


C# PDF-Parser
Parsen Sie PDF-Dateien in C# mit der ExtractAllText-Methode von IronPDF, um Text aus ganzen Dokumenten oder bestimmten Seiten zu extrahieren. Dieser Ansatz bietet eine einfache, effiziente PDF-Textextraktion for .NET-Anwendungen mit nur wenigen Codezeilen.
IronPDF macht das Parsen von PDF-Dateien in C#-Anwendungen zum Kinderspiel. Dieses Tutorial demonstriert die Verwendung von IronPDF, einer umfassenden C#-Bibliothek für PDF-Erzeugung und -Bearbeitung, um PDFs in wenigen Schritten zu parsen.
Schnellstart: Effizientes PDF-Parsing mit IronPDF
Mit IronPDF können Sie PDFs in C# mit minimalem Code analysieren. Dieses Beispiel zeigt, wie man den gesamten Text aus einer PDF-Datei extrahiert und dabei die ursprüngliche Formatierung beibehält. Die ExtractAllText-Methode von IronPDF ermöglicht die nahtlose Integration der PDF-Parsing-Funktionalität in .NET-Anwendungen. Befolgen Sie diese Schritte für eine unkomplizierte Einrichtung und Ausführung.
-
Installieren Sie IronPDF mit NuGet Package Manager
PM > Install-Package IronPdf -
Kopieren Sie diesen Codeausschnitt und führen Sie ihn aus.
var text = IronPdf.FromFile("sample.pdf").ExtractAllText(); -
Bereitstellen zum Testen in Ihrer Live-Umgebung
Beginnen Sie noch heute, IronPDF in Ihrem Projekt zu verwenden, mit einer kostenlosen Testversion

Minimaler Arbeitsablauf (5 Schritte)
- Herunterladen der C# PDF-Parser-Bibliothek
- Installieren Sie in Ihrem Visual Studio
- Verwenden Sie die Methode
ExtractAllText, um jede einzelne Zeile des Textes zu extrahieren - Extrahieren des gesamten Textes aus einer einzelnen Seite mit der Methode
ExtractTextFromPage - Zugehörige PDF-Inhalte anzeigen
Wie analysiere ich PDF-Dateien in C#?
Das Parsen von PDF-Dateien ist mit IronPDF ganz einfach. Der folgende Code verwendet die Methode ExtractAllText, um jede Textzeile aus dem gesamten PDF-Dokument zu extrahieren. Der Vergleich zeigt den extrahierten PDF-Inhalt und seine Ausgabe. Die Bibliothek unterstützt auch die Extraktion von Text und Bildern aus bestimmten Abschnitten von PDF-Dokumenten.
:path=/static-assets/pdf/content-code-examples/how-to/csharp-parse-pdf-parse-pdf.csusing IronPdf;
// Select the desired PDF File
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract all text from an pdf
string allText = pdf.ExtractAllText();
// Extract all text from page 1
string page1Text = pdf.ExtractTextFromPage(0);Imports IronPdf
' Select the desired PDF File
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract all text from an pdf
Private allText As String = pdf.ExtractAllText()
' Extract all text from page 1
Private page1Text As String = pdf.ExtractTextFromPage(0)IronPDF vereinfacht das Parsen von PDF-Dateien in verschiedenen Szenarien. Ob bei der Arbeit mit HTML-zu-PDF-Konvertierungen, der Extraktion von Inhalten aus bestehenden Dokumenten oder der Implementierung von erweiterten PDF-Funktionen, die Bibliothek bietet umfassende Unterstützung.
IronPDF bietet eine nahtlose Integration mit Windows-Anwendungen und unterstützt den Einsatz auf Linux und macOS Plattformen. Die Bibliothek unterstützt auch Azure deployment für Cloud-basierte Lösungen.
