

C# 中的 AI 驅動 PDF 處理:使用 IronPDF 摘要、擷取及分析文件
透過 IronPDF 在 C# 中實現的 AI 驅動 PDF 處理功能,讓 .NET 開發人員能夠直接在現有的 PDF 工作流程上進行文件摘要、結構化資料擷取,以及建置問答系統——利用基於 Microsoft Semantic Kernel 所建構的 IronPdf.Extensions.AI 套件,可與 Azure OpenAI 及 OpenAI 模型無縫整合。 無論您正在開發法律證據開示工具、財務分析流程,還是文件智慧平台,IronPDF 都能處理 PDF 擷取與內容預處理,讓您專注於 AI 邏輯的開發。
TL;DR:快速入門指南
本教學將說明如何在 C# .NET 環境中將 IronPDF 連接到 AI 服務,以實現文件摘要、資料擷取及智慧查詢功能。
- 適用對象:開發文件智能應用程式的 .NET 開發人員——例如法律證據開示系統、財務分析工具、合規審查平台,或任何需要從大量 PDF 文件中提取資訊的應用程式。
- 您將開發的內容:單一文件摘要、基於自訂架構的結構化 JSON 資料擷取、針對文件內容的問答系統、用於長篇文件的 RAG 處理流程,以及跨文件庫的批次 AI 處理工作流程。
- 執行環境:任何具備 Azure OpenAI 或 OpenAI API 金鑰的 .NET 6+ 環境。 此 AI 擴充功能整合了 Microsoft Semantic Kernel,並能自動處理語境視窗管理、分段處理及協調作業。
- 適用情境:當您的應用程式需要對 PDF 進行超越文字擷取的處理時——例如理解合約條款、摘要研究論文、將財務表格擷取為結構化資料,或大規模回答使用者關於文件內容的提問。
- 技術層面的重要性:原始文字擷取會導致文件結構丟失——表格會塌陷、多欄版面會崩壞,且語義關聯性亦不復存在。 IronPDF 透過保留文件結構並管理字元限制,將文件預處理為適合 AI 使用的格式,確保模型能接收乾淨且組織完善的輸入資料。
僅需幾行程式碼即可摘要 PDF 文件:
購買 IronPDF 或註冊 30 天試用版後,請在應用程式啟動時輸入您的授權金鑰。
IronPdf.License.LicenseKey = "KEY";IronPdf.License.LicenseKey = "KEY";Imports IronPdf
IronPdf.License.LicenseKey = "KEY"目錄
AI 與 PDF 的合作契機
為何 PDF 是最大且尚未開發的資料來源
PDF 檔是現代 Enterprise 中結構化商業知識的最大儲存庫之一。Professional 文件——包括合約、財務報表、合規報告、法律摘要及研究論文——主要皆以 PDF 格式儲存。 這些文件包含關鍵的商業智慧:定義義務與責任的合約條款、驅動投資決策的財務指標、確保合規的監管要求,以及指引策略的研究結果。
然而,傳統的 PDF 處理方法一直存在嚴重限制。 基本的文字擷取工具雖能從網頁中提取原始字元,卻會遺失關鍵的上下文脈絡:表格結構會崩解成雜亂的文字、多欄位版面會變得毫無意義,而各區塊之間的語義關聯也隨之消失。
這項突破源自 AI 理解語境與結構的能力。 現代的大型語言模型(LLM)不僅能辨識文字——它們還能理解文件結構、辨識合約條款或財務表格等模式,甚至能從複雜的版面配置中提取意義。 GPT-5 的統一推理系統搭配其即時路由器,以及 Claude Sonnet 4.5 增強的代理能力,兩者相較於早期模型均展現出顯著降低的幻覺率,使其成為 Professional 文件分析的可靠選擇。
大型語言模型如何理解文件結構
大型語言模型為 PDF 分析帶來了先進的自然語言處理能力。 GPT-5 的混合式架構包含多個子模型(主模型、迷你模型、思考模型、奈米模型),並配備即時路由器,能根據任務複雜度動態選擇最佳變體——簡單的問題會路由至處理速度較快的模型,而複雜的推理任務則會調用完整模型。
Claude Opus 4.6 在處理長時間運行的代理任務方面表現尤為出色,其代理團隊能針對分段任務進行直接協調,並具備 100 萬個標記的上下文視窗,可無需分塊處理整個文件庫。
這種語境理解能力使大型語言模型(LLMs)能夠執行需要真正理解的任務。 在分析合約時,LLM不僅能識別包含"終止"一詞的條款,更能理解允許終止的具體條件、相關的通知要求,以及由此產生的責任。 實現此功能的核心技術基礎是驅動現代大型語言模型(LLM)的變壓器架構,其中 GPT-5 的上下文視窗最多可支援 272,000 個輸入標記,而 Claude Sonnet 4.5 的 200,000 標記視窗則能提供全面的文件覆蓋範圍。
IronPDF 的內建 AI 整合
安裝 IronPDF 和 AI 擴充套件
要開始使用 AI 驅動的 PDF 處理功能,需要核心 IronPDF 函式庫、AI 擴充套件以及 Microsoft Semantic Kernel 依賴項。 using NuGet 套件管理員安裝 IronPDF:
PM > Install-Package IronPdf
PM > Install-Package IronPdf.Extensions.AI
PM > Install-Package Microsoft.SemanticKernel
PM > Install-Package Microsoft.SemanticKernel.Plugins.MemoryPM > Install-Package IronPdf
PM > Install-Package IronPdf.Extensions.AI
PM > Install-Package Microsoft.SemanticKernel
PM > Install-Package Microsoft.SemanticKernel.Plugins.Memory這些套件相互配合,共同提供完整的解決方案。 IronPDF 負責處理所有與 PDF 相關的操作——包括文字擷取、頁面渲染及格式轉換——而 AI 擴充套件則透過 Microsoft Semantic Kernel 管理與語言模型的整合。
<NoWarn>$(NoWarn);SKEXP0001;SKEXP0010;SKEXP0050</NoWarn> 以抑制編譯器警告。設定您的 OpenAI/Azure API 金鑰
在使用 AI 功能之前,您需要先設定對 AI 服務供應商的存取權限。 IronPDF 的 AI 擴充功能同時支援 OpenAI 與 Azure OpenAI。 Azure OpenAI 常被 Enterprise 應用程式所青睞,因為它提供增強的安全功能、合規認證,以及將資料保留在特定地理區域的能力。
要設定 Azure OpenAI,您需要從 Azure 入口網站取得您的 Azure 端點 URL、API 金鑰,以及聊天和嵌入模型的部署名稱。
初始化 AI 引擎
IronPDF 的 AI 擴充功能在底層採用了 Microsoft Semantic Kernel。 在使用任何 AI 功能之前,您必須使用您的 Azure OpenAI 憑證初始化核心,並為文件處理配置記憶體儲存空間。
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/configure-azure-credentials.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
// Initialize IronPDF AI with Azure OpenAI credentials
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel with Azure OpenAI
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
// Create memory store for document embeddings
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
// Initialize IronPDF AI
IronDocumentAI.Initialize(kernel, memory);
Console.WriteLine("IronPDF AI initialized successfully with Azure OpenAI");Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
' Initialize IronPDF AI with Azure OpenAI credentials
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel with Azure OpenAI
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
' Create memory store for document embeddings
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
' Initialize IronPDF AI
IronDocumentAI.Initialize(kernel, memory)
Console.WriteLine("IronPDF AI initialized successfully with Azure OpenAI")初始化會建立兩個關鍵元件:
- Kernel:透過 Azure OpenAI 處理聊天語法補全及文字嵌入內容的生成
- 記憶體:用於儲存文件嵌入向量,以支援語義搜尋與檢索操作
只要使用 IronDocumentAI.Initialize() 進行初始化,您便可在整個應用程式中使用 AI 功能。 對於生產環境的應用程式,強烈建議將憑證儲存於環境變數或 Azure Key Vault 中。
IronPDF 如何為 AI 應用情境準備 PDF 檔案
人工智慧驅動的 PDF 處理中最具挑戰性的環節之一,在於將文件預先處理好,以便語言模型能夠有效利用。 儘管 GPT-5 支援多達 272,000 個輸入標記,且 Claude Opus 4.6 現已提供 100 萬標記的上下文視窗,但單份法律合約或財務報告仍可能輕易超過舊版模型的限制。
IronPDF 的 AI 擴充功能透過智慧型文件預處理來處理此複雜性。 當您呼叫 AI 方法時,IronPDF 會先從 PDF 中擷取文字,同時保留結構資訊——識別段落、保留表格結構,並維持各區段之間的關聯性。
對於超過上下文限制的文件,IronPDF 會在語義斷點處實施策略性分塊處理——即文件結構中的自然分隔點,例如章節標題、分頁符或段落邊界。
文件摘要
單一文件摘要
文件摘要功能能將冗長的文件濃縮為易於理解的洞見,從而立即創造價值。 Summarize 方法負責處理整個工作流程:提取文字、將其預處理以供 AI 使用、向語言模型請求摘要,以及儲存結果。
輸入
該程式碼使用 PdfDocument.FromFile() 載入 PDF 檔案,並呼叫 pdf.Summarize() 來產生簡明摘要,最後將結果儲存至文字檔案中。
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/single-document-summary.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
// Summarize a PDF document using IronPDF AI
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
// Load and summarize PDF
var pdf = PdfDocument.FromFile("sample-report.pdf");
string summary = await pdf.Summarize();
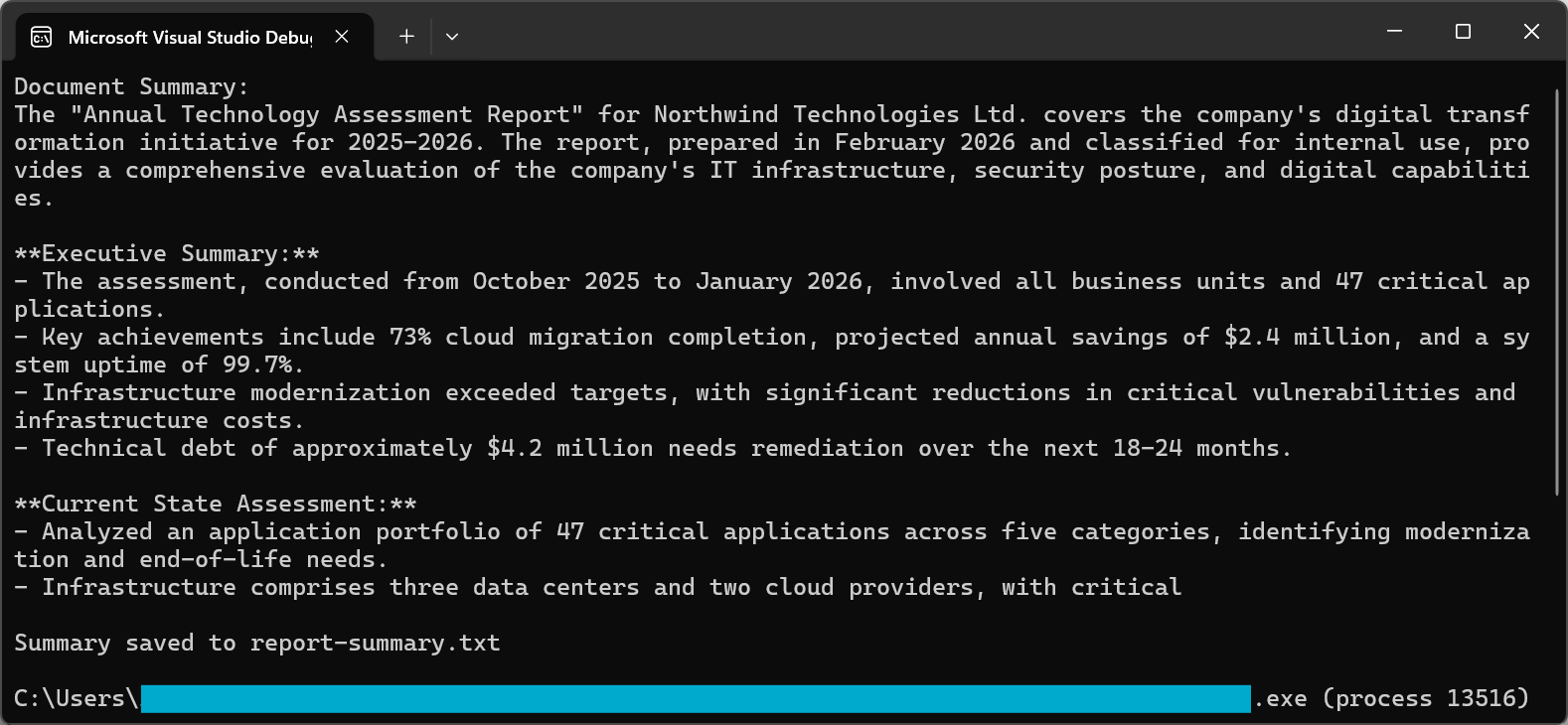
Console.WriteLine("Document Summary:");
