

KI-gestützte PDF-Verarbeitung in C#: Summarize, Extrahieren und Analysieren von Dokumenten mit IronPDF
KI-gestützte PDF-Verarbeitung in C# mit IronPDF ermöglicht .NET-Entwicklern, Dokumente zusammenzufassen, strukturierte Daten zu extrahieren und Frage-Antwort-Systeme direkt auf bestehenden PDF-Arbeitsabläufen aufzubauen – durch Verwendung des auf Microsoft Semantic Kernel aufgebauten IronPdf.Extensions.AI-Pakets zur nahtlosen Verbindung mit Azure OpenAI und OpenAI-Modellen. Ganz gleich, ob Sie juristische Discovery-Tools, Finanzanalyse-Pipelines oder Document Intelligence-Plattformen entwickeln, IronPDF übernimmt die PDF-Extraktion und Kontextvorbereitung, damit Sie sich auf die KI-Logik konzentrieren können.
TL;DR: Schnellstartanleitung
Dieses Tutorial behandelt die Anbindung von IronPDF an KI-Dienste zur Dokumentenzusammenfassung, Datenextraktion und intelligenten Abfrage in C# .NET.
- Für wen ist das?: .NET-Entwickler, die Document Intelligence-Anwendungen erstellen - juristische Ermittlungssysteme, Finanzanalysewerkzeuge, Plattformen zur Überprüfung der Einhaltung von Vorschriften oder jede Anwendung, die Bedeutung aus großen Mengen von PDF-Dokumenten extrahieren muss.
- Was Sie erstellen werden: Zusammenfassung einzelner Dokumente, strukturierte JSON-Datenextraktion mit benutzerdefinierten Schemata, Beantwortung von Fragen über den Inhalt von Dokumenten, RAG-Pipelines für lange Dokumente und Stapelverarbeitung von KI-Workflows in Dokumentenbibliotheken.
- Wo es läuft: Jede .NET 6+ Umgebung mit einem Azure OpenAI oder OpenAI API Schlüssel. Die AI-Erweiterung ist in den Microsoft Semantic Kernel integriert und übernimmt automatisch die Verwaltung von Kontextfenstern, Chunking und Orchestrierung.
- Wann sollte dieser Ansatz verwendet werden: Wenn Ihre Anwendung PDFs verarbeiten muss, die über die Textextraktion hinausgehen - Verständnis von Vertragsverpflichtungen, Zusammenfassung von Forschungsarbeiten, Extraktion von Finanztabellen als strukturierte Daten oder Beantwortung von Benutzerfragen zu Dokumenteninhalten in großem Umfang.
- Warum es technisch wichtig ist: Bei der Extraktion von Rohtext geht die Struktur des Dokuments verloren - Tabellen fallen zusammen, mehrspaltige Layouts brechen ab und semantische Beziehungen verschwinden. IronPDF bereitet die Dokumente für die KI-Nutzung vor, indem es die Struktur beibehält und Token-Limits verwaltet, so dass das Modell eine saubere, gut organisierte Eingabe erhält.
Fassen Sie eine PDF-Datei mit nur wenigen Codezeilen zusammen:
-
Installieren Sie IronPDF mit NuGet Package Manager
-
Kopieren Sie diesen Codeausschnitt und führen Sie ihn aus.
await IronPdf.AI.PdfAIEngine.Summarize("contract.pdf", "summary.txt", azureEndpoint, azureApiKey); -
Bereitstellen zum Testen in Ihrer Live-Umgebung
Beginnen Sie noch heute, IronPDF in Ihrem Projekt zu verwenden, mit einer kostenlosen Testversion

Nachdem Sie IronPDF gekauft oder sich für eine 30-tägige Testversion angemeldet haben, fügen Sie Ihren Lizenzschlüssel am Anfang Ihrer Anwendung hinzu.
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp-2.csIronPdf.License.LicenseKey = "KEY";
Imports IronPdf
IronPdf.License.LicenseKey = "KEY"Inhaltsverzeichnis
- Die KI + PDF-Chance
- IronPDFs integrierte KI-Integration
- Dokumentenzusammenfassung
- Intelligente Datenextraktion
- Frage-Antwort-über-Dokumente
- Batch-KI-Verarbeitung
- Anwendungsfälle aus der Praxis
- Fehlersuche und technischer Support
Die AI + PDF Chance
Warum PDFs die größte ungenutzte Datenquelle sind
PDFs sind eine der größten Quellen für strukturiertes Geschäftswissen in modernen Unternehmen. Professionelle Dokumente - Verträge, Jahresabschlüsse, Compliance-Berichte, juristische Schriftsätze und Forschungsarbeiten - werden überwiegend im PDF-Format gespeichert. Diese Dokumente enthalten wichtige Geschäftsinformationen: Vertragsbedingungen, die Verpflichtungen und Verbindlichkeiten definieren, Finanzkennzahlen, die Investitionsentscheidungen vorantreiben, gesetzliche Anforderungen, die die Einhaltung von Vorschriften gewährleisten, und Forschungsergebnisse, die die Strategie bestimmen.
Herkömmliche Ansätze zur PDF-Verarbeitung sind jedoch stark eingeschränkt. Einfache Textextraktionstools können rohe Zeichen aus einer Seite extrahieren, aber dabei geht wichtiger Kontext verloren: Tabellenstrukturen werden zu ungeordnetem Text, mehrspaltige Layouts werden unsinnig und die semantischen Beziehungen zwischen Abschnitten verschwinden.
Der Durchbruch kommt durch die Fähigkeit der KI, Kontext und Struktur zu verstehen. Moderne LLMs sehen nicht nur Wörter - sie verstehen die Organisation von Dokumenten, erkennen Muster wie Vertragsklauseln oder Finanztabellen und können selbst aus komplexen Layouts eine Bedeutung herauslesen. Das Unified Reasoning System von GPT-5 mit seinem Echtzeit-Router und die verbesserten agentenbasierten Fähigkeiten von Claude Sonnet 4.5 weisen beide im Vergleich zu früheren Modellen deutlich geringere Halluzinationsraten auf, was sie für die professionelle Dokumentenanalyse zuverlässig macht.
Wie LLMs die Dokumentenstruktur verstehen
Umfangreiche Sprachmodelle bieten ausgefeilte Funktionen zur Verarbeitung natürlicher Sprache für die PDF-Analyse. Die hybride Architektur von GPT-5 umfasst mehrere Teilmodelle (Main, Mini, Thinking, Nano) mit einem Echtzeit-Router, der je nach Komplexität der Aufgabe dynamisch die optimale Variante auswählt - einfache Fragen werden an die schnelleren Modelle weitergeleitet, während komplexe Denkaufgaben das vollständige Modell in Anspruch nehmen.
Claude Opus 4.6 zeichnet sich besonders bei langwierigen agentenbasierten Aufgaben aus, mit Agententeams, die sich direkt bei segmentierten Aufträgen koordinieren, und einem Kontextfenster mit 1 Mio. Token, das ganze Dokumentenbibliotheken ohne Chunking verarbeiten kann.
Dieses kontextbezogene Verständnis ermöglicht es den LLMs, Aufgaben auszuführen, die echtes Verständnis erfordern. Bei der Analyse eines Vertrags kann ein LLM nicht nur Klauseln identifizieren, die das Wort "Kündigung" enthalten, sondern auch die spezifischen Bedingungen, unter denen eine Kündigung zulässig ist, die damit verbundenen Kündigungsanforderungen und die sich daraus ergebenden Verpflichtungen verstehen. Die technische Grundlage, die diese Fähigkeit ermöglicht, ist die Transformator-Architektur, die moderne LLMs antreibt, wobei das Kontextfenster von GPT-5 bis zu 272.000 Eingabe-Token unterstützt und das 200K-Token-Fenster von Claude Sonnet 4.5 eine umfassende Dokumentabdeckung bietet.
IronPDFs integrierte KI-Integration
Installation von IronPDF und AI-Erweiterungen
Für den Einstieg in die KI-gestützte PDF-Verarbeitung sind die IronPDF-Kernbibliothek, das KI-Erweiterungspaket und die Microsoft Semantic Kernel-Abhängigkeiten erforderlich.
Installieren Sie IronPDF mit NuGet Package Manager:
Install-Package IronPdf, IronPdf.Extensions.AI, Microsoft.SemanticKernel, Microsoft.SemanticKernel.Plugins.Memory
Diese Pakete arbeiten zusammen, um eine vollständige Lösung zu bieten. IronPDF übernimmt alle PDF-bezogenen Operationen - Textextraktion, Seitenrendering, Formatkonvertierung - während die KI-Erweiterung die Integration mit Sprachmodellen über den Microsoft Semantic Kernel verwaltet.
<NoWarn>$(NoWarn);SKEXP0001;SKEXP0010;SKEXP0050</NoWarn> zu Ihrer .csproj PropertyGroup hinzu, um Compiler-Warnungen zu unterdrücken.Konfiguration Ihres OpenAI/Azure API-Schlüssels
Bevor Sie die KI-Funktionen nutzen können, müssen Sie den Zugang zu einem KI-Dienstanbieter konfigurieren. Die AI-Erweiterung von IronPDF unterstützt sowohl OpenAI als auch Azure OpenAI. Azure OpenAI wird häufig für Unternehmensanwendungen bevorzugt, da es erweiterte Sicherheitsfunktionen, Compliance-Zertifizierungen und die Möglichkeit bietet, Daten innerhalb bestimmter geografischer Regionen zu speichern.
Um Azure OpenAI zu konfigurieren, benötigen Sie Ihre Azure-Endpunkt-URL, den API-Schlüssel und die Bereitstellungsnamen sowohl für den Chat als auch für die Einbettung von Modellen aus dem Azure-Portal.
Initialisierung der KI-Engine
Die KI-Erweiterung von IronPDF nutzt den Microsoft Semantic Kernel unter der Haube. Bevor Sie die KI-Funktionen nutzen können, müssen Sie den Kernel mit Ihren Azure OpenAI-Anmeldeinformationen initialisieren und den Speicher für die Dokumentenverarbeitung konfigurieren.
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/configure-azure-credentials.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
// Initialize IronPDF AI with Azure OpenAI credentials
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel with Azure OpenAI
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
// Create memory store for document embeddings
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
// Initialize IronPDF AI
IronDocumentAI.Initialize(kernel, memory);
Console.WriteLine("IronPDF AI initialized successfully with Azure OpenAI");Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
' Initialize IronPDF AI with Azure OpenAI credentials
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel with Azure OpenAI
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
' Create memory store for document embeddings
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
' Initialize IronPDF AI
IronDocumentAI.Initialize(kernel, memory)
Console.WriteLine("IronPDF AI initialized successfully with Azure OpenAI")Bei der Initialisierung werden zwei Schlüsselkomponenten erstellt:
- Kernel: Vervollständigung von Chats und Erzeugung von Texteinbettungen durch Azure OpenAI
- Speicher: Speichert Dokumenteinbettungen für semantische Such- und Abrufvorgänge
Sobald es mit IronDocumentAI.Initialize() initialisiert ist, können Sie KI-Funktionen in Ihrer gesamten Anwendung verwenden. Für Produktionsanwendungen wird die Speicherung von Anmeldeinformationen in Umgebungsvariablen oder Azure Key Vault dringend empfohlen.
Wie IronPDF PDFs für den KI-Kontext aufbereitet
Einer der schwierigsten Aspekte der KI-gestützten PDF-Verarbeitung ist die Vorbereitung der Dokumente für die Verwendung durch Sprachmodelle. Obwohl GPT-5 bis zu 272.000 Eingabe-Token unterstützt und Claude Opus 4.6 jetzt ein Kontextfenster mit 1 Mio. Token bietet, kann ein einzelner juristischer Vertrag oder Finanzbericht die Grenzen älterer Modelle immer noch leicht überschreiten.
Die KI-Erweiterung von IronPDF bewältigt diese Komplexität durch intelligente Dokumentvorbereitung. Wenn Sie eine AI-Methode aufrufen, extrahiert IronPDF zunächst den Text aus der PDF-Datei, wobei die strukturellen Informationen erhalten bleiben, d. h. die Absätze werden identifiziert, die Tabellenstrukturen bleiben erhalten und die Beziehungen zwischen den Abschnitten werden beibehalten.
Für Dokumente, die über den Kontext hinausgehen, implementiert IronPDF strategisches Chunking an semantischen Haltepunkten, d. h. an natürlichen Unterteilungen der Dokumentstruktur wie Abschnittsüberschriften, Seitenumbrüchen oder Absatzgrenzen.
Zusammenfassung eines Dokuments
Zusammenfassungen einzelner Dokumente
Die Zusammenfassung von Dokumenten liefert einen unmittelbaren Nutzen, indem sie lange Dokumente zu verdaulichen Erkenntnissen verdichtet. Die Methode Summarize verwaltet den gesamten Arbeitsablauf: extrahiert Text, bereitet ihn für die KI-Nutzung vor, fordert eine Zusammenfassung vom Sprachmodell an und speichert die Ergebnisse.
Eingabe
Der Code lädt ein PDF mit PdfDocument.FromFile() und ruft pdf.Summarize() auf, um eine prägnante Zusammenfassung zu erstellen, und speichert dann das Ergebnis in einer Textdatei.
