


Extract Embedded Text and Images from PDFs in C
通过简单的方法调用,用 C# 从 PDF 文档中提取文本内容和图像。 检索嵌入内容,以便在其他应用程序中进行编辑、分析或重新使用。
文本和图像提取可检索 PDF 文档中的文本内容和图形元素。 访问和重新利用内容,以便进行编辑、搜索、将文本转换为其他格式或保存图像以供重复使用。 无论您是需要用 C# 解析 PDF 以进行数据分析、将内容转换为可搜索格式,还是提取可视化元素以进行归档,IronPDF 都能提供全面的提取工具。
using IronPDF 提取文本和图像。 将提取的图像保存到磁盘或转换为其他格式,然后再嵌入到新文档中。 这种灵活性可支持需要进行内容转换的工作流程,例如 将 PDF 转换为 HTML 或重新利用提取的图像。
快速入门:使用IronPDF提取文本和图像
只需几行代码即可从 PDF 中提取文本和图像。 本快速入门手册演示了如何从 PDF 文档中检索嵌入内容,以便进行内容再利用和分析。 使用 IronPDF 的精简解决方案,提取文本进行编辑或保存图像以供进一步使用。
最小工作流程(5 个步骤)
- 下载
IronPdfC#库 - 准备PDF文档以进行文本和图像提取
- 使用
ExtractAllText方法提取文本 - 使用
ExtractAllImages方法提取图像 - 指定要从中提取文本和图像的特定页面
如何从 PDF 中提取文本?
从新渲染的和现有的 PDF 文档中提取文本。 使用ExtractAllText方法从文档中提取嵌入的文本。 该方法返回一个包含 PDF 中所有文本的字符串。 各页之间用四个连续换行符隔开。 本示例使用了从维基百科网站渲染的 示例 PDF。
在处理包含 国际语言和 UTF-8 字符的 PDF 时,IronPDF 可保持正确的编码和字符表示。 这将确保正确显示非拉丁脚本和特殊字符。