Console.WriteLine(summary);
File.WriteAllText("report-summary.txt", summary);
Console.WriteLine("\nSummary saved to report-summary.txt");Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
' Summarize a PDF document using IronPDF AI
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
' Load and summarize PDF
Dim pdf = PdfDocument.FromFile("sample-report.pdf")
Dim summary As String = Await pdf.Summarize()
Console.WriteLine("Document Summary:")
Console.WriteLine(summary)
File.WriteAllText("report-summary.txt", summary)
Console.WriteLine(vbCrLf & "Summary saved to report-summary.txt")主控台輸出
摘要生成過程採用精密的提示機制,以確保產出高品質的結果。 2026 年的 GPT-5 和 Claude Sonnet 4.5 均具備顯著提升的指令遵循能力,確保摘要能精準捕捉關鍵資訊,同時保持簡潔易讀。
如需更詳細的文件摘要技術及進階選項說明,請參閱我們的操作指南。
多文件整合
許多實際應用情境都需要整合來自多個文件中的資訊。 法律團隊可能需要識別合約組合中的常見條款,或財務分析師可能希望比較各季度報告中的指標。
多文件整合的方法是先分別處理每份文件以提取關鍵資訊,再將這些洞察彙整起來進行最終整合。
此範例會遍歷多個 PDF 檔案,對每個檔案呼叫 pdf.Summarize(),然後使用 pdf.Query() 結合這些摘要,以產生一份統整的綜合報告。
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/multi-document-synthesis.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
// Synthesize insights across multiple related documents (e.g., quarterly reports into annual summary)
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
// Define documents to synthesize
string[] documentPaths = {
"Q1-report.pdf",
"Q2-report.pdf",
"Q3-report.pdf",
"Q4-report.pdf"
};
var documentSummaries = new List<string>();
// Summarize each document
foreach (string path in documentPaths)
{
var pdf = PdfDocument.FromFile(path);
string summary = await pdf.Summarize();
documentSummaries.Add($"=== {Path.GetFileName(path)} ===\n{summary}");
Console.WriteLine($"Processed: {path}");
}
// Combine and synthesize across all documents
string combinedSummaries = string.Join("\n\n", documentSummaries);
var synthesisDoc = PdfDocument.FromFile(documentPaths[0]);
string synthesisQuery = @"Based on the quarterly summaries below, provide an annual synthesis:
ll trends across quarters
chievements and challenges
over-year patterns
s:
inedSummaries;
string synthesis = await synthesisDoc.Query(synthesisQuery);
Console.WriteLine("\n=== Annual Synthesis ===");
Console.WriteLine(synthesis);
File.WriteAllText("annual-synthesis.txt", synthesis);Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
Imports System.IO
' Synthesize insights across multiple related documents (e.g., quarterly reports into annual summary)
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
' Define documents to synthesize
Dim documentPaths As String() = {
"Q1-report.pdf",
"Q2-report.pdf",
"Q3-report.pdf",
"Q4-report.pdf"
}
Dim documentSummaries = New List(Of String)()
' Summarize each document
For Each path As String In documentPaths
Dim pdf = PdfDocument.FromFile(path)
Dim summary As String = Await pdf.Summarize()
documentSummaries.Add($"=== {Path.GetFileName(path)} ==={vbCrLf}{summary}")
Console.WriteLine($"Processed: {path}")
Next
' Combine and synthesize across all documents
Dim combinedSummaries As String = String.Join(vbCrLf & vbCrLf, documentSummaries)
Dim synthesisDoc = PdfDocument.FromFile(documentPaths(0))
Dim synthesisQuery As String = "Based on the quarterly summaries below, provide an annual synthesis:" & vbCrLf &
"Overall trends across quarters" & vbCrLf &
"Key achievements and challenges" & vbCrLf &
"Year-over-year patterns" & vbCrLf & vbCrLf &
combinedSummaries
Dim synthesis As String = Await synthesisDoc.Query(synthesisQuery)
Console.WriteLine(vbCrLf & "=== Annual Synthesis ===")
Console.WriteLine(synthesis)
File.WriteAllText("annual-synthesis.txt", synthesis)此模式能有效擴展至大型文件集。 透過並行處理文件並管理中間結果,您可以在保持內容連貫性的同時,分析數百或數千份文件。
執行摘要生成
執行摘要的撰寫方式與標準摘要有所不同。 執行摘要不應僅是內容的濃縮,而應辨識出對業務最關鍵的資訊,突顯關鍵決策或建議,並以適合高層審閱的格式呈現研究結果。
程式碼使用 pdf.Query() 格式,並透過結構化提示以商業用語要求輸入關鍵決策、重要發現、財務影響及風險評估。
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/executive-summary.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
// Generate executive summary from strategic documents for C-suite leadership
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
var pdf = PdfDocument.FromFile("strategic-plan.pdf");
string executiveQuery = @"Create an executive summary for C-suite leadership. Include:
cisions Required:**
ny decisions needing executive approval
al Findings:**
5 most important findings (bullet points)
ial Impact:**
e/cost implications if mentioned
ssessment:**
riority risks identified
ended Actions:**
ate next steps
er 500 words. Use business language appropriate for board presentation.";
string executiveSummary = await pdf.Query(executiveQuery);
File.WriteAllText("executive-summary.txt", executiveSummary);
Console.WriteLine("Executive summary saved to executive-summary.txt");Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
' Generate executive summary from strategic documents for C-suite leadership
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
Dim pdf = PdfDocument.FromFile("strategic-plan.pdf")
Dim executiveQuery As String = "Create an executive summary for C-suite leadership. Include:
cisions Required:**
ny decisions needing executive approval
al Findings:**
5 most important findings (bullet points)
ial Impact:**
e/cost implications if mentioned
ssessment:**
riority risks identified
ended Actions:**
ate next steps
er 500 words. Use business language appropriate for board presentation."
