

C#'ta Toplu PDF İşleme: Belge İş Akışlarını Ölçekte Otomatikleştirin
IronPDF ile C# de Toplu PDF işleme, .NET geliştiricilerin belge iş akışlarını otomatikleştirmelerini sağlar — paralel HTML'den PDF'e dönüşüm ve toplu birleştirme/bölünmeden asenkron PDF hatlarına, yerleşik hata işleme, yeniden deneme mantığı ve kontrol noktalarına kadar. IronPDF'in thread-safe Chromium motoru ve IDisposable tabanlı bellek yönetimi, gerek yerinde çalışırken, gerekse Azure Functions, AWS Lambda ya da Kubernetes üzerinde, yüksek geçirken PDF otomasyonu için özel olarak tasarlanmıştır.
Kısa-Özet: Hızlı Başlangıç Kılavuzu
Bu eğitim, C#'da ölçeklenebilir PDF otomasyonunu kapsar — paralel dönüştürme ve toplu işlemlerden bulut dağıtım ve dayanıklı hat döngüsü desenlerine kadar.
- Kimin için: Belge ağırlıklı iş akışlarından sorumlu .NET geliştiricileri ve mimarları — ardışık işlemenin mümkün olmadığı belge göç projeleri, günlük rapor üretim hatları, uyumluluk iyileştirme süpürmeleri veya arşiv dijitalleştirme çabaları.
- Ne inşa edeceksiniz:
Parallel.ForEachile paralel HTML'den PDF'e dönüşüm, toplu birleştirme ve ayırma işlemleri, eşzamanlılık kontrolü içinSemaphoreSlimile asenkron boru hatları, başarısızlıkta atlama ve yeniden deneme mantığı ile hata yönetimi, çökmeleri önlemek için kontrol noktası/devam etme kalıpları ve Azure Functions, AWS Lambda ve Kubernetes için bulut tabanlı konuşlandırma yapılandırmaları. - Nerede çalışır: .NET 6+, .NET Framework 4.6.2+, .NET Standard 2.0. Tüm renderlar, IronPDF'in yerleşik Chromium motorunu kullanır — başsız tarayıcı bağımlılığı veya harici hizmetler gerektirmez.
- Bu yaklaşıma ne zaman başvurulur? Seviyeli çalışmanın gerektirdiğinden daha fazla PDF işlemek gerektiğinde — ölçekle belge göçü, belirli zaman diliminde planlanan toplu işler veya değişken belge yükleri olan çok kiracılı platformlar.
- Tecnically neden önemli: IronPDF'in
ChromePdfRenderer'si iş parçacığı güvenli ve her render için durumsuzdur, bu yüzden birden çok iş parçacığı güvenli bir şekilde tek bir oluşturucu örneğini paylaşabilir. .NET'in Görev Paralel Kütüphanesi veIDisposable'ınPdfDocumentüzerindeki kombinasyonu ile tahmin edilebilir bellek davranışı ve CPU doyumu elde edersiniz, yarış koşulları veya bellek sızıntılarına karşı.
Bir dizindeki tüm HTML dosyalarını sadece birkaç satır kodla PDF'ye toplu olarak dönüştürün:
-
IronPDF aşağıdaki NuGet Paket Yöneticisi ile yükleyin
-
Bu kod parçacığını kopyalayın ve çalıştırın.
using IronPdf; using System.IO; using System.Threading.Tasks; var renderer = new ChromePdfRenderer(); var htmlFiles = Directory.GetFiles("input/", "*.html"); Parallel.ForEach(htmlFiles, htmlFile => { var pdf = renderer.RenderHtmlFileAsPdf(htmlFile); pdf.SaveAs($"output/{Path.GetFileNameWithoutExtension(htmlFile)}.pdf"); }); -
Canlı ortamınızda test için dağıtım yapın
Ücretsiz deneme ile bugün projenizde IronPDF kullanmaya başlayın

IronPDF'yi satın aldıktan veya 30 günlük denemeye kaydolduktan sonra, başvurunuzda lisans anahtarınızı ekleyin.
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp-2.csIronPdf.License.LicenseKey = "KEY";
Imports IronPdf
IronPdf.License.LicenseKey = "KEY"Bugün IronPDF ile projenizde ücretsiz bir deneme ile başlayın.
İçindekiler
- Sorunu Anlamak
- Binlerce PDF İşlemeniz Gerektiğinde
- Temel
- IronPDF Toplu İşleme Mimarisi
- Eşzamanlılık Kontrolü ve Thread Güvenliği
- Büyük Ölçekte Bellek Yönetimi
- İlerleme Raporlama ve Kayıt Tutma
- Temel İşlemler
- Yaygın Toplu İşlemler
- Toplu HTML den PDF'e Dönüşüm
- Toplu PDF Birleştirme
- Toplu PDF Bölme
- Toplu Sıkıştırma
- Toplu Format Dönüşümü (PDF/A, PDF/UA)
- Dayanıklılık
- Dayanıklı Toplu Hatlar İnşa Etmek
- Hata Yönetimi ve Hata Durumunda Atlama
- Geçici Hatalar İçin Yeniden Deneme Mantığı
- Çöküşten Sonra Devam Etmek İçin Kontrol Noktası
- İşlem Öncesi ve Sonrası Doğrulama
- Performans
- Asenkron ve Paralel İşleme Desenleri
- Görev Paralel Kütüphanesi Entegrasyonu
- Eşzamanlılığı Kontrol Etme (SemaphoreSlim)
- Async/Await En İyi Uygulamalar
- Bellek Tükenmesini Önlemek
- Dağıtım
- Toplu İşler İçin Bulut Dağıtımı
- Dayanıklı Fonksiyonlar ile Azure Fonksiyonları
- AWS Lambda İle Adım Fonksiyonları
- Kubernetes İş Zamanlama
- Maliyet Optimizasyon Stratejileri
- Tümünü Bir Araya Getir
- Gerçek Dünya Hat Örneği
Binlerce PDF İşlemeniz Gerektiğinde
Toplu PDF işleme bir niş gereksinim değil — kurumsal belge yönetiminin rutin bir parçasıdır. Her sektörde ortaya çıkan ve ortak bir özelliğe sahip olan senaryolar: işleri birer birer yapmak bir seçenek değil.
Belge göç projeleri en yaygın tetikleyicilerden biridir. Bir kuruluş, bir belge yönetim sisteminden diğerine geçerken, binlerce (bazı durumlarda milyonlarca) belgenin dönüştürülmesi, yeniden biçimlendirilmesi veya tekrar etiketlenmesi gerekir. Bir sigorta şirketi eski bir talepler sisteminden geçiyorsa, 500.000 TIFF tabanlı talep belgesini aranabilir PDF'lere dönüştürmesi gerekebilir. Bir hukuk firması yeni bir dava yönetim platformuna geçiyorsa, dağınık yazışmaları birleşik dava dosyalarına dönüştürmesi gerekebilir. Bunlar tek seferlik işlerdir, ancak kapsamları oldukça büyüktür ve hatalara karşı hoşgörüsüzdürler.
Günlük rapor üretimi aynı sorunun durgun hâlidir. Binlerce müşteri için gün sonu portföy raporları üreten finans kurumları, her çıkış konteyneri için sevkiyat bildirileri üreten lojistik şirketleri, yüzlerce departmanda günlük hasta özetlerini yaratan sağlık sistemleri — hepsi bu kadar büyük ölçekte PDF çıktısı üreterek, ardışık işlemenin kabul edilebilir zaman sınırlarını aşmasını sağlar. 10.000 raporun sabah 6'ya kadar hazır olması gerektiğinde ve veri gece yarısına kadar kesinleşmediğinde, onları bire bir sıra ile oluşturmak için altı saatiniz yoktur.
Arşiv dijitalleştirme, göç ve uyumluluğun kesişimindedir. Onlarca yıllık kağıt kayıtlarına sahip olan devlet daireleri, üniversiteler ve şirketler, belgeleri standartlara uygun formatlarda (genellikle PDF/A) dijitalleştirme ve arşivleme talimatlarıyla karşı karşıya kalır. Hacimler şaşkınlık vericidir — yalnızca NARA, kalıcı koruma için milyonlarca sayfa federal belge almaktadır — ve sürecin, yıllar sonra eksiklikler keşfetmeyeceğiniz kadar güvenilir olması gerekir.
Uyumluluk iyileştirme genellikle en acil tetikleyicidir. Bir denetim, belge arşivinizin, yeni olarak uygulanan bir standardı karşılamadığını ortaya koyduğunda — örneğin, saklanan faturalarınız PDF/A-3'e uyum sağlamıyorsa veya tıbbi kayıtlarınız, Bölüm 508 tarafından gereken erişilebilirlik etiketlerini içermiyorsa — mevcut arşivinizi yeni standarda karşı işlemeniz gerekir. Baskı yüksek, zaman çizelgesi sıkı ve hacim arşivinizin içereceği her şeydir.
Bu senaryoların her birinde, temel meydan okuma aynıdır: büyük sayıda PDF işlemeyi güvenilir, verimli ve bellekten çıkmadan ya da bir şeyler ters gittiğinde yarıda kesilmiş işler bırakmadan nasıl yaparsınız?
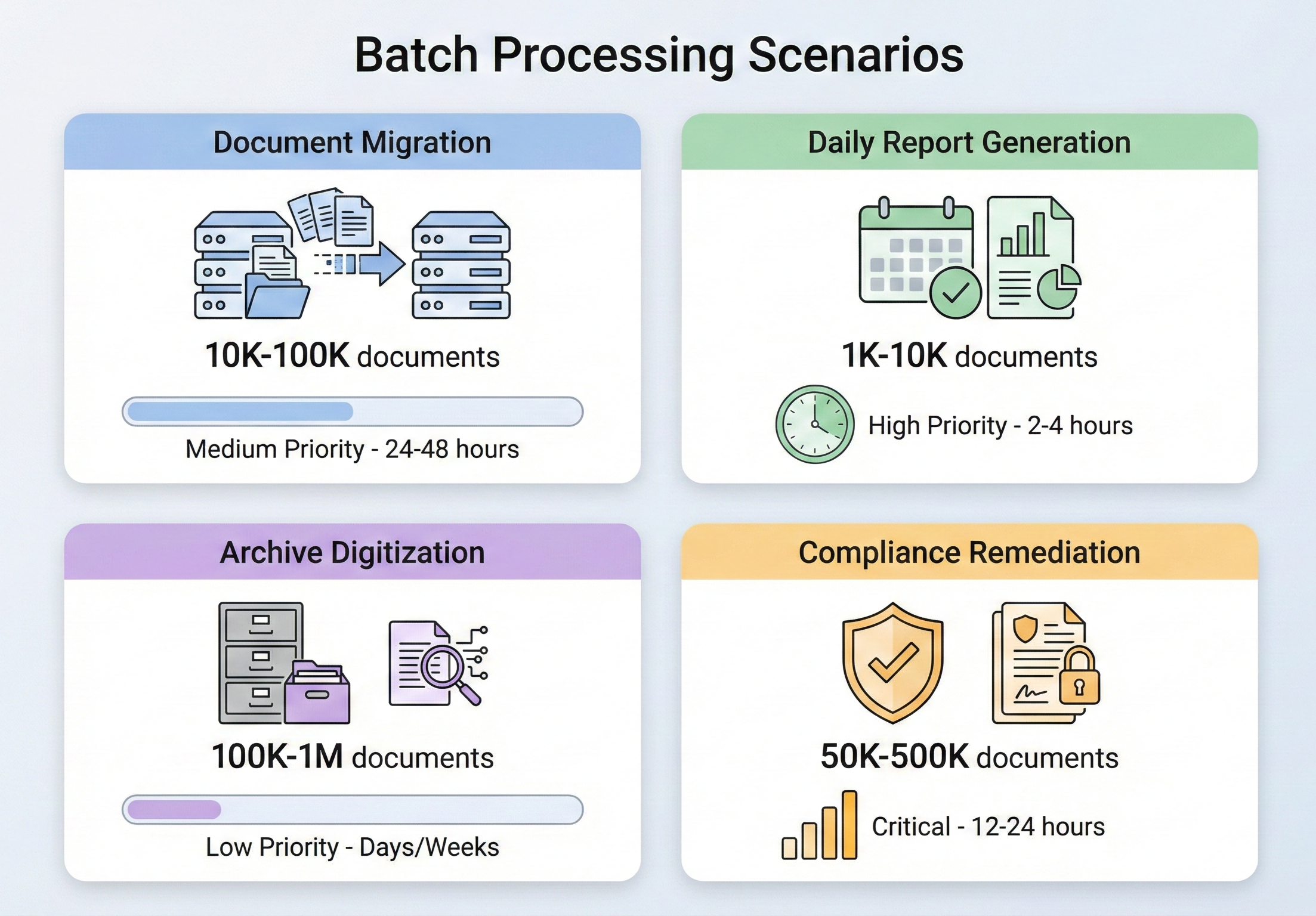
IronPDF Toplu İşleme Mimarisi
Belirli işlemlere dalmadan önce, IronPDF'in eşzamanlı iş yüklerini nasıl yönetecek şekilde tasarlandığını ve üzerine bir toplu hat inşa ederken ne tür mimari kararlar almanız gerektiğini anlamak önemlidir.
Installing IronPDF
NuGet üzerinden IronPDF'i kurun:
Install-Package IronPdf
.NET CLI kullanarak:
dotnet add package IronPdf
IronPDF, .NET Framework 4.6.2+, .NET Core, .NET 5 ila .NET 10 ve .NET Standard 2.0'ı destekler. Windows, Linux, macOS ve Docker konteynerlerinde çalışıyor ve hem yerinde toplu işler hem de bulut tabanlı dağıtım için uygundur.
Üretim toplu işlemesi için, lisans anahtarınızı, herhangi bir PDF işlemi başlamadan önce uygulama başlatıldığında License.LicenseKey ile ayarlayın. Bu, tüm threadlar üzerindeki her render çağrısının, dosya başına watermarks olmadan tüm özellik setine erişimini sağlar.
Eşzamanlılık Kontrolü ve Thread Güvenliği
IronPDF'in Chromium tabanlı rendering motoru thread-safe'tir. İş parçacıkları arasında birden çok ChromePdfRenderer örneği oluşturabilir veya tek bir örneği paylaşabilirsiniz — IronPDF iç senkronizasyonu elle alır. Toplu işleme için resmi öneri, tüm mevcut CPU çekirdeklerini otomatik olarak iş yükünü dağıtan .NET'in yerleşik Parallel.ForEach kullanmaktır.
"Thread-safe" ifadesi "sınırsız iş parçacığı kullan" anlamına gelmez. Her eşzamanlı PDF işlem operasyonu bellek tüketir (Chromium motoru DOM parsellemesi, CSS yerleşimi ve görüntü rasterizasyonu için çalışma alanına ihtiyaç duyar) ve bellek sınırlı bir sistemde çok fazla paralel işlem başlatmak performansı düşürebilir veya OutOfMemoryException'ya neden olabilir. Doğru düzeyde eşzamanlılık donanımınıza bağlıdır: 64 GB RAM'li 16 çekirdekli bir sunucu, rahatça 8-12 eşzamanlı render yapabilir; 8 GB bellekli 4 çekirdekli bir VM 2-4 ile sınırlı olabilir. Bunu ParallelOptions.MaxDegreeOfParallelism ile kontrol edin — başlangıç noktası olarak mevcut CPU çekirdeklerinizin yaklaşık yarısına ayarlayın, ardından gözlemlenen bellek baskısına göre ayarlayın.
