


Extract Embedded Text and Images from PDFs in C
C# ile PDF belgelerinden hem metin içerik hem de görüntüleri basit metot çağrıları ile çıkarın. Diğer uygulamalarda düzenleme, analiz veya yeniden amaçlandırma için gömülü içeriği alın.
Metin ve resim çıkarma, PDF belgelerinden metinsel içeriği ve grafik öğeleri alır. İçeriğe erişin ve düzenleme, arama yapma, metni diğer formatlara dönüştürme veya yeniden kullanım için görselleri kaydetmek amacıyla içeriği yeniden değerlendirin. İster PDF'leri C# içinde ayrıştırmak yoluyla veri analizi, ister içerikleri aranabilir formatlara dönüştürmek veya görsel öğeleri arşivlemek için çıkarmak isteyin, IronPDF kapsamlı çıkarma araçları sağlar.
IronPDF kullanarak metin ve resimleri çıkarın. Çıkarılan görüntüleri diske kaydedin veya yeni belgelere yerleştirmeden önce başka bir formata dönüştürün. Bu esneklik, içerik dönüşümünü gerektiren iş akışlarını destekler, örneğin PDF'leri HTML'ye dönüştürmek veya çıkarılan görüntüleri yeniden kullanmak gibi.
Hızlı Başlangıç: IronPDF ile Metin ve Görüntü Çıkarma
PDF dosyalarından metin ve resimleri sadece birkaç satır kodla çıkarın. Bu hızlı başlangıç, içerik yeniden kullanımı ve analiz için PDF belgelerinden gömülü içeriğin nasıl alınacağını gösterir. IronPDF'nin kesintisiz çözümü ile düzenleme için metin çıkarın veya ileride kullanmak üzere görüntüleri kaydedin.
-
IronPDF aşağıdaki NuGet Paket Yöneticisi ile yükleyin
-
Bu kod parçacığını kopyalayın ve çalıştırın.
var pdf = new IronPdf.PdfDocument("sample.pdf"); string text = pdf.ExtractAllText(); var images = pdf.ExtractAllImages(); -
Canlı ortamınızda test için dağıtım yapın
Ücretsiz deneme ile bugün projenizde IronPDF kullanmaya başlayın

Asgari İş Akışı (5 adım)
- IronPdf C# Kütüphanesini İndir
- Metin ve görüntü çıkarma için PDF belgesini hazırlayın
ExtractAllTextyöntemini kullanarak metin çıkarınExtractAllImagesyöntemini kullanarak görüntüleri çıkarın- Metin ve resimleri çıkarmak için belirli sayfaları belirtin
PDF'lerden Metin Nasıl Çıkarılır?
Hem yeni oluşturulmuş hem de mevcut PDF belgelerinden metin çıkarın. Belgeden gömülü metni çıkarmak için ExtractAllText yöntemini kullanın. Yöntem, PDF'deki tüm metni içeren bir dize döndürür. Sayfalar, ardışık dört yeni satır karakteriyle ayrılır. Bu örnek, Wikipedia web sitesinden render edilen bir örnek PDF kullanır.
PDF'lerle çalışırken uluslararası diller ve UTF-8 karakterleri içeren, IronPDF uygun kodlama ve karakter temsilini korur. Bu, Latin olmayan yazılar ve özel karakterlerin doğru görüntülenmesini sağlar.