Dim executiveSummary As String = Await pdf.Query(executiveQuery)
File.WriteAllText("executive-summary.txt", executiveSummary)
Console.WriteLine("Executive summary saved to executive-summary.txt")最終產出的執行摘要將可操作性資訊置於全面性涵蓋之上,精準提供決策者所需內容,避免過多冗贅細節。
智慧型資料擷取
將結構化資料擷取為 JSON
人工智慧驅動的 PDF 處理技術最強大的應用之一,便是從非結構化文件中提取結構化資料。 在 2026 年,成功進行結構化擷取的關鍵在於使用 JSON 模式並搭配結構化輸出模式。 GPT-5 引入了改良的結構化輸出功能,而 Claude Sonnet 4.5 則提供了增強的工具協調功能,以實現可靠的数据提取。
輸入
程式碼會透過 JSON 模式提示呼叫 pdf.Query(),接著使用 JsonSerializer.Deserialize() 來解析並驗證擷取的發票資料。
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/extract-invoice-json.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
using System.Text.Json;
// Extract structured invoice data as JSON from PDF
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
var pdf = PdfDocument.FromFile("sample-invoice.pdf");
// Define JSON schema for extraction
string extractionQuery = @"Extract invoice data and return as JSON with this exact structure:
voiceNumber"": ""string"",
voiceDate"": ""YYYY-MM-DD"",
eDate"": ""YYYY-MM-DD"",
ndor"": {
""name"": ""string"",
""address"": ""string"",
""taxId"": ""string or null""
stomer"": {
""name"": ""string"",
""address"": ""string""
neItems"": [
{
""description"": ""string"",
""quantity"": number,
""unitPrice"": number,
""total"": number
}
btotal"": number,
xRate"": number,
xAmount"": number,
tal"": number,
rrency"": ""string""
NLY valid JSON, no additional text.";
string jsonResponse = await pdf.Query(extractionQuery);
// Parse and save JSON
try
{
var invoiceData = JsonSerializer.Deserialize<JsonElement>(jsonResponse);
string formattedJson = JsonSerializer.Serialize(invoiceData, new JsonSerializerOptions { WriteIndented = true });
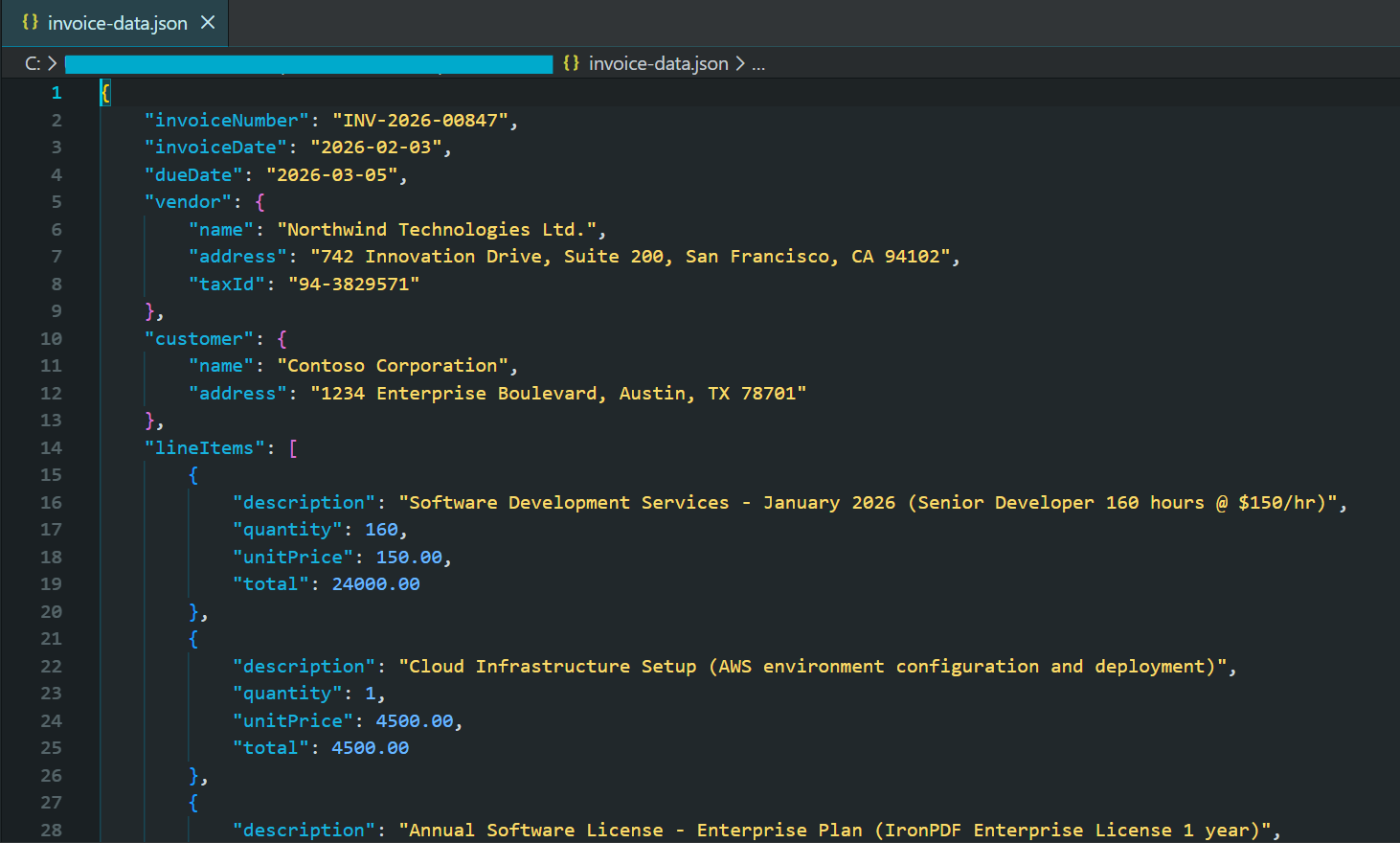
Console.WriteLine("Extracted Invoice Data:");
Console.WriteLine(formattedJson);
File.WriteAllText("invoice-data.json", formattedJson);
}
catch (JsonException)
{
Console.WriteLine("Unable to parse JSON response");
File.WriteAllText("invoice-raw-response.txt", jsonResponse);
}Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
Imports System.Text.Json
' Extract structured invoice data as JSON from PDF
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
Dim pdf = PdfDocument.FromFile("sample-invoice.pdf")
' Define JSON schema for extraction
Dim extractionQuery As String = "Extract invoice data and return as JSON with this exact structure:
voiceNumber"": ""string"",
voiceDate"": ""YYYY-MM-DD"",
eDate"": ""YYYY-MM-DD"",
ndor"": {
""name"": ""string"",
""address"": ""string"",
""taxId"": ""string or null""
stomer"": {
""name"": ""string"",
""address"": ""string""
neItems"": [
{
""description"": ""string"",
""quantity"": number,
""unitPrice"": number,
""total"": number
}
btotal"": number,
xRate"": number,
xAmount"": number,
tal"": number,
rrency"": ""string""
NLY valid JSON, no additional text."