:path=/static-assets/pdf/content-code-examples/how-to/extract-text-and-images-extract-text.csusing IronPdf;
using System.IO;
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract text
string text = pdf.ExtractAllText();
// Export the extracted text to a text file
File.WriteAllText("extractedText.txt", text);Imports IronPdf
Imports System.IO
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract text
Private text As String = pdf.ExtractAllText()
' Export the extracted text to a text file
File.WriteAllText("extractedText.txt", text)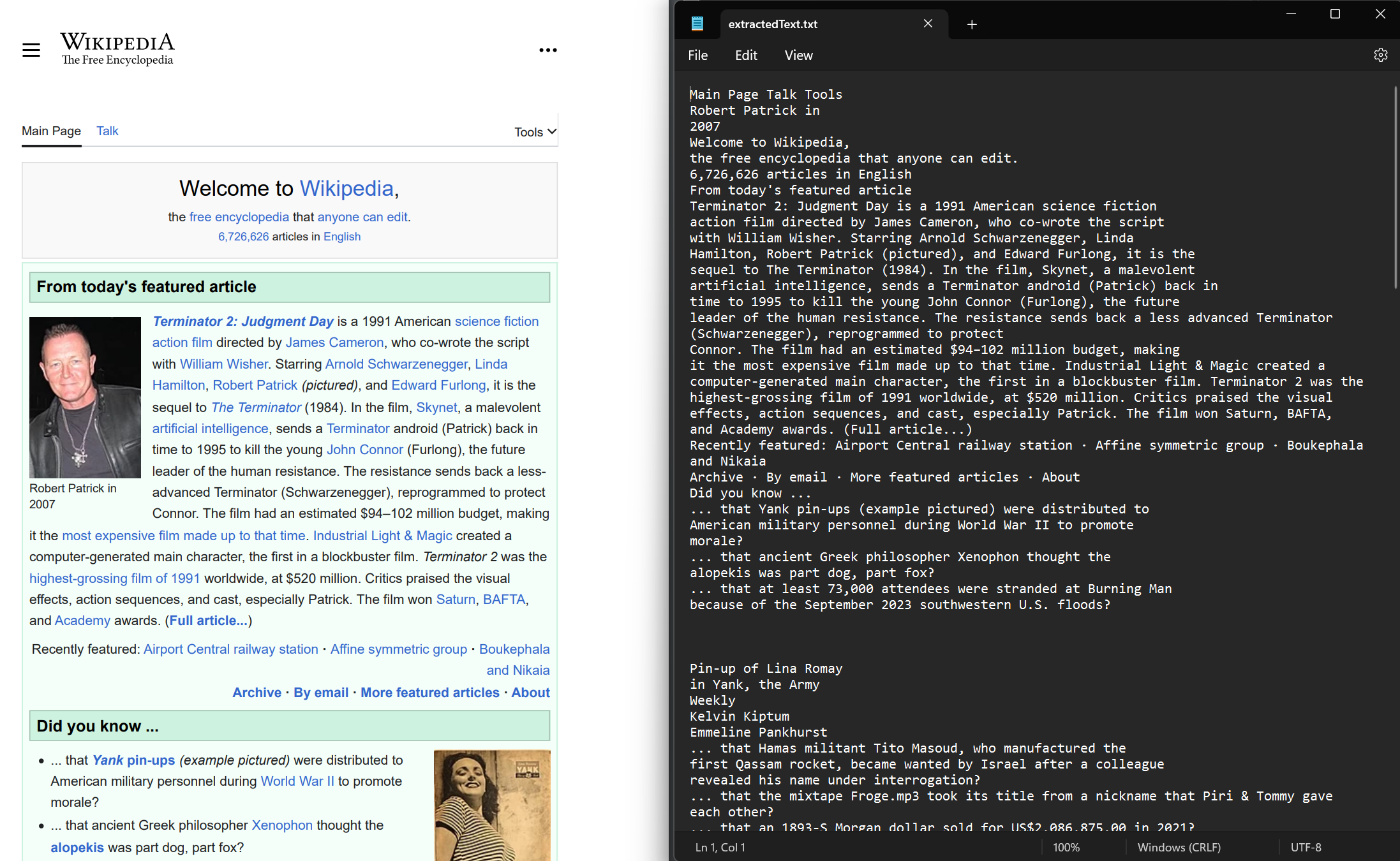
如何提取具有精确坐标的文本?
检索每个 PDF 页面中文本行和字符的坐标。 从PDF中选择一页,访问Characters属性。 坐标包括表示文本位置的Left值。 该功能保留了空间布局,并可进行文本位置分析。
对于需要在 C# 中读取具有位置意识的 PDF 文件的开发人员来说,坐标提取为维护文档结构和实施高级文本分析提供了数据。
