


C# ; PDF Parser
Analysez des fichiers PDF en C# à l'aide de la méthode ExtractAllText d'IronPDF pour extraire du texte de documents entiers ou de pages spécifiques. Cette approche permet une extraction de texte PDF simple et efficace pour les applications .NET avec seulement quelques lignes de code.
IronPDF facilite l'analyse des fichiers PDF dans les applications C#. Ce tutoriel montre comment utiliser IronPDF, une bibliothèque C# complète pour la génération de PDF et la manipulation, pour analyser les PDF en quelques étapes seulement.
Démarrage rapide : Analyse PDF efficace avec IronPDF
Commencez à analyser des PDF en C# à l'aide d'IronPDF avec un minimum de code. Cet exemple montre comment extraire tout le texte d'un fichier PDF tout en conservant son formatage d'origine. La méthode ExtractAllText d'IronPDF permet une intégration transparente de l'analyse de fichiers PDF dans les applications .NET. Suivez les étapes suivantes pour une installation et une exécution simples.
-
Installez IronPDF avec le Gestionnaire de Packages NuGet
PM > Install-Package IronPdf -
Copiez et exécutez cet extrait de code.
var text = IronPdf.FromFile("sample.pdf").ExtractAllText(); -
Déployez pour tester sur votre environnement de production.
Commencez à utiliser IronPDF dans votre projet dès aujourd'hui avec un essai gratuit

Flux de travail minimal (5 étapes)
- Télécharger la bibliothèque C# PDF parser
- Installer dans votre Visual Studio
- Utilisez la méthode
ExtractAllTextpour extraire chaque ligne de texte - Extraire tout le texte d'une seule page avec la méthode
ExtractTextFromPage - Voir le contenu PDF analysé
Comment analyser des fichiers PDF en C#?
L'analyse des fichiers PDF est simple avec IronPDF. Le code ci-dessous utilise la méthode ExtractAllText pour extraire chaque ligne de texte de l'ensemble du document PDF. La comparaison montre le contenu PDF extrait avec son résultat. La bibliothèque prend également en charge l'extraction de texte et d'images à partir de sections spécifiques de documents PDF.
:path=/static-assets/pdf/content-code-examples/how-to/csharp-parse-pdf-parse-pdf.csusing IronPdf;
// Select the desired PDF File
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract all text from an pdf
string allText = pdf.ExtractAllText();
// Extract all text from page 1
string page1Text = pdf.ExtractTextFromPage(0);Imports IronPdf
' Select the desired PDF File
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract all text from an pdf
Private allText As String = pdf.ExtractAllText()
' Extract all text from page 1
Private page1Text As String = pdf.ExtractTextFromPage(0)IronPDF simplifie l'analyse des fichiers PDF dans divers scénarios. Qu'il s'agisse de travailler avec des conversions HTML vers PDF, d'extraire du contenu à partir de documents existants ou de mettre en œuvre des fonctions PDF avancées, la bibliothèque fournit une assistance complète.
IronPDF offre une intégration transparente avec les applications Windows et prend en charge le déploiement sur les plateformes Linux et macOS. La bibliothèque prend également en charge le déploiement Azure pour les solutions basées sur le cloud.
