


Extract Embedded Text and Images from PDFs in C
Extrayez à la fois le contenu textuel et les images des documents PDF en C# à l'aide d'appels de méthodes simples. Récupérer le contenu intégré pour l'éditer, l'analyser ou le réutiliser dans d'autres applications.
L'extraction de texte et d'image permet de récupérer le contenu textuel et les éléments graphiques des documents PDF. Accédez au contenu et réutilisez-le pour l'édition, la recherche, la conversion de texte dans d'autres formats ou l'enregistrement d'images en vue de leur réutilisation. Que vous ayez besoin d'parser des PDF en C# pour l'analyse de données, de convertir du contenu dans des formats de recherche ou d'extraire des éléments visuels pour l'archivage, IronPDF fournit des outils d'extraction complets.
Extrayez du texte et des images à l'aide d'IronPDF. Enregistrez les images extraites sur le disque ou convertissez-les dans un autre format avant de les intégrer dans de nouveaux documents. Cette flexibilité prend en charge les flux de travail nécessitant une transformation du contenu, tels que la conversion de PDF en HTML ou la réaffectation d'images extraites.
Démarrage rapide : Extraire du texte et des images avec IronPDF
Extrayez du texte et des images à partir de PDF en quelques lignes de code seulement. Ce quickstart montre comment récupérer du contenu incorporé dans des documents PDF à des fins de réutilisation et d'analyse du contenu. Extrayez du texte pour l'éditer ou enregistrez des images pour une utilisation ultérieure avec la solution rationalisée d'IronPDF.
-
Installez IronPDF avec le Gestionnaire de Packages NuGet
PM > Install-Package IronPdf -
Copiez et exécutez cet extrait de code.
var pdf = new IronPdf.PdfDocument("sample.pdf"); string text = pdf.ExtractAllText(); var images = pdf.ExtractAllImages(); -
Déployez pour tester sur votre environnement de production.
Commencez à utiliser IronPDF dans votre projet dès aujourd'hui avec un essai gratuit

Flux de travail minimal (5 étapes)
- Télécharger la bibliothèque C#
IronPdf - Préparez le document PDF pour l'extraction de texte et d'images
- Utilisez la méthode
ExtractAllTextpour extraire le texte - Utilisez la méthode
ExtractAllImagespour extraire des images - Spécifiez les pages particulières dont vous souhaitez extraire le texte et les images
Comment extraire du texte d'un fichier PDF?
Extraire du texte à partir de documents PDF existants ou nouvellement rendus. Utilisez la méthode ExtractAllText pour extraire le texte intégré du document. La méthode renvoie une chaîne contenant tout le texte du PDF. Les pages sont séparées par quatre caractères de retour à la ligne consécutifs. Cet exemple utilise un exemple de PDF rendu à partir du site web de Wikipedia.
Lorsque vous travaillez avec des PDF contenant des langues internationales et des caractères UTF-8, IronPDF conserve un codage et une représentation des caractères corrects. Cela garantit l'affichage correct des scripts non latins et des caractères spéciaux.
