria revela que seu arquivo de documentos não atende a um padrão recentemente imposto — por exemplo, suas faturas armazenadas não estão em conformidade com o formato PDF/A-3 para faturamento eletrônico, ou seus registros médicos não possuem a marcação de acessibilidade exigida pela Seção 508 — você precisa processar todo o seu arquivo existente de acordo com o novo padrão. A pressão é grande, o prazo é apertado e o volume é o que quer que seu arquivo contenha.
Em todos esses cenários, o principal desafio é o mesmo: como processar um grande número de operações em PDF de forma confiável, eficiente e sem ficar sem memória ou deixar trabalho inacabado para trás quando algo dá errado?
Infográfico mostrando quatro cenários de processamento em lote — Migração de Documentos, Geração de Relatórios Diários, Digitalização de Arquivos e Remediação de Conformidade — cada um com um ícone, faixa de volume típica e indicador de pressão de tempo.
Arquitetura de Processamento em Lote do IronPDF
Antes de abordar operações específicas, é importante entender como o IronPDF foi projetado para lidar com cargas de trabalho simultâneas e quais decisões arquitetônicas você deve tomar ao construir um pipeline em lote com base nele.
Instalando o IronPDF
Instale o IronPDF via NuGet:
Install-Package IronPdf
Ou usando a CLI do .NET:
dotnet add package IronPdf
O IronPDF é compatível com .NET Framework 4.6.2+, .NET Core, .NET 5 até .NET 10 e .NET Standard 2.0. Ele funciona em Windows, Linux, macOS e contêineres Docker, tornando-o adequado tanto para trabalhos em lote locais quanto para implantação nativa em nuvem.
Para processamento em lote de produção, configure sua chave de licença com License.LicenseKey na inicialização do aplicativo antes de qualquer operação de PDF começar. Isso garante que cada chamada de renderização em todas as threads tenha acesso ao conjunto completo de recursos, sem marcas d'água por arquivo.
Controle de Concorrência e Segurança de Threads
O mecanismo de renderização do IronPDF, baseado no Chromium, é seguro para uso com múltiplas threads. Você pode criar várias instâncias de ChromePdfRenderer em threads, ou compartilhar uma única instância — IronPDF lida com a sincronização interna. A recomendação oficial para processamento em lote é usar o Parallel.ForEach embutido no .NET, que distribui o trabalho por todos os núcleos de CPU disponíveis automaticamente.
Dito isso, "seguro para threads" não significa "usar threads ilimitados". Cada operação de renderização de PDF concorrente consome memória (o engine Chromium precisa de espaço de trabalho para análise DOM, layout CSS e rasterização de imagem), e iniciar muitas operações em paralelo em um sistema com memória limitada degradará o desempenho ou causará OutOfMemoryException. O nível ideal de processamento simultâneo depende do seu hardware: um servidor de 16 núcleos com 64 GB de RAM pode lidar confortavelmente com 8 a 12 renderizações simultâneas; uma VM de 4 núcleos com 8 GB pode estar limitada a 2–4. Controle isso com ParallelOptions.MaxDegreeOfParallelism — configure-o para aproximadamente metade dos núcleos de CPU disponíveis como ponto de partida, depois ajuste com base na pressão de memória observada.
Gerenciamento de memória em escala
O gerenciamento de memória é a principal preocupação no processamento em lote de PDFs. Cada objeto PdfDocument mantém o conteúdo binário completo de um PDF na memória, e não descartar esses objetos fará com que a memória cresça linearmente com o número de arquivos processados.
A regra crítica: sempre use declarações using ou chame explicitamente Dispose() em objetos PdfDocument. O PdfDocument do IronPDF implementa IDisposable, e não descartar é a causa mais comum de problemas de memória em cenários de lote. Cada iteração do seu loop de processamento deve criar um PdfDocument, fazer seu trabalho e descartar — nunca acumule objetos PdfDocument em uma lista ou coleção, a menos que você tenha um motivo específico e memória suficiente para lidar com isso.
Além do descarte, considere estas estratégias de gerenciamento de memória para grandes lotes:
Processe em partes, em vez de carregar tudo de uma vez. Se você precisar processar 50.000 arquivos, não os enumere todos em uma lista e depois itere — processe-os em lotes de 100 ou 500, permitindo que o coletor de lixo recupere a memória entre os lotes.
Forçar a coleta de lixo entre blocos para lotes extremamente grandes. Embora você geralmente deva deixar o GC se gerenciar, o processamento em lote é um dos raros cenários onde chamar GC.Collect() entre os limites de bloco pode evitar que a pressão de memória se acumule.
Monitore o consumo de memória usando GC.GetTotalMemory() ou métricas a nível de processo. Se o uso de memória exceder um limite (por exemplo, 80% da RAM disponível), o processamento será pausado para permitir que o coletor de lixo (GC) recupere o atraso.
Relatórios e Registros de Progresso
Quando uma tarefa em lote leva horas para ser concluída, a visibilidade do seu progresso não é opcional — é essencial. No mínimo, você deve registrar o início e o término de cada arquivo, acompanhar a contagem de sucessos/falhas e fornecer uma estimativa do tempo restante. Use Interlocked.Increment para contadores seguros para threads ao executar operações paralelas, e registre em intervalos regulares (a cada 50 ou 100 arquivos) em vez de em cada arquivo único para evitar inundar sua saída. Acompanhe seu tempo decorrido com System.Diagnostics.Stopwatch e calcule uma taxa de arquivos por segundo em execução para dar um ETA significativo.
Para trabalhos em lote de produção, considere gravar o progresso em um armazenamento persistente (banco de dados, arquivo ou fila de mensagens) para que os painéis de monitoramento possam exibir o status em tempo real sem precisar se conectar diretamente ao processo em lote.
Operações comuns em lote
Com a base arquitetônica estabelecida, vamos analisar as operações em lote mais comuns e suas implementações no IronPDF .
Conversão em lote de HTML para PDF
A conversão de HTML para PDF é a operação em lote mais comum. Quer você esteja gerando faturas a partir de modelos, convertendo uma biblioteca de documentação HTML em PDF ou renderizando relatórios dinâmicos de um aplicativo web, o padrão é o mesmo: itere sobre as entradas, renderize cada uma delas e salve a saída.
Entrada (5 arquivos HTML)
INV-2026-001
INV-2026-002
INV-2026-003
INV-2026-004
INV-2026-005
A implementação usa ChromePdfRenderer com Parallel.ForEach para processar todos os arquivos HTML simultaneamente, controlando o paralelismo através de MaxDegreeOfParallelism para equilibrar a taxa de transferência com o consumo de memória. Cada arquivo é renderizado com RenderHtmlFileAsPdf e salvo no diretório de saída, com rastreamento de progresso através de contadores seguros para threads Interlocked.
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-html-to-pdf.csusing IronPdf;
using System;
using System.IO;
using System.Threading.Tasks;
using System.Threading;
// Configure paths
string inputFolder = "input/";
string outputFolder = "output/";
Directory.CreateDirectory(outputFolder);
string[] htmlFiles = Directory.GetFiles(inputFolder, "*.html");
Console.WriteLine($"Found {htmlFiles.Length} HTML files to convert");
// Create renderer instance (thread-safe, can be shared)
var renderer = new ChromePdfRenderer();
// Track progress
int processed = 0;
int failed = 0;
// Process in parallel with controlled concurrency
var options = new ParallelOptions
{
MaxDegreeOfParallelism = Environment.ProcessorCount / 2
};
Parallel.ForEach(htmlFiles, options, htmlFile =>
{
try
{
string fileName = Path.GetFileNameWithoutExtension(htmlFile);
string outputPath = Path.Combine(outputFolder, $"{fileName}.pdf");
using var pdf = renderer.RenderHtmlFileAsPdf(htmlFile);
pdf.SaveAs(outputPath);
Interlocked.Increment(ref processed);
Console.WriteLine($"[OK] {fileName}.pdf");
}
catch (Exception ex)
{
Interlocked.Increment(ref failed);
Console.WriteLine($"[ERROR] {Path.GetFileName(htmlFile)}: {ex.Message}");
}
});
Console.WriteLine($"\nComplete: {processed} succeeded, {failed} failed");Imports IronPdf
Imports System
Imports System.IO
Imports System.Threading.Tasks
Imports System.Threading
' Configure paths
Dim inputFolder As String = "input/"
Dim outputFolder As String = "output/"
Directory.CreateDirectory(outputFolder)
Dim htmlFiles As String() = Directory.GetFiles(inputFolder, "*.html")
Console.WriteLine($"Found {htmlFiles.Length} HTML files to convert")
' Create renderer instance (thread-safe, can be shared)
Dim renderer As New ChromePdfRenderer()
' Track progress
Dim processed As Integer = 0
Dim failed As Integer = 0
' Process in parallel with controlled concurrency
Dim options As New ParallelOptions With {
.MaxDegreeOfParallelism = Environment.ProcessorCount \ 2
}
Parallel.ForEach(htmlFiles, options, Sub(htmlFile)
Try
Dim fileName As String = Path.GetFileNameWithoutExtension(htmlFile)
Dim outputPath As String = Path.Combine(outputFolder, $"{fileName}.pdf")
Using pdf = renderer.RenderHtmlFileAsPdf(htmlFile)
pdf.SaveAs(outputPath)
End Using
Interlocked.Increment(processed)
Console.WriteLine($"[OK] {fileName}.pdf")
Catch ex As Exception
Interlocked.Increment(failed)
Console.WriteLine($"[ERROR] {Path.GetFileName(htmlFile)}: {ex.Message}")
End Try
End Sub)
Console.WriteLine($"\nComplete: {processed} succeeded, {failed} failed")Saída
Cada fatura em HTML é convertida em um PDF correspondente. Acima está o arquivo INV-2026-001.pdf — um dos 5 resultados em lote.
Para geração baseada em modelos (por exemplo, faturas, relatórios), normalmente você mesclará os dados em um modelo HTML antes da renderização. A abordagem é direta: carregue seu template HTML uma vez, use string.Replace para injetar dados por registro (nome do cliente, totais, datas), e passe o HTML populado para RenderHtmlAsPdf dentro do seu loop paralelo. O IronPDF também fornece RenderHtmlAsPdfAsync para cenários onde você deseja usar async/await em vez de Parallel.ForEach — abordaremos padrões assíncronos em detalhes em uma seção posterior.
Fusão em lote de PDFs
A fusão de grupos de PDFs em documentos combinados é comum em fluxos de trabalho jurídicos (fusão de documentos de processos), financeiros (combinação de extratos mensais em relatórios trimestrais) e editoriais.