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/single-document-summary.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
// Summarize a PDF document using IronPDF AI
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
// Load and summarize PDF
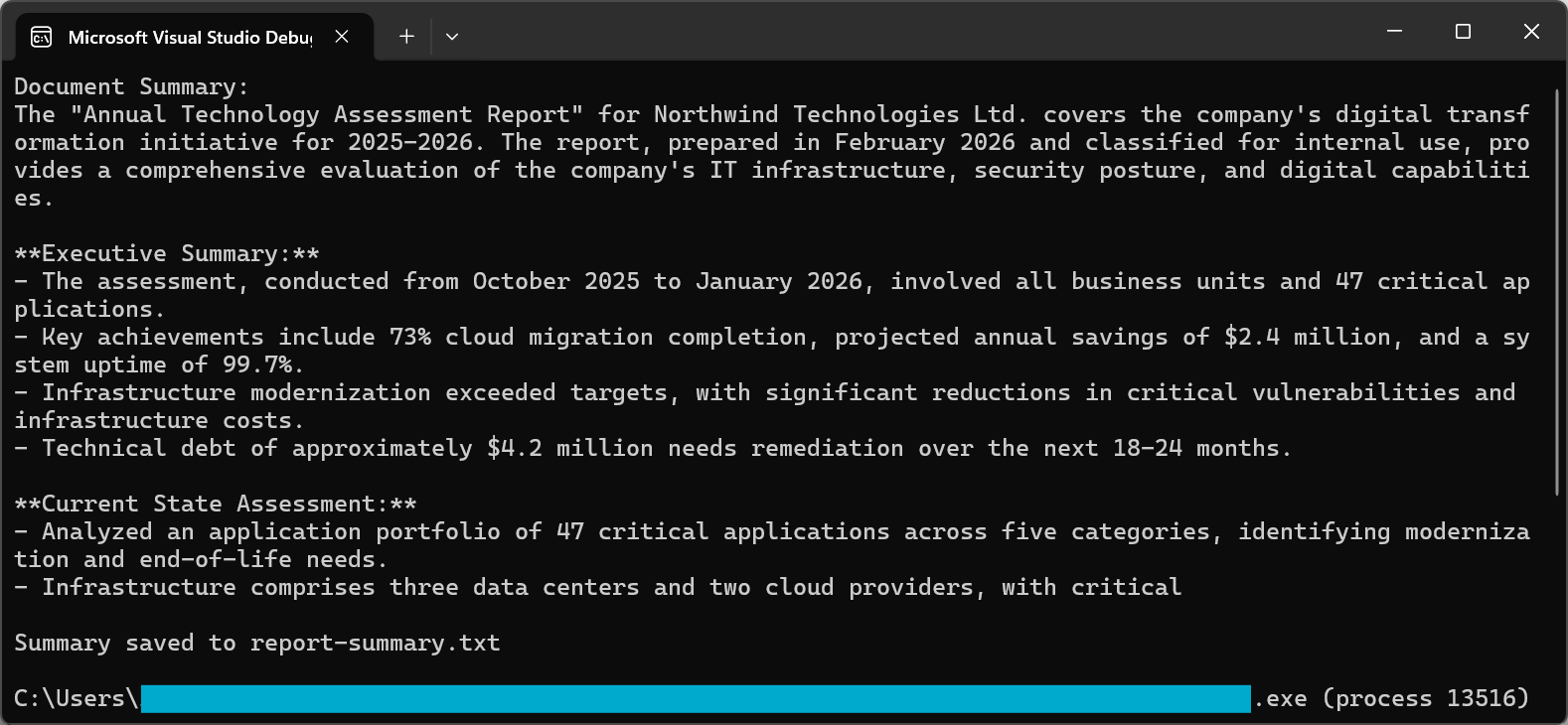
var pdf = PdfDocument.FromFile("sample-report.pdf");
string summary = await pdf.Summarize();
Console.WriteLine("Document Summary:");
Console.WriteLine(summary);
File.WriteAllText("report-summary.txt", summary);
Console.WriteLine("\nSummary saved to report-summary.txt");Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
' Summarize a PDF document using IronPDF AI
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
' Load and summarize PDF
Dim pdf = PdfDocument.FromFile("sample-report.pdf")
Dim summary As String = Await pdf.Summarize()
Console.WriteLine("Document Summary:")
Console.WriteLine(summary)
File.WriteAllText("report-summary.txt", summary)
Console.WriteLine(vbCrLf & "Summary saved to report-summary.txt")Konsolenausgabe
Der Zusammenfassungsprozess verwendet ausgefeilte Eingabeaufforderungen, um qualitativ hochwertige Ergebnisse zu gewährleisten. Sowohl GPT-5 als auch Claude Sonnet 4.5 im Jahr 2026 verfügen über deutlich verbesserte Funktionen zum Verfolgen von Anweisungen, die sicherstellen, dass die Zusammenfassungen die wesentlichen Informationen erfassen und gleichzeitig prägnant und lesbar bleiben.
Eine ausführlichere Erläuterung der Techniken zur Zusammenfassung von Dokumenten und der erweiterten Optionen finden Sie in unserem How-to-Guide.
Multi-Dokumenten-Synthese
Viele reale Szenarien erfordern die Zusammenfassung von Informationen aus mehreren Dokumenten. Ein Rechtsteam muss möglicherweise gemeinsame Klauseln in einem Portfolio von Verträgen identifizieren, oder ein Finanzanalyst möchte Kennzahlen in Quartalsberichten vergleichen.
Bei der Synthese mehrerer Dokumente wird jedes Dokument einzeln bearbeitet, um die wichtigsten Informationen zu extrahieren, und diese Erkenntnisse werden dann für die endgültige Synthese zusammengefasst.
Dieses Beispiel durchläuft mehrere PDFs, ruft bei jedem pdf.Summarize() auf, und verwendet dann pdf.Query() mit den kombinierten Zusammenfassungen, um eine einheitliche Synthese zu erstellen.
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/multi-document-synthesis.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
// Synthesize insights across multiple related documents (e.g., quarterly reports into annual summary)
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
// Define documents to synthesize
string[] documentPaths = {
"Q1-report.pdf",
"Q2-report.pdf",
"Q3-report.pdf",
"Q4-report.pdf"
};
var documentSummaries = new List<string>();
// Summarize each document
foreach (string path in documentPaths)
{
var pdf = PdfDocument.FromFile(path);
string summary = await pdf.Summarize();
documentSummaries.Add($"=== {Path.GetFileName(path)} ===\n{summary}");
Console.WriteLine($"Processed: {path}");
}
// Combine and synthesize across all documents
string combinedSummaries = string.Join("\n\n", documentSummaries);
var synthesisDoc = PdfDocument.FromFile(documentPaths[0]);
string synthesisQuery = @"Based on the quarterly summaries below, provide an annual synthesis:
ll trends across quarters
chievements and challenges
over-year patterns
s:
inedSummaries;
string synthesis = await synthesisDoc.Query(synthesisQuery);
Console.WriteLine("\n=== Annual Synthesis ===");
Console.WriteLine(synthesis);
File.WriteAllText("annual-synthesis.txt", synthesis);Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
Imports System.IO
' Synthesize insights across multiple related documents (e.g., quarterly reports into annual summary)
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
' Define documents to synthesize
Dim documentPaths As String() = {
"Q1-report.pdf",
"Q2-report.pdf",
"Q3-report.pdf",
"Q4-report.pdf"
}
Dim documentSummaries = New List(Of String)()
' Summarize each document
For Each path As String In documentPaths
Dim pdf = PdfDocument.FromFile(path)
Dim summary As String = Await pdf.Summarize()
documentSummaries.Add($"=== {Path.GetFileName(path)} ==={vbCrLf}{summary}")
Console.WriteLine($"Processed: {path}")
Next
' Combine and synthesize across all documents
Dim combinedSummaries As String = String.Join(vbCrLf & vbCrLf, documentSummaries)
Dim synthesisDoc = PdfDocument.FromFile(documentPaths(0))
Dim synthesisQuery As String = "Based on the quarterly summaries below, provide an annual synthesis:" & vbCrLf &
"Overall trends across quarters" & vbCrLf &
"Key achievements and challenges" & vbCrLf &
"Year-over-year patterns" & vbCrLf & vbCrLf &
combinedSummaries
Dim synthesis As String = Await synthesisDoc.Query(synthesisQuery)
Console.WriteLine(vbCrLf & "=== Annual Synthesis ===")
Console.WriteLine(synthesis)
File.WriteAllText("annual-synthesis.txt", synthesis)Dieses Muster lässt sich effektiv auf große Dokumentensätze übertragen. Durch die parallele Verarbeitung von Dokumenten und die Verwaltung von Zwischenergebnissen können Sie Hunderte oder Tausende von Dokumenten analysieren und dabei eine kohärente Synthese beibehalten.
Erstellung einer Zusammenfassung
Zusammenfassungen erfordern einen anderen Ansatz als Standardzusammenfassungen. Anstatt den Inhalt einfach nur zusammenzufassen, muss eine Zusammenfassung die wichtigsten Informationen herausstellen, die wichtigsten Entscheidungen oder Empfehlungen hervorheben und die Ergebnisse in einem Format präsentieren, das für die Überprüfung durch die Geschäftsführung geeignet ist.
Der Code verwendet pdf.Query() mit einem strukturierten Prompt, der nach wichtigen Entscheidungen, kritischen Ergebnissen, finanziellen Auswirkungen und Risikobewertungen in Geschäftssprache fragt.
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/executive-summary.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
// Generate executive summary from strategic documents for C-suite leadership
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
var pdf = PdfDocument.FromFile("strategic-plan.pdf");
string executiveQuery = @"Create an executive summary for C-suite leadership. Include:
cisions Required:**
ny decisions needing executive approval
al Findings:**
5 most important findings (bullet points)
ial Impact:**
e/cost implications if mentioned
ssessment:**
riority risks identified
ended Actions:**
ate next steps
er 500 words. Use business language appropriate for board presentation.";
string executiveSummary = await pdf.Query(executiveQuery);
File.WriteAllText("executive-summary.txt", executiveSummary);
Console.WriteLine("Executive summary saved to executive-summary.txt");Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
' Generate executive summary from strategic documents for C-suite leadership
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
Dim pdf = PdfDocument.FromFile("strategic-plan.pdf")
Dim executiveQuery As String = "Create an executive summary for C-suite leadership. Include:
cisions Required:**
ny decisions needing executive approval
al Findings:**
5 most important findings (bullet points)
ial Impact:**
e/cost implications if mentioned
ssessment:**
riority risks identified
ended Actions:**
ate next steps
er 500 words. Use business language appropriate for board presentation."
Dim executiveSummary As String = Await pdf.Query(executiveQuery)
File.WriteAllText("executive-summary.txt", executiveSummary)
Console.WriteLine("Executive summary saved to executive-summary.txt")Das Ergebnis ist eine Zusammenfassung, die den Schwerpunkt auf umsetzbare Informationen legt und nicht auf umfassende Informationen, die den Entscheidungsträgern genau das liefern, was sie brauchen, ohne sie mit Details zu überfordern.
Intelligente Datenextraktion
Strukturierte Daten in JSON extrahieren
Eine der leistungsfähigsten Anwendungen der KI-gestützten PDF-Verarbeitung ist die Extraktion strukturierter Daten aus unstrukturierten Dokumenten. Der Schlüssel zur erfolgreichen strukturierten Extraktion im Jahr 2026 ist die Verwendung von JSON-Schemata mit strukturierten Ausgabemodi. GPT-5 führt eine verbesserte strukturierte Ausgabe ein, während Claude Sonnet 4.5 eine verbesserte Tool-Orchestrierung für eine zuverlässige Datenextraktion bietet.
Eingabe
Der Code ruft pdf.Query() mit einem JSON-Schema-Prompt auf und verwendet dann JsonSerializer.Deserialize(), um die extrahierten Rechnungsdaten zu analysieren und zu validieren.
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/extract-invoice-json.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
using System.Text.Json;
// Extract structured invoice data as JSON from PDF
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
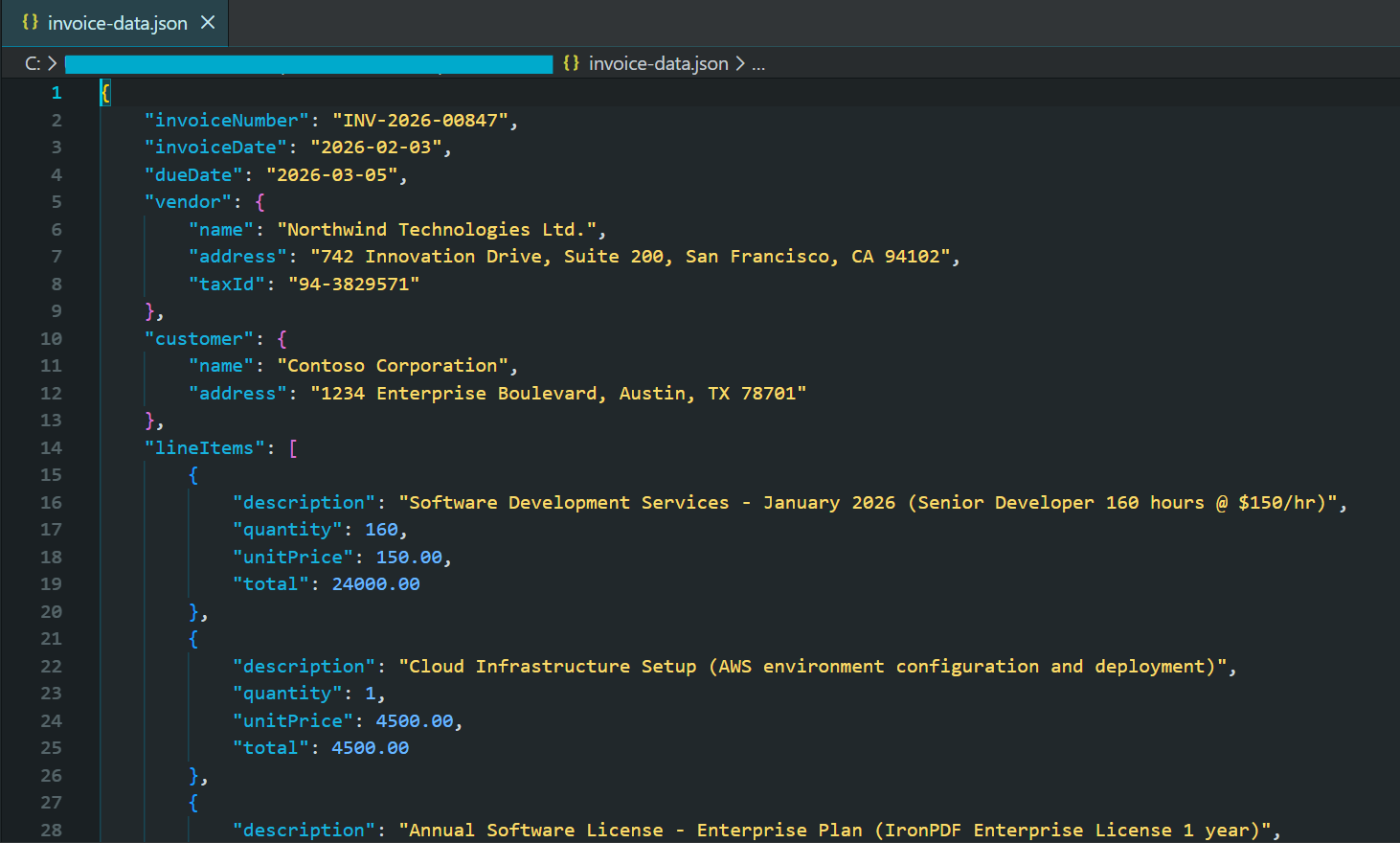
var pdf = PdfDocument.FromFile("sample-invoice.pdf");
// Define JSON schema for extraction
string extractionQuery = @"Extract invoice data and return as JSON with this exact structure:
voiceNumber"": ""string"",
voiceDate"": ""YYYY-MM-DD"",
eDate"": ""YYYY-MM-DD"",
ndor"": {
""name"": ""string"",
""address"": ""string"",
""taxId"": ""string or null""
stomer"": {
""name"": ""string"",
""address"": ""string""
neItems"": [
{
""description"": ""string"",
""quantity"": number,
""unitPrice"": number,
""total"": number
}
btotal"": number,
xRate"": number,
xAmount"": number,
tal"": number,
rrency"": ""string""
NLY valid JSON, no additional text.";
string jsonResponse = await pdf.Query(extractionQuery);
// Parse and save JSON
try
{
var invoiceData = JsonSerializer.Deserialize<JsonElement>(jsonResponse);
string formattedJson = JsonSerializer.Serialize(invoiceData, new JsonSerializerOptions { WriteIndented = true });
Console.WriteLine("Extracted Invoice Data:");
Console.WriteLine(formattedJson);
File.WriteAllText("invoice-data.json", formattedJson);
}
catch (JsonException)
{
Console.WriteLine("Unable to parse JSON response");
File.WriteAllText("invoice-raw-response.txt", jsonResponse);
}Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
Imports System.Text.Json
' Extract structured invoice data as JSON from PDF
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
Dim pdf = PdfDocument.FromFile("sample-invoice.pdf")
' Define JSON schema for extraction
Dim extractionQuery As String = "Extract invoice data and return as JSON with this exact structure:
voiceNumber"": ""string"",
voiceDate"": ""YYYY-MM-DD"",
eDate"": ""YYYY-MM-DD"",
ndor"": {
""name"": ""string"",
""address"": ""string"",
""taxId"": ""string or null""
stomer"": {
""name"": ""string"",
""address"": ""string""
neItems"": [
{
""description"": ""string"",
""quantity"": number,
""unitPrice"": number,
""total"": number
}
btotal"": number,
xRate"": number,
xAmount"": number,
tal"": number,
rrency"": ""string""
NLY valid JSON, no additional text."