Dim jsonResponse As String = Await pdf.QueryAsync(extractionQuery)
' Parse and save JSON
Try
Dim invoiceData = JsonSerializer.Deserialize(Of JsonElement)(jsonResponse)
Dim formattedJson As String = JsonSerializer.Serialize(invoiceData, New JsonSerializerOptions With {.WriteIndented = True})
Console.WriteLine("Extracted Invoice Data:")
Console.WriteLine(formattedJson)
File.WriteAllText("invoice-data.json", formattedJson)
Catch ex As JsonException
Console.WriteLine("Unable to parse JSON response")
File.WriteAllText("invoice-raw-response.txt", jsonResponse)
End Try生成的 JSON 檔案部分截圖
2026 年的現代 AI 模型支援結構化輸出模式,可確保產生符合指定架構的有效 JSON 回應。 這消除了針對格式錯誤回應進行複雜錯誤處理的必要性。
合約條款識別
法律合約包含若干特別重要的條款類型:終止條款、責任限制、賠償要求、智慧財產權轉讓,以及保密義務。 由 AI 驅動的子句識別功能可自動化此分析,同時維持高準確度。
此範例使用 pdf.Query() 搭配以條款為核心的 JSON 架構,用以擷取合約類型、合約方、關鍵日期,以及附有風險等級的個別條款。
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/contract-clause-analysis.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
using System.Text.Json;
// Analyze contract clauses and identify key terms, risks, and critical dates
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
var pdf = PdfDocument.FromFile("contract.pdf");
// Define JSON schema for contract analysis
string clauseQuery = @"Analyze this contract and identify key clauses. Return JSON:
ntractType"": ""string"",
rties"": [""string""],
fectiveDate"": ""string"",
auses"": [
{
""type"": ""Termination|Liability|Indemnification|Confidentiality|IP|Payment|Warranty|Other"",
""title"": ""string"",
""summary"": ""string"",
""riskLevel"": ""Low|Medium|High"",
""keyTerms"": [""string""]
}
iticalDates"": [
{
""description"": ""string"",
""date"": ""string""
}
erallRiskAssessment"": ""Low|Medium|High"",
commendations"": [""string""]
: termination rights, liability caps, indemnification, IP ownership, confidentiality, payment terms.
NLY valid JSON.";
string analysisJson = await pdf.Query(clauseQuery);
try
{
var analysis = JsonSerializer.Deserialize<JsonElement>(analysisJson);
string formatted = JsonSerializer.Serialize(analysis, new JsonSerializerOptions { WriteIndented = true });
Console.WriteLine("Contract Clause Analysis:");
Console.WriteLine(formatted);
File.WriteAllText("contract-analysis.json", formatted);
// Display high-risk clauses
Console.WriteLine("\n=== High Risk Clauses ===");
foreach (var clause in analysis.GetProperty("clauses").EnumerateArray())
{
if (clause.GetProperty("riskLevel").GetString() == "High")
{
Console.WriteLine($"- {clause.GetProperty("type")}: {clause.GetProperty("summary")}");
}
}
}
catch (JsonException)
{
Console.WriteLine("Unable to parse contract analysis");
File.WriteAllText("contract-analysis-raw.txt", analysisJson);
}Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
Imports System.Text.Json
' Analyze contract clauses and identify key terms, risks, and critical dates
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
Dim pdf = PdfDocument.FromFile("contract.pdf")
' Define JSON schema for contract analysis
Dim clauseQuery As String = "Analyze this contract and identify key clauses. Return JSON:
ntractType"": ""string"",
rties"": [""string""],
fectiveDate"": ""string"",
auses"": [
{
""type"": ""Termination|Liability|Indemnification|Confidentiality|IP|Payment|Warranty|Other"",
""title"": ""string"",
""summary"": ""string"",
""riskLevel"": ""Low|Medium|High"",
""keyTerms"": [""string""]
}
iticalDates"": [
{
""description"": ""string"",
""date"": ""string""
}
erallRiskAssessment"": ""Low|Medium|High"",
commendations"": [""string""]
: termination rights, liability caps, indemnification, IP ownership, confidentiality, payment terms.
NLY valid JSON."
Dim analysisJson As String = Await pdf.Query(clauseQuery)
Try
Dim analysis = JsonSerializer.Deserialize(Of JsonElement)(analysisJson)
Dim formatted As String = JsonSerializer.Serialize(analysis, New JsonSerializerOptions With {.WriteIndented = True})
Console.WriteLine("Contract Clause Analysis:")
Console.WriteLine(formatted)
File.WriteAllText("contract-analysis.json", formatted)
' Display high-risk clauses
Console.WriteLine(vbCrLf & "=== High Risk Clauses ===")
For Each clause In analysis.GetProperty("clauses").EnumerateArray()
If clause.GetProperty("riskLevel").GetString() = "High" Then
Console.WriteLine($"- {clause.GetProperty("type")}: {clause.GetProperty("summary")}")
End If
Next
Catch ex As JsonException
Console.WriteLine("Unable to parse contract analysis")
File.WriteAllText("contract-analysis-raw.txt", analysisJson)
End Try此功能將合約審閱從循序漸進的手動流程,轉變為自動化且可擴展的工作流程。 法務團隊能夠迅速在數百份合約中識別出高風險條款。
財務資料解析
財務文件包含嵌入於複雜敘述與表格中的關鍵定量數據。 AI 驅動的解析技術在處理財務文件方面表現出色,因為它能理解上下文——區分歷史結果與未來預測、辨識數字單位是千還是百萬,並理解不同指標之間的關聯性。
程式碼使用 pdf.Query() 搭配財務 JSON 架構,將損益表資料、資產負債表指標及前瞻指引擷取為結構化輸出。
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/financial-data-extraction.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
using System.Text.Json;
// Extract financial metrics from annual reports and earnings documents
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
var pdf = PdfDocument.FromFile("annual-report.pdf");
// Define JSON schema for financial extraction (numbers in millions)
string financialQuery = @"Extract financial metrics from this document. Return JSON:
portPeriod"": ""string"",
mpany"": ""string"",
rrency"": ""string"",
comeStatement"": {
""revenue"": number,
""costOfRevenue"": number,
""grossProfit"": number,
""operatingExpenses"": number,
""operatingIncome"": number,
""netIncome"": number,
""eps"": number
lanceSheet"": {
""totalAssets"": number,
""totalLiabilities"": number,
""shareholdersEquity"": number,
""cash"": number,
""totalDebt"": number
yMetrics"": {
""revenueGrowthYoY"": ""string"",
""grossMargin"": ""string"",
""operatingMargin"": ""string"",
""netMargin"": ""string"",
""debtToEquity"": number
idance"": {
""nextQuarterRevenue"": ""string"",
""fullYearRevenue"": ""string"",
""notes"": ""string""
for unavailable data. Numbers in millions unless stated.
NLY valid JSON.";
string financialJson = await pdf.Query(financialQuery);
try
{
var financials = JsonSerializer.Deserialize<JsonElement>(financialJson);
string formatted = JsonSerializer.Serialize(financials, new JsonSerializerOptions { WriteIndented = true });
Console.WriteLine("Extracted Financial Data:");
Console.WriteLine(formatted);
File.WriteAllText("financial-data.json", formatted);
}
catch (JsonException)
{
Console.WriteLine("Unable to parse financial data");
File.WriteAllText("financial-raw.txt", financialJson);
}Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
Imports System.Text.Json
' Extract financial metrics from annual reports and earnings documents
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
Dim pdf = PdfDocument.FromFile("annual-report.pdf")
' Define JSON schema for financial extraction (numbers in millions)
Dim financialQuery As String = "Extract financial metrics from this document. Return JSON:
portPeriod"": ""string"",
mpany"": ""string"",
rrency"": ""string"",
comeStatement"": {
""revenue"": number,
""costOfRevenue"": number,
""grossProfit"": number,
""operatingExpenses"": number,
""operatingIncome"": number,
""netIncome"": number,
""eps"": number
lanceSheet"": {
""totalAssets"": number,
""totalLiabilities"": number,
""shareholdersEquity"": number,
""cash"": number,
""totalDebt"": number
yMetrics"": {
""revenueGrowthYoY"": ""string"",
""grossMargin"": ""string"",
""operatingMargin"": ""string"",
""netMargin"": ""string"",
""debtToEquity"": number
idance"": {
""nextQuarterRevenue"": ""string"",
""fullYearRevenue"": ""string"",
""notes"": ""string""
for unavailable data. Numbers in millions unless stated.
NLY valid JSON."