:path=/static-assets/pdf/content-code-examples/how-to/extract-text-and-images-extract-text.csusing IronPdf;
using System.IO;
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract text
string text = pdf.ExtractAllText();
// Export the extracted text to a text file
File.WriteAllText("extractedText.txt", text);Imports IronPdf
Imports System.IO
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract text
Private text As String = pdf.ExtractAllText()
' Export the extracted text to a text file
File.WriteAllText("extractedText.txt", text)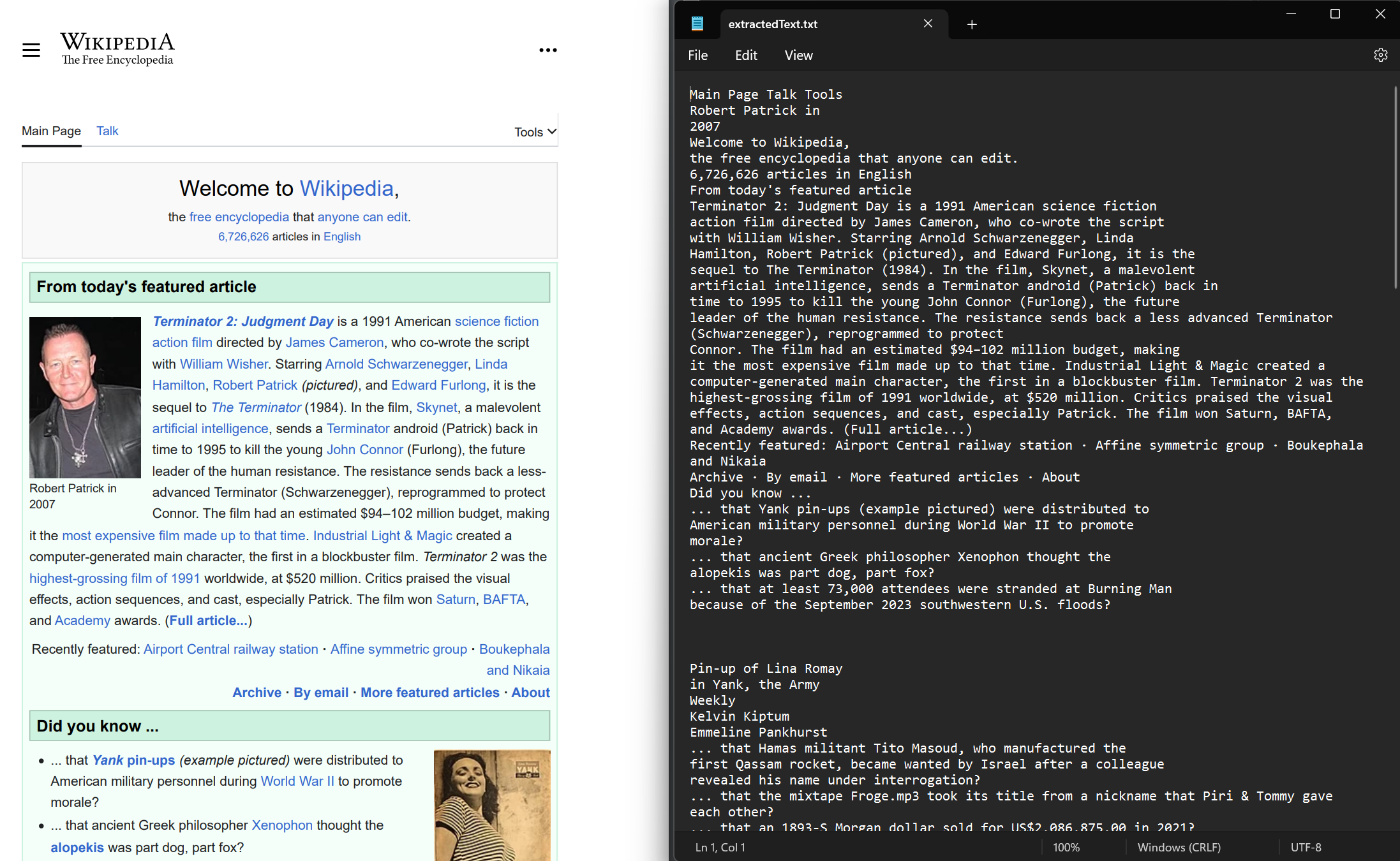
Metni Belirli Koordinatlarla Nasıl Çıkarabilirim?
Her bir PDF sayfasındaki metin satırlarının ve karakterlerinin koordinatlarını alın. PDF'den bir sayfa seçin ve Lines ile Characters özelliklerine erişin. Koordinatlar, metin konumunu temsil eden Top, Right, Bottom ve Left değerlerini içerir. Bu özellik, mekansal yerleşimi korur ve metin konumu analizini mümkün kılar.
Belge yapısını korumak ve ileri düzey metin analizini uygulamak için konum farkındalığına sahip C# dilinde PDF dosyalarını okuması gereken geliştiriciler için, koordinat çıkarımı veri sağlar.