:path=/static-assets/pdf/content-code-examples/how-to/extract-text-and-images-extract-text.csusing IronPdf;
using System.IO;
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract text
string text = pdf.ExtractAllText();
// Export the extracted text to a text file
File.WriteAllText("extractedText.txt", text);Imports IronPdf
Imports System.IO
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract text
Private text As String = pdf.ExtractAllText()
' Export the extracted text to a text file
File.WriteAllText("extractedText.txt", text)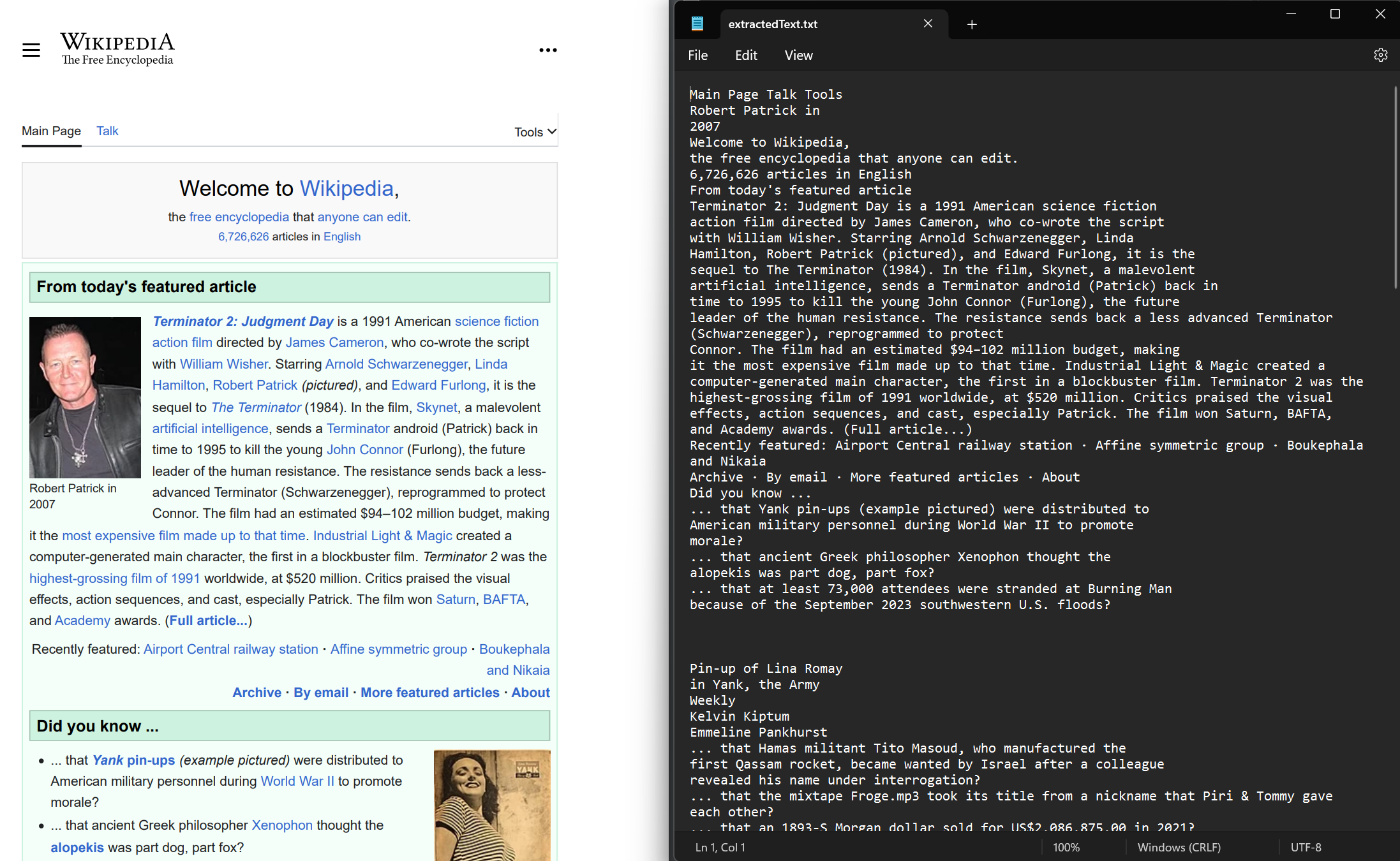
Comment extraire du texte avec des coordonnées précises?
Récupérer les coordonnées des lignes de texte et des caractères dans chaque page PDF. Sélectionnez une page du PDF et accédez aux propriétés Lines et Characters. Les coordonnées comprennent les valeurs Top, Right, Bottom et Left qui indiquent la position du texte. Cette fonction préserve la disposition spatiale et permet l'analyse de la position du texte.