Büyük Ölçekte Bellek Yönetimi
Toplu PDF işlemede bellek yönetimi en önemli endişedir. Her PdfDocument nesnesi bir PDF'in tüm ikili içeriğini bellekte tutar ve bu nesneleri serbest bırakmamak bellek gereksiniminin, işlenen dosya sayısıyla doğrusal olarak artmasına neden olur.
Kritik kural: her zaman using ifadelerini kullanın veya açıkça Dispose() nesneleri üzerinde çağrı yapın. IronPDF'in PdfDocument, IDisposable'ı uygular ve toplu senaryolarda sıklıkla gözden kaçan bellek sorunlarının en yaygın nedeni nesneleri serbest bırakmamaktır. İşleme döngünüzün her iterasyonu bir PdfDocument oluşturmalı, görevini yapmalı ve serbest bırakmalı — liste veya koleksiyonda PdfDocument nesneleri biriktirmemelisiniz, sadece belirli bir nedenle ve bunu ele alacak yeterli belleğiniz varsa.
Ortadan kaldırmanın ötesinde, büyük partiler için bu bellek yönetimi stratejilerini düşünün:
Küçük parçalarda işleyin her şeyi bir kerede yüklemek yerine. 50.000 dosya işlemeniz gerekiyorsa, hepsini bir listeye almayın ve ardından sırayla işlemeyin — 100 veya 500 partiler halinde işlem yapın, çöp toplayıcının parçalar arasında belleği geri kazanmasına izin verin.
Çok büyük partiler için çöp toplama çağırmalarını zorlayın. Genellikle GC'nin kendini yönetmesine izin verirken, toplu işlem, bu nadir senaryolardan biridir, parça sınırları arasında GC.Collect() çağrısı yapmak bellek baskısının birikmesini önleyebilir.
Bellek tüketimini izleyin GC.GetTotalMemory() veya süreç düzeyinde metrikler kullanarak. Bellek kullanımı bir eşiği (örneğin, kullanılabilir RAM'in %80'i) aşarsa, çöp toplayıcının yetişmesine izin vermek için işlemi duraklatın.
İlerleme Raporlama ve Günlükleme
Bir toplu iş saatlerce sürdüğünde, ilerlemesine dair görünürlük seçenek değildir — gerekliliktir. Minimumda, her dosyanın başlangıcı ve tamamlanmasını kaydetmeli, başarı/başarısızlık sayımlarını izlemeli ve kalan süreyi tahmin etmelisiniz. Paralel operasyonlar yaparken iş parçacığı güvenli sayaçlar için Interlocked.Increment kullanın ve çıkışınızı doldurmamak için düzenli aralıklarla (her 50 veya 100 dosyada bir) kaydedin. Geçen süreyi System.Diagnostics.Stopwatch ile izleyin ve anlamlı bir ETA vermek için bir çalışma dosyaları-başına saniye oranı hesaplayın.
Üretim toplu işler için, izleme panolarının gerçek zamanlı durumu gösterebilmesi için ilerlemeyi kalıcı bir depoya (veritabanı, dosya veya mesaj kuyruğu) yazmayı düşünün, böylece toplu işleme sürecine doğrudan bağlanmadan gösterebilir.
Ortak Toplu İşlemler
Mimari temeli yerine oturttuktan sonra, en yaygın toplu işlemleri ve bunların IronPDF uygulamalarını inceleyelim.
Toplu HTML'den PDF'e Dönüşüm
HTML'den PDF'e dönüştürme en yaygın toplu işlemdir. İster şablonlardan fatura oluştursun, ister HTML dokümantasyon kütüphanesini PDF'e dönüştürsün, isterse bir web uygulamasından dinamik raporları görselleştirsin, desen aynıdır: girişlerinizi yineleyin, her birini işleyin ve çıktıyı kaydedin.
Girdi (5 HTML Dosyası)
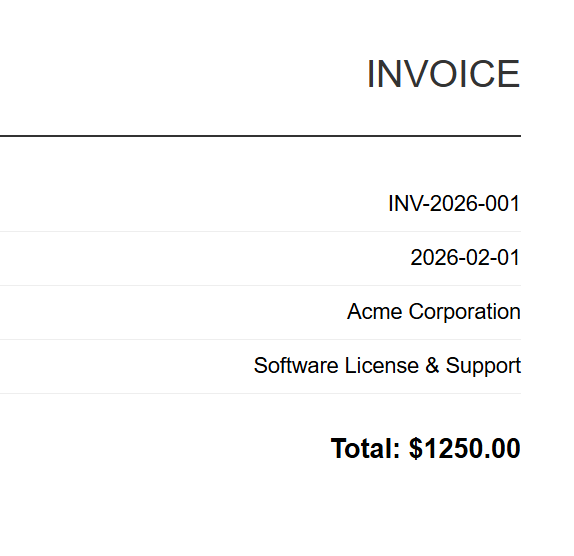
INV-2026-001
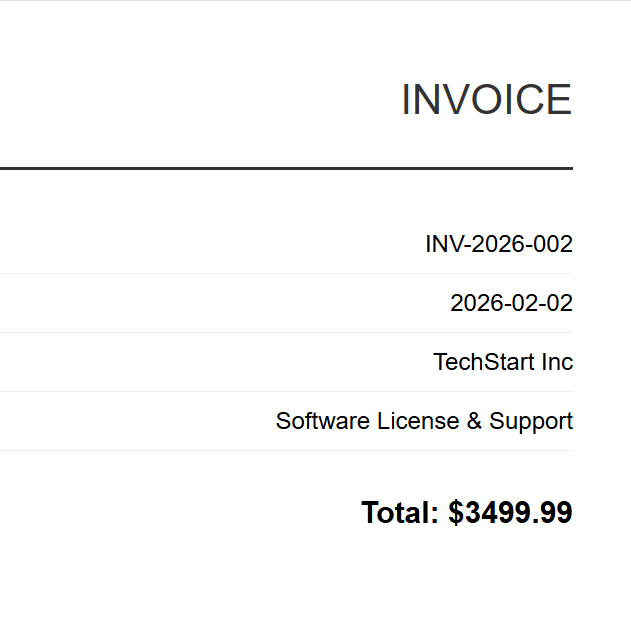
INV-2026-002
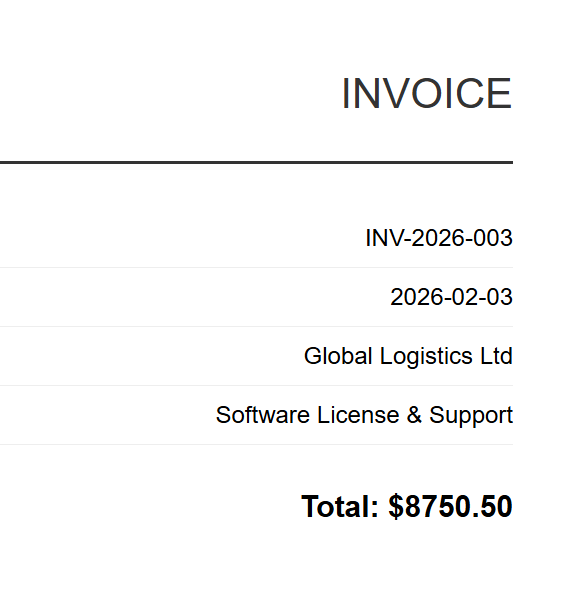
INV-2026-003
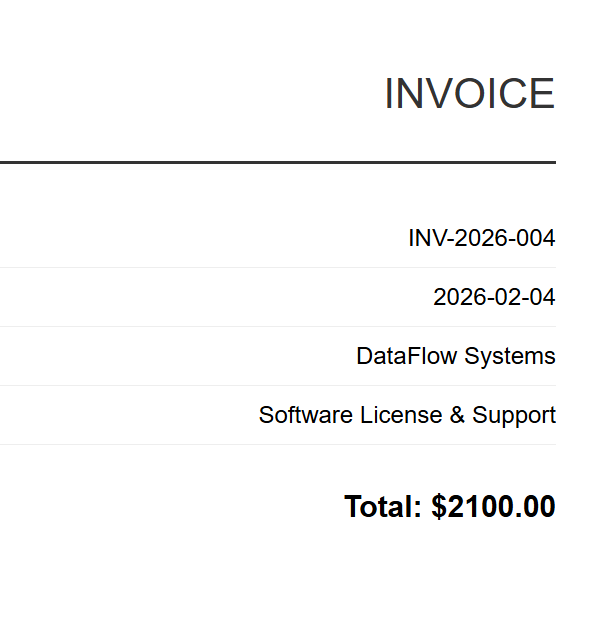
INV-2026-004
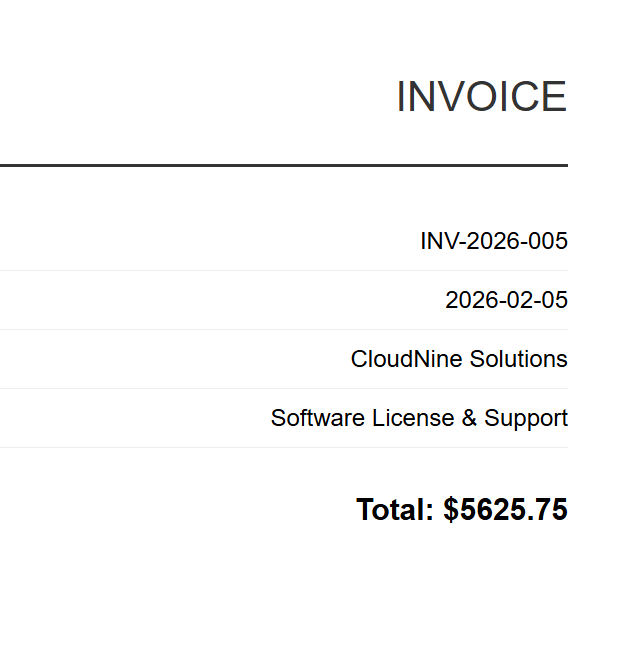
INV-2026-005
Uygulama, tüm HTML dosyalarını eşanlı olarak işlemek için ChromePdfRenderer ile Parallel.ForEach kullanır, MaxDegreeOfParallelism aracılığıyla paralel çalışmayı denetleyerek geçirgenliği bellek tüketimine karşı dengeler. Her bir dosya RenderHtmlFileAsPdf ile işlenir ve ilerleme takibi için iş parçacığı güvenli Interlocked sayaçları ile sonuç dizinine kaydedilir.
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-html-to-pdf.csusing IronPdf;
using System;
using System.IO;
using System.Threading.Tasks;
using System.Threading;
// Configure paths
string inputFolder = "input/";
string outputFolder = "output/";
Directory.CreateDirectory(outputFolder);
string[] htmlFiles = Directory.GetFiles(inputFolder, "*.html");
Console.WriteLine($"Found {htmlFiles.Length} HTML files to convert");
// Create renderer instance (thread-safe, can be shared)
var renderer = new ChromePdfRenderer();
// Track progress
int processed = 0;
int failed = 0;
// Process in parallel with controlled concurrency
var options = new ParallelOptions
{
MaxDegreeOfParallelism = Environment.ProcessorCount / 2
};
Parallel.ForEach(htmlFiles, options, htmlFile =>
{
try
{
string fileName = Path.GetFileNameWithoutExtension(htmlFile);
string outputPath = Path.Combine(outputFolder, $"{fileName}.pdf");
using var pdf = renderer.RenderHtmlFileAsPdf(htmlFile);
pdf.SaveAs(outputPath);
Interlocked.Increment(ref processed);
Console.WriteLine($"[OK] {fileName}.pdf");
}
catch (Exception ex)
{
Interlocked.Increment(ref failed);
Console.WriteLine($"[ERROR] {Path.GetFileName(htmlFile)}: {ex.Message}");
}
});
Console.WriteLine($"\nComplete: {processed} succeeded, {failed} failed");Imports IronPdf
Imports System
Imports System.IO
Imports System.Threading.Tasks
Imports System.Threading
' Configure paths
Dim inputFolder As String = "input/"
Dim outputFolder As String = "output/"
Directory.CreateDirectory(outputFolder)
Dim htmlFiles As String() = Directory.GetFiles(inputFolder, "*.html")
Console.WriteLine($"Found {htmlFiles.Length} HTML files to convert")
' Create renderer instance (thread-safe, can be shared)
Dim renderer As New ChromePdfRenderer()
' Track progress
Dim processed As Integer = 0
Dim failed As Integer = 0
' Process in parallel with controlled concurrency
Dim options As New ParallelOptions With {
.MaxDegreeOfParallelism = Environment.ProcessorCount \ 2
}
Parallel.ForEach(htmlFiles, options, Sub(htmlFile)
Try
Dim fileName As String = Path.GetFileNameWithoutExtension(htmlFile)
Dim outputPath As String = Path.Combine(outputFolder, $"{fileName}.pdf")
Using pdf = renderer.RenderHtmlFileAsPdf(htmlFile)
pdf.SaveAs(outputPath)
End Using
Interlocked.Increment(processed)
Console.WriteLine($"[OK] {fileName}.pdf")
Catch ex As Exception
Interlocked.Increment(failed)
Console.WriteLine($"[ERROR] {Path.GetFileName(htmlFile)}: {ex.Message}")
End Try
End Sub)
Console.WriteLine($"\nComplete: {processed} succeeded, {failed} failed")Çıktı
Her HTML faturası, karşılık gelen bir PDF olarak işlenir. Yukarıda INV-2026-001.pdf gösterilmektedir - 5 toplu çıktıdan biri.
Şablon tabanlı üretim için (ör., faturalar, raporlar), tipik olarak veriyi bir HTML şablonuna birleştirip işleme başlamadan önce birleştirirsiniz. Yaklaşım basittir: HTML şablonunuzu bir kez yükleyin, satır içi kayıt verilerini (müşteri adı, toplamlar, tarihler) enjekte etmek için string.Replace kullanın ve dolu HTML'yi paralel döngünüz içindeki RenderHtmlAsPdf'ya iletin. IronPDF, RenderHtmlAsPdfAsync sağlayarak async/await kullanmak istediğiniz durumlar için de çözüm sunar — asenkron desenleri ayrıntılı olarak ilerleyen bir bölümde ele alacağız.
Toplu PDF Birleştirme
Yasal (dava dosyası belgelerini birleştirme), finansal (aylık bildirimleri üç aylık raporlara dönüştürme) ve yayıncılık iş akışlarında belgelerin gruplarını birleştirmek yaygındır.