:path=/static-assets/pdf/content-code-examples/how-to/extract-text-and-images-extract-text-by-line-character.csusing IronPdf;
using System.IO;
using System.Linq;
// Open PDF from file
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract text by lines
var lines = pdf.Pages[0].Lines;
// Extract text by characters
var characters = pdf.Pages[0].Characters;
File.WriteAllLines("lines.txt", lines.Select(l => $"at Y={l.BoundingBox.Bottom:F2}: {l.Contents}"));Imports IronPdf
Imports System.IO
Imports System.Linq
' Open PDF from file
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract text by lines
Private lines = pdf.Pages(0).Lines
' Extract text by characters
Private characters = pdf.Pages(0).Characters
File.WriteAllLines("lines.txt", lines.Select(Function(l) $"at Y={l.BoundingBox.Bottom:F2}: {l.Contents}"))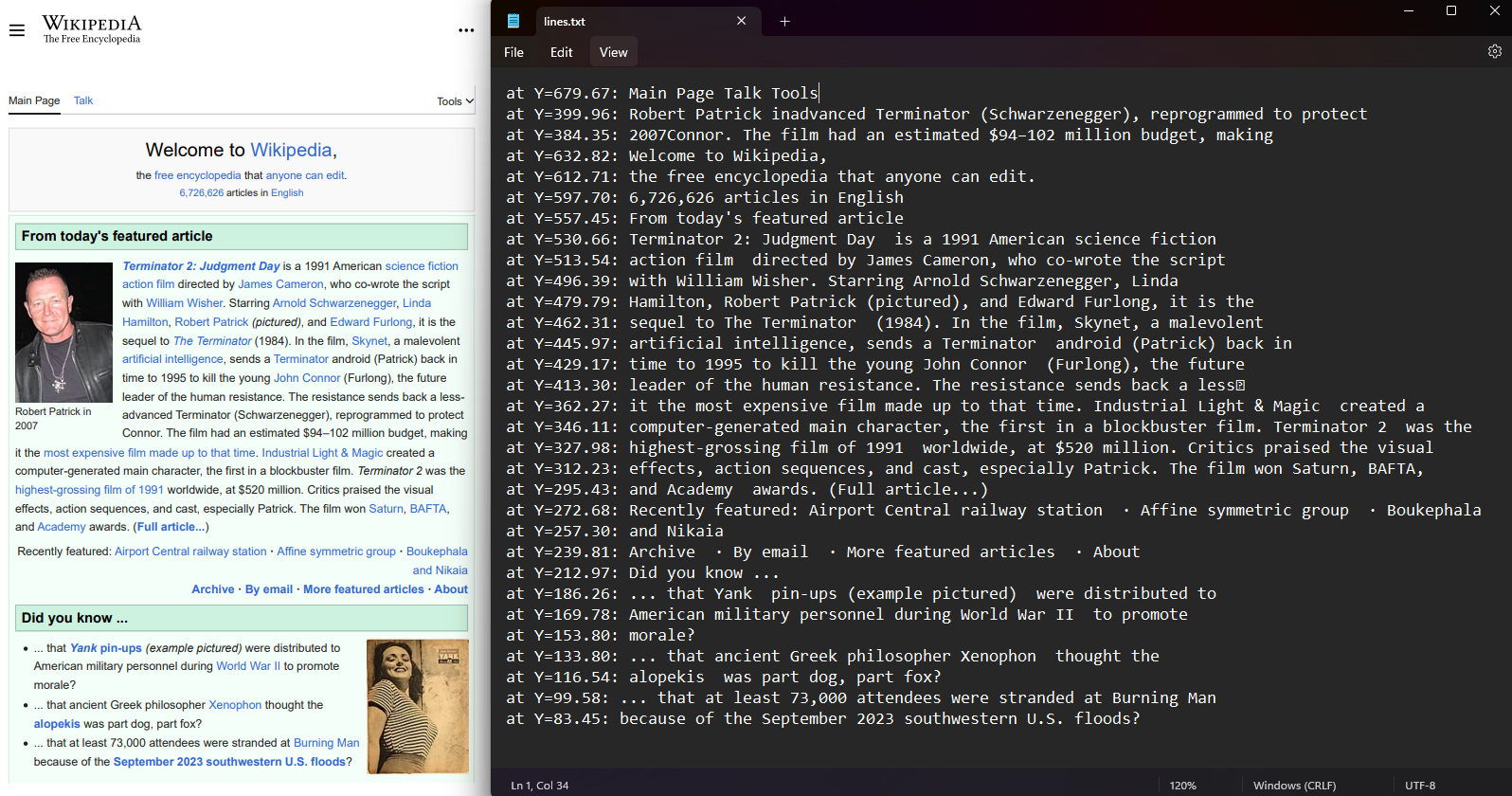
Bu türden favori kütüphanem IronPDF'dir. PDF dosyalarının hızlı ve verimli bir şekilde işlenmesine olanak tanır. Ayrıca, PDF/A formatına dışa aktarma ve dijital imzalama gibi birçok değerli özelliğe sahiptir.