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-merge.csusing IronPdf;
using System;
using System.IO;
using System.Linq;
using System.Collections.Generic;
string inputFolder = "documents/";
string outputFolder = "merged/";
Directory.CreateDirectory(outputFolder);
// Group PDFs by prefix (e.g., "invoice-2026-01-*.pdf" -> one merged file)
var pdfFiles = Directory.GetFiles(inputFolder, "*.pdf");
var groups = pdfFiles
.GroupBy(f => Path.GetFileName(f).Split('-').Take(3).Aggregate((a, b) => $"{a}-{b}"))
.Where(g => g.Count() > 1);
Console.WriteLine($"Found {groups.Count()} groups to merge");
foreach (var group in groups)
{
string groupName = group.Key;
var filesToMerge = group.OrderBy(f => f).ToList();
Console.WriteLine($"Merging {filesToMerge.Count} files into {groupName}.pdf");
try
{
// Load all PDFs for this group
var pdfDocs = new List<PdfDocument>();
foreach (string filePath in filesToMerge)
{
pdfDocs.Add(PdfDocument.FromFile(filePath));
}
// Merge all documents
using var merged = PdfDocument.Merge(pdfDocs);
merged.SaveAs(Path.Combine(outputFolder, $"{groupName}-merged.pdf"));
// Dispose source documents
foreach (var doc in pdfDocs)
{
doc.Dispose();
}
Console.WriteLine($" [OK] Created {groupName}-merged.pdf ({merged.PageCount} pages)");
}
catch (Exception ex)
{
Console.WriteLine($" [ERROR] {groupName}: {ex.Message}");
}
}
Console.WriteLine("\nMerge complete");Imports IronPdf
Imports System
Imports System.IO
Imports System.Linq
Imports System.Collections.Generic
Module Program
Sub Main()
Dim inputFolder As String = "documents/"
Dim outputFolder As String = "merged/"
Directory.CreateDirectory(outputFolder)
' Group PDFs by prefix (e.g., "invoice-2026-01-*.pdf" -> one merged file)
Dim pdfFiles = Directory.GetFiles(inputFolder, "*.pdf")
Dim groups = pdfFiles _
.GroupBy(Function(f) Path.GetFileName(f).Split("-"c).Take(3).Aggregate(Function(a, b) $"{a}-{b}")) _
.Where(Function(g) g.Count() > 1)
Console.WriteLine($"Found {groups.Count()} groups to merge")
For Each group In groups
Dim groupName As String = group.Key
Dim filesToMerge = group.OrderBy(Function(f) f).ToList()
Console.WriteLine($"Merging {filesToMerge.Count} files into {groupName}.pdf")
Try
' Load all PDFs for this group
Dim pdfDocs As New List(Of PdfDocument)()
For Each filePath As String In filesToMerge
pdfDocs.Add(PdfDocument.FromFile(filePath))
Next
' Merge all documents
Using merged = PdfDocument.Merge(pdfDocs)
merged.SaveAs(Path.Combine(outputFolder, $"{groupName}-merged.pdf"))
End Using
' Dispose source documents
For Each doc In pdfDocs
doc.Dispose()
Next
Console.WriteLine($" [OK] Created {groupName}-merged.pdf ({merged.PageCount} pages)")
Catch ex As Exception
Console.WriteLine($" [ERROR] {groupName}: {ex.Message}")
End Try
Next
Console.WriteLine(vbCrLf & "Merge complete")
End Sub
End ModulePara mesclar um grande número de arquivos, esteja ciente da memória: o método PdfDocument.Merge carrega todos os documentos de origem na memória simultaneamente. Se você estiver mesclando centenas de PDFs grandes, considere fazer a mesclagem em etapas — combine grupos de 10 a 20 arquivos em documentos intermediários e, em seguida, mescle esses documentos intermediários.
Divisão em lote de PDF
Dividir PDFs com várias páginas em páginas individuais (ou intervalos de páginas) é o inverso da mesclagem. Comum no processamento de correspondências, onde um lote de documentos digitalizados precisa ser separado em registros individuais, e em fluxos de trabalho de impressão, onde documentos compostos precisam ser divididos.
Entrada
O código abaixo demonstra a extração de páginas individuais usando CopyPage em um loop paralelo, criando arquivos PDF separados para cada página. Uma função auxiliar SplitByRange alternativa mostra como extrair intervalos de páginas em vez de páginas individuais, útil para dividir documentos grandes em segmentos menores.
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-split.csusing IronPdf;
using System;
using System.IO;
using System.Threading.Tasks;
string inputFolder = "multipage/";
string outputFolder = "split/";
Directory.CreateDirectory(outputFolder);
string[] pdfFiles = Directory.GetFiles(inputFolder, "*.pdf");
Console.WriteLine($"Found {pdfFiles.Length} PDFs to split");
var options = new ParallelOptions
{
MaxDegreeOfParallelism = Environment.ProcessorCount / 2
};
Parallel.ForEach(pdfFiles, options, pdfFile =>
{
string baseName = Path.GetFileNameWithoutExtension(pdfFile);
try
{
using var pdf = PdfDocument.FromFile(pdfFile);
int pageCount = pdf.PageCount;
Console.WriteLine($"Splitting {baseName}.pdf ({pageCount} pages)");
// Extract each page as a separate PDF
for (int i = 0; i < pageCount; i++)
{
using var singlePage = pdf.CopyPage(i);
string outputPath = Path.Combine(outputFolder, $"{baseName}-page-{i + 1:D3}.pdf");
singlePage.SaveAs(outputPath);
}
Console.WriteLine($" [OK] Created {pageCount} files from {baseName}.pdf");
}
catch (Exception ex)
{
Console.WriteLine($" [ERROR] {baseName}: {ex.Message}");
}
});
// Alternative: Extract page ranges instead of individual pages
void SplitByRange(string inputFile, string outputFolder, int pagesPerChunk)
{
using var pdf = PdfDocument.FromFile(inputFile);
string baseName = Path.GetFileNameWithoutExtension(inputFile);
int totalPages = pdf.PageCount;
int chunkNumber = 1;
for (int startPage = 0; startPage < totalPages; startPage += pagesPerChunk)
{
int endPage = Math.Min(startPage + pagesPerChunk - 1, totalPages - 1);
using var chunk = pdf.CopyPages(startPage, endPage);
chunk.SaveAs(Path.Combine(outputFolder, $"{baseName}-chunk-{chunkNumber:D3}.pdf"));
chunkNumber++;
}
}
Console.WriteLine("\nSplit complete");Imports IronPdf
Imports System
Imports System.IO
Imports System.Threading.Tasks
Module Program
Sub Main()
Dim inputFolder As String = "multipage/"
Dim outputFolder As String = "split/"
Directory.CreateDirectory(outputFolder)
Dim pdfFiles As String() = Directory.GetFiles(inputFolder, "*.pdf")
Console.WriteLine($"Found {pdfFiles.Length} PDFs to split")
Dim options As New ParallelOptions With {
.MaxDegreeOfParallelism = Environment.ProcessorCount \ 2
}
Parallel.ForEach(pdfFiles, options, Sub(pdfFile)
Dim baseName As String = Path.GetFileNameWithoutExtension(pdfFile)
Try
Using pdf = PdfDocument.FromFile(pdfFile)
Dim pageCount As Integer = pdf.PageCount
Console.WriteLine($"Splitting {baseName}.pdf ({pageCount} pages)")
' Extract each page as a separate PDF
For i As Integer = 0 To pageCount - 1
Using singlePage = pdf.CopyPage(i)
Dim outputPath As String = Path.Combine(outputFolder, $"{baseName}-page-{i + 1:D3}.pdf")
singlePage.SaveAs(outputPath)
End Using
Next
Console.WriteLine($" [OK] Created {pageCount} files from {baseName}.pdf")
End Using
Catch ex As Exception
Console.WriteLine($" [ERROR] {baseName}: {ex.Message}")
End Try
End Sub)
' Alternative: Extract page ranges instead of individual pages
Sub SplitByRange(inputFile As String, outputFolder As String, pagesPerChunk As Integer)
Using pdf = PdfDocument.FromFile(inputFile)
Dim baseName As String = Path.GetFileNameWithoutExtension(inputFile)
Dim totalPages As Integer = pdf.PageCount
Dim chunkNumber As Integer = 1
For startPage As Integer = 0 To totalPages - 1 Step pagesPerChunk
Dim endPage As Integer = Math.Min(startPage + pagesPerChunk - 1, totalPages - 1)
Using chunk = pdf.CopyPages(startPage, endPage)
chunk.SaveAs(Path.Combine(outputFolder, $"{baseName}-chunk-{chunkNumber:D3}.pdf"))
chunkNumber += 1
End Using
Next
End Using
End Sub
Console.WriteLine(vbCrLf & "Split complete")
End Sub
End ModuleSaída
Página 2 extraída como PDF independente (annual-report-page-2.pdf)
Os métodos CopyPage e CopyPages do IronPDF criam novos objetos PdfDocument contendo as páginas especificadas. Lembre-se de descartar tanto o documento original quanto cada página extraída após salvar.
Compressão em lote
Quando os custos de armazenamento são importantes ou quando você precisa transmitir PDFs por conexões com largura de banda limitada, a compressão em lote pode reduzir drasticamente o espaço ocupado pelo seu arquivo. O IronPDF oferece duas abordagens de compressão: CompressImages para reduzir a qualidade/tamanho da imagem, e CompressStructTree para remover metadados estruturais. A nova API CompressAndSaveAs (introduzida na versão 2025.12) oferece compressão superior combinando múltiplas técnicas de otimização.
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-compression.csusing IronPdf;
using System;
using System.IO;
using System.Threading.Tasks;
using System.Threading;
string inputFolder = "originals/";
string outputFolder = "compressed/";
Directory.CreateDirectory(outputFolder);
string[] pdfFiles = Directory.GetFiles(inputFolder, "*.pdf");
Console.WriteLine($"Found {pdfFiles.Length} PDFs to compress");
long totalOriginalSize = 0;
long totalCompressedSize = 0;
int processed = 0;
var options = new ParallelOptions
{
MaxDegreeOfParallelism = Environment.ProcessorCount / 2
};
Parallel.ForEach(pdfFiles, options, pdfFile =>
{
string fileName = Path.GetFileName(pdfFile);
string outputPath = Path.Combine(outputFolder, fileName);
try
{
long originalSize = new FileInfo(pdfFile).Length;
Interlocked.Add(ref totalOriginalSize, originalSize);
using var pdf = PdfDocument.FromFile(pdfFile);
// Apply compression with JPEG quality setting (0-100, lower = more compression)
pdf.CompressAndSaveAs(outputPath, 60);
long compressedSize = new FileInfo(outputPath).Length;
Interlocked.Add(ref totalCompressedSize, compressedSize);
Interlocked.Increment(ref processed);
double reduction = (1 - (double)compressedSize / originalSize) * 100;
Console.WriteLine($"[OK] {fileName}: {originalSize / 1024}KB → {compressedSize / 1024}KB ({reduction:F1}% reduction)");
}
catch (Exception ex)
{
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}");
}
});
double totalReduction = (1 - (double)totalCompressedSize / totalOriginalSize) * 100;
Console.WriteLine($"\nCompression complete:");
Console.WriteLine($" Files processed: {processed}");
Console.WriteLine($" Total original: {totalOriginalSize / 1024 / 1024}MB");
Console.WriteLine($" Total compressed: {totalCompressedSize / 1024 / 1024}MB");
Console.WriteLine($" Overall reduction: {totalReduction:F1}%");Imports IronPdf
Imports System
Imports System.IO
Imports System.Threading.Tasks
Imports System.Threading
Module Program
Sub Main()
Dim inputFolder As String = "originals/"
Dim outputFolder As String = "compressed/"
Directory.CreateDirectory(outputFolder)
Dim pdfFiles As String() = Directory.GetFiles(inputFolder, "*.pdf")
Console.WriteLine($"Found {pdfFiles.Length} PDFs to compress")
Dim totalOriginalSize As Long = 0
Dim totalCompressedSize As Long = 0
Dim processed As Integer = 0
Dim options As New ParallelOptions With {
.MaxDegreeOfParallelism = Environment.ProcessorCount \ 2
}
Parallel.ForEach(pdfFiles, options, Sub(pdfFile)
Dim fileName As String = Path.GetFileName(pdfFile)
Dim outputPath As String = Path.Combine(outputFolder, fileName)
Try
Dim originalSize As Long = New FileInfo(pdfFile).Length
Interlocked.Add(totalOriginalSize, originalSize)
Using pdf = PdfDocument.FromFile(pdfFile)
' Apply compression with JPEG quality setting (0-100, lower = more compression)
pdf.CompressAndSaveAs(outputPath, 60)
End Using
Dim compressedSize As Long = New FileInfo(outputPath).Length
Interlocked.Add(totalCompressedSize, compressedSize)
Interlocked.Increment(processed)
Dim reduction As Double = (1 - CDbl(compressedSize) / originalSize) * 100
Console.WriteLine($"[OK] {fileName}: {originalSize \ 1024}KB → {compressedSize \ 1024}KB ({reduction:F1}% reduction)")
Catch ex As Exception
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}")
End Try
End Sub)
Dim totalReduction As Double = (1 - CDbl(totalCompressedSize) / totalOriginalSize) * 100
Console.WriteLine(vbCrLf & "Compression complete:")
Console.WriteLine($" Files processed: {processed}")
Console.WriteLine($" Total original: {totalOriginalSize \ 1024 \ 1024}MB")
Console.WriteLine($" Total compressed: {totalCompressedSize \ 1024 \ 1024}MB")
Console.WriteLine($" Overall reduction: {totalReduction:F1}%")
End Sub
End ModuleAlgumas coisas a ter em mente sobre compressão: configurações de qualidade JPEG abaixo de 60 produzirão artefatos visíveis na maioria das imagens. A opção ShrinkImage pode causar distorção em algumas configurações — teste com amostras representativas antes de executar um lote completo. E remover a árvore de estrutura (CompressStructTree) afetará a seleção de texto e busca nos PDFs comprimidos, então use apenas quando essas capacidades não forem necessárias.