Fortgeschrittene Beispiele zur Textextraktion
Hier finden Sie weitere Möglichkeiten zum Parsen von PDF-Inhalten mit IronPDF:
using IronPdf;
// Parse PDF from URL
var pdfFromUrl = PdfDocument.FromUrl("https://example.com/document.pdf");
string urlPdfText = pdfFromUrl.ExtractAllText();
// Parse password-protected PDFs
var protectedPdf = PdfDocument.FromFile("protected.pdf", "password123");
string protectedText = protectedPdf.ExtractAllText();
// Extract text from specific page range
var largePdf = PdfDocument.FromFile("large-document.pdf");
for (int i = 5; i < 10; i++)
{
string pageText = largePdf.ExtractTextFromPage(i);
Console.WriteLine($"Page {i + 1}: {pageText.Substring(0, 100)}...");
}using IronPdf;
// Parse PDF from URL
var pdfFromUrl = PdfDocument.FromUrl("https://example.com/document.pdf");
string urlPdfText = pdfFromUrl.ExtractAllText();
// Parse password-protected PDFs
var protectedPdf = PdfDocument.FromFile("protected.pdf", "password123");
string protectedText = protectedPdf.ExtractAllText();
// Extract text from specific page range
var largePdf = PdfDocument.FromFile("large-document.pdf");
for (int i = 5; i < 10; i++)
{
string pageText = largePdf.ExtractTextFromPage(i);
Console.WriteLine($"Page {i + 1}: {pageText.Substring(0, 100)}...");
}Imports IronPdf
' Parse PDF from URL
Dim pdfFromUrl = PdfDocument.FromUrl("https://example.com/document.pdf")
Dim urlPdfText As String = pdfFromUrl.ExtractAllText()
' Parse password-protected PDFs
Dim protectedPdf = PdfDocument.FromFile("protected.pdf", "password123")
Dim protectedText As String = protectedPdf.ExtractAllText()
' Extract text from specific page range
Dim largePdf = PdfDocument.FromFile("large-document.pdf")
For i As Integer = 5 To 9
Dim pageText As String = largePdf.ExtractTextFromPage(i)
Console.WriteLine($"Page {i + 1}: {pageText.Substring(0, 100)}...")
NextDiese Beispiele zeigen die Flexibilität von IronPDF bei der Verarbeitung unterschiedlicher PDF-Quellen und -Szenarien. Für komplexe Parsing-Anforderungen sollten Sie PDF DOM Object Access erkunden, um mit strukturierten Inhalten zu arbeiten.
Verarbeitung verschiedener PDF-Typen
IronPDF eignet sich hervorragend zum Parsen verschiedener PDF-Typen:
using IronPdf;
using System.Text.RegularExpressions;
// Parse scanned PDFs with OCR (requires IronOcr)
var scannedPdf = PdfDocument.FromFile("scanned-document.pdf");
string ocrText = scannedPdf.ExtractAllText();
// Parse PDFs with forms
var formPdf = PdfDocument.FromFile("form.pdf");
string formText = formPdf.ExtractAllText();
// Extract and filter specific content
string invoiceText = pdf.ExtractAllText();
var invoiceNumber = Regex.Match(invoiceText, @"Invoice #: (\d+)").Groups[1].Value;
var totalAmount = Regex.Match(invoiceText, @"Total: \$([0-9,]+\.\d{2})").Groups[1].Value;using IronPdf;
using System.Text.RegularExpressions;
// Parse scanned PDFs with OCR (requires IronOcr)
var scannedPdf = PdfDocument.FromFile("scanned-document.pdf");
string ocrText = scannedPdf.ExtractAllText();
// Parse PDFs with forms
var formPdf = PdfDocument.FromFile("form.pdf");
string formText = formPdf.ExtractAllText();
// Extract and filter specific content
string invoiceText = pdf.ExtractAllText();
var invoiceNumber = Regex.Match(invoiceText, @"Invoice #: (\d+)").Groups[1].Value;
var totalAmount = Regex.Match(invoiceText, @"Total: \$([0-9,]+\.\d{2})").Groups[1].Value;Imports IronPdf
Imports System.Text.RegularExpressions
' Parse scanned PDFs with OCR (requires IronOcr)
Dim scannedPdf = PdfDocument.FromFile("scanned-document.pdf")
Dim ocrText As String = scannedPdf.ExtractAllText()
' Parse PDFs with forms
Dim formPdf = PdfDocument.FromFile("form.pdf")
Dim formText As String = formPdf.ExtractAllText()
' Extract and filter specific content
Dim invoiceText As String = pdf.ExtractAllText()
Dim invoiceNumber = Regex.Match(invoiceText, "Invoice #: (\d+)").Groups(1).Value
Dim totalAmount = Regex.Match(invoiceText, "Total: \$([0-9,]+\.\d{2})").Groups(1).ValueWie kann ich den geparsten PDF-Inhalt anzeigen?
Ein C#-Formular zeigt den geparsten PDF-Inhalt aus der obigen Codeausführung an. Diese Ausgabe liefert den genauen Text aus einem PDF-Dokument für die Dokumentenverarbeitung.
