

PDF 可访问性在C#中:创建、转换和验证PDF/UA文档
对于.NET开发人员来说,无障碍立法不再是未来的担忧。 就在这里,截止日期是真实的,处罚是可以执行的。 PDF/UA C#合规性、可访问的 PDF .NET生成、第 508 条 PDF C#合规性以及WCAG PDF C# 合规性现在已成为任何构建涉及政府、医疗保健、教育、法律或金融服务的文档工作流程的团队的常规要求。 IronPDF提供了标记的PDF引擎,RenderHtmlAsPdfUA方法,批量转换功能和跨平台.NET运行时支持,以使您的PDF输出符合PDF/UA-1和PDF/UA-2标准,无论您是转换遗留档案还是在运行时从HTML生成可访问文档。
TL;DR:快速入门指南
本教程涵盖了 C# 中的 PDF/UA 可访问性,从监管背景到大规模的实施、验证和修复。
-适用对象:负责生成、转换或分发 PDF 的应用程序的文档可访问性的.NET开发人员、架构师和合规负责人。 这包括为第 508 条款审计做准备的政府承包商、构建无障碍报告管道的 SaaS 团队以及根据 ADA 第二章截止日期规划文档修复项目的企业架构师。
- 您将构建的内容:PDF/UA-1和PDF/UA-2转换使用
ConvertToPdfUA进行内存转换,使用并行处理和错误处理进行批量修复管线,并使用veraPDF和Matterhorn Protocol进行验证工作流。 -运行平台: .NET 6+、. .NET Framework 4.6.2+、. .NET标准2.0。Windows、Linux、macOS、Docker、Azure 和 AWS。 所有渲染均使用 IronPDF 内置的 Chromium 引擎,不依赖任何外部浏览器。 -何时使用此方法:当您的 PDF 需要满足第 508 节、ADA 第二章(2026 年 4 月/2027 年截止日期)、欧盟无障碍法案(2025 年 6 月)或组织 WCAG 2.1 AA 级政策规定的无障碍标准时。 -从技术角度来看,这很重要: IronPDF 的 Chromium 渲染引擎通过转换保留 HTML 语义结构,生成带标签的 PDF,其中标题、列表、表格和替代文本直接映射到 PDF 结构元素。 与适用于现有文件的单一方法SaveAsPdfUA转换结合,您可以同时获得生成路径和修复路径,而无需手动标记操作。
只需两行代码即可将现有 PDF 文件转换为 PDF/UA 格式:
购买或注册 IronPDF 30 天试用版后,请在应用程序的开头添加许可证密钥。
:path=/static-assets/pdf/content-code-examples/tutorials/pdf-accessibility-csharp-pdfua-tutorial-2.csIronPdf.License.LicenseKey = "KEY";
Imports IronPdf
IronPdf.License.LicenseKey = "KEY"今天在您的项目中使用 IronPDF,免费试用。
目录
-理解标准 -什么是 PDF/UA?为什么现在强制要求使用 PDF/UA? 法律转折点 PDF/UA 实际需要什么 PDF/UA 与 WCAG:两种标准如何协同运作 -追溯要求 PDF 版本和 UA 版本之间有什么区别?
- PDF/UA-1(ISO 14289-1,基于 PDF 1.7)
- PDF/UA-2(ISO 14289-2:2024,基于 PDF 2.0)
- WTPDF(良好标记的 PDF)及其关联性 -你应该选择哪个版本? -从 HTML 生成 如何从 HTML 创建无障碍 PDF? 编写易于访问的 HTML
- 字体、色彩空间和元数据要求。 自动化无法发现的手动检查 大规模修复 如何大规模修复不合规的PDF文件? -批量将文档库转换为 PDF/UA 格式 -实现 80-90% 的自动化无障碍转换 -优先进行补救 -将 PDF/UA 与合并、签名和元数据工作流程相结合 -实际应用
什么是PDF/UA?为什么现在强制要求使用PDF/UA?
过去,PDF 可访问性通常是团队最终才会考虑的事情。 这是最佳实践,而非硬性要求。 情况已经改变了。 多个重叠的法规和严格的截止日期现时使得PDF/UA 合规非常紧迫。 不合规的后果范围从审计发现到关于软件产生的几个月或几年前文档的诉讼。
法律转折点
三项监管发展趋势共同促使 PDF/UA 合规性变得迫切。
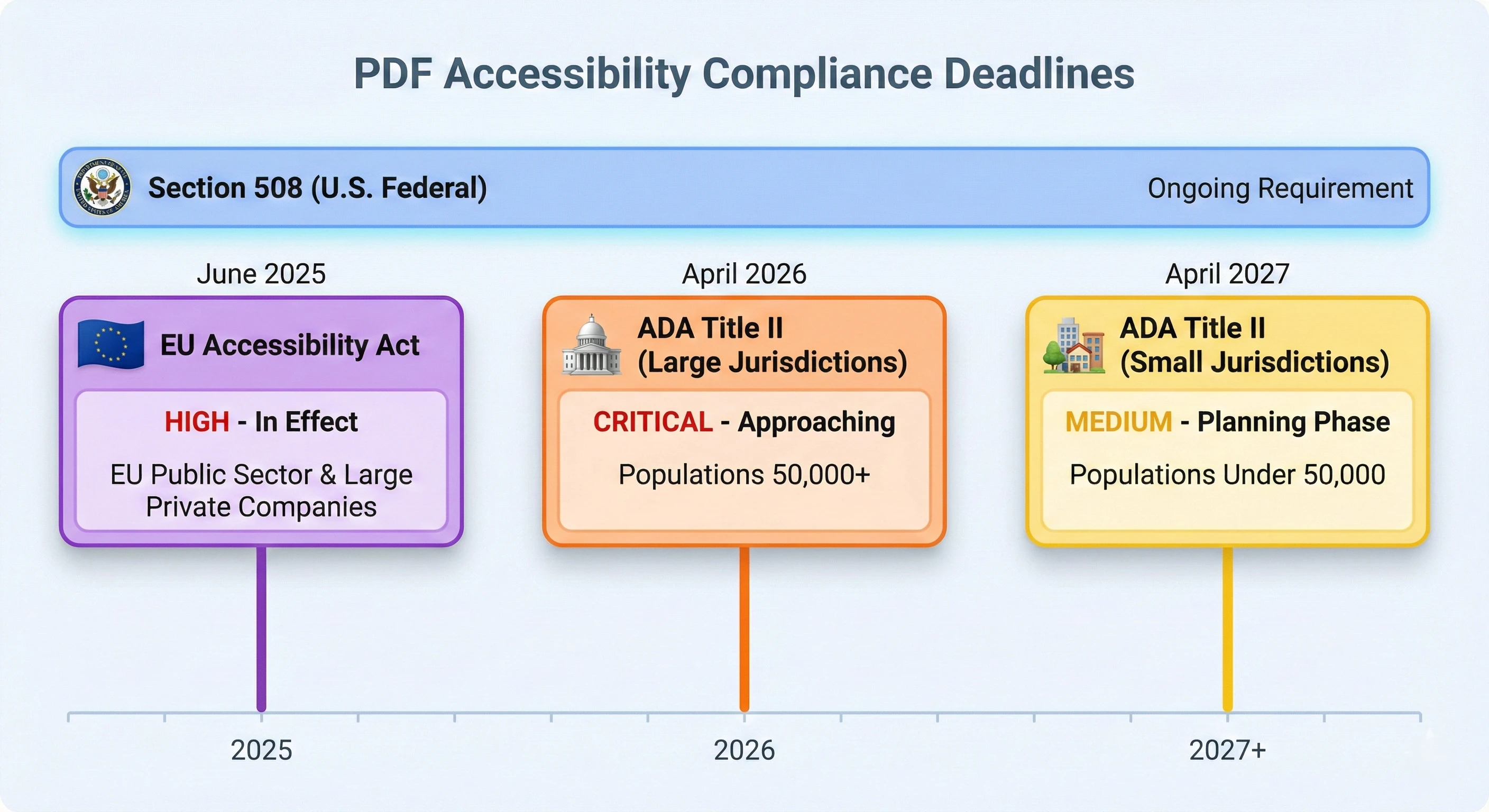
这些并非理论上的风险。 无障碍诉讼案件逐年增加,法院也一直认为电子文档属于残疾歧视法的管辖范围。 将无障碍功能视为未来问题的组织越来越发现自己要为几个月甚至几年前其软件生成的文档辩护,以应对投诉、审计结果和诉讼。
《康复法案》第508条要求美国 多年来,联邦机构及其承包商一直在生产易于使用的电子信息技术。 PDF文件已明确纳入涵盖范围。 如果您的软件生成的文件会被联邦机构使用或代表联邦机构使用,则这些文件必须能够被访问。 司法部负责调查投诉,并对不合规的组织采取强制措施。
美国残疾人法案第二章将无障碍义务扩展到州和地方政府。 美国司法部于 2024 年发布的最终规则规定,人口超过 5 万的实体必须在 2026 年 4 月之前完成合规,人口较少的实体必须在 2027 年 4 月之前完成合规。 范围很广:政府网站上发布的、通过电子邮件分发的或通过面向民众的应用程序生成的每个 PDF 文件都必须符合 WCAG 2.1 AA 级标准。 其中包括会议议程、预算文件、许可证申请、法庭记录、分区地图和议会会议记录等多种文件类型。