Conversão em lote de formatos (PDF/A, PDF/UA)
Converter um arquivo existente para um formato compatível com os padrões — PDF/A para arquivamento de longo prazo ou PDF/UA para acessibilidade — é uma das operações em lote de maior valor. O IronPDF oferece suporte a toda a gama de versões do PDF/A (incluindo PDF/A-4, adicionado na versão 2025.11) e conformidade com PDF/UA (incluindo PDF/UA-2, adicionado na versão 2025.12).
Entrada
O exemplo carrega cada PDF com PdfDocument.FromFile, em seguida, converte para PDF/A-3b usando SaveAsPdfA com o parâmetro PdfAVersions.PdfA3b. Uma função alternativa ConvertToPdfUA demonstra conversão compatível com acessibilidade usando SaveAsPdfUA, embora PDF/UA requeira documentos de origem com marcação estrutural adequada.
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-format-conversion.csusing IronPdf;
using System;
using System.IO;
using System.Threading.Tasks;
using System.Threading;
string inputFolder = "originals/";
string outputFolder = "pdfa-archive/";
Directory.CreateDirectory(outputFolder);
string[] pdfFiles = Directory.GetFiles(inputFolder, "*.pdf");
Console.WriteLine($"Found {pdfFiles.Length} PDFs to convert to PDF/A-3b");
int converted = 0;
int failed = 0;
var options = new ParallelOptions
{
MaxDegreeOfParallelism = Environment.ProcessorCount / 2
};
Parallel.ForEach(pdfFiles, options, pdfFile =>
{
string fileName = Path.GetFileName(pdfFile);
string outputPath = Path.Combine(outputFolder, fileName);
try
{
using var pdf = PdfDocument.FromFile(pdfFile);
// Convert to PDF/A-3b for long-term archival
pdf.SaveAsPdfA(outputPath, PdfAVersions.PdfA3b);
Interlocked.Increment(ref converted);
Console.WriteLine($"[OK] {fileName} → PDF/A-3b");
}
catch (Exception ex)
{
Interlocked.Increment(ref failed);
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}");
}
});
Console.WriteLine($"\nConversion complete: {converted} succeeded, {failed} failed");
// Alternative: Convert to PDF/UA for accessibility compliance
void ConvertToPdfUA(string inputFolder, string outputFolder)
{
Directory.CreateDirectory(outputFolder);
string[] files = Directory.GetFiles(inputFolder, "*.pdf");
Parallel.ForEach(files, pdfFile =>
{
string fileName = Path.GetFileName(pdfFile);
try
{
using var pdf = PdfDocument.FromFile(pdfFile);
// PDF/UA requires proper tagging - ensure source is well-structured
pdf.SaveAsPdfUA(Path.Combine(outputFolder, fileName));
Console.WriteLine($"[OK] {fileName} → PDF/UA");
}
catch (Exception ex)
{
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}");
}
});
}Imports IronPdf
Imports System
Imports System.IO
Imports System.Threading.Tasks
Imports System.Threading
Module Program
Sub Main()
Dim inputFolder As String = "originals/"
Dim outputFolder As String = "pdfa-archive/"
Directory.CreateDirectory(outputFolder)
Dim pdfFiles As String() = Directory.GetFiles(inputFolder, "*.pdf")
Console.WriteLine($"Found {pdfFiles.Length} PDFs to convert to PDF/A-3b")
Dim converted As Integer = 0
Dim failed As Integer = 0
Dim options As New ParallelOptions With {
.MaxDegreeOfParallelism = Environment.ProcessorCount \ 2
}
Parallel.ForEach(pdfFiles, options, Sub(pdfFile)
Dim fileName As String = Path.GetFileName(pdfFile)
Dim outputPath As String = Path.Combine(outputFolder, fileName)
Try
Using pdf = PdfDocument.FromFile(pdfFile)
' Convert to PDF/A-3b for long-term archival
pdf.SaveAsPdfA(outputPath, PdfAVersions.PdfA3b)
Interlocked.Increment(converted)
Console.WriteLine($"[OK] {fileName} → PDF/A-3b")
End Using
Catch ex As Exception
Interlocked.Increment(failed)
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}")
End Try
End Sub)
Console.WriteLine($"{vbCrLf}Conversion complete: {converted} succeeded, {failed} failed")
End Sub
' Alternative: Convert to PDF/UA for accessibility compliance
Sub ConvertToPdfUA(inputFolder As String, outputFolder As String)
Directory.CreateDirectory(outputFolder)
Dim files As String() = Directory.GetFiles(inputFolder, "*.pdf")
Parallel.ForEach(files, Sub(pdfFile)
Dim fileName As String = Path.GetFileName(pdfFile)
Try
Using pdf = PdfDocument.FromFile(pdfFile)
' PDF/UA requires proper tagging - ensure source is well-structured
pdf.SaveAsPdfUA(Path.Combine(outputFolder, fileName))
Console.WriteLine($"[OK] {fileName} → PDF/UA")
End Using
Catch ex As Exception
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}")
End Try
End Sub)
End Sub
End ModuleSaída
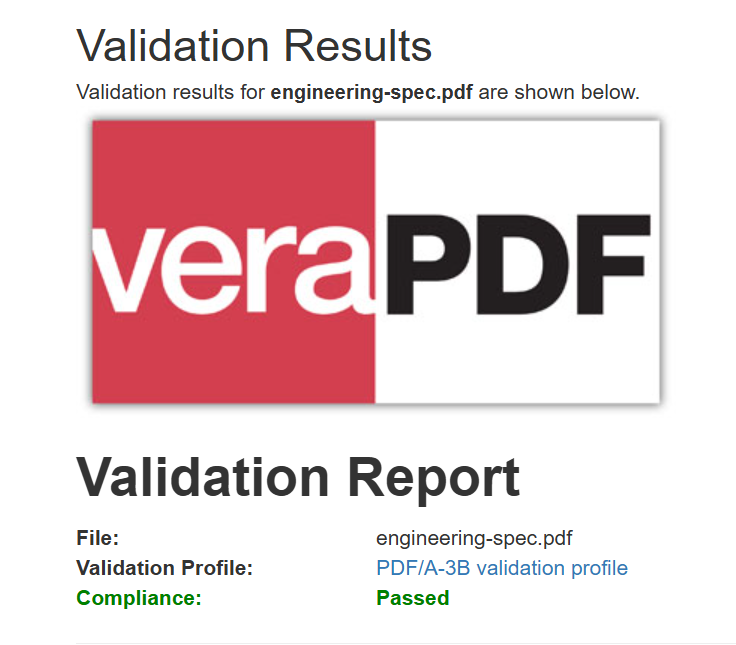
O PDF gerado é idêntico em aparência, byte a byte, mas agora contém metadados de conformidade com o padrão PDF/A-3b para sistemas de arquivamento.
A conversão de formato é particularmente importante para projetos de adequação à conformidade, nos quais uma organização descobre que seu arquivo existente não atende a um padrão regulatório. O processo em lote é simples, mas a etapa de validação é crucial — sempre verifique se cada arquivo convertido realmente passa nas verificações de conformidade antes de considerá-lo concluído. Abordamos a validação em detalhes na seção sobre resiliência abaixo.
Construindo Pipelines de Processamento em Lote Resilientes
Um pipeline em lote que funciona perfeitamente em 100 arquivos e falha no arquivo nº 4.327 de 50.000 não é útil. Resiliência — a capacidade de lidar com erros de forma elegante, tentar novamente em caso de falhas transitórias e retomar após travamentos — é o que diferencia um pipeline de nível de produção de um protótipo.
Tratamento de erros e opção de ignorar em caso de falha
O padrão de resiliência mais básico é o "pular em caso de falha": se um único arquivo não for processado, o erro é registrado e o processamento continua com o próximo arquivo, em vez de abortar todo o lote. Isso soa óbvio, mas é surpreendentemente fácil de perder quando se está usando Parallel.ForEach — uma exceção não tratada em qualquer tarefa paralela se propagará como um AggregateException e terminará o loop.
O exemplo a seguir demonstra tanto lógica de pular em falha quanto de tentar novamente — envolvendo cada arquivo em um try-catch para tratamento de erro gracioso, com um loop interno de tentativa usando recuo exponencial para exceções transitórias como IOException e OutOfMemoryException:
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-error-handling-retry.csusing IronPdf;
using System;
using System.IO;
using System.Threading.Tasks;
using System.Threading;
using System.Collections.Concurrent;
string inputFolder = "input/";
string outputFolder = "output/";
string errorLogPath = "error-log.txt";
Directory.CreateDirectory(outputFolder);
string[] htmlFiles = Directory.GetFiles(inputFolder, "*.html");
var renderer = new ChromePdfRenderer();
var errorLog = new ConcurrentBag<string>();
int processed = 0;
int failed = 0;
int retried = 0;
const int maxRetries = 3;
var options = new ParallelOptions
{
MaxDegreeOfParallelism = Environment.ProcessorCount / 2
};
Parallel.ForEach(htmlFiles, options, htmlFile =>
{
string fileName = Path.GetFileNameWithoutExtension(htmlFile);
string outputPath = Path.Combine(outputFolder, $"{fileName}.pdf");
int attempt = 0;
bool success = false;
while (attempt < maxRetries && !success)
{
attempt++;
try
{
using var pdf = renderer.RenderHtmlFileAsPdf(htmlFile);
pdf.SaveAs(outputPath);
success = true;
Interlocked.Increment(ref processed);
if (attempt > 1)
{
Interlocked.Increment(ref retried);
Console.WriteLine($"[OK] {fileName}.pdf (succeeded on attempt {attempt})");
}
else
{
Console.WriteLine($"[OK] {fileName}.pdf");
}
}
catch (Exception ex) when (IsTransientException(ex) && attempt < maxRetries)
{
// Transient error - wait and retry with exponential backoff
int delayMs = (int)Math.Pow(2, attempt) * 500;
Console.WriteLine($"[RETRY] {fileName}: {ex.Message} (attempt {attempt}, waiting {delayMs}ms)");
Thread.Sleep(delayMs);
}
catch (Exception ex)
{
// Non-transient error or max retries exceeded
Interlocked.Increment(ref failed);
string errorMessage = $"{DateTime.Now:yyyy-MM-dd HH:mm:ss} | {fileName} | {ex.GetType().Name} | {ex.Message}";
errorLog.Add(errorMessage);
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}");
}
}
});
// Write error log
if (errorLog.Count > 0)
{
File.WriteAllLines(errorLogPath, errorLog);
}
Console.WriteLine($"\nBatch complete:");
Console.WriteLine($" Processed: {processed}");
Console.WriteLine($" Failed: {failed}");
Console.WriteLine($" Retried: {retried}");
if (failed > 0)
{
Console.WriteLine($" Error log: {errorLogPath}");
}
// Helper to identify transient exceptions worth retrying
bool IsTransientException(Exception ex)
{
return ex is IOException ||
ex is OutOfMemoryException ||
ex.Message.Contains("timeout", StringComparison.OrdinalIgnoreCase) ||
ex.Message.Contains("locked", StringComparison.OrdinalIgnoreCase);
}Imports IronPdf
Imports System
Imports System.IO
Imports System.Threading
Imports System.Collections.Concurrent
Module Program
Sub Main()
Dim inputFolder As String = "input/"
Dim outputFolder As String = "output/"
Dim errorLogPath As String = "error-log.txt"
Directory.CreateDirectory(outputFolder)
Dim htmlFiles As String() = Directory.GetFiles(inputFolder, "*.html")
Dim renderer As New ChromePdfRenderer()
Dim errorLog As New ConcurrentBag(Of String)()
Dim processed As Integer = 0
Dim failed As Integer = 0
Dim retried As Integer = 0
Const maxRetries As Integer = 3
Dim options As New ParallelOptions With {
.MaxDegreeOfParallelism = Environment.ProcessorCount \ 2
}
Parallel.ForEach(htmlFiles, options, Sub(htmlFile)
Dim fileName As String = Path.GetFileNameWithoutExtension(htmlFile)
Dim outputPath As String = Path.Combine(outputFolder, $"{fileName}.pdf")
Dim attempt As Integer = 0
Dim success As Boolean = False
While attempt < maxRetries AndAlso Not success
attempt += 1
Try
Using pdf = renderer.RenderHtmlFileAsPdf(htmlFile)
pdf.SaveAs(outputPath)
success = True
Interlocked.Increment(processed)
If attempt > 1 Then
Interlocked.Increment(retried)
Console.WriteLine($"[OK] {fileName}.pdf (succeeded on attempt {attempt})")
Else
Console.WriteLine($"[OK] {fileName}.pdf")
End If
End Using
Catch ex As Exception When IsTransientException(ex) AndAlso attempt < maxRetries
' Transient error - wait and retry with exponential backoff
Dim delayMs As Integer = CInt(Math.Pow(2, attempt)) * 500
Console.WriteLine($"[RETRY] {fileName}: {ex.Message} (attempt {attempt}, waiting {delayMs}ms)")
Thread.Sleep(delayMs)
Catch ex As Exception
' Non-transient error or max retries exceeded
Interlocked.Increment(failed)
Dim errorMessage As String = $"{DateTime.Now:yyyy-MM-dd HH:mm:ss} | {fileName} | {ex.GetType().Name} | {ex.Message}"
errorLog.Add(errorMessage)
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}")
End Try
End While
End Sub)
' Write error log
If errorLog.Count > 0 Then
File.WriteAllLines(errorLogPath, errorLog)
End If
Console.WriteLine($"{vbCrLf}Batch complete:")
Console.WriteLine($" Processed: {processed}")
Console.WriteLine($" Failed: {failed}")
Console.WriteLine($" Retried: {retried}")
If failed > 0 Then
Console.WriteLine($" Error log: {errorLogPath}")
End If
End Sub
' Helper to identify transient exceptions worth retrying
Function IsTransientException(ex As Exception) As Boolean
Return TypeOf ex Is IOException OrElse
TypeOf ex Is OutOfMemoryException OrElse
ex.Message.Contains("timeout", StringComparison.OrdinalIgnoreCase) OrElse
ex.Message.Contains("locked", StringComparison.OrdinalIgnoreCase)
End Function
End ModuleApós a conclusão do processamento em lote, revise o registro de erros para entender quais arquivos falharam e por quê. As causas comuns de falhas incluem arquivos de origem corrompidos, PDFs protegidos por senha, recursos não suportados no conteúdo de origem e falta de memória em documentos muito grandes.