Dim financialJson As String = Await pdf.Query(financialQuery)
Try
Dim financials = JsonSerializer.Deserialize(Of JsonElement)(financialJson)
Dim formatted As String = JsonSerializer.Serialize(financials, New JsonSerializerOptions With {.WriteIndented = True})
Console.WriteLine("Extracted Financial Data:")
Console.WriteLine(formatted)
File.WriteAllText("financial-data.json", formatted)
Catch ex As JsonException
Console.WriteLine("Unable to parse financial data")
File.WriteAllText("financial-raw.txt", financialJson)
End Try擷取的結構化資料可直接導入財務模型、時間序列資料庫或分析平台,從而實現跨報告期間的指標自動追蹤。
自訂提取提示
許多組織會根據其特定領域、文件格式或業務流程,而有獨特的資料擷取需求。 IronPDF 的 AI 整合功能完全支援自訂擷取提示,讓您能精確定義應擷取哪些資訊,以及其結構應如何呈現。
此範例展示 pdf.Query(),內容包含以研究為導向的模式萃取方法論、附有信賴水準的關鍵發現,以及學術論文中的限制性說明。
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/custom-research-extraction.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
using System.Text.Json;
// Extract structured research metadata from academic papers
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
var pdf = PdfDocument.FromFile("research-paper.pdf");
// Define JSON schema for research paper extraction
string researchQuery = @"Extract structured information from this research paper. Return JSON:
tle"": ""string"",
thors"": [""string""],
stitution"": ""string"",
blicationDate"": ""string"",
stract"": ""string"",
searchQuestion"": ""string"",
thodology"": {
""type"": ""Quantitative|Qualitative|Mixed Methods"",
""approach"": ""string"",
""sampleSize"": ""string"",
""dataCollection"": ""string""
yFindings"": [
{
""finding"": ""string"",
""significance"": ""string"",
""confidence"": ""High|Medium|Low""
}
mitations"": [""string""],
tureWork"": [""string""],
ywords"": [""string""]
extracting verifiable claims and noting uncertainty.
NLY valid JSON.";
string extractionResult = await pdf.Query(researchQuery);
try
{
var research = JsonSerializer.Deserialize<JsonElement>(extractionResult);
string formatted = JsonSerializer.Serialize(research, new JsonSerializerOptions { WriteIndented = true });
Console.WriteLine("Research Paper Extraction:");
Console.WriteLine(formatted);
File.WriteAllText("research-extraction.json", formatted);
// Display key findings with confidence levels
Console.WriteLine("\n=== Key Findings ===");
foreach (var finding in research.GetProperty("keyFindings").EnumerateArray())
{
string confidence = finding.GetProperty("confidence").GetString() ?? "Unknown";
Console.WriteLine($"[{confidence}] {finding.GetProperty("finding")}");
}
}
catch (JsonException)
{
Console.WriteLine("Unable to parse research extraction");
File.WriteAllText("research-raw.txt", extractionResult);
}Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
Imports System.Text.Json
' Extract structured research metadata from academic papers
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
Dim pdf = PdfDocument.FromFile("research-paper.pdf")
' Define JSON schema for research paper extraction
Dim researchQuery As String = "Extract structured information from this research paper. Return JSON:
tle"": ""string"",
thors"": [""string""],
stitution"": ""string"",
blicationDate"": ""string"",
stract"": ""string"",
searchQuestion"": ""string"",
thodology"": {
""type"": ""Quantitative|Qualitative|Mixed Methods"",
""approach"": ""string"",
""sampleSize"": ""string"",
""dataCollection"": ""string""
yFindings"": [
{
""finding"": ""string"",
""significance"": ""string"",
""confidence"": ""High|Medium|Low""
}
mitations"": [""string""],
tureWork"": [""string""],
ywords"": [""string""]
extracting verifiable claims and noting uncertainty.
NLY valid JSON."
Dim extractionResult As String = Await pdf.Query(researchQuery)
Try
Dim research = JsonSerializer.Deserialize(Of JsonElement)(extractionResult)
Dim formatted As String = JsonSerializer.Serialize(research, New JsonSerializerOptions With {.WriteIndented = True})
Console.WriteLine("Research Paper Extraction:")
Console.WriteLine(formatted)
File.WriteAllText("research-extraction.json", formatted)
' Display key findings with confidence levels
Console.WriteLine(vbCrLf & "=== Key Findings ===")
For Each finding In research.GetProperty("keyFindings").EnumerateArray()
Dim confidence As String = finding.GetProperty("confidence").GetString() OrElse "Unknown"
Console.WriteLine($"[{confidence}] {finding.GetProperty("finding")}")
Next
Catch ex As JsonException
Console.WriteLine("Unable to parse research extraction")
File.WriteAllText("research-raw.txt", extractionResult)
End Try自訂提示語能將 AI 驅動的資料擷取功能,從通用工具轉化為專為您的特定需求量身打造的專業解決方案。
基於文件的問答系統
建置 PDF 問答系統
問答系統讓使用者能以對話方式與 PDF 文件互動,透過自然語言提問並獲得精準且符合上下文的回答。 基本操作模式為:從 PDF 中擷取文字,將其與使用者的提問結合成提示語,並向 AI 請求答案。
輸入
程式碼呼叫 pdf.Memorize() 為文件建立索引以進行語義搜尋,接著透過 pdf.Query() 進入互動式迴圈,以回應使用者的提問。
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/pdf-question-answering.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
// Interactive Q&A system for querying PDF documents
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
var pdf = PdfDocument.FromFile("sample-legal-document.pdf");
// Memorize document to enable persistent querying
await pdf.Memorize();
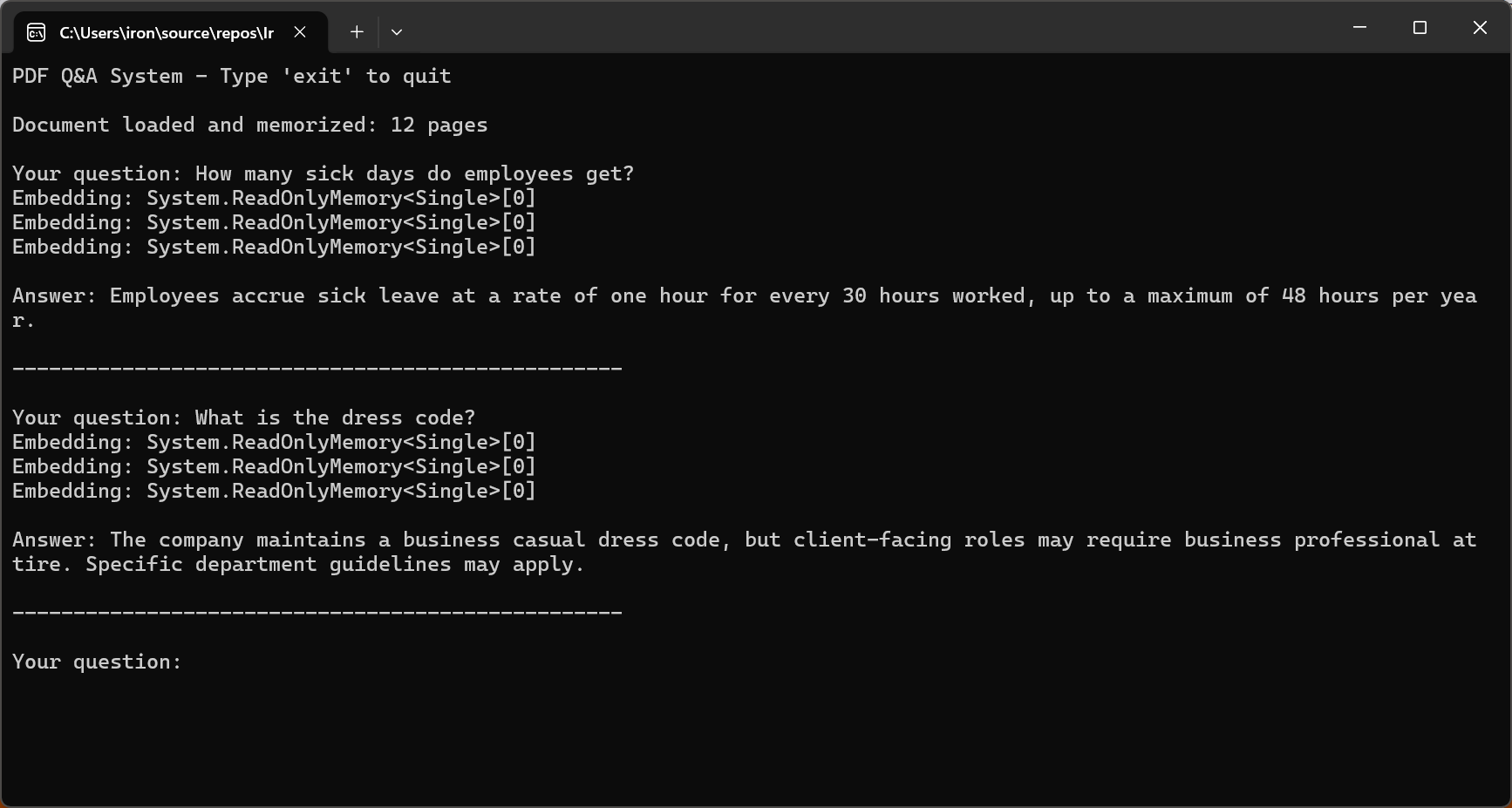
Console.WriteLine("PDF Q&A System - Type 'exit' to quit\n");