Exemples d'extraction de texte avancée
Voici d'autres façons d'analyser du contenu PDF à l'aide d'IronPDF :
using IronPdf;
// Parse PDF from URL
var pdfFromUrl = PdfDocument.FromUrl("https://example.com/document.pdf");
string urlPdfText = pdfFromUrl.ExtractAllText();
// Parse password-protected PDFs
var protectedPdf = PdfDocument.FromFile("protected.pdf", "password123");
string protectedText = protectedPdf.ExtractAllText();
// Extract text from specific page range
var largePdf = PdfDocument.FromFile("large-document.pdf");
for (int i = 5; i < 10; i++)
{
string pageText = largePdf.ExtractTextFromPage(i);
Console.WriteLine($"Page {i + 1}: {pageText.Substring(0, 100)}...");
}using IronPdf;
// Parse PDF from URL
var pdfFromUrl = PdfDocument.FromUrl("https://example.com/document.pdf");
string urlPdfText = pdfFromUrl.ExtractAllText();
// Parse password-protected PDFs
var protectedPdf = PdfDocument.FromFile("protected.pdf", "password123");
string protectedText = protectedPdf.ExtractAllText();
// Extract text from specific page range
var largePdf = PdfDocument.FromFile("large-document.pdf");
for (int i = 5; i < 10; i++)
{
string pageText = largePdf.ExtractTextFromPage(i);
Console.WriteLine($"Page {i + 1}: {pageText.Substring(0, 100)}...");
}Imports IronPdf
' Parse PDF from URL
Dim pdfFromUrl = PdfDocument.FromUrl("https://example.com/document.pdf")
Dim urlPdfText As String = pdfFromUrl.ExtractAllText()
' Parse password-protected PDFs
Dim protectedPdf = PdfDocument.FromFile("protected.pdf", "password123")
Dim protectedText As String = protectedPdf.ExtractAllText()
' Extract text from specific page range
Dim largePdf = PdfDocument.FromFile("large-document.pdf")
For i As Integer = 5 To 9
Dim pageText As String = largePdf.ExtractTextFromPage(i)
Console.WriteLine($"Page {i + 1}: {pageText.Substring(0, 100)}...")
NextCes exemples démontrent la flexibilité d'IronPDF lorsqu'il s'agit de gérer différentes sources de PDF et différents scénarios. Pour les besoins d'analyse complexe, explorez l'accès à l'objet IronPDF DOM pour travailler avec du contenu structuré.
Traiter les différents types de PDF
IronPDF excelle dans l'analyse de divers types de PDF :
using IronPdf;
using System.Text.RegularExpressions;
// Parse scanned PDFs with OCR (requires IronOcr)
var scannedPdf = PdfDocument.FromFile("scanned-document.pdf");
string ocrText = scannedPdf.ExtractAllText();
// Parse PDFs with forms
var formPdf = PdfDocument.FromFile("form.pdf");
string formText = formPdf.ExtractAllText();
// Extract and filter specific content
string invoiceText = pdf.ExtractAllText();
var invoiceNumber = Regex.Match(invoiceText, @"Invoice #: (\d+)").Groups[1].Value;
var totalAmount = Regex.Match(invoiceText, @"Total: \$([0-9,]+\.\d{2})").Groups[1].Value;using IronPdf;
using System.Text.RegularExpressions;
// Parse scanned PDFs with OCR (requires IronOcr)
var scannedPdf = PdfDocument.FromFile("scanned-document.pdf");
string ocrText = scannedPdf.ExtractAllText();
// Parse PDFs with forms
var formPdf = PdfDocument.FromFile("form.pdf");
string formText = formPdf.ExtractAllText();
// Extract and filter specific content
string invoiceText = pdf.ExtractAllText();
var invoiceNumber = Regex.Match(invoiceText, @"Invoice #: (\d+)").Groups[1].Value;
var totalAmount = Regex.Match(invoiceText, @"Total: \$([0-9,]+\.\d{2})").Groups[1].Value;Imports IronPdf
Imports System.Text.RegularExpressions
' Parse scanned PDFs with OCR (requires IronOcr)
Dim scannedPdf = PdfDocument.FromFile("scanned-document.pdf")
Dim ocrText As String = scannedPdf.ExtractAllText()
' Parse PDFs with forms
Dim formPdf = PdfDocument.FromFile("form.pdf")
Dim formText As String = formPdf.ExtractAllText()
' Extract and filter specific content
Dim invoiceText As String = pdf.ExtractAllText()
Dim invoiceNumber = Regex.Match(invoiceText, "Invoice #: (\d+)").Groups(1).Value
Dim totalAmount = Regex.Match(invoiceText, "Total: \$([0-9,]+\.\d{2})").Groups(1).ValueComment visualiser le contenu PDF analysé?
Un formulaire C# affiche le contenu PDF analysé à partir de l'exécution du code ci-dessus. Ce résultat fournit le texte exact d'un PDF pour les besoins de traitement de documents.