Lógica de repetição para falhas transitórias
Algumas falhas são passageiras — você terá sucesso se tentar novamente. Isso inclui disputa pelo sistema de arquivos (outro processo está bloqueando o arquivo), pressão temporária na memória (o coletor de lixo ainda não conseguiu processar todas as informações) e tempos limite de rede ao carregar recursos externos em conteúdo HTML. O exemplo de código acima lida com isso usando recuo exponencial — começando com um pequeno atraso e dobrando-o a cada nova tentativa, com um limite máximo de tentativas (normalmente 3).
O essencial é distinguir entre falhas que permitem nova tentativa e falhas que não permitem nova tentativa. Um IOException (arquivo bloqueado) ou OutOfMemoryException (pressão temporária) vale a tentativa. Um ArgumentException (entrada inválida) ou um erro de renderização consistente não é — tentar novamente não ajudará, e você desperdiçará tempo e recursos.
Ponto de verificação para retomar após falha
Quando um processo em lote processa 50.000 arquivos ao longo de várias horas, uma falha no arquivo nº 35.000 não deveria significar recomeçar do início. O recurso de checkpoint — que consiste em registrar quais arquivos foram processados com sucesso — permite que você retome o trabalho de onde parou.
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-checkpointing.csusing IronPdf;
using System;
using System.IO;
using System.Linq;
using System.Threading.Tasks;
using System.Threading;
using System.Collections.Generic;
string inputFolder = "input/";
string outputFolder = "output/";
string checkpointPath = "checkpoint.txt";
string errorLogPath = "errors.txt";
Directory.CreateDirectory(outputFolder);
// Load checkpoint - files already processed successfully
var completedFiles = new HashSet<string>();
if (File.Exists(checkpointPath))
{
completedFiles = new HashSet<string>(File.ReadAllLines(checkpointPath));
Console.WriteLine($"Resuming from checkpoint: {completedFiles.Count} files already processed");
}
// Get files to process (excluding already completed)
string[] allFiles = Directory.GetFiles(inputFolder, "*.html");
string[] filesToProcess = allFiles
.Where(f => !completedFiles.Contains(Path.GetFileName(f)))
.ToArray();
Console.WriteLine($"Files to process: {filesToProcess.Length} (skipping {completedFiles.Count} already done)");
var renderer = new ChromePdfRenderer();
var checkpointLock = new object();
int processed = 0;
int failed = 0;
var options = new ParallelOptions
{
MaxDegreeOfParallelism = Environment.ProcessorCount / 2
};
Parallel.ForEach(filesToProcess, options, htmlFile =>
{
string fileName = Path.GetFileName(htmlFile);
string baseName = Path.GetFileNameWithoutExtension(htmlFile);
string outputPath = Path.Combine(outputFolder, $"{baseName}.pdf");
try
{
using var pdf = renderer.RenderHtmlFileAsPdf(htmlFile);
pdf.SaveAs(outputPath);
// Record success in checkpoint (thread-safe)
lock (checkpointLock)
{
File.AppendAllText(checkpointPath, fileName + Environment.NewLine);
}
Interlocked.Increment(ref processed);
Console.WriteLine($"[OK] {baseName}.pdf");
}
catch (Exception ex)
{
Interlocked.Increment(ref failed);
// Log error for review
lock (checkpointLock)
{
File.AppendAllText(errorLogPath,
$"{DateTime.Now:yyyy-MM-dd HH:mm:ss} | {fileName} | {ex.Message}{Environment.NewLine}");
}
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}");
}
});
Console.WriteLine($"\nBatch complete:");
Console.WriteLine($" Newly processed: {processed}");
Console.WriteLine($" Failed: {failed}");
Console.WriteLine($" Total completed: {completedFiles.Count + processed}");
Console.WriteLine($" Checkpoint saved to: {checkpointPath}");Imports IronPdf
Imports System
Imports System.IO
Imports System.Linq
Imports System.Threading.Tasks
Imports System.Threading
Imports System.Collections.Generic
Module Program
Sub Main()
Dim inputFolder As String = "input/"
Dim outputFolder As String = "output/"
Dim checkpointPath As String = "checkpoint.txt"
Dim errorLogPath As String = "errors.txt"
Directory.CreateDirectory(outputFolder)
' Load checkpoint - files already processed successfully
Dim completedFiles As New HashSet(Of String)()
If File.Exists(checkpointPath) Then
completedFiles = New HashSet(Of String)(File.ReadAllLines(checkpointPath))
Console.WriteLine($"Resuming from checkpoint: {completedFiles.Count} files already processed")
End If
' Get files to process (excluding already completed)
Dim allFiles As String() = Directory.GetFiles(inputFolder, "*.html")
Dim filesToProcess As String() = allFiles _
.Where(Function(f) Not completedFiles.Contains(Path.GetFileName(f))) _
.ToArray()
Console.WriteLine($"Files to process: {filesToProcess.Length} (skipping {completedFiles.Count} already done)")
Dim renderer As New ChromePdfRenderer()
Dim checkpointLock As New Object()
Dim processed As Integer = 0
Dim failed As Integer = 0
Dim options As New ParallelOptions With {
.MaxDegreeOfParallelism = Environment.ProcessorCount \ 2
}
Parallel.ForEach(filesToProcess, options, Sub(htmlFile)
Dim fileName As String = Path.GetFileName(htmlFile)
Dim baseName As String = Path.GetFileNameWithoutExtension(htmlFile)
Dim outputPath As String = Path.Combine(outputFolder, $"{baseName}.pdf")
Try
Using pdf = renderer.RenderHtmlFileAsPdf(htmlFile)
pdf.SaveAs(outputPath)
End Using
' Record success in checkpoint (thread-safe)
SyncLock checkpointLock
File.AppendAllText(checkpointPath, fileName & Environment.NewLine)
End SyncLock
Interlocked.Increment(processed)
Console.WriteLine($"[OK] {baseName}.pdf")
Catch ex As Exception
Interlocked.Increment(failed)
' Log error for review
SyncLock checkpointLock
File.AppendAllText(errorLogPath,
$"{DateTime.Now:yyyy-MM-dd HH:mm:ss} | {fileName} | {ex.Message}{Environment.NewLine}")
End SyncLock
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}")
End Try
End Sub)
Console.WriteLine(vbCrLf & "Batch complete:")
Console.WriteLine($" Newly processed: {processed}")
Console.WriteLine($" Failed: {failed}")
Console.WriteLine($" Total completed: {completedFiles.Count + processed}")
Console.WriteLine($" Checkpoint saved to: {checkpointPath}")
End Sub
End ModuleO arquivo de ponto de verificação funciona como um registro permanente do trabalho concluído. Quando o pipeline é iniciado, ele lê o arquivo de ponto de verificação e ignora quaisquer arquivos que já tenham sido processados com sucesso. Quando um arquivo termina de ser processado, seu caminho é adicionado ao arquivo de ponto de verificação. Essa abordagem é simples, baseada em arquivos e não requer nenhuma dependência externa.
Para cenários mais complexos, considere usar uma tabela de banco de dados ou um cache distribuído (como o Redis) como armazenamento de checkpoint, especialmente se vários processos estiverem processando arquivos em paralelo em máquinas diferentes.
Validação antes e depois do processamento
A validação é a etapa fundamental de um pipeline resiliente. A validação pré-processamento identifica entradas problemáticas antes que elas desperdicem tempo de processamento; a validação pós-processamento garante que a saída atenda aos seus requisitos de qualidade e conformidade.
Entrada
Esta implementação envolve o loop de processamento com funções auxiliares PreValidate e PostValidate. A pré-validação verifica o tamanho do arquivo, o tipo de conteúdo e a estrutura básica do HTML antes do processamento. A pós-validação verifica se o PDF de saída possui uma contagem de páginas válida e um tamanho de arquivo razoável, movendo os arquivos validados para uma pasta separada, enquanto os arquivos com falhas são encaminhados para uma pasta de rejeição para revisão manual.