:path=/static-assets/pdf/content-code-examples/how-to/extract-text-and-images-extract-text-by-line-character.csusing IronPdf;
using System.IO;
using System.Linq;
// Open PDF from file
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract text by lines
var lines = pdf.Pages[0].Lines;
// Extract text by characters
var characters = pdf.Pages[0].Characters;
File.WriteAllLines("lines.txt", lines.Select(l => $"at Y={l.BoundingBox.Bottom:F2}: {l.Contents}"));Imports IronPdf
Imports System.IO
Imports System.Linq
' Open PDF from file
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract text by lines
Private lines = pdf.Pages(0).Lines
' Extract text by characters
Private characters = pdf.Pages(0).Characters
File.WriteAllLines("lines.txt", lines.Select(Function(l) $"at Y={l.BoundingBox.Bottom:F2}: {l.Contents}"))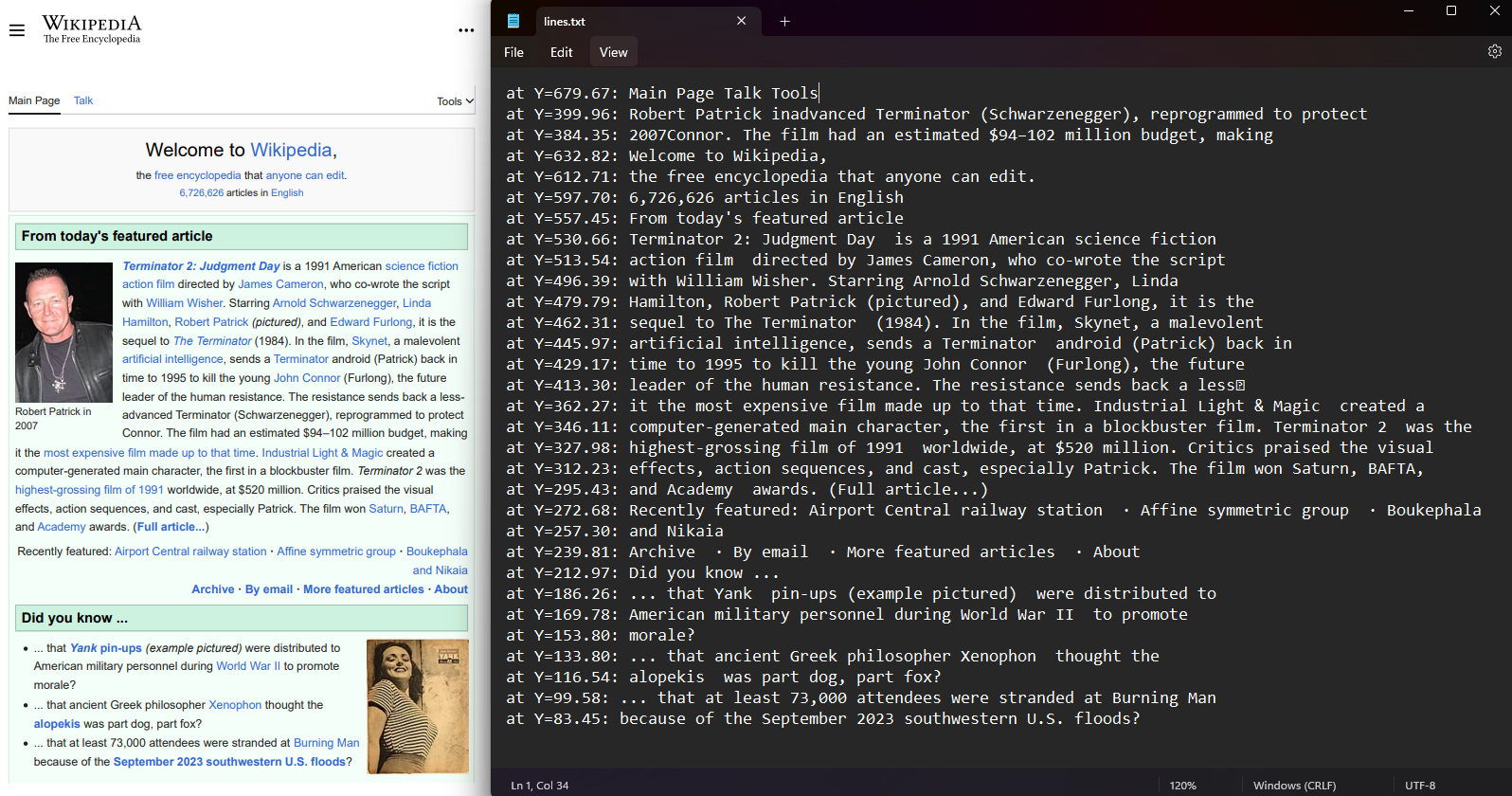
如何从 PDF 中提取图像?
