

Processamento de PDF Automatizado por IA em C#: Resuma, Extraia e Analise Documentos com IronPDF
Processamento de PDF com inteligência artificial em C# com IronPDF permite que os desenvolvedores .NET resumam documentos, extraiam dados estruturados e criem sistemas de perguntas e respostas diretamente sobre fluxos de trabalho de PDF existentes — usando o pacote IronPdf.Extensions.AI construído sobre o Microsoft Semantic Kernel para se conectar perfeitamente com modelos Azure OpenAI e OpenAI. Seja para criar ferramentas de descoberta jurídica , fluxos de trabalho de análise financeira ou plataformas de inteligência documental , o IronPDF cuida da extração de PDFs e da preparação do contexto, permitindo que você se concentre na lógica da IA.
Resumo: Guia de Início Rápido
Este tutorial aborda como conectar o IronPDF a serviços de IA para sumarização de documentos, extração de dados e consultas inteligentes em C# .NET.
- Para quem é indicado: Desenvolvedores .NET que criam aplicativos de inteligência documental — sistemas de descoberta legal, ferramentas de análise financeira, plataformas de revisão de conformidade ou qualquer aplicativo que precise extrair significado de grandes volumes de documentos PDF.
- O que você vai desenvolver: Sumarização de documentos individuais, extração de dados JSON estruturados com esquemas personalizados, perguntas e respostas sobre o conteúdo de documentos, pipelines RAG para documentos longos e fluxos de trabalho de processamento de IA em lote em bibliotecas de documentos.
- Onde funciona: Qualquer ambiente .NET 6+ com uma chave de API do Azure OpenAI ou OpenAI. A extensão de IA integra-se ao Microsoft Semantic Kernel e lida automaticamente com o gerenciamento de janelas de contexto, fragmentação e orquestração.
- Quando usar essa abordagem: Quando seu aplicativo precisa processar PDFs além da extração de texto — como entender obrigações contratuais, resumir artigos de pesquisa, extrair tabelas financeiras como dados estruturados ou responder a perguntas de usuários sobre o conteúdo de documentos em grande escala.
- Por que isso é importante tecnicamente: A extração de texto bruto perde a estrutura do documento — tabelas colapsam, layouts com várias colunas são quebrados e relações semânticas desaparecem. O IronPDF prepara documentos para consumo por IA, preservando a estrutura e gerenciando os limites de tokens, para que o modelo receba dados de entrada limpos e bem organizados.
Resuma um PDF com apenas algumas linhas de código:
-
Instale IronPDF com o Gerenciador de Pacotes NuGet
-
Copie e execute este trecho de código.
await IronPdf.AI.PdfAIEngine.Summarize("contract.pdf", "summary.txt", azureEndpoint, azureApiKey); -
Implante para testar em seu ambiente de produção.
Comece a usar IronPDF em seu projeto hoje com uma avaliação gratuita

Após adquirir ou se inscrever para um período de avaliação de 30 dias do IronPDF, adicione sua chave de licença no início do seu aplicativo.
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp-2.csIronPdf.License.LicenseKey = "KEY";
Imports IronPdf
IronPdf.License.LicenseKey = "KEY"Índice
- A oportunidade IA + PDF
- Integração de IA integrada do IronPDF
- Resumo de Documentos
- Extração Inteligente de Dados
- Perguntas e respostas sobre documentos
- Processamento de IA em lote
- Casos de uso no mundo real
- Resolução de problemas e suporte técnico
A oportunidade IA + PDF
Por que os PDFs são a maior fonte de dados inexplorada?
Os PDFs representam um dos maiores repositórios de conhecimento empresarial estruturado na empresa moderna. Documentos profissionais — contratos, demonstrações financeiras, relatórios de conformidade, pareceres jurídicos e artigos de pesquisa — são predominantemente armazenados em formato PDF. Esses documentos contêm informações comerciais essenciais: termos contratuais que definem obrigações e responsabilidades, métricas financeiras que orientam as decisões de investimento, requisitos regulatórios que garantem a conformidade e resultados de pesquisas que guiam a estratégia.
No entanto, as abordagens tradicionais para o processamento de PDFs têm sido severamente limitadas. Ferramentas básicas de extração de texto podem extrair caracteres brutos de uma página, mas perdem o contexto crucial: as estruturas de tabelas se transformam em texto embaralhado, os layouts de várias colunas tornam-se sem sentido e as relações semânticas entre as seções desaparecem.
O avanço reside na capacidade da IA de compreender o contexto e a estrutura. Os profissionais de Direito modernos não apenas enxergam palavras — eles compreendem a organização de documentos, reconhecem padrões como cláusulas contratuais ou tabelas financeiras e conseguem extrair significado até mesmo de layouts complexos. O sistema de raciocínio unificado do GPT-5, com seu roteador em tempo real, e os recursos agentivos aprimorados do Claude Sonnet 4.5 demonstram taxas de alucinação significativamente reduzidas em comparação com modelos anteriores, tornando-os confiáveis para análise profissional de documentos.
Como os mestres em Direito entendem a estrutura de um documento
Grandes modelos de linguagem trazem recursos sofisticados de processamento de linguagem natural para a análise de PDFs. A arquitetura híbrida do GPT-5 apresenta múltiplos submodelos (principal, mini, de raciocínio, nano) com um roteador em tempo real que seleciona dinamicamente a variante ideal com base na complexidade da tarefa — perguntas simples são direcionadas para modelos mais rápidos, enquanto tarefas de raciocínio complexas envolvem o modelo completo.
O Claude Opus 4.6 se destaca particularmente em tarefas de longa duração com agentes, com equipes de agentes que se coordenam diretamente em trabalhos segmentados e uma janela de contexto de 1 milhão de tokens que pode processar bibliotecas de documentos inteiras sem fragmentação.
Essa compreensão contextual permite que os LLMs (Licensed Liability Masters - Mestres em Liderança Jurídica) executem tarefas que exigem uma compreensão genuína. Ao analisar um contrato, um profissional com mestrado em Direito (LLM) pode identificar não apenas as cláusulas que contêm a palavra "rescisão", mas também compreender as condições específicas em que a rescisão é permitida, os requisitos de notificação envolvidos e as responsabilidades daí resultantes. A base técnica que possibilita essa capacidade é a arquitetura de transformadores que alimenta os modernos LLMs (Learning Learning Machines), com a janela de contexto do GPT-5 suportando até 272.000 tokens de entrada e a janela de 200 mil tokens do Claude Sonnet 4.5 fornecendo uma cobertura abrangente de documentos.
Integração de IA integrada do IronPDF
Instalando o IronPDF e as extensões de IA
Para começar a usar o processamento de PDFs com inteligência artificial, você precisa da biblioteca principal IronPDF , do pacote de extensões de IA e das dependências do Microsoft Semantic Kernel.
Instale o IronPDF com o gerenciador de pacotes NuGet :
Install-Package IronPdf, IronPdf.Extensions.AI, Microsoft.SemanticKernel, Microsoft.SemanticKernel.Plugins.Memory
Esses pacotes funcionam em conjunto para fornecer uma solução completa. O IronPDF lida com todas as operações relacionadas a PDFs — extração de texto, renderização de páginas, conversão de formatos — enquanto a extensão de IA gerencia a integração com modelos de linguagem por meio do Microsoft Semantic Kernel.
<NoWarn>$(NoWarn);SKEXP0001;SKEXP0010;SKEXP0050</NoWarn> ao seu .csproj PropertyGroup para suprimir avisos do compilador.Configurando sua chave de API OpenAI/Azure
Antes de poder utilizar os recursos de IA, você precisa configurar o acesso a um provedor de serviços de IA. A extensão de IA do IronPDF oferece suporte tanto ao OpenAI quanto ao Azure OpenAI. O Azure OpenAI costuma ser a opção preferida para aplicações empresariais por oferecer recursos de segurança aprimorados, certificações de conformidade e a capacidade de manter os dados dentro de regiões geográficas específicas.
Para configurar o Azure OpenAI, você precisará do URL do endpoint do Azure, da chave da API e dos nomes de implantação para os modelos de chat e de incorporação, obtidos no portal do Azure.
Inicializando o mecanismo de IA
A extensão de IA do IronPDF utiliza o Microsoft Semantic Kernel internamente. Antes de usar qualquer recurso de IA, você deve inicializar o kernel com suas credenciais do Azure OpenAI e configurar o armazenamento de memória para processamento de documentos.
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/configure-azure-credentials.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
// Initialize IronPDF AI with Azure OpenAI credentials
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel with Azure OpenAI
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
// Create memory store for document embeddings
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
// Initialize IronPDF AI
IronDocumentAI.Initialize(kernel, memory);
Console.WriteLine("IronPDF AI initialized successfully with Azure OpenAI");Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
' Initialize IronPDF AI with Azure OpenAI credentials
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel with Azure OpenAI
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
' Create memory store for document embeddings
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
' Initialize IronPDF AI
IronDocumentAI.Initialize(kernel, memory)
Console.WriteLine("IronPDF AI initialized successfully with Azure OpenAI")A inicialização cria dois componentes principais:
- Kernel: Gerencia as conclusões de bate-papo e a incorporação de texto por meio do Azure OpenAI.
- Memória: Armazena representações vetoriais de documentos para operações de busca e recuperação semântica.
Uma vez inicializado com IronDocumentAI.Initialize(), você pode usar recursos de IA em todo o seu aplicativo. Para aplicações de produção, é altamente recomendável armazenar credenciais em variáveis de ambiente ou no Azure Key Vault.
Como o IronPDF prepara PDFs para contexto de IA
Um dos aspectos mais desafiadores do processamento de PDFs com inteligência artificial é preparar os documentos para serem consumidos por modelos de linguagem. Embora o GPT-5 suporte até 272.000 tokens de entrada e o Claude Opus 4.6 agora ofereça uma janela de contexto de 1 milhão de tokens, um único contrato legal ou relatório financeiro ainda pode facilmente exceder os limites dos modelos mais antigos.
A extensão de IA do IronPDF lida com essa complexidade por meio da preparação inteligente de documentos. Ao invocar um método de IA, o IronPDF primeiro extrai o texto do PDF, preservando as informações estruturais — identificando parágrafos, preservando a estrutura das tabelas e mantendo as relações entre as seções.
Para documentos que excedem os limites de contexto, o IronPDF implementa o particionamento estratégico em pontos de quebra semântica — divisões naturais na estrutura do documento, como cabeçalhos de seção, quebras de página ou limites de parágrafo.
Resumo de Documentos
Resumos de Documentos Únicos
A sumarização de documentos oferece valor imediato ao condensar documentos extensos em informações fáceis de assimilar. O método Summarize lida com todo o fluxo de trabalho: extraindo texto, preparando-o para consumo de IA, solicitando um resumo do modelo de linguagem e salvando os resultados.
Entrada
O código carrega um PDF usando PdfDocument.FromFile() e chama pdf.Summarize() para gerar um resumo conciso, depois salva o resultado em um arquivo de texto.
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/single-document-summary.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
// Summarize a PDF document using IronPDF AI
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
// Load and summarize PDF
var pdf = PdfDocument.FromFile("sample-report.pdf");
string summary = await pdf.Summarize();
Console.WriteLine("Document Summary:");
Console.WriteLine(summary);
File.WriteAllText("report-summary.txt", summary);
Console.WriteLine("\nSummary saved to report-summary.txt");Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
' Summarize a PDF document using IronPDF AI
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
' Load and summarize PDF
Dim pdf = PdfDocument.FromFile("sample-report.pdf")
Dim summary As String = Await pdf.Summarize()
Console.WriteLine("Document Summary:")
Console.WriteLine(summary)
File.WriteAllText("report-summary.txt", summary)
Console.WriteLine(vbCrLf & "Summary saved to report-summary.txt")Saída do console
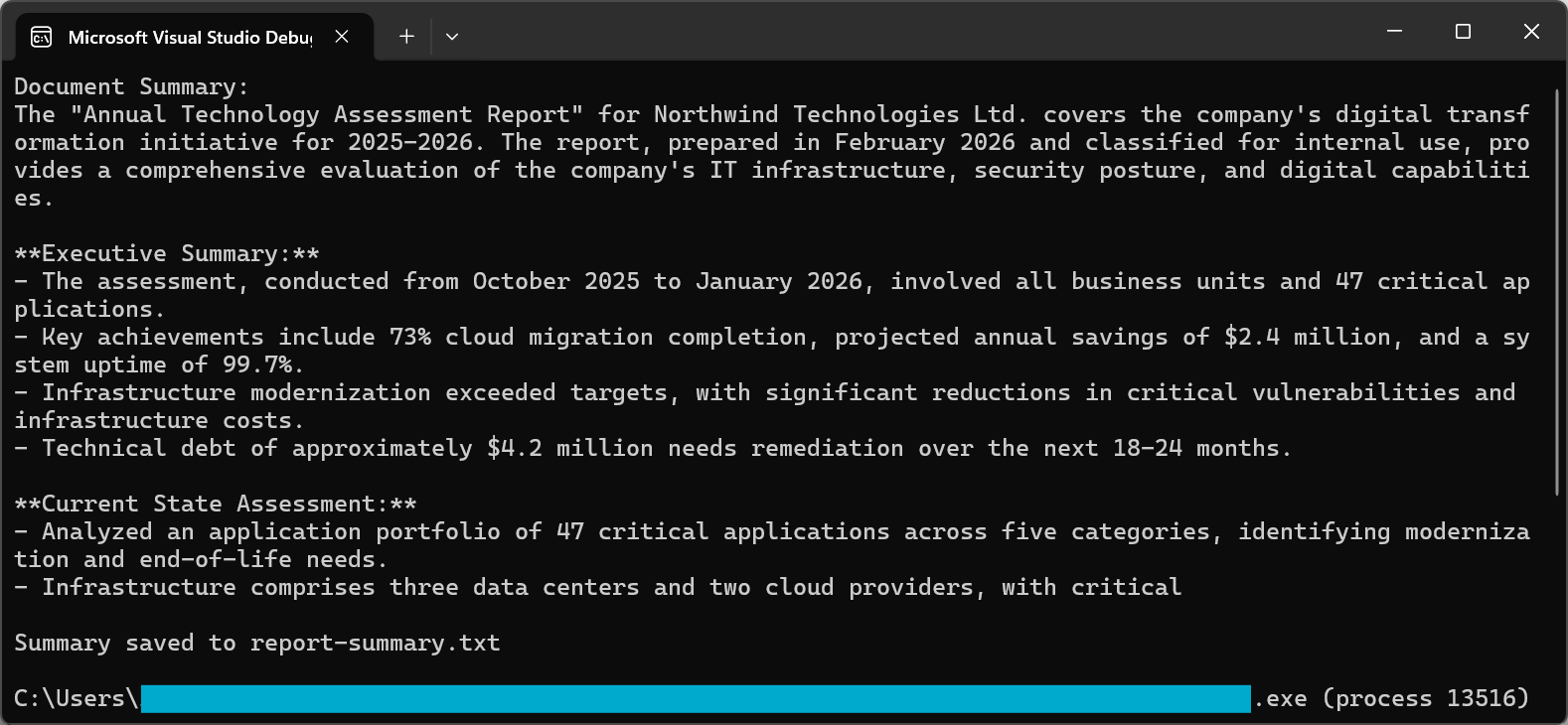
O processo de sumarização utiliza instruções sofisticadas para garantir resultados de alta qualidade. Tanto o GPT-5 quanto o Claude Sonnet 4.5, em 2026, apresentam capacidades de seguimento de instruções significativamente aprimoradas, garantindo que os resumos capturem as informações essenciais, mantendo-se concisos e legíveis.