Console.WriteLine($"Document loaded and memorized: {pdf.PageCount} pages\n");
// Interactive Q&A loop
while (true)
{
Console.Write("Your question: ");
string? question = Console.ReadLine();
if (string.IsNullOrWhiteSpace(question) || question.ToLower() == "exit")
break;
string answer = await pdf.Query(question);
Console.WriteLine($"\nAnswer: {answer}\n");
Console.WriteLine(new string('-', 50) + "\n");
}
Console.WriteLine("Q&A session ended.");Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
' Interactive Q&A system for querying PDF documents
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
Dim pdf = PdfDocument.FromFile("sample-legal-document.pdf")
' Memorize document to enable persistent querying
Await pdf.Memorize()
Console.WriteLine("PDF Q&A System - Type 'exit' to quit" & vbCrLf)
Console.WriteLine($"Document loaded and memorized: {pdf.PageCount} pages" & vbCrLf)
' Interactive Q&A loop
While True
Console.Write("Your question: ")
Dim question As String = Console.ReadLine()
If String.IsNullOrWhiteSpace(question) OrElse question.ToLower() = "exit" Then
Exit While
End If
Dim answer As String = Await pdf.Query(question)
Console.WriteLine($"{vbCrLf}Answer: {answer}{vbCrLf}")
Console.WriteLine(New String("-"c, 50) & vbCrLf)
End While
Console.WriteLine("Q&A session ended.")主控台輸出
2026 年有效問答的關鍵在於限制 AI 僅能依據文件內容進行回答。 GPT-5 的"安全完成"訓練方法與 Claude Sonnet 4.5 的改良對齊機制,大幅降低了產生錯誤資訊的機率。
將長篇文件分段以建立語境Windows
大多數實際文件的內容長度都超出 AI 的上下文視窗範圍。 有效的分段策略對於處理這些文件至關重要。 分塊處理是指將文件分割成足以容納於語境視窗內的段落,同時保持語義連貫性。
此程式碼會遍歷 pdf.Pages,並建立 DocumentChunk 物件,其 maxChunkTokens 和 overlapTokens 屬性可自訂,以確保上下文的連續性。
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/semantic-document-chunking.csusing IronPdf;
// Split long documents into overlapping chunks for RAG systems
var pdf = PdfDocument.FromFile("long-document.pdf");
// Chunking configuration
int maxChunkTokens = 4000; // Leave room for prompts and responses
int overlapTokens = 200; // Overlap for context continuity
int approxCharsPerToken = 4; // Rough estimate for tokenization
int maxChunkChars = maxChunkTokens * approxCharsPerToken;
int overlapChars = overlapTokens * approxCharsPerToken;
var chunks = new List<DocumentChunk>();
var currentChunk = new System.Text.StringBuilder();
int chunkStartPage = 1;
int currentPage = 1;
for (int i = 0; i < pdf.PageCount; i++)
{
string pageText = pdf.Pages[i].Text;
currentPage = i + 1;
if (currentChunk.Length + pageText.Length > maxChunkChars && currentChunk.Length > 0)
{
chunks.Add(new DocumentChunk
{
Text = currentChunk.ToString(),
StartPage = chunkStartPage,
EndPage = currentPage - 1,
ChunkIndex = chunks.Count
});
// Create overlap with previous chunk for continuity
string overlap = currentChunk.Length > overlapChars
? currentChunk.ToString().Substring(currentChunk.Length - overlapChars)
: currentChunk.ToString();
currentChunk.Clear();
currentChunk.Append(overlap);
chunkStartPage = currentPage - 1;
}
currentChunk.AppendLine($"\n--- Page {currentPage} ---\n");
currentChunk.Append(pageText);
}
if (currentChunk.Length > 0)
{
chunks.Add(new DocumentChunk
{
Text = currentChunk.ToString(),
StartPage = chunkStartPage,
EndPage = currentPage,
ChunkIndex = chunks.Count
});
}
Console.WriteLine($"Document chunked into {chunks.Count} segments");
foreach (var chunk in chunks)
{
Console.WriteLine($" Chunk {chunk.ChunkIndex + 1}: Pages {chunk.StartPage}-{chunk.EndPage} ({chunk.Text.Length} chars)");
}
// Save chunk metadata for RAG indexing
File.WriteAllText("chunks-metadata.json", System.Text.Json.JsonSerializer.Serialize(
chunks.Select(c => new { c.ChunkIndex, c.StartPage, c.EndPage, Length = c.Text.Length }),
new System.Text.Json.JsonSerializerOptions { WriteIndented = true }
));
ic class DocumentChunk
public string Text { get; set; } = "";
public int StartPage { get; set; }
public int EndPage { get; set; }
public int ChunkIndex { get; set; }Imports IronPdf
Imports System.IO
Imports System.Text
Imports System.Text.Json
' Split long documents into overlapping chunks for RAG systems
Dim pdf = PdfDocument.FromFile("long-document.pdf")
' Chunking configuration
Dim maxChunkTokens As Integer = 4000 ' Leave room for prompts and responses
Dim overlapTokens As Integer = 200 ' Overlap for context continuity
Dim approxCharsPerToken As Integer = 4 ' Rough estimate for tokenization
Dim maxChunkChars As Integer = maxChunkTokens * approxCharsPerToken
Dim overlapChars As Integer = overlapTokens * approxCharsPerToken
Dim chunks As New List(Of DocumentChunk)()
Dim currentChunk As New StringBuilder()
Dim chunkStartPage As Integer = 1
Dim currentPage As Integer = 1
For i As Integer = 0 To pdf.PageCount - 1
Dim pageText As String = pdf.Pages(i).Text
currentPage = i + 1
If currentChunk.Length + pageText.Length > maxChunkChars AndAlso currentChunk.Length > 0 Then
chunks.Add(New DocumentChunk With {
.Text = currentChunk.ToString(),
.StartPage = chunkStartPage,
.EndPage = currentPage - 1,
.ChunkIndex = chunks.Count
})
' Create overlap with previous chunk for continuity
Dim overlap As String = If(currentChunk.Length > overlapChars,
currentChunk.ToString().Substring(currentChunk.Length - overlapChars),
currentChunk.ToString())
currentChunk.Clear()
currentChunk.Append(overlap)