Dim jsonResponse As String = Await pdf.QueryAsync(extractionQuery)
' Parse and save JSON
Try
Dim invoiceData = JsonSerializer.Deserialize(Of JsonElement)(jsonResponse)
Dim formattedJson As String = JsonSerializer.Serialize(invoiceData, New JsonSerializerOptions With {.WriteIndented = True})
Console.WriteLine("Extracted Invoice Data:")
Console.WriteLine(formattedJson)
File.WriteAllText("invoice-data.json", formattedJson)
Catch ex As JsonException
Console.WriteLine("Unable to parse JSON response")
File.WriteAllText("invoice-raw-response.txt", jsonResponse)
End TryTeilweiser Screenshot der generierten JSON-Datei
Moderne KI-Modelle im Jahr 2026 unterstützen strukturierte Ausgabemodi, die gültige JSON-Antworten garantieren, die den vorgegebenen Schemata entsprechen. Dadurch entfällt die Notwendigkeit einer komplexen Fehlerbehandlung bei fehlerhaften Antworten.
Vertragsklausel-Identifizierung
Juristische Verträge enthalten bestimmte Arten von Klauseln, die von besonderer Bedeutung sind: Kündigungsbestimmungen, Haftungsbeschränkungen, Entschädigungsanforderungen, Abtretung von geistigem Eigentum und Vertraulichkeitsverpflichtungen. Die KI-gestützte Klauselidentifizierung automatisiert diese Analyse und gewährleistet gleichzeitig eine hohe Genauigkeit.
Dieses Beispiel verwendet pdf.Query() mit einem auf Klauseln fokussierten JSON-Schema, um Vertragstyp, Parteien, kritische Termine und einzelne Vertragsklauseln mit Risikolevels zu extrahieren.
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/contract-clause-analysis.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
using System.Text.Json;
// Analyze contract clauses and identify key terms, risks, and critical dates
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
var pdf = PdfDocument.FromFile("contract.pdf");
// Define JSON schema for contract analysis
string clauseQuery = @"Analyze this contract and identify key clauses. Return JSON:
ntractType"": ""string"",
rties"": [""string""],
fectiveDate"": ""string"",
auses"": [
{
""type"": ""Termination|Liability|Indemnification|Confidentiality|IP|Payment|Warranty|Other"",
""title"": ""string"",
""summary"": ""string"",
""riskLevel"": ""Low|Medium|High"",
""keyTerms"": [""string""]
}
iticalDates"": [
{
""description"": ""string"",
""date"": ""string""
}
erallRiskAssessment"": ""Low|Medium|High"",
commendations"": [""string""]
: termination rights, liability caps, indemnification, IP ownership, confidentiality, payment terms.
NLY valid JSON.";
string analysisJson = await pdf.Query(clauseQuery);
try
{
var analysis = JsonSerializer.Deserialize<JsonElement>(analysisJson);
string formatted = JsonSerializer.Serialize(analysis, new JsonSerializerOptions { WriteIndented = true });
Console.WriteLine("Contract Clause Analysis:");
Console.WriteLine(formatted);
File.WriteAllText("contract-analysis.json", formatted);
// Display high-risk clauses
Console.WriteLine("\n=== High Risk Clauses ===");
foreach (var clause in analysis.GetProperty("clauses").EnumerateArray())
{
if (clause.GetProperty("riskLevel").GetString() == "High")
{
Console.WriteLine($"- {clause.GetProperty("type")}: {clause.GetProperty("summary")}");
}
}
}
catch (JsonException)
{
Console.WriteLine("Unable to parse contract analysis");
File.WriteAllText("contract-analysis-raw.txt", analysisJson);
}Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
Imports System.Text.Json
' Analyze contract clauses and identify key terms, risks, and critical dates
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
Dim pdf = PdfDocument.FromFile("contract.pdf")
' Define JSON schema for contract analysis
Dim clauseQuery As String = "Analyze this contract and identify key clauses. Return JSON:
ntractType"": ""string"",
rties"": [""string""],
fectiveDate"": ""string"",
auses"": [
{
""type"": ""Termination|Liability|Indemnification|Confidentiality|IP|Payment|Warranty|Other"",
""title"": ""string"",
""summary"": ""string"",
""riskLevel"": ""Low|Medium|High"",
""keyTerms"": [""string""]
}
iticalDates"": [
{
""description"": ""string"",
""date"": ""string""
}
erallRiskAssessment"": ""Low|Medium|High"",
commendations"": [""string""]
: termination rights, liability caps, indemnification, IP ownership, confidentiality, payment terms.
NLY valid JSON."
Dim analysisJson As String = Await pdf.Query(clauseQuery)
Try
Dim analysis = JsonSerializer.Deserialize(Of JsonElement)(analysisJson)
Dim formatted As String = JsonSerializer.Serialize(analysis, New JsonSerializerOptions With {.WriteIndented = True})
Console.WriteLine("Contract Clause Analysis:")
Console.WriteLine(formatted)
File.WriteAllText("contract-analysis.json", formatted)
' Display high-risk clauses
Console.WriteLine(vbCrLf & "=== High Risk Clauses ===")
For Each clause In analysis.GetProperty("clauses").EnumerateArray()
If clause.GetProperty("riskLevel").GetString() = "High" Then
Console.WriteLine($"- {clause.GetProperty("type")}: {clause.GetProperty("summary")}")
End If
Next
Catch ex As JsonException
Console.WriteLine("Unable to parse contract analysis")
File.WriteAllText("contract-analysis-raw.txt", analysisJson)
End TryDiese Funktion verwandelt die Vertragsprüfung von einem sequentiellen, manuellen Prozess in einen automatisierten, skalierbaren Arbeitsablauf. Rechtsteams können risikoreiche Bestimmungen in Hunderten von Verträgen schnell identifizieren.
Finanzdaten-Parsing
Finanzdokumente enthalten wichtige quantitative Daten, die in komplexe Erzählungen und Tabellen eingebettet sind. KI-gestütztes Parsing eignet sich hervorragend für Finanzdokumente, da es den Kontext versteht - es kann zwischen historischen Ergebnissen und Zukunftsprognosen unterscheiden, erkennen, ob Zahlen in Tausend oder Millionen angegeben sind, und Beziehungen zwischen verschiedenen Kennzahlen verstehen.
Der Code verwendet pdf.Query() mit einem finanziellen JSON-Schema, um Daten der Gewinn- und Verlustrechnung, Bilanzkennzahlen und Zukunftsprognosen in eine strukturierte Ausgabe zu extrahieren.
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/financial-data-extraction.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
using System.Text.Json;
// Extract financial metrics from annual reports and earnings documents
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
var pdf = PdfDocument.FromFile("annual-report.pdf");
// Define JSON schema for financial extraction (numbers in millions)
string financialQuery = @"Extract financial metrics from this document. Return JSON:
portPeriod"": ""string"",
mpany"": ""string"",
rrency"": ""string"",
comeStatement"": {
""revenue"": number,
""costOfRevenue"": number,
""grossProfit"": number,
""operatingExpenses"": number,
""operatingIncome"": number,
""netIncome"": number,
""eps"": number
lanceSheet"": {
""totalAssets"": number,
""totalLiabilities"": number,
""shareholdersEquity"": number,
""cash"": number,
""totalDebt"": number
yMetrics"": {
""revenueGrowthYoY"": ""string"",
""grossMargin"": ""string"",
""operatingMargin"": ""string"",
""netMargin"": ""string"",
""debtToEquity"": number
idance"": {
""nextQuarterRevenue"": ""string"",
""fullYearRevenue"": ""string"",
""notes"": ""string""
for unavailable data. Numbers in millions unless stated.
NLY valid JSON.";
string financialJson = await pdf.Query(financialQuery);
try
{
var financials = JsonSerializer.Deserialize<JsonElement>(financialJson);
string formatted = JsonSerializer.Serialize(financials, new JsonSerializerOptions { WriteIndented = true });
Console.WriteLine("Extracted Financial Data:");
Console.WriteLine(formatted);
File.WriteAllText("financial-data.json", formatted);
}
catch (JsonException)
{
Console.WriteLine("Unable to parse financial data");
File.WriteAllText("financial-raw.txt", financialJson);
}Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
Imports System.Text.Json
' Extract financial metrics from annual reports and earnings documents
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
Dim pdf = PdfDocument.FromFile("annual-report.pdf")
' Define JSON schema for financial extraction (numbers in millions)
Dim financialQuery As String = "Extract financial metrics from this document. Return JSON:
portPeriod"": ""string"",
mpany"": ""string"",
rrency"": ""string"",
comeStatement"": {
""revenue"": number,
""costOfRevenue"": number,
""grossProfit"": number,
""operatingExpenses"": number,
""operatingIncome"": number,
""netIncome"": number,
""eps"": number
lanceSheet"": {
""totalAssets"": number,
""totalLiabilities"": number,
""shareholdersEquity"": number,
""cash"": number,
""totalDebt"": number
yMetrics"": {
""revenueGrowthYoY"": ""string"",
""grossMargin"": ""string"",
""operatingMargin"": ""string"",
""netMargin"": ""string"",
""debtToEquity"": number
idance"": {
""nextQuarterRevenue"": ""string"",
""fullYearRevenue"": ""string"",
""notes"": ""string""
for unavailable data. Numbers in millions unless stated.
NLY valid JSON."
Dim financialJson As String = Await pdf.Query(financialQuery)
Try
Dim financials = JsonSerializer.Deserialize(Of JsonElement)(financialJson)
Dim formatted As String = JsonSerializer.Serialize(financials, New JsonSerializerOptions With {.WriteIndented = True})
Console.WriteLine("Extracted Financial Data:")
Console.WriteLine(formatted)
File.WriteAllText("financial-data.json", formatted)
Catch ex As JsonException
Console.WriteLine("Unable to parse financial data")
File.WriteAllText("financial-raw.txt", financialJson)
End TryDie extrahierten strukturierten Daten können direkt in Finanzmodelle, Zeitreihendatenbanken oder Analyseplattformen eingespeist werden und ermöglichen eine automatische Verfolgung von Kennzahlen über Berichtszeiträume hinweg.
Benutzerdefinierte Extraktionsaufforderungen
Viele Unternehmen haben spezielle Extraktionsanforderungen, die auf ihrem spezifischen Fachgebiet, ihren Dokumentenformaten oder Geschäftsprozessen basieren. Die KI-Integration von IronPDF unterstützt in vollem Umfang benutzerdefinierte Extraktionsaufforderungen, so dass Sie genau festlegen können, welche Informationen extrahiert werden sollen und wie sie strukturiert werden sollen.
Dieses Beispiel zeigt pdf.Query() mit einem auf Forschung fokussierten Schema, das Methodik, wichtige Ergebnisse mit Vertrauensstufen und Einschränkungen aus wissenschaftlichen Arbeiten extrahiert.
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/custom-research-extraction.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
using System.Text.Json;
// Extract structured research metadata from academic papers
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
var pdf = PdfDocument.FromFile("research-paper.pdf");
// Define JSON schema for research paper extraction
string researchQuery = @"Extract structured information from this research paper. Return JSON:
tle"": ""string"",
thors"": [""string""],
stitution"": ""string"",
blicationDate"": ""string"",
stract"": ""string"",
searchQuestion"": ""string"",
thodology"": {
""type"": ""Quantitative|Qualitative|Mixed Methods"",
""approach"": ""string"",
""sampleSize"": ""string"",
""dataCollection"": ""string""
yFindings"": [
{
""finding"": ""string"",
""significance"": ""string"",
""confidence"": ""High|Medium|Low""
}
mitations"": [""string""],
tureWork"": [""string""],
ywords"": [""string""]
extracting verifiable claims and noting uncertainty.
NLY valid JSON.";
string extractionResult = await pdf.Query(researchQuery);
try
{
var research = JsonSerializer.Deserialize<JsonElement>(extractionResult);
string formatted = JsonSerializer.Serialize(research, new JsonSerializerOptions { WriteIndented = true });
Console.WriteLine("Research Paper Extraction:");
Console.WriteLine(formatted);
File.WriteAllText("research-extraction.json", formatted);
// Display key findings with confidence levels
Console.WriteLine("\n=== Key Findings ===");
foreach (var finding in research.GetProperty("keyFindings").EnumerateArray())
{
string confidence = finding.GetProperty("confidence").GetString() ?? "Unknown";
Console.WriteLine($"[{confidence}] {finding.GetProperty("finding")}");
}
}
catch (JsonException)
{
Console.WriteLine("Unable to parse research extraction");
File.WriteAllText("research-raw.txt", extractionResult);
}Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
Imports System.Text.Json
' Extract structured research metadata from academic papers
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
Dim pdf = PdfDocument.FromFile("research-paper.pdf")
' Define JSON schema for research paper extraction
Dim researchQuery As String = "Extract structured information from this research paper. Return JSON:
tle"": ""string"",
thors"": [""string""],
stitution"": ""string"",
blicationDate"": ""string"",
stract"": ""string"",
searchQuestion"": ""string"",
thodology"": {
""type"": ""Quantitative|Qualitative|Mixed Methods"",
""approach"": ""string"",
""sampleSize"": ""string"",
""dataCollection"": ""string""
yFindings"": [
{
""finding"": ""string"",
""significance"": ""string"",
""confidence"": ""High|Medium|Low""
}
mitations"": [""string""],
tureWork"": [""string""],
ywords"": [""string""]
extracting verifiable claims and noting uncertainty.