Para uma explicação mais detalhada das técnicas de sumarização de documentos e opções avançadas, consulte nosso guia prático .
Síntese de múltiplos documentos
Muitos cenários do mundo real exigem a síntese de informações provenientes de vários documentos. Uma equipe jurídica pode precisar identificar cláusulas comuns em um conjunto de contratos, ou um analista financeiro pode querer comparar métricas entre relatórios trimestrais.
A abordagem para a síntese de múltiplos documentos envolve o processamento individual de cada documento para extrair informações-chave e, em seguida, agregar essas informações para a síntese final.
Este exemplo itera através de vários PDFs, chamando pdf.Summarize() em cada um, depois usa pdf.Query() com os resumos combinados para gerar uma síntese unificada.
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/multi-document-synthesis.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
// Synthesize insights across multiple related documents (e.g., quarterly reports into annual summary)
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
// Define documents to synthesize
string[] documentPaths = {
"Q1-report.pdf",
"Q2-report.pdf",
"Q3-report.pdf",
"Q4-report.pdf"
};
var documentSummaries = new List<string>();
// Summarize each document
foreach (string path in documentPaths)
{
var pdf = PdfDocument.FromFile(path);
string summary = await pdf.Summarize();
documentSummaries.Add($"=== {Path.GetFileName(path)} ===\n{summary}");
Console.WriteLine($"Processed: {path}");
}
// Combine and synthesize across all documents
string combinedSummaries = string.Join("\n\n", documentSummaries);
var synthesisDoc = PdfDocument.FromFile(documentPaths[0]);
string synthesisQuery = @"Based on the quarterly summaries below, provide an annual synthesis:
ll trends across quarters
chievements and challenges
over-year patterns
s:
inedSummaries;
string synthesis = await synthesisDoc.Query(synthesisQuery);
Console.WriteLine("\n=== Annual Synthesis ===");
Console.WriteLine(synthesis);
File.WriteAllText("annual-synthesis.txt", synthesis);Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
Imports System.IO
' Synthesize insights across multiple related documents (e.g., quarterly reports into annual summary)
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
' Define documents to synthesize
Dim documentPaths As String() = {
"Q1-report.pdf",
"Q2-report.pdf",
"Q3-report.pdf",
"Q4-report.pdf"
}
Dim documentSummaries = New List(Of String)()
' Summarize each document
For Each path As String In documentPaths
Dim pdf = PdfDocument.FromFile(path)
Dim summary As String = Await pdf.Summarize()
documentSummaries.Add($"=== {Path.GetFileName(path)} ==={vbCrLf}{summary}")
Console.WriteLine($"Processed: {path}")
Next
' Combine and synthesize across all documents
Dim combinedSummaries As String = String.Join(vbCrLf & vbCrLf, documentSummaries)
Dim synthesisDoc = PdfDocument.FromFile(documentPaths(0))
Dim synthesisQuery As String = "Based on the quarterly summaries below, provide an annual synthesis:" & vbCrLf &
"Overall trends across quarters" & vbCrLf &
"Key achievements and challenges" & vbCrLf &
"Year-over-year patterns" & vbCrLf & vbCrLf &
combinedSummaries
Dim synthesis As String = Await synthesisDoc.Query(synthesisQuery)
Console.WriteLine(vbCrLf & "=== Annual Synthesis ===")
Console.WriteLine(synthesis)
File.WriteAllText("annual-synthesis.txt", synthesis)Esse padrão se adapta bem a grandes conjuntos de documentos. Ao processar documentos em paralelo e gerenciar resultados intermediários, é possível analisar centenas ou milhares de documentos, mantendo uma síntese coerente.
Geração de Resumo Executivo
Os resumos executivos exigem uma abordagem diferente da sumarização padrão. Em vez de simplesmente condensar o conteúdo, um resumo executivo deve identificar as informações mais críticas para o negócio, destacar as principais decisões ou recomendações e apresentar as conclusões em um formato adequado para análise pela liderança.
O código usa pdf.Query() com um prompt estruturado solicitando decisões-chave, descobertas críticas, impacto financeiro e avaliação de riscos em linguagem empresarial.
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/executive-summary.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
// Generate executive summary from strategic documents for C-suite leadership
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
var pdf = PdfDocument.FromFile("strategic-plan.pdf");
string executiveQuery = @"Create an executive summary for C-suite leadership. Include:
cisions Required:**
ny decisions needing executive approval
al Findings:**
5 most important findings (bullet points)
ial Impact:**
e/cost implications if mentioned
ssessment:**
riority risks identified
ended Actions:**
ate next steps
er 500 words. Use business language appropriate for board presentation.";
string executiveSummary = await pdf.Query(executiveQuery);
File.WriteAllText("executive-summary.txt", executiveSummary);
Console.WriteLine("Executive summary saved to executive-summary.txt");Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
' Generate executive summary from strategic documents for C-suite leadership
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
Dim pdf = PdfDocument.FromFile("strategic-plan.pdf")
Dim executiveQuery As String = "Create an executive summary for C-suite leadership. Include:
cisions Required:**
ny decisions needing executive approval
al Findings:**
5 most important findings (bullet points)
ial Impact:**
e/cost implications if mentioned
ssessment:**
riority risks identified
ended Actions:**
ate next steps
er 500 words. Use business language appropriate for board presentation."
Dim executiveSummary As String = Await pdf.Query(executiveQuery)
File.WriteAllText("executive-summary.txt", executiveSummary)
Console.WriteLine("Executive summary saved to executive-summary.txt")O resumo executivo resultante prioriza informações práticas em vez de uma cobertura abrangente, fornecendo exatamente o que os tomadores de decisão precisam, sem detalhes excessivos.
Extração Inteligente de Dados
Extraindo dados estruturados para JSON
Uma das aplicações mais poderosas do processamento de PDFs com inteligência artificial é a extração de dados estruturados de documentos não estruturados. A chave para uma extração estruturada bem-sucedida em 2026 é usar esquemas JSON com modos de saída estruturados. O GPT-5 introduz saídas estruturadas aprimoradas, enquanto o Claude Sonnet 4.5 oferece orquestração de ferramentas otimizada para extração de dados confiável.
Entrada
O código chama pdf.Query() com um prompt de esquema JSON e depois usa JsonSerializer.Deserialize() para analisar e validar os dados de fatura extraídos.
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/extract-invoice-json.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
using System.Text.Json;
// Extract structured invoice data as JSON from PDF
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
var pdf = PdfDocument.FromFile("sample-invoice.pdf");
// Define JSON schema for extraction
string extractionQuery = @"Extract invoice data and return as JSON with this exact structure:
voiceNumber"": ""string"",
voiceDate"": ""YYYY-MM-DD"",
eDate"": ""YYYY-MM-DD"",
ndor"": {
""name"": ""string"",
""address"": ""string"",
""taxId"": ""string or null""
stomer"": {
""name"": ""string"",
""address"": ""string""
neItems"": [
{
""description"": ""string"",
""quantity"": number,
""unitPrice"": number,
""total"": number
}
btotal"": number,
xRate"": number,
xAmount"": number,
tal"": number,
rrency"": ""string""
NLY valid JSON, no additional text.";
string jsonResponse = await pdf.Query(extractionQuery);
// Parse and save JSON
try
{
var invoiceData = JsonSerializer.Deserialize<JsonElement>(jsonResponse);
string formattedJson = JsonSerializer.Serialize(invoiceData, new JsonSerializerOptions { WriteIndented = true });
Console.WriteLine("Extracted Invoice Data:");
Console.WriteLine(formattedJson);
File.WriteAllText("invoice-data.json", formattedJson);
}
catch (JsonException)
{
Console.WriteLine("Unable to parse JSON response");
File.WriteAllText("invoice-raw-response.txt", jsonResponse);
}Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
Imports System.Text.Json
' Extract structured invoice data as JSON from PDF
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
Dim pdf = PdfDocument.FromFile("sample-invoice.pdf")
' Define JSON schema for extraction
Dim extractionQuery As String = "Extract invoice data and return as JSON with this exact structure:
voiceNumber"": ""string"",
voiceDate"": ""YYYY-MM-DD"",
eDate"": ""YYYY-MM-DD"",
ndor"": {
""name"": ""string"",
""address"": ""string"",
""taxId"": ""string or null""
stomer"": {
""name"": ""string"",
""address"": ""string""
neItems"": [
{
""description"": ""string"",
""quantity"": number,
""unitPrice"": number,
""total"": number
}
btotal"": number,
xRate"": number,
xAmount"": number,
tal"": number,
rrency"": ""string""
NLY valid JSON, no additional text."
Dim jsonResponse As String = Await pdf.QueryAsync(extractionQuery)
' Parse and save JSON
Try
Dim invoiceData = JsonSerializer.Deserialize(Of JsonElement)(jsonResponse)
Dim formattedJson As String = JsonSerializer.Serialize(invoiceData, New JsonSerializerOptions With {.WriteIndented = True})
Console.WriteLine("Extracted Invoice Data:")
Console.WriteLine(formattedJson)
File.WriteAllText("invoice-data.json", formattedJson)
Catch ex As JsonException
Console.WriteLine("Unable to parse JSON response")
File.WriteAllText("invoice-raw-response.txt", jsonResponse)
End TryCaptura de tela parcial do arquivo JSON gerado
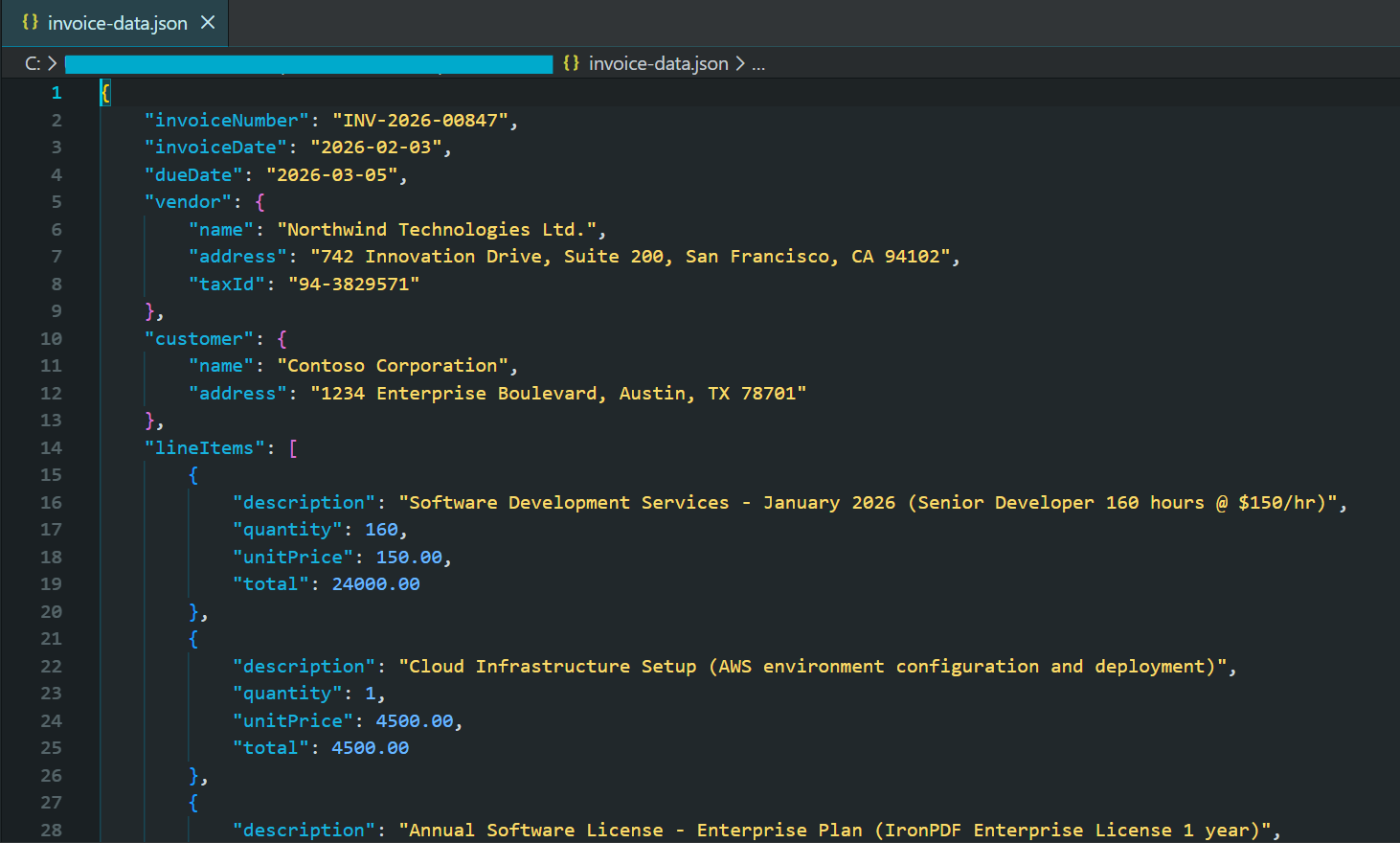
Os modelos modernos de IA em 2026 suportam modos de saída estruturados que garantem respostas JSON válidas e em conformidade com os esquemas fornecidos. Isso elimina a necessidade de tratamento complexo de erros relacionados a respostas malformadas.