Pour les développeurs qui ont besoin de lire des fichiers PDF en C# avec une conscience de la position, l'extraction de coordonnées fournit des données pour maintenir la structure du document et mettre en œuvre une analyse de texte avancée.
:path=/static-assets/pdf/content-code-examples/how-to/extract-text-and-images-extract-text-by-line-character.csusing IronPdf;
using System.IO;
using System.Linq;
// Open PDF from file
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract text by lines
var lines = pdf.Pages[0].Lines;
// Extract text by characters
var characters = pdf.Pages[0].Characters;
File.WriteAllLines("lines.txt", lines.Select(l => $"at Y={l.BoundingBox.Bottom:F2}: {l.Contents}"));Imports IronPdf
Imports System.IO
Imports System.Linq
' Open PDF from file
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract text by lines
Private lines = pdf.Pages(0).Lines
' Extract text by characters
Private characters = pdf.Pages(0).Characters
File.WriteAllLines("lines.txt", lines.Select(Function(l) $"at Y={l.BoundingBox.Bottom:F2}: {l.Contents}"))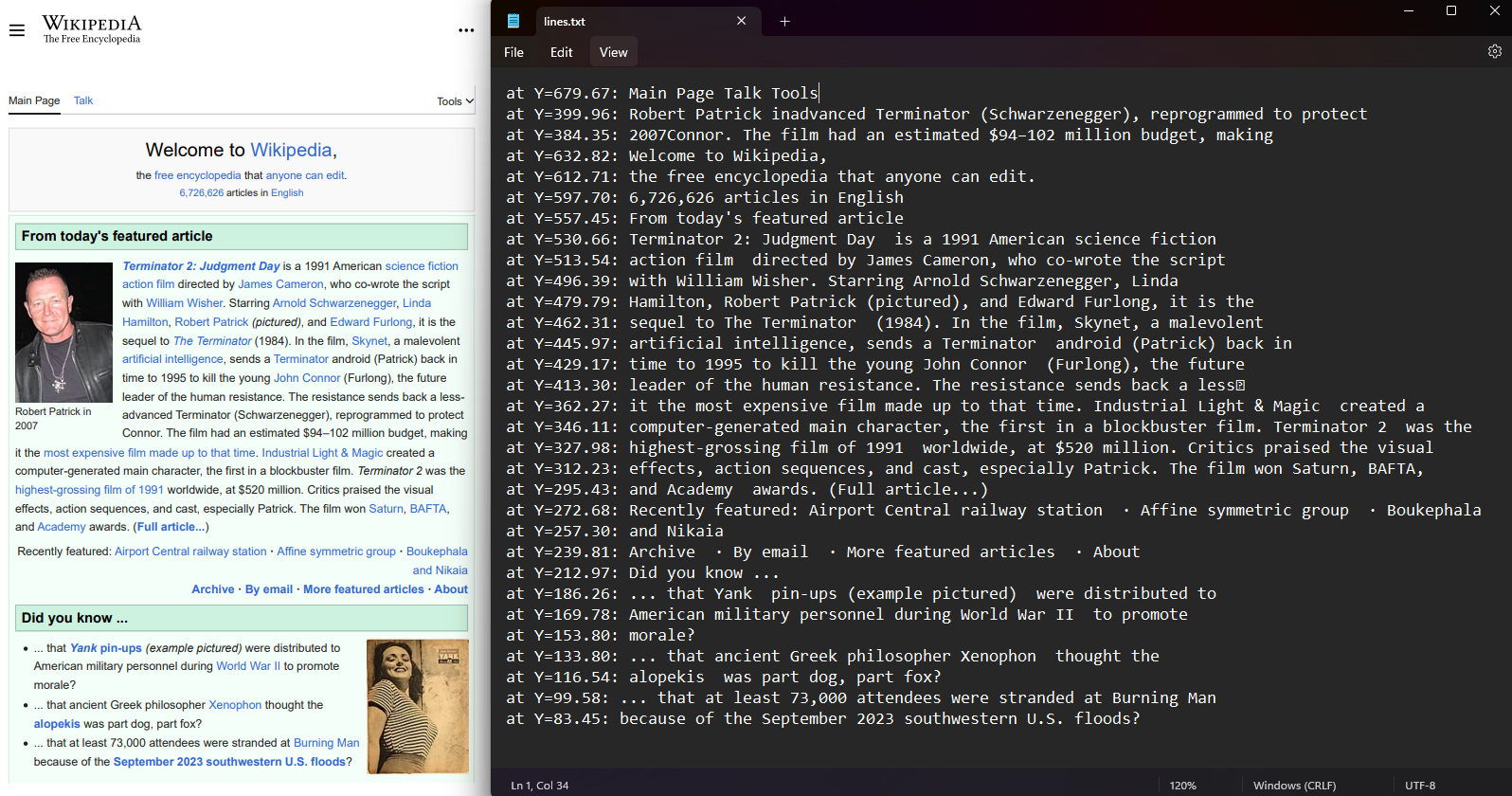
Comment extraire des images d'un PDF?