NLY valid JSON."
Dim extractionResult As String = Await pdf.Query(researchQuery)
Try
Dim research = JsonSerializer.Deserialize(Of JsonElement)(extractionResult)
Dim formatted As String = JsonSerializer.Serialize(research, New JsonSerializerOptions With {.WriteIndented = True})
Console.WriteLine("Research Paper Extraction:")
Console.WriteLine(formatted)
File.WriteAllText("research-extraction.json", formatted)
' Display key findings with confidence levels
Console.WriteLine(vbCrLf & "=== Key Findings ===")
For Each finding In research.GetProperty("keyFindings").EnumerateArray()
Dim confidence As String = finding.GetProperty("confidence").GetString() OrElse "Unknown"
Console.WriteLine($"[{confidence}] {finding.GetProperty("finding")}")
Next
Catch ex As JsonException
Console.WriteLine("Unable to parse research extraction")
File.WriteAllText("research-raw.txt", extractionResult)
End TryBenutzerdefinierte Prompts verwandeln die KI-gestützte Extraktion von einem generischen Tool in eine spezialisierte Lösung, die auf Ihre spezifischen Bedürfnisse zugeschnitten ist.
Meine Lieblingsbibliothek dieser Art ist IronPDF. Es ermöglicht eine schnelle und effiziente Bearbeitung von PDF-Dateien. Es verfügt auch über viele wertvolle Funktionen, wie das Exportieren in das PDF/A-Format und das digitale Signieren von PDF-Dokumenten.
IronOCR bedeutet, dass wir jährlich 40.000 $ durch manuelle Verarbeitung einsparen können, während die Produktivität gesteigert wird und Ressourcen für wichtige Aufgaben freigesetzt werden. Ich würde es sehr empfehlen.
Die Iron Suite spielt eine entscheidende Rolle in unseren Operationen. Diese Werkzeuge erhöhen die Effizienz im gesamten Unternehmen, einschließlich der Erstellung von Grundrissen und der Verbesserung des Bestandsmanagements.
Fragenbeantwortung über Dokumente
Aufbau eines PDF-Q&A-Systems
Systeme zur Beantwortung von Fragen ermöglichen es Benutzern, mit PDF-Dokumenten zu interagieren, indem sie in natürlicher Sprache Fragen stellen und präzise, kontextbezogene Antworten erhalten. Das Grundmuster besteht darin, Text aus der PDF-Datei zu extrahieren, ihn mit der Frage des Benutzers in einer Eingabeaufforderung zu kombinieren und eine Antwort von der KI anzufordern.
Eingabe
Der Code ruft pdf.Memorize() auf, um das Dokument für die semantische Suche zu indexieren, und tritt dann in eine interaktive Schleife ein, um mit pdf.Query() Benutzerfragen zu beantworten.
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/pdf-question-answering.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
// Interactive Q&A system for querying PDF documents
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
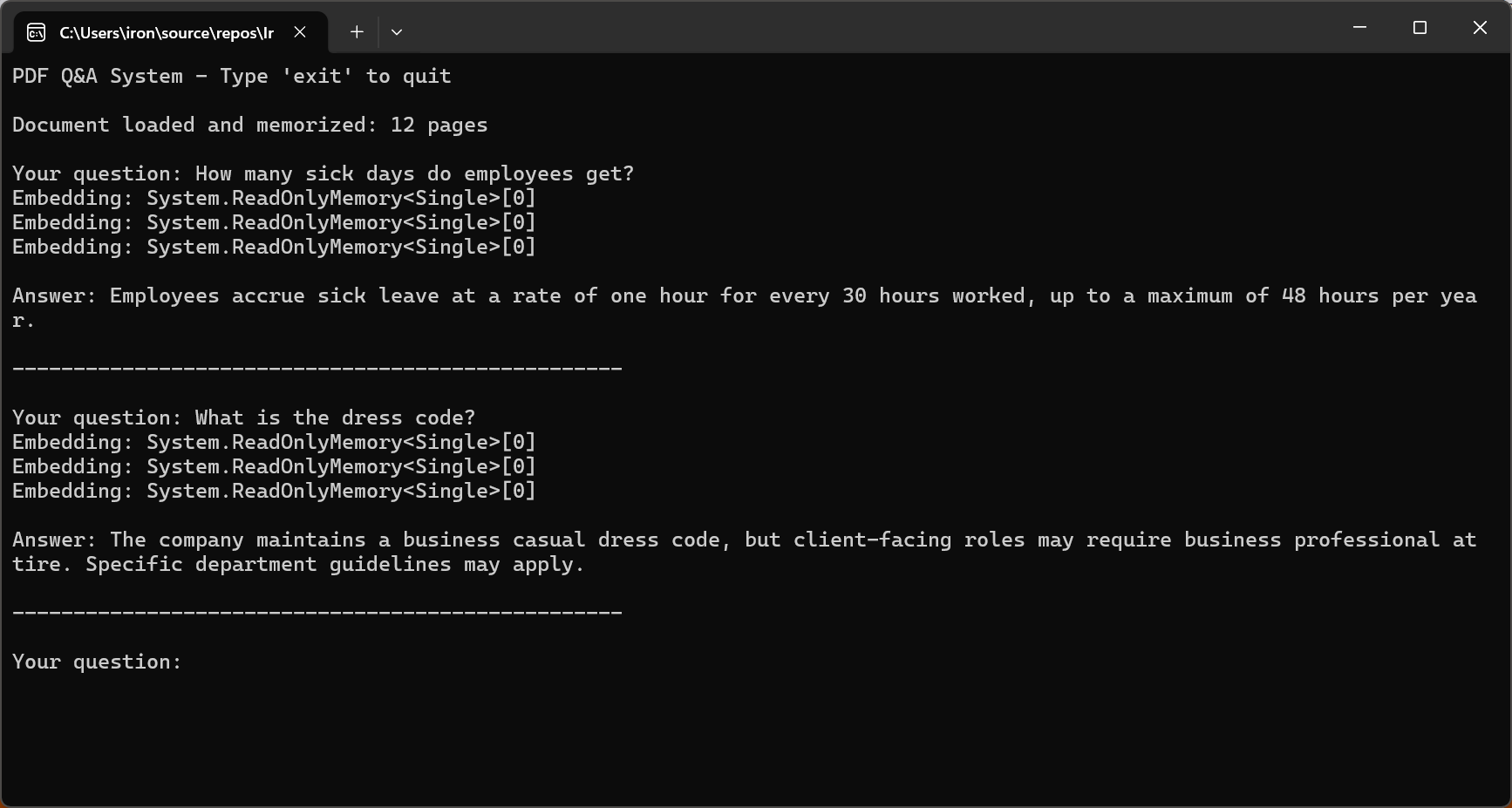
var pdf = PdfDocument.FromFile("sample-legal-document.pdf");
// Memorize document to enable persistent querying
await pdf.Memorize();
Console.WriteLine("PDF Q&A System - Type 'exit' to quit\n");
Console.WriteLine($"Document loaded and memorized: {pdf.PageCount} pages\n");
// Interactive Q&A loop
while (true)
{
Console.Write("Your question: ");
string? question = Console.ReadLine();
if (string.IsNullOrWhiteSpace(question) || question.ToLower() == "exit")
break;
string answer = await pdf.Query(question);
Console.WriteLine($"\nAnswer: {answer}\n");
Console.WriteLine(new string('-', 50) + "\n");
}
Console.WriteLine("Q&A session ended.");Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
' Interactive Q&A system for querying PDF documents
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
Dim pdf = PdfDocument.FromFile("sample-legal-document.pdf")
' Memorize document to enable persistent querying
Await pdf.Memorize()
Console.WriteLine("PDF Q&A System - Type 'exit' to quit" & vbCrLf)
Console.WriteLine($"Document loaded and memorized: {pdf.PageCount} pages" & vbCrLf)
' Interactive Q&A loop
While True
Console.Write("Your question: ")
Dim question As String = Console.ReadLine()
If String.IsNullOrWhiteSpace(question) OrElse question.ToLower() = "exit" Then
Exit While
End If
Dim answer As String = Await pdf.Query(question)
Console.WriteLine($"{vbCrLf}Answer: {answer}{vbCrLf}")
Console.WriteLine(New String("-"c, 50) & vbCrLf)
End While
Console.WriteLine("Q&A session ended.")Konsolenausgabe
Der Schlüssel zu effektiven Fragen und Antworten im Jahr 2026 ist die Beschränkung der KI auf Antworten, die ausschließlich auf dem Dokumentinhalt basieren. Die Trainingsmethode "sichere Vervollständigungen" von GPT-5 und das verbesserte Alignment von Claude Sonnet 4.5 reduzieren die Halluzinationsrate erheblich.
Lange Dokumente für Kontextfenster chunking
Die meisten Dokumente aus der realen Welt überschreiten die AI-Kontextfenster. Effektive Chunking-Strategien sind für die Bearbeitung dieser Dokumente unerlässlich. Beim Chunking werden Dokumente in Segmente unterteilt, die klein genug sind, um in Kontextfenster zu passen, wobei die semantische Kohärenz erhalten bleibt.
Dieser Code iteriert über pdf.Pages, erstellt DocumentChunk Objekte mit konfigurierbaren maxChunkTokens und overlapTokens für Kontextkontinuität.
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/semantic-document-chunking.csusing IronPdf;
// Split long documents into overlapping chunks for RAG systems
var pdf = PdfDocument.FromFile("long-document.pdf");
// Chunking configuration
int maxChunkTokens = 4000; // Leave room for prompts and responses
int overlapTokens = 200; // Overlap for context continuity
int approxCharsPerToken = 4; // Rough estimate for tokenization
int maxChunkChars = maxChunkTokens * approxCharsPerToken;
int overlapChars = overlapTokens * approxCharsPerToken;
var chunks = new List<DocumentChunk>();
var currentChunk = new System.Text.StringBuilder();
int chunkStartPage = 1;
int currentPage = 1;
for (int i = 0; i < pdf.PageCount; i++)
{
string pageText = pdf.Pages[i].Text;
currentPage = i + 1;
if (currentChunk.Length + pageText.Length > maxChunkChars && currentChunk.Length > 0)
{
chunks.Add(new DocumentChunk
{
Text = currentChunk.ToString(),
StartPage = chunkStartPage,
EndPage = currentPage - 1,
ChunkIndex = chunks.Count
});
// Create overlap with previous chunk for continuity
string overlap = currentChunk.Length > overlapChars
? currentChunk.ToString().Substring(currentChunk.Length - overlapChars)
: currentChunk.ToString();
currentChunk.Clear();
currentChunk.Append(overlap);
chunkStartPage = currentPage - 1;
}
currentChunk.AppendLine($"\n--- Page {currentPage} ---\n");
currentChunk.Append(pageText);
}
if (currentChunk.Length > 0)
{
chunks.Add(new DocumentChunk
{
Text = currentChunk.ToString(),
StartPage = chunkStartPage,
EndPage = currentPage,
ChunkIndex = chunks.Count
});
}
Console.WriteLine($"Document chunked into {chunks.Count} segments");
foreach (var chunk in chunks)
{
Console.WriteLine($" Chunk {chunk.ChunkIndex + 1}: Pages {chunk.StartPage}-{chunk.EndPage} ({chunk.Text.Length} chars)");
}
// Save chunk metadata for RAG indexing
File.WriteAllText("chunks-metadata.json", System.Text.Json.JsonSerializer.Serialize(
chunks.Select(c => new { c.ChunkIndex, c.StartPage, c.EndPage, Length = c.Text.Length }),
new System.Text.Json.JsonSerializerOptions { WriteIndented = true }
));
ic class DocumentChunk
public string Text { get; set; } = "";
public int StartPage { get; set; }
public int EndPage { get; set; }
public int ChunkIndex { get; set; }Imports IronPdf
Imports System.IO
Imports System.Text
Imports System.Text.Json
' Split long documents into overlapping chunks for RAG systems
Dim pdf = PdfDocument.FromFile("long-document.pdf")
' Chunking configuration
Dim maxChunkTokens As Integer = 4000 ' Leave room for prompts and responses
Dim overlapTokens As Integer = 200 ' Overlap for context continuity
Dim approxCharsPerToken As Integer = 4 ' Rough estimate for tokenization
Dim maxChunkChars As Integer = maxChunkTokens * approxCharsPerToken
Dim overlapChars As Integer = overlapTokens * approxCharsPerToken
Dim chunks As New List(Of DocumentChunk)()
Dim currentChunk As New StringBuilder()
Dim chunkStartPage As Integer = 1
Dim currentPage As Integer = 1
For i As Integer = 0 To pdf.PageCount - 1
Dim pageText As String = pdf.Pages(i).Text
currentPage = i + 1
If currentChunk.Length + pageText.Length > maxChunkChars AndAlso currentChunk.Length > 0 Then
chunks.Add(New DocumentChunk With {
.Text = currentChunk.ToString(),
.StartPage = chunkStartPage,
.EndPage = currentPage - 1,
.ChunkIndex = chunks.Count
})
' Create overlap with previous chunk for continuity
Dim overlap As String = If(currentChunk.Length > overlapChars,