Identificação de cláusulas contratuais
Os contratos legais contêm tipos específicos de cláusulas que possuem particular importância: disposições sobre rescisão, limitações de responsabilidade, requisitos de indenização, cessões de propriedade intelectual e obrigações de confidencialidade. A identificação de cláusulas com tecnologia de IA automatiza essa análise, mantendo alta precisão.
Este exemplo usa pdf.Query() com um esquema de JSON focado em cláusulas para extrair tipo de contrato, partes, datas críticas e cláusulas individuais com níveis de risco.
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/contract-clause-analysis.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
using System.Text.Json;
// Analyze contract clauses and identify key terms, risks, and critical dates
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
var pdf = PdfDocument.FromFile("contract.pdf");
// Define JSON schema for contract analysis
string clauseQuery = @"Analyze this contract and identify key clauses. Return JSON:
ntractType"": ""string"",
rties"": [""string""],
fectiveDate"": ""string"",
auses"": [
{
""type"": ""Termination|Liability|Indemnification|Confidentiality|IP|Payment|Warranty|Other"",
""title"": ""string"",
""summary"": ""string"",
""riskLevel"": ""Low|Medium|High"",
""keyTerms"": [""string""]
}
iticalDates"": [
{
""description"": ""string"",
""date"": ""string""
}
erallRiskAssessment"": ""Low|Medium|High"",
commendations"": [""string""]
: termination rights, liability caps, indemnification, IP ownership, confidentiality, payment terms.
NLY valid JSON.";
string analysisJson = await pdf.Query(clauseQuery);
try
{
var analysis = JsonSerializer.Deserialize<JsonElement>(analysisJson);
string formatted = JsonSerializer.Serialize(analysis, new JsonSerializerOptions { WriteIndented = true });
Console.WriteLine("Contract Clause Analysis:");
Console.WriteLine(formatted);
File.WriteAllText("contract-analysis.json", formatted);
// Display high-risk clauses
Console.WriteLine("\n=== High Risk Clauses ===");
foreach (var clause in analysis.GetProperty("clauses").EnumerateArray())
{
if (clause.GetProperty("riskLevel").GetString() == "High")
{
Console.WriteLine($"- {clause.GetProperty("type")}: {clause.GetProperty("summary")}");
}
}
}
catch (JsonException)
{
Console.WriteLine("Unable to parse contract analysis");
File.WriteAllText("contract-analysis-raw.txt", analysisJson);
}Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
Imports System.Text.Json
' Analyze contract clauses and identify key terms, risks, and critical dates
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
Dim pdf = PdfDocument.FromFile("contract.pdf")
' Define JSON schema for contract analysis
Dim clauseQuery As String = "Analyze this contract and identify key clauses. Return JSON:
ntractType"": ""string"",
rties"": [""string""],
fectiveDate"": ""string"",
auses"": [
{
""type"": ""Termination|Liability|Indemnification|Confidentiality|IP|Payment|Warranty|Other"",
""title"": ""string"",
""summary"": ""string"",
""riskLevel"": ""Low|Medium|High"",
""keyTerms"": [""string""]
}
iticalDates"": [
{
""description"": ""string"",
""date"": ""string""
}
erallRiskAssessment"": ""Low|Medium|High"",
commendations"": [""string""]
: termination rights, liability caps, indemnification, IP ownership, confidentiality, payment terms.
NLY valid JSON."
Dim analysisJson As String = Await pdf.Query(clauseQuery)
Try
Dim analysis = JsonSerializer.Deserialize(Of JsonElement)(analysisJson)
Dim formatted As String = JsonSerializer.Serialize(analysis, New JsonSerializerOptions With {.WriteIndented = True})
Console.WriteLine("Contract Clause Analysis:")
Console.WriteLine(formatted)
File.WriteAllText("contract-analysis.json", formatted)
' Display high-risk clauses
Console.WriteLine(vbCrLf & "=== High Risk Clauses ===")
For Each clause In analysis.GetProperty("clauses").EnumerateArray()
If clause.GetProperty("riskLevel").GetString() = "High" Then
Console.WriteLine($"- {clause.GetProperty("type")}: {clause.GetProperty("summary")}")
End If
Next
Catch ex As JsonException
Console.WriteLine("Unable to parse contract analysis")
File.WriteAllText("contract-analysis-raw.txt", analysisJson)
End TryEssa funcionalidade transforma a revisão de contratos de um processo sequencial e manual em um fluxo de trabalho automatizado e escalável. As equipes jurídicas podem identificar rapidamente cláusulas de alto risco em centenas de contratos.
Análise de Dados Financeiros
Os documentos financeiros contêm dados quantitativos essenciais inseridos em narrativas e tabelas complexas. A análise sintática com inteligência artificial se destaca em documentos financeiros porque entende o contexto — distinguindo entre resultados históricos e projeções futuras, identificando se os números estão na casa dos milhares ou dos milhões e compreendendo as relações entre diferentes métricas.
O código usa pdf.Query() com um esquema JSON financeiro para extrair dados de demonstração de resultados, métricas de balanço patrimonial e orientações futuras em saída estruturada.
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/financial-data-extraction.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
using System.Text.Json;
// Extract financial metrics from annual reports and earnings documents
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
var pdf = PdfDocument.FromFile("annual-report.pdf");
// Define JSON schema for financial extraction (numbers in millions)
string financialQuery = @"Extract financial metrics from this document. Return JSON:
portPeriod"": ""string"",
mpany"": ""string"",
rrency"": ""string"",
comeStatement"": {
""revenue"": number,
""costOfRevenue"": number,
""grossProfit"": number,
""operatingExpenses"": number,
""operatingIncome"": number,
""netIncome"": number,
""eps"": number
lanceSheet"": {
""totalAssets"": number,
""totalLiabilities"": number,
""shareholdersEquity"": number,
""cash"": number,
""totalDebt"": number
yMetrics"": {
""revenueGrowthYoY"": ""string"",
""grossMargin"": ""string"",
""operatingMargin"": ""string"",
""netMargin"": ""string"",
""debtToEquity"": number
idance"": {
""nextQuarterRevenue"": ""string"",
""fullYearRevenue"": ""string"",
""notes"": ""string""
for unavailable data. Numbers in millions unless stated.
NLY valid JSON.";
string financialJson = await pdf.Query(financialQuery);
try
{
var financials = JsonSerializer.Deserialize<JsonElement>(financialJson);
string formatted = JsonSerializer.Serialize(financials, new JsonSerializerOptions { WriteIndented = true });
Console.WriteLine("Extracted Financial Data:");
Console.WriteLine(formatted);
File.WriteAllText("financial-data.json", formatted);
}
catch (JsonException)
{
Console.WriteLine("Unable to parse financial data");
File.WriteAllText("financial-raw.txt", financialJson);
}Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
Imports System.Text.Json
' Extract financial metrics from annual reports and earnings documents
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
Dim pdf = PdfDocument.FromFile("annual-report.pdf")
' Define JSON schema for financial extraction (numbers in millions)
Dim financialQuery As String = "Extract financial metrics from this document. Return JSON:
portPeriod"": ""string"",
mpany"": ""string"",
rrency"": ""string"",
comeStatement"": {
""revenue"": number,
""costOfRevenue"": number,
""grossProfit"": number,
""operatingExpenses"": number,
""operatingIncome"": number,
""netIncome"": number,
""eps"": number
lanceSheet"": {
""totalAssets"": number,
""totalLiabilities"": number,
""shareholdersEquity"": number,
""cash"": number,
""totalDebt"": number
yMetrics"": {
""revenueGrowthYoY"": ""string"",
""grossMargin"": ""string"",
""operatingMargin"": ""string"",
""netMargin"": ""string"",
""debtToEquity"": number
idance"": {
""nextQuarterRevenue"": ""string"",
""fullYearRevenue"": ""string"",
""notes"": ""string""
for unavailable data. Numbers in millions unless stated.
NLY valid JSON."
Dim financialJson As String = Await pdf.Query(financialQuery)
Try
Dim financials = JsonSerializer.Deserialize(Of JsonElement)(financialJson)
Dim formatted As String = JsonSerializer.Serialize(financials, New JsonSerializerOptions With {.WriteIndented = True})
Console.WriteLine("Extracted Financial Data:")
Console.WriteLine(formatted)
File.WriteAllText("financial-data.json", formatted)
Catch ex As JsonException
Console.WriteLine("Unable to parse financial data")
File.WriteAllText("financial-raw.txt", financialJson)
End TryOs dados estruturados extraídos podem alimentar diretamente modelos financeiros, bancos de dados de séries temporais ou plataformas de análise, permitindo o rastreamento automatizado de métricas ao longo dos períodos de relatório.
Instruções de extração personalizadas
Muitas organizações têm requisitos de extração exclusivos, baseados em seu domínio específico, formatos de documentos ou processos de negócios. A integração de IA do IronPDF oferece suporte completo a prompts de extração personalizados, permitindo que você defina exatamente quais informações devem ser extraídas e como devem ser estruturadas.
Este exemplo demonstra pdf.Query() com um esquema focado em pesquisa extraindo metodologia, descobertas-chave com níveis de confiança e limitações de artigos acadêmicos.
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/custom-research-extraction.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
using System.Text.Json;
// Extract structured research metadata from academic papers
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
var pdf = PdfDocument.FromFile("research-paper.pdf");
// Define JSON schema for research paper extraction
string researchQuery = @"Extract structured information from this research paper. Return JSON:
tle"": ""string"",
thors"": [""string""],
stitution"": ""string"",
blicationDate"": ""string"",
stract"": ""string"",
searchQuestion"": ""string"",
thodology"": {
""type"": ""Quantitative|Qualitative|Mixed Methods"",
""approach"": ""string"",
""sampleSize"": ""string"",
""dataCollection"": ""string""
yFindings"": [
{
""finding"": ""string"",
""significance"": ""string"",
""confidence"": ""High|Medium|Low""
}
mitations"": [""string""],
tureWork"": [""string""],
ywords"": [""string""]
extracting verifiable claims and noting uncertainty.
NLY valid JSON.";
string extractionResult = await pdf.Query(researchQuery);
try
{
var research = JsonSerializer.Deserialize<JsonElement>(extractionResult);
string formatted = JsonSerializer.Serialize(research, new JsonSerializerOptions { WriteIndented = true });
Console.WriteLine("Research Paper Extraction:");
Console.WriteLine(formatted);
File.WriteAllText("research-extraction.json", formatted);
// Display key findings with confidence levels
Console.WriteLine("\n=== Key Findings ===");
foreach (var finding in research.GetProperty("keyFindings").EnumerateArray())
{
string confidence = finding.GetProperty("confidence").GetString() ?? "Unknown";
Console.WriteLine($"[{confidence}] {finding.GetProperty("finding")}");
}
}
catch (JsonException)
{
Console.WriteLine("Unable to parse research extraction");
File.WriteAllText("research-raw.txt", extractionResult);
}Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
Imports System.Text.Json
' Extract structured research metadata from academic papers
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
Dim pdf = PdfDocument.FromFile("research-paper.pdf")
' Define JSON schema for research paper extraction
Dim researchQuery As String = "Extract structured information from this research paper. Return JSON:
tle"": ""string"",
thors"": [""string""],
stitution"": ""string"",
blicationDate"": ""string"",
stract"": ""string"",
searchQuestion"": ""string"",
thodology"": {
""type"": ""Quantitative|Qualitative|Mixed Methods"",
""approach"": ""string"",
""sampleSize"": ""string"",
""dataCollection"": ""string""
yFindings"": [
{
""finding"": ""string"",
""significance"": ""string"",
""confidence"": ""High|Medium|Low""
}
mitations"": [""string""],
tureWork"": [""string""],
ywords"": [""string""]
extracting verifiable claims and noting uncertainty.
NLY valid JSON."