~ PDF ~
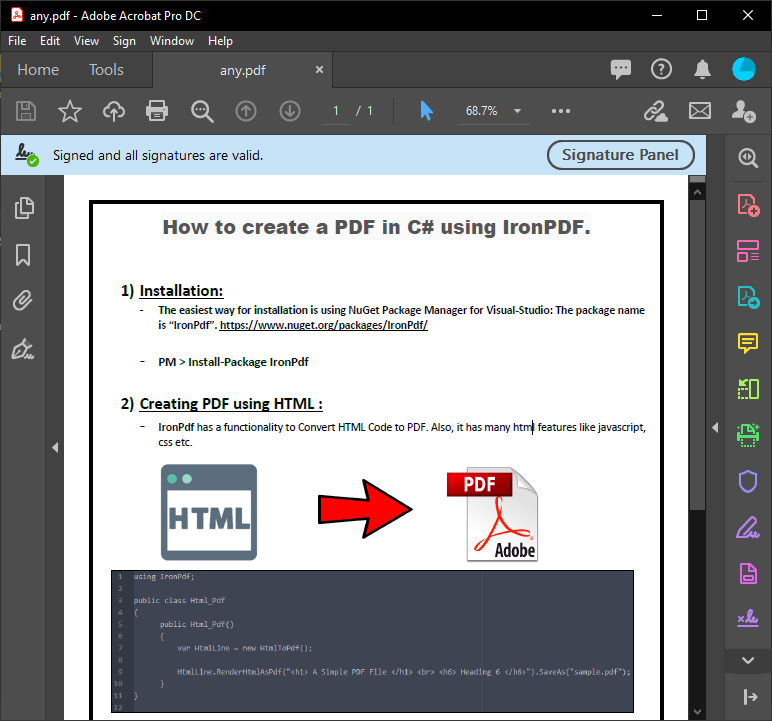
~ C# Formular ~
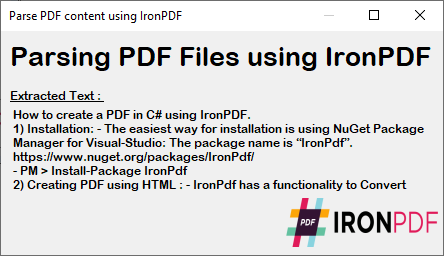
Der extrahierte Text behält die ursprüngliche Formatierung und Struktur der PDF-Datei bei und eignet sich daher ideal für Datenverarbeitung, Inhaltsanalyse oder Migrationsaufgaben. Bearbeiten Sie diesen Text weiter, indem Sie bestimmte Inhalte suchen und ersetzen oder ihn in andere Formate exportieren.
PDF-Parsing in Ihre Anwendungen integrieren
Die Parsing-Funktionen von IronPDF lassen sich in verschiedene Anwendungstypen integrieren:
// ASP.NET Core example
public IActionResult ParseUploadedPdf(IFormFile pdfFile)
{
using var stream = pdfFile.OpenReadStream();
var pdf = PdfDocument.FromStream(stream);
var extractedText = pdf.ExtractAllText();
// Process or store the extracted text
return Json(new {
success = true,
textLength = extractedText.Length,
preview = extractedText.Substring(0, Math.Min(500, extractedText.Length))
});
}
// Console application example
static void BatchParsePdfs(string folderPath)
{
var pdfFiles = Directory.GetFiles(folderPath, "*.pdf");
foreach (var file in pdfFiles)
{
var pdf = PdfDocument.FromFile(file);
var text = pdf.ExtractAllText();
// Save extracted text
var textFile = Path.ChangeExtension(file, ".txt");
File.WriteAllText(textFile, text);
Console.WriteLine($"Parsed: {Path.GetFileName(file)} - {text.Length} characters");
}
}// ASP.NET Core example
public IActionResult ParseUploadedPdf(IFormFile pdfFile)
{
using var stream = pdfFile.OpenReadStream();
var pdf = PdfDocument.FromStream(stream);
var extractedText = pdf.ExtractAllText();
// Process or store the extracted text
return Json(new {
success = true,
textLength = extractedText.Length,
preview = extractedText.Substring(0, Math.Min(500, extractedText.Length))
});
}
// Console application example
static void BatchParsePdfs(string folderPath)
{
var pdfFiles = Directory.GetFiles(folderPath, "*.pdf");
foreach (var file in pdfFiles)
{
var pdf = PdfDocument.FromFile(file);
var text = pdf.ExtractAllText();
// Save extracted text
var textFile = Path.ChangeExtension(file, ".txt");
File.WriteAllText(textFile, text);
Console.WriteLine($"Parsed: {Path.GetFileName(file)} - {text.Length} characters");
}
}Imports Microsoft.AspNetCore.Mvc
Imports System.IO
' ASP.NET Core example
Public Function ParseUploadedPdf(pdfFile As IFormFile) As IActionResult
Using stream = pdfFile.OpenReadStream()
Dim pdf = PdfDocument.FromStream(stream)
Dim extractedText = pdf.ExtractAllText()
' Process or store the extracted text
Return Json(New With {
.success = True,
.textLength = extractedText.Length,
.preview = extractedText.Substring(0, Math.Min(500, extractedText.Length))
})
End Using
End Function
' Console application example
Private Shared Sub BatchParsePdfs(folderPath As String)
Dim pdfFiles = Directory.GetFiles(folderPath, "*.pdf")
For Each file In pdfFiles
Dim pdf = PdfDocument.FromFile(file)
Dim text = pdf.ExtractAllText()
' Save extracted text
Dim textFile = Path.ChangeExtension(file, ".txt")
File.WriteAllText(textFile, text)
Console.WriteLine($"Parsed: {Path.GetFileName(file)} - {text.Length} characters")
Next
End SubDiese Beispiele zeigen die Einbindung von PDF-Parsing in Webanwendungen und Stapelverarbeitungsszenarien. Für fortgeschrittene Implementierungen werden async und multithreading Techniken zur Verbesserung der Leistung bei der Verarbeitung mehrerer PDFs erläutert.