currentChunk.ToString().Substring(currentChunk.Length - overlapChars),
currentChunk.ToString())
currentChunk.Clear()
currentChunk.Append(overlap)
chunkStartPage = currentPage - 1
End If
currentChunk.AppendLine(vbCrLf & "--- Page " & currentPage & " ---" & vbCrLf)
currentChunk.Append(pageText)
Next
If currentChunk.Length > 0 Then
chunks.Add(New DocumentChunk With {
.Text = currentChunk.ToString(),
.StartPage = chunkStartPage,
.EndPage = currentPage,
.ChunkIndex = chunks.Count
})
End If
Console.WriteLine($"Document chunked into {chunks.Count} segments")
For Each chunk In chunks
Console.WriteLine($" Chunk {chunk.ChunkIndex + 1}: Pages {chunk.StartPage}-{chunk.EndPage} ({chunk.Text.Length} chars)")
Next
' Save chunk metadata for RAG indexing
File.WriteAllText("chunks-metadata.json", JsonSerializer.Serialize(
chunks.Select(Function(c) New With {.ChunkIndex = c.ChunkIndex, .StartPage = c.StartPage, .EndPage = c.EndPage, .Length = c.Text.Length}),
New JsonSerializerOptions With {.WriteIndented = True}
))
Public Class DocumentChunk
Public Property Text As String = ""
Public Property StartPage As Integer
Public Property EndPage As Integer
Public Property ChunkIndex As Integer
End Class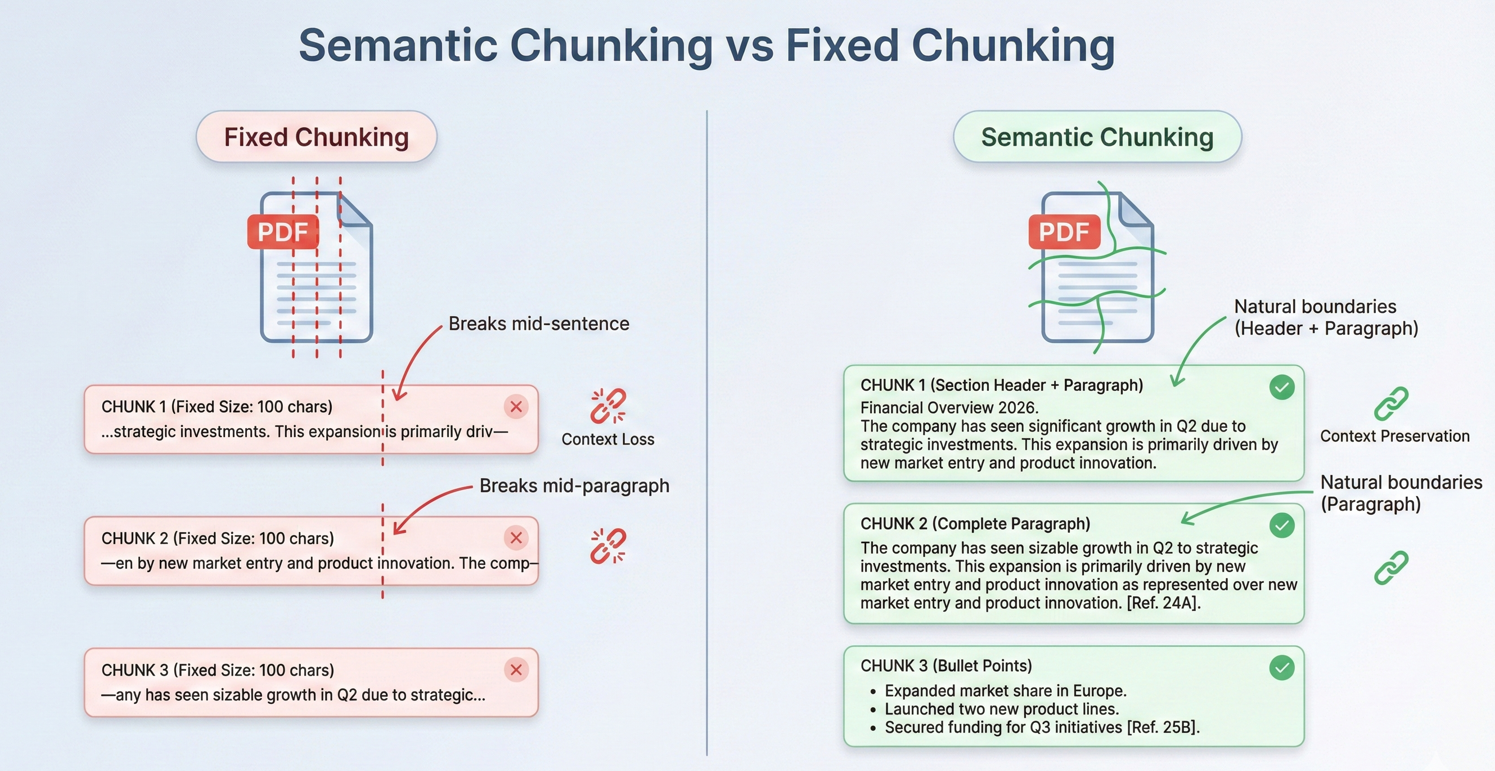
Überlappende Chunks sorgen für Kontinuität über die Grenzen hinweg und stellen sicher, dass die KI über ausreichend Kontext verfügt, selbst wenn relevante Informationen die Chunk-Grenzen überschreiten.
RAG-Muster (Retrieval-Augmented Generation)
Retrieval-Augmented Generation ist ein leistungsstarkes Muster für die KI-gestützte Dokumentenanalyse im Jahr 2026. Anstatt die KI mit ganzen Dokumenten zu füttern, rufen RAG-Systeme zunächst nur die relevanten Teile für eine bestimmte Anfrage ab und verwenden diese Teile dann als Kontext für die Generierung von Antworten.
Der RAG-Arbeitsablauf besteht aus drei Hauptphasen: Dokumentvorbereitung (Chunking und Erstellung von Einbettungen), Abruf (Suche nach relevanten Chunks) und Generierung (Verwendung der abgerufenen Chunks als Kontext für KI-Antworten).
Der Code indexiert mehrere PDFs, indem er bei jedem pdf.Memorize() aufruft, und verwendet dann pdf.Query(), um Antworten aus dem kombinierten Dokumentgedächtnis abzurufen.
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/rag-system-implementation.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
// Retrieval-Augmented Generation (RAG) system for querying across multiple indexed documents
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
// Index all documents in folder
string[] documentPaths = Directory.GetFiles("documents/", "*.pdf");
Console.WriteLine($"Indexing {documentPaths.Length} documents...\n");
// Memorize each document (creates embeddings for retrieval)
foreach (string path in documentPaths)
{
var pdf = PdfDocument.FromFile(path);
await pdf.Memorize();
Console.WriteLine($"Indexed: {Path.GetFileName(path)} ({pdf.PageCount} pages)");
}
Console.WriteLine("\n=== RAG System Ready ===\n");
// Query across all indexed documents
string query = "What are the key compliance requirements for data retention?";
Console.WriteLine($"Query: {query}\n");
var searchPdf = PdfDocument.FromFile(documentPaths[0]);
string answer = await searchPdf.Query(query);
Console.WriteLine($"Answer: {answer}");
// Interactive query loop
Console.WriteLine("\n--- Enter questions (type 'exit' to quit) ---\n");
while (true)
{
Console.Write("Question: ");
string? userQuery = Console.ReadLine();
if (string.IsNullOrWhiteSpace(userQuery) || userQuery.ToLower() == "exit")
break;
string response = await searchPdf.Query(userQuery);
Console.WriteLine($"\nAnswer: {response}\n");
}Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
Imports System.IO
' Retrieval-Augmented Generation (RAG) system for querying across multiple indexed documents
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
' Index all documents in folder
Dim documentPaths As String() = Directory.GetFiles("documents/", "*.pdf")
Console.WriteLine($"Indexing {documentPaths.Length} documents..." & vbCrLf)
' Memorize each document (creates embeddings for retrieval)
For Each path As String In documentPaths
Dim pdf = PdfDocument.FromFile(path)
Await pdf.Memorize()
Console.WriteLine($"Indexed: {Path.GetFileName(path)} ({pdf.PageCount} pages)")
Next
Console.WriteLine(vbCrLf & "=== RAG System Ready ===" & vbCrLf)
' Query across all indexed documents
Dim query As String = "What are the key compliance requirements for data retention?"
Console.WriteLine($"Query: {query}" & vbCrLf)
Dim searchPdf = PdfDocument.FromFile(documentPaths(0))
Dim answer As String = Await searchPdf.Query(query)
Console.WriteLine($"Answer: {answer}")
' Interactive query loop
Console.WriteLine(vbCrLf & "--- Enter questions (type 'exit' to quit) ---" & vbCrLf)
While True
Console.Write("Question: ")
Dim userQuery As String = Console.ReadLine()
If String.IsNullOrWhiteSpace(userQuery) OrElse userQuery.ToLower() = "exit" Then
Exit While
End If
Dim response As String = Await searchPdf.Query(userQuery)
Console.WriteLine(vbCrLf & $"Answer: {response}" & vbCrLf)
End WhileRAG-Systeme eignen sich hervorragend für den Umgang mit großen Dokumentensammlungen - juristische Falldatenbanken, technische Dokumentationsbibliotheken, Forschungsarchive. Da nur relevante Teile abgerufen werden, bleibt die Antwortqualität erhalten, während die Skalierung auf praktisch unbegrenzte Dokumentgrößen erfolgt.
Quellennachweis aus PDF-Seiten
Für professionelle Anwendungen müssen die KI-Antworten überprüfbar sein. Der Zitieransatz beinhaltet die Pflege von Metadaten über die Herkunft der Chunks während des Chunkings und der Abfrage. Jeder Chunk speichert nicht nur den Textinhalt, sondern auch die Seitenzahlen der Quelle, die Abschnittsüberschriften und die Position im Dokument.
Eingabe
Der Code verwendet pdf.Query() mit Zitierhinweisen und ruft dann ExtractCitedPages() mit Regex auf, um Seitenreferenzen zu analysieren und Quellen mit pdf.Pages[pageNum - 1].Text zu überprüfen.
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/answer-with-citations.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
using System.Text.RegularExpressions;
// Answer questions with page citations and source verification
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
var pdf = PdfDocument.FromFile("sample-legal-document.pdf");
await pdf.Memorize();
string question = "What are the termination conditions in this agreement?";
// Request citations in query
string citationQuery = $@"{question}
T: Include specific page citations in your answer using the format (Page X) or (Pages X-Y).
e information that appears in the document.";
string answerWithCitations = await pdf.Query(citationQuery);
Console.WriteLine("Question: " + question);
Console.WriteLine("\nAnswer with Citations:");
Console.WriteLine(answerWithCitations);
// Extract cited page numbers using regex
var citedPages = ExtractCitedPages(answerWithCitations);
Console.WriteLine($"\nCited pages: {string.Join(", ", citedPages)}");
// Verify citations with page excerpts
Console.WriteLine("\n=== Source Verification ===");
foreach (int pageNum in citedPages.Take(3))
{
if (pageNum <= pdf.PageCount && pageNum > 0)
{
string pageText = pdf.Pages[pageNum - 1].Text;
string excerpt = pageText.Length > 200 ? pageText.Substring(0, 200) + "..." : pageText;
Console.WriteLine($"\nPage {pageNum} excerpt:\n{excerpt}");
}
}
// Extract page numbers from citation format (Page X) or (Pages X-Y)
List<int> ExtractCitedPages(string text)
{
var pages = new HashSet<int>();
var matches = Regex.Matches(text, @"\(Pages?\s*(\d+)(?:\s*-\s*(\d+))?\)", RegexOptions.IgnoreCase);
foreach (Match match in matches)
{
int startPage = int.Parse(match.Groups[1].Value);
pages.Add(startPage);
if (match.Groups[2].Success)
{
int endPage = int.Parse(match.Groups[2].Value);
for (int p = startPage; p <= endPage; p++)
pages.Add(p);
}
}
return pages.OrderBy(p => p).ToList();
}Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
Imports System.Text.RegularExpressions
' Answer questions with page citations and source verification
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
Dim pdf = PdfDocument.FromFile("sample-legal-document.pdf")
Await pdf.Memorize()
Dim question As String = "What are the termination conditions in this agreement?"
' Request citations in query
Dim citationQuery As String = $"{question}
T: Include specific page citations in your answer using the format (Page X) or (Pages X-Y).
e information that appears in the document."