《欧洲无障碍法案》(EAA)于 2025 年 6 月生效,要求在欧盟销售的产品和服务必须符合无障碍要求。 对于服务于欧盟客户的软件公司而言,其应用程序生成的文档必须易于访问。 这不仅限于政府; 它适用于私营部门的各种类别的产品和服务。
PDF/UA 实际需要什么
PDF/UA(ISO 14289)定义了 PDF 必须满足的技术要求,以便辅助技术能够可靠地处理它。 一份符合规范的文件必须包含:
完整的标记结构。 每段有意义的内容都必须使用标准PDF标签在逻辑结构树中表示:<l>用于列表。 纯粹装饰性的内容必须标记为人工制品,以便屏幕阅读器跳过它。
正确的阅读顺序。标签树必须反映内容的逻辑阅读顺序,而不是内容在页面上的视觉呈现顺序。 对于多列布局或带有侧边栏的文档,这种区别非常重要。
为非文本内容提供备用文本。 传达信息的每个图像、图表和示意图必须在其<Figure>标签中附有备用文本。 装饰性图像必须标记为文物。
正确的元数据。文档必须声明其自然语言(例如,英语用"en"表示),具有有意义的标题,并在其 XMP 元数据中包含 PDF/UA 标识符。
嵌入字体并进行 Unicode 映射。所有字体都必须嵌入,并且必须存在 Unicode 字符映射(ToUnicode CMap),以便能够准确提取和朗读文本。
PDF/UA 与 WCAG:两种标准如何协同运作
开发人员经常会问,他们应该以 PDF/UA 为目标还是以 WCAG 为目标。 答案是两者兼有,因为它们在不同的层面上运作。
WCAG(Web 内容无障碍指南)定义了 Web 内容的无障碍原则和成功标准。 这是《美国残疾人法》第 508 章、《美国残疾人法》第二章和《平等机会法案》所引用的标准。 WCAG 告诉您无障碍内容应该达到什么标准:可感知、可操作、可理解和稳健。
PDF/UA 规定了如何在 PDF 文件中实现这些目标。它是技术实现标准。 符合 PDF/UA 标准的 PDF 将满足适用于文档内容的 WCAG 成功标准。 这两个标准是互补的,而不是相互竞争的。 实际上,如果您的工作流程能够生成带有标签、结构良好的 PDF 文件,并通过 PDF/UA 验证,那么您在符合 WCAG 标准方面也处于有利地位。
追溯要求
有一点会让各机构措手不及:这些规定不仅适用于新文件。 网站上发布的或通过应用程序分发的现有 PDF 文件也可能需要进行修复。 ADA 第二章要求州和地方政府发布的网络内容(包括 PDF)符合 WCAG 2.1 AA 级标准。 对于历史文件,没有一概豁免。
这使得程序化转化工具变得至关重要。 手动修复数千个PDF文件是不切实际的。 我们将在本教程的后续部分介绍批量修复模式。
PDF 版本和 UA 版本有什么区别?
PDF/UA-1(ISO 14289-1,基于 PDF 1.7)
PDF/UA-1 于 2012 年发布,至今仍是该标准最广泛采用的版本。 它以 PDF 1.7 规范为基础,定义了一套全面的带标签 PDF 结构、元数据、字体和辅助技术兼容性要求。 大多数验证工具,包括 veraPDF 和 Adobe Acrobat 的辅助功能检查器,都以PDF/UA-1作为其主要目标。
如果您正在启动一个新的无障碍项目,并且需要与现有工具和工作流程广泛兼容,那么PDF/UA-1是安全的默认选择。 它符合《美国残疾人法案》第 508 条、《美国残疾人法案》第二章和《欧盟无障碍法案》的要求。
PDF/UA-2(ISO 14289-2:2024,基于 PDF 2.0)
PDF/UA-2 于 2024 年发布,是一次重大更新。 它基于 PDF 2.0 规范(ISO 32000-2:2020)构建,改进了对现代 PDF 功能的处理,包括注释、表单域、多媒体内容和复杂文档结构。PDF/UA-2也更好地与不断发展的网络无障碍标准保持一致。
IronPDF同时支持这两个版本。 导出时可以指定要导出的目标文件,我们将在下面的代码示例中进行演示。
WTPDF(良好标记的 PDF)及其关联性
您可能会遇到对 WTPDF 的引用,它是 Well-Tagged PDF 的缩写。 WTPDF 由 PDF 协会出版,是一套技术指南,阐明了如何创建正确标记的 PDF。 它不是一个独立的标准,而是PDF/UA-2和 PDF 2.0 的实用补充。WTPDF 提供了标签使用、结构元素映射和内容标记的详细规则,这些规则超出了 PDF/UA 规范本身的定义。 你可以把它看作是与正式标准并行的实施指南。
应该选择哪个版本?
| PDF/UA-1 | PDF/UA-2 | |
|---|---|---|
| 已发布 | 2012 | 2024 |
| 基本规格 | PDF 1.7(ISO 32000-1) | PDF 2.0(ISO 32000-2) |
| 监管覆盖范围 | 《美国残疾人法案》第508条、《美国残疾人法案》第二章、《欧盟无障碍法案》 | 与现有法规向前兼容 |
| 验证工具 | veraPDF、Adobe Acrobat Pro、PAC 2024 | veraPDF(支持率不断提高) |
| 表单字段语义 | 标准 | 增强型(更丰富的辅助功能元数据) |
| 最适合 | 当今的大多数项目 | 需要 PDF 2.0 功能的新系统 |
对于当今大多数项目而言, PDF/UA-1是正确的选择。它拥有最广泛的工具支持、最成熟的验证生态系统,并且满足所有现行的监管要求。 如果您需要特定的PDF 2.0功能如增强的表单字段语义、改进的注解处理,或对基于PDF 2.0的新兴标准的前向兼容性,请选择PDF/UA-2。
IronPDF默认使用PDF/UA-1 ,当您准备好时,可以轻松切换到 PDF/UA-2。
如何从 HTML 创建无障碍 PDF?