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-validation.csusing IronPdf;
using System;
using System.IO;
using System.Threading.Tasks;
using System.Threading;
using System.Collections.Concurrent;
string inputFolder = "input/";
string outputFolder = "output/";
string validatedFolder = "validated/";
string rejectedFolder = "rejected/";
Directory.CreateDirectory(outputFolder);
Directory.CreateDirectory(validatedFolder);
Directory.CreateDirectory(rejectedFolder);
string[] inputFiles = Directory.GetFiles(inputFolder, "*.html");
var renderer = new ChromePdfRenderer();
int preValidationFailed = 0;
int processingFailed = 0;
int postValidationFailed = 0;
int succeeded = 0;
var options = new ParallelOptions
{
MaxDegreeOfParallelism = Environment.ProcessorCount / 2
};
Parallel.ForEach(inputFiles, options, inputFile =>
{
string fileName = Path.GetFileNameWithoutExtension(inputFile);
string outputPath = Path.Combine(outputFolder, $"{fileName}.pdf");
// Pre-validation: Check input file
if (!PreValidate(inputFile))
{
Interlocked.Increment(ref preValidationFailed);
Console.WriteLine($"[SKIP] {fileName}: Failed pre-validation");
return;
}
try
{
// Process
using var pdf = renderer.RenderHtmlFileAsPdf(inputFile);
pdf.SaveAs(outputPath);
// Post-validation: Check output file
if (PostValidate(outputPath))
{
// Move to validated folder
string validatedPath = Path.Combine(validatedFolder, $"{fileName}.pdf");
File.Move(outputPath, validatedPath, overwrite: true);
Interlocked.Increment(ref succeeded);
Console.WriteLine($"[OK] {fileName}.pdf (validated)");
}
else
{
// Move to rejected folder for manual review
string rejectedPath = Path.Combine(rejectedFolder, $"{fileName}.pdf");
File.Move(outputPath, rejectedPath, overwrite: true);
Interlocked.Increment(ref postValidationFailed);
Console.WriteLine($"[REJECT] {fileName}.pdf: Failed post-validation");
}
}
catch (Exception ex)
{
Interlocked.Increment(ref processingFailed);
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}");
}
});
Console.WriteLine($"\nValidation summary:");
Console.WriteLine($" Succeeded: {succeeded}");
Console.WriteLine($" Pre-validation failed: {preValidationFailed}");
Console.WriteLine($" Processing failed: {processingFailed}");
Console.WriteLine($" Post-validation failed: {postValidationFailed}");
// Pre-validation: Quick checks on input file
bool PreValidate(string filePath)
{
try
{
var fileInfo = new FileInfo(filePath);
// Check file exists and is readable
if (!fileInfo.Exists) return false;
// Check file is not empty
if (fileInfo.Length == 0) return false;
// Check file is not too large (e.g., 50MB limit)
if (fileInfo.Length > 50 * 1024 * 1024) return false;
// Quick content check - must be valid HTML
string content = File.ReadAllText(filePath);
if (string.IsNullOrWhiteSpace(content)) return false;
if (!content.Contains("<html", StringComparison.OrdinalIgnoreCase) &&
!content.Contains("<!DOCTYPE", StringComparison.OrdinalIgnoreCase))
{
return false;
}
return true;
}
catch
{
return false;
}
}
// Post-validation: Verify output PDF meets requirements
bool PostValidate(string pdfPath)
{
try
{
using var pdf = PdfDocument.FromFile(pdfPath);
// Check PDF has at least one page
if (pdf.PageCount < 1) return false;
// Check file size is reasonable (not just header, not corrupted)
var fileInfo = new FileInfo(pdfPath);
if (fileInfo.Length < 1024) return false;
return true;
}
catch
{
return false;
}
}Imports IronPdf
Imports System
Imports System.IO
Imports System.Threading.Tasks
Imports System.Threading
Imports System.Collections.Concurrent
Module Program
Sub Main()
Dim inputFolder As String = "input/"
Dim outputFolder As String = "output/"
Dim validatedFolder As String = "validated/"
Dim rejectedFolder As String = "rejected/"
Directory.CreateDirectory(outputFolder)
Directory.CreateDirectory(validatedFolder)
Directory.CreateDirectory(rejectedFolder)
Dim inputFiles As String() = Directory.GetFiles(inputFolder, "*.html")
Dim renderer As New ChromePdfRenderer()
Dim preValidationFailed As Integer = 0
Dim processingFailed As Integer = 0
Dim postValidationFailed As Integer = 0
Dim succeeded As Integer = 0
Dim options As New ParallelOptions With {
.MaxDegreeOfParallelism = Environment.ProcessorCount \ 2
}
Parallel.ForEach(inputFiles, options, Sub(inputFile)
Dim fileName As String = Path.GetFileNameWithoutExtension(inputFile)
Dim outputPath As String = Path.Combine(outputFolder, $"{fileName}.pdf")
' Pre-validation: Check input file
If Not PreValidate(inputFile) Then
Interlocked.Increment(preValidationFailed)
Console.WriteLine($"[SKIP] {fileName}: Failed pre-validation")
Return
End If
Try
' Process
Using pdf = renderer.RenderHtmlFileAsPdf(inputFile)
pdf.SaveAs(outputPath)
' Post-validation: Check output file
If PostValidate(outputPath) Then
' Move to validated folder
Dim validatedPath As String = Path.Combine(validatedFolder, $"{fileName}.pdf")
File.Move(outputPath, validatedPath, overwrite:=True)
Interlocked.Increment(succeeded)
Console.WriteLine($"[OK] {fileName}.pdf (validated)")
Else
' Move to rejected folder for manual review
Dim rejectedPath As String = Path.Combine(rejectedFolder, $"{fileName}.pdf")
File.Move(outputPath, rejectedPath, overwrite:=True)
Interlocked.Increment(postValidationFailed)
Console.WriteLine($"[REJECT] {fileName}.pdf: Failed post-validation")
End If
End Using
Catch ex As Exception
Interlocked.Increment(processingFailed)
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}")
End Try
End Sub)
Console.WriteLine(vbCrLf & "Validation summary:")
Console.WriteLine($" Succeeded: {succeeded}")
Console.WriteLine($" Pre-validation failed: {preValidationFailed}")
Console.WriteLine($" Processing failed: {processingFailed}")
Console.WriteLine($" Post-validation failed: {postValidationFailed}")
End Sub
' Pre-validation: Quick checks on input file
Function PreValidate(filePath As String) As Boolean
Try
Dim fileInfo As New FileInfo(filePath)
' Check file exists and is readable
If Not fileInfo.Exists Then Return False
' Check file is not empty
If fileInfo.Length = 0 Then Return False
' Check file is not too large (e.g., 50MB limit)
If fileInfo.Length > 50 * 1024 * 1024 Then Return False
' Quick content check - must be valid HTML
Dim content As String = File.ReadAllText(filePath)
If String.IsNullOrWhiteSpace(content) Then Return False
If Not content.Contains("<html", StringComparison.OrdinalIgnoreCase) AndAlso
Not content.Contains("<!DOCTYPE", StringComparison.OrdinalIgnoreCase) Then
Return False
End If
Return True
Catch
Return False
End Try
End Function
' Post-validation: Verify output PDF meets requirements
Function PostValidate(pdfPath As String) As Boolean
Try
Using pdf = PdfDocument.FromFile(pdfPath)
' Check PDF has at least one page
If pdf.PageCount < 1 Then Return False
' Check file size is reasonable (not just header, not corrupted)
Dim fileInfo As New FileInfo(pdfPath)
If fileInfo.Length < 1024 Then Return False
Return True
End Using
Catch
Return False
End Try
End Function
End ModuleSaída
Todos os 5 arquivos passaram na validação e foram movidos para a pasta de arquivos validados.
A validação do pré-processamento deve ser rápida — você está verificando entradas obviamente incorretas, não realizando o processamento completo. A validação pós-processamento pode ser mais rigorosa, especialmente para conversões de conformidade em que o resultado deve atender a padrões específicos (PDF/A, PDF/UA). Qualquer arquivo que não passar na validação pós-processamento deve ser sinalizado para revisão manual, em vez de ser aceito silenciosamente.
Minha biblioteca favorita desse tipo é o IronPDF. Ele permite a manipulação rápida e eficiente de arquivos PDF. Além disso, possui muitos recursos valiosos, como a exportação para o formato PDF/A e a assinatura digital de documentos PDF.
Com o IronOCR, podemos economizar US$ 40.000 por ano em processamento manual, ao mesmo tempo que aumentamos a produtividade e liberamos recursos para tarefas de alto impacto. Eu o recomendo fortemente.
O IronSuite desempenha um papel crucial nas nossas operações. Estas são ferramentas que aumentam a eficiência no negócio, incluindo a criação de plantas baixas e melhoria na gestão de inventário.
Padrões de processamento assíncrono e paralelo
IronPDF suporta tanto Parallel.ForEach (paralelismo baseado em thread) quanto async/await (I/O assíncrono). Compreender quando usar cada um deles — e como combiná-los de forma eficaz — é fundamental para maximizar a produtividade.
Integração de biblioteca paralela de tarefas
Parallel.ForEach é a abordagem mais simples e eficaz para operações de lote com uso intensivo de CPU. O motor de renderização do IronPDF é intensivo de CPU (análise HTML, layout CSS, rasterização de imagem), e Parallel.ForEach distribui automaticamente esse trabalho por todos os núcleos disponíveis.
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-tpl.csusing IronPdf;
using System;
using System.IO;
using System.Threading.Tasks;
using System.Threading;
using System.Diagnostics;
string inputFolder = "input/";
string outputFolder = "output/";
Directory.CreateDirectory(outputFolder);
string[] htmlFiles = Directory.GetFiles(inputFolder, "*.html");
var renderer = new ChromePdfRenderer();
Console.WriteLine($"Processing {htmlFiles.Length} files with {Environment.ProcessorCount} CPU cores");
int processed = 0;
var stopwatch = Stopwatch.StartNew();
// Configure parallelism based on system resources
// Rule of thumb: ProcessorCount / 2 for memory-intensive operations
var options = new ParallelOptions
{
MaxDegreeOfParallelism = Math.Max(1, Environment.ProcessorCount / 2)
};
Console.WriteLine($"Max parallelism: {options.MaxDegreeOfParallelism}");
// Use Parallel.ForEach for CPU-bound batch operations
Parallel.ForEach(htmlFiles, options, htmlFile =>
{
string fileName = Path.GetFileNameWithoutExtension(htmlFile);
string outputPath = Path.Combine(outputFolder, $"{fileName}.pdf");
try
{
// Render HTML to PDF
using var pdf = renderer.RenderHtmlFileAsPdf(htmlFile);
pdf.SaveAs(outputPath);
int current = Interlocked.Increment(ref processed);
// Progress reporting every 10 files
if (current % 10 == 0)
{
double elapsed = stopwatch.Elapsed.TotalSeconds;
double rate = current / elapsed;
double remaining = (htmlFiles.Length - current) / rate;
Console.WriteLine($"Progress: {current}/{htmlFiles.Length} ({rate:F1} files/sec, ~{remaining:F0}s remaining)");
}
}
catch (Exception ex)
{
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}");
}
});
stopwatch.Stop();
double totalRate = processed / stopwatch.Elapsed.TotalSeconds;
Console.WriteLine($"\nComplete:");
Console.WriteLine($" Files processed: {processed}/{htmlFiles.Length}");
Console.WriteLine($" Total time: {stopwatch.Elapsed.TotalSeconds:F1}s");
Console.WriteLine($" Average rate: {totalRate:F1} files/sec");
Console.WriteLine($" Time per file: {stopwatch.Elapsed.TotalMilliseconds / processed:F0}ms");
// Memory monitoring helper (call between chunks for large batches)
void CheckMemoryPressure()
{
const long memoryThreshold = 4L * 1024 * 1024 * 1024; // 4 GB
long currentMemory = GC.GetTotalMemory(forceFullCollection: false);
if (currentMemory > memoryThreshold)
{
Console.WriteLine($"Memory pressure detected ({currentMemory / 1024 / 1024}MB), forcing GC...");
GC.Collect();
GC.WaitForPendingFinalizers();
GC.Collect();
}
}Imports IronPdf
Imports System
Imports System.IO
Imports System.Threading.Tasks
Imports System.Threading
Imports System.Diagnostics
Module Program
Sub Main()
Dim inputFolder As String = "input/"
Dim outputFolder As String = "output/"
Directory.CreateDirectory(outputFolder)
Dim htmlFiles As String() = Directory.GetFiles(inputFolder, "*.html")
Dim renderer As New ChromePdfRenderer()
Console.WriteLine($"Processing {htmlFiles.Length} files with {Environment.ProcessorCount} CPU cores")
Dim processed As Integer = 0
Dim stopwatch As Stopwatch = Stopwatch.StartNew()
' Configure parallelism based on system resources
' Rule of thumb: ProcessorCount / 2 for memory-intensive operations
Dim options As New ParallelOptions With {
.MaxDegreeOfParallelism = Math.Max(1, Environment.ProcessorCount \ 2)
}
Console.WriteLine($"Max parallelism: {options.MaxDegreeOfParallelism}")
' Use Parallel.ForEach for CPU-bound batch operations
Parallel.ForEach(htmlFiles, options, Sub(htmlFile)
Dim fileName As String = Path.GetFileNameWithoutExtension(htmlFile)
Dim outputPath As String = Path.Combine(outputFolder, $"{fileName}.pdf")
Try
' Render HTML to PDF
Using pdf = renderer.RenderHtmlFileAsPdf(htmlFile)
pdf.SaveAs(outputPath)
End Using
Dim current As Integer = Interlocked.Increment(processed)
' Progress reporting every 10 files
If current Mod 10 = 0 Then
Dim elapsed As Double = stopwatch.Elapsed.TotalSeconds
Dim rate As Double = current / elapsed
Dim remaining As Double = (htmlFiles.Length - current) / rate
Console.WriteLine($"Progress: {current}/{htmlFiles.Length} ({rate:F1} files/sec, ~{remaining:F0}s remaining)")
End If
Catch ex As Exception
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}")
End Try
End Sub)
stopwatch.Stop()
Dim totalRate As Double = processed / stopwatch.Elapsed.TotalSeconds
Console.WriteLine(vbCrLf & "Complete:")
Console.WriteLine($" Files processed: {processed}/{htmlFiles.Length}")
Console.WriteLine($" Total time: {stopwatch.Elapsed.TotalSeconds:F1}s")
Console.WriteLine($" Average rate: {totalRate:F1} files/sec")
Console.WriteLine($" Time per file: {stopwatch.Elapsed.TotalMilliseconds / processed:F0}ms")
' Memory monitoring helper (call between chunks for large batches)
CheckMemoryPressure()
End Sub
Sub CheckMemoryPressure()
Const memoryThreshold As Long = 4L * 1024 * 1024 * 1024 ' 4 GB
Dim currentMemory As Long = GC.GetTotalMemory(forceFullCollection:=False)
If currentMemory > memoryThreshold Then
Console.WriteLine($"Memory pressure detected ({currentMemory \ 1024 \ 1024}MB), forcing GC...")