Dim extractionResult As String = Await pdf.Query(researchQuery)
Try
Dim research = JsonSerializer.Deserialize(Of JsonElement)(extractionResult)
Dim formatted As String = JsonSerializer.Serialize(research, New JsonSerializerOptions With {.WriteIndented = True})
Console.WriteLine("Research Paper Extraction:")
Console.WriteLine(formatted)
File.WriteAllText("research-extraction.json", formatted)
' Display key findings with confidence levels
Console.WriteLine(vbCrLf & "=== Key Findings ===")
For Each finding In research.GetProperty("keyFindings").EnumerateArray()
Dim confidence As String = finding.GetProperty("confidence").GetString() OrElse "Unknown"
Console.WriteLine($"[{confidence}] {finding.GetProperty("finding")}")
Next
Catch ex As JsonException
Console.WriteLine("Unable to parse research extraction")
File.WriteAllText("research-raw.txt", extractionResult)
End TryOs prompts personalizados transformam a extração com inteligência artificial, de uma ferramenta genérica, em uma solução especializada e adaptada às suas necessidades específicas.
Minha biblioteca favorita desse tipo é o IronPDF. Ele permite a manipulação rápida e eficiente de arquivos PDF. Além disso, possui muitos recursos valiosos, como a exportação para o formato PDF/A e a assinatura digital de documentos PDF.
Com o IronOCR, podemos economizar US$ 40.000 por ano em processamento manual, ao mesmo tempo que aumentamos a produtividade e liberamos recursos para tarefas de alto impacto. Eu o recomendo fortemente.
O IronSuite desempenha um papel crucial nas nossas operações. Estas são ferramentas que aumentam a eficiência no negócio, incluindo a criação de plantas baixas e melhoria na gestão de inventário.
Perguntas e respostas sobre documentos
Criando um sistema de perguntas e respostas em PDF
Os sistemas de perguntas e respostas permitem que os usuários interajam com documentos PDF de forma conversacional, fazendo perguntas em linguagem natural e recebendo respostas precisas e contextuais. O padrão básico envolve extrair o texto do PDF, combiná-lo com a pergunta do usuário em um prompt e solicitar uma resposta da IA.
Entrada
O código chama pdf.Memorize() para indexar o documento para busca semântica e depois entra em um loop interativo usando pdf.Query() para responder a perguntas dos usuários.
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/pdf-question-answering.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
// Interactive Q&A system for querying PDF documents
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
var pdf = PdfDocument.FromFile("sample-legal-document.pdf");
// Memorize document to enable persistent querying
await pdf.Memorize();
Console.WriteLine("PDF Q&A System - Type 'exit' to quit\n");
Console.WriteLine($"Document loaded and memorized: {pdf.PageCount} pages\n");
// Interactive Q&A loop
while (true)
{
Console.Write("Your question: ");
string? question = Console.ReadLine();
if (string.IsNullOrWhiteSpace(question) || question.ToLower() == "exit")
break;
string answer = await pdf.Query(question);
Console.WriteLine($"\nAnswer: {answer}\n");
Console.WriteLine(new string('-', 50) + "\n");
}
Console.WriteLine("Q&A session ended.");Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
' Interactive Q&A system for querying PDF documents
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
Dim pdf = PdfDocument.FromFile("sample-legal-document.pdf")
' Memorize document to enable persistent querying
Await pdf.Memorize()
Console.WriteLine("PDF Q&A System - Type 'exit' to quit" & vbCrLf)
Console.WriteLine($"Document loaded and memorized: {pdf.PageCount} pages" & vbCrLf)
' Interactive Q&A loop
While True
Console.Write("Your question: ")
Dim question As String = Console.ReadLine()
If String.IsNullOrWhiteSpace(question) OrElse question.ToLower() = "exit" Then
Exit While
End If
Dim answer As String = Await pdf.Query(question)
Console.WriteLine($"{vbCrLf}Answer: {answer}{vbCrLf}")
Console.WriteLine(New String("-"c, 50) & vbCrLf)
End While
Console.WriteLine("Q&A session ended.")Saída do console
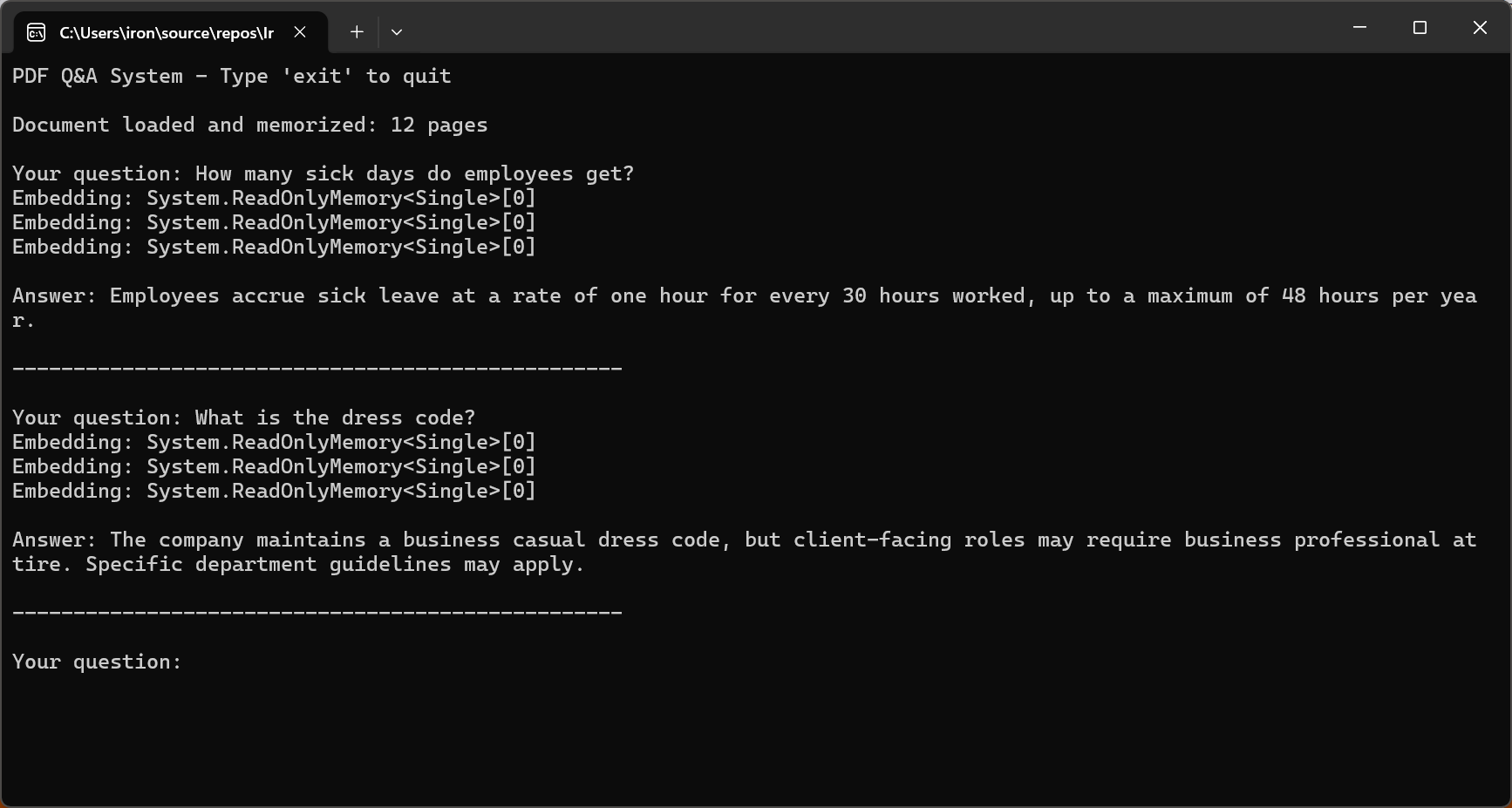
A chave para um processo de perguntas e respostas eficaz em 2026 é limitar a IA a responder com base exclusivamente no conteúdo do documento. O método de treinamento de "conclusões seguras" do GPT-5 e o alinhamento aprimorado do Claude Sonnet 4.5 reduzem substancialmente as taxas de alucinação.
Dividindo documentos longos em partes para janelas de contexto
A maioria dos documentos do mundo real ultrapassa os limites de contexto da IA. Estratégias eficazes de fragmentação são essenciais para o processamento desses documentos. O chunking consiste em dividir documentos em segmentos suficientemente pequenos para caberem em janelas de contexto, preservando a coerência semântica.
Este código itera através de pdf.Pages, criando objetos DocumentChunk com maxChunkTokens e overlapTokens configuráveis para continuidade do contexto.
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/semantic-document-chunking.csusing IronPdf;
// Split long documents into overlapping chunks for RAG systems
var pdf = PdfDocument.FromFile("long-document.pdf");
// Chunking configuration
int maxChunkTokens = 4000; // Leave room for prompts and responses
int overlapTokens = 200; // Overlap for context continuity
int approxCharsPerToken = 4; // Rough estimate for tokenization
int maxChunkChars = maxChunkTokens * approxCharsPerToken;
int overlapChars = overlapTokens * approxCharsPerToken;
var chunks = new List<DocumentChunk>();
var currentChunk = new System.Text.StringBuilder();
int chunkStartPage = 1;
int currentPage = 1;
for (int i = 0; i < pdf.PageCount; i++)
{
string pageText = pdf.Pages[i].Text;
currentPage = i + 1;
if (currentChunk.Length + pageText.Length > maxChunkChars && currentChunk.Length > 0)
{
chunks.Add(new DocumentChunk
{
Text = currentChunk.ToString(),
StartPage = chunkStartPage,
EndPage = currentPage - 1,
ChunkIndex = chunks.Count
});
// Create overlap with previous chunk for continuity
string overlap = currentChunk.Length > overlapChars
? currentChunk.ToString().Substring(currentChunk.Length - overlapChars)
: currentChunk.ToString();
currentChunk.Clear();
currentChunk.Append(overlap);
chunkStartPage = currentPage - 1;
}
currentChunk.AppendLine($"\n--- Page {currentPage} ---\n");
currentChunk.Append(pageText);
}
if (currentChunk.Length > 0)
{
chunks.Add(new DocumentChunk
{
Text = currentChunk.ToString(),
StartPage = chunkStartPage,
EndPage = currentPage,
ChunkIndex = chunks.Count
});
}
Console.WriteLine($"Document chunked into {chunks.Count} segments");
foreach (var chunk in chunks)
{
Console.WriteLine($" Chunk {chunk.ChunkIndex + 1}: Pages {chunk.StartPage}-{chunk.EndPage} ({chunk.Text.Length} chars)");
}
// Save chunk metadata for RAG indexing
File.WriteAllText("chunks-metadata.json", System.Text.Json.JsonSerializer.Serialize(
chunks.Select(c => new { c.ChunkIndex, c.StartPage, c.EndPage, Length = c.Text.Length }),
new System.Text.Json.JsonSerializerOptions { WriteIndented = true }
));
ic class DocumentChunk
public string Text { get; set; } = "";
public int StartPage { get; set; }
public int EndPage { get; set; }
public int ChunkIndex { get; set; }Imports IronPdf
Imports System.IO
Imports System.Text
Imports System.Text.Json
' Split long documents into overlapping chunks for RAG systems
Dim pdf = PdfDocument.FromFile("long-document.pdf")
' Chunking configuration
Dim maxChunkTokens As Integer = 4000 ' Leave room for prompts and responses
Dim overlapTokens As Integer = 200 ' Overlap for context continuity
Dim approxCharsPerToken As Integer = 4 ' Rough estimate for tokenization
Dim maxChunkChars As Integer = maxChunkTokens * approxCharsPerToken
Dim overlapChars As Integer = overlapTokens * approxCharsPerToken
Dim chunks As New List(Of DocumentChunk)()
Dim currentChunk As New StringBuilder()
Dim chunkStartPage As Integer = 1
Dim currentPage As Integer = 1
For i As Integer = 0 To pdf.PageCount - 1
Dim pageText As String = pdf.Pages(i).Text
currentPage = i + 1
If currentChunk.Length + pageText.Length > maxChunkChars AndAlso currentChunk.Length > 0 Then
chunks.Add(New DocumentChunk With {
.Text = currentChunk.ToString(),
.StartPage = chunkStartPage,
.EndPage = currentPage - 1,
.ChunkIndex = chunks.Count
})
' Create overlap with previous chunk for continuity
Dim overlap As String = If(currentChunk.Length > overlapChars,
currentChunk.ToString().Substring(currentChunk.Length - overlapChars),