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-merge.csusing IronPdf;
using System;
using System.IO;
using System.Linq;
using System.Collections.Generic;
string inputFolder = "documents/";
string outputFolder = "merged/";
Directory.CreateDirectory(outputFolder);
// Group PDFs by prefix (e.g., "invoice-2026-01-*.pdf" -> one merged file)
var pdfFiles = Directory.GetFiles(inputFolder, "*.pdf");
var groups = pdfFiles
.GroupBy(f => Path.GetFileName(f).Split('-').Take(3).Aggregate((a, b) => $"{a}-{b}"))
.Where(g => g.Count() > 1);
Console.WriteLine($"Found {groups.Count()} groups to merge");
foreach (var group in groups)
{
string groupName = group.Key;
var filesToMerge = group.OrderBy(f => f).ToList();
Console.WriteLine($"Merging {filesToMerge.Count} files into {groupName}.pdf");
try
{
// Load all PDFs for this group
var pdfDocs = new List<PdfDocument>();
foreach (string filePath in filesToMerge)
{
pdfDocs.Add(PdfDocument.FromFile(filePath));
}
// Merge all documents
using var merged = PdfDocument.Merge(pdfDocs);
merged.SaveAs(Path.Combine(outputFolder, $"{groupName}-merged.pdf"));
// Dispose source documents
foreach (var doc in pdfDocs)
{
doc.Dispose();
}
Console.WriteLine($" [OK] Created {groupName}-merged.pdf ({merged.PageCount} pages)");
}
catch (Exception ex)
{
Console.WriteLine($" [ERROR] {groupName}: {ex.Message}");
}
}
Console.WriteLine("\nMerge complete");Imports IronPdf
Imports System
Imports System.IO
Imports System.Linq
Imports System.Collections.Generic
Module Program
Sub Main()
Dim inputFolder As String = "documents/"
Dim outputFolder As String = "merged/"
Directory.CreateDirectory(outputFolder)
' Group PDFs by prefix (e.g., "invoice-2026-01-*.pdf" -> one merged file)
Dim pdfFiles = Directory.GetFiles(inputFolder, "*.pdf")
Dim groups = pdfFiles _
.GroupBy(Function(f) Path.GetFileName(f).Split("-"c).Take(3).Aggregate(Function(a, b) $"{a}-{b}")) _
.Where(Function(g) g.Count() > 1)
Console.WriteLine($"Found {groups.Count()} groups to merge")
For Each group In groups
Dim groupName As String = group.Key
Dim filesToMerge = group.OrderBy(Function(f) f).ToList()
Console.WriteLine($"Merging {filesToMerge.Count} files into {groupName}.pdf")
Try
' Load all PDFs for this group
Dim pdfDocs As New List(Of PdfDocument)()
For Each filePath As String In filesToMerge
pdfDocs.Add(PdfDocument.FromFile(filePath))
Next
' Merge all documents
Using merged = PdfDocument.Merge(pdfDocs)
merged.SaveAs(Path.Combine(outputFolder, $"{groupName}-merged.pdf"))
End Using
' Dispose source documents
For Each doc In pdfDocs
doc.Dispose()
Next
Console.WriteLine($" [OK] Created {groupName}-merged.pdf ({merged.PageCount} pages)")
Catch ex As Exception
Console.WriteLine($" [ERROR] {groupName}: {ex.Message}")
End Try
Next
Console.WriteLine(vbCrLf & "Merge complete")
End Sub
End ModuleÇok sayıda dosyayı birleştirmek için, bellek konusunda dikkatli olun: PdfDocument.Merge yöntemi tüm kaynak belgeleri aynı anda belleğe yükler. Yüzlerce büyük PDF dosyası birleştiriyorsanız, aşamalar halinde birleştirmeyi düşünün — 10-20 dosya gruplarını ara belgeler olarak birleştirin, ardından bu ara belgeleri birleştirin.
Toplu PDF Ayrıştırma
Çok sayfalı PDF'leri bireysel sayfalara (veya sayfa aralıklarına) ayırmak, birleştirmenin tersidir. Posta odası işlemede yaygındır, burada taranmış bir belge yığını bireysel kayıtlara ayrılmalı, ve yazdırma iş akışlarında karma belgeler ayrılmalıdır.
Girdi
Aşağıdaki kod, paralel bir döngüde CopyPage kullanarak bireysel sayfaları çıkarmayı ve her sayfa için ayrı PDF dosyaları oluşturmayı gösterir. Alternatif bir SplitByRange yardımcı işlevi, bireysel sayfalar yerine sayfa aralıklarının nasıl çıkarılacağını gösterir, büyük belgeleri daha küçük segmentlere bölmek için kullanışlıdır.
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-split.csusing IronPdf;
using System;
using System.IO;
using System.Threading.Tasks;
string inputFolder = "multipage/";
string outputFolder = "split/";
Directory.CreateDirectory(outputFolder);
string[] pdfFiles = Directory.GetFiles(inputFolder, "*.pdf");
Console.WriteLine($"Found {pdfFiles.Length} PDFs to split");
var options = new ParallelOptions
{
MaxDegreeOfParallelism = Environment.ProcessorCount / 2
};
Parallel.ForEach(pdfFiles, options, pdfFile =>
{
string baseName = Path.GetFileNameWithoutExtension(pdfFile);
try
{
using var pdf = PdfDocument.FromFile(pdfFile);
int pageCount = pdf.PageCount;
Console.WriteLine($"Splitting {baseName}.pdf ({pageCount} pages)");
// Extract each page as a separate PDF
for (int i = 0; i < pageCount; i++)
{
using var singlePage = pdf.CopyPage(i);
string outputPath = Path.Combine(outputFolder, $"{baseName}-page-{i + 1:D3}.pdf");
singlePage.SaveAs(outputPath);
}
Console.WriteLine($" [OK] Created {pageCount} files from {baseName}.pdf");
}
catch (Exception ex)
{
Console.WriteLine($" [ERROR] {baseName}: {ex.Message}");
}
});
// Alternative: Extract page ranges instead of individual pages
void SplitByRange(string inputFile, string outputFolder, int pagesPerChunk)
{
using var pdf = PdfDocument.FromFile(inputFile);
string baseName = Path.GetFileNameWithoutExtension(inputFile);
int totalPages = pdf.PageCount;
int chunkNumber = 1;
for (int startPage = 0; startPage < totalPages; startPage += pagesPerChunk)
{
int endPage = Math.Min(startPage + pagesPerChunk - 1, totalPages - 1);
using var chunk = pdf.CopyPages(startPage, endPage);
chunk.SaveAs(Path.Combine(outputFolder, $"{baseName}-chunk-{chunkNumber:D3}.pdf"));
chunkNumber++;
}
}
Console.WriteLine("\nSplit complete");Imports IronPdf
Imports System
Imports System.IO
Imports System.Threading.Tasks
Module Program
Sub Main()
Dim inputFolder As String = "multipage/"
Dim outputFolder As String = "split/"
Directory.CreateDirectory(outputFolder)
Dim pdfFiles As String() = Directory.GetFiles(inputFolder, "*.pdf")
Console.WriteLine($"Found {pdfFiles.Length} PDFs to split")
Dim options As New ParallelOptions With {
.MaxDegreeOfParallelism = Environment.ProcessorCount \ 2
}
Parallel.ForEach(pdfFiles, options, Sub(pdfFile)
Dim baseName As String = Path.GetFileNameWithoutExtension(pdfFile)
Try
Using pdf = PdfDocument.FromFile(pdfFile)
Dim pageCount As Integer = pdf.PageCount
Console.WriteLine($"Splitting {baseName}.pdf ({pageCount} pages)")
' Extract each page as a separate PDF
For i As Integer = 0 To pageCount - 1
Using singlePage = pdf.CopyPage(i)
Dim outputPath As String = Path.Combine(outputFolder, $"{baseName}-page-{i + 1:D3}.pdf")
singlePage.SaveAs(outputPath)
End Using
Next
Console.WriteLine($" [OK] Created {pageCount} files from {baseName}.pdf")
End Using
Catch ex As Exception
Console.WriteLine($" [ERROR] {baseName}: {ex.Message}")
End Try
End Sub)
' Alternative: Extract page ranges instead of individual pages
Sub SplitByRange(inputFile As String, outputFolder As String, pagesPerChunk As Integer)
Using pdf = PdfDocument.FromFile(inputFile)
Dim baseName As String = Path.GetFileNameWithoutExtension(inputFile)
Dim totalPages As Integer = pdf.PageCount
Dim chunkNumber As Integer = 1
For startPage As Integer = 0 To totalPages - 1 Step pagesPerChunk
Dim endPage As Integer = Math.Min(startPage + pagesPerChunk - 1, totalPages - 1)
Using chunk = pdf.CopyPages(startPage, endPage)
chunk.SaveAs(Path.Combine(outputFolder, $"{baseName}-chunk-{chunkNumber:D3}.pdf"))
chunkNumber += 1
End Using
Next
End Using
End Sub
Console.WriteLine(vbCrLf & "Split complete")
End Sub
End ModuleÇıktı
Sayfa 2, bağımsız PDF olarak çıkarıldı (annual-report-page-2.pdf)
IronPDF'in CopyPage ve CopyPages yöntemleri, belirtilen sayfaları içeren yeni PdfDocument nesneleri oluşturur. Kaydettikten sonra hem kaynak belgeyi hem de çıkarılan sayfa belgesini atmayı unutmayın.
Toplu Sıkıştırma
Saklama maliyetleri önemli olduğunda veya PDF'leri bant genişliği kısıtlı bağlantılar üzerinde iletmeniz gerektiğinde, toplu sıkıştırma arşiv ayak izinizi ciddi şekilde azaltabilir. IronPDF iki sıkıştırma yaklaşımı sağlar: Görüntü kalitesini/boyutunu düşürmek için CompressImages, yapısal meta verileri kaldırmak için CompressStructTree. Yeni CompressAndSaveAs API (sürüm 2025.12'de tanıtıldı), birden fazla optimizasyon tekniğini birleştirerek üstün sıkıştırma sağlar.
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-compression.csusing IronPdf;
using System;
using System.IO;
using System.Threading.Tasks;
using System.Threading;
string inputFolder = "originals/";
string outputFolder = "compressed/";
Directory.CreateDirectory(outputFolder);
string[] pdfFiles = Directory.GetFiles(inputFolder, "*.pdf");
Console.WriteLine($"Found {pdfFiles.Length} PDFs to compress");
long totalOriginalSize = 0;
long totalCompressedSize = 0;
int processed = 0;
var options = new ParallelOptions
{
MaxDegreeOfParallelism = Environment.ProcessorCount / 2
};
Parallel.ForEach(pdfFiles, options, pdfFile =>
{
string fileName = Path.GetFileName(pdfFile);
string outputPath = Path.Combine(outputFolder, fileName);
try
{
long originalSize = new FileInfo(pdfFile).Length;
Interlocked.Add(ref totalOriginalSize, originalSize);
using var pdf = PdfDocument.FromFile(pdfFile);
// Apply compression with JPEG quality setting (0-100, lower = more compression)
pdf.CompressAndSaveAs(outputPath, 60);
long compressedSize = new FileInfo(outputPath).Length;
Interlocked.Add(ref totalCompressedSize, compressedSize);
Interlocked.Increment(ref processed);
double reduction = (1 - (double)compressedSize / originalSize) * 100;
Console.WriteLine($"[OK] {fileName}: {originalSize / 1024}KB → {compressedSize / 1024}KB ({reduction:F1}% reduction)");
}
catch (Exception ex)
{
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}");
}
});
double totalReduction = (1 - (double)totalCompressedSize / totalOriginalSize) * 100;
Console.WriteLine($"\nCompression complete:");
Console.WriteLine($" Files processed: {processed}");
Console.WriteLine($" Total original: {totalOriginalSize / 1024 / 1024}MB");
Console.WriteLine($" Total compressed: {totalCompressedSize / 1024 / 1024}MB");
Console.WriteLine($" Overall reduction: {totalReduction:F1}%");Imports IronPdf
Imports System
Imports System.IO
Imports System.Threading.Tasks
Imports System.Threading
Module Program
Sub Main()
Dim inputFolder As String = "originals/"
Dim outputFolder As String = "compressed/"
Directory.CreateDirectory(outputFolder)
Dim pdfFiles As String() = Directory.GetFiles(inputFolder, "*.pdf")
Console.WriteLine($"Found {pdfFiles.Length} PDFs to compress")
Dim totalOriginalSize As Long = 0
Dim totalCompressedSize As Long = 0
Dim processed As Integer = 0
Dim options As New ParallelOptions With {
.MaxDegreeOfParallelism = Environment.ProcessorCount \ 2
}
Parallel.ForEach(pdfFiles, options, Sub(pdfFile)
Dim fileName As String = Path.GetFileName(pdfFile)
Dim outputPath As String = Path.Combine(outputFolder, fileName)
Try
Dim originalSize As Long = New FileInfo(pdfFile).Length
Interlocked.Add(totalOriginalSize, originalSize)
Using pdf = PdfDocument.FromFile(pdfFile)
' Apply compression with JPEG quality setting (0-100, lower = more compression)
pdf.CompressAndSaveAs(outputPath, 60)
End Using
Dim compressedSize As Long = New FileInfo(outputPath).Length
Interlocked.Add(totalCompressedSize, compressedSize)
Interlocked.Increment(processed)
Dim reduction As Double = (1 - CDbl(compressedSize) / originalSize) * 100
Console.WriteLine($"[OK] {fileName}: {originalSize \ 1024}KB → {compressedSize \ 1024}KB ({reduction:F1}% reduction)")
Catch ex As Exception
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}")
End Try
End Sub)
Dim totalReduction As Double = (1 - CDbl(totalCompressedSize) / totalOriginalSize) * 100
Console.WriteLine(vbCrLf & "Compression complete:")
Console.WriteLine($" Files processed: {processed}")
Console.WriteLine($" Total original: {totalOriginalSize \ 1024 \ 1024}MB")
Console.WriteLine($" Total compressed: {totalCompressedSize \ 1024 \ 1024}MB")
Console.WriteLine($" Overall reduction: {totalReduction:F1}%")
End Sub
End ModuleSıkıştırma hakkında akılda tutulması gereken birkaç şey: 60'ın altındaki JPEG kalite ayarları çoğu görselde belirgin artefaktlar üretecektir. ShrinkImage seçeneği bazı yapılandırmalarda bozulmaya neden olabilir — temsilci örneklerle test edin ve ardından tam bir toplu işlem yapın. Ve yapı ağacını kaldırmak (CompressStructTree), sıkıştırılmış PDF'lerde metin seçimi ve aramayı etkileyeceği için bu yeteneklere ihtiyaç duyulmadığında kullanın.
Toplu Biçim Dönüşümü (PDF/A, PDF/UA)
Mevcut bir arşivi standartlarla uyumlu bir formata dönüştürmek — uzun süreli arşivleme için PDF/A veya erişilebilirlik için PDF/UA — en yüksek değerli toplu işlemlerden biridir. IronPDF, PDF/A sürümlerinin tüm kapsamını destekler (PDF/A-4 dahil, 2025.11'de eklendi) ve PDF/UA uyumunu (PDF/UA-2 dahil, 2025.12'de eklendi).
Girdi
Her PDF'i PdfDocument.FromFile kullanarak yükleyen örnek, ardından PdfAVersions.PdfA3b parametresiyle SaveAsPdfA kullanarak PDF/A-3b'ye dönüştürür. Alternatif bir ConvertToPdfUA fonksiyonu, SaveAsPdfUA kullanarak erişim uyumluluk dönüşümünü gösterir, ancak PDF/UA, uygun yapısal etiketleme ile kaynak belgeler gerektirir.