如果您的应用程序从 HTML 内容(报告、发票、报表、信函)生成 PDF ,那么您就有机会从一开始就构建可访问性,而不是事后进行补救。 IronPDF的RenderHtmlAsPdfUA方法直接将HTML渲染为符合PDF/UA的输出,结果的质量在很大程度上依赖于HTML输入的质量。
编写易于访问的 HTML
无障碍HTML可以自然地转换为无障碍的带标签PDF结构。 以下是一些最重要的做法:
使用语义的HTML元素。 使用<section>用于页面结构。
为每个有意义的图像提供备用文本。 在所有alt属性。 对于装饰性图像,使用一个空白的alt=""以表示该图像应被视为工件。
保持一个合乎逻辑的标题层次结构。 以一个<h1>开始,并且不要跳过层次。 从<h3>的文档将在PDF输出中产生一个破损的标题树。
标记表单字段。 如果您的HTML包含表单元素,使用<label>元素关联。
设置文档语言。 在您的<html lang="en">)。
使用RenderHtmlAsPdfUA渲染HTML为PDF/UA
以下是一个完整的示例,它将可访问的 HTML 文档直接渲染为 PDF/UA:
将带有语义标题、数据表、有序列表和替代文本图像的 HTML 字符串直接渲染到符合 PDF/UA 规范的文档中。
:path=/static-assets/pdf/content-code-examples/tutorials/pdf-accessibility-csharp-pdfua-tutorial/pdfua-render-html.csusing IronPdf;
ChromePdfRenderer renderer = new ChromePdfRenderer();
string accessibleHtml = @"
<!DOCTYPE html>
<html lang='en'>
<head>
<meta charset='UTF-8'>
<title>Quarterly Accessibility Report</title>
<style>
body {
font-family: Arial, sans-serif;
line-height: 1.6;
color: #333;
max-width: 800px;
margin: 0 auto;
padding: 20px;
}
h1 {
color: #1a1a1a;
border-bottom: 2px solid #0066cc;
padding-bottom: 8px;
}
h2 {
color: #2a2a2a;
margin-top: 24px;
}
table {
border-collapse: collapse;
width: 100%;
margin: 16px 0;
}
th, td {
border: 1px solid #ccc;
padding: 10px;
text-align: left;
}
th {
background-color: #f0f0f0;
font-weight: bold;
}
.summary {
background-color: #f9f9f9;
padding: 16px;
border-left: 4px solid #0066cc;
margin: 16px 0;
}
</style>
</head>
<body>
<h1>Q3 2025 Accessibility Compliance Report</h1>
<div class='summary'>
<p>This report summarizes the accessibility remediation progress
for all public-facing PDF documents across the organization.</p>
</div>
<h2>Document Inventory</h2>
<p>The following table shows the current status of document
remediation by department.</p>
<table>
<thead>
<tr>
<th scope='col'>Department</th>
<th scope='col'>Total Documents</th>
<th scope='col'>Compliant</th>
<th scope='col'>Pending</th>
</tr>
</thead>
<tbody>
<tr>
<td>Legal</td>
<td>1,247</td>
<td>892</td>
<td>355</td>
</tr>
<tr>
<td>Finance</td>
<td>3,891</td>
<td>3,102</td>
<td>789</td>
</tr>
<tr>
<td>Human Resources</td>
<td>567</td>
<td>401</td>
<td>166</td>
</tr>
</tbody>
</table>
<h2>Key Findings</h2>
<p>Three areas require immediate attention before the
April 2026 deadline:</p>
<ol>
<li>Legacy court filing templates lack heading
structure entirely.</li>
<li>Financial statement PDFs generated before 2023
have no tagged content.</li>
<li>HR onboarding packets contain scanned images
without OCR text layers.</li>
</ol>
<h2>Remediation Timeline</h2>
<p>The project team recommends prioritizing public-facing
documents first, followed by internal documents accessed by
more than 50 employees.</p>
<img src='timeline-chart.png'
alt='Gantt chart showing remediation phases: Phase 1
covers public documents from October through December
2025, Phase 2 covers internal documents from January
through March 2026.' />
</body>
</html>";
// Render directly to PDF/UA-compliant output
PdfDocument pdf = renderer.RenderHtmlAsPdfUA(accessibleHtml);
// Set document metadata (required by PDF/UA)
pdf.MetaData.Title = "Q3 2025 Accessibility Compliance Report";
pdf.MetaData.Author = "Compliance Department";
pdf.SaveAs("accessibility-report-pdfua.pdf");
Imports IronPdf
Dim renderer As New ChromePdfRenderer()
Dim accessibleHtml As String = "
<!DOCTYPE html>
<html lang='en'>
<head>
<meta charset='UTF-8'>
<title>Quarterly Accessibility Report</title>
<style>
body {
font-family: Arial, sans-serif;
line-height: 1.6;
color: #333;
max-width: 800px;
margin: 0 auto;
padding: 20px;
}
h1 {
color: #1a1a1a;
border-bottom: 2px solid #0066cc;
padding-bottom: 8px;
}
h2 {
color: #2a2a2a;
margin-top: 24px;
}
table {
border-collapse: collapse;
width: 100%;
margin: 16px 0;
}
th, td {
border: 1px solid #ccc;
padding: 10px;
text-align: left;
}
th {
background-color: #f0f0f0;
font-weight: bold;
}
.summary {
background-color: #f9f9f9;
padding: 16px;
border-left: 4px solid #0066cc;
margin: 16px 0;
}
</style>
</head>
<body>
<h1>Q3 2025 Accessibility Compliance Report</h1>
<div class='summary'>
<p>This report summarizes the accessibility remediation progress
for all public-facing PDF documents across the organization.</p>
</div>
<h2>Document Inventory</h2>
<p>The following table shows the current status of document
remediation by department.</p>
<table>
<thead>
<tr>
<th scope='col'>Department</th>
<th scope='col'>Total Documents</th>
<th scope='col'>Compliant</th>
<th scope='col'>Pending</th>