IronOCR, manuel işleme maliyetinden yıllık 40.000 USD tasarruf etmemizi sağlıyor, üretkenliği artırıyor ve yüksek etkili görevler için kaynakları serbest bırakıyor. Kesinlikle tavsiye ederim.
IronSuite, operasyonlarımızda kritik bir rol oynar. Bunlar, iş süreçlerinde verimliliği artıran, kat planları oluşturmak ve envanter yönetimini geliştirmek gibi araçlardır.
PDF'lerden Görüntüleri Nasıl Çıkarırım?
Belgedeki tüm gömülü resimleri çıkarmak için ExtractAllImages yöntemini kullanın. Yöntem, resimleri AnyBitmap nesnelerinin List listesi olarak döndürür. Aynı belgeyi kullanarak, görüntüleri çıkardık ve 'images' klasörüne aktardık. Bu işlevsellik, görüntü arşivleme, içerik taşıma ve PDF sayfalarını görüntülere rasterleştirme işlemlerine destek verir ve daha ileri işlemler için kullanılabilir.
Çıkarılan görüntüler, orijinal kalitesini korur ve PNG, JPEG ve BMP dahil olmak üzere çeşitli formatlarda kaydedilebilir. Bulut depolama iş akışları için, bu işlevselliği Azure Blob Storage ile görüntü yönetimi ile entegre edin.
:path=/static-assets/pdf/content-code-examples/how-to/extract-text-and-images-extract-image.csusing IronPdf;
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract images
var images = pdf.ExtractAllImages();
for(int i = 0; i < images.Count; i++)
{
// Export the extracted images
images[i].SaveAs($"images/image{i}.png");
}Imports IronPdf