Utilisez la méthode ExtractAllImages pour extraire toutes les images intégrées du document. La méthode renvoie les images sous la forme d'une liste de List objets AnyBitmap. À partir du même document, nous avons extrait des images et les avons exportées dans le dossier "images". Cette fonctionnalité prend en charge l'archivage d'images, la migration de contenu et le tramage de pages PDF en images en vue d'un traitement ultérieur.
Les images extraites conservent leur qualité d'origine et peuvent être enregistrées dans différents formats, notamment PNG, JPEG et BMP. Pour les flux de travail de stockage dans le cloud, intégrez cette fonctionnalité avec Azure Blob Storage pour la gestion des images.
:path=/static-assets/pdf/content-code-examples/how-to/extract-text-and-images-extract-image.csusing IronPdf;
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract images
var images = pdf.ExtractAllImages();
for(int i = 0; i < images.Count; i++)
{
// Export the extracted images
images[i].SaveAs($"images/image{i}.png");
}Imports IronPdf
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract images
Private images = pdf.ExtractAllImages()
For i As Integer = 0 To images.Count - 1
' Export the extracted images
images(i).SaveAs($"images/image{i}.png")
Next i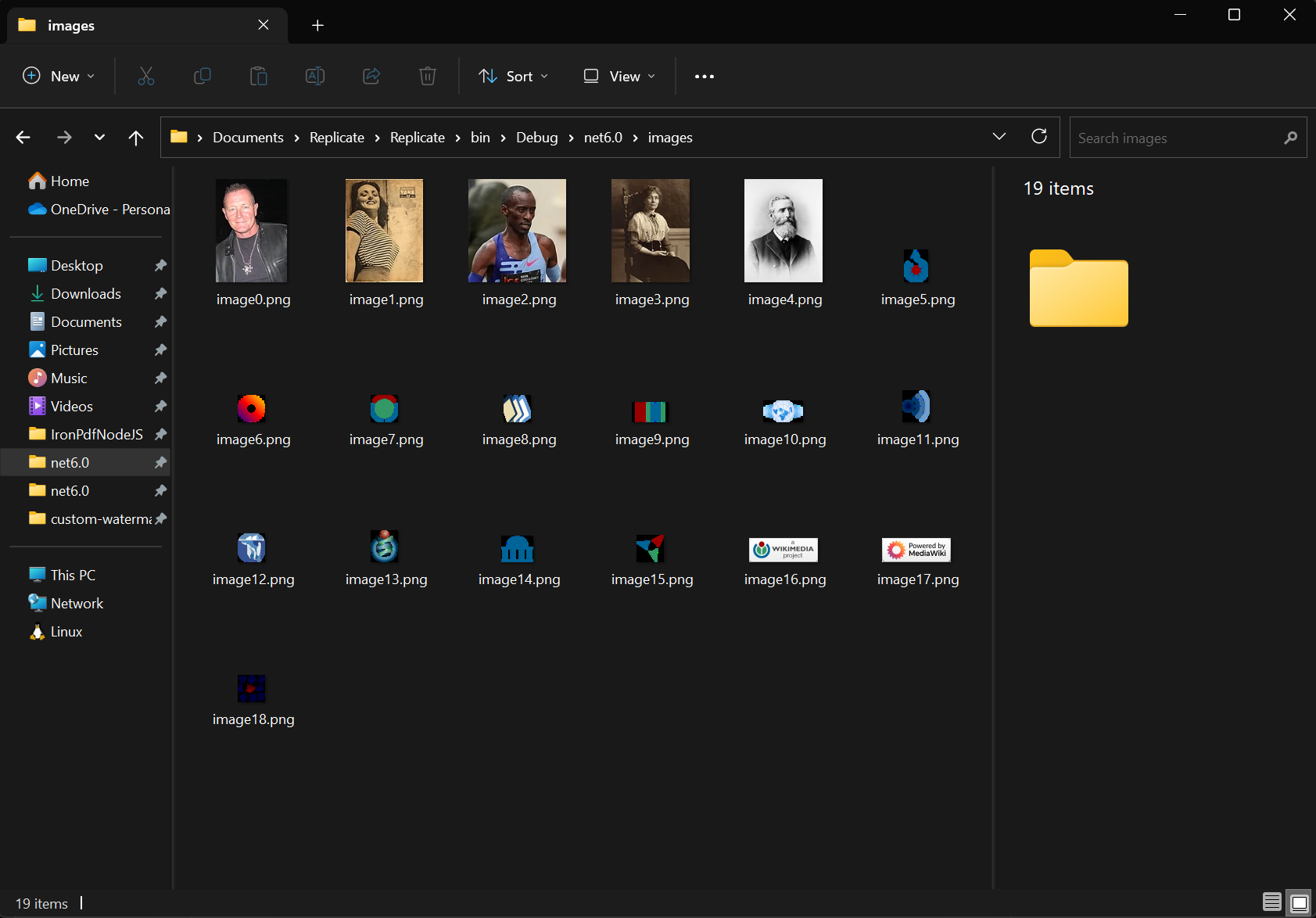
Quelles sont les différentes méthodes d'extraction d'images ?