currentChunk.ToString())
currentChunk.Clear()
currentChunk.Append(overlap)
chunkStartPage = currentPage - 1
End If
currentChunk.AppendLine(vbCrLf & "--- Page " & currentPage & " ---" & vbCrLf)
currentChunk.Append(pageText)
Next
If currentChunk.Length > 0 Then
chunks.Add(New DocumentChunk With {
.Text = currentChunk.ToString(),
.StartPage = chunkStartPage,
.EndPage = currentPage,
.ChunkIndex = chunks.Count
})
End If
Console.WriteLine($"Document chunked into {chunks.Count} segments")
For Each chunk In chunks
Console.WriteLine($" Chunk {chunk.ChunkIndex + 1}: Pages {chunk.StartPage}-{chunk.EndPage} ({chunk.Text.Length} chars)")
Next
' Save chunk metadata for RAG indexing
File.WriteAllText("chunks-metadata.json", JsonSerializer.Serialize(
chunks.Select(Function(c) New With {.ChunkIndex = c.ChunkIndex, .StartPage = c.StartPage, .EndPage = c.EndPage, .Length = c.Text.Length}),
New JsonSerializerOptions With {.WriteIndented = True}
))
Public Class DocumentChunk
Public Property Text As String = ""
Public Property StartPage As Integer
Public Property EndPage As Integer
Public Property ChunkIndex As Integer
End Class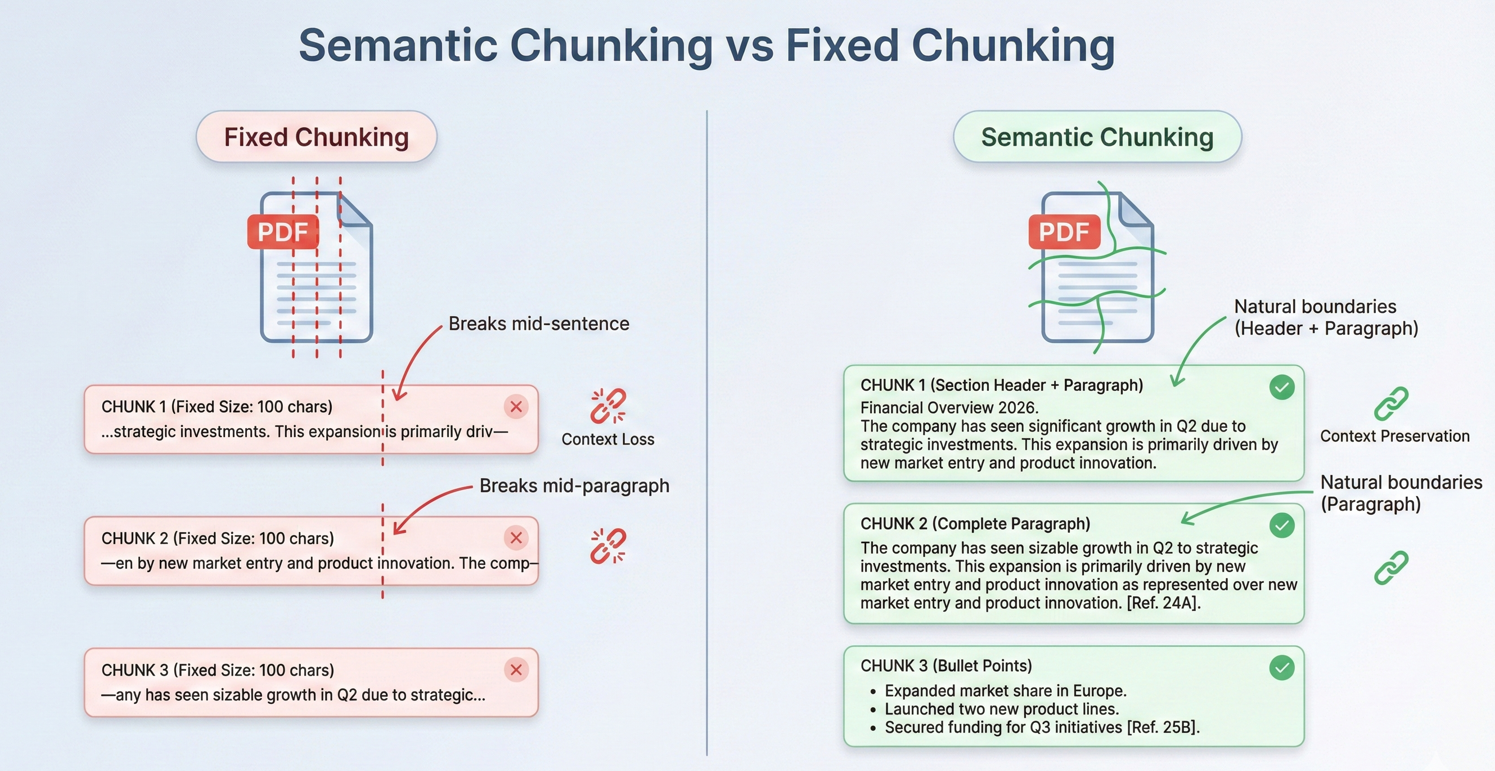
Os blocos sobrepostos proporcionam continuidade entre as fronteiras, garantindo que a IA tenha contexto suficiente mesmo quando as informações relevantes se estendem por vários blocos.
Padrões RAG (Geração Aumentada por Recuperação)
A Geração Aumentada por Recuperação (RAG, na sigla em inglês) representa um padrão poderoso para a análise de documentos com inteligência artificial em 2026. Em vez de alimentar a IA com documentos inteiros, os sistemas RAG primeiro recuperam apenas as partes relevantes para uma determinada consulta e, em seguida, usam essas partes como contexto para gerar respostas.
O fluxo de trabalho RAG possui três fases principais: preparação do documento (fragmentação e criação de embeddings), recuperação (busca por fragmentos relevantes) e geração (uso dos fragmentos recuperados como contexto para respostas de IA).
O código indexa vários PDFs chamando pdf.Memorize() em cada um, depois usa pdf.Query() para recuperar respostas da memória combinada do documento.
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/rag-system-implementation.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
// Retrieval-Augmented Generation (RAG) system for querying across multiple indexed documents
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
// Index all documents in folder
string[] documentPaths = Directory.GetFiles("documents/", "*.pdf");
Console.WriteLine($"Indexing {documentPaths.Length} documents...\n");
// Memorize each document (creates embeddings for retrieval)
foreach (string path in documentPaths)
{
var pdf = PdfDocument.FromFile(path);
await pdf.Memorize();
Console.WriteLine($"Indexed: {Path.GetFileName(path)} ({pdf.PageCount} pages)");
}
Console.WriteLine("\n=== RAG System Ready ===\n");
// Query across all indexed documents
string query = "What are the key compliance requirements for data retention?";
Console.WriteLine($"Query: {query}\n");
var searchPdf = PdfDocument.FromFile(documentPaths[0]);
string answer = await searchPdf.Query(query);
Console.WriteLine($"Answer: {answer}");
// Interactive query loop
Console.WriteLine("\n--- Enter questions (type 'exit' to quit) ---\n");
while (true)
{
Console.Write("Question: ");
string? userQuery = Console.ReadLine();
if (string.IsNullOrWhiteSpace(userQuery) || userQuery.ToLower() == "exit")
break;
string response = await searchPdf.Query(userQuery);
Console.WriteLine($"\nAnswer: {response}\n");
}Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
Imports System.IO
' Retrieval-Augmented Generation (RAG) system for querying across multiple indexed documents
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
' Index all documents in folder
Dim documentPaths As String() = Directory.GetFiles("documents/", "*.pdf")
Console.WriteLine($"Indexing {documentPaths.Length} documents..." & vbCrLf)
' Memorize each document (creates embeddings for retrieval)
For Each path As String In documentPaths
Dim pdf = PdfDocument.FromFile(path)
Await pdf.Memorize()
Console.WriteLine($"Indexed: {Path.GetFileName(path)} ({pdf.PageCount} pages)")
Next
Console.WriteLine(vbCrLf & "=== RAG System Ready ===" & vbCrLf)
' Query across all indexed documents
Dim query As String = "What are the key compliance requirements for data retention?"
Console.WriteLine($"Query: {query}" & vbCrLf)
Dim searchPdf = PdfDocument.FromFile(documentPaths(0))
Dim answer As String = Await searchPdf.Query(query)
Console.WriteLine($"Answer: {answer}")
' Interactive query loop
Console.WriteLine(vbCrLf & "--- Enter questions (type 'exit' to quit) ---" & vbCrLf)
While True
Console.Write("Question: ")
Dim userQuery As String = Console.ReadLine()
If String.IsNullOrWhiteSpace(userQuery) OrElse userQuery.ToLower() = "exit" Then
Exit While
End If
Dim response As String = Await searchPdf.Query(userQuery)
Console.WriteLine(vbCrLf & $"Answer: {response}" & vbCrLf)
End WhileOs sistemas RAG são excelentes no gerenciamento de grandes coleções de documentos — bancos de dados de processos judiciais, bibliotecas de documentação técnica, arquivos de pesquisa. Ao recuperar apenas as partes relevantes, eles mantêm a qualidade da resposta, ao mesmo tempo que se adaptam a tamanhos de documento praticamente ilimitados.
Citação de fontes de páginas em PDF
Para aplicações profissionais, as respostas da IA devem ser verificáveis. A abordagem de citação envolve a manutenção de metadados sobre as origens dos fragmentos durante o processo de fragmentação e recuperação. Cada bloco armazena não apenas o conteúdo do texto, mas também os números das páginas de origem, os cabeçalhos das seções e a posição no documento.
Entrada
O código usa pdf.Query() com instruções de citação e depois chama ExtractCitedPages() com regex para analisar referências de página e verificar fontes usando pdf.Pages[pageNum - 1].Text.
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/answer-with-citations.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
using System.Text.RegularExpressions;
// Answer questions with page citations and source verification
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
var pdf = PdfDocument.FromFile("sample-legal-document.pdf");
await pdf.Memorize();
string question = "What are the termination conditions in this agreement?";
// Request citations in query
string citationQuery = $@"{question}
T: Include specific page citations in your answer using the format (Page X) or (Pages X-Y).
e information that appears in the document.";
string answerWithCitations = await pdf.Query(citationQuery);
Console.WriteLine("Question: " + question);
Console.WriteLine("\nAnswer with Citations:");
Console.WriteLine(answerWithCitations);
// Extract cited page numbers using regex
var citedPages = ExtractCitedPages(answerWithCitations);
Console.WriteLine($"\nCited pages: {string.Join(", ", citedPages)}");
// Verify citations with page excerpts
Console.WriteLine("\n=== Source Verification ===");
foreach (int pageNum in citedPages.Take(3))
{
if (pageNum <= pdf.PageCount && pageNum > 0)
{
string pageText = pdf.Pages[pageNum - 1].Text;
string excerpt = pageText.Length > 200 ? pageText.Substring(0, 200) + "..." : pageText;
Console.WriteLine($"\nPage {pageNum} excerpt:\n{excerpt}");
}
}
// Extract page numbers from citation format (Page X) or (Pages X-Y)
List<int> ExtractCitedPages(string text)
{
var pages = new HashSet<int>();
var matches = Regex.Matches(text, @"\(Pages?\s*(\d+)(?:\s*-\s*(\d+))?\)", RegexOptions.IgnoreCase);
foreach (Match match in matches)
{
int startPage = int.Parse(match.Groups[1].Value);
pages.Add(startPage);
if (match.Groups[2].Success)
{
int endPage = int.Parse(match.Groups[2].Value);
for (int p = startPage; p <= endPage; p++)
pages.Add(p);
}
}
return pages.OrderBy(p => p).ToList();
}Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
Imports System.Text.RegularExpressions
' Answer questions with page citations and source verification
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
Dim pdf = PdfDocument.FromFile("sample-legal-document.pdf")
Await pdf.Memorize()
Dim question As String = "What are the termination conditions in this agreement?"
' Request citations in query
Dim citationQuery As String = $"{question}
T: Include specific page citations in your answer using the format (Page X) or (Pages X-Y).
e information that appears in the document."