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-format-conversion.csusing IronPdf;
using System;
using System.IO;
using System.Threading.Tasks;
using System.Threading;
string inputFolder = "originals/";
string outputFolder = "pdfa-archive/";
Directory.CreateDirectory(outputFolder);
string[] pdfFiles = Directory.GetFiles(inputFolder, "*.pdf");
Console.WriteLine($"Found {pdfFiles.Length} PDFs to convert to PDF/A-3b");
int converted = 0;
int failed = 0;
var options = new ParallelOptions
{
MaxDegreeOfParallelism = Environment.ProcessorCount / 2
};
Parallel.ForEach(pdfFiles, options, pdfFile =>
{
string fileName = Path.GetFileName(pdfFile);
string outputPath = Path.Combine(outputFolder, fileName);
try
{
using var pdf = PdfDocument.FromFile(pdfFile);
// Convert to PDF/A-3b for long-term archival
pdf.SaveAsPdfA(outputPath, PdfAVersions.PdfA3b);
Interlocked.Increment(ref converted);
Console.WriteLine($"[OK] {fileName} → PDF/A-3b");
}
catch (Exception ex)
{
Interlocked.Increment(ref failed);
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}");
}
});
Console.WriteLine($"\nConversion complete: {converted} succeeded, {failed} failed");
// Alternative: Convert to PDF/UA for accessibility compliance
void ConvertToPdfUA(string inputFolder, string outputFolder)
{
Directory.CreateDirectory(outputFolder);
string[] files = Directory.GetFiles(inputFolder, "*.pdf");
Parallel.ForEach(files, pdfFile =>
{
string fileName = Path.GetFileName(pdfFile);
try
{
using var pdf = PdfDocument.FromFile(pdfFile);
// PDF/UA requires proper tagging - ensure source is well-structured
pdf.SaveAsPdfUA(Path.Combine(outputFolder, fileName));
Console.WriteLine($"[OK] {fileName} → PDF/UA");
}
catch (Exception ex)
{
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}");
}
});
}Imports IronPdf
Imports System
Imports System.IO
Imports System.Threading.Tasks
Imports System.Threading
Module Program
Sub Main()
Dim inputFolder As String = "originals/"
Dim outputFolder As String = "pdfa-archive/"
Directory.CreateDirectory(outputFolder)
Dim pdfFiles As String() = Directory.GetFiles(inputFolder, "*.pdf")
Console.WriteLine($"Found {pdfFiles.Length} PDFs to convert to PDF/A-3b")
Dim converted As Integer = 0
Dim failed As Integer = 0
Dim options As New ParallelOptions With {
.MaxDegreeOfParallelism = Environment.ProcessorCount \ 2
}
Parallel.ForEach(pdfFiles, options, Sub(pdfFile)
Dim fileName As String = Path.GetFileName(pdfFile)
Dim outputPath As String = Path.Combine(outputFolder, fileName)
Try
Using pdf = PdfDocument.FromFile(pdfFile)
' Convert to PDF/A-3b for long-term archival
pdf.SaveAsPdfA(outputPath, PdfAVersions.PdfA3b)
Interlocked.Increment(converted)
Console.WriteLine($"[OK] {fileName} → PDF/A-3b")
End Using
Catch ex As Exception
Interlocked.Increment(failed)
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}")
End Try
End Sub)
Console.WriteLine($"{vbCrLf}Conversion complete: {converted} succeeded, {failed} failed")
End Sub
' Alternative: Convert to PDF/UA for accessibility compliance
Sub ConvertToPdfUA(inputFolder As String, outputFolder As String)
Directory.CreateDirectory(outputFolder)
Dim files As String() = Directory.GetFiles(inputFolder, "*.pdf")
Parallel.ForEach(files, Sub(pdfFile)
Dim fileName As String = Path.GetFileName(pdfFile)
Try
Using pdf = PdfDocument.FromFile(pdfFile)
' PDF/UA requires proper tagging - ensure source is well-structured
pdf.SaveAsPdfUA(Path.Combine(outputFolder, fileName))
Console.WriteLine($"[OK] {fileName} → PDF/UA")
End Using
Catch ex As Exception
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}")
End Try
End Sub)
End Sub
End ModuleÇıktı
Çıktı PDF görsel olarak bayt için bayt aynıdır ancak artık arşiv sistemleri için PDF/A-3b uyum metadata'sı taşır.
Biçim dönüşümü, belirli bir düzenleyici standardı karşılamadığı tespit edilen mevcut arşiv için uyum iyileştirme projeleri açısından özellikle önemlidir. Toplu model basittir, ancak değerlendirme adımı kritiktir — dönüştürülen her dosyanın gerçekten uyum kontrolünden geçtiğini doğrulamadan tamamlandığını kabul etmeyin. Değerlendirme konusunu, aşağıda direnç bölümünde detaylı olarak ele alacağız.
Dirençli Toplu İş Boru Hatları Oluşturma
İşlenen 100 dosyada sorunsuz çalışan ve 50.000 dosya arasında #4,327 numaralı dosyada çöken bir toplu iş boru hattı kullanılabilir değildir. Direnç — hataları zarifçe ele alabilme, geçici hataları yeniden deneme ve çökmelerin ardından devam etme kapasitesi — üretim seviyesinde bir boru hattını prototipten ayıran şeydir.
Hata İşleme ve Başarısızlıkta Atlamak
En temel direnç deseni başarısızlıkta atlamaktır: tek bir dosya işlenmezse hatayı kaydedin ve tüm toplu işlemi iptal etmek yerine bir sonraki dosyaya devam edin. Bu bariz gibi görünse de, Parallel.ForEach kullanıyorsanız gözden kaçırılması şaşırtıcı derecede kolaydır — paralel bir görevde işlenmeyen bir istisna AggregateException olarak yayılacak ve döngüyü sona erdirecektir.
Aşağıdaki örnek, hem başarısızlıkta atlamayı hem de yeniden deneme mantığını birlikte gösterir — her dosyayı zarif hata yönetimi için bir try-catch içine alarak, IOException ve OutOfMemoryException gibi geçici istisnalara karşılı iç kelepir bir döngü ile kullanarak üssel gecikme ile yeniden deneme döngüsü yapar.
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-error-handling-retry.csusing IronPdf;
using System;
using System.IO;
using System.Threading.Tasks;
using System.Threading;
using System.Collections.Concurrent;
string inputFolder = "input/";
string outputFolder = "output/";
string errorLogPath = "error-log.txt";
Directory.CreateDirectory(outputFolder);
string[] htmlFiles = Directory.GetFiles(inputFolder, "*.html");
var renderer = new ChromePdfRenderer();
var errorLog = new ConcurrentBag<string>();
int processed = 0;
int failed = 0;
int retried = 0;
const int maxRetries = 3;
var options = new ParallelOptions
{
MaxDegreeOfParallelism = Environment.ProcessorCount / 2
};
Parallel.ForEach(htmlFiles, options, htmlFile =>
{
string fileName = Path.GetFileNameWithoutExtension(htmlFile);
string outputPath = Path.Combine(outputFolder, $"{fileName}.pdf");
int attempt = 0;
bool success = false;
while (attempt < maxRetries && !success)
{
attempt++;
try
{
using var pdf = renderer.RenderHtmlFileAsPdf(htmlFile);
pdf.SaveAs(outputPath);
success = true;
Interlocked.Increment(ref processed);
if (attempt > 1)
{
Interlocked.Increment(ref retried);
Console.WriteLine($"[OK] {fileName}.pdf (succeeded on attempt {attempt})");
}
else
{
Console.WriteLine($"[OK] {fileName}.pdf");
}
}
catch (Exception ex) when (IsTransientException(ex) && attempt < maxRetries)
{
// Transient error - wait and retry with exponential backoff
int delayMs = (int)Math.Pow(2, attempt) * 500;
Console.WriteLine($"[RETRY] {fileName}: {ex.Message} (attempt {attempt}, waiting {delayMs}ms)");
Thread.Sleep(delayMs);
}
catch (Exception ex)
{
// Non-transient error or max retries exceeded
Interlocked.Increment(ref failed);
string errorMessage = $"{DateTime.Now:yyyy-MM-dd HH:mm:ss} | {fileName} | {ex.GetType().Name} | {ex.Message}";
errorLog.Add(errorMessage);
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}");
}
}
});
// Write error log
if (errorLog.Count > 0)
{
File.WriteAllLines(errorLogPath, errorLog);
}
Console.WriteLine($"\nBatch complete:");
Console.WriteLine($" Processed: {processed}");
Console.WriteLine($" Failed: {failed}");
Console.WriteLine($" Retried: {retried}");
if (failed > 0)
{
Console.WriteLine($" Error log: {errorLogPath}");
}
// Helper to identify transient exceptions worth retrying
bool IsTransientException(Exception ex)
{
return ex is IOException ||
ex is OutOfMemoryException ||
ex.Message.Contains("timeout", StringComparison.OrdinalIgnoreCase) ||
ex.Message.Contains("locked", StringComparison.OrdinalIgnoreCase);
}Imports IronPdf
Imports System
Imports System.IO
Imports System.Threading
Imports System.Collections.Concurrent
Module Program
Sub Main()
Dim inputFolder As String = "input/"
Dim outputFolder As String = "output/"
Dim errorLogPath As String = "error-log.txt"
Directory.CreateDirectory(outputFolder)
Dim htmlFiles As String() = Directory.GetFiles(inputFolder, "*.html")
Dim renderer As New ChromePdfRenderer()
Dim errorLog As New ConcurrentBag(Of String)()
Dim processed As Integer = 0
Dim failed As Integer = 0
Dim retried As Integer = 0
Const maxRetries As Integer = 3
Dim options As New ParallelOptions With {
.MaxDegreeOfParallelism = Environment.ProcessorCount \ 2
}
Parallel.ForEach(htmlFiles, options, Sub(htmlFile)
Dim fileName As String = Path.GetFileNameWithoutExtension(htmlFile)
Dim outputPath As String = Path.Combine(outputFolder, $"{fileName}.pdf")
Dim attempt As Integer = 0
Dim success As Boolean = False
While attempt < maxRetries AndAlso Not success
attempt += 1
Try
Using pdf = renderer.RenderHtmlFileAsPdf(htmlFile)
pdf.SaveAs(outputPath)
success = True
Interlocked.Increment(processed)
If attempt > 1 Then
Interlocked.Increment(retried)
Console.WriteLine($"[OK] {fileName}.pdf (succeeded on attempt {attempt})")
Else
Console.WriteLine($"[OK] {fileName}.pdf")
End If
End Using
Catch ex As Exception When IsTransientException(ex) AndAlso attempt < maxRetries
' Transient error - wait and retry with exponential backoff
Dim delayMs As Integer = CInt(Math.Pow(2, attempt)) * 500
Console.WriteLine($"[RETRY] {fileName}: {ex.Message} (attempt {attempt}, waiting {delayMs}ms)")
Thread.Sleep(delayMs)
Catch ex As Exception
' Non-transient error or max retries exceeded
Interlocked.Increment(failed)
Dim errorMessage As String = $"{DateTime.Now:yyyy-MM-dd HH:mm:ss} | {fileName} | {ex.GetType().Name} | {ex.Message}"
errorLog.Add(errorMessage)
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}")
End Try
End While
End Sub)
' Write error log
If errorLog.Count > 0 Then
File.WriteAllLines(errorLogPath, errorLog)
End If
Console.WriteLine($"{vbCrLf}Batch complete:")
Console.WriteLine($" Processed: {processed}")
Console.WriteLine($" Failed: {failed}")
Console.WriteLine($" Retried: {retried}")
If failed > 0 Then
Console.WriteLine($" Error log: {errorLogPath}")
End If
End Sub
' Helper to identify transient exceptions worth retrying
Function IsTransientException(ex As Exception) As Boolean
Return TypeOf ex Is IOException OrElse
TypeOf ex Is OutOfMemoryException OrElse
ex.Message.Contains("timeout", StringComparison.OrdinalIgnoreCase) OrElse
ex.Message.Contains("locked", StringComparison.OrdinalIgnoreCase)
End Function
End ModuleToplu işlem tamamlandıktan sonra, hangi dosyaların başarısız olduğunu ve nedenini anlamak için hata kaydını gözden geçirin. Yaygın hata nedenleri arasında bozuk kaynak dosyalar, parola korumalı PDF'ler, kaynak içeriğinde desteklenmeyen özellikler ve çok büyük belgeler üzerinde bellek yetersizliği gibi nedenler bulunur.
Geçici Hatalar İçin Geri Deneme Mantığı
Bazı hatalar geçicidir — tekrar denerseniz başarılı olurlar. Bunlar arasında dosya sistemi içeriği (başka bir işlem dosyayı kilitlemiş), geçici bellek baskısı (GC henüz günümüze yetişmedi) ve HTML içeriğini yüklerken harici kaynaklarda ağ zaman aşımı gibi durumlar bulunur. Yukarıdaki kod örneğinde bunlar, kısa bir gecikme ile başlayarak ve her yeniden deneme denemesinde ikiye katlayarak üstel geri tepme ile işlenir, maksimum retry sayısında sınırlanır (genellikle 3).
Anahtar, yeniden denenebilir ve yeniden denenemez hatalar arasında ayrım yapabilme yeteneğidir. IOException (dosya kilitli) veya OutOfMemoryException (geçici baskı) yeniden denemeye değerdir. ArgumentException (geçersiz giriş) veya tutarlı bir render hatası değildir — yeniden deneme yardımcı olmaz ve zaman ve kaynak israf edersiniz.
Çökmelerden Sonra Devam İçin Kontrol Noktası Oluşturma
Bir toplu iş, birkaç saat içinde 50.000 dosya işlerken, #35.000 numaralı dosyada bir çökme başlamayı yeniden başlatmamalıdır. Kontrol noktası oluşturma — hangi dosyaların başarıyla işlendiğini kaydetmek — kaldığınız yerden devam etmenizi sağlar.