</tr>
</thead>
<tbody>
<tr>
<td>Legal</td>
<td>1,247</td>
<td>892</td>
<td>355</td>
</tr>
<tr>
<td>Finance</td>
<td>3,891</td>
<td>3,102</td>
<td>789</td>
</tr>
<tr>
<td>Human Resources</td>
<td>567</td>
<td>401</td>
<td>166</td>
</tr>
</tbody>
</table>
<h2>Key Findings</h2>
<p>Three areas require immediate attention before the
April 2026 deadline:</p>
<ol>
<li>Legacy court filing templates lack heading
structure entirely.</li>
<li>Financial statement PDFs generated before 2023
have no tagged content.</li>
<li>HR onboarding packets contain scanned images
without OCR text layers.</li>
</ol>
<h2>Remediation Timeline</h2>
<p>The project team recommends prioritizing public-facing
documents first, followed by internal documents accessed by
more than 50 employees.</p>
<img src='timeline-chart.png'
alt='Gantt chart showing remediation phases: Phase 1
covers public documents from October through December
2025, Phase 2 covers internal documents from January
through March 2026.' />
</body>
</html>"
' Render directly to PDF/UA-compliant output
Dim pdf As PdfDocument = renderer.RenderHtmlAsPdfUA(accessibleHtml)
' Set document metadata (required by PDF/UA)
pdf.MetaData.Title = "Q3 2025 Accessibility Compliance Report"
pdf.MetaData.Author = "Compliance Department"
pdf.SaveAs("accessibility-report-pdfua.pdf")输出
如您所见,语义化的 HTML 元素(标题、带有列标题的数据表、有序列表和替代文本图像)在渲染的输出中被保留为正确的 PDF/UA 结构标签。
通过转换来保护结构
IronPDF使用嵌入式 Chromium 渲染引擎,该引擎与 Google Chrome 和 Microsoft Edge 所使用的技术相同。 这对于可访问性至关重要,因为 Chromium 已经能够理解 HTML 语义。 IronPDF将 HTML 渲染成 PDF/UA 时,会将 HTML 元素映射到对应的 PDF 标签:
<h6>标签。 <p>段落标签。 <td>结构元素。 <li>(列表项)子条目。 <Figure>。
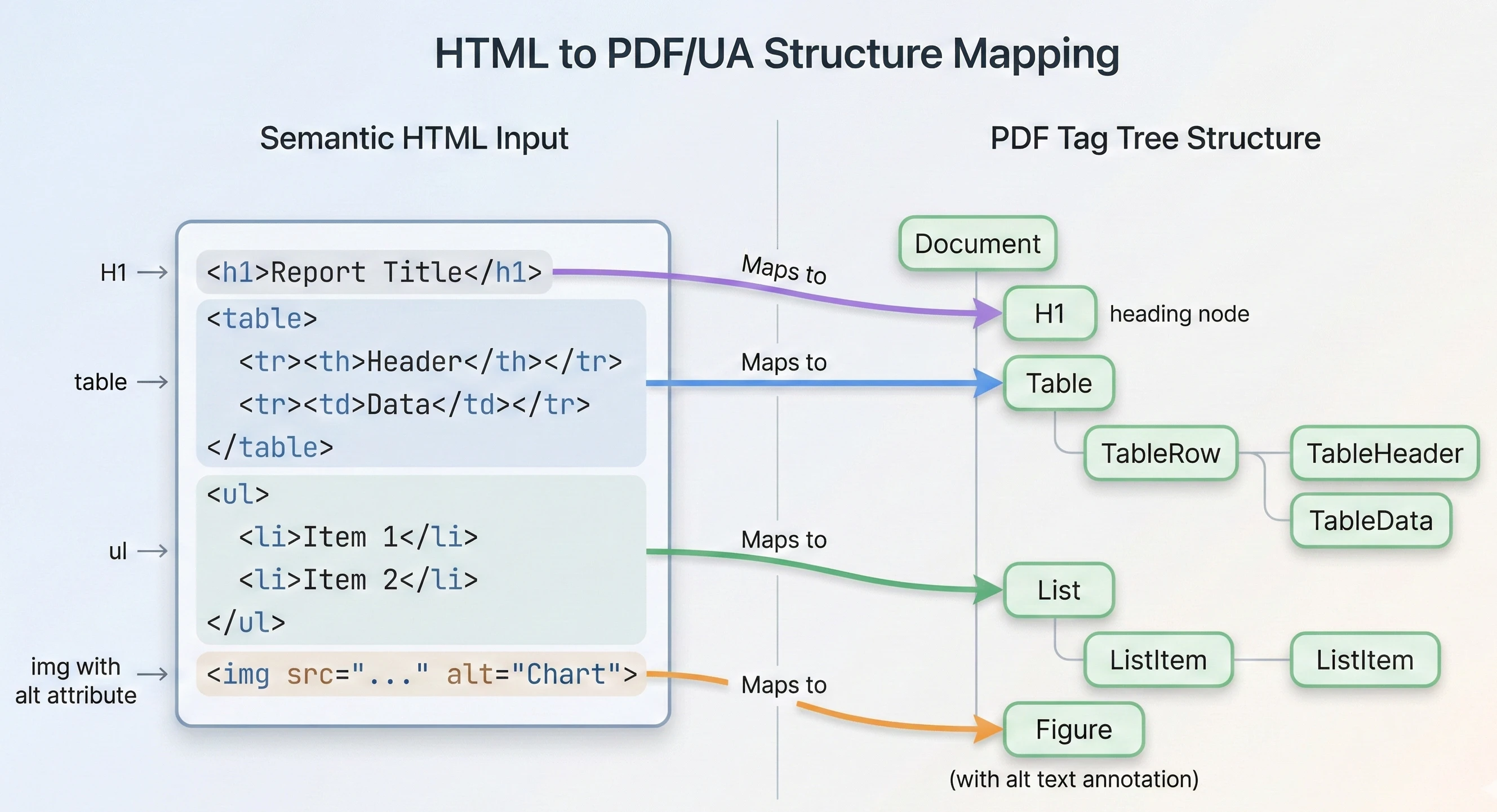
此映射过程自动进行。 您无需手动构建 PDF 标签树或编写任何结构元素代码。
破坏可访问性的常见HTML模式
即使是编写通常很规范的 HTML 代码的开发人员,有时也会使用导致 PDF 输出无法访问的模式。 注意以下几点:
为一切都使用<div>。 完全由未样式化的<div>元素构建的文档会产生一个扁平的、非结构化的标记树。 屏幕阅读器无法对其进行有效导航。 请改用语义元素。
使用CSS网格或弹性盒模型模拟表格。 使用CSS在视觉网格布局中显示的数据但不是实际的<table>元素不会在PDF中生成正确的表格标签。 如果内容是表格数据,请使用一个真正的<table>。
跳过标题级别。 从<h3>在标题层次结构中创建了一个缺口,可访问性检查工具会将其标记为失败。
没有alt文本的图像。 任何缺少<Figure>标签,这直接违反了PDF/UA。
嵌入在图像中的文本。如果您的 HTML 代码包含以图像形式呈现的文本(例如表格截图、栅格化图表),则屏幕阅读器无法读取这些内容。 尽可能使用真正的 HTML 文本,并为所有剩余的图像提供全面的替代文本。
如何选择PDF/UA-1还是 PDF/UA-2?
默认输出(PDF/UA-1)
默认情况下, IronPDF生成PDF/UA-1输出。 除非你有特殊原因需要针对 PDF/UA-2,否则请坚持使用默认设置。
:path=/static-assets/pdf/content-code-examples/tutorials/pdf-accessibility-csharp-pdfua-tutorial/pdfua-default-output.csusing IronPdf;
PdfDocument pdf = PdfDocument.FromFile("standard-report.pdf");
// Default: saves as PDF/UA-1
pdf.SaveAsPdfUA("accessible-report.pdf");
Imports IronPdf
Dim pdf As PdfDocument = PdfDocument.FromFile("standard-report.pdf")
' Default: saves as PDF/UA-1
pdf.SaveAsPdfUA("accessible-report.pdf")输出
同一份报告现在符合PDF/UA-1标准,具有完整的标签结构,并且 ISO 14289-1 标识符嵌入在其 XMP 元数据中。
导出为PDF/UA-2格式并带有版本参数
当您需要PDF/UA-2版本时,请指定版本参数:
:path=/static-assets/pdf/content-code-examples/tutorials/pdf-accessibility-csharp-pdfua-tutorial/pdfua-export-pdfua2.csusing IronPdf;
PdfDocument pdf = PdfDocument.FromFile("modern-form.pdf");
// Export as PDF/UA-2 (based on PDF 2.0)
pdf.SaveAsPdfUA("accessible-form-ua2.pdf", PdfUAVersions.PdfUA2);
Imports IronPdf
Dim pdf As PdfDocument = PdfDocument.FromFile("modern-form.pdf")
' Export as PDF/UA-2 (based on PDF 2.0)
pdf.SaveAsPdfUA("accessible-form-ua2.pdf", PdfUAVersions.PdfUA2)输出
表单以PDF/UA-2格式导出,使用 PDF 2.0 内部结构,并为表单字段提供更丰富的辅助功能元数据。
您也可以在内存中进行转换并单独保存:
:path=/static-assets/pdf/content-code-examples/tutorials/pdf-accessibility-csharp-pdfua-tutorial/pdfua-in-memory-pdfua2.csusing IronPdf;
PdfDocument pdf = PdfDocument.FromFile("complex-document.pdf");
// Convert to PDF/UA-2 in memory
pdf.ConvertToPdfUA(PdfUAVersions.PdfUA2);
// Perform additional modifications
pdf.MetaData.Title = "Complex Document - Accessible Version";
// Save the converted document
pdf.SaveAs("complex-document-accessible.pdf");
Imports IronPdf
Dim pdf As PdfDocument = PdfDocument.FromFile("complex-document.pdf")
' Convert to PDF/UA-2 in memory
pdf.ConvertToPdfUA(PdfUAVersions.PdfUA2)
' Perform additional modifications
pdf.MetaData.Title = "Complex Document - Accessible Version"
' Save the converted document
pdf.SaveAs("complex-document-accessible.pdf")输出
内存中转换后的文档保存为PDF/UA-2格式。注意:PDF/UA-2 内部使用 PDF 2.0 格式。 切换前请确认您的下游工具支持 PDF 2.0。
何时使用 PDF/UA-2
当您的文档依赖于 PDF 2.0 功能而PDF/UA-1无法完全满足这些功能时,请考虑使用 PDF/UA-2。 这包括增强表单字段的可访问性,提供更丰富的语义信息;改进注释处理,支持评论、标记和审阅工作流程;更好地支持嵌入 PDF 中的多媒体内容;以及向前兼容基于 PDF 2.0 的新兴辅助功能标准。
对于当今大多数合规项目而言,PDF/UA-1 都能胜任。PDF/UA-2是面向未来的选择,适用于不需要使用传统工具处理输出的新系统。
如何验证 PDF/UA 合规性?