GC.Collect()
GC.WaitForPendingFinalizers()
GC.Collect()
End If
End Sub
End ModuleA opção MaxDegreeOfParallelism é crítica. Sem isso, o TPL tentará usar todos os núcleos disponíveis, o que pode sobrecarregar a memória se cada renderização exigir muitos recursos. Defina esse valor com base na RAM disponível do seu sistema, dividida pelo consumo típico de memória por renderização (geralmente de 100 a 300 MB por renderização simultânea para HTML complexo).
Controle de Concorrência (SemaphoreSlim)
Quando você precisa de um controle mais fino sobre a concorrência do que Parallel.ForEach oferece — por exemplo, ao misturar I/O assíncrono com renderização com uso intensivo de CPU — SemaphoreSlim dá a você controle explícito sobre quantas operações são executadas simultaneamente. O padrão é simples: crie um SemaphoreSlim com o limite de concorrência desejado (por exemplo, 4 renderizações simultâneas), chame WaitAsync antes de cada renderização, e Release em um bloco finally depois. Em seguida, inicie todas as tarefas com Task.WhenAll.
Esse padrão é particularmente útil quando seu pipeline inclui etapas com uso intensivo de E/S (leitura de arquivos do armazenamento de blobs, gravação de resultados em um banco de dados) e etapas com uso intensivo de CPU (renderização de PDFs). O semáforo limita a concorrência de renderização que depende da CPU, ao mesmo tempo que permite que as etapas que dependem de E/S prossigam sem limitação.
Melhores práticas para Async/Await
IronPDF fornece variantes assíncronas de seus métodos de renderização, incluindo RenderHtmlAsPdfAsync, RenderUrlAsPdfAsync e RenderHtmlFileAsPdfAsync. Essas opções são ideais para aplicações web (onde bloquear a thread de requisição é inaceitável) e para pipelines que combinam renderização de PDF com operações de E/S assíncronas.
Algumas práticas recomendadas importantes para processamento assíncrono em lote:
Não use Task.Run para envolver métodos síncronos do IronPDF — use as variantes nativas assíncronas em vez disso. Envolver métodos síncronos em Task.Run desperdiça uma thread do pool de threads e adiciona sobrecarga sem qualquer benefício.
Não use .Result ou .Wait() em tarefas assíncronas — isso bloqueia a thread de chamada e pode causar deadlocks em contextos de UI ou ASP.NET. Sempre use await.
Agrupe suas chamadas Task.WhenAll em vez de aguardar todas as tarefas de uma vez. Se você tiver 10.000 tarefas e chamar Task.WhenAll em todas elas simultaneamente, você iniciará 10.000 operações simultâneas. Em vez disso, use .Chunk(10) ou uma abordagem semelhante para processá-las em grupos, aguardando cada grupo sequencialmente.
Evitando a exaustão da memória
A falta de memória é o modo de falha mais comum no processamento em lote de PDFs. A abordagem defensiva é monitorar o uso de memória com GC.GetTotalMemory() antes de cada renderização e acionar uma coleta quando o consumo cruzar um limite (por exemplo, 4 GB ou 80% da RAM disponível). Chame GC.Collect() seguido de GC.WaitForPendingFinalizers() e um segundo GC.Collect() para recuperar o máximo de memória possível antes de continuar. Isso adiciona uma pequena pausa, mas previne a alternativa catastrófica de um OutOfMemoryException quebrando todo o seu lote no arquivo #30.000.
Combine isso com a limitação MaxDegreeOfParallelism da seção TPL e o padrão de descarte using da seção de gestão de memória, e você terá uma defesa de três camadas contra problemas de memória: limite a concorrência, descarte agressivamente e monitore com uma válvula de segurança.
Implantação na nuvem para trabalhos em lote
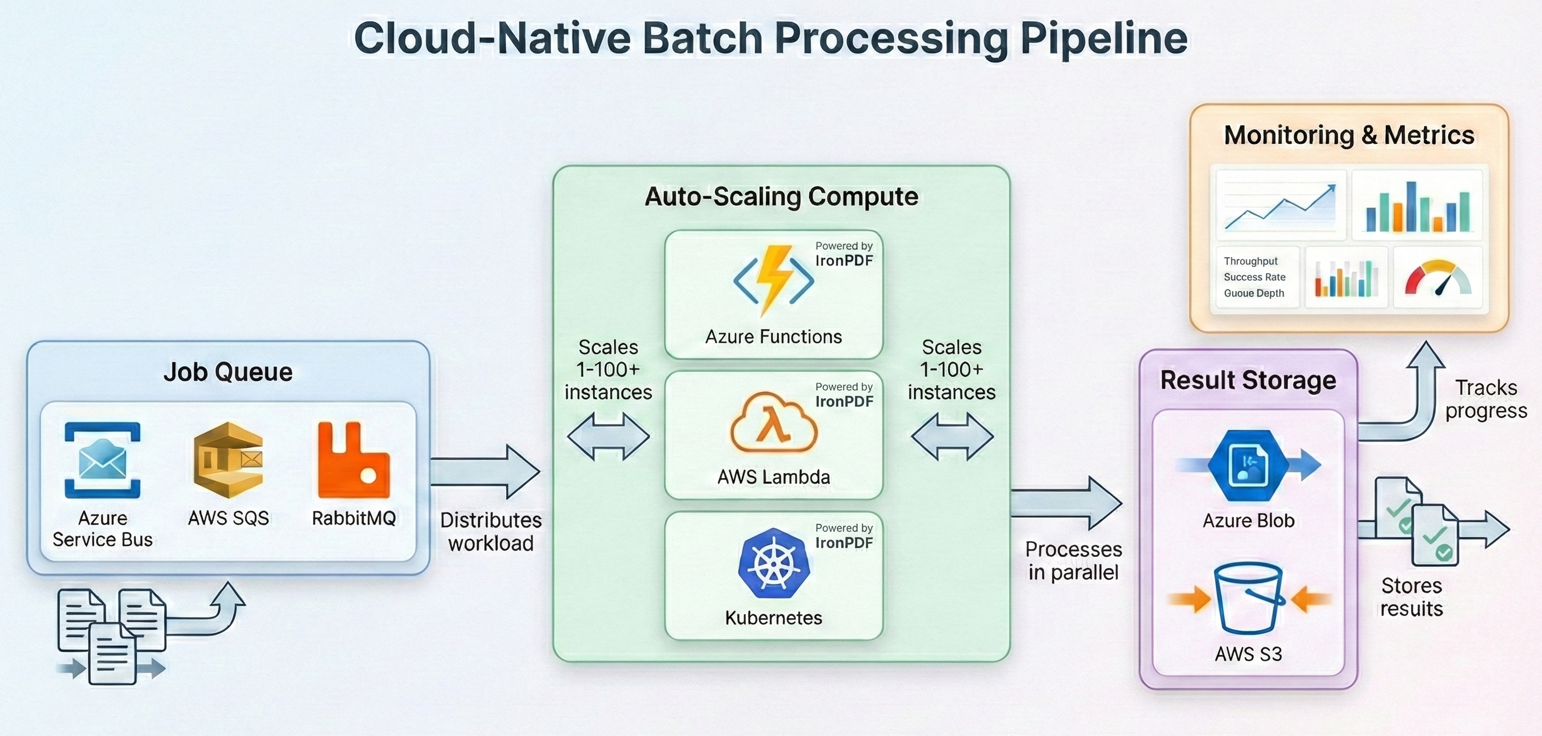
O processamento em lote moderno é cada vez mais executado na nuvem, onde você pode dimensionar os recursos computacionais para atender às demandas da carga de trabalho e pagar apenas pelo que usar. O IronPDF funciona em todas as principais plataformas de nuvem — veja como arquitetar pipelines de processamento em lote para cada uma delas.
Azure Functions com Durable Functions
O Azure Durable Functions oferece orquestração integrada para padrões de distribuição (fan-out/fan-in), tornando-o uma solução natural para o processamento em lote de PDFs. A função de orquestração distribui o trabalho entre várias instâncias da função de atividade, cada uma processando um subconjunto de arquivos. Seu orquestrador chama CallActivityAsync em um loop fan-out, cada função de atividade instancia um ChromePdfRenderer, processa sua parte dos arquivos, e o orquestrador coleta os resultados.
Principais considerações sobre o Azure Functions: o plano de consumo padrão tem um tempo limite de 5 minutos por invocação de função e memória limitada. Para processamento em lote, utilize o plano Premium ou Dedicado , que oferece suporte a tempos limite mais longos e mais memória. O IronPDF requer o runtime .NET completo (sem cortes), portanto, certifique-se de que seu aplicativo de funções esteja configurado para .NET 8 ou superior com o identificador de runtime apropriado.
AWS Lambda com Step Functions
O AWS Step Functions oferece uma capacidade de orquestração semelhante à do Azure Durable Functions. Cada etapa na máquina de estados invoca uma função Lambda que processa um conjunto de arquivos. Seu manipulador Lambda recebe um lote de chaves de objetos S3, carrega cada PDF com PdfDocument.FromFile, aplica seu pipeline de processamento (compressão, conversão de formato, etc.) e grava os resultados de volta em um bucket de saída S3.
O AWS Lambda tem um tempo máximo de execução de 15 minutos e armazenamento /tmp limitado (512 MB por padrão, configurável até 10 GB). Para grandes trabalhos em lote, use o Step Functions para dividir a carga de trabalho em partes e processar cada parte em uma invocação Lambda separada. Armazene os resultados intermediários no S3 em vez do armazenamento local.
Agendamento de tarefas do Kubernetes
Para organizações que executam seus próprios clusters Kubernetes, o processamento em lote de PDFs se integra bem aos Jobs e CronJobs do Kubernetes. Cada pod executa um processo em lote que extrai arquivos de uma fila (Azure Service Bus, RabbitMQ ou SQS), os processa com o IronPDF e grava os resultados no armazenamento de objetos. O loop de trabalho segue o mesmo padrão coberto nas seções anteriores: descarregue uma mensagem, use ChromePdfRenderer.RenderHtmlAsPdf() ou PdfDocument.FromFile() para processar o documento, envie o resultado para upload e reconheça a mensagem. Envolva o processamento no mesmo try-catch com lógica de tentativa da resiliência dos padrões e use SemaphoreSlim para controlar a concorrência por pod.
O IronPDF oferece suporte oficial ao Docker e funciona em contêineres Linux. Use o pacote NuGet IronPdf com os pacotes de runtime nativos apropriados para o SO do seu container (por exemplo, IronPdf.Linux para imagens baseadas em Linux). Para o Kubernetes, defina as solicitações e os limites de recursos que correspondam aos requisitos de memória do IronPDF (normalmente de 512 MB a 2 GB por pod, dependendo da concorrência). O Horizontal Pod Autoscaler consegue dimensionar os workers com base na profundidade da fila, e o padrão de checkpoint garante que nenhum trabalho seja perdido caso os pods sejam removidos.
Estratégias de Otimização de Custos
O processamento em lote na nuvem pode ficar caro se você não planejar cuidadosamente a alocação de recursos. Aqui estão as estratégias que têm o maior impacto:
Dimensionar seus recursos computacionais é a melhor opção. A renderização de PDFs exige muito da CPU e da memória, mas não da GPU. Utilize instâncias otimizadas para computação (série C no Azure, tipo C na AWS) em vez de instâncias de uso geral ou otimizadas para memória. Você obterá melhores relações custo-benefício por renderização.
Utilize instâncias spot/preemptíveis para cargas de trabalho em lote que podem tolerar interrupções. O processamento em lote de PDFs é inerentemente retomável (graças ao recurso de checkpoints), tornando-o um candidato ideal para preços pontuais, que normalmente oferecem descontos de 60 a 90% em relação ao processamento sob demanda.
Processe o processo fora dos horários de pico, se o seu cronograma permitir. Muitos provedores de nuvem oferecem preços mais baixos ou maior disponibilidade de vagas durante as noites e fins de semana.
Comprima cedo, armazene uma única vez. Inclua a compressão no seu fluxo de processamento, em vez de uma etapa separada. Armazenar PDFs comprimidos desde o início reduz os custos contínuos de armazenamento durante toda a vida útil do arquivo.