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-checkpointing.csusing IronPdf;
using System;
using System.IO;
using System.Linq;
using System.Threading.Tasks;
using System.Threading;
using System.Collections.Generic;
string inputFolder = "input/";
string outputFolder = "output/";
string checkpointPath = "checkpoint.txt";
string errorLogPath = "errors.txt";
Directory.CreateDirectory(outputFolder);
// Load checkpoint - files already processed successfully
var completedFiles = new HashSet<string>();
if (File.Exists(checkpointPath))
{
completedFiles = new HashSet<string>(File.ReadAllLines(checkpointPath));
Console.WriteLine($"Resuming from checkpoint: {completedFiles.Count} files already processed");
}
// Get files to process (excluding already completed)
string[] allFiles = Directory.GetFiles(inputFolder, "*.html");
string[] filesToProcess = allFiles
.Where(f => !completedFiles.Contains(Path.GetFileName(f)))
.ToArray();
Console.WriteLine($"Files to process: {filesToProcess.Length} (skipping {completedFiles.Count} already done)");
var renderer = new ChromePdfRenderer();
var checkpointLock = new object();
int processed = 0;
int failed = 0;
var options = new ParallelOptions
{
MaxDegreeOfParallelism = Environment.ProcessorCount / 2
};
Parallel.ForEach(filesToProcess, options, htmlFile =>
{
string fileName = Path.GetFileName(htmlFile);
string baseName = Path.GetFileNameWithoutExtension(htmlFile);
string outputPath = Path.Combine(outputFolder, $"{baseName}.pdf");
try
{
using var pdf = renderer.RenderHtmlFileAsPdf(htmlFile);
pdf.SaveAs(outputPath);
// Record success in checkpoint (thread-safe)
lock (checkpointLock)
{
File.AppendAllText(checkpointPath, fileName + Environment.NewLine);
}
Interlocked.Increment(ref processed);
Console.WriteLine($"[OK] {baseName}.pdf");
}
catch (Exception ex)
{
Interlocked.Increment(ref failed);
// Log error for review
lock (checkpointLock)
{
File.AppendAllText(errorLogPath,
$"{DateTime.Now:yyyy-MM-dd HH:mm:ss} | {fileName} | {ex.Message}{Environment.NewLine}");
}
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}");
}
});
Console.WriteLine($"\nBatch complete:");
Console.WriteLine($" Newly processed: {processed}");
Console.WriteLine($" Failed: {failed}");
Console.WriteLine($" Total completed: {completedFiles.Count + processed}");
Console.WriteLine($" Checkpoint saved to: {checkpointPath}");Imports IronPdf
Imports System
Imports System.IO
Imports System.Linq
Imports System.Threading.Tasks
Imports System.Threading
Imports System.Collections.Generic
Module Program
Sub Main()
Dim inputFolder As String = "input/"
Dim outputFolder As String = "output/"
Dim checkpointPath As String = "checkpoint.txt"
Dim errorLogPath As String = "errors.txt"
Directory.CreateDirectory(outputFolder)
' Load checkpoint - files already processed successfully
Dim completedFiles As New HashSet(Of String)()
If File.Exists(checkpointPath) Then
completedFiles = New HashSet(Of String)(File.ReadAllLines(checkpointPath))
Console.WriteLine($"Resuming from checkpoint: {completedFiles.Count} files already processed")
End If
' Get files to process (excluding already completed)
Dim allFiles As String() = Directory.GetFiles(inputFolder, "*.html")
Dim filesToProcess As String() = allFiles _
.Where(Function(f) Not completedFiles.Contains(Path.GetFileName(f))) _
.ToArray()
Console.WriteLine($"Files to process: {filesToProcess.Length} (skipping {completedFiles.Count} already done)")
Dim renderer As New ChromePdfRenderer()
Dim checkpointLock As New Object()
Dim processed As Integer = 0
Dim failed As Integer = 0
Dim options As New ParallelOptions With {
.MaxDegreeOfParallelism = Environment.ProcessorCount \ 2
}
Parallel.ForEach(filesToProcess, options, Sub(htmlFile)
Dim fileName As String = Path.GetFileName(htmlFile)
Dim baseName As String = Path.GetFileNameWithoutExtension(htmlFile)
Dim outputPath As String = Path.Combine(outputFolder, $"{baseName}.pdf")
Try
Using pdf = renderer.RenderHtmlFileAsPdf(htmlFile)
pdf.SaveAs(outputPath)
End Using
' Record success in checkpoint (thread-safe)
SyncLock checkpointLock
File.AppendAllText(checkpointPath, fileName & Environment.NewLine)
End SyncLock
Interlocked.Increment(processed)
Console.WriteLine($"[OK] {baseName}.pdf")
Catch ex As Exception
Interlocked.Increment(failed)
' Log error for review
SyncLock checkpointLock
File.AppendAllText(errorLogPath,
$"{DateTime.Now:yyyy-MM-dd HH:mm:ss} | {fileName} | {ex.Message}{Environment.NewLine}")
End SyncLock
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}")
End Try
End Sub)
Console.WriteLine(vbCrLf & "Batch complete:")
Console.WriteLine($" Newly processed: {processed}")
Console.WriteLine($" Failed: {failed}")
Console.WriteLine($" Total completed: {completedFiles.Count + processed}")
Console.WriteLine($" Checkpoint saved to: {checkpointPath}")
End Sub
End ModuleKontrol noktası dosyası, tamamlanan işin kalıcı bir kaydı gibi davranır. Boru hattı başladığında, kontrol noktası dosyasını okuy ve zaten başarıyla işlenmiş dosyaları atlar. Bir dosya işlemi tamamladığında, yolu kontrol noktası dosyasına eklenir. Bu yaklaşım basittir, dosya tabanlıdır ve herhangi bir harici bağımlılığa ihtiyaç duymaz.
Daha sofistike senaryolar için, özellikle farklı makinelerde paralel olarak dosya işleyen birden çok çalışan varsa kontrol noktası depolamanız olarak bir veritabanı tablosu veya dağıtılmış bir önbellek (Redis gibi) kullanmayı düşünün.
İşleme Öncesi ve Sonrası Değerlendirme
Değerlendirme, dirençli bir boru hattının kitaplığını oluşturur. Ön işlem değerlendirmesi, problemli girdileri işlem süresi kaybetmeden önce yakalar; işlem sonrası değerlendirme, çıktının kalite ve uyumluluk gereksinimlerinizi karşıladığından emin olur.
Girdi
Bu uygulama, hem PreValidate hem de PostValidate yardımcı işlevleri ile işleme döngüsünü sarar. Ön doğrulama dosya boyutunu, içerik türünü ve temel HTML yapısını işlemden önce kontrol eder. İşlem sonrası validasyon, çıktının geçerli sayfa sayısına sahip olduğunu ve makul dosya boyutunu doğrulayarak, doğrulanan dosyaları ayrı bir klasöre taşırken, hata verilerini manuel inceleme için bir red klasörüne yönlendirir.
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-validation.csusing IronPdf;
using System;
using System.IO;
using System.Threading.Tasks;
using System.Threading;
using System.Collections.Concurrent;
string inputFolder = "input/";
string outputFolder = "output/";
string validatedFolder = "validated/";
string rejectedFolder = "rejected/";
Directory.CreateDirectory(outputFolder);
Directory.CreateDirectory(validatedFolder);
Directory.CreateDirectory(rejectedFolder);
string[] inputFiles = Directory.GetFiles(inputFolder, "*.html");
var renderer = new ChromePdfRenderer();
int preValidationFailed = 0;
int processingFailed = 0;
int postValidationFailed = 0;
int succeeded = 0;
var options = new ParallelOptions
{
MaxDegreeOfParallelism = Environment.ProcessorCount / 2
};
Parallel.ForEach(inputFiles, options, inputFile =>
{
string fileName = Path.GetFileNameWithoutExtension(inputFile);
string outputPath = Path.Combine(outputFolder, $"{fileName}.pdf");
// Pre-validation: Check input file
if (!PreValidate(inputFile))
{
Interlocked.Increment(ref preValidationFailed);
Console.WriteLine($"[SKIP] {fileName}: Failed pre-validation");
return;
}
try
{
// Process
using var pdf = renderer.RenderHtmlFileAsPdf(inputFile);
pdf.SaveAs(outputPath);
// Post-validation: Check output file
if (PostValidate(outputPath))
{
// Move to validated folder
string validatedPath = Path.Combine(validatedFolder, $"{fileName}.pdf");
File.Move(outputPath, validatedPath, overwrite: true);
Interlocked.Increment(ref succeeded);
Console.WriteLine($"[OK] {fileName}.pdf (validated)");
}
else
{
// Move to rejected folder for manual review
string rejectedPath = Path.Combine(rejectedFolder, $"{fileName}.pdf");
File.Move(outputPath, rejectedPath, overwrite: true);
Interlocked.Increment(ref postValidationFailed);
Console.WriteLine($"[REJECT] {fileName}.pdf: Failed post-validation");
}
}
catch (Exception ex)
{
Interlocked.Increment(ref processingFailed);
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}");
}
});
Console.WriteLine($"\nValidation summary:");
Console.WriteLine($" Succeeded: {succeeded}");
Console.WriteLine($" Pre-validation failed: {preValidationFailed}");
Console.WriteLine($" Processing failed: {processingFailed}");
Console.WriteLine($" Post-validation failed: {postValidationFailed}");
// Pre-validation: Quick checks on input file
bool PreValidate(string filePath)
{
try
{
var fileInfo = new FileInfo(filePath);
// Check file exists and is readable
if (!fileInfo.Exists) return false;
// Check file is not empty
if (fileInfo.Length == 0) return false;
// Check file is not too large (e.g., 50MB limit)
if (fileInfo.Length > 50 * 1024 * 1024) return false;
// Quick content check - must be valid HTML
string content = File.ReadAllText(filePath);
if (string.IsNullOrWhiteSpace(content)) return false;
if (!content.Contains("<html", StringComparison.OrdinalIgnoreCase) &&
!content.Contains("<!DOCTYPE", StringComparison.OrdinalIgnoreCase))
{
return false;
}
return true;
}
catch
{
return false;
}
}
// Post-validation: Verify output PDF meets requirements
bool PostValidate(string pdfPath)
{
try
{
using var pdf = PdfDocument.FromFile(pdfPath);
// Check PDF has at least one page
if (pdf.PageCount < 1) return false;
// Check file size is reasonable (not just header, not corrupted)
var fileInfo = new FileInfo(pdfPath);
if (fileInfo.Length < 1024) return false;
return true;
}
catch
{
return false;
}
}Imports IronPdf
Imports System
Imports System.IO
Imports System.Threading.Tasks
Imports System.Threading
Imports System.Collections.Concurrent
Module Program
Sub Main()
Dim inputFolder As String = "input/"
Dim outputFolder As String = "output/"
Dim validatedFolder As String = "validated/"
Dim rejectedFolder As String = "rejected/"
Directory.CreateDirectory(outputFolder)
Directory.CreateDirectory(validatedFolder)
Directory.CreateDirectory(rejectedFolder)
Dim inputFiles As String() = Directory.GetFiles(inputFolder, "*.html")
Dim renderer As New ChromePdfRenderer()
Dim preValidationFailed As Integer = 0
Dim processingFailed As Integer = 0
Dim postValidationFailed As Integer = 0
Dim succeeded As Integer = 0
Dim options As New ParallelOptions With {
.MaxDegreeOfParallelism = Environment.ProcessorCount \ 2
}
Parallel.ForEach(inputFiles, options, Sub(inputFile)
Dim fileName As String = Path.GetFileNameWithoutExtension(inputFile)
Dim outputPath As String = Path.Combine(outputFolder, $"{fileName}.pdf")
' Pre-validation: Check input file
If Not PreValidate(inputFile) Then
Interlocked.Increment(preValidationFailed)
Console.WriteLine($"[SKIP] {fileName}: Failed pre-validation")
Return
End If
Try
' Process
Using pdf = renderer.RenderHtmlFileAsPdf(inputFile)
pdf.SaveAs(outputPath)
' Post-validation: Check output file
If PostValidate(outputPath) Then
' Move to validated folder
Dim validatedPath As String = Path.Combine(validatedFolder, $"{fileName}.pdf")
File.Move(outputPath, validatedPath, overwrite:=True)
Interlocked.Increment(succeeded)
Console.WriteLine($"[OK] {fileName}.pdf (validated)")
Else
' Move to rejected folder for manual review
Dim rejectedPath As String = Path.Combine(rejectedFolder, $"{fileName}.pdf")
File.Move(outputPath, rejectedPath, overwrite:=True)
Interlocked.Increment(postValidationFailed)
Console.WriteLine($"[REJECT] {fileName}.pdf: Failed post-validation")
End If
End Using
Catch ex As Exception
Interlocked.Increment(processingFailed)
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}")
End Try
End Sub)
Console.WriteLine(vbCrLf & "Validation summary:")
Console.WriteLine($" Succeeded: {succeeded}")
Console.WriteLine($" Pre-validation failed: {preValidationFailed}")
Console.WriteLine($" Processing failed: {processingFailed}")
Console.WriteLine($" Post-validation failed: {postValidationFailed}")
End Sub
' Pre-validation: Quick checks on input file
Function PreValidate(filePath As String) As Boolean
Try
Dim fileInfo As New FileInfo(filePath)
' Check file exists and is readable
If Not fileInfo.Exists Then Return False
' Check file is not empty
If fileInfo.Length = 0 Then Return False
' Check file is not too large (e.g., 50MB limit)
If fileInfo.Length > 50 * 1024 * 1024 Then Return False
' Quick content check - must be valid HTML
Dim content As String = File.ReadAllText(filePath)
If String.IsNullOrWhiteSpace(content) Then Return False
If Not content.Contains("<html", StringComparison.OrdinalIgnoreCase) AndAlso
Not content.Contains("<!DOCTYPE", StringComparison.OrdinalIgnoreCase) Then
Return False
End If
Return True
Catch
Return False
End Try
End Function
' Post-validation: Verify output PDF meets requirements
Function PostValidate(pdfPath As String) As Boolean
Try
Using pdf = PdfDocument.FromFile(pdfPath)
' Check PDF has at least one page
If pdf.PageCount < 1 Then Return False
' Check file size is reasonable (not just header, not corrupted)
Dim fileInfo As New FileInfo(pdfPath)
If fileInfo.Length < 1024 Then Return False
Return True
End Using
Catch
Return False
End Try
End Function
End ModuleÇıktı
Tüm 5 dosya doğrulamayı geçti ve doğrulanan klasöre taşındı.
Ön işleme doğrulaması hızlı olmalıdır — açıkça bozuk girdileri kontrol ediyorsunuz, tam bir işlem yapmıyorsunuz. İşlem sonrası validasyon, özellikle çıktı belirli standartları geçmesi gereken uyumluluk dönüşümleri için daha kapsamlı olabilir (PDF/A, PDF/UA). İşlem sonrası validasyonu geçemeyen herhangi bir dosya, sessizce kabul edilmek yerine manuel gözden geçirme için işaretlenmelidir.
Bu türden favori kütüphanem IronPDF'dir. PDF dosyalarının hızlı ve verimli bir şekilde işlenmesine olanak tanır. Ayrıca, PDF/A formatına dışa aktarma ve dijital imzalama gibi birçok değerli özelliğe sahiptir.
IronOCR, manuel işleme maliyetinden yıllık 40.000 USD tasarruf etmemizi sağlıyor, üretkenliği artırıyor ve yüksek etkili görevler için kaynakları serbest bırakıyor. Kesinlikle tavsiye ederim.
IronSuite, operasyonlarımızda kritik bir rol oynar. Bunlar, iş süreçlerinde verimliliği artıran, kat planları oluşturmak ve envanter yönetimini geliştirmek gibi araçlardır.
Async ve Paralel İşleme Kalıpları
IronPDF, hem Parallel.ForEach (iş parçacığı tabanlı eşzamanlılık) hem de async/await (asenkron I/O) destekler. Her birinin ne zaman kullanılacağını ve bunların nasıl etkili bir şekilde birleştirileceğinin anlaşılması, verimliliği artırmak için anahtardır.