Dim answerWithCitations As String = Await pdf.Query(citationQuery)
Console.WriteLine("Question: " & question)
Console.WriteLine(vbCrLf & "Answer with Citations:")
Console.WriteLine(answerWithCitations)
' Extract cited page numbers using regex
Dim citedPages = ExtractCitedPages(answerWithCitations)
Console.WriteLine(vbCrLf & "Cited pages: " & String.Join(", ", citedPages))
' Verify citations with page excerpts
Console.WriteLine(vbCrLf & "=== Source Verification ===")
For Each pageNum As Integer In citedPages.Take(3)
If pageNum <= pdf.PageCount AndAlso pageNum > 0 Then
Dim pageText As String = pdf.Pages(pageNum - 1).Text
Dim excerpt As String = If(pageText.Length > 200, pageText.Substring(0, 200) & "...", pageText)
Console.WriteLine(vbCrLf & "Page " & pageNum & " excerpt:" & vbCrLf & excerpt)
End If
Next
' Extract page numbers from citation format (Page X) or (Pages X-Y)
Function ExtractCitedPages(ByVal text As String) As List(Of Integer)
Dim pages = New HashSet(Of Integer)()
Dim matches = Regex.Matches(text, "\((Pages?)\s*(\d+)(?:\s*-\s*(\d+))?\)", RegexOptions.IgnoreCase)
For Each match As Match In matches
Dim startPage As Integer = Integer.Parse(match.Groups(2).Value)
pages.Add(startPage)
If match.Groups(3).Success Then
Dim endPage As Integer = Integer.Parse(match.Groups(3).Value)
For p As Integer = startPage To endPage
pages.Add(p)
Next
End If
Next
Return pages.OrderBy(Function(p) p).ToList()
End FunctionSaída do console
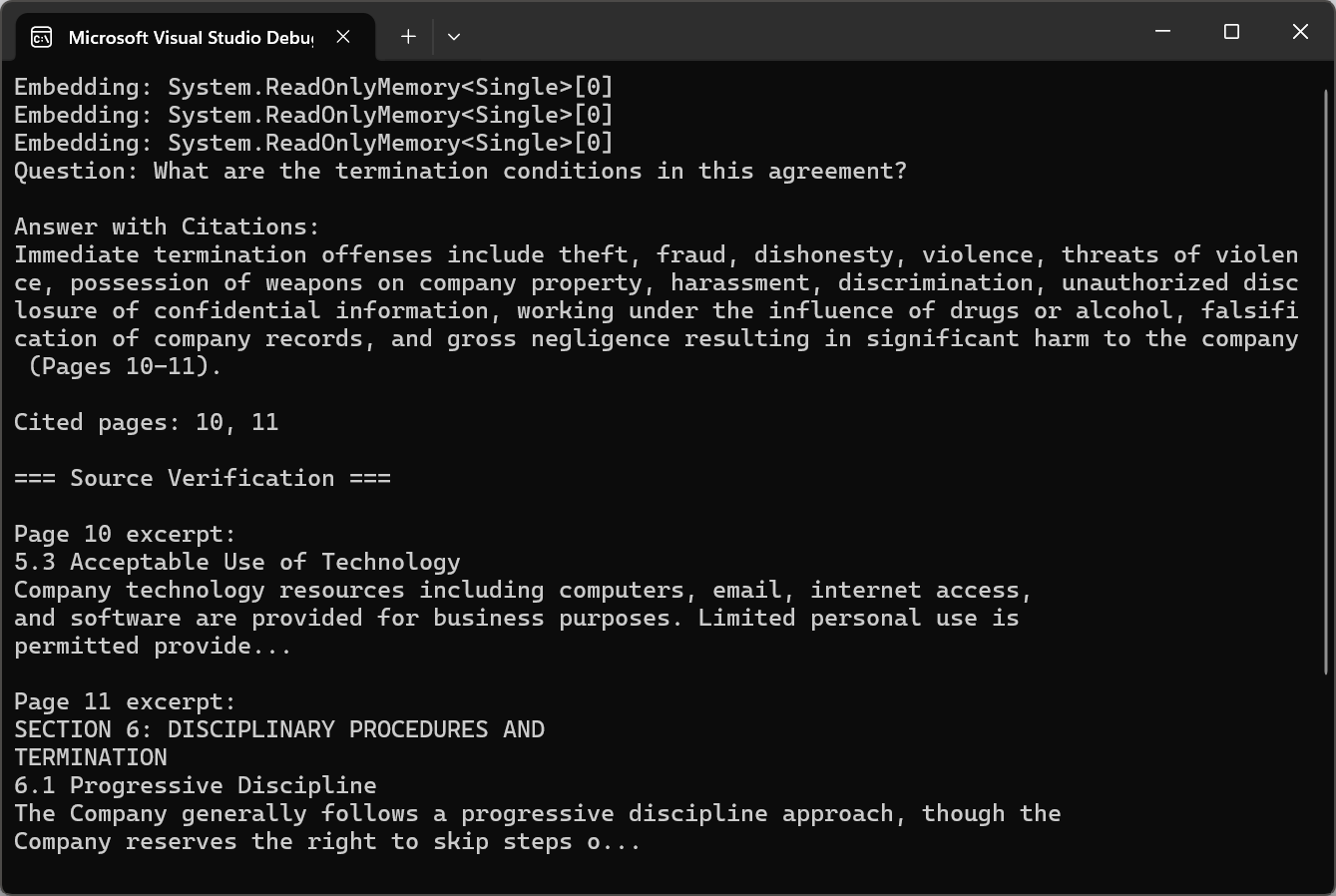
As citações transformam respostas geradas por IA, de resultados opacos para informações transparentes e verificáveis. Os usuários podem revisar o material de origem para validar as respostas e aumentar a confiança na análise assistida por IA.
Processamento de IA em lote
Processamento de bibliotecas de documentos em grande escala
O processamento de documentos empresariais geralmente envolve milhares ou milhões de PDFs. A base do processamento em lote escalável é a paralelização. O IronPDF é seguro para uso em múltiplas threads, permitindo o processamento simultâneo de PDFs sem interferências.
Este código usa SemaphoreSlim com maxConcurrency configuráveis para processar PDFs em paralelo, chamando pdf.Summarize() em cada um enquanto rastreia os resultados em um ConcurrentBag.
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/batch-document-processing.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
using System;
using System.Collections.Concurrent;
using System.Text;
// Process multiple documents in parallel with rate limiting
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
// Configure parallel processing with rate limiting
int maxConcurrency = 3;
string inputFolder = "documents/";
string outputFolder = "summaries/";
Directory.CreateDirectory(outputFolder);
string[] pdfFiles = Directory.GetFiles(inputFolder, "*.pdf");
Console.WriteLine($"Processing {pdfFiles.Length} documents...\n");
var results = new ConcurrentBag<ProcessingResult>();
var semaphore = new SemaphoreSlim(maxConcurrency);
var tasks = pdfFiles.Select(async filePath =>
{
await semaphore.WaitAsync();
var result = new ProcessingResult { FilePath = filePath };
try
{
var stopwatch = System.Diagnostics.Stopwatch.StartNew();
var pdf = PdfDocument.FromFile(filePath);
string summary = await pdf.Summarize();
string outputPath = Path.Combine(outputFolder,
Path.GetFileNameWithoutExtension(filePath) + "-summary.txt");
await File.WriteAllTextAsync(outputPath, summary);
stopwatch.Stop();
result.Success = true;
result.ProcessingTime = stopwatch.Elapsed;
result.OutputPath = outputPath;
Console.WriteLine($"[OK] {Path.GetFileName(filePath)} ({stopwatch.ElapsedMilliseconds}ms)");
}
catch (Exception ex)
{
result.Success = false;
result.ErrorMessage = ex.Message;
Console.WriteLine($"[ERROR] {Path.GetFileName(filePath)}: {ex.Message}");
}
finally
{
semaphore.Release();
results.Add(result);
}
}).ToArray();
await Task.WhenAll(tasks);
// Generate processing report
var successful = results.Where(r => r.Success).ToList();
var failed = results.Where(r => !r.Success).ToList();
var report = new StringBuilder();
report.AppendLine("=== Batch Processing Report ===");
report.AppendLine($"Successful: {successful.Count}");
report.AppendLine($"Failed: {failed.Count}");
if (successful.Any())
{
var avgTime = TimeSpan.FromMilliseconds(successful.Average(r => r.ProcessingTime.TotalMilliseconds));
report.AppendLine($"Average processing time: {avgTime.TotalSeconds:F1}s");
}
if (failed.Any())
{
report.AppendLine("\nFailed documents:");
foreach (var fail in failed)
report.AppendLine($" - {Path.GetFileName(fail.FilePath)}: {fail.ErrorMessage}");
}
string reportText = report.ToString();
Console.WriteLine($"\n{reportText}");
File.WriteAllText(Path.Combine(outputFolder, "processing-report.txt"), reportText);
s ProcessingResult
public string FilePath { get; set; } = "";
public bool Success { get; set; }
public TimeSpan ProcessingTime { get; set; }
public string OutputPath { get; set; } = "";
public string ErrorMessage { get; set; } = "";Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
Imports System
Imports System.Collections.Concurrent
Imports System.Text
Imports System.IO
Imports System.Linq
Imports System.Threading
Imports System.Threading.Tasks
' Process multiple documents in parallel with rate limiting
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
' Configure parallel processing with rate limiting
Dim maxConcurrency As Integer = 3
Dim inputFolder As String = "documents/"
Dim outputFolder As String = "summaries/"
Directory.CreateDirectory(outputFolder)
Dim pdfFiles As String() = Directory.GetFiles(inputFolder, "*.pdf")
Console.WriteLine($"Processing {pdfFiles.Length} documents...{vbCrLf}")
Dim results = New ConcurrentBag(Of ProcessingResult)()
Dim semaphore = New SemaphoreSlim(maxConcurrency)
Dim tasks = pdfFiles.Select(Async Function(filePath)
Await semaphore.WaitAsync()
Dim result = New ProcessingResult With {.FilePath = filePath}
Try
Dim stopwatch = System.Diagnostics.Stopwatch.StartNew()
Dim pdf = PdfDocument.FromFile(filePath)
Dim summary As String = Await pdf.Summarize()
Dim outputPath = Path.Combine(outputFolder, Path.GetFileNameWithoutExtension(filePath) & "-summary.txt")
Await File.WriteAllTextAsync(outputPath, summary)
stopwatch.Stop()
result.Success = True
result.ProcessingTime = stopwatch.Elapsed
result.OutputPath = outputPath
Console.WriteLine($"[OK] {Path.GetFileName(filePath)} ({stopwatch.ElapsedMilliseconds}ms)")
Catch ex As Exception
result.Success = False
result.ErrorMessage = ex.Message
Console.WriteLine($"[ERROR] {Path.GetFileName(filePath)}: {ex.Message}")
Finally
semaphore.Release()
results.Add(result)
End Try
End Function).ToArray()
Await Task.WhenAll(tasks)
' Generate processing report
Dim successful = results.Where(Function(r) r.Success).ToList()
Dim failed = results.Where(Function(r) Not r.Success).ToList()
Dim report = New StringBuilder()
report.AppendLine("=== Batch Processing Report ===")
report.AppendLine($"Successful: {successful.Count}")
report.AppendLine($"Failed: {failed.Count}")
If successful.Any() Then
Dim avgTime = TimeSpan.FromMilliseconds(successful.Average(Function(r) r.ProcessingTime.TotalMilliseconds))
report.AppendLine($"Average processing time: {avgTime.TotalSeconds:F1}s")
End If
If failed.Any() Then
report.AppendLine($"{vbCrLf}Failed documents:")
For Each fail In failed
report.AppendLine($" - {Path.GetFileName(fail.FilePath)}: {fail.ErrorMessage}")
Next
End If
Dim reportText As String = report.ToString()
Console.WriteLine($"{vbCrLf}{reportText}")
File.WriteAllText(Path.Combine(outputFolder, "processing-report.txt"), reportText)
Public Class ProcessingResult
Public Property FilePath As String = ""
Public Property Success As Boolean
Public Property ProcessingTime As TimeSpan
Public Property OutputPath As String = ""
Public Property ErrorMessage As String = ""
End ClassUm tratamento robusto de erros é crucial em larga escala. Os sistemas de produção implementam lógica de repetição com recuo exponencial, registro de erros separado para documentos com falha e processamento retomável.
Gestão de custos e utilização de tokens
Normalmente, os custos da API de IA são cobrados por token. Em 2026, o GPT-5 custará US$ 1,25 por milhão de tokens de entrada e US$ 10 por milhão de tokens de saída, enquanto o Claude Sonnet 4.5 custará US$ 3 por milhão de tokens de entrada e US$ 15 por milhão de tokens de saída. A principal estratégia de otimização de custos é minimizar o uso desnecessário de tokens.
A API Batch da OpenAI oferece descontos de 50% no custo dos tokens em troca de tempos de processamento mais longos (até 24 horas). Para processamento noturno ou análises periódicas, o processamento em lote proporciona economias substanciais.
O código extrai texto usando pdf.ExtractAllText(), cria solicitações de lote JSONL, faz upload via HttpClient para o endpoint de arquivos do OpenAI e submete à API de lote.
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/batch-api-processing.csusing IronPdf;
using System.Text.Json;
using System.Net.Http.Headers;
// Use OpenAI Batch API for 50% cost savings on large-scale document processing
string openAiApiKey = "your-openai-api-key";
string inputFolder = "documents/";
// Prepare batch requests in JSONL format
var batchRequests = new List<string>();
string[] pdfFiles = Directory.GetFiles(inputFolder, "*.pdf");
Console.WriteLine($"Preparing batch for {pdfFiles.Length} documents...\n");
foreach (string filePath in pdfFiles)
{
var pdf = PdfDocument.FromFile(filePath);
string pdfText = pdf.ExtractAllText();
// Truncate to stay within batch API limits
if (pdfText.Length > 100000)
pdfText = pdfText.Substring(0, 100000) + "\n[Truncated...]";
var request = new
{
custom_id = Path.GetFileNameWithoutExtension(filePath),
method = "POST",
url = "/v1/chat/completions",
body = new
{
model = "gpt-4o",
messages = new[]
{
new { role = "system", content = "Summarize the following document concisely." },
new { role = "user", content = pdfText }
},
max_tokens = 1000
}
};
batchRequests.Add(JsonSerializer.Serialize(request));
}
// Create JSONL file
string batchFilePath = "batch-requests.jsonl";
File.WriteAllLines(batchFilePath, batchRequests);
Console.WriteLine($"Created batch file with {batchRequests.Count} requests");
// Upload file to OpenAI
using var httpClient = new HttpClient();
httpClient.DefaultRequestHeaders.Authorization = new AuthenticationHeaderValue("Bearer", openAiApiKey);
using var fileContent = new MultipartFormDataContent();
fileContent.Add(new ByteArrayContent(File.ReadAllBytes(batchFilePath)), "file", "batch-requests.jsonl");
fileContent.Add(new StringContent("batch"), "purpose");
var uploadResponse = await httpClient.PostAsync("https://api.openai.com/v1/files", fileContent);
var uploadResult = JsonSerializer.Deserialize<JsonElement>(await uploadResponse.Content.ReadAsStringAsync());
string fileId = uploadResult.GetProperty("id").GetString()!;
Console.WriteLine($"Uploaded file: {fileId}");
// Create batch job (24-hour completion window for 50% discount)
var batchJobRequest = new
{
input_file_id = fileId,
endpoint = "/v1/chat/completions",
completion_window = "24h"
};
var batchResponse = await httpClient.PostAsync(
"https://api.openai.com/v1/batches",
new StringContent(JsonSerializer.Serialize(batchJobRequest), System.Text.Encoding.UTF8, "application/json")
);
var batchResult = JsonSerializer.Deserialize<JsonElement>(await batchResponse.Content.ReadAsStringAsync());
string batchId = batchResult.GetProperty("id").GetString()!;
Console.WriteLine($"\nBatch job created: {batchId}");
Console.WriteLine("Job will complete within 24 hours");
Console.WriteLine($"Check status: GET https://api.openai.com/v1/batches/{batchId}");
File.WriteAllText("batch-job-id.txt", batchId);
Console.WriteLine("\nBatch ID saved to batch-job-id.txt");Imports IronPdf
Imports System.Text.Json
Imports System.Net.Http.Headers
' Use OpenAI Batch API for 50% cost savings on large-scale document processing
Dim openAiApiKey As String = "your-openai-api-key"
Dim inputFolder As String = "documents/"
' Prepare batch requests in JSONL format
Dim batchRequests As New List(Of String)()
Dim pdfFiles As String() = Directory.GetFiles(inputFolder, "*.pdf")
Console.WriteLine($"Preparing batch for {pdfFiles.Length} documents..." & vbCrLf)
For Each filePath As String In pdfFiles
Dim pdf = PdfDocument.FromFile(filePath)
Dim pdfText As String = pdf.ExtractAllText()
' Truncate to stay within batch API limits
If pdfText.Length > 100000 Then
pdfText = pdfText.Substring(0, 100000) & vbCrLf & "[Truncated...]"