Organize seu armazenamento em camadas. PDFs processados que são acessados com frequência devem ser armazenados em locais de uso frequente; Os PDFs arquivados que são acessados raramente devem ser movidos para camadas de armazenamento frias ou de arquivo (Azure Cool/Archive, AWS S3 Glacier). Só isso pode reduzir os custos de armazenamento em 50 a 80%.
Exemplo de pipeline no mundo real
Vamos consolidar tudo com um pipeline de lote completo e pronto para produção que demonstra todo o fluxo de trabalho: Ingestão → Validação → Processamento → Arquivamento → Relatório .
Este exemplo processa um diretório de modelos de faturas HTML, renderiza-os em PDF, comprime a saída, converte para PDF/A-3b para conformidade com arquivamento, valida o resultado e gera um relatório resumido no final.
Usando as mesmas 5 faturas HTML do exemplo de conversão em lote acima...
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-full-pipeline.csusing IronPdf;
using System;
using System.Collections.Generic;
using System.IO;
using System.Linq;
using System.Threading.Tasks;
using System.Threading;
using System.Collections.Concurrent;
using System.Diagnostics;
using System.Text.Json;
// Configuration
var config = new PipelineConfig
{
InputFolder = "input/",
OutputFolder = "output/",
ArchiveFolder = "archive/",
ErrorFolder = "errors/",
CheckpointPath = "pipeline-checkpoint.json",
ReportPath = "pipeline-report.json",
MaxConcurrency = Math.Max(1, Environment.ProcessorCount / 2),
MaxRetries = 3,
JpegQuality = 70
};
// Initialize folders
Directory.CreateDirectory(config.OutputFolder);
Directory.CreateDirectory(config.ArchiveFolder);
Directory.CreateDirectory(config.ErrorFolder);
// Load checkpoint for resume capability
var checkpoint = LoadCheckpoint(config.CheckpointPath);
var results = new ConcurrentBag<ProcessingResult>();
var stopwatch = Stopwatch.StartNew();
// Get files to process
string[] allFiles = Directory.GetFiles(config.InputFolder, "*.html");
string[] filesToProcess = allFiles
.Where(f => !checkpoint.CompletedFiles.Contains(Path.GetFileName(f)))
.ToArray();
Console.WriteLine($"Pipeline starting:");
Console.WriteLine($" Total files: {allFiles.Length}");
Console.WriteLine($" Already processed: {checkpoint.CompletedFiles.Count}");
Console.WriteLine($" To process: {filesToProcess.Length}");
Console.WriteLine($" Concurrency: {config.MaxConcurrency}");
var renderer = new ChromePdfRenderer();
var checkpointLock = new object();
var options = new ParallelOptions
{
MaxDegreeOfParallelism = config.MaxConcurrency
};
Parallel.ForEach(filesToProcess, options, inputFile =>
{
var result = new ProcessingResult
{
FileName = Path.GetFileName(inputFile),
StartTime = DateTime.UtcNow
};
try
{
// Stage: Pre-validation
if (!ValidateInput(inputFile))
{
result.Status = "PreValidationFailed";
result.Error = "Input file failed validation";
results.Add(result);
return;
}
string baseName = Path.GetFileNameWithoutExtension(inputFile);
string tempPath = Path.Combine(config.OutputFolder, $"{baseName}.pdf");
string archivePath = Path.Combine(config.ArchiveFolder, $"{baseName}.pdf");
// Stage: Process with retry
PdfDocument pdf = null;
int attempt = 0;
bool success = false;
while (attempt < config.MaxRetries && !success)
{
attempt++;
try
{
pdf = renderer.RenderHtmlFileAsPdf(inputFile);
success = true;
}
catch (Exception ex) when (IsTransient(ex) && attempt < config.MaxRetries)
{
Thread.Sleep((int)Math.Pow(2, attempt) * 500);
}
}
if (!success || pdf == null)
{
result.Status = "ProcessingFailed";
result.Error = "Max retries exceeded";
results.Add(result);
return;
}
using (pdf)
{
// Stage: Compress and convert to PDF/A-3b for archival
pdf.SaveAsPdfA(tempPath, PdfAVersions.PdfA3b);
}
// Stage: Post-validation
if (!ValidateOutput(tempPath))
{
File.Move(tempPath, Path.Combine(config.ErrorFolder, $"{baseName}.pdf"), overwrite: true);
result.Status = "PostValidationFailed";
result.Error = "Output file failed validation";
results.Add(result);
return;
}
// Stage: Archive
File.Move(tempPath, archivePath, overwrite: true);
// Update checkpoint
lock (checkpointLock)
{
checkpoint.CompletedFiles.Add(result.FileName);
SaveCheckpoint(config.CheckpointPath, checkpoint);
}
result.Status = "Success";
result.OutputSize = new FileInfo(archivePath).Length;
result.EndTime = DateTime.UtcNow;
results.Add(result);
Console.WriteLine($"[OK] {baseName}.pdf ({result.OutputSize / 1024}KB)");
}
catch (Exception ex)
{
result.Status = "Error";
result.Error = ex.Message;
result.EndTime = DateTime.UtcNow;
results.Add(result);
Console.WriteLine($"[ERROR] {result.FileName}: {ex.Message}");
}
});
stopwatch.Stop();
// Generate report
var report = new PipelineReport
{
TotalFiles = allFiles.Length,
ProcessedThisRun = results.Count,
Succeeded = results.Count(r => r.Status == "Success"),
PreValidationFailed = results.Count(r => r.Status == "PreValidationFailed"),
ProcessingFailed = results.Count(r => r.Status == "ProcessingFailed"),
PostValidationFailed = results.Count(r => r.Status == "PostValidationFailed"),
Errors = results.Count(r => r.Status == "Error"),
TotalDuration = stopwatch.Elapsed,
AverageFileTime = results.Any() ? TimeSpan.FromMilliseconds(stopwatch.Elapsed.TotalMilliseconds / results.Count) : TimeSpan.Zero
};
string reportJson = JsonSerializer.Serialize(report, new JsonSerializerOptions { WriteIndented = true });
File.WriteAllText(config.ReportPath, reportJson);
Console.WriteLine($"\n=== Pipeline Complete ===");
Console.WriteLine($"Succeeded: {report.Succeeded}");
Console.WriteLine($"Failed: {report.PreValidationFailed + report.ProcessingFailed + report.PostValidationFailed + report.Errors}");
Console.WriteLine($"Duration: {report.TotalDuration.TotalMinutes:F1} minutes");
Console.WriteLine($"Report: {config.ReportPath}");
// Helper methods
bool ValidateInput(string path)
{
try
{
var info = new FileInfo(path);
if (!info.Exists || info.Length == 0 || info.Length > 50 * 1024 * 1024) return false;
string content = File.ReadAllText(path);
return content.Contains("<html", StringComparison.OrdinalIgnoreCase) ||
content.Contains("<!DOCTYPE", StringComparison.OrdinalIgnoreCase);
}
catch { return false; }
}
bool ValidateOutput(string path)
{
try
{
using var pdf = PdfDocument.FromFile(path);
return pdf.PageCount > 0 && new FileInfo(path).Length > 1024;
}
catch { return false; }
}
bool IsTransient(Exception ex) =>
ex is IOException || ex is OutOfMemoryException ||
ex.Message.Contains("timeout", StringComparison.OrdinalIgnoreCase);
Checkpoint LoadCheckpoint(string path)
{
if (File.Exists(path))
{
string json = File.ReadAllText(path);
return JsonSerializer.Deserialize<Checkpoint>(json) ?? new Checkpoint();
}
return new Checkpoint();
}
void SaveCheckpoint(string path, Checkpoint cp) =>
File.WriteAllText(path, JsonSerializer.Serialize(cp));
// Data classes
public class PipelineConfig
{
public string InputFolder { get; set; } = "";
public string OutputFolder { get; set; } = "";
public string ArchiveFolder { get; set; } = "";
public string ErrorFolder { get; set; } = "";
public string CheckpointPath { get; set; } = "";
public string ReportPath { get; set; } = "";
public int MaxConcurrency { get; set; }
public int MaxRetries { get; set; }
public int JpegQuality { get; set; }
}
public class Checkpoint
{
public HashSet<string> CompletedFiles { get; set; } = new();
}
public class ProcessingResult
{
public string FileName { get; set; } = "";
public string Status { get; set; } = "";
public string Error { get; set; } = "";
public long OutputSize { get; set; }
public DateTime StartTime { get; set; }
public DateTime EndTime { get; set; }
}
public class PipelineReport
{
public int TotalFiles { get; set; }
public int ProcessedThisRun { get; set; }
public int Succeeded { get; set; }
public int PreValidationFailed { get; set; }
public int ProcessingFailed { get; set; }
public int PostValidationFailed { get; set; }
public int Errors { get; set; }
public TimeSpan TotalDuration { get; set; }
public TimeSpan AverageFileTime { get; set; }
}Imports IronPdf
Imports System
Imports System.Collections.Generic
Imports System.IO
Imports System.Linq
Imports System.Threading.Tasks
Imports System.Threading
Imports System.Collections.Concurrent
Imports System.Diagnostics
Imports System.Text.Json
' Configuration
Dim config As New PipelineConfig With {
.InputFolder = "input/",
.OutputFolder = "output/",
.ArchiveFolder = "archive/",
.ErrorFolder = "errors/",
.CheckpointPath = "pipeline-checkpoint.json",
.ReportPath = "pipeline-report.json",
.MaxConcurrency = Math.Max(1, Environment.ProcessorCount \ 2),
.MaxRetries = 3,
.JpegQuality = 70
}
' Initialize folders
Directory.CreateDirectory(config.OutputFolder)
Directory.CreateDirectory(config.ArchiveFolder)
Directory.CreateDirectory(config.ErrorFolder)
' Load checkpoint for resume capability
Dim checkpoint As Checkpoint = LoadCheckpoint(config.CheckpointPath)
Dim results As New ConcurrentBag(Of ProcessingResult)()
Dim stopwatch As Stopwatch = Stopwatch.StartNew()
' Get files to process
Dim allFiles As String() = Directory.GetFiles(config.InputFolder, "*.html")
Dim filesToProcess As String() = allFiles.
Where(Function(f) Not checkpoint.CompletedFiles.Contains(Path.GetFileName(f))).