chunkStartPage = currentPage - 1
End If
currentChunk.AppendLine(vbCrLf & "--- Page " & currentPage & " ---" & vbCrLf)
currentChunk.Append(pageText)
Next
If currentChunk.Length > 0 Then
chunks.Add(New DocumentChunk With {
.Text = currentChunk.ToString(),
.StartPage = chunkStartPage,
.EndPage = currentPage,
.ChunkIndex = chunks.Count
})
End If
Console.WriteLine($"Document chunked into {chunks.Count} segments")
For Each chunk In chunks
Console.WriteLine($" Chunk {chunk.ChunkIndex + 1}: Pages {chunk.StartPage}-{chunk.EndPage} ({chunk.Text.Length} chars)")
Next
' Save chunk metadata for RAG indexing
File.WriteAllText("chunks-metadata.json", JsonSerializer.Serialize(
chunks.Select(Function(c) New With {.ChunkIndex = c.ChunkIndex, .StartPage = c.StartPage, .EndPage = c.EndPage, .Length = c.Text.Length}),
New JsonSerializerOptions With {.WriteIndented = True}
))
Public Class DocumentChunk
Public Property Text As String = ""
Public Property StartPage As Integer
Public Property EndPage As Integer
Public Property ChunkIndex As Integer
End Class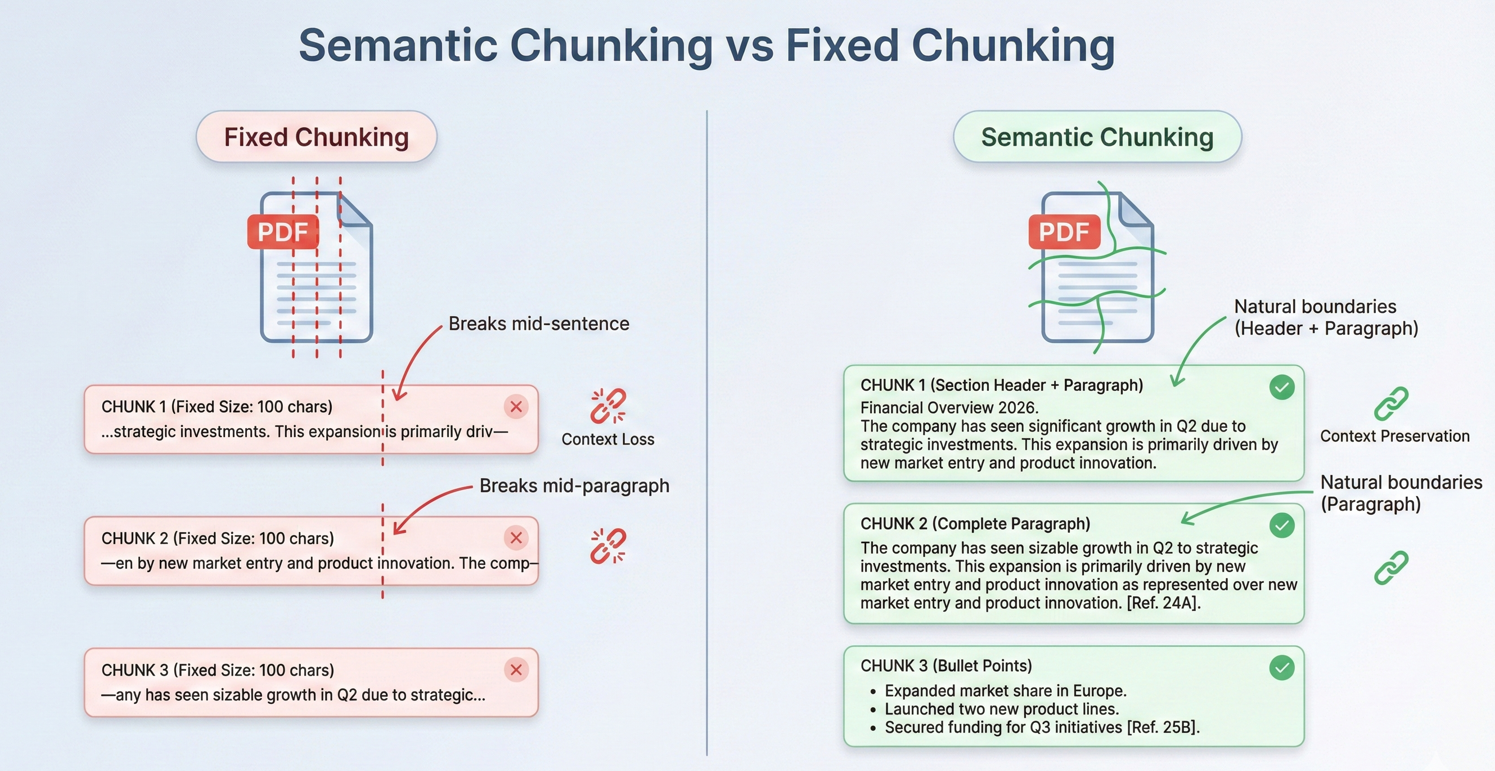
透過區塊重疊來維持跨區塊的連貫性,確保即使相關資訊跨越區塊邊界,AI 仍能獲得足夠的上下文資訊。
RAG(檢索增強生成)模式
檢索增強生成(RAG)是 2026 年人工智慧驅動文件分析的一種強大模式。RAG 系統並非將整份文件餵入人工智慧,而是先針對特定查詢檢索相關段落,再利用這些段落作為上下文來生成答案。
RAG 工作流程包含三個主要階段:文件準備(分塊與建立嵌入向量)、檢索(搜尋相關片段),以及生成(將檢索到的片段作為 AI 回應的上下文)。
程式碼透過在每個 PDF 檔案上呼叫 pdf.Memorize() 來建立多個 PDF 索引,接著使用 pdf.Query() 從合併的文件記憶體中擷取答案。
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/rag-system-implementation.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
// Retrieval-Augmented Generation (RAG) system for querying across multiple indexed documents
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
// Index all documents in folder
string[] documentPaths = Directory.GetFiles("documents/", "*.pdf");
Console.WriteLine($"Indexing {documentPaths.Length} documents...\n");
// Memorize each document (creates embeddings for retrieval)
foreach (string path in documentPaths)
{
var pdf = PdfDocument.FromFile(path);
await pdf.Memorize();
Console.WriteLine($"Indexed: {Path.GetFileName(path)} ({pdf.PageCount} pages)");
}
Console.WriteLine("\n=== RAG System Ready ===\n");
// Query across all indexed documents
string query = "What are the key compliance requirements for data retention?";
Console.WriteLine($"Query: {query}\n");
var searchPdf = PdfDocument.FromFile(documentPaths[0]);
string answer = await searchPdf.Query(query);
Console.WriteLine($"Answer: {answer}");
// Interactive query loop
Console.WriteLine("\n--- Enter questions (type 'exit' to quit) ---\n");
while (true)
{
Console.Write("Question: ");
string? userQuery = Console.ReadLine();
if (string.IsNullOrWhiteSpace(userQuery) || userQuery.ToLower() == "exit")
break;
string response = await searchPdf.Query(userQuery);
Console.WriteLine($"\nAnswer: {response}\n");
}Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
Imports System.IO
' Retrieval-Augmented Generation (RAG) system for querying across multiple indexed documents
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
' Index all documents in folder
Dim documentPaths As String() = Directory.GetFiles("documents/", "*.pdf")
Console.WriteLine($"Indexing {documentPaths.Length} documents..." & vbCrLf)
' Memorize each document (creates embeddings for retrieval)
For Each path As String In documentPaths
Dim pdf = PdfDocument.FromFile(path)
Await pdf.Memorize()
Console.WriteLine($"Indexed: {Path.GetFileName(path)} ({pdf.PageCount} pages)")
Next
Console.WriteLine(vbCrLf & "=== RAG System Ready ===" & vbCrLf)
' Query across all indexed documents
Dim query As String = "What are the key compliance requirements for data retention?"
Console.WriteLine($"Query: {query}" & vbCrLf)
Dim searchPdf = PdfDocument.FromFile(documentPaths(0))
Dim answer As String = Await searchPdf.Query(query)
Console.WriteLine($"Answer: {answer}")
' Interactive query loop
Console.WriteLine(vbCrLf & "--- Enter questions (type 'exit' to quit) ---" & vbCrLf)
While True
Console.Write("Question: ")
Dim userQuery As String = Console.ReadLine()
If String.IsNullOrWhiteSpace(userQuery) OrElse userQuery.ToLower() = "exit" Then
Exit While
End If
Dim response As String = Await searchPdf.Query(userQuery)
Console.WriteLine(vbCrLf & $"Answer: {response}" & vbCrLf)
End WhileRAG 系統在處理大型文件集合方面表現出色——例如法律案件資料庫、技術文件庫以及研究檔案庫。 透過僅擷取相關內容,這些工具在維持回應品質的同時,還能擴展至幾乎無限制的文件大小。
引用 PDF 頁面來源
針對專業應用,AI 產出的答案必須能夠被驗證。 引用方法涉及在分塊與檢索過程中,維持關於分塊來源的元資料。 每個區塊不僅儲存文字內容,還包含其來源頁碼、章節標題以及在文件中的位置。
輸入
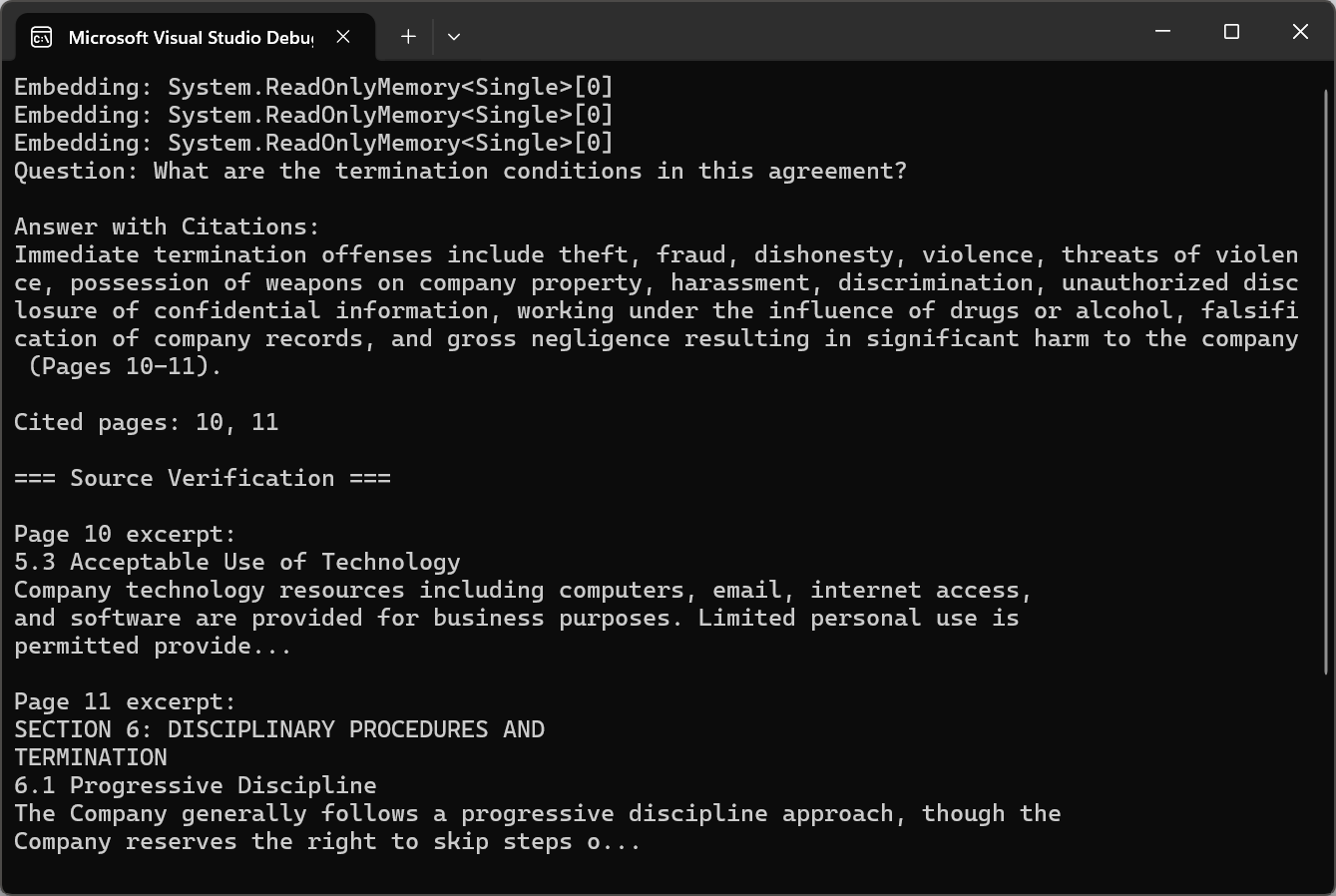
程式碼使用 pdf.Query() 並附上引用說明,接著呼叫 ExtractCitedPages() 透過正規表達式解析頁面參照,並使用 pdf.Pages[pageNum - 1].Text 驗證來源。
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/answer-with-citations.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
using System.Text.RegularExpressions;
// Answer questions with page citations and source verification
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
var pdf = PdfDocument.FromFile("sample-legal-document.pdf");
await pdf.Memorize();
string question = "What are the termination conditions in this agreement?";
// Request citations in query
string citationQuery = $@"{question}
T: Include specific page citations in your answer using the format (Page X) or (Pages X-Y).