Bereit zu sehen, was Sie sonst noch tun können? Besuchen Sie unsere Tutorialseite hier: PDFs bearbeiten
Häufig gestellte Fragen
Wie kann ich in C# den gesamten Text aus einer PDF-Datei extrahieren?
Mit der ExtractAllText-Methode von IronPDF können Sie den gesamten Text aus einer PDF-Datei extrahieren. Laden Sie Ihre PDF-Datei einfach mit IronPdf.FromFile("sample.pdf") und rufen Sie ExtractAllText() auf, um den gesamten Textinhalt unter Beibehaltung der ursprünglichen Formatierung zu extrahieren.
Wie lässt sich eine PDF-Datei in .NET am einfachsten analysieren?
Der einfachste Weg ist die Verwendung von IronPDF mit nur einer Zeile Code: var text = IronPdf.FromFile("sample.pdf").ExtractAllText(). Diese Methode extrahiert jede Textzeile aus dem gesamten PDF-Dokument, wobei nur minimale Einstellungen erforderlich sind.
Kann ich Text aus einer bestimmten Seite einer PDF-Datei extrahieren?
Ja, IronPDF bietet die Methode ExtractTextFromPage, um Text aus einzelnen Seiten zu extrahieren. Dies ermöglicht es Ihnen, bestimmte Abschnitte Ihres PDF-Dokuments zu extrahieren, anstatt den gesamten Inhalt auf einmal.
Wie kann ich passwortgeschützte PDF-Dateien in C# analysieren?
IronPDF unterstützt das Parsen passwortgeschützter PDF-Dateien. Verwenden Sie PdfDocument.FromFile("protected.pdf", "password123"), um das geschützte Dokument zu laden, und rufen Sie dann ExtractAllText() auf, um den Textinhalt zu extrahieren.
Kann ich PDFs von URLs statt von lokalen Dateien analysieren?
Ja, IronPDF kann PDFs direkt aus URLs mit PdfDocument.FromUrl("https://example.com/document.pdf") analysieren. Nachdem Sie die PDF-Datei von der URL geladen haben, verwenden Sie ExtractAllText(), um den Textinhalt zu extrahieren.
Welche Plattformen unterstützt der PDF-Parser?
IronPDF unterstützt PDF-Parsing auf mehreren Plattformen, darunter Windows-Anwendungen, Linux, macOS und Azure-Cloud-Implementierungen, und bietet so umfassende plattformübergreifende Kompatibilität für Ihre .NET-Anwendungen.
Behält der PDF-Parser die Textformatierung während der Extraktion bei?
Ja, die ExtractAllText-Methode von IronPDF behält die ursprüngliche Formatierung des PDF-Inhalts während der Extraktion bei und stellt sicher, dass der geparste Text seine Struktur und sein Layout aus dem Quelldokument beibehält.
Kann ich sowohl Text als auch Bilder aus PDFs extrahieren?
IronPDF unterstützt die Extraktion von Text und Bildern aus PDF-Dokumenten. Neben der ExtractAllText-Methode zur Textextraktion bietet die Bibliothek zusätzliche Funktionen zur Extraktion von Bildern aus bestimmten Abschnitten von PDF-Dokumenten.


Scrollst du immer noch?
Sie brauchen schnell einen Beweis? PM > Install-Package IronPdf
Führen Sie eine Probe aus Sehen Sie zu, wie Ihr HTML-Code in eine PDF-Datei umgewandelt wird.