Dim answerWithCitations As String = Await pdf.Query(citationQuery)
Console.WriteLine("Question: " & question)
Console.WriteLine(vbCrLf & "Answer with Citations:")
Console.WriteLine(answerWithCitations)
' Extract cited page numbers using regex
Dim citedPages = ExtractCitedPages(answerWithCitations)
Console.WriteLine(vbCrLf & "Cited pages: " & String.Join(", ", citedPages))
' Verify citations with page excerpts
Console.WriteLine(vbCrLf & "=== Source Verification ===")
For Each pageNum As Integer In citedPages.Take(3)
If pageNum <= pdf.PageCount AndAlso pageNum > 0 Then
Dim pageText As String = pdf.Pages(pageNum - 1).Text
Dim excerpt As String = If(pageText.Length > 200, pageText.Substring(0, 200) & "...", pageText)
Console.WriteLine(vbCrLf & "Page " & pageNum & " excerpt:" & vbCrLf & excerpt)
End If
Next
' Extract page numbers from citation format (Page X) or (Pages X-Y)
Function ExtractCitedPages(ByVal text As String) As List(Of Integer)
Dim pages = New HashSet(Of Integer)()
Dim matches = Regex.Matches(text, "\((Pages?)\s*(\d+)(?:\s*-\s*(\d+))?\)", RegexOptions.IgnoreCase)
For Each match As Match In matches
Dim startPage As Integer = Integer.Parse(match.Groups(2).Value)
pages.Add(startPage)
If match.Groups(3).Success Then
Dim endPage As Integer = Integer.Parse(match.Groups(3).Value)
For p As Integer = startPage To endPage
pages.Add(p)
Next
End If
Next
Return pages.OrderBy(Function(p) p).ToList()
End FunctionKonsolenausgabe
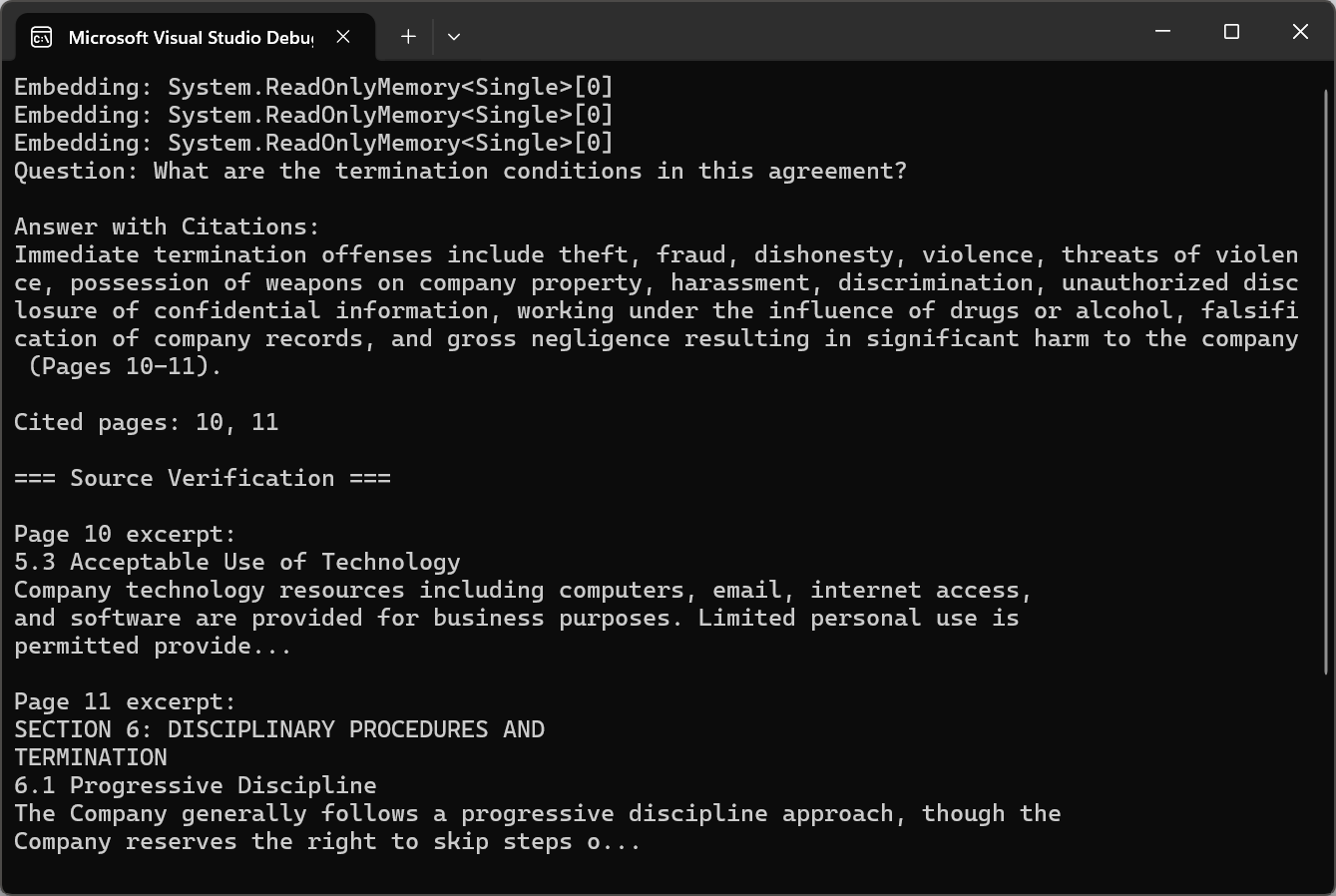
Zitate verwandeln KI-generierte Antworten von undurchsichtigen Ausgaben in transparente, überprüfbare Informationen. Die Benutzer können das Quellmaterial überprüfen, um die Antworten zu validieren und Vertrauen in die KI-gestützte Analyse aufzubauen.
Batch-KI-Verarbeitung
Dokumentenbibliotheken in großem Maßstab verarbeiten
Die Dokumentenverarbeitung in Unternehmen umfasst oft Tausende oder Millionen von PDF-Dateien. Die Grundlage einer skalierbaren Stapelverarbeitung ist die Parallelisierung. IronPDF ist thread-sicher und ermöglicht die gleichzeitige Verarbeitung von PDF-Dateien ohne Störungen.
Dieser Code verwendet SemaphoreSlim mit konfigurierbaren maxConcurrency, um PDFs parallel zu verarbeiten und bei jedem pdf.Summarize() aufzurufen, während die Ergebnisse in einem ConcurrentBag nachverfolgt werden.
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/batch-document-processing.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
using System;
using System.Collections.Concurrent;
using System.Text;
// Process multiple documents in parallel with rate limiting
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
// Configure parallel processing with rate limiting
int maxConcurrency = 3;
string inputFolder = "documents/";
string outputFolder = "summaries/";
Directory.CreateDirectory(outputFolder);
string[] pdfFiles = Directory.GetFiles(inputFolder, "*.pdf");
Console.WriteLine($"Processing {pdfFiles.Length} documents...\n");
var results = new ConcurrentBag<ProcessingResult>();
var semaphore = new SemaphoreSlim(maxConcurrency);
var tasks = pdfFiles.Select(async filePath =>
{
await semaphore.WaitAsync();
var result = new ProcessingResult { FilePath = filePath };
try
{
var stopwatch = System.Diagnostics.Stopwatch.StartNew();
var pdf = PdfDocument.FromFile(filePath);
string summary = await pdf.Summarize();
string outputPath = Path.Combine(outputFolder,
Path.GetFileNameWithoutExtension(filePath) + "-summary.txt");
await File.WriteAllTextAsync(outputPath, summary);
stopwatch.Stop();
result.Success = true;
result.ProcessingTime = stopwatch.Elapsed;
result.OutputPath = outputPath;
Console.WriteLine($"[OK] {Path.GetFileName(filePath)} ({stopwatch.ElapsedMilliseconds}ms)");
}
catch (Exception ex)
{
result.Success = false;
result.ErrorMessage = ex.Message;
Console.WriteLine($"[ERROR] {Path.GetFileName(filePath)}: {ex.Message}");
}
finally
{
semaphore.Release();
results.Add(result);
}
}).ToArray();
await Task.WhenAll(tasks);
// Generate processing report
var successful = results.Where(r => r.Success).ToList();
var failed = results.Where(r => !r.Success).ToList();
var report = new StringBuilder();
report.AppendLine("=== Batch Processing Report ===");
report.AppendLine($"Successful: {successful.Count}");
report.AppendLine($"Failed: {failed.Count}");
if (successful.Any())
{
var avgTime = TimeSpan.FromMilliseconds(successful.Average(r => r.ProcessingTime.TotalMilliseconds));
report.AppendLine($"Average processing time: {avgTime.TotalSeconds:F1}s");
}
if (failed.Any())
{
report.AppendLine("\nFailed documents:");
foreach (var fail in failed)
report.AppendLine($" - {Path.GetFileName(fail.FilePath)}: {fail.ErrorMessage}");
}
string reportText = report.ToString();
Console.WriteLine($"\n{reportText}");
File.WriteAllText(Path.Combine(outputFolder, "processing-report.txt"), reportText);
s ProcessingResult
public string FilePath { get; set; } = "";
public bool Success { get; set; }
public TimeSpan ProcessingTime { get; set; }
public string OutputPath { get; set; } = "";
public string ErrorMessage { get; set; } = "";Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
Imports System
Imports System.Collections.Concurrent
Imports System.Text
Imports System.IO
Imports System.Linq
Imports System.Threading
Imports System.Threading.Tasks
' Process multiple documents in parallel with rate limiting
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
' Configure parallel processing with rate limiting
Dim maxConcurrency As Integer = 3
Dim inputFolder As String = "documents/"
Dim outputFolder As String = "summaries/"
Directory.CreateDirectory(outputFolder)
Dim pdfFiles As String() = Directory.GetFiles(inputFolder, "*.pdf")
Console.WriteLine($"Processing {pdfFiles.Length} documents...{vbCrLf}")
Dim results = New ConcurrentBag(Of ProcessingResult)()
Dim semaphore = New SemaphoreSlim(maxConcurrency)
Dim tasks = pdfFiles.Select(Async Function(filePath)
Await semaphore.WaitAsync()
Dim result = New ProcessingResult With {.FilePath = filePath}
Try
Dim stopwatch = System.Diagnostics.Stopwatch.StartNew()
Dim pdf = PdfDocument.FromFile(filePath)
Dim summary As String = Await pdf.Summarize()
Dim outputPath = Path.Combine(outputFolder, Path.GetFileNameWithoutExtension(filePath) & "-summary.txt")
Await File.WriteAllTextAsync(outputPath, summary)
stopwatch.Stop()
result.Success = True
result.ProcessingTime = stopwatch.Elapsed
result.OutputPath = outputPath
Console.WriteLine($"[OK] {Path.GetFileName(filePath)} ({stopwatch.ElapsedMilliseconds}ms)")
Catch ex As Exception
result.Success = False
result.ErrorMessage = ex.Message
Console.WriteLine($"[ERROR] {Path.GetFileName(filePath)}: {ex.Message}")
Finally
semaphore.Release()
results.Add(result)
End Try
End Function).ToArray()
Await Task.WhenAll(tasks)
' Generate processing report
Dim successful = results.Where(Function(r) r.Success).ToList()
Dim failed = results.Where(Function(r) Not r.Success).ToList()
Dim report = New StringBuilder()
report.AppendLine("=== Batch Processing Report ===")
report.AppendLine($"Successful: {successful.Count}")
report.AppendLine($"Failed: {failed.Count}")
If successful.Any() Then
Dim avgTime = TimeSpan.FromMilliseconds(successful.Average(Function(r) r.ProcessingTime.TotalMilliseconds))
report.AppendLine($"Average processing time: {avgTime.TotalSeconds:F1}s")
End If
If failed.Any() Then
report.AppendLine($"{vbCrLf}Failed documents:")
For Each fail In failed
report.AppendLine($" - {Path.GetFileName(fail.FilePath)}: {fail.ErrorMessage}")
Next
End If
Dim reportText As String = report.ToString()
Console.WriteLine($"{vbCrLf}{reportText}")
File.WriteAllText(Path.Combine(outputFolder, "processing-report.txt"), reportText)
Public Class ProcessingResult
Public Property FilePath As String = ""
Public Property Success As Boolean
Public Property ProcessingTime As TimeSpan
Public Property OutputPath As String = ""
Public Property ErrorMessage As String = ""
End ClassEine robuste Fehlerbehandlung ist in diesem Umfang entscheidend. Produktionssysteme implementieren eine Wiederholungslogik mit exponentiellem Backoff, eine separate Fehlerprotokollierung für fehlgeschlagene Dokumente und eine wiederaufnehmbare Verarbeitung.
Kostenmanagement und Token-Verwendung
Die Kosten für AI API werden in der Regel pro Token berechnet. Im Jahr 2026 kostet GPT-5 1,25 US-Dollar pro Million Input-Token und 10 US-Dollar pro Million Output-Token, während Claude Sonnet 4.5 3 US-Dollar pro Million Input-Token und 15 US-Dollar pro Million Output-Token kostet. Die primäre Strategie zur Kostenoptimierung ist die Minimierung der Verwendung unnötiger Token.
Die Batch-API von OpenAI bietet 50 % Rabatt auf die Token-Kosten im Gegenzug für längere Bearbeitungszeiten (bis zu 24 Stunden). Bei der Verarbeitung von Daten über Nacht oder bei periodischen Analysen bringt die Stapelverarbeitung erhebliche Einsparungen.
Der Code extrahiert Text mit pdf.ExtractAllText(), erstellt JSONL-Batch-Anfragen, lädt über HttpClient zum OpenAI-Dateiendpunkt hoch und reicht sie bei der Batch-API ein.
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/batch-api-processing.csusing IronPdf;
using System.Text.Json;
using System.Net.Http.Headers;
// Use OpenAI Batch API for 50% cost savings on large-scale document processing
string openAiApiKey = "your-openai-api-key";
string inputFolder = "documents/";
// Prepare batch requests in JSONL format
var batchRequests = new List<string>();
string[] pdfFiles = Directory.GetFiles(inputFolder, "*.pdf");
Console.WriteLine($"Preparing batch for {pdfFiles.Length} documents...\n");
foreach (string filePath in pdfFiles)
{
var pdf = PdfDocument.FromFile(filePath);
string pdfText = pdf.ExtractAllText();
// Truncate to stay within batch API limits
if (pdfText.Length > 100000)
pdfText = pdfText.Substring(0, 100000) + "\n[Truncated...]";
var request = new
{
custom_id = Path.GetFileNameWithoutExtension(filePath),
method = "POST",
url = "/v1/chat/completions",
body = new
{
model = "gpt-4o",
messages = new[]
{
new { role = "system", content = "Summarize the following document concisely." },
new { role = "user", content = pdfText }
},
max_tokens = 1000
}
};
batchRequests.Add(JsonSerializer.Serialize(request));
}
// Create JSONL file
string batchFilePath = "batch-requests.jsonl";
File.WriteAllLines(batchFilePath, batchRequests);
Console.WriteLine($"Created batch file with {batchRequests.Count} requests");
// Upload file to OpenAI
using var httpClient = new HttpClient();
httpClient.DefaultRequestHeaders.Authorization = new AuthenticationHeaderValue("Bearer", openAiApiKey);
using var fileContent = new MultipartFormDataContent();
fileContent.Add(new ByteArrayContent(File.ReadAllBytes(batchFilePath)), "file", "batch-requests.jsonl");
fileContent.Add(new StringContent("batch"), "purpose");
var uploadResponse = await httpClient.PostAsync("https://api.openai.com/v1/files", fileContent);
var uploadResult = JsonSerializer.Deserialize<JsonElement>(await uploadResponse.Content.ReadAsStringAsync());
string fileId = uploadResult.GetProperty("id").GetString()!;
Console.WriteLine($"Uploaded file: {fileId}");
// Create batch job (24-hour completion window for 50% discount)
var batchJobRequest = new
{
input_file_id = fileId,
endpoint = "/v1/chat/completions",
completion_window = "24h"
};
var batchResponse = await httpClient.PostAsync(
"https://api.openai.com/v1/batches",
new StringContent(JsonSerializer.Serialize(batchJobRequest), System.Text.Encoding.UTF8, "application/json")
);
var batchResult = JsonSerializer.Deserialize<JsonElement>(await batchResponse.Content.ReadAsStringAsync());
string batchId = batchResult.GetProperty("id").GetString()!;
Console.WriteLine($"\nBatch job created: {batchId}");
Console.WriteLine("Job will complete within 24 hours");
Console.WriteLine($"Check status: GET https://api.openai.com/v1/batches/{batchId}");
File.WriteAllText("batch-job-id.txt", batchId);
Console.WriteLine("\nBatch ID saved to batch-job-id.txt");Imports IronPdf
Imports System.Text.Json
Imports System.Net.Http.Headers
' Use OpenAI Batch API for 50% cost savings on large-scale document processing
Dim openAiApiKey As String = "your-openai-api-key"
Dim inputFolder As String = "documents/"
' Prepare batch requests in JSONL format
Dim batchRequests As New List(Of String)()
Dim pdfFiles As String() = Directory.GetFiles(inputFolder, "*.pdf")
Console.WriteLine($"Preparing batch for {pdfFiles.Length} documents..." & vbCrLf)
For Each filePath As String In pdfFiles
Dim pdf = PdfDocument.FromFile(filePath)
Dim pdfText As String = pdf.ExtractAllText()
' Truncate to stay within batch API limits
If pdfText.Length > 100000 Then
pdfText = pdfText.Substring(0, 100000) & vbCrLf & "[Truncated...]"