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract images
Private images = pdf.ExtractAllImages()
For i As Integer = 0 To images.Count - 1
' Export the extracted images
images(i).SaveAs($"images/image{i}.png")
Next i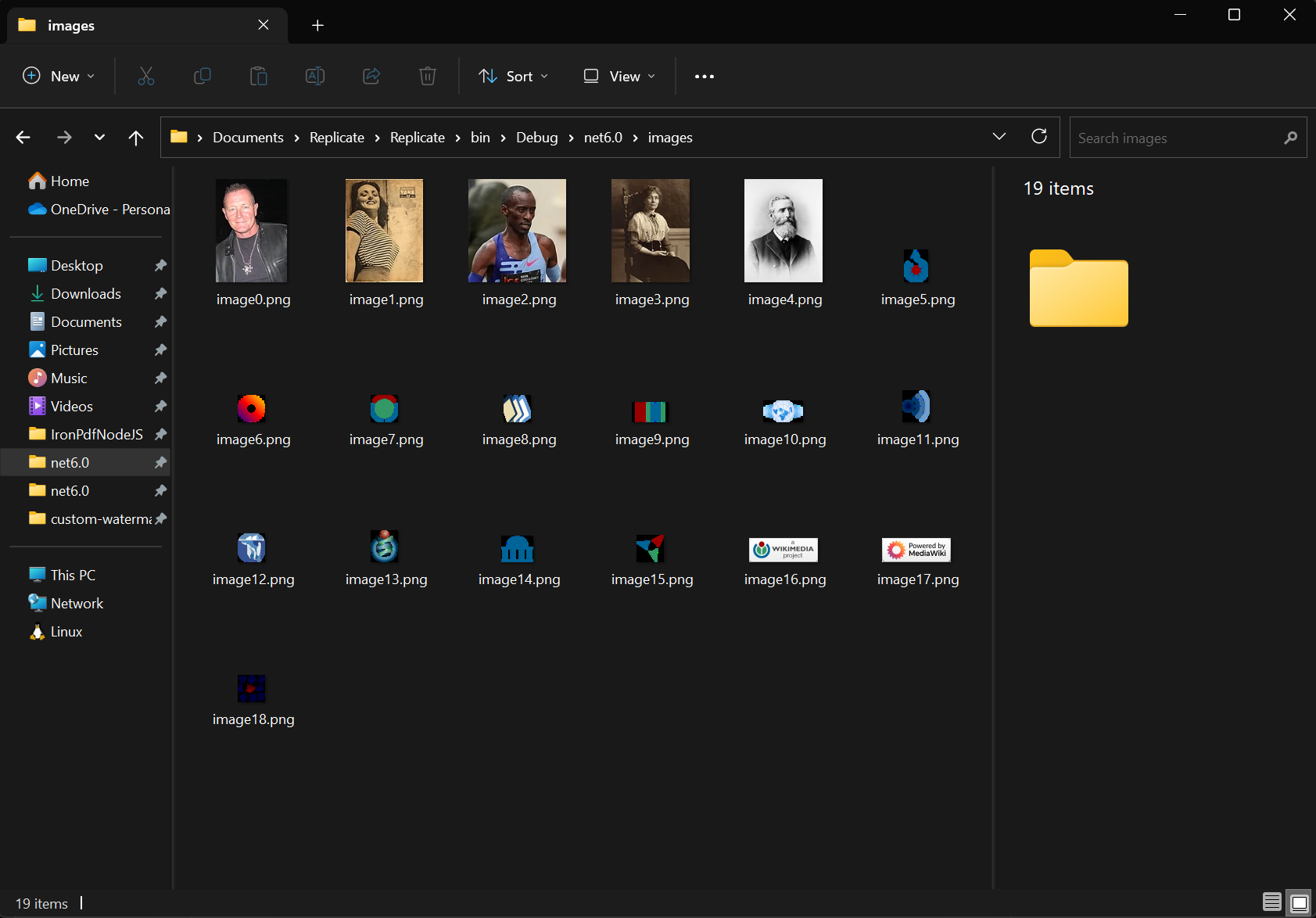
Görüntü Çıkartma İçin Farklı Yöntemler Nelerdir?
ExtractAllImages yönteminin ötesinde, görüntü bilgilerini çıkarmak için ExtractAllBitmaps ve ExtractAllRawImages yöntemlerini kullanın. ExtractAllBitmaps, AnyBitmap nesnelerinin List listesini döndürürken, ExtractAllRawImages tüm resimleri çıkarır ve onları ham byte[] (byte[]) olarak döndürür.
Bu yöntem, resim verisini bellek içinde işlerken veya bayt dizisi girişi gerektiren sistemlerle bütünleştirirken iyi çalışır. PDF'leri bellek akışlarına aktarma senaryoları için buraya tıklayın. Ham bayt dizisi formatı en iyi esnekliği sağlar.
Belirli PDF Sayfalarından İçerik Nasıl Çıkarırım?
Belirtilen tek veya birden fazla sayfadan metin ve görselleri çıkartın. Metin çıkarmak için ExtractTextFromPage ve ExtractTextFromPages yöntemlerini kullanın. Resimler için ExtractImagesFromPage ve ExtractImagesFromPages yöntemlerini kullanın.
Bu ayrıntılı kontrol, yalnızca belirli bölümlerin ilgili içeriği içerdiği büyük belgelerle çalışırken yardımcı olur. PDF'leri bölmek ve ayrı işlem için bireysel sayfaları çıkarmak için özellikler de destekleniyor.