Görev Paralel Kütüphane Entegrasyonu
Parallel.ForEach CPU tabanlı toplu işlemler için en basit ve en etkili yaklaşımdır. IronPDF'in işleme motoru CPU-yoğundur (HTML ayrıştırma, CSS yerleşimi, görüntü rastalizasyonu) ve Parallel.ForEach bu işi tüm mevcut çekirdekler arasında otomatik olarak dağıtır.
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-tpl.csusing IronPdf;
using System;
using System.IO;
using System.Threading.Tasks;
using System.Threading;
using System.Diagnostics;
string inputFolder = "input/";
string outputFolder = "output/";
Directory.CreateDirectory(outputFolder);
string[] htmlFiles = Directory.GetFiles(inputFolder, "*.html");
var renderer = new ChromePdfRenderer();
Console.WriteLine($"Processing {htmlFiles.Length} files with {Environment.ProcessorCount} CPU cores");
int processed = 0;
var stopwatch = Stopwatch.StartNew();
// Configure parallelism based on system resources
// Rule of thumb: ProcessorCount / 2 for memory-intensive operations
var options = new ParallelOptions
{
MaxDegreeOfParallelism = Math.Max(1, Environment.ProcessorCount / 2)
};
Console.WriteLine($"Max parallelism: {options.MaxDegreeOfParallelism}");
// Use Parallel.ForEach for CPU-bound batch operations
Parallel.ForEach(htmlFiles, options, htmlFile =>
{
string fileName = Path.GetFileNameWithoutExtension(htmlFile);
string outputPath = Path.Combine(outputFolder, $"{fileName}.pdf");
try
{
// Render HTML to PDF
using var pdf = renderer.RenderHtmlFileAsPdf(htmlFile);
pdf.SaveAs(outputPath);
int current = Interlocked.Increment(ref processed);
// Progress reporting every 10 files
if (current % 10 == 0)
{
double elapsed = stopwatch.Elapsed.TotalSeconds;
double rate = current / elapsed;
double remaining = (htmlFiles.Length - current) / rate;
Console.WriteLine($"Progress: {current}/{htmlFiles.Length} ({rate:F1} files/sec, ~{remaining:F0}s remaining)");
}
}
catch (Exception ex)
{
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}");
}
});
stopwatch.Stop();
double totalRate = processed / stopwatch.Elapsed.TotalSeconds;
Console.WriteLine($"\nComplete:");
Console.WriteLine($" Files processed: {processed}/{htmlFiles.Length}");
Console.WriteLine($" Total time: {stopwatch.Elapsed.TotalSeconds:F1}s");
Console.WriteLine($" Average rate: {totalRate:F1} files/sec");
Console.WriteLine($" Time per file: {stopwatch.Elapsed.TotalMilliseconds / processed:F0}ms");
// Memory monitoring helper (call between chunks for large batches)
void CheckMemoryPressure()
{
const long memoryThreshold = 4L * 1024 * 1024 * 1024; // 4 GB
long currentMemory = GC.GetTotalMemory(forceFullCollection: false);
if (currentMemory > memoryThreshold)
{
Console.WriteLine($"Memory pressure detected ({currentMemory / 1024 / 1024}MB), forcing GC...");
GC.Collect();
GC.WaitForPendingFinalizers();
GC.Collect();
}
}Imports IronPdf
Imports System
Imports System.IO
Imports System.Threading.Tasks
Imports System.Threading
Imports System.Diagnostics
Module Program
Sub Main()
Dim inputFolder As String = "input/"
Dim outputFolder As String = "output/"
Directory.CreateDirectory(outputFolder)
Dim htmlFiles As String() = Directory.GetFiles(inputFolder, "*.html")
Dim renderer As New ChromePdfRenderer()
Console.WriteLine($"Processing {htmlFiles.Length} files with {Environment.ProcessorCount} CPU cores")
Dim processed As Integer = 0
Dim stopwatch As Stopwatch = Stopwatch.StartNew()
' Configure parallelism based on system resources
' Rule of thumb: ProcessorCount / 2 for memory-intensive operations
Dim options As New ParallelOptions With {
.MaxDegreeOfParallelism = Math.Max(1, Environment.ProcessorCount \ 2)
}
Console.WriteLine($"Max parallelism: {options.MaxDegreeOfParallelism}")
' Use Parallel.ForEach for CPU-bound batch operations
Parallel.ForEach(htmlFiles, options, Sub(htmlFile)
Dim fileName As String = Path.GetFileNameWithoutExtension(htmlFile)
Dim outputPath As String = Path.Combine(outputFolder, $"{fileName}.pdf")
Try
' Render HTML to PDF
Using pdf = renderer.RenderHtmlFileAsPdf(htmlFile)
pdf.SaveAs(outputPath)
End Using
Dim current As Integer = Interlocked.Increment(processed)
' Progress reporting every 10 files
If current Mod 10 = 0 Then
Dim elapsed As Double = stopwatch.Elapsed.TotalSeconds
Dim rate As Double = current / elapsed
Dim remaining As Double = (htmlFiles.Length - current) / rate
Console.WriteLine($"Progress: {current}/{htmlFiles.Length} ({rate:F1} files/sec, ~{remaining:F0}s remaining)")
End If
Catch ex As Exception
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}")
End Try
End Sub)
stopwatch.Stop()
Dim totalRate As Double = processed / stopwatch.Elapsed.TotalSeconds
Console.WriteLine(vbCrLf & "Complete:")
Console.WriteLine($" Files processed: {processed}/{htmlFiles.Length}")
Console.WriteLine($" Total time: {stopwatch.Elapsed.TotalSeconds:F1}s")
Console.WriteLine($" Average rate: {totalRate:F1} files/sec")
Console.WriteLine($" Time per file: {stopwatch.Elapsed.TotalMilliseconds / processed:F0}ms")
' Memory monitoring helper (call between chunks for large batches)
CheckMemoryPressure()
End Sub
Sub CheckMemoryPressure()
Const memoryThreshold As Long = 4L * 1024 * 1024 * 1024 ' 4 GB
Dim currentMemory As Long = GC.GetTotalMemory(forceFullCollection:=False)
If currentMemory > memoryThreshold Then
Console.WriteLine($"Memory pressure detected ({currentMemory \ 1024 \ 1024}MB), forcing GC...")
GC.Collect()
GC.WaitForPendingFinalizers()
GC.Collect()
End If
End Sub
End ModuleMaxDegreeOfParallelism seçeneği kritiktir. Olmadan, TPL mevcut tüm çekirdekleri kullanmaya çalışacaktır, ki bu her işleme kaynak yoğunsa bellek yetersizliğine neden olabilir. Sisteminize ait kullanılabilir RAM'i genellikle işleme başına tipik bellek tüketimiyle bölen (genellikle karmaşık HTML için eşzamanlı işleme başına 100–300 MB) ayarlayın.
Eşzamanlılık Kontrolü (SemaphoreSlim)
Parallel.ForEach sağladığından daha ince eşzamanlılık kontrolüne ihtiyacınız olduğunda — örneğin, async I/O'yu CPU tabanlı render ile birleştirdiğinizde — SemaphoreSlim aynı anda kaç işlem çalışacağını açıkça kontrol etme imkanı sağlar. Desen basittir: İstediğiniz eşzamanlılık limitine sahip bir SemaphoreSlim oluşturun (örneğin, 4 eşzamanlı render), her bir render öncesinde WaitAsync çağırılacak ve ardından Release bir finally bloğunda çağırılacak. Daha sonra tüm görevleri Task.WhenAll ile başlatın.
Bu desen, boru hattınızın hem blob depolamadan dosyaları okuyan, hem de bir veritabanına sonuçları yazan I/O bağlı adımları ve CPU-bağlı adımları (PDF işleme) içeriğinde özellikle kullanışlıdır. Semafor, CPU-bağlı işleme eşzamanlılığını sınırlandırırken I/O-bağlı adımların kısıtlama olmaksızın ilerlemesine izin verir.
Async/Await En İyi Uygulamalar
IronPDF, işleme yöntemlerinin asenkron varyantlarını sağlar, RenderHtmlAsPdfAsync, RenderUrlAsPdfAsync ve RenderHtmlFileAsPdfAsync dahil. Bunlar, web uygulamaları için (istek iş parçacığını engellemek kabul edilemez) ve PDF işleme ile async I/O işlemlerini karıştıran boru hatları için idealdir.
Toplu işleme için birkaç önemli async en iyi uygulaması:
Sync IronPDF yöntemlerini sarmalamak için Task.Run kullanmayın — Yerel async varyantları kullanın. Sync yöntemlerini Task.Run ile sarmalamak, bir iş parçacığı ziyafeti daha fazla ekler ve herhangi bir yarar sağlamadan yük ekler.
Asenkron görevlere .Result veya .Wait() kullanmayın — Bu, çağırma iş parçacığını engeller ve UI veya ASP.NET bağlamlarında kilitlenmelere neden olabilir. Her zaman await kullanın.
Task.WhenAll çağrılarınızı toplu hale getirin yerine tüm görevleri bir kerede bekleyin. 10.000 göreviniz varsa ve hepsine Task.WhenAll çağrısı yaparsanız, 10.000 eşzamanlı işlem başlatırsınız. Bunun yerine, bunları gruplar halinde işlemek ve her grubu sırasıyla bekleyin geçirmek için .Chunk(10) veya benzeri bir yaklaşımı kullanın.
Bellek Tükenmesini Önlemek
Bellek tükenmesi, toplu PDF işleminde en yaygın hata modudur. Savunma yaklaşımı, her işlem öncesinde GC.GetTotalMemory() ile bellek kullanımını izlemek ve tüketim bir eşik değere (örneğin 4 GB veya mevcut RAM'in %80'i) geçtiğinde bir toplama başlatmaktır. Birinci çağrı GC.Collect() ardından GC.WaitForPendingFinalizers() ve devamında mümkün olan en fazla belleği geri kazanmak için ikinci bir GC.Collect() çağrısı yaparak devam edin. Bu, küçük bir duraklama ekler ancak #30.000 numaralı dosyada tüm toplu işinizin çökmesine neden olan bir OutOfMemoryException felaket alternatifini önler.
Bunu, TPL bölümünden MaxDegreeOfParallelism kısıtlama ile bir araya getirin ve bellek yönetimi bölümünden using boşaltma kalıbı ile bir araya getirin, ve bellek sorunlarına karşı üç katmanlı bir savunma: eşzamanlı sayısını sınırlayın, agresif bir şekilde boşaltın ve güvenlik valfi ile izleyin.
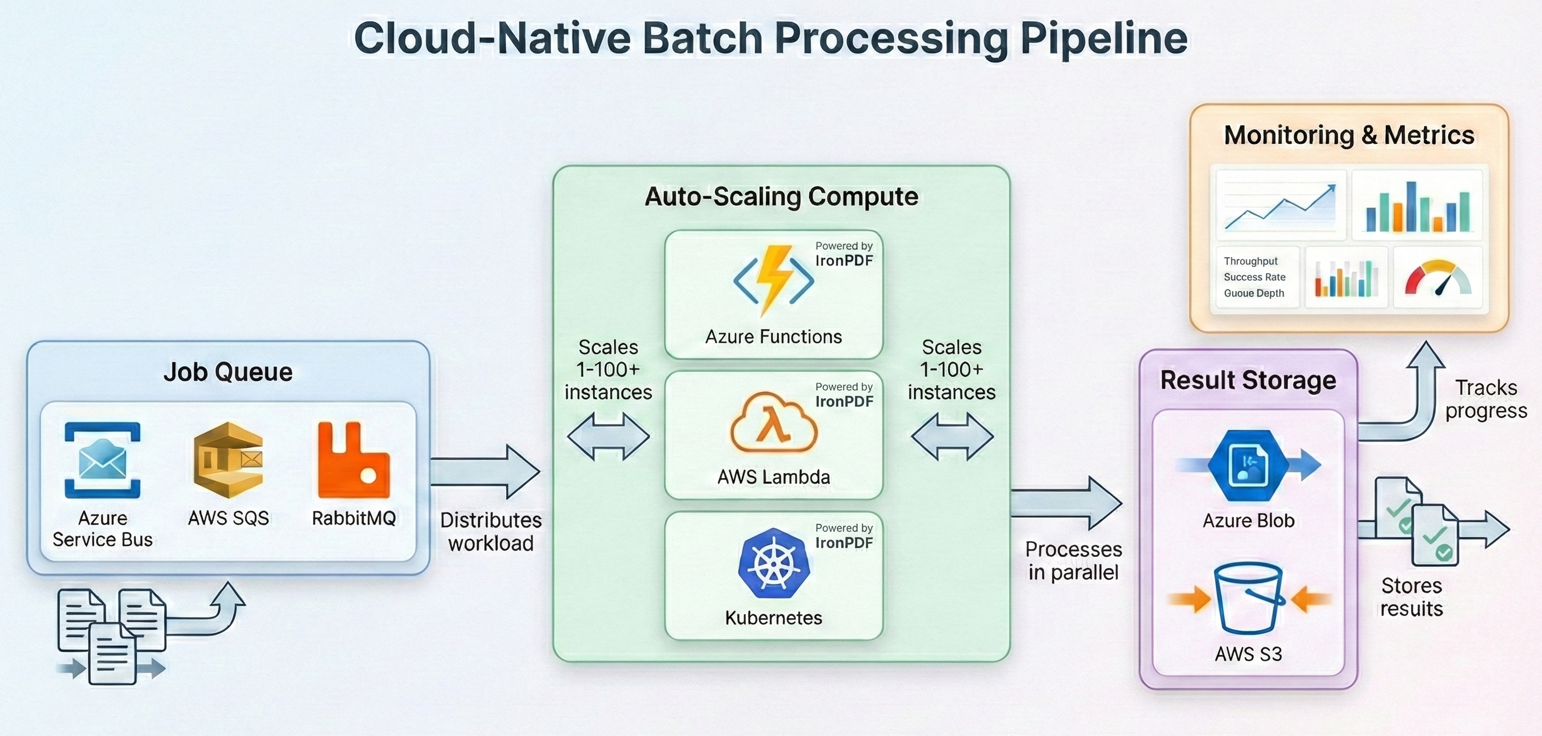
Toplu İşler İçin Bulut Dağıtımı
Modern toplu işleme giderek bulutta çalışır, burada iş yükü taleplerine uymak için hesaplama kaynaklarını ölçeklendirebilir ve sadece kullandığınız kadar ödersiniz. IronPDF, tüm büyük bulut platformlarında çalışır — işte her biri için toplu iş boru hatlarını nasıl tasarlayacağınız.
Azure Fonksiyonları ve Dayanıklı Fonksiyonlar
Azure Dayanıklı Fonksiyonlar, fan-out/fan-in desenleri için yerleşik düzenleme sağlar ve bu nedenle toplu PDF işlemi için doğal bir uyum sağlar. Orkestra fonksiyonu, her biri dosyaların bir alt kümesini işleyen birçok etkinlik fonksiyonu örneği arasında çalışmayı dağıtır. Orchestrator'unuz, fan-out döngüsünde CallActivityAsync çağırır, her bir etkinlik işlevi bir ChromePdfRenderer oluşturur, kendi dosya parçasını işler ve orchestrator sonuçları toplar.