创建 PDF/UA 文档只是工作的一半。 您需要验证输出结果是否确实符合标准。 验证可以发现开发过程中容易被忽略的问题,并提供合规性审计所需的书面证据。
使用 VeraPDF 进行验证
veraPDF是一个免费的开源命令行和 GUI 工具,用于根据 PDF/UA 和 PDF/A 标准检查 PDF 文件。 传递转换后的文件和ua1配置文件进行检查:
输入
IronPDF 生成的 PDF/UA 文档已准备好进行验证。 这是SaveAsPdfUA的输出。
verapdf --profile ua1 output-quarterly-report-accessible.pdfverapdf --profile ua1 output-quarterly-report-accessible.pdf输出
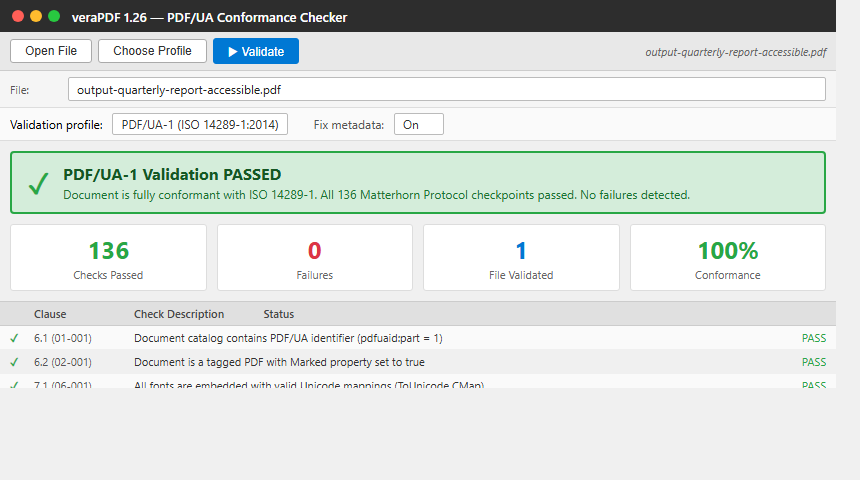
通过 136 项检查,0 项检查失败。 IronPDF输出完全符合 ISO 14289-1 标准。HTML 报告列出了 Matterhorn 协议的每个检查点及其结果。 将 CLI 集成到您的 CI/CD 管道中,以便在回归问题影响生产环境之前将其捕获。
了解马特洪峰协议
Matterhorn 协议是由 PDF 协会发布的一组测试条件,它精确地定义了如何检查 PDF 是否符合PDF/UA-1标准。 它将检查分为 31 个检查点,涵盖 136 种具体故障情况。 每个故障条件都对应PDF/UA-1规范中的一个条款。
例如,检查点 01 涵盖文档目录是否包含所需的 PDF/UA 标识符。 检查点 06 检查所有字体是否都嵌入了有效的 Unicode 映射。 第 13 项检查内容是图形是否有合适的替代文本。
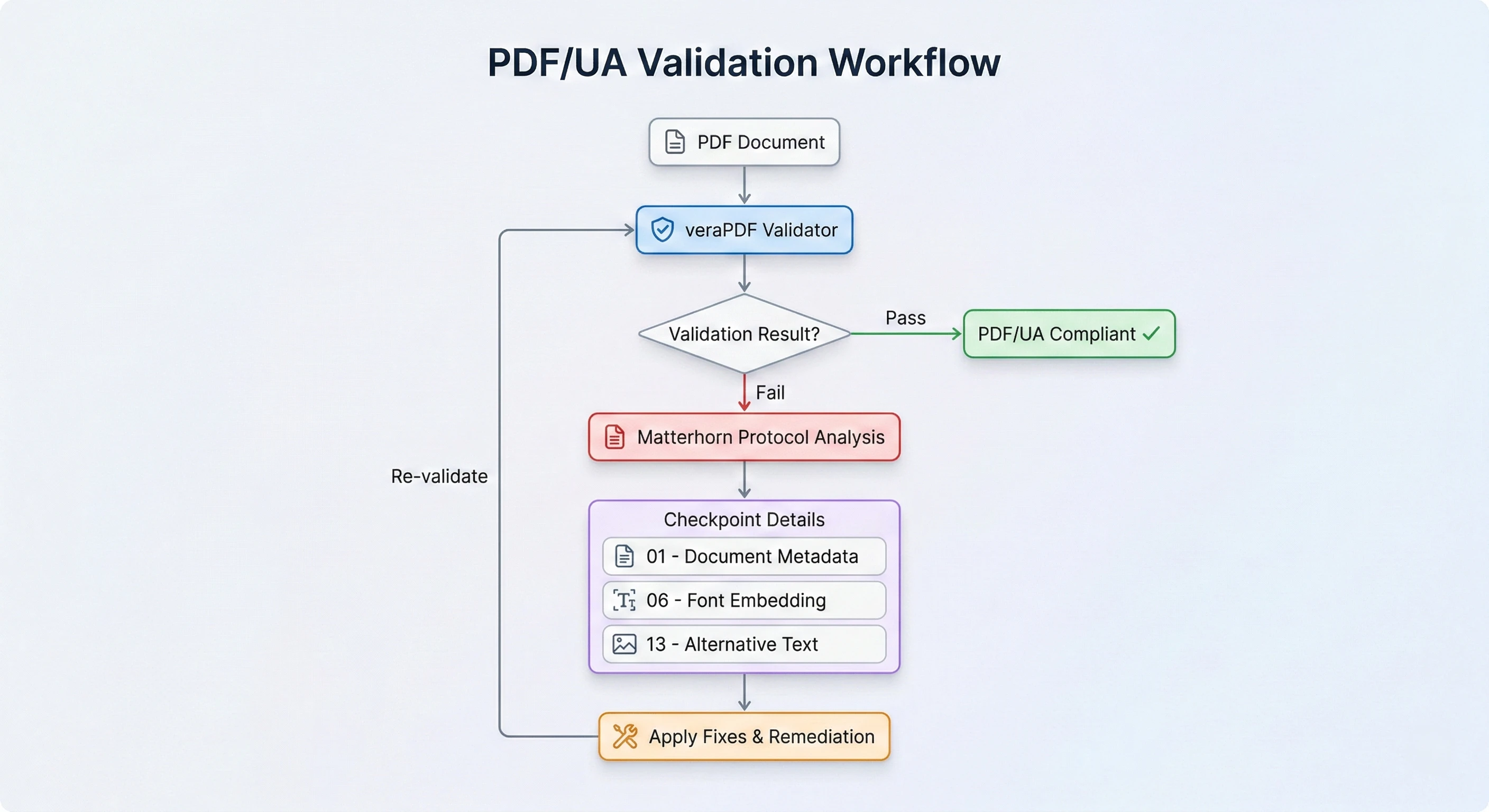
了解马特洪峰协议有助于您解读验证结果并确定修复的优先级。 并非所有失效条件都具有相同的重要性。 文档标题缺失的问题只需五分钟即可解决。 完全未添加标签的文档需要进行完整转换。
常见的合规性问题及解决方法
以下是在验证 PDF/UA 输出时最常出现的问题:
缺少文档标题。文档元数据必须包含标题条目,并且 ViewerPreferences 字典必须指定在窗口标题栏中显示标题(而不是文件名)。 解决方法是在保存之前设置元数据:
:path=/static-assets/pdf/content-code-examples/tutorials/pdf-accessibility-csharp-pdfua-tutorial/pdfua-fix-document-title.csusing IronPdf;
PdfDocument pdf = PdfDocument.FromFile("input.pdf");
// Set the required document title
pdf.MetaData.Title = "Annual Budget Report - FY2025";
pdf.SaveAsPdfUA("budget-report-accessible.pdf");
Imports IronPdf
Dim pdf As PdfDocument = PdfDocument.FromFile("input.pdf")
' Set the required document title
pdf.MetaData.Title = "Annual Budget Report - FY2025"
pdf.SaveAsPdfUA("budget-report-accessible.pdf")输出
现在输出的文件标题已通过检查,标题会显示在 PDF 查看器的窗口标题栏中,而不是文件名。
图片缺少替代文字。任何传达含义的图片都必须配有替代文字。 在渲染之前将其添加到源 HTML 中,或者直接修复源 PDF。
标题层级结构不正确。标题层级跳跃或顺序错乱的文档将无法通过验证。 转换前请先修正源文件中的标题结构。
字体未嵌入或缺少 Unicode 映射。这种情况通常发生在采用非标准字体编码的旧版 PDF 文件中。 IronPDF在转换过程中会处理字体嵌入,但对于年代久远或已损坏的源文件,可能需要特别注意。
字体、色彩空间和元数据要求
PDF/UA 对视觉呈现有特定的要求,自动化工具会进行检查。 所有字体都必须嵌入正确的 ToUnicode 映射。 文本必须能够以Unicode字符形式提取。 色彩空间必须与设备无关,或具有关联的ICC配置文件。表单字段必须具有正确的标签和描述。
IronPDF在转换过程中会自动处理字体嵌入、颜色空间和结构要求。 语言和元数据在代码中设置起来非常简单,正如本教程中的示例所示。
自动化无法发现的人工检查
无障碍设计的某些方面需要人工审核。 自动验证器可以告诉你图片有替代文本,但它们无法判断替代文本是否真的有用。 他们可以确认标题存在,但无法验证标题文本是否准确描述了后面的内容。
在工作流程中加入人工审核步骤,用于处理高优先级文档。 重点关注 alt 文本是否准确描述图像内容,线性阅读顺序是否合乎逻辑,链接文本是否具有描述性(而不仅仅是"点击这里"),以及语言声明是否与文档的实际内容相符。
其他验证工具
VeraPDF 是自动化 PDF/UA 一致性检查的标准工具,但其他工具也可以与其配合使用:
Adobe Acrobat Pro在"工具">"辅助功能">"完整检查"下包含辅助功能检查器。 它可用于开发过程中的快速视觉抽查,并生成易于阅读的报告。 虽然其对PDF/UA-1的覆盖范围不如 veraPDF 全面,但它在大多数团队中广泛可用。
PDF 协会推出的PAC 2024 (PDF 无障碍检查器,Windows 版免费)提供可视化标签树检查,以及针对 PDF/UA 和 WCAG 的一致性检查。 它特别适用于以可视化的方式检查阅读顺序和标题结构,而不是通过文本报告。
Acrobat Reader允许您直接在"视图">"显示/隐藏">"导航窗格">"标签"下打开"标签"面板。 这虽然不是一个验证器,但它可以快速直观地检查结构树,而无需使用 Acrobat Pro。
最可靠的方法是将 veraPDF 用于自动 CI/CD 检查,并结合在 Acrobat 或 PAC 中对高优先级文档进行手动检查。
如何大规模修复不合规的PDF文件?
对于拥有大型文档库的组织而言,逐个文件转换是不切实际的。 当审计发现您的档案不符合无障碍标准,或者当截止日期临近而您有数千份文档需要处理时,您需要一种程序化的方法,能够以最少的人工干预处理大量数据。
批量将文档库转换为 PDF/UA 格式
IronPDF是线程安全的,这意味着您可以并行处理多个文档。 这是一个具备并发控制、错误处理和进度报告功能的生产级批量转换实现:
:path=/static-assets/pdf/content-code-examples/tutorials/pdf-accessibility-csharp-pdfua-tutorial/pdfua-batch-conversion.csusing IronPdf;
using System;
using System.Collections.Concurrent;
using System.IO;
using System.Linq;
using System.Threading;
using System.Threading.Tasks;
public class PdfUaBatchConverter
{
private readonly SemaphoreSlim _semaphore;
private readonly ConcurrentBag<string> _failures;
private int _processed;
public PdfUaBatchConverter(int maxConcurrency = 4)
{
_semaphore = new SemaphoreSlim(maxConcurrency);
_failures = new ConcurrentBag<string>();
_processed = 0;
}
public async Task ConvertDirectoryAsync(
string inputDirectory,
string outputDirectory,
NaturalLanguages language = NaturalLanguages.English)
{
Directory.CreateDirectory(outputDirectory);
string[] pdfFiles = Directory.GetFiles(inputDirectory, "*.pdf");