使用ExtractAllImages方法从文档中提取所有嵌入的图像。 该方法返回包含AnyBitmap对象列表。 使用同一文档,我们提取了图片并将其导出到 "images "文件夹。 该功能支持图像归档、内容迁移和将 PDF 页面栅格化为图像以便进一步处理。
提取的图像可以保持原始质量,并可以 PNG、JPEG 和 BMP 等多种格式保存。对于云存储工作流,可将此功能与用于图像管理的 Azure Blob Storage 集成。
:path=/static-assets/pdf/content-code-examples/how-to/extract-text-and-images-extract-image.csusing IronPdf;
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract images
var images = pdf.ExtractAllImages();
for(int i = 0; i < images.Count; i++)
{
// Export the extracted images
images[i].SaveAs($"images/image{i}.png");
}Imports IronPdf
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract images
Private images = pdf.ExtractAllImages()
For i As Integer = 0 To images.Count - 1
' Export the extracted images
images(i).SaveAs($"images/image{i}.png")
Next i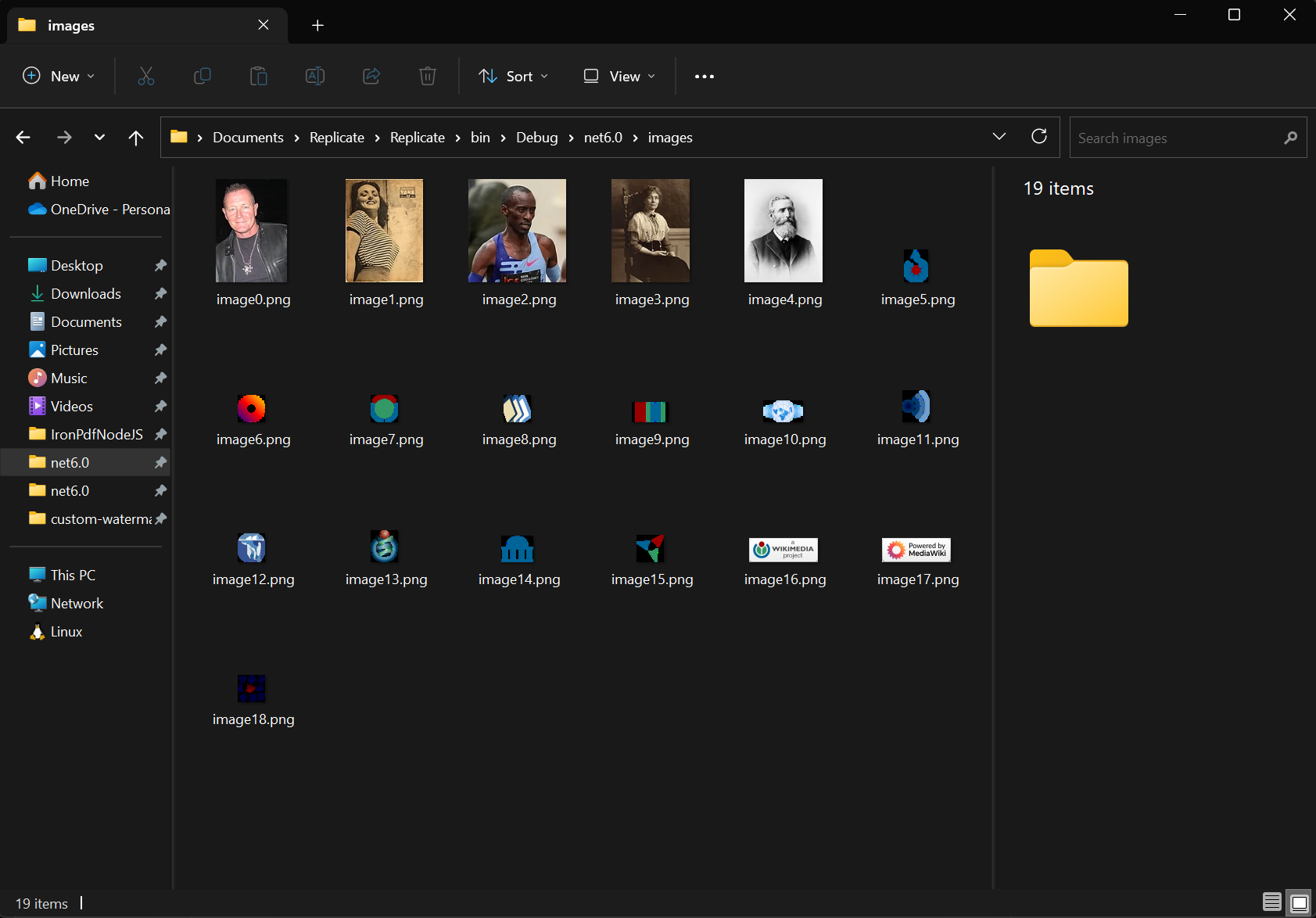
图像提取有哪些不同方法?