~ PDF ~
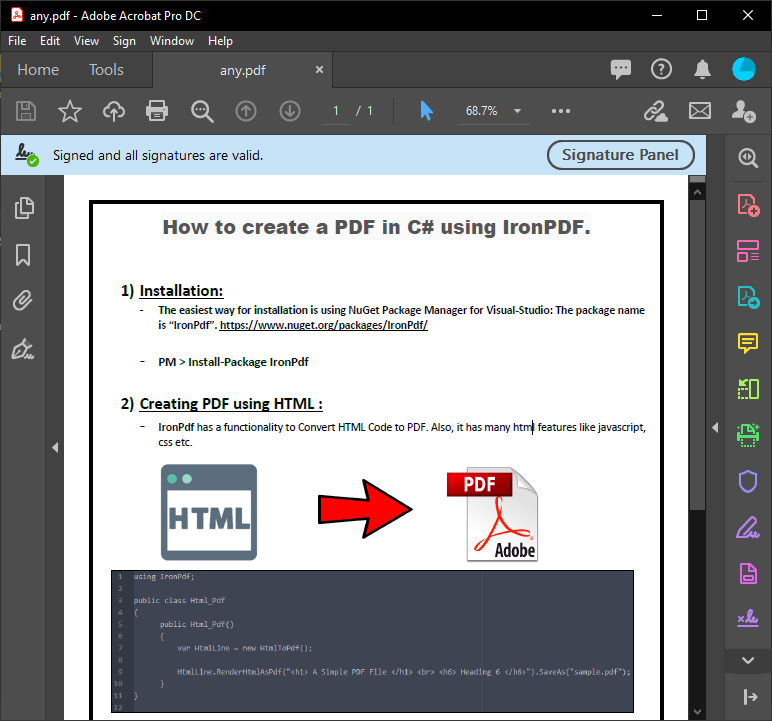
~ Formulaire C# ~
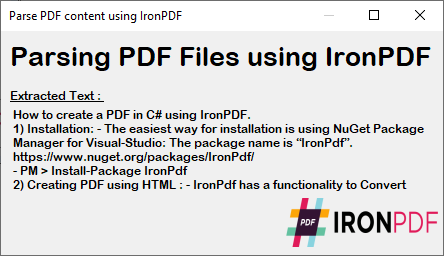
Le texte extrait conserve le formatage et la structure d'origine du PDF, ce qui le rend idéal pour le traitement des données, l'analyse du contenu ou les tâches de migration. Traitez ensuite ce texte en retrouvant et remplaçant du contenu spécifique ou en l'exportant vers d'autres formats.
Intégrer l'analyse PDF dans vos applications
Les capacités d'analyse d'IronPDF s'intègrent dans divers types d'applications :
// ASP.NET Core example
public IActionResult ParseUploadedPdf(IFormFile pdfFile)
{
using var stream = pdfFile.OpenReadStream();
var pdf = PdfDocument.FromStream(stream);
var extractedText = pdf.ExtractAllText();
// Process or store the extracted text
return Json(new {
success = true,
textLength = extractedText.Length,
preview = extractedText.Substring(0, Math.Min(500, extractedText.Length))
});
}
// Console application example
static void BatchParsePdfs(string folderPath)
{
var pdfFiles = Directory.GetFiles(folderPath, "*.pdf");
foreach (var file in pdfFiles)
{
var pdf = PdfDocument.FromFile(file);
var text = pdf.ExtractAllText();
// Save extracted text
var textFile = Path.ChangeExtension(file, ".txt");
File.WriteAllText(textFile, text);
Console.WriteLine($"Parsed: {Path.GetFileName(file)} - {text.Length} characters");
}
}// ASP.NET Core example
public IActionResult ParseUploadedPdf(IFormFile pdfFile)
{
using var stream = pdfFile.OpenReadStream();
var pdf = PdfDocument.FromStream(stream);
var extractedText = pdf.ExtractAllText();
// Process or store the extracted text
return Json(new {
success = true,
textLength = extractedText.Length,
preview = extractedText.Substring(0, Math.Min(500, extractedText.Length))
});
}
// Console application example
static void BatchParsePdfs(string folderPath)
{
var pdfFiles = Directory.GetFiles(folderPath, "*.pdf");
foreach (var file in pdfFiles)
{
var pdf = PdfDocument.FromFile(file);
var text = pdf.ExtractAllText();
// Save extracted text
var textFile = Path.ChangeExtension(file, ".txt");
File.WriteAllText(textFile, text);
Console.WriteLine($"Parsed: {Path.GetFileName(file)} - {text.Length} characters");
}
}Imports Microsoft.AspNetCore.Mvc
Imports System.IO
' ASP.NET Core example
Public Function ParseUploadedPdf(pdfFile As IFormFile) As IActionResult
Using stream = pdfFile.OpenReadStream()
Dim pdf = PdfDocument.FromStream(stream)
Dim extractedText = pdf.ExtractAllText()
' Process or store the extracted text
Return Json(New With {
.success = True,
.textLength = extractedText.Length,
.preview = extractedText.Substring(0, Math.Min(500, extractedText.Length))
})
End Using
End Function
' Console application example
Private Shared Sub BatchParsePdfs(folderPath As String)
Dim pdfFiles = Directory.GetFiles(folderPath, "*.pdf")
For Each file In pdfFiles
Dim pdf = PdfDocument.FromFile(file)
Dim text = pdf.ExtractAllText()
' Save extracted text
Dim textFile = Path.ChangeExtension(file, ".txt")
File.WriteAllText(textFile, text)
Console.WriteLine($"Parsed: {Path.GetFileName(file)} - {text.Length} characters")