End If
Dim request = New With {
.custom_id = Path.GetFileNameWithoutExtension(filePath),
.method = "POST",
.url = "/v1/chat/completions",
.body = New With {
.model = "gpt-4o",
.messages = New Object() {
New With {.role = "system", .content = "Summarize the following document concisely."},
New With {.role = "user", .content = pdfText}
},
.max_tokens = 1000
}
}
batchRequests.Add(JsonSerializer.Serialize(request))
Next
' Create JSONL file
Dim batchFilePath As String = "batch-requests.jsonl"
File.WriteAllLines(batchFilePath, batchRequests)
Console.WriteLine($"Created batch file with {batchRequests.Count} requests")
' Upload file to OpenAI
Using httpClient As New HttpClient()
httpClient.DefaultRequestHeaders.Authorization = New AuthenticationHeaderValue("Bearer", openAiApiKey)
Using fileContent As New MultipartFormDataContent()
fileContent.Add(New ByteArrayContent(File.ReadAllBytes(batchFilePath)), "file", "batch-requests.jsonl")
fileContent.Add(New StringContent("batch"), "purpose")
Dim uploadResponse = Await httpClient.PostAsync("https://api.openai.com/v1/files", fileContent)
Dim uploadResult = JsonSerializer.Deserialize(Of JsonElement)(Await uploadResponse.Content.ReadAsStringAsync())
Dim fileId As String = uploadResult.GetProperty("id").GetString()
Console.WriteLine($"Uploaded file: {fileId}")
' Create batch job (24-hour completion window for 50% discount)
Dim batchJobRequest = New With {
.input_file_id = fileId,
.endpoint = "/v1/chat/completions",
.completion_window = "24h"
}
Dim batchResponse = Await httpClient.PostAsync(
"https://api.openai.com/v1/batches",
New StringContent(JsonSerializer.Serialize(batchJobRequest), System.Text.Encoding.UTF8, "application/json")
)
Dim batchResult = JsonSerializer.Deserialize(Of JsonElement)(Await batchResponse.Content.ReadAsStringAsync())
Dim batchId As String = batchResult.GetProperty("id").GetString()
Console.WriteLine(vbCrLf & $"Batch job created: {batchId}")
Console.WriteLine("Job will complete within 24 hours")
Console.WriteLine($"Check status: GET https://api.openai.com/v1/batches/{batchId}")
File.WriteAllText("batch-job-id.txt", batchId)
Console.WriteLine(vbCrLf & "Batch ID saved to batch-job-id.txt")
End Using
End UsingDie Überwachung der Token-Verwendung in der Produktion ist unerlässlich. Viele Unternehmen stellen fest, dass 80 % ihrer Dokumente mit kleineren, billigeren Modellen bearbeitet werden können und teure Modelle nur für komplexe Fälle reserviert sind.
Caching und inkrementelle Verarbeitung
Bei Dokumentensammlungen, die inkrementell aktualisiert werden, lassen sich durch intelligente Caching- und inkrementelle Verarbeitungsstrategien die Kosten drastisch senken. Bei der Zwischenspeicherung auf Dokumentenebene werden die Ergebnisse zusammen mit einem Hash der Quell-PDF-Datei gespeichert, um eine unnötige erneute Verarbeitung unveränderter Dokumente zu vermeiden.
Die Klasse DocumentCacheManager verwendet ComputeFileHash() mit SHA256, um Änderungen zu erkennen, und speichert Ergebnisse in CacheEntry-Objekten mit LastAccessed-Zeitstempeln.
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/incremental-caching.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
using System;
using System.Collections.Generic;
using System.Security.Cryptography;
using System.Text.Json;
// Cache AI processing results using file hashes to avoid reprocessing unchanged documents
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
// Configure caching
string cacheFolder = "ai-cache/";
string documentsFolder = "documents/";
Directory.CreateDirectory(cacheFolder);
var cacheManager = new DocumentCacheManager(cacheFolder);
// Process documents with caching
string[] pdfFiles = Directory.GetFiles(documentsFolder, "*.pdf");
int cached = 0, processed = 0;
foreach (string filePath in pdfFiles)
{
string fileName = Path.GetFileName(filePath);
string fileHash = cacheManager.ComputeFileHash(filePath);
var cachedResult = cacheManager.GetCachedResult(fileName, fileHash);
if (cachedResult != null)
{
Console.WriteLine($"[CACHE HIT] {fileName}");
cached++;
continue;
}
Console.WriteLine($"[PROCESSING] {fileName}");
var pdf = PdfDocument.FromFile(filePath);
string summary = await pdf.Summarize();
cacheManager.CacheResult(fileName, fileHash, summary);
processed++;
}
Console.WriteLine($"\nProcessing complete: {cached} cached, {processed} newly processed");
Console.WriteLine($"Cost savings: {(cached * 100.0 / Math.Max(1, cached + processed)):F1}% served from cache");
ash-based cache manager with JSON index
s DocumentCacheManager
private readonly string _cacheFolder;
private readonly string _indexPath;
private Dictionary<string, CacheEntry> _index;
public DocumentCacheManager(string cacheFolder)
{
_cacheFolder = cacheFolder;
_indexPath = Path.Combine(cacheFolder, "cache-index.json");
_index = LoadIndex();
}
private Dictionary<string, CacheEntry> LoadIndex()
{
if (File.Exists(_indexPath))
{
string json = File.ReadAllText(_indexPath);
return JsonSerializer.Deserialize<Dictionary<string, CacheEntry>>(json) ?? new();
}
return new Dictionary<string, CacheEntry>();
}
private void SaveIndex()
{
string json = JsonSerializer.Serialize(_index, new JsonSerializerOptions { WriteIndented = true });
File.WriteAllText(_indexPath, json);
}
// SHA256 hash to detect file changes
public string ComputeFileHash(string filePath)
{
using var sha256 = SHA256.Create();
using var stream = File.OpenRead(filePath);
byte[] hash = sha256.ComputeHash(stream);
return Convert.ToHexString(hash);
}
public string? GetCachedResult(string fileName, string currentHash)
{
if (_index.TryGetValue(fileName, out var entry))
{
if (entry.FileHash == currentHash && File.Exists(entry.CachePath))
{
entry.LastAccessed = DateTime.UtcNow;
SaveIndex();
return File.ReadAllText(entry.CachePath);
}
}
return null;
}
public void CacheResult(string fileName, string fileHash, string result)
{
string cachePath = Path.Combine(_cacheFolder, $"{Path.GetFileNameWithoutExtension(fileName)}-{fileHash[..8]}.txt");
File.WriteAllText(cachePath, result);
_index[fileName] = new CacheEntry
{
FileHash = fileHash,
CachePath = cachePath,
CreatedAt = DateTime.UtcNow,
LastAccessed = DateTime.UtcNow
};
SaveIndex();
}
s CacheEntry
public string FileHash { get; set; } = "";
public string CachePath { get; set; } = "";
public DateTime CreatedAt { get; set; }
public DateTime LastAccessed { get; set; }Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
Imports System
Imports System.Collections.Generic
Imports System.Security.Cryptography
Imports System.Text.Json
' Cache AI processing results using file hashes to avoid reprocessing unchanged documents
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
' Configure caching
Dim cacheFolder As String = "ai-cache/"
Dim documentsFolder As String = "documents/"
Directory.CreateDirectory(cacheFolder)
Dim cacheManager = New DocumentCacheManager(cacheFolder)
' Process documents with caching
Dim pdfFiles As String() = Directory.GetFiles(documentsFolder, "*.pdf")
Dim cached As Integer = 0, processed As Integer = 0
For Each filePath As String In pdfFiles
Dim fileName As String = Path.GetFileName(filePath)
Dim fileHash As String = cacheManager.ComputeFileHash(filePath)
Dim cachedResult As String = cacheManager.GetCachedResult(fileName, fileHash)
If cachedResult IsNot Nothing Then
Console.WriteLine($"[CACHE HIT] {fileName}")
cached += 1
Continue For
End If
Console.WriteLine($"[PROCESSING] {fileName}")
Dim pdf = PdfDocument.FromFile(filePath)
Dim summary As String = Await pdf.Summarize()
cacheManager.CacheResult(fileName, fileHash, summary)
processed += 1
Next
Console.WriteLine(vbCrLf & $"Processing complete: {cached} cached, {processed} newly processed")
Console.WriteLine($"Cost savings: {(cached * 100.0 / Math.Max(1, cached + processed)):F1}% served from cache")
' Hash-based cache manager with JSON index
Public Class DocumentCacheManager
Private ReadOnly _cacheFolder As String
Private ReadOnly _indexPath As String
Private _index As Dictionary(Of String, CacheEntry)
Public Sub New(cacheFolder As String)
_cacheFolder = cacheFolder
_indexPath = Path.Combine(cacheFolder, "cache-index.json")
_index = LoadIndex()
End Sub
Private Function LoadIndex() As Dictionary(Of String, CacheEntry)
If File.Exists(_indexPath) Then
Dim json As String = File.ReadAllText(_indexPath)
Return JsonSerializer.Deserialize(Of Dictionary(Of String, CacheEntry))(json) OrElse New Dictionary(Of String, CacheEntry)()
End If
Return New Dictionary(Of String, CacheEntry)()
End Function
Private Sub SaveIndex()
Dim json As String = JsonSerializer.Serialize(_index, New JsonSerializerOptions With {.WriteIndented = True})
File.WriteAllText(_indexPath, json)
End Sub
' SHA256 hash to detect file changes
Public Function ComputeFileHash(filePath As String) As String
Using sha256 = SHA256.Create()
Using stream = File.OpenRead(filePath)
Dim hash As Byte() = sha256.ComputeHash(stream)
Return Convert.ToHexString(hash)
End Using
End Using
End Function
Public Function GetCachedResult(fileName As String, currentHash As String) As String
If _index.TryGetValue(fileName, entry) Then
If entry.FileHash = currentHash AndAlso File.Exists(entry.CachePath) Then
entry.LastAccessed = DateTime.UtcNow
SaveIndex()
Return File.ReadAllText(entry.CachePath)
End If
End If
Return Nothing
End Function
Public Sub CacheResult(fileName As String, fileHash As String, result As String)
Dim cachePath As String = Path.Combine(_cacheFolder, $"{Path.GetFileNameWithoutExtension(fileName)}-{fileHash.Substring(0, 8)}.txt")
File.WriteAllText(cachePath, result)
_index(fileName) = New CacheEntry With {
.FileHash = fileHash,
.CachePath = cachePath,
.CreatedAt = DateTime.UtcNow,
.LastAccessed = DateTime.UtcNow
}
SaveIndex()
End Sub
End Class
Public Class CacheEntry
Public Property FileHash As String = ""
Public Property CachePath As String = ""
Public Property CreatedAt As DateTime
Public Property LastAccessed As DateTime
End ClassGPT-5 und Claude Sonnet 4.5 im Jahr 2026 bieten außerdem eine automatische Zwischenspeicherung von Eingabeaufforderungen, die den effektiven Token-Verbrauch bei sich wiederholenden Mustern um 50-90 % reduzieren kann - eine erhebliche Kosteneinsparung für umfangreiche Operationen.
Echte Anwendungsfälle
Rechtsaufklärung und Vertragsanalyse
Für die juristische Erkundung waren bisher Heerscharen von Junioranwälten erforderlich, die Hunderttausende von Seiten manuell durchgesehen haben. Die KI-gestützte Recherche verändert diesen Prozess, indem sie eine schnelle Identifizierung relevanter Dokumente, eine automatische Überprüfung der Rechte und eine Extraktion der wichtigsten beweiskräftigen Fakten ermöglicht.
Die KI-Integration von IronPDF ermöglicht anspruchsvolle juristische Workflows: Erkennung von Privilegien, Relevanzbewertung, Identifizierung von Problemen und Extraktion von Stichtagen. Anwaltskanzleien berichten, dass sie die Zeit für die Überprüfung von Dokumenten um 70-80 % verkürzen und so größere Fälle mit kleineren Teams bearbeiten können.
Mit der verbesserten Genauigkeit von GPT-5 und Claude Sonnet 4.5 und den geringeren Halluzinationsraten im Jahr 2026 können sich Juristen bei immer wichtigeren Entscheidungen auf die KI-gestützte Analyse verlassen.
Finanzbericht-Analyse
Finanzanalysten verbringen viel Zeit damit, Daten aus Gewinnberichten, SEC-Berichten und Analystenpräsentationen zu extrahieren. Die KI-gestützte Verarbeitung von Finanzdokumenten automatisiert diese Extraktion und ermöglicht es den Analysten, sich auf die Interpretation statt auf die Datenerfassung zu konzentrieren.
Dieses Beispiel verarbeitet mehrere 10-K-Einreichungen, verwendet pdf.Query() mit einem CompanyFinancials-JSON-Schema, um Umsatz, Margen und Risikofaktoren über Unternehmen hinweg zu extrahieren und zu vergleichen.
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/financial-sector-analysis.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
using System.Collections.Generic;
using System.Text.Json;
using System.Text;
// Compare financial metrics across multiple company filings for sector analysis
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
// Analyze company filings
string[] companyFilings = {
"filings/company-a-10k.pdf",
"filings/company-b-10k.pdf",
"filings/company-c-10k.pdf"
};
var sectorData = new List<CompanyFinancials>();
foreach (string filing in companyFilings)
{
Console.WriteLine($"Analyzing: {Path.GetFileName(filing)}");
var pdf = PdfDocument.FromFile(filing);
// Define JSON schema for 10-K extraction (numbers in millions USD)
string extractionQuery = @"Extract key financial metrics from this 10-K filing. Return JSON:
mpanyName"": ""string"",
scalYear"": ""string"",
venue"": number,
venueGrowth"": number,
ossMargin"": number,
eratingMargin"": number,
tIncome"": number,
s"": number,
talDebt"": number,
shPosition"": number,
ployeeCount"": number,
yRisks"": [""string""],
idance"": ""string""
in millions USD. Growth/margins as percentages.