End If
Dim request = New With {
.custom_id = Path.GetFileNameWithoutExtension(filePath),
.method = "POST",
.url = "/v1/chat/completions",
.body = New With {
.model = "gpt-4o",
.messages = New Object() {
New With {.role = "system", .content = "Summarize the following document concisely."},
New With {.role = "user", .content = pdfText}
},
.max_tokens = 1000
}
}
batchRequests.Add(JsonSerializer.Serialize(request))
Next
' Create JSONL file
Dim batchFilePath As String = "batch-requests.jsonl"
File.WriteAllLines(batchFilePath, batchRequests)
Console.WriteLine($"Created batch file with {batchRequests.Count} requests")
' Upload file to OpenAI
Using httpClient As New HttpClient()
httpClient.DefaultRequestHeaders.Authorization = New AuthenticationHeaderValue("Bearer", openAiApiKey)
Using fileContent As New MultipartFormDataContent()
fileContent.Add(New ByteArrayContent(File.ReadAllBytes(batchFilePath)), "file", "batch-requests.jsonl")
fileContent.Add(New StringContent("batch"), "purpose")
Dim uploadResponse = Await httpClient.PostAsync("https://api.openai.com/v1/files", fileContent)
Dim uploadResult = JsonSerializer.Deserialize(Of JsonElement)(Await uploadResponse.Content.ReadAsStringAsync())
Dim fileId As String = uploadResult.GetProperty("id").GetString()
Console.WriteLine($"Uploaded file: {fileId}")
' Create batch job (24-hour completion window for 50% discount)
Dim batchJobRequest = New With {
.input_file_id = fileId,
.endpoint = "/v1/chat/completions",
.completion_window = "24h"
}
Dim batchResponse = Await httpClient.PostAsync(
"https://api.openai.com/v1/batches",
New StringContent(JsonSerializer.Serialize(batchJobRequest), System.Text.Encoding.UTF8, "application/json")
)
Dim batchResult = JsonSerializer.Deserialize(Of JsonElement)(Await batchResponse.Content.ReadAsStringAsync())
Dim batchId As String = batchResult.GetProperty("id").GetString()
Console.WriteLine(vbCrLf & $"Batch job created: {batchId}")
Console.WriteLine("Job will complete within 24 hours")
Console.WriteLine($"Check status: GET https://api.openai.com/v1/batches/{batchId}")
File.WriteAllText("batch-job-id.txt", batchId)
Console.WriteLine(vbCrLf & "Batch ID saved to batch-job-id.txt")
End Using
End UsingMonitorar o uso de tokens em produção é essencial. Muitas organizações descobrem que 80% de seus documentos podem ser processados com modelos menores e mais baratos, reservando os modelos mais caros apenas para casos complexos.
Armazenamento em cache e processamento incremental
Para coleções de documentos que são atualizadas incrementalmente, estratégias inteligentes de cache e processamento incremental reduzem drasticamente os custos. O armazenamento em cache em nível de documento guarda os resultados juntamente com um hash do PDF de origem, evitando o reprocessamento desnecessário de documentos inalterados.
A classe DocumentCacheManager usa ComputeFileHash() com SHA256 para detectar mudanças, armazenando resultados em objetos CacheEntry com carimbos de tempo LastAccessed.
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/incremental-caching.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
using System;
using System.Collections.Generic;
using System.Security.Cryptography;
using System.Text.Json;
// Cache AI processing results using file hashes to avoid reprocessing unchanged documents
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
// Configure caching
string cacheFolder = "ai-cache/";
string documentsFolder = "documents/";
Directory.CreateDirectory(cacheFolder);
var cacheManager = new DocumentCacheManager(cacheFolder);
// Process documents with caching
string[] pdfFiles = Directory.GetFiles(documentsFolder, "*.pdf");
int cached = 0, processed = 0;
foreach (string filePath in pdfFiles)
{
string fileName = Path.GetFileName(filePath);
string fileHash = cacheManager.ComputeFileHash(filePath);
var cachedResult = cacheManager.GetCachedResult(fileName, fileHash);
if (cachedResult != null)
{
Console.WriteLine($"[CACHE HIT] {fileName}");
cached++;
continue;
}
Console.WriteLine($"[PROCESSING] {fileName}");
var pdf = PdfDocument.FromFile(filePath);
string summary = await pdf.Summarize();
cacheManager.CacheResult(fileName, fileHash, summary);
processed++;
}
Console.WriteLine($"\nProcessing complete: {cached} cached, {processed} newly processed");
Console.WriteLine($"Cost savings: {(cached * 100.0 / Math.Max(1, cached + processed)):F1}% served from cache");
ash-based cache manager with JSON index
s DocumentCacheManager
private readonly string _cacheFolder;
private readonly string _indexPath;
private Dictionary<string, CacheEntry> _index;
public DocumentCacheManager(string cacheFolder)
{
_cacheFolder = cacheFolder;
_indexPath = Path.Combine(cacheFolder, "cache-index.json");
_index = LoadIndex();
}
private Dictionary<string, CacheEntry> LoadIndex()
{
if (File.Exists(_indexPath))
{
string json = File.ReadAllText(_indexPath);
return JsonSerializer.Deserialize<Dictionary<string, CacheEntry>>(json) ?? new();
}
return new Dictionary<string, CacheEntry>();
}
private void SaveIndex()
{
string json = JsonSerializer.Serialize(_index, new JsonSerializerOptions { WriteIndented = true });
File.WriteAllText(_indexPath, json);
}
// SHA256 hash to detect file changes
public string ComputeFileHash(string filePath)
{
using var sha256 = SHA256.Create();
using var stream = File.OpenRead(filePath);
byte[] hash = sha256.ComputeHash(stream);
return Convert.ToHexString(hash);
}
public string? GetCachedResult(string fileName, string currentHash)
{
if (_index.TryGetValue(fileName, out var entry))
{
if (entry.FileHash == currentHash && File.Exists(entry.CachePath))
{
entry.LastAccessed = DateTime.UtcNow;
SaveIndex();
return File.ReadAllText(entry.CachePath);
}
}
return null;
}
public void CacheResult(string fileName, string fileHash, string result)
{
string cachePath = Path.Combine(_cacheFolder, $"{Path.GetFileNameWithoutExtension(fileName)}-{fileHash[..8]}.txt");
File.WriteAllText(cachePath, result);
_index[fileName] = new CacheEntry
{
FileHash = fileHash,
CachePath = cachePath,
CreatedAt = DateTime.UtcNow,
LastAccessed = DateTime.UtcNow
};
SaveIndex();
}
s CacheEntry
public string FileHash { get; set; } = "";
public string CachePath { get; set; } = "";
public DateTime CreatedAt { get; set; }
public DateTime LastAccessed { get; set; }Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
Imports System
Imports System.Collections.Generic
Imports System.Security.Cryptography
Imports System.Text.Json
' Cache AI processing results using file hashes to avoid reprocessing unchanged documents
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
' Configure caching
Dim cacheFolder As String = "ai-cache/"
Dim documentsFolder As String = "documents/"
Directory.CreateDirectory(cacheFolder)
Dim cacheManager = New DocumentCacheManager(cacheFolder)
' Process documents with caching
Dim pdfFiles As String() = Directory.GetFiles(documentsFolder, "*.pdf")
Dim cached As Integer = 0, processed As Integer = 0
For Each filePath As String In pdfFiles
Dim fileName As String = Path.GetFileName(filePath)
Dim fileHash As String = cacheManager.ComputeFileHash(filePath)
Dim cachedResult As String = cacheManager.GetCachedResult(fileName, fileHash)
If cachedResult IsNot Nothing Then
Console.WriteLine($"[CACHE HIT] {fileName}")
cached += 1
Continue For
End If
Console.WriteLine($"[PROCESSING] {fileName}")
Dim pdf = PdfDocument.FromFile(filePath)
Dim summary As String = Await pdf.Summarize()
cacheManager.CacheResult(fileName, fileHash, summary)
processed += 1
Next
Console.WriteLine(vbCrLf & $"Processing complete: {cached} cached, {processed} newly processed")
Console.WriteLine($"Cost savings: {(cached * 100.0 / Math.Max(1, cached + processed)):F1}% served from cache")
' Hash-based cache manager with JSON index
Public Class DocumentCacheManager
Private ReadOnly _cacheFolder As String
Private ReadOnly _indexPath As String
Private _index As Dictionary(Of String, CacheEntry)
Public Sub New(cacheFolder As String)
_cacheFolder = cacheFolder
_indexPath = Path.Combine(cacheFolder, "cache-index.json")
_index = LoadIndex()
End Sub
Private Function LoadIndex() As Dictionary(Of String, CacheEntry)
If File.Exists(_indexPath) Then
Dim json As String = File.ReadAllText(_indexPath)
Return JsonSerializer.Deserialize(Of Dictionary(Of String, CacheEntry))(json) OrElse New Dictionary(Of String, CacheEntry)()
End If
Return New Dictionary(Of String, CacheEntry)()
End Function
Private Sub SaveIndex()
Dim json As String = JsonSerializer.Serialize(_index, New JsonSerializerOptions With {.WriteIndented = True})
File.WriteAllText(_indexPath, json)
End Sub
' SHA256 hash to detect file changes
Public Function ComputeFileHash(filePath As String) As String
Using sha256 = SHA256.Create()
Using stream = File.OpenRead(filePath)
Dim hash As Byte() = sha256.ComputeHash(stream)
Return Convert.ToHexString(hash)
End Using
End Using
End Function
Public Function GetCachedResult(fileName As String, currentHash As String) As String
If _index.TryGetValue(fileName, entry) Then
If entry.FileHash = currentHash AndAlso File.Exists(entry.CachePath) Then
entry.LastAccessed = DateTime.UtcNow
SaveIndex()
Return File.ReadAllText(entry.CachePath)
End If
End If
Return Nothing
End Function
Public Sub CacheResult(fileName As String, fileHash As String, result As String)
Dim cachePath As String = Path.Combine(_cacheFolder, $"{Path.GetFileNameWithoutExtension(fileName)}-{fileHash.Substring(0, 8)}.txt")
File.WriteAllText(cachePath, result)
_index(fileName) = New CacheEntry With {
.FileHash = fileHash,
.CachePath = cachePath,
.CreatedAt = DateTime.UtcNow,
.LastAccessed = DateTime.UtcNow
}
SaveIndex()
End Sub
End Class
Public Class CacheEntry
Public Property FileHash As String = ""
Public Property CachePath As String = ""
Public Property CreatedAt As DateTime
Public Property LastAccessed As DateTime
End ClassO GPT-5 e o Claude Sonnet 4.5, previstos para 2026, também apresentam cache automático de prompts, o que pode reduzir o consumo efetivo de tokens em 50 a 90% para padrões repetidos — uma economia significativa para operações em larga escala.
Casos de uso no mundo real
Descoberta Legal e Análise de Contratos
Tradicionalmente, a descoberta de provas em processos judiciais exigia um verdadeiro exército de advogados juniores que revisavam manualmente centenas de milhares de páginas. A descoberta baseada em IA transforma esse processo, permitindo a identificação rápida de documentos relevantes, a revisão automática de privilégios e a extração de fatos probatórios essenciais.
A integração de IA do IronPDF possibilita fluxos de trabalho jurídicos sofisticados: detecção de privilégios, pontuação de relevância, identificação de problemas e extração de dados importantes. Escritórios de advocacia relatam redução no tempo de revisão de documentos em 70 a 80%, o que lhes permite lidar com casos maiores com equipes menores.
Com a precisão aprimorada e as taxas reduzidas de alucinações do GPT-5 e do Claude Sonnet 4.5 em 2026, os profissionais da área jurídica poderão confiar na análise assistida por IA para decisões cada vez mais críticas.
Análise do Relatório Financeiro
Os analistas financeiros dedicam um tempo enorme à extração de dados de relatórios de resultados, documentos da SEC e apresentações de analistas. O processamento de documentos financeiros com inteligência artificial automatiza essa extração, permitindo que os analistas se concentrem na interpretação em vez da coleta de dados.
Este exemplo processa várias declarações 10-K, usando pdf.Query() com um esquema JSON CompanyFinancials para extrair e comparar receita, margens e fatores de risco entre empresas.