Next
End SubCes exemples montrent l'incorporation de l'analyse PDF dans des applications web et des scénarios de traitement par lots. Pour les implémentations avancées, explorez les techniques async et multithreading pour améliorer les performances lors du traitement de plusieurs PDF.
Prêt à voir ce que vous pouvez faire d'autre? Consultez notre page de tutoriel ici : Modifier les PDFs
Questions Fréquemment Posées
Comment extraire tout le texte d'un fichier PDF en C# ?
Vous pouvez extraire tout le texte d'un fichier PDF à l'aide de la méthode ExtractAllText d'IronPDF. Il suffit de charger votre PDF avec IronPdf.FromFile("sample.pdf") et d'appeler ExtractAllText() pour récupérer tout le contenu textuel tout en conservant le formatage d'origine.
Quel est le moyen le plus simple d'analyser un PDF en .NET ?
La méthode la plus simple consiste à utiliser IronPDF avec une seule ligne de code : var text = IronPdf.FromFile("sample.pdf").ExtractAllText(). Cette méthode permet d'extraire chaque ligne de texte de l'ensemble du document PDF avec une configuration minimale.
Puis-je extraire du texte d'une page spécifique d'un PDF ?
Oui, IronPDF propose la méthode ExtractTextFromPage pour extraire le texte de pages individuelles. Cela vous permet de cibler des sections spécifiques de votre document PDF plutôt que d'extraire tout le contenu en une seule fois.
Comment analyser des PDF protégés par un mot de passe en C# ?
IronPDF prend en charge l'analyse des PDF protégés par un mot de passe. Utilisez PdfDocument.FromFile("protected.pdf", "password123") pour charger le document protégé, puis appelez ExtractAllText() pour extraire le contenu textuel.
Puis-je analyser des PDF à partir d'URL plutôt que de fichiers locaux ?
Oui, IronPDF peut analyser des PDF directement à partir d'URL en utilisant PdfDocument.FromUrl("https://example.com/document.pdf"). Après avoir chargé le PDF à partir de l'URL, utilisez ExtractAllText() pour extraire le contenu textuel.
Quelles sont les plateformes prises en charge par l'analyseur PDF ?
IronPDF prend en charge l'analyse des fichiers PDF sur plusieurs plateformes, notamment les applications Windows, Linux, macOS et les déploiements dans le cloud Azure, offrant ainsi une compatibilité multiplateforme complète pour vos applications .NET.
L'analyseur PDF conserve-t-il le formatage du texte lors de l'extraction ?
Oui, la méthode ExtractAllText d'IronPDF maintient le formatage original du contenu PDF pendant l'extraction, garantissant que le texte analysé conserve sa structure et sa mise en page du document source.
Puis-je extraire à la fois du texte et des images des PDF ?
IronPDF permet d'extraire à la fois du texte et des images de documents PDF. Outre la méthode ExtractAllText pour l'extraction de texte, la bibliothèque offre des fonctionnalités supplémentaires pour l'extraction d'images à partir de sections spécifiques de documents PDF.


Vous faites encore défiler ?
Vous voulez une preuve rapidement ? PM > Install-Package IronPdf
exécuter un échantillon Regardez votre code HTML se transformer en PDF.