NLY valid JSON.";
string result = await pdf.Query(extractionQuery);
try
{
var financials = JsonSerializer.Deserialize<CompanyFinancials>(result);
if (financials != null)
sectorData.Add(financials);
}
catch
{
Console.WriteLine($" Warning: Could not parse financials for {filing}");
}
}
// Generate sector comparison report
var report = new StringBuilder();
report.AppendLine("=== Sector Analysis Report ===\n");
report.AppendLine("Revenue Comparison (millions USD):");
foreach (var company in sectorData.OrderByDescending(c => c.Revenue))
report.AppendLine($" {company.CompanyName}: ${company.Revenue:N0} ({company.RevenueGrowth:+0.0;-0.0}% YoY)");
report.AppendLine("\nProfitability Margins:");
foreach (var company in sectorData.OrderByDescending(c => c.OperatingMargin))
report.AppendLine($" {company.CompanyName}: {company.GrossMargin:F1}% gross, {company.OperatingMargin:F1}% operating");
report.AppendLine("\nFinancial Health (Debt vs Cash):");
foreach (var company in sectorData)
{
double netDebt = company.TotalDebt - company.CashPosition;
string status = netDebt < 0 ? "Net Cash" : "Net Debt";
report.AppendLine($" {company.CompanyName}: {status} ${Math.Abs(netDebt):N0}M");
}
string reportText = report.ToString();
Console.WriteLine($"\n{reportText}");
File.WriteAllText("sector-analysis-report.txt", reportText);
// Save full JSON data
string outputJson = JsonSerializer.Serialize(sectorData, new JsonSerializerOptions { WriteIndented = true });
File.WriteAllText("sector-analysis.json", outputJson);
Console.WriteLine("Analysis saved to sector-analysis.json and sector-analysis-report.txt");
s CompanyFinancials
public string CompanyName { get; set; } = "";
public string FiscalYear { get; set; } = "";
public double Revenue { get; set; }
public double RevenueGrowth { get; set; }
public double GrossMargin { get; set; }
public double OperatingMargin { get; set; }
public double NetIncome { get; set; }
public double Eps { get; set; }
public double TotalDebt { get; set; }
public double CashPosition { get; set; }
public int EmployeeCount { get; set; }
public List<string> KeyRisks { get; set; } = new();
public string Guidance { get; set; } = "";Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
Imports System.Collections.Generic
Imports System.Text.Json
Imports System.Text
Imports System.IO
' Compare financial metrics across multiple company filings for sector analysis
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
' Analyze company filings
Dim companyFilings As String() = {
"filings/company-a-10k.pdf",
"filings/company-b-10k.pdf",
"filings/company-c-10k.pdf"
}
Dim sectorData = New List(Of CompanyFinancials)()
For Each filing As String In companyFilings
Console.WriteLine($"Analyzing: {Path.GetFileName(filing)}")
Dim pdf = PdfDocument.FromFile(filing)
' Define JSON schema for 10-K extraction (numbers in millions USD)
Dim extractionQuery As String = "Extract key financial metrics from this 10-K filing. Return JSON:
mpanyName"": ""string"",
scalYear"": ""string"",
venue"": number,
venueGrowth"": number,
ossMargin"": number,
eratingMargin"": number,
tIncome"": number,
s"": number,
talDebt"": number,
shPosition"": number,
ployeeCount"": number,
yRisks"": [""string""],
idance"": ""string""
in millions USD. Growth/margins as percentages.
NLY valid JSON."
Dim result As String = Await pdf.Query(extractionQuery)
Try
Dim financials = JsonSerializer.Deserialize(Of CompanyFinancials)(result)
If financials IsNot Nothing Then
sectorData.Add(financials)
End If
Catch
Console.WriteLine($" Warning: Could not parse financials for {filing}")
End Try
Next
' Generate sector comparison report
Dim report = New StringBuilder()
report.AppendLine("=== Sector Analysis Report ===" & vbCrLf)
report.AppendLine("Revenue Comparison (millions USD):")
For Each company In sectorData.OrderByDescending(Function(c) c.Revenue)
report.AppendLine($" {company.CompanyName}: ${company.Revenue:N0} ({company.RevenueGrowth:+0.0;-0.0}% YoY)")
Next
report.AppendLine(vbCrLf & "Profitability Margins:")
For Each company In sectorData.OrderByDescending(Function(c) c.OperatingMargin)
report.AppendLine($" {company.CompanyName}: {company.GrossMargin:F1}% gross, {company.OperatingMargin:F1}% operating")
Next
report.AppendLine(vbCrLf & "Financial Health (Debt vs Cash):")
For Each company In sectorData
Dim netDebt As Double = company.TotalDebt - company.CashPosition
Dim status As String = If(netDebt < 0, "Net Cash", "Net Debt")
report.AppendLine($" {company.CompanyName}: {status} ${Math.Abs(netDebt):N0}M")
Next
Dim reportText As String = report.ToString()
Console.WriteLine(vbCrLf & reportText)
File.WriteAllText("sector-analysis-report.txt", reportText)
' Save full JSON data
Dim outputJson As String = JsonSerializer.Serialize(sectorData, New JsonSerializerOptions With {.WriteIndented = True})
File.WriteAllText("sector-analysis.json", outputJson)
Console.WriteLine("Analysis saved to sector-analysis.json and sector-analysis-report.txt")
Public Class CompanyFinancials
Public Property CompanyName As String = ""
Public Property FiscalYear As String = ""
Public Property Revenue As Double
Public Property RevenueGrowth As Double
Public Property GrossMargin As Double
Public Property OperatingMargin As Double
Public Property NetIncome As Double
Public Property Eps As Double
Public Property TotalDebt As Double
Public Property CashPosition As Double
Public Property EmployeeCount As Integer
Public Property KeyRisks As List(Of String) = New List(Of String)()
Public Property Guidance As String = ""
End ClassWertpapierfirmen nutzen KI-gestützte Analysen, um täglich Tausende von Dokumenten zu verarbeiten. Dadurch können Analysten eine breitere Marktabdeckung überwachen und schneller auf sich bietende Chancen reagieren.
Zusammenfassung von Forschungsarbeiten
In der akademischen Forschung werden jährlich Millionen von Dokumenten verfasst. KI-gestützte Zusammenfassungen helfen Forschern, die Relevanz von Artikeln schnell zu beurteilen, die wichtigsten Ergebnisse zu verstehen und Artikel zu identifizieren, die eine detaillierte Lektüre verdienen. Eine effektive Forschungszusammenfassung muss die Forschungsfrage identifizieren, die Methodik erläutern, die wichtigsten Ergebnisse mit entsprechenden Vorbehalten zusammenfassen und die Ergebnisse in den Kontext stellen.
Forschungseinrichtungen nutzen die KI-Zusammenfassung zur Pflege institutioneller Wissensdatenbanken und zur automatischen Verarbeitung neuer Veröffentlichungen. Mit der verbesserten wissenschaftlichen Argumentation von GPT-5 und den erweiterten analytischen Fähigkeiten von Claude Sonnet 4.5 im Jahr 2026 erreicht die akademische Zusammenfassung ein neues Niveau an Genauigkeit.
Behördliche Dokumentenverarbeitung
Regierungsbehörden erstellen umfangreiche Dokumentensammlungen - Verordnungen, öffentliche Stellungnahmen, Umweltverträglichkeitserklärungen, Gerichtsakten, Prüfberichte. KI-gestützte Dokumentenverarbeitung macht Regierungsinformationen durch Analyse der Einhaltung von Vorschriften, Umweltverträglichkeitsprüfungen und Verfolgung von Gesetzen verwertbar.
Die Analyse von öffentlichen Kommentaren stellt eine besondere Herausforderung dar - zu großen Gesetzesvorschlägen können Hunderttausende von Kommentaren eingehen. KI-Systeme können Kommentare nach Themen kategorisieren, gemeinsame Themen identifizieren, koordinierte Kampagnen erkennen und inhaltliche Argumente extrahieren, die eine Reaktion der Behörde rechtfertigen.
Die KI-Modelle der Generation 2026 bieten beispiellose Möglichkeiten für die Verarbeitung von Regierungsdokumenten und unterstützen demokratische Transparenz und fundierte politische Entscheidungen.
Fehlerbehebung und technische Unterstützung
Schnelle Lösungen für häufige Fehler
- Langsame erste Renderphase? Normal. Chrome initialisiert in 2-3s, dann beschleunigt es.
- Cloud-Themen? Verwenden Sie mindestens Azure B1 oder gleichwertige Ressourcen.
- Fehlende Assets? Setzen Sie Basispfade oder betten Sie als base64 ein.
- Fehlende Elemente? Fügen Sie RenderDelay für die JavaScript-Ausführung hinzu.
- Speicherprobleme? Aktualisieren Sie auf die neueste IronPDF-Version, um die Leistung zu verbessern.
- Formularfeldprobleme? Stellen Sie eindeutige Namen sicher und aktualisieren Sie auf die neueste Version.
Hilfe von den Ingenieuren, die IronPDF entwickelt haben, 24/7
IronPDF bietet 24/7-Support für Ingenieure. Haben Sie Probleme mit der Konvertierung von HTML in PDF oder der Integration von KI? Kontaktieren Sie uns:
- Umfassende Anleitung zur Fehlerbehebung
- Leistungsoptimierungsstrategien
- Engineering-Support-Anfragen
- Checkliste zur schnellen Fehlerbehebung
Nächste Schritte
Nachdem Sie nun die KI-gestützte PDF-Verarbeitung verstanden haben, können Sie sich im nächsten Schritt mit den breiteren Möglichkeiten von IronPDF vertraut machen. Der OpenAI-Integrationsleitfaden behandelt Zusammenfassungs-, Abfrage- und Erinnerungsmuster, während das Tutorial zur Text- und Bildextraktion zeigt, wie man PDFs vor der KI-Analyse vorverarbeitet. Für die Arbeitsabläufe bei der Zusammenstellung von Dokumenten erfahren Sie, wie Sie PDFs zusammenführen und aufteilen, um sie im Stapel zu verarbeiten.
Wenn Sie bereit sind, über die KI-Funktionen hinauszugehen, behandelt das komplette PDF-Bearbeitungstutorial Wasserzeichen, Kopfzeilen, Fußzeilen, Formulare und Anmerkungen. Für alternative KI-Integrationsansätze zeigt das ChatGPT C#-Tutorial verschiedene Muster auf. Der Einsatz in der Produktion wird im Azure Deployment Guide für WebApps und Funktionen behandelt, und das C#-Tutorial zur PDF-Erstellung behandelt die Erzeugung von PDFs aus HTML, URLs und Rohinhalten.
Bereit zum Start? Starten Sie Ihre kostenlose 30-Tage-Testversion, um die Software ohne Wasserzeichen in der Produktion zu testen, mit flexibler Lizenzierung, die mit Ihrem Team skaliert. Bei Fragen zur KI-Integration oder anderen IronPDF-Funktionen steht Ihnen unser Technik-Support-Team zur Verfügung.
Häufig gestellte Fragen
Welche Vorteile bietet die Verwendung von KI für die PDF-Verarbeitung in C#?
Die KI-gestützte PDF-Verarbeitung in C# ermöglicht fortschrittliche Funktionen wie die Zusammenfassung von Dokumenten, die Datenextraktion in JSON und den Aufbau von Q&A-Systemen. Sie verbessert die Effizienz und Genauigkeit bei der Verarbeitung großer Mengen von Dokumenten.
Wie integriert IronPDF KI für die Zusammenfassung von Dokumenten?
IronPDF integriert künstliche Intelligenz, indem es Modelle wie GPT-5 und Claude nutzt, die Dokumente analysieren und zusammenfassen können, wodurch es einfacher wird, Erkenntnisse abzuleiten und große Texte schnell zu verstehen.
Welche Rolle spielen die RAG-Muster bei der KI-gestützten PDF-Verarbeitung?
RAG-Muster (Retrieve and Generate) werden in der KI-gestützten PDF-Verarbeitung verwendet, um die Qualität der Informationsbeschaffung und -generierung zu verbessern und eine genauere und kontextbezogene Dokumentenanalyse zu ermöglichen.
Wie können mit IronPDF strukturierte Daten aus PDFs extrahiert werden?
IronPDF ermöglicht die Extraktion strukturierter Daten aus PDFs in Formate wie JSON und erleichtert so die nahtlose Datenintegration und -analyse über verschiedene Anwendungen und Systeme hinweg.
Kann IronPDF große Dokumentenbibliotheken mit AI verarbeiten?
Ja, IronPDF kann große Dokumentenbibliotheken effizient verarbeiten, indem es KI-Modelle zur Automatisierung von Aufgaben wie Zusammenfassung und Datenextraktion einsetzt, was sich gut mit OpenAI und Azure OpenAI-Integrationen skalieren lässt.
Welche KI-Modelle werden von IronPDF für die PDF-Verarbeitung unterstützt?
IronPDF unterstützt fortschrittliche KI-Modelle wie GPT-5 und Claude, die für Aufgaben wie die Zusammenfassung von Dokumenten und den Aufbau von Frage-Antwort-Systemen verwendet werden, wodurch die allgemeinen Verarbeitungsmöglichkeiten verbessert werden.
Wie erleichtert IronPDF den Aufbau von Q&A-Systemen?
IronPDF hilft beim Aufbau von Q&A-Systemen, indem es Dokumente verarbeitet und analysiert, um relevante Informationen zu extrahieren, die dann verwendet werden können, um genaue Antworten auf Benutzeranfragen zu generieren.
Was sind die wichtigsten Anwendungsfälle für KI-gestützte PDF-Verarbeitung in C#?
Zu den wichtigsten Anwendungsfällen gehören die Zusammenfassung von Dokumenten, die Extraktion strukturierter Daten, die Entwicklung von Q&A-Systemen und die Bearbeitung umfangreicher Dokumentenverarbeitungsaufgaben mit Hilfe von KI-Integrationen wie OpenAI.
Ist es möglich, IronPDF mit Azure OpenAI für die Dokumentenverarbeitung zu verwenden?
Ja, IronPDF kann in Azure OpenAI integriert werden, um Dokumentenverarbeitungsaufgaben zu verbessern und skalierbare Lösungen für die Zusammenfassung, Extraktion und Analyse von PDF-Dokumenten bereitzustellen.
Wie verbessert IronPDF die Dokumentenanalyse mit KI?
IronPDF verbessert die Dokumentenanalyse durch den Einsatz von KI-Modellen zur Automatisierung und Verbesserung von Aufgaben wie Zusammenfassung, Datenextraktion und Informationsabfrage, was zu einer effizienteren und genaueren Bearbeitung von Dokumenten führt.


Scrollst du immer noch?
Sie brauchen schnell einen Beweis? PM > Install-Package IronPdf
Führen Sie eine Probe aus Sehen Sie zu, wie Ihr HTML-Code in eine PDF-Datei umgewandelt wird.