Au-delà de la méthode ExtractAllImages, utilisez les méthodes ExtractAllBitmaps et ExtractAllRawImages pour extraire des informations sur les images. Alors que ExtractAllBitmaps renvoie un List de AnyBitmap, ExtractAllRawImages extrait toutes les images et les renvoie sous forme de byte[] brutes (byte[]).
La méthode ExtractAllRawImages fonctionne bien lors du traitement de données d'image en mémoire ou de l'intégration à des systèmes nécessitant des entrées de tableaux d'octets. Pour les scénarios impliquant l'exportation de PDF vers des flux de mémoire, le format de tableau d'octets brut offre une flexibilité optimale.
Comment extraire le contenu de pages PDF spécifiques?
Extraction de texte et d'images à partir d'une ou de plusieurs pages spécifiées. Utilisez les méthodes ExtractTextFromPage et ExtractTextFromPages pour l'extraction de texte à partir d'une ou plusieurs pages. Pour les images, utilisez les méthodes ExtractImagesFromPage et ExtractImagesFromPages.
Ce contrôle granulaire est utile lorsque l'on travaille avec des documents volumineux dont seules des sections spécifiques contiennent un contenu pertinent. Elle prend également en charge les fonctionnalités permettant de séparer les PDF et d'extraire des pages individuelles en vue d'un traitement séparé.