Azure Fonksiyonları için anahtar dikkate alınacaklar: varsayılan tüketim planının işlev daveti başına 5 dakikalık bir zaman aşımı ve sınırlı bellek vardır. Toplu işleme için, daha uzun zaman aşımlarını ve daha fazla belleği destekleyen Premium veya Dedicated planını kullanın. IronPDF tam .NET çalışma zamanını (kırpılmış değil) gerektirir, bu yüzden işlev uygulamanızın uygun çalışma zamanı tanımlayıcısıyla .NET 8+ için yapılandırıldığından emin olun.
AWS Lambda ve Adım İşlevleri
AWS Adım İşlevleri, Azure Dayanıklı Fonksiyonlar'a benzer bir düzenleme yeteneği sağlar. Durum makinesindeki her adım, dosyaların bir kısmını işleyen bir Lambda fonksiyonu çağırır. Lambda işleyiciniz bir S3 nesne anahtarı partisi alır, her PDF'i PdfDocument.FromFile ile yükler, işleme hattınızı (sıkıştırma, format dönüştürme vb.) uygular ve sonuçları bir çıkış S3 kovasına yazar.
AWS Lambda'nın maksimum 15 dakikalık çalışma süresi ve sınırlı /tmp saklaması vardır (varsayılan olarak 512 MB, 10 GB'a kadar yapılandırılabilir). Büyük toplu işleri için, iş yükünü bölebilmek ve her parçayı ayrı bir Lambda çağrısında işlemek için Adım İşlevlerini kullanın. Yerel depolama yerine ara sonuçları S3'te saklayın.
Kubernetes İş Zamanlaması
Kendi Kubernetes kümelerini işleten kuruluşlar için toplu PDF işleme, Kubernetes İşleri ve Kron İşlerine iyi bir şekilde uyum sağlar. Her pod, bir kuyruktan dosyaları çeken bir toplu işçi çalıştırır (Azure Service Bus, RabbitMQ veya SQS), IronPDF ile işler ve sonuçları nesne depolamaya yazar. İşçi döngüsü önceki bölümlerde ele alınan aynı modeli takip eder: bir mesajı kuyruktan çıkarın, dosyayı işlemek için ChromePdfRenderer.RenderHtmlAsPdf() veya PdfDocument.FromFile() kullanın, sonucu yükleyin ve mesajı onaylayın. İşlemeyi, try-catch içindeki dayanıklılık desenlerinden yeniden deneme mantığıyla sarın ve her pod için eşzamanlı sayısını kontrol etmek SemaphoreSlim kullanın.
IronPDF, resmi Docker desteği sağlar ve Linux konteynerlerinde çalışır. Konteynerinizin OS'sine uygun yerel çalışma zamanı paketleriyle IronPdf NuGet paketi kullanın (örneğin, Linux tabanlı görüntüler için IronPdf.Linux). Kubernetes için, IronPDF'nin bellek gereksinimlerini karşılayan kaynak istekleri ve sınırlarını tanımlayın (genellikle eşzamanlılığa bağlı olarak pod başına 512 MB–2 GB). Yatay Pod Otomatik Ölçekleyici, iş kuyruğu derinliğine bağlı olarak işçileri ölçeklendirebilir ve check ifadeleri deseni, podların boşaltılması durumunda hiçbir işin kaybolmadığını garanti eder.
Maliyet Optimizasyonu Stratejileri
Bulut toplu işlem, kaynak tahsisini düşünceli bir şekilde yapmazsanız pahalı hale gelebilir. En büyük etkisi olan stratejiler şunlardır:
Compute'unuzu doğru boyutlandırın. PDF işleme CPU ve bellek açısından yoğundur, GPU açısından değil. Genel amaçlı veya bellek optimize edilmiş yerine hesaplama optimize edilmiş örnekler (Azure'da C-serisi, AWS'de C-tipi) kullanın. Daha iyi fiyat-başına-rende oranları alacaksınız.
Kısa/öncelikli örnekler kullanın kesinti toleransı gösteren toplu iş yükleri için. Toplu PDF işleme inherent derecede devam edebilir (checkpointing sayesinde), bu da genellikle talep üzerine %60–90 indirim sağlayan alan fiyatlaması için ideal bir aday yapar.
Yüksek trafiğin dışındaki saatlerde işleyin zaman çerçeveniz izin verirse. Birçok bulut sağlayıcısı, geceleri ve hafta sonlarında daha düşük fiyatlar veya daha yüksek yer yerleşimi kullanılabilirliği sunar.
Erken sıkıştırma, bir kez depolayın. İşleme hattınızın bir parçası olarak, ayrı bir adım yerine sıkıştırma çalıştırın. Başlangıçtan itibaren sıkıştırılmış PDF'leri depolamak, arşiv ömrü boyunca sürekli indirme maliyetlerini azaltır.
Saklamanızı katmanlara bölün. Sık erişilen işlenmiş PDF'ler sıcak depolamaya gitmelidir; nadiren erişilen arşivlenmiş PDF'ler ise soğuk veya arşiv katmanlarına (Azure Cool/Archive, AWS S3 Glacier) taşınmalıdır. Bu tek başına depolama maliyetlerini %50-80 oranında azaltabilir.
Gerçek Dünya Boru Hattı Örneği
Her şeyi bir araya getirip, Ingest → Validate → Process → Archive → Report tam iş akışı gösteren eksiksiz, üretim seviyesinde bir toplu boru hattı örneği verelim.
Bu örnek, bir dizin dolusu HTML fatura şablonunu işler, bunları PDF'e dönüştürür, çıktıyı sıkıştırır, arşiv uyumluluğu için PDF/A-3b'ye dönüştürür, sonucu doğrular ve sonunda bir özet raporu üretir.
Yukarıdaki toplu dönüştürme örneğinden aynı 5 HTML faturasını kullanarak...
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-full-pipeline.csusing IronPdf;
using System;
using System.Collections.Generic;
using System.IO;
using System.Linq;
using System.Threading.Tasks;
using System.Threading;
using System.Collections.Concurrent;
using System.Diagnostics;
using System.Text.Json;
// Configuration
var config = new PipelineConfig
{
InputFolder = "input/",
OutputFolder = "output/",
ArchiveFolder = "archive/",
ErrorFolder = "errors/",
CheckpointPath = "pipeline-checkpoint.json",
ReportPath = "pipeline-report.json",
MaxConcurrency = Math.Max(1, Environment.ProcessorCount / 2),
MaxRetries = 3,
JpegQuality = 70
};
// Initialize folders
Directory.CreateDirectory(config.OutputFolder);
Directory.CreateDirectory(config.ArchiveFolder);
Directory.CreateDirectory(config.ErrorFolder);
// Load checkpoint for resume capability
var checkpoint = LoadCheckpoint(config.CheckpointPath);
var results = new ConcurrentBag<ProcessingResult>();
var stopwatch = Stopwatch.StartNew();
// Get files to process
string[] allFiles = Directory.GetFiles(config.InputFolder, "*.html");
string[] filesToProcess = allFiles
.Where(f => !checkpoint.CompletedFiles.Contains(Path.GetFileName(f)))
.ToArray();
Console.WriteLine($"Pipeline starting:");
Console.WriteLine($" Total files: {allFiles.Length}");
Console.WriteLine($" Already processed: {checkpoint.CompletedFiles.Count}");
Console.WriteLine($" To process: {filesToProcess.Length}");
Console.WriteLine($" Concurrency: {config.MaxConcurrency}");
var renderer = new ChromePdfRenderer();
var checkpointLock = new object();
var options = new ParallelOptions
{
MaxDegreeOfParallelism = config.MaxConcurrency
};
Parallel.ForEach(filesToProcess, options, inputFile =>
{
var result = new ProcessingResult
{
FileName = Path.GetFileName(inputFile),
StartTime = DateTime.UtcNow
};
try
{
// Stage: Pre-validation
if (!ValidateInput(inputFile))
{
result.Status = "PreValidationFailed";
result.Error = "Input file failed validation";
results.Add(result);
return;
}
string baseName = Path.GetFileNameWithoutExtension(inputFile);
string tempPath = Path.Combine(config.OutputFolder, $"{baseName}.pdf");
string archivePath = Path.Combine(config.ArchiveFolder, $"{baseName}.pdf");
// Stage: Process with retry
PdfDocument pdf = null;
int attempt = 0;
bool success = false;
while (attempt < config.MaxRetries && !success)
{
attempt++;
try
{
pdf = renderer.RenderHtmlFileAsPdf(inputFile);
success = true;
}
catch (Exception ex) when (IsTransient(ex) && attempt < config.MaxRetries)
{
Thread.Sleep((int)Math.Pow(2, attempt) * 500);
}
}
if (!success || pdf == null)
{
result.Status = "ProcessingFailed";
result.Error = "Max retries exceeded";
results.Add(result);
return;
}
using (pdf)
{
// Stage: Compress and convert to PDF/A-3b for archival
pdf.SaveAsPdfA(tempPath, PdfAVersions.PdfA3b);
}
// Stage: Post-validation
if (!ValidateOutput(tempPath))
{
File.Move(tempPath, Path.Combine(config.ErrorFolder, $"{baseName}.pdf"), overwrite: true);
result.Status = "PostValidationFailed";
result.Error = "Output file failed validation";
results.Add(result);
return;
}
// Stage: Archive
File.Move(tempPath, archivePath, overwrite: true);
// Update checkpoint
lock (checkpointLock)
{
checkpoint.CompletedFiles.Add(result.FileName);
SaveCheckpoint(config.CheckpointPath, checkpoint);
}
result.Status = "Success";
result.OutputSize = new FileInfo(archivePath).Length;
result.EndTime = DateTime.UtcNow;
results.Add(result);
Console.WriteLine($"[OK] {baseName}.pdf ({result.OutputSize / 1024}KB)");
}
catch (Exception ex)
{
result.Status = "Error";
result.Error = ex.Message;
result.EndTime = DateTime.UtcNow;
results.Add(result);
Console.WriteLine($"[ERROR] {result.FileName}: {ex.Message}");
}
});
stopwatch.Stop();
// Generate report
var report = new PipelineReport
{
TotalFiles = allFiles.Length,
ProcessedThisRun = results.Count,
Succeeded = results.Count(r => r.Status == "Success"),
PreValidationFailed = results.Count(r => r.Status == "PreValidationFailed"),
ProcessingFailed = results.Count(r => r.Status == "ProcessingFailed"),
PostValidationFailed = results.Count(r => r.Status == "PostValidationFailed"),
Errors = results.Count(r => r.Status == "Error"),
TotalDuration = stopwatch.Elapsed,
AverageFileTime = results.Any() ? TimeSpan.FromMilliseconds(stopwatch.Elapsed.TotalMilliseconds / results.Count) : TimeSpan.Zero
};
string reportJson = JsonSerializer.Serialize(report, new JsonSerializerOptions { WriteIndented = true });
File.WriteAllText(config.ReportPath, reportJson);
Console.WriteLine($"\n=== Pipeline Complete ===");
Console.WriteLine($"Succeeded: {report.Succeeded}");
Console.WriteLine($"Failed: {report.PreValidationFailed + report.ProcessingFailed + report.PostValidationFailed + report.Errors}");
Console.WriteLine($"Duration: {report.TotalDuration.TotalMinutes:F1} minutes");
Console.WriteLine($"Report: {config.ReportPath}");
// Helper methods
bool ValidateInput(string path)
{
try
{
var info = new FileInfo(path);
if (!info.Exists || info.Length == 0 || info.Length > 50 * 1024 * 1024) return false;
string content = File.ReadAllText(path);
return content.Contains("<html", StringComparison.OrdinalIgnoreCase) ||
content.Contains("<!DOCTYPE", StringComparison.OrdinalIgnoreCase);
}
catch { return false; }
}
bool ValidateOutput(string path)
{
try
{
using var pdf = PdfDocument.FromFile(path);
return pdf.PageCount > 0 && new FileInfo(path).Length > 1024;
}
catch { return false; }
}
bool IsTransient(Exception ex) =>
ex is IOException || ex is OutOfMemoryException ||
ex.Message.Contains("timeout", StringComparison.OrdinalIgnoreCase);
Checkpoint LoadCheckpoint(string path)
{
if (File.Exists(path))
{
string json = File.ReadAllText(path);
return JsonSerializer.Deserialize<Checkpoint>(json) ?? new Checkpoint();
}
return new Checkpoint();
}
void SaveCheckpoint(string path, Checkpoint cp) =>
File.WriteAllText(path, JsonSerializer.Serialize(cp));
// Data classes
public class PipelineConfig
{
public string InputFolder { get; set; } = "";
public string OutputFolder { get; set; } = "";
public string ArchiveFolder { get; set; } = "";
public string ErrorFolder { get; set; } = "";
public string CheckpointPath { get; set; } = "";
public string ReportPath { get; set; } = "";
public int MaxConcurrency { get; set; }
public int MaxRetries { get; set; }
public int JpegQuality { get; set; }
}
public class Checkpoint
{
public HashSet<string> CompletedFiles { get; set; } = new();
}
public class ProcessingResult
{
public string FileName { get; set; } = "";
public string Status { get; set; } = "";
public string Error { get; set; } = "";
public long OutputSize { get; set; }
public DateTime StartTime { get; set; }
public DateTime EndTime { get; set; }
}
public class PipelineReport
{
public int TotalFiles { get; set; }
public int ProcessedThisRun { get; set; }
public int Succeeded { get; set; }
public int PreValidationFailed { get; set; }
public int ProcessingFailed { get; set; }
public int PostValidationFailed { get; set; }
public int Errors { get; set; }
public TimeSpan TotalDuration { get; set; }
public TimeSpan AverageFileTime { get; set; }
}Imports IronPdf
Imports System
Imports System.Collections.Generic
Imports System.IO
Imports System.Linq
Imports System.Threading.Tasks
Imports System.Threading
Imports System.Collections.Concurrent
Imports System.Diagnostics
Imports System.Text.Json
' Configuration
Dim config As New PipelineConfig With {
.InputFolder = "input/",
.OutputFolder = "output/",
.ArchiveFolder = "archive/",
.ErrorFolder = "errors/",
.CheckpointPath = "pipeline-checkpoint.json",
.ReportPath = "pipeline-report.json",
.MaxConcurrency = Math.Max(1, Environment.ProcessorCount \ 2),
.MaxRetries = 3,
.JpegQuality = 70
}
' Initialize folders
Directory.CreateDirectory(config.OutputFolder)
Directory.CreateDirectory(config.ArchiveFolder)
Directory.CreateDirectory(config.ErrorFolder)
' Load checkpoint for resume capability
Dim checkpoint As Checkpoint = LoadCheckpoint(config.CheckpointPath)
Dim results As New ConcurrentBag(Of ProcessingResult)()
Dim stopwatch As Stopwatch = Stopwatch.StartNew()
' Get files to process
Dim allFiles As String() = Directory.GetFiles(config.InputFolder, "*.html")
Dim filesToProcess As String() = allFiles.
Where(Function(f) Not checkpoint.CompletedFiles.Contains(Path.GetFileName(f))).