ToArray()
Console.WriteLine("Pipeline starting:")
Console.WriteLine($" Total files: {allFiles.Length}")
Console.WriteLine($" Already processed: {checkpoint.CompletedFiles.Count}")
Console.WriteLine($" To process: {filesToProcess.Length}")
Console.WriteLine($" Concurrency: {config.MaxConcurrency}")
Dim renderer As New ChromePdfRenderer()
Dim checkpointLock As New Object()
Dim options As New ParallelOptions With {
.MaxDegreeOfParallelism = config.MaxConcurrency
}
Parallel.ForEach(filesToProcess, options, Sub(inputFile)
Dim result As New ProcessingResult With {
.FileName = Path.GetFileName(inputFile),
.StartTime = DateTime.UtcNow
}
Try
' Stage: Pre-validation
If Not ValidateInput(inputFile) Then
result.Status = "PreValidationFailed"
result.Error = "Input file failed validation"
results.Add(result)
Return
End If
Dim baseName As String = Path.GetFileNameWithoutExtension(inputFile)
Dim tempPath As String = Path.Combine(config.OutputFolder, $"{baseName}.pdf")
Dim archivePath As String = Path.Combine(config.ArchiveFolder, $"{baseName}.pdf")
' Stage: Process with retry
Dim pdf As PdfDocument = Nothing
Dim attempt As Integer = 0
Dim success As Boolean = False
While attempt < config.MaxRetries AndAlso Not success
attempt += 1
Try
pdf = renderer.RenderHtmlFileAsPdf(inputFile)
success = True
Catch ex As Exception When IsTransient(ex) AndAlso attempt < config.MaxRetries
Thread.Sleep(CInt(Math.Pow(2, attempt)) * 500)
End Try
End While
If Not success OrElse pdf Is Nothing Then
result.Status = "ProcessingFailed"
result.Error = "Max retries exceeded"
results.Add(result)
Return
End If
Using pdf
' Stage: Compress and convert to PDF/A-3b for archival
pdf.SaveAsPdfA(tempPath, PdfAVersions.PdfA3b)
End Using
' Stage: Post-validation
If Not ValidateOutput(tempPath) Then
File.Move(tempPath, Path.Combine(config.ErrorFolder, $"{baseName}.pdf"), overwrite:=True)
result.Status = "PostValidationFailed"
result.Error = "Output file failed validation"
results.Add(result)
Return
End If
' Stage: Archive
File.Move(tempPath, archivePath, overwrite:=True)
' Update checkpoint
SyncLock checkpointLock
checkpoint.CompletedFiles.Add(result.FileName)
SaveCheckpoint(config.CheckpointPath, checkpoint)
End SyncLock
result.Status = "Success"
result.OutputSize = New FileInfo(archivePath).Length
result.EndTime = DateTime.UtcNow
results.Add(result)
Console.WriteLine($"[OK] {baseName}.pdf ({result.OutputSize \ 1024}KB)")
Catch ex As Exception
result.Status = "Error"
result.Error = ex.Message
result.EndTime = DateTime.UtcNow
results.Add(result)
Console.WriteLine($"[ERROR] {result.FileName}: {ex.Message}")
End Try
End Sub)
stopwatch.Stop()
' Generate report
Dim report As New PipelineReport With {
.TotalFiles = allFiles.Length,
.ProcessedThisRun = results.Count,
.Succeeded = results.Count(Function(r) r.Status = "Success"),
.PreValidationFailed = results.Count(Function(r) r.Status = "PreValidationFailed"),
.ProcessingFailed = results.Count(Function(r) r.Status = "ProcessingFailed"),
.PostValidationFailed = results.Count(Function(r) r.Status = "PostValidationFailed"),
.Errors = results.Count(Function(r) r.Status = "Error"),
.TotalDuration = stopwatch.Elapsed,
.AverageFileTime = If(results.Any(), TimeSpan.FromMilliseconds(stopwatch.Elapsed.TotalMilliseconds / results.Count), TimeSpan.Zero)
}
Dim reportJson As String = JsonSerializer.Serialize(report, New JsonSerializerOptions With {.WriteIndented = True})
File.WriteAllText(config.ReportPath, reportJson)
Console.WriteLine(vbCrLf & "=== Pipeline Complete ===")
Console.WriteLine($"Succeeded: {report.Succeeded}")
Console.WriteLine($"Failed: {report.PreValidationFailed + report.ProcessingFailed + report.PostValidationFailed + report.Errors}")
Console.WriteLine($"Duration: {report.TotalDuration.TotalMinutes:F1} minutes")
Console.WriteLine($"Report: {config.ReportPath}")
' Helper methods
Function ValidateInput(path As String) As Boolean
Try
Dim info As New FileInfo(path)
If Not info.Exists OrElse info.Length = 0 OrElse info.Length > 50 * 1024 * 1024 Then Return False
Dim content As String = File.ReadAllText(path)
Return content.Contains("<html", StringComparison.OrdinalIgnoreCase) OrElse
content.Contains("<!DOCTYPE", StringComparison.OrdinalIgnoreCase)
Catch
Return False
End Try
End Function
Function ValidateOutput(path As String) As Boolean
Try
Using pdf = PdfDocument.FromFile(path)
Return pdf.PageCount > 0 AndAlso New FileInfo(path).Length > 1024
End Using
Catch
Return False
End Try
End Function
Function IsTransient(ex As Exception) As Boolean
Return TypeOf ex Is IOException OrElse TypeOf ex Is OutOfMemoryException OrElse
ex.Message.Contains("timeout", StringComparison.OrdinalIgnoreCase)
End Function
Function LoadCheckpoint(path As String) As Checkpoint
If File.Exists(path) Then
Dim json As String = File.ReadAllText(path)
Return JsonSerializer.Deserialize(Of Checkpoint)(json) OrElse New Checkpoint()
End If
Return New Checkpoint()
End Function
Sub SaveCheckpoint(path As String, cp As Checkpoint)
File.WriteAllText(path, JsonSerializer.Serialize(cp))
End Sub
' Data classes
Public Class PipelineConfig
Public Property InputFolder As String = ""
Public Property OutputFolder As String = ""
Public Property ArchiveFolder As String = ""
Public Property ErrorFolder As String = ""
Public Property CheckpointPath As String = ""
Public Property ReportPath As String = ""
Public Property MaxConcurrency As Integer
Public Property MaxRetries As Integer
Public Property JpegQuality As Integer
End Class
Public Class Checkpoint
Public Property CompletedFiles As HashSet(Of String) = New HashSet(Of String)()
End Class
Public Class ProcessingResult
Public Property FileName As String = ""
Public Property Status As String = ""
Public Property Error As String = ""
Public Property OutputSize As Long
Public Property StartTime As DateTime
Public Property EndTime As DateTime
End Class
Public Class PipelineReport
Public Property TotalFiles As Integer
Public Property ProcessedThisRun As Integer
Public Property Succeeded As Integer
Public Property PreValidationFailed As Integer
Public Property ProcessingFailed As Integer
Public Property PostValidationFailed As Integer
Public Property Errors As Integer
Public Property TotalDuration As TimeSpan
Public Property AverageFileTime As TimeSpan
End ClassSaída
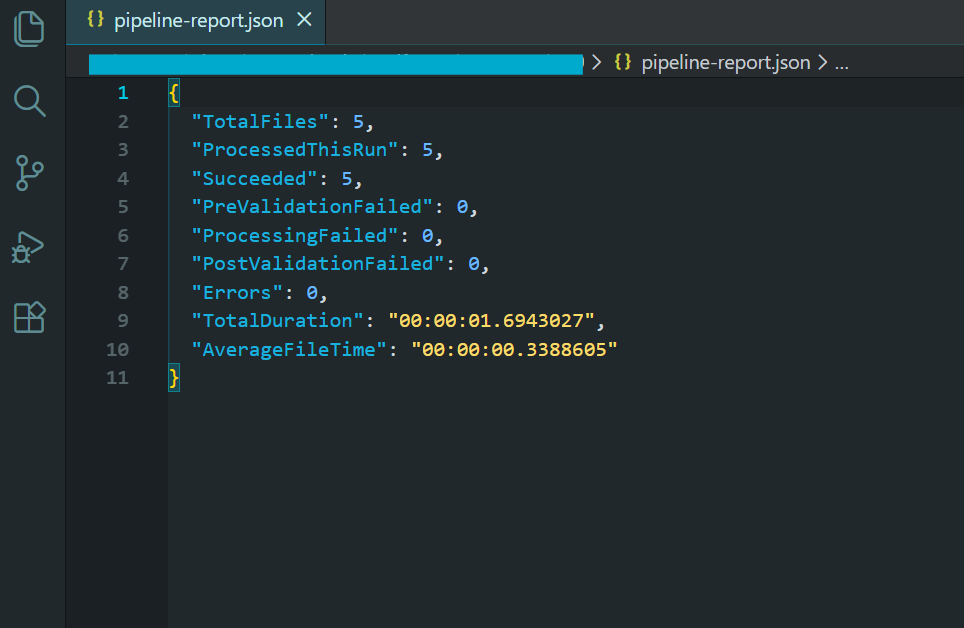
Relatório do pipeline mostrando os resultados do processamento em lote.
Este pipeline incorpora todos os padrões que abordamos neste tutorial: processamento paralelo com concorrência controlada, tratamento de erros por arquivo com opção de ignorar em caso de falha, lógica de repetição para erros transitórios, criação de pontos de verificação para retomada após falha, validação pré e pós-processamento, gerenciamento de memória com descarte explícito e registro abrangente com um relatório de resumo final.
O resultado desse processo é um diretório de arquivos compactados compatíveis com PDF/A-3b, um arquivo de ponto de verificação para permitir a retomada do processamento, um registro de erros para os arquivos que não puderam ser processados e um relatório resumido com estatísticas de processamento. Este é o padrão que você deseja para qualquer carga de trabalho séria de processamento em lote de PDFs.
Próximos passos
O processamento em lote de PDFs em grande escala não se resume a chamar um método de renderização em um loop. Requer uma arquitetura bem pensada em relação à concorrência, gerenciamento de memória, tratamento de erros e implantação — e a biblioteca certa para fazer tudo funcionar. O IronPDF fornece o mecanismo de renderização thread-safe, a superfície de API assíncrona, as ferramentas de compressão e os recursos de conversão de formato que formam a base de qualquer pipeline de PDF em lote .NET .
Seja para criar um gerador de relatórios noturnos que produza milhares de PDFs antes do amanhecer, migrar um arquivo de documentos legado para conformidade com PDF/A ou implementar um serviço de processamento nativo da nuvem no Kubernetes, os padrões deste tutorial oferecem uma estrutura comprovada para você construir. O processamento paralelo com concorrência controlada mantém a taxa de transferência elevada. A lógica de ignorar em caso de falha e de repetição mantém o fluxo de trabalho em andamento quando arquivos individuais causam problemas. O sistema de pontos de verificação garante que você nunca perca o progresso. E os padrões de implantação em nuvem permitem que você dimensione a capacidade computacional para atender à sua carga de trabalho.
Pronto para começar a construir? Baixar IronPDF e experimentá-lo com um teste gratuito — a mesma biblioteca gerencia tudo, desde a renderização de arquivo único até pipelines de lote de cem mil arquivos. Se você tiver dúvidas sobre escalabilidade, implantação ou arquitetura para o seu caso de uso específico, entre em contato com nossa equipe de suporte de engenharia — já ajudamos equipes a criar pipelines em lote de todos os tamanhos e teremos prazer em ajudá-lo a fazer tudo certo.
Perguntas frequentes
O que é processamento em lote de PDFs em C#?
O processamento em lote de PDFs em C# refere-se ao processamento automatizado de inúmeros documentos PDF simultaneamente, utilizando a linguagem de programação C#. Este método é ideal para automatizar fluxos de trabalho de documentos em grande escala.
Como o IronPDF pode auxiliar no processamento em lote de PDFs?
O IronPDF fornece ferramentas e bibliotecas robustas que simplificam o processamento em lote de PDFs em C#. Ele suporta processamento paralelo, permitindo o gerenciamento eficiente de milhares de PDFs simultaneamente.
Quais são os benefícios de usar o processamento paralelo com o IronPDF?
O processamento paralelo com IronPDF permite um processamento em lote de PDFs mais rápido e eficiente. Essa abordagem maximiza a utilização de recursos e reduz significativamente o tempo de processamento.
O IronPDF pode ser implementado em plataformas de nuvem para processamento em lote?
Sim, o IronPDF pode ser implementado em plataformas de nuvem como Azure Functions, AWS Lambda e Kubernetes, permitindo o processamento em lote de PDFs de forma escalável e flexível.
Como o IronPDF lida com erros durante o processamento em lote de PDFs?
O IronPDF inclui recursos de tratamento de erros e lógica de repetição que garantem a confiabilidade durante o processamento em lote de PDFs. Esses recursos ajudam a gerenciar e corrigir erros sem intervenção manual.
Qual é o papel da lógica de repetição no processamento de PDFs com o IronPDF?
A lógica de repetição do IronPDF garante que problemas temporários não interrompam o fluxo de trabalho de processamento em lote. Se ocorrer um erro, o IronPDF pode tentar reprocessar automaticamente o documento com falha.
Por que C# é uma linguagem adequada para processamento em lote de PDFs?
C# é uma linguagem de programação poderosa com extensas bibliotecas e frameworks que a tornam ideal para o processamento em lote de PDFs. Ela se integra perfeitamente ao IronPDF para uma automação eficiente de documentos.
Como o IronPDF garante a segurança dos documentos PDF durante o processamento?
O IronPDF oferece suporte ao manuseio seguro de documentos PDF, fornecendo recursos de criptografia e proteção por senha, garantindo que os documentos processados permaneçam confidenciais e seguros.
Quais são alguns exemplos de casos de uso do processamento em lote de PDFs em empresas?
As empresas utilizam o processamento em lote de PDFs para tarefas como geração de faturas em massa, digitalização de documentos e distribuição de relatórios em larga escala. O IronPDF facilita esses casos de uso automatizando e otimizando os fluxos de trabalho de documentos.
O IronPDF é compatível com diferentes formatos e versões de PDF?
Sim, o IronPDF foi projetado para lidar com vários formatos e versões de PDF, garantindo compatibilidade e flexibilidade em tarefas de processamento em lote.


Ainda está rolando a tela?
Quer provas rápidas? PM > Install-Package IronPdf
executar um exemplo Veja seu HTML se transformar em um PDF.