:path=/static-assets/pdf/content-code-examples/how-to/extract-text-and-images-extract-text-single-multiple.csusing IronPdf;
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract text from page 1
string textFromPage1 = pdf.ExtractTextFromPage(0);
int[] pages = new[] { 0, 2 };
// Extract text from pages 1 & 3
string textFromPage1_3 = pdf.ExtractTextFromPages(pages);Imports IronPdf
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract text from page 1
Private textFromPage1 As String = pdf.ExtractTextFromPage(0)
Private pages() As Integer = { 0, 2 }
' Extract text from pages 1 & 3
Private textFromPage1_3 As String = pdf.ExtractTextFromPages(pages)Ne Zaman Tüm Sayfalar Yerine Belirli Sayfalardan Çıkartmalıyım?
Belirli sayfalardan çıkarın ne zaman:
- Belirli bölümlerinde ilgili veri içeren büyük PDF'lerle çalışmak
- Sayfaları bağımsız olarak işlerken iş akışlarını uygulama
- Artımlı içerik ekranı veya işleme gerektiren uygulamalar geliştirme
- Sadece gerekli sayfaları işleyerek bellek kullanımını optimize etme
- Sayfa özel arama veya indeksleme işlevselliği oluşturma
Hangi Performans Dikkatlerini Bilmeliyim?
PDF içeriğini çıkarmak istediğinizde şu performans faktörlerini göz önünde bulundurun:
- Bellek Kullanımı: Büyük belgelerden sayfaları tek tek çıkararak bellek tüketimini minimize edin
- İşlem Süresi: Çok sayfalı ekstraksiyonlarda uygun olduğunda paralel işlem kullanın
- Dosya Boyutu: Yüksek çözünürlüklü görüntüler içeren daha büyük PDF'ler daha fazla işlem süresi gerektirir
- Depolama: Çok sayıda yüksek çözünürlüklü görüntü çıkarımı için yeterli disk alanı planlayın
- Threading: IronPDF, çok çekirdekli sistemlerde performansı artırmak için çoklu iş parçacığı işlemlerini destekler
En iyi performans için, bellekteki PDF'lerle çalışırken, disk I/O yükünü azaltmak amacıyla bellek akışı işlemleri kullanın.
Sıkça Sorulan Sorular
C#'da PDF belgelerinden metin nasıl çıkarılır?
IronPDF'nin ExtractAllText yöntemiyle PDF belgelerinden gömülü metin çıkarın. Yöntem, PDF'deki tüm metni içeren bir dize döndürür, sayfalar dört ardışık yeni satır karakteri ile ayrılır. IronPDF, uluslararası diller ve UTF-8 karakterleri için doğru kodlamayı sürdürür.
PDF dosyalarından programlı olarak görüntü çıkarabiliyor muyum?
Evet, IronPDF PDF belgelerinden grafik öğeleri almak için ExtractAllImages yöntemini sağlar. Çıkarılan görüntüleri diske kaydedebilir veya yeni belgelerde gömmeden önce diğer formatlara dönüştürebilirsiniz.
PDF içerik çıkarımı için ana kullanım alanları nelerdir?
IronPDF'nin çıkarma araçları, veri analizi için PDF'leri ayrıştırmak, içeriği aranabilir formatlara dönüştürmek, arşivleme için görsel öğeler çıkarmak ve düzenleme veya diğer formatlara dönüştürme için içerik yeniden kullanma gibi çeşitli iş akışlarını destekler.
PDF içeriğinin çıkarılması ne kadar kod satırı gerektirir?
IronPDF ile birkaç kod satırı içinde metin ve görüntüleri çıkarabilirsiniz. Basitçe PDF belgenizi yükleyin ve metin çıkarımı için ExtractAllText() veya görüntü çıkarımı için ExtractAllImages() yöntemini çağırın.
Tüm belge yerine belirli sayfalardan içerik çıkarabilir miyim?
Evet, IronPDF PDF belgelerinizden hangi içeriği çıkarmak istediğinize ilişkin kesin kontrol sağlayarak metin ve görüntüleri hangi sayfalardan çıkaracağınızı belirlemenize olanak tanır.


Hâlâ Kaydırıyor Musunuz?
Hızlıca kanıt ister misiniz? PM > Install-Package IronPdf
bir örnek çalıştır HTML'nizi bir PDF'ye dönüştüğünü izleyin.