:path=/static-assets/pdf/content-code-examples/how-to/extract-text-and-images-extract-text-single-multiple.csusing IronPdf;
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract text from page 1
string textFromPage1 = pdf.ExtractTextFromPage(0);
int[] pages = new[] { 0, 2 };
// Extract text from pages 1 & 3
string textFromPage1_3 = pdf.ExtractTextFromPages(pages);Imports IronPdf
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract text from page 1
Private textFromPage1 As String = pdf.ExtractTextFromPage(0)
Private pages() As Integer = { 0, 2 }
' Extract text from pages 1 & 3
Private textFromPage1_3 As String = pdf.ExtractTextFromPages(pages)Quand dois-je extraire des pages spécifiques plutôt que toutes les pages?
Extraire des pages spécifiques lorsque :
- Travailler avec de grands PDF contenant des données pertinentes dans certaines sections
- Mettre en œuvre des flux de travail qui traitent les pages de manière indépendante
- Construire des applications nécessitant un affichage ou un traitement de contenu incrémental
- Optimiser l'utilisation de la mémoire en traitant uniquement les pages requises
- Création d'une fonctionnalité de recherche ou d'indexation spécifique à une page
Quelles sont les considérations en matière de performances à prendre en compte ?
Tenez compte des facteurs de performance suivants lors de l'extraction de contenu PDF :
- Utilisation de la mémoire : Extraire des pages individuellement à partir de grands documents pour minimiser la consommation de mémoire
- Temps de traitement : Utilisez le traitement parallèle pour les extractions de plusieurs pages lorsque cela est approprié
- Taille du fichier : Les PDF plus grands avec des images en haute résolution nécessitent plus de temps de traitement
- Stockage : Planifiez un espace disque adéquat pour l'extraction de nombreuses images en haute résolution
- Threading : IronPDF prend en charge les opérations multi-thread pour une performance améliorée sur les systèmes multi-cœurs
Pour des performances optimales avec les PDF en mémoire, utilisez les opérations de flux en mémoire pour réduire la surcharge d'E/S sur disque.
Questions Fréquemment Posées
Comment extraire du texte de documents PDF en C# ?
Utilisez la méthode ExtractAllText d'IronPDF pour extraire le texte incorporé dans les documents PDF. La méthode renvoie une chaîne contenant tout le texte du PDF, les pages étant séparées par quatre caractères de retour à la ligne consécutifs. IronPDF maintient un encodage correct pour les langues internationales et les caractères UTF-8.
Puis-je extraire des images de fichiers PDF par programmation ?
Oui, IronPDF propose la méthode ExtractAllImages pour extraire les éléments graphiques des documents PDF. Vous pouvez enregistrer les images extraites sur le disque ou les convertir dans d'autres formats avant de les incorporer dans de nouveaux documents.
Quels sont les principaux cas d'utilisation de l'extraction de contenu PDF ?
Les outils d'extraction d'IronPDF prennent en charge divers flux de travail, notamment l'analyse des PDF pour l'analyse des données, la conversion du contenu en formats consultables, l'extraction d'éléments visuels pour l'archivage et la réaffectation du contenu pour l'édition ou la transformation dans d'autres formats tels que HTML.
Combien de lignes de code faut-il pour extraire le contenu d'un PDF ?
Avec IronPDF, vous pouvez extraire du texte et des images en quelques lignes de code seulement. Il vous suffit de charger votre document PDF et d'appeler ExtractAllText() pour l'extraction de texte ou ExtractAllImages() pour l'extraction d'images.
Puis-je extraire le contenu de certaines pages plutôt que du document entier ?
Oui, IronPDF vous permet de spécifier des pages particulières à partir desquelles extraire du texte et des images, ce qui vous donne un contrôle précis sur le contenu à extraire de vos documents PDF.


Vous faites encore défiler ?
Vous voulez une preuve rapidement ? PM > Install-Package IronPdf
exécuter un échantillon Regardez votre code HTML se transformer en PDF.