int totalFiles = pdfFiles.Length;
Console.WriteLine($"Starting PDF/UA conversion: {totalFiles} files");
Console.WriteLine($"Concurrency: {_semaphore.CurrentCount} parallel operations");
Console.WriteLine($"Language: {language}");
Console.WriteLine(new string('-', 50));
var stopwatch = System.Diagnostics.Stopwatch.StartNew();
var tasks = pdfFiles.Select(async inputPath =>
{
await _semaphore.WaitAsync();
try
{
string fileName = Path.GetFileName(inputPath);
string outputPath = Path.Combine(outputDirectory, fileName);
using (PdfDocument pdf = PdfDocument.FromFile(inputPath))
{
pdf.SaveAsPdfUA(outputPath, NaturalLanguage: language);
}
int count = Interlocked.Increment(ref _processed);
// Log progress every 10 files
if (count % 10 == 0 || count == totalFiles)
{
double rate = count / stopwatch.Elapsed.TotalSeconds;
Console.WriteLine(
$" [{count}/{totalFiles}] " +
$"{rate:F1} files/sec");
}
}
catch (Exception ex)
{
_failures.Add(
$"{Path.GetFileName(inputPath)}: {ex.Message}");
Interlocked.Increment(ref _processed);
}
finally
{
_semaphore.Release();
}
});
await Task.WhenAll(tasks);
stopwatch.Stop();
// Summary report
Console.WriteLine(new string('-', 50));
Console.WriteLine($"Completed in {stopwatch.Elapsed.TotalSeconds:F1}s");
Console.WriteLine(
$"Succeeded: {totalFiles - _failures.Count} " +
$"Failed: {_failures.Count}");
if (_failures.Any())
{
Console.WriteLine("\nFailed files:");
foreach (string failure in _failures)
Console.WriteLine($" - {failure}");
// Write failures to log file for later review
File.WriteAllLines(
Path.Combine(outputDirectory, "_failures.log"),
_failures);
}
}
}
// Usage
var converter = new PdfUaBatchConverter(
maxConcurrency: Environment.ProcessorCount);
await converter.ConvertDirectoryAsync(
inputDirectory: @"C:\Documents\Legacy",
outputDirectory: @"C:\Documents\Accessible",
language: NaturalLanguages.English
);
Imports IronPdf
Imports System
Imports System.Collections.Concurrent
Imports System.IO
Imports System.Linq
Imports System.Threading
Imports System.Threading.Tasks
Public Class PdfUaBatchConverter
Private ReadOnly _semaphore As SemaphoreSlim
Private ReadOnly _failures As ConcurrentBag(Of String)
Private _processed As Integer
Public Sub New(Optional maxConcurrency As Integer = 4)
_semaphore = New SemaphoreSlim(maxConcurrency)
_failures = New ConcurrentBag(Of String)()
_processed = 0
End Sub
Public Async Function ConvertDirectoryAsync(inputDirectory As String, outputDirectory As String, Optional language As NaturalLanguages = NaturalLanguages.English) As Task
Directory.CreateDirectory(outputDirectory)
Dim pdfFiles As String() = Directory.GetFiles(inputDirectory, "*.pdf")
Dim totalFiles As Integer = pdfFiles.Length
Console.WriteLine($"Starting PDF/UA conversion: {totalFiles} files")
Console.WriteLine($"Concurrency: {_semaphore.CurrentCount} parallel operations")
Console.WriteLine($"Language: {language}")
Console.WriteLine(New String("-"c, 50))
Dim stopwatch = System.Diagnostics.Stopwatch.StartNew()
Dim tasks = pdfFiles.Select(Async Function(inputPath)
Await _semaphore.WaitAsync()
Try
Dim fileName As String = Path.GetFileName(inputPath)
Dim outputPath As String = Path.Combine(outputDirectory, fileName)
Using pdf As PdfDocument = PdfDocument.FromFile(inputPath)
pdf.SaveAsPdfUA(outputPath, NaturalLanguage:=language)
End Using
Dim count As Integer = Interlocked.Increment(_processed)
' Log progress every 10 files
If count Mod 10 = 0 OrElse count = totalFiles Then
Dim rate As Double = count / stopwatch.Elapsed.TotalSeconds
Console.WriteLine($" [{count}/{totalFiles}] {rate:F1} files/sec")
End If
Catch ex As Exception
_failures.Add($"{Path.GetFileName(inputPath)}: {ex.Message}")
Interlocked.Increment(_processed)
Finally
_semaphore.Release()
End Try
End Function)