除了ExtractAllRawImages方法提取图像信息。 虽然byte[])返回。
ExtractAllRawImages方法在处理内存中的图像数据或与需要字节数组输入的系统集成时效果很好。 对于涉及将 PDF 导出到内存流的场景,原始字节数组格式提供了最佳的灵活性。
如何从特定 PDF 页面中提取内容?
从单个或多个指定页面中提取文本和图像。 使用ExtractTextFromPages方法从一页或多页中提取文本。 对于图像,使用ExtractImagesFromPages方法。
在处理只有特定部分包含相关内容的大型文档时,这种细粒度的控制很有帮助。 它还支持分割 PDF 和提取单个页面进行单独处理的功能。
:path=/static-assets/pdf/content-code-examples/how-to/extract-text-and-images-extract-text-single-multiple.csusing IronPdf;
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract text from page 1
string textFromPage1 = pdf.ExtractTextFromPage(0);
int[] pages = new[] { 0, 2 };
// Extract text from pages 1 & 3
string textFromPage1_3 = pdf.ExtractTextFromPages(pages);Imports IronPdf
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract text from page 1
Private textFromPage1 As String = pdf.ExtractTextFromPage(0)
Private pages() As Integer = { 0, 2 }
' Extract text from pages 1 & 3
Private textFromPage1_3 As String = pdf.ExtractTextFromPages(pages)何时应从特定页面而非所有页面提取内容?
在以下情况下从特定页面提取内容
- 处理包含某些区域内相关数据的大型PDF
- 实现独立处理页面的工作流程
- 构建需要增量内容显示或处理的应用程序
- 通过仅处理需要的页面优化内存使用
- 创建特定页面的搜索或索引功能
我应该了解哪些性能注意事项?
提取 PDF 内容时要考虑这些性能因素:
- 内存使用:从大型文档中单独提取页面以最小化内存消耗
- 处理时间:在适当时使用并行处理进行多页提取
- 文件大小:包含高分辨率图像的大型PDF需要更多的处理时间
- 存储:为提取大量高分辨率图像计划足够的硬盘空间
- 多线程:IronPDF支持多线程操作,在多核系统上提高性能
要使内存 PDF 获得最佳性能,请使用 内存流操作,以减少磁盘 I/O 开销。
常见问题解答
如何用 C# 从 PDF 文档中提取文本?
using IronPDF 的 ExtractAllText 方法从 PDF 文档中提取嵌入的文本。该方法会返回一个包含 PDF 中所有文本的字符串,各页之间用四个连续换行符隔开。IronPDF 可为国际语言和 UTF-8 字符保持正确的编码。
我可以通过编程从 PDF 文件中提取图像吗?
是的,IronPDF 提供了 ExtractAllImages 方法,用于从 PDF 文档中检索图形元素。您可以将提取的图像保存到磁盘或转换为其他格式,然后再将其嵌入到新文档中。
PDF 内容提取的主要用途是什么?
IronPDF 的提取工具支持各种工作流程,包括解析 PDF 以进行数据分析、将内容转换为可搜索格式、提取可视化元素进行存档,以及将内容重新用于编辑或转换为 HTML 等其他格式。
提取 PDF 内容需要多少行代码?
有了 IronPDF,您只需几行代码就能提取文本和图像。只需加载 PDF 文档,然后调用 ExtractAllText() 提取文本或 ExtractAllImages() 提取图像即可。
我可以从特定页面而不是整个文档中提取内容吗?
是的,IronPDF 允许您指定从中提取文本和图像的特定页面,让您精确控制从 PDF 文档中检索哪些内容。


还在滚动吗?
想快速获得证据? PM > Install-Package IronPdf
运行示例看着你的HTML代码变成PDF文件。