ToArray()
Console.WriteLine("Pipeline starting:")
Console.WriteLine($" Total files: {allFiles.Length}")
Console.WriteLine($" Already processed: {checkpoint.CompletedFiles.Count}")
Console.WriteLine($" To process: {filesToProcess.Length}")
Console.WriteLine($" Concurrency: {config.MaxConcurrency}")
Dim renderer As New ChromePdfRenderer()
Dim checkpointLock As New Object()
Dim options As New ParallelOptions With {
.MaxDegreeOfParallelism = config.MaxConcurrency
}
Parallel.ForEach(filesToProcess, options, Sub(inputFile)
Dim result As New ProcessingResult With {
.FileName = Path.GetFileName(inputFile),
.StartTime = DateTime.UtcNow
}
Try
' Stage: Pre-validation
If Not ValidateInput(inputFile) Then
result.Status = "PreValidationFailed"
result.Error = "Input file failed validation"
results.Add(result)
Return
End If
Dim baseName As String = Path.GetFileNameWithoutExtension(inputFile)
Dim tempPath As String = Path.Combine(config.OutputFolder, $"{baseName}.pdf")
Dim archivePath As String = Path.Combine(config.ArchiveFolder, $"{baseName}.pdf")
' Stage: Process with retry
Dim pdf As PdfDocument = Nothing
Dim attempt As Integer = 0
Dim success As Boolean = False
While attempt < config.MaxRetries AndAlso Not success
attempt += 1
Try
pdf = renderer.RenderHtmlFileAsPdf(inputFile)
success = True
Catch ex As Exception When IsTransient(ex) AndAlso attempt < config.MaxRetries
Thread.Sleep(CInt(Math.Pow(2, attempt)) * 500)
End Try
End While
If Not success OrElse pdf Is Nothing Then
result.Status = "ProcessingFailed"
result.Error = "Max retries exceeded"
results.Add(result)
Return
End If
Using pdf
' Stage: Compress and convert to PDF/A-3b for archival
pdf.SaveAsPdfA(tempPath, PdfAVersions.PdfA3b)
End Using
' Stage: Post-validation
If Not ValidateOutput(tempPath) Then
File.Move(tempPath, Path.Combine(config.ErrorFolder, $"{baseName}.pdf"), overwrite:=True)
result.Status = "PostValidationFailed"
result.Error = "Output file failed validation"
results.Add(result)
Return
End If
' Stage: Archive
File.Move(tempPath, archivePath, overwrite:=True)
' Update checkpoint
SyncLock checkpointLock
checkpoint.CompletedFiles.Add(result.FileName)
SaveCheckpoint(config.CheckpointPath, checkpoint)
End SyncLock
result.Status = "Success"
result.OutputSize = New FileInfo(archivePath).Length
result.EndTime = DateTime.UtcNow
results.Add(result)
Console.WriteLine($"[OK] {baseName}.pdf ({result.OutputSize \ 1024}KB)")
Catch ex As Exception
result.Status = "Error"
result.Error = ex.Message
result.EndTime = DateTime.UtcNow
results.Add(result)
Console.WriteLine($"[ERROR] {result.FileName}: {ex.Message}")
End Try
End Sub)
stopwatch.Stop()
' Generate report
Dim report As New PipelineReport With {
.TotalFiles = allFiles.Length,
.ProcessedThisRun = results.Count,
.Succeeded = results.Count(Function(r) r.Status = "Success"),
.PreValidationFailed = results.Count(Function(r) r.Status = "PreValidationFailed"),
.ProcessingFailed = results.Count(Function(r) r.Status = "ProcessingFailed"),
.PostValidationFailed = results.Count(Function(r) r.Status = "PostValidationFailed"),
.Errors = results.Count(Function(r) r.Status = "Error"),
.TotalDuration = stopwatch.Elapsed,
.AverageFileTime = If(results.Any(), TimeSpan.FromMilliseconds(stopwatch.Elapsed.TotalMilliseconds / results.Count), TimeSpan.Zero)
}
Dim reportJson As String = JsonSerializer.Serialize(report, New JsonSerializerOptions With {.WriteIndented = True})
File.WriteAllText(config.ReportPath, reportJson)
Console.WriteLine(vbCrLf & "=== Pipeline Complete ===")
Console.WriteLine($"Succeeded: {report.Succeeded}")
Console.WriteLine($"Failed: {report.PreValidationFailed + report.ProcessingFailed + report.PostValidationFailed + report.Errors}")
Console.WriteLine($"Duration: {report.TotalDuration.TotalMinutes:F1} minutes")
Console.WriteLine($"Report: {config.ReportPath}")
' Helper methods
Function ValidateInput(path As String) As Boolean
Try
Dim info As New FileInfo(path)
If Not info.Exists OrElse info.Length = 0 OrElse info.Length > 50 * 1024 * 1024 Then Return False
Dim content As String = File.ReadAllText(path)
Return content.Contains("<html", StringComparison.OrdinalIgnoreCase) OrElse
content.Contains("<!DOCTYPE", StringComparison.OrdinalIgnoreCase)
Catch
Return False
End Try
End Function
Function ValidateOutput(path As String) As Boolean
Try
Using pdf = PdfDocument.FromFile(path)
Return pdf.PageCount > 0 AndAlso New FileInfo(path).Length > 1024
End Using
Catch
Return False
End Try
End Function
Function IsTransient(ex As Exception) As Boolean
Return TypeOf ex Is IOException OrElse TypeOf ex Is OutOfMemoryException OrElse
ex.Message.Contains("timeout", StringComparison.OrdinalIgnoreCase)
End Function
Function LoadCheckpoint(path As String) As Checkpoint
If File.Exists(path) Then
Dim json As String = File.ReadAllText(path)
Return JsonSerializer.Deserialize(Of Checkpoint)(json) OrElse New Checkpoint()
End If
Return New Checkpoint()
End Function
Sub SaveCheckpoint(path As String, cp As Checkpoint)
File.WriteAllText(path, JsonSerializer.Serialize(cp))
End Sub
' Data classes
Public Class PipelineConfig
Public Property InputFolder As String = ""
Public Property OutputFolder As String = ""
Public Property ArchiveFolder As String = ""
Public Property ErrorFolder As String = ""
Public Property CheckpointPath As String = ""
Public Property ReportPath As String = ""
Public Property MaxConcurrency As Integer
Public Property MaxRetries As Integer
Public Property JpegQuality As Integer
End Class
Public Class Checkpoint
Public Property CompletedFiles As HashSet(Of String) = New HashSet(Of String)()
End Class
Public Class ProcessingResult
Public Property FileName As String = ""
Public Property Status As String = ""
Public Property Error As String = ""
Public Property OutputSize As Long
Public Property StartTime As DateTime
Public Property EndTime As DateTime
End Class
Public Class PipelineReport
Public Property TotalFiles As Integer
Public Property ProcessedThisRun As Integer
Public Property Succeeded As Integer
Public Property PreValidationFailed As Integer
Public Property ProcessingFailed As Integer
Public Property PostValidationFailed As Integer
Public Property Errors As Integer
Public Property TotalDuration As TimeSpan
Public Property AverageFileTime As TimeSpan
End ClassÇıktı
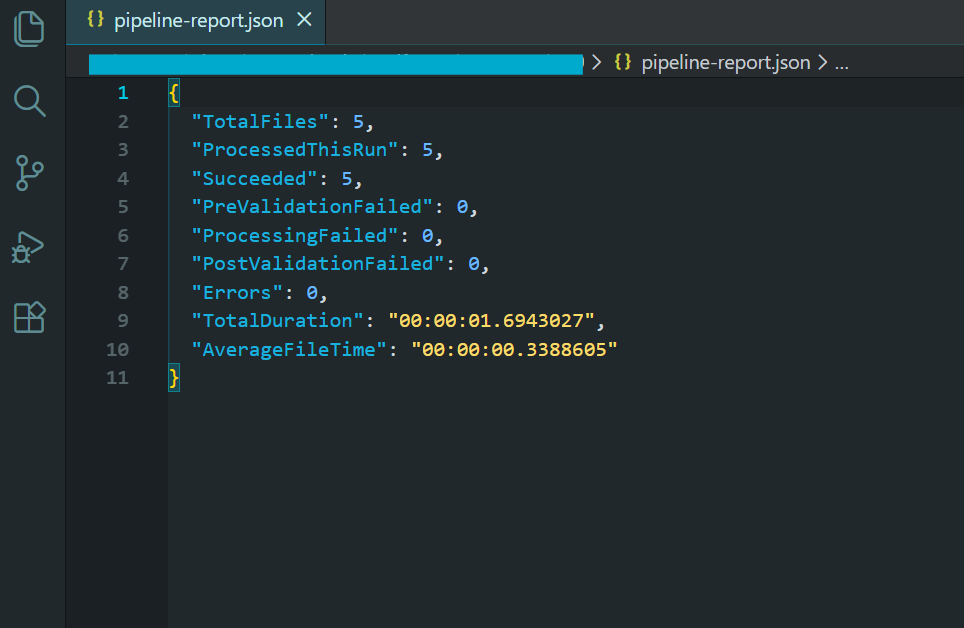
Toplu işleme sonuçlarını gösteren pipeline raporu.
Bu boru hattı, kontrol edilen eşzamanlılık ile paralel işleme, başarısızlıkta atlamayla hata işleme, geçici hatalar için geri deneme mantığı, çökmeden sonra devam için kontrol noktası oluşturma, işlem öncesi ve sonrası doğrulama, açıkça imha ile bellek yönetimi ve son bir özet raporuyla kapsamlı günlükleme dahil, bu öğreticide ele aldığımız her kalıbı içeriyor.
Bu boru hattının çıktısı, PDF/A-3b uyumluluğunu sağlayan sıkıştırılmış bir arşiv dosyaları dizini, tekrar başlama yeteneği için bir kontrol noktası dosyası, işlenemeyen dosyalar için bir hatalar kaydı ve işleme istatistiklerini içeren bir özet raporu olacaktır. Bu, ciddi bir toplu PDF işleme iş yükü için istediğiniz desendir.
Sonraki Adımlar
Ölçekte toplu PDF işleme, bir döngüde bir işleme yöntemini çağırmaktan ibaret değildir. Eşzamanlılık, bellek yönetimi, hata işleme ve dağıtım etrafında düşünceli bir mimari gerektirir — ve hepsini çalıştıracak doğru kütüphane. IronPDF, herhangi bir .NET toplu PDF boru hattının temellerini oluşturan, iş parçacığı güvenli işleme motoru, async API yüzeyi, sıkıştırma araçları ve biçim dönüştürme olanakları sağlar.
İster gece raporu üreticisi inşa ediyor olun ki gün doğmadan önce binlerce PDF üretir, ister bir eski belge arşivini PDF/A uyumluluğuna gömüyorsunuz ya da bir Kubernetes üzerinde bulut yerel bir işleme hizmeti ayarlıyorsunuz, bu öğreticideki desenler üzerinde dayanabileceğiniz kanıtlanmış bir çerçeve sunar. Kontrol edilen eşzamanlılık ile paralel işleme, verimliliği yüksek tutar. Başarısızlıkta atlama ve geri deneme mantığı, bireysel dosyalar sorun oluşturduğunda boru hattını hareket ettirir. Kontrol noktası oluşturma, hiçbir ilerlemeyi asla kaybetmediğinizden emin olur. Ve bulut dağıtım kalıpları, iş yükünüzle eşleşen hesaplamaları ölçeklendirmenize izin verir.
İşe başlamaya hazır mısınız? IronPDF'i İndirin ve aynı kütüphanenin tek dosya iş işleminden yüz bin dosyalık toplu boru hatlarına kadar her şeyi nasıl ele aldığını ücretsiz deneme ile deneyin. Özellikle kullanım durumunuz için ölçeklendirme, dağıtım veya mimari hakkında sorularınız varsa, mühendislik destek ekibimize ulaşın — her ölçekte toplu boru hatları inşa eden takımlara yardımcı olduk ve doğru yapmanıza yardımcı olmaktan mutluluk duyarız.
Sıkça Sorulan Sorular
C#'ta toplu PDF işleme nedir?
C#'ta toplu PDF işleme, C# programlama dilini kullanarak çok sayıda PDF belgesinin eş zamanlı otomatik olarak işlenmesidir. Bu yöntem, belge iş akışlarını geniş ölçekte otomatikleştirmek için idealdir.
IronPDF toplu PDF işlemede nasıl yardımcı olabilir?
IronPDF, C#'ta toplu PDF işlemeyi düzgünleştiren güçlü araçlar ve kütüphaneler sağlar. Binlerce PDF'nin eş zamanlı olarak verimli bir şekilde ele alınmasına izin veren paralel işlemi destekler.
IronPDF ile paralel işlemeyi kullanmanın faydaları nelerdir?
IronPDF ile paralel işleme, daha hızlı ve daha verimli toplu PDF işleme sağlar. Bu yaklaşım, kaynak kullanımını maksimize eder ve işlem süresini önemli ölçüde azaltır.
IronPDF toplu işlem için bulut platformlarında dağıtılabilir mi?
Evet, IronPDF, Azure Fonksiyonları, AWS Lambda ve Kubernetes gibi bulut platformlarında dağıtılabilir, böylece ölçeklenebilir ve esnek bir toplu PDF işlemeyi sağlar.
IronPDF toplu PDF işlem sırasında hataları nasıl ele alır?
IronPDF, toplu PDF işlem sırasında güvenilirlik sağlayan hata yönetimi ve yeniden deneme mantığı özellikleri içerir. Bu özellikler, manuel müdahaleye gerek kalmadan hataları yönetmeye ve düzeltmeye yardımcı olur.
IronPDF'de PDF işlemeyle ilgili yeniden deneme mantığının rolü nedir?
IronPDF'deki yeniden deneme mantığı, geçici sorunların toplu işleme iş akışını kesmemesini sağlar. Bir hata oluştuğunda, IronPDF başarısız belgeyi otomatik olarak yeniden işleyebilir.
C# neden toplu PDF işleme için uygun bir dil?
C# geniş kütüphaneler ve toplu PDF işlemeyi ideal kılan çerçevelere sahip güçlü bir programlama dilidir. Verimli belge otomasyonu için IronPDF ile sorunsuz bir şekilde entegre olur.
IronPDF, PDF belgelerinin işlenmesi sırasında güvenliğini nasıl sağlar?
IronPDF, işlenen belgelerin gizli kalmasını ve güvenliğini sağlamak için şifreleme ve parola koruma özellikleri sağlayarak PDF belgelerinin güvenli şekilde ele alınmasını destekler.
Toplu PDF işlemenin işletmelerdeki bazı kullanım durumları nelerdir?
İşletmeler, toplu PDF işlemi, toplu fatura oluşturma, belge dijitalleştirme ve geniş çapta rapor dağıtımı gibi görevler için kullanır. IronPDF, bu kullanım durumlarını otomasyon ve iş akışlarının basitleştirilmesini sağlayarak kolaylaştırır.
IronPDF farklı PDF formatlarını ve sürümlerini ele alabilir mi?
Evet, IronPDF, çeşitli PDF format ve sürümlerini işlemek için tasarlanmıştır, toplu işleme görevlerinde uyumluluk ve esneklik sağlar.


Hâlâ Kaydırıyor Musunuz?
Hızlıca kanıt ister misiniz? PM > Install-Package IronPdf
bir örnek çalıştır HTML'nizi bir PDF'ye dönüştüğünü izleyin.