Await Task.WhenAll(tasks)
stopwatch.Stop()
' Summary report
Console.WriteLine(New String("-"c, 50))
Console.WriteLine($"Completed in {stopwatch.Elapsed.TotalSeconds:F1}s")
Console.WriteLine($"Succeeded: {totalFiles - _failures.Count} Failed: {_failures.Count}")
If _failures.Any() Then
Console.WriteLine(vbCrLf & "Failed files:")
For Each failure As String In _failures
Console.WriteLine($" - {failure}")
Next
' Write failures to log file for later review
File.WriteAllLines(Path.Combine(outputDirectory, "_failures.log"), _failures)
End If
End Function
End Class
' Usage
Dim converter As New PdfUaBatchConverter(maxConcurrency:=Environment.ProcessorCount)
Await converter.ConvertDirectoryAsync(inputDirectory:="C:\Documents\Legacy", outputDirectory:="C:\Documents\Accessible", language:=NaturalLanguages.English)输出
一个处理文件的PDF/UA-1输出。该模式使用using的清理防止内存泄漏,以及运行中的每秒文件进度速率。
实现 80-90% 的自动化无障碍转换
剩余的 10-20% 合规工作需要人工判断:为复杂的图像添加有意义的替代文本,纠正不寻常布局的阅读顺序,以及为源文件中从未正确构建的文档分配语义标题。 自动审核完成后,对优先级最高的文档安排人工审核步骤。
优先考虑补救措施
并非所有文件都具有相同的合规风险。 有策略地集中精力进行补救工作:
优先处理面向公众的文件。任何发布在您网站上、分发给客户或提交给政府机构的文件都属于最高优先级。 这些文件最有可能引发投诉或审计。
其次是经常使用的内部文件。许多员工经常使用的培训材料、政策手册和人事表格应尽快进行整改。
存档文档和访问量低的文档会长期保存。访问量极少的旧文档可以分阶段进行修复,或者在有人提出请求时按需转换。
这种分诊方法可以让您在处理档案中剩余的大量文件的同时,展示最显眼文件的合规进展。
将 PDF/UA 与合并、签名和元数据工作流程相结合
在生产流程中,PDF/UA 转换很少单独发生。 您通常需要将其与其他文档操作结合使用。 IronPDF支持将这些功能串联起来使用:
输入
两份源文件:封面和财务报告,分别转换为 PDF/UA 格式并合并成一个可访问的文件。
:path=/static-assets/pdf/content-code-examples/tutorials/pdf-accessibility-csharp-pdfua-tutorial/pdfua-merge-metadata.csusing IronPdf;
// Load and convert to PDF/UA in memory
PdfDocument report = PdfDocument.FromFile("financial-report.pdf");
report.ConvertToPdfUA();
// Set comprehensive metadata
report.MetaData.Title = "Annual Financial Report 2025";
report.MetaData.Author = "Finance Department";
report.MetaData.Subject = "Year-end financial summary and analysis";
// Merge with a cover page (also converted to PDF/UA)
PdfDocument coverPage = PdfDocument.FromFile("cover-page.pdf");
coverPage.ConvertToPdfUA();
PdfDocument finalDocument = PdfDocument.Merge(coverPage, report);
// Save the combined, accessible document
finalDocument.SaveAs("annual-report-final-accessible.pdf");
// Dispose of intermediate documents
report.Dispose();
coverPage.Dispose();
Imports IronPdf
' Load and convert to PDF/UA in memory
Dim report As PdfDocument = PdfDocument.FromFile("financial-report.pdf")
report.ConvertToPdfUA()
' Set comprehensive metadata
report.MetaData.Title = "Annual Financial Report 2025"
report.MetaData.Author = "Finance Department"
report.MetaData.Subject = "Year-end financial summary and analysis"
' Merge with a cover page (also converted to PDF/UA)
Dim coverPage As PdfDocument = PdfDocument.FromFile("cover-page.pdf")
coverPage.ConvertToPdfUA()
Dim finalDocument As PdfDocument = PdfDocument.Merge(coverPage, report)
' Save the combined, accessible document
finalDocument.SaveAs("annual-report-final-accessible.pdf")
' Dispose of intermediate documents
report.Dispose()
coverPage.Dispose()输出
如您所见,这两个源文档现在已合并为一个符合 PDF/UA 标准的单个文件(封面页后跟财务报告),并应用了数字签名和全面的元数据。
PDF/UA 转换还兼容数字签名、密码保护和 PDF/A 归档格式。
PDF/UA 合规性在现实世界中有哪些应用案例?
PDF 可访问性要求在各个行业都会出现,但具体挑战因行业而异。
政府机构面临着最具体的期限。 受《美国残疾人法案》第二章约束的州和地方政府正在处理数万份历史文件(会议议程、许可证申请、分区地图等),以赶在 2026 年 4 月和 2027 年 4 月的截止日期前完成。 前面介绍的批量补救模式可以直接应用于此。
法律机构会产生大量的 PDF 文件:文件、简报、案件记录、合同和调查材料。 当文件以电子方式存档或与可能存在残疾的各方共享时,应遵守无障碍要求。 将 PDF/UA 转换功能构建到文档管理系统的输出阶段,可以确保无论内容是如何创作的,都能符合规范。
高等教育机构制作课程材料、教学大纲、研究论文、行政表格和机构报告。 根据《美国法典》第 508 条(适用于接受联邦资助的机构)和《美国残疾人法》第二章(适用于公共机构),这些文件必须易于访问。 HTML 转 PDF/UA 工作流程在这里特别有用,因为很多学术内容都源自网络内容或由模板生成。
医疗机构制作的患者账单、保险说明、检验结果和教育材料必须符合第 508 条和各州法律的规定,以便于获取。 这些文档通常包含表格数据和图表,因此正确的表格标记和图像替代文本尤为重要。
金融服务公司生成账户报表、披露文件、监管文件和报告。 其中许多文件在分发给客户或提交给政府机构时必须能够被访问。 大批量生产使得批量处理成为必要条件。
如何实现 PDF/UA 和 PDF/A 双重合规性?