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/financial-sector-analysis.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
using System.Collections.Generic;
using System.Text.Json;
using System.Text;
// Compare financial metrics across multiple company filings for sector analysis
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
// Analyze company filings
string[] companyFilings = {
"filings/company-a-10k.pdf",
"filings/company-b-10k.pdf",
"filings/company-c-10k.pdf"
};
var sectorData = new List<CompanyFinancials>();
foreach (string filing in companyFilings)
{
Console.WriteLine($"Analyzing: {Path.GetFileName(filing)}");
var pdf = PdfDocument.FromFile(filing);
// Define JSON schema for 10-K extraction (numbers in millions USD)
string extractionQuery = @"Extract key financial metrics from this 10-K filing. Return JSON:
mpanyName"": ""string"",
scalYear"": ""string"",
venue"": number,
venueGrowth"": number,
ossMargin"": number,
eratingMargin"": number,
tIncome"": number,
s"": number,
talDebt"": number,
shPosition"": number,
ployeeCount"": number,
yRisks"": [""string""],
idance"": ""string""
in millions USD. Growth/margins as percentages.
NLY valid JSON.";
string result = await pdf.Query(extractionQuery);
try
{
var financials = JsonSerializer.Deserialize<CompanyFinancials>(result);
if (financials != null)
sectorData.Add(financials);
}
catch
{
Console.WriteLine($" Warning: Could not parse financials for {filing}");
}
}
// Generate sector comparison report
var report = new StringBuilder();
report.AppendLine("=== Sector Analysis Report ===\n");
report.AppendLine("Revenue Comparison (millions USD):");
foreach (var company in sectorData.OrderByDescending(c => c.Revenue))
report.AppendLine($" {company.CompanyName}: ${company.Revenue:N0} ({company.RevenueGrowth:+0.0;-0.0}% YoY)");
report.AppendLine("\nProfitability Margins:");
foreach (var company in sectorData.OrderByDescending(c => c.OperatingMargin))
report.AppendLine($" {company.CompanyName}: {company.GrossMargin:F1}% gross, {company.OperatingMargin:F1}% operating");
report.AppendLine("\nFinancial Health (Debt vs Cash):");
foreach (var company in sectorData)
{
double netDebt = company.TotalDebt - company.CashPosition;
string status = netDebt < 0 ? "Net Cash" : "Net Debt";
report.AppendLine($" {company.CompanyName}: {status} ${Math.Abs(netDebt):N0}M");
}
string reportText = report.ToString();
Console.WriteLine($"\n{reportText}");
File.WriteAllText("sector-analysis-report.txt", reportText);
// Save full JSON data
string outputJson = JsonSerializer.Serialize(sectorData, new JsonSerializerOptions { WriteIndented = true });
File.WriteAllText("sector-analysis.json", outputJson);
Console.WriteLine("Analysis saved to sector-analysis.json and sector-analysis-report.txt");
s CompanyFinancials
public string CompanyName { get; set; } = "";
public string FiscalYear { get; set; } = "";
public double Revenue { get; set; }
public double RevenueGrowth { get; set; }
public double GrossMargin { get; set; }
public double OperatingMargin { get; set; }
public double NetIncome { get; set; }
public double Eps { get; set; }
public double TotalDebt { get; set; }
public double CashPosition { get; set; }
public int EmployeeCount { get; set; }
public List<string> KeyRisks { get; set; } = new();
public string Guidance { get; set; } = "";Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
Imports System.Collections.Generic
Imports System.Text.Json
Imports System.Text
Imports System.IO
' Compare financial metrics across multiple company filings for sector analysis
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
' Analyze company filings
Dim companyFilings As String() = {
"filings/company-a-10k.pdf",
"filings/company-b-10k.pdf",
"filings/company-c-10k.pdf"
}
Dim sectorData = New List(Of CompanyFinancials)()
For Each filing As String In companyFilings
Console.WriteLine($"Analyzing: {Path.GetFileName(filing)}")
Dim pdf = PdfDocument.FromFile(filing)
' Define JSON schema for 10-K extraction (numbers in millions USD)
Dim extractionQuery As String = "Extract key financial metrics from this 10-K filing. Return JSON:
mpanyName"": ""string"",
scalYear"": ""string"",
venue"": number,
venueGrowth"": number,
ossMargin"": number,
eratingMargin"": number,
tIncome"": number,
s"": number,
talDebt"": number,
shPosition"": number,
ployeeCount"": number,
yRisks"": [""string""],
idance"": ""string""
in millions USD. Growth/margins as percentages.
NLY valid JSON."
Dim result As String = Await pdf.Query(extractionQuery)
Try
Dim financials = JsonSerializer.Deserialize(Of CompanyFinancials)(result)
If financials IsNot Nothing Then
sectorData.Add(financials)
End If
Catch
Console.WriteLine($" Warning: Could not parse financials for {filing}")
End Try
Next
' Generate sector comparison report
Dim report = New StringBuilder()
report.AppendLine("=== Sector Analysis Report ===" & vbCrLf)
report.AppendLine("Revenue Comparison (millions USD):")
For Each company In sectorData.OrderByDescending(Function(c) c.Revenue)
report.AppendLine($" {company.CompanyName}: ${company.Revenue:N0} ({company.RevenueGrowth:+0.0;-0.0}% YoY)")
Next
report.AppendLine(vbCrLf & "Profitability Margins:")
For Each company In sectorData.OrderByDescending(Function(c) c.OperatingMargin)
report.AppendLine($" {company.CompanyName}: {company.GrossMargin:F1}% gross, {company.OperatingMargin:F1}% operating")
Next
report.AppendLine(vbCrLf & "Financial Health (Debt vs Cash):")
For Each company In sectorData
Dim netDebt As Double = company.TotalDebt - company.CashPosition
Dim status As String = If(netDebt < 0, "Net Cash", "Net Debt")
report.AppendLine($" {company.CompanyName}: {status} ${Math.Abs(netDebt):N0}M")
Next
Dim reportText As String = report.ToString()
Console.WriteLine(vbCrLf & reportText)
File.WriteAllText("sector-analysis-report.txt", reportText)
' Save full JSON data
Dim outputJson As String = JsonSerializer.Serialize(sectorData, New JsonSerializerOptions With {.WriteIndented = True})
File.WriteAllText("sector-analysis.json", outputJson)
Console.WriteLine("Analysis saved to sector-analysis.json and sector-analysis-report.txt")
Public Class CompanyFinancials
Public Property CompanyName As String = ""
Public Property FiscalYear As String = ""
Public Property Revenue As Double
Public Property RevenueGrowth As Double
Public Property GrossMargin As Double
Public Property OperatingMargin As Double
Public Property NetIncome As Double
Public Property Eps As Double
Public Property TotalDebt As Double
Public Property CashPosition As Double
Public Property EmployeeCount As Integer
Public Property KeyRisks As List(Of String) = New List(Of String)()
Public Property Guidance As String = ""
End ClassEmpresas de investimento utilizam análises baseadas em inteligência artificial para processar milhares de documentos diariamente, permitindo que os analistas monitorem uma cobertura de mercado mais ampla e respondam mais rapidamente a oportunidades emergentes.
Resumo de Artigo de Pesquisa
A pesquisa acadêmica gera milhões de artigos anualmente. A sumarização com inteligência artificial ajuda os pesquisadores a avaliar rapidamente a relevância dos artigos, compreender as principais conclusões e identificar os artigos que merecem uma leitura detalhada. Um resumo eficaz de pesquisa deve identificar a questão de pesquisa, explicar a metodologia, sintetizar as principais descobertas com as devidas ressalvas e contextualizar os resultados.
Instituições de pesquisa utilizam a sumarização por IA para manter bases de conhecimento institucionais, processando automaticamente novas publicações. Com o raciocínio científico aprimorado do GPT-5 e as capacidades analíticas aperfeiçoadas do Claude Sonnet 4.5 em 2026, a sumarização acadêmica atingirá novos níveis de precisão.
Processamento de Documentos Governamentais
Órgãos governamentais produzem coleções de documentos enormes — regulamentos, comentários públicos, estudos de impacto ambiental, processos judiciais, relatórios de auditoria. O processamento de documentos com inteligência artificial torna as informações governamentais acionáveis por meio de análises de conformidade regulatória, avaliações de impacto ambiental e acompanhamento legislativo.
A análise de comentários públicos apresenta desafios únicos — grandes propostas regulatórias podem receber centenas de milhares de comentários. Os sistemas de IA podem categorizar comentários por tópico, identificar temas comuns, detectar campanhas coordenadas e extrair argumentos substanciais que justifiquem uma resposta da agência.
A geração de modelos de IA de 2026 traz capacidades sem precedentes para o processamento de documentos governamentais, apoiando a transparência democrática e a formulação de políticas informadas.
Resolução de problemas e suporte técnico
Soluções rápidas para erros comuns
- Primeira renderização lenta? Normal. O Chrome inicializa em 2 a 3 segundos e depois acelera.
- Problemas com a nuvem? Use pelo menos o Azure B1 ou recursos equivalentes.
- Recursos ausentes? Defina os caminhos base ou incorpore como base64.
- Elementos ausentes? Adicione um RenderDelay para a execução do JavaScript .
- Problemas de memória? Atualize para a versão mais recente do IronPDF para corrigir problemas de desempenho.
- Problemas com os campos do formulário? Verifique se os nomes são exclusivos e atualize para a versão mais recente.
Obtenha ajuda dos engenheiros que construíram o IronPDF, 24 horas por dia, 7 dias por semana.
A IronPDF oferece suporte técnico 24 horas por dia, 7 dias por semana. Está com dificuldades na conversão de HTML para PDF ou na integração com IA? Contate-nos:
- Guia completo de resolução de problemas
- Estratégias de otimização de desempenho
- Solicitações de suporte de engenharia
- Lista de verificação rápida para resolução de problemas
Próximos passos
Agora que você entende o processamento de PDFs com inteligência artificial, o próximo passo é explorar os recursos mais amplos do IronPDF. O guia de integração da OpenAI oferece uma cobertura mais aprofundada dos padrões de sumarização, consulta e memorização, enquanto o tutorial de extração de texto e imagem mostra como pré-processar PDFs antes da análise por IA. Para fluxos de trabalho de montagem de documentos, aprenda como mesclar e dividir PDFs para processamento em lote.
Quando estiver pronto para ir além dos recursos de IA, o tutorial completo de edição de PDF aborda marcas d'água, cabeçalhos, rodapés, formulários e anotações. Para abordagens alternativas de integração de IA, o tutorial ChatGPT em C# demonstra diferentes padrões. A implantação em produção é abordada no guia de implantação do Azure para WebApps e Functions, e o tutorial de criação de PDFs em C# aborda a geração de PDFs a partir de HTML, URLs e conteúdo bruto.
Pronto para começar? Comece seu teste gratuito de 30 dias para experimentar em produção sem marcas d'água, com licenciamento flexível que se adapta ao crescimento da sua equipe. Para dúvidas sobre integração de IA ou qualquer recurso do IronPDF , nossa equipe de suporte técnico está à disposição para ajudar.
Perguntas frequentes
Quais são os benefícios de usar IA para processamento de PDF em C#?
O processamento de PDFs com inteligência artificial em C# permite recursos avançados, como sumarização de documentos, extração de dados para JSON e criação de sistemas de perguntas e respostas. Isso aumenta a eficiência e a precisão no processamento de grandes volumes de documentos.
Como o IronPDF integra IA para resumir documentos?
O IronPDF integra IA utilizando modelos como GPT-5 e Claude, que podem analisar e resumir documentos, facilitando a obtenção de insights e a compreensão rápida de textos extensos.
Qual é o papel dos padrões RAG no processamento de PDFs com inteligência artificial?
Os padrões RAG (Recuperar e Gerar) são usados no processamento de PDFs com inteligência artificial para melhorar a qualidade da recuperação e geração de informações, permitindo uma análise de documentos mais precisa e contextualizada.
Como extrair dados estruturados de PDFs usando o IronPDF?
O IronPDF permite a extração de dados estruturados de PDFs para formatos como JSON, facilitando a integração e análise de dados em diferentes aplicações e sistemas.
O IronPDF consegue lidar com grandes bibliotecas de documentos usando IA?
Sim, o IronPDF consegue processar grandes bibliotecas de documentos de forma eficiente, utilizando modelos de IA para automatizar tarefas como sumarização e extração de dados, e oferece boa escalabilidade com as integrações do OpenAI e do Azure OpenAI.
Quais modelos de IA são suportados pelo IronPDF para processamento de PDFs?
O IronPDF suporta modelos avançados de IA, como GPT-5 e Claude, que são usados para tarefas como sumarização de documentos e criação de sistemas de perguntas e respostas, aprimorando as capacidades gerais de processamento.
Como o IronPDF facilita a criação de sistemas de perguntas e respostas?
O IronPDF auxilia na construção de sistemas de perguntas e respostas, processando e analisando documentos para extrair informações relevantes, que podem então ser usadas para gerar respostas precisas às consultas dos usuários.
Quais são os principais casos de uso para processamento de PDF com inteligência artificial em C#?
Os principais casos de uso incluem sumarização de documentos, extração de dados estruturados, desenvolvimento de sistemas de perguntas e respostas e processamento de documentos em larga escala utilizando integrações de IA como a OpenAI.
É possível usar o IronPDF com o Azure OpenAI para processamento de documentos?
Sim, o IronPDF pode ser integrado ao Azure OpenAI para aprimorar as tarefas de processamento de documentos, fornecendo soluções escaláveis para resumir, extrair e analisar documentos PDF.
Como o IronPDF aprimora a análise de documentos com IA?
O IronPDF aprimora a análise de documentos utilizando modelos de IA para automatizar e otimizar tarefas como sumarização, extração de dados e recuperação de informações, resultando em um manuseio de documentos mais eficiente e preciso.


Ainda está rolando a tela?
Quer provas rápidas? PM > Install-Package IronPdf
executar um exemplo Veja seu HTML se transformar em um PDF.