当您既需要存档功能又需要无障碍访问功能时
PDF/A 是一种存档标准,可确保文档在长期内保持可查看和可复制性。 PDF/UA 是无障碍标准。 有些组织既需要永久保存的文件,也需要能够随时访问的文件。 这在政府档案保存、法律存档和医疗保健文档中很常见。
PDF/A-3a 合规级别特别要求既符合存档要求,又完全可访问("a"代表"可访问")。 如果达到 PDF/A-3a 标准,则相当于同时满足了 PDF/A 和 PDF/UA 的要求。
IronPDF同时支持这两种标准:
:path=/static-assets/pdf/content-code-examples/tutorials/pdf-accessibility-csharp-pdfua-tutorial/pdfua-dual-compliance.csusing IronPdf;
PdfDocument pdf = PdfDocument.FromFile("government-record.pdf");
// Convert to PDF/UA for accessibility
pdf.ConvertToPdfUA();
// Set required metadata
pdf.MetaData.Title = "Public Hearing Minutes - January 2025";
pdf.MetaData.Author = "City Clerk's Office";
// Convert to PDF/A for archival compliance
pdf.SaveAsPdfA("government-record-archive.pdf", PdfAVersions.PdfA3a);
Imports IronPdf
Dim pdf As PdfDocument = PdfDocument.FromFile("government-record.pdf")
' Convert to PDF/UA for accessibility
pdf.ConvertToPdfUA()
' Set required metadata
pdf.MetaData.Title = "Public Hearing Minutes - January 2025"
pdf.MetaData.Author = "City Clerk's Office"
' Convert to PDF/A for archival compliance
pdf.SaveAsPdfA("government-record-archive.pdf", PdfAVersions.PdfA3a)输出
该文档保存为 PDF/A-3a 格式,该格式同时满足存档 (PDF/A) 和可访问性 (PDF/UA) 要求。
将PDF/UA与数字签名相结合
需要身份验证的无障碍文档可以将 PDF/UA 转换与数字签名结合起来。 先进行PDF/UA转换,然后再签署文档:
:path=/static-assets/pdf/content-code-examples/tutorials/pdf-accessibility-csharp-pdfua-tutorial/pdfua-digital-signature.csusing IronPdf;
using IronPdf.Signing;
PdfDocument pdf = PdfDocument.FromFile("contract.pdf");
pdf.ConvertToPdfUA();
pdf.MetaData.Title = "Service Agreement - Executed Copy";
// Apply a digital signature to the accessible document
var signature = new PdfSignature("certificate.pfx", "password");
pdf.Sign(signature);
pdf.SaveAs("contract-accessible-signed.pdf");
Imports IronPdf
Imports IronPdf.Signing
Dim pdf As PdfDocument = PdfDocument.FromFile("contract.pdf")
pdf.ConvertToPdfUA()
pdf.MetaData.Title = "Service Agreement - Executed Copy"
' Apply a digital signature to the accessible document
Dim signature As New PdfSignature("certificate.pfx", "password")
pdf.Sign(signature)
pdf.SaveAs("contract-accessible-signed.pdf")为适应不断发展的标准而制定面向未来的文档
无障碍标准仍在不断发展。 WCAG 2.2 于 2023 年发布,WCAG 3.0 的制定工作正在进行中。 与PDF/UA-1相比,PDF/UA-2 更符合现代网络标准。 现在就将 PDF/UA 合规性构建到您的文档管道中,您可以创建一个可以随着标准的演变而更新的基础,而不是以后面临完全改造。
投资于易于访问的文档基础设施,其带来的回报远不止于合规性。 正确标记的 PDF 文件更易于搜索,在移动设备上重排效果更好,文本提取效果更佳,并且在不同的 PDF 查看器和平台上运行更可靠。 无障碍设计不仅仅是一项法律要求。 这是更好的工程设计。
下一步
PDF/UA合规性并非只需勾选一个复选框即可实现。 它涵盖了监管理解、正确的 HTML 编写、程序化转换、自动化验证以及现有档案的大规模修复。 但是,即使对于拥有庞大文档库和紧迫期限的组织来说,也存在着使其可控的工具和模式。 IronPDF提供带标记的PDF引擎,RenderHtmlAsPdfUA方法,批量处理能力,以及跨平台.NET支持,构成任何可访问的PDF .NET管道的基础。无论您需要为政府合同进行Section 508 PDF C#合规,为企业报告平台进行WCAG PDF合规C#,或为具有紧迫期限的文档修复项目进行PDF/UA C#转换,本教程中的模式为您提供了一个经过验证的框架。
从单个文件转换开始,以了解SaveAsPdfUA的产出。 使用 veraPDF 和 Matterhorn 协议验证输出结果。 构建使用语义元素和正确标题层次结构的易于访问的HTML模板。 然后,利用批量转换流程扩展现有归档系统。将 PDF/UA 与PDF/A 归档合规性、数字签名、元数据管理和PDF 压缩相结合,构建满足组织所有需求的文档工作流程。
如需更深入的参考, IronPDF PDF/UA 操作指南详细介绍了 API 接口,而PDF/A 归档教程则详细介绍了完整的归档合规工作流程(如果您需要同时使用这两种标准)。
准备好开始构建了吗? 下载IronPDF并试用免费试用版。 同一个库可以处理从单个文件可访问性转换到企业级修复管道的所有操作。 如果您对特定用例的实施、合规策略或架构有任何疑问,请联系我们的工程支持团队。 我们已经帮助各种规模的团队解决了文档可访问性问题,我们也乐意帮助您做到这一点。
常见问题解答
什么是 PDF/UA,为什么它很重要?
PDF/UA(通用无障碍)是一个ISO标准,适用于无障碍PDF文档,确保残障人士可以访问和交互PDF内容。这对于符合无障碍法规(如第508条和欧盟无障碍法)的要求至关重要。
如何使用C#将现有的PDF转换为PDF/UA?
可以使用IronPDF的SaveAsPdfUA方法在C#中将现有PDF转换为PDF/UA,从而通过嵌入必要的标签和结构确保您的文档符合无障碍标准。
IronPDF提供哪些工具用于将HTML渲染为无障碍PDF/UA?
IronPDF提供RenderHtmlAsPdfUA方法,允许开发人员将HTML内容转换为符合PDF/UA无障碍标准的标签PDF。
IronPDF能否处理大规模的PDF/UA修复项目?
可以,IronPDF通过并行处理管道支持批量修复大型文档档案,使其在处理大规模PDF/UA修复项目时高效。
如何使用IronPDF验证PDF/UA合规性?
IronPDF与veraPDF集成,这是一种帮助验证PDF/UA合规性与马特霍恩协议的工具,确保您的文档符合无障碍标准。
IronPDF可以解决哪些常见的PDF/UA合规性问题?
IronPDF可以帮助修复常见的合规性问题,例如缺少文档标题、缺少字体嵌入和断裂的标题层次结构。
IronPDF 兼容不同的 .NET 环境吗?
是的,IronPDF兼容.NET 6+、.NET Framework 4.6.2+和.NET Standard 2.0,并支持在Windows、Linux、macOS、Docker、Azure和AWS上部署。
如何使用IronPDF将PDF/UA文档与数字签名结合?
IronPDF允许您将符合PDF/UA标准的文档与数字签名结合,以增强文档安全性和合规性。
2026年和2027年4月的ADA Title II截止日期有何重要性?
这些截止日期标志着某些公共应用程序必须符合ADA Title II下更新的无障碍标准,使得像IronPDF这样的工具对于开发人员确保其PDF符合这些要求至关重要。
IronPDF可以帮助PDF/UA文档的元数据工作流吗?
可以,IronPDF支持将元数据工作流集成到PDF/UA文档中,这对于维护无障碍性和合规性至关重要。


还在滚动吗?
想快速获得证据? PM > Install-Package IronPdf
运行示例看着你的HTML代码变成PDF文件。