e information that appears in the document.";
string answerWithCitations = await pdf.Query(citationQuery);
Console.WriteLine("Question: " + question);
Console.WriteLine("\nAnswer with Citations:");
Console.WriteLine(answerWithCitations);
// Extract cited page numbers using regex
var citedPages = ExtractCitedPages(answerWithCitations);
Console.WriteLine($"\nCited pages: {string.Join(", ", citedPages)}");
// Verify citations with page excerpts
Console.WriteLine("\n=== Source Verification ===");
foreach (int pageNum in citedPages.Take(3))
{
if (pageNum <= pdf.PageCount && pageNum > 0)
{
string pageText = pdf.Pages[pageNum - 1].Text;
string excerpt = pageText.Length > 200 ? pageText.Substring(0, 200) + "..." : pageText;
Console.WriteLine($"\nPage {pageNum} excerpt:\n{excerpt}");
}
}
// Extract page numbers from citation format (Page X) or (Pages X-Y)
List<int> ExtractCitedPages(string text)
{
var pages = new HashSet<int>();
var matches = Regex.Matches(text, @"\(Pages?\s*(\d+)(?:\s*-\s*(\d+))?\)", RegexOptions.IgnoreCase);
foreach (Match match in matches)
{
int startPage = int.Parse(match.Groups[1].Value);
pages.Add(startPage);
if (match.Groups[2].Success)
{
int endPage = int.Parse(match.Groups[2].Value);
for (int p = startPage; p <= endPage; p++)
pages.Add(p);
}
}
return pages.OrderBy(p => p).ToList();
}Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
Imports System.Text.RegularExpressions
' Answer questions with page citations and source verification
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
Dim pdf = PdfDocument.FromFile("sample-legal-document.pdf")
Await pdf.Memorize()
Dim question As String = "What are the termination conditions in this agreement?"
' Request citations in query
Dim citationQuery As String = $"{question}
T: Include specific page citations in your answer using the format (Page X) or (Pages X-Y).
e information that appears in the document."
Dim answerWithCitations As String = Await pdf.Query(citationQuery)
Console.WriteLine("Question: " & question)
Console.WriteLine(vbCrLf & "Answer with Citations:")
Console.WriteLine(answerWithCitations)
' Extract cited page numbers using regex
Dim citedPages = ExtractCitedPages(answerWithCitations)
Console.WriteLine(vbCrLf & "Cited pages: " & String.Join(", ", citedPages))
' Verify citations with page excerpts
Console.WriteLine(vbCrLf & "=== Source Verification ===")
For Each pageNum As Integer In citedPages.Take(3)
If pageNum <= pdf.PageCount AndAlso pageNum > 0 Then
Dim pageText As String = pdf.Pages(pageNum - 1).Text
Dim excerpt As String = If(pageText.Length > 200, pageText.Substring(0, 200) & "...", pageText)
Console.WriteLine(vbCrLf & "Page " & pageNum & " excerpt:" & vbCrLf & excerpt)
End If
Next
' Extract page numbers from citation format (Page X) or (Pages X-Y)
Function ExtractCitedPages(ByVal text As String) As List(Of Integer)
Dim pages = New HashSet(Of Integer)()
Dim matches = Regex.Matches(text, "\((Pages?)\s*(\d+)(?:\s*-\s*(\d+))?\)", RegexOptions.IgnoreCase)
For Each match As Match In matches
Dim startPage As Integer = Integer.Parse(match.Groups(2).Value)
pages.Add(startPage)
If match.Groups(3).Success Then
Dim endPage As Integer = Integer.Parse(match.Groups(3).Value)
For p As Integer = startPage To endPage
pages.Add(p)
Next
End If
Next
Return pages.OrderBy(Function(p) p).ToList()
End Function主控台輸出
引用功能能將 AI 生成的答案,從晦澀難懂的輸出轉化為透明且可驗證的資訊。 使用者可參閱原始資料以驗證答案,並對 AI 輔助分析建立信心。
批次 AI 處理
大規模處理文件庫
Enterprise 文件處理通常涉及數千甚至數百萬份 PDF 檔案。 可擴展批次處理的基礎在於平行化。 IronPDF 具備執行緒安全性,可讓 PDF 處理在無干擾的情況下並行進行。
此程式碼使用 SemaphoreSlim 並搭配可配置的 maxConcurrency 來並行處理 PDF 檔案,在每個檔案上呼叫 pdf.Summarize(),同時透過 ConcurrentBag 追蹤處理結果。
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/batch-document-processing.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
using System;
using System.Collections.Concurrent;
using System.Text;
// Process multiple documents in parallel with rate limiting
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
// Configure parallel processing with rate limiting
int maxConcurrency = 3;
string inputFolder = "documents/";
string outputFolder = "summaries/";
Directory.CreateDirectory(outputFolder);
string[] pdfFiles = Directory.GetFiles(inputFolder, "*.pdf");
Console.WriteLine($"Processing {pdfFiles.Length} documents...\n");
var results = new ConcurrentBag<ProcessingResult>();
var semaphore = new SemaphoreSlim(maxConcurrency);
var tasks = pdfFiles.Select(async filePath =>
{
await semaphore.WaitAsync();
var result = new ProcessingResult { FilePath = filePath };
try
{
var stopwatch = System.Diagnostics.Stopwatch.StartNew();
var pdf = PdfDocument.FromFile(filePath);
string summary = await pdf.Summarize();
string outputPath = Path.Combine(outputFolder,
Path.GetFileNameWithoutExtension(filePath) + "-summary.txt");
await File.WriteAllTextAsync(outputPath, summary);
stopwatch.Stop();
result.Success = true;
result.ProcessingTime = stopwatch.Elapsed;
result.OutputPath = outputPath;
Console.WriteLine($"[OK] {Path.GetFileName(filePath)} ({stopwatch.ElapsedMilliseconds}ms)");
}
catch (Exception ex)
{
result.Success = false;
result.ErrorMessage = ex.Message;
Console.WriteLine($"[ERROR] {Path.GetFileName(filePath)}: {ex.Message}");
}
finally
{
semaphore.Release();
results.Add(result);
}
}).ToArray();
await Task.WhenAll(tasks);
// Generate processing report
var successful = results.Where(r => r.Success).ToList();
var failed = results.Where(r => !r.Success).ToList();
var report = new StringBuilder();
report.AppendLine("=== Batch Processing Report ===");
report.AppendLine($"Successful: {successful.Count}");
report.AppendLine($"Failed: {failed.Count}");
if (successful.Any())
{
var avgTime = TimeSpan.FromMilliseconds(successful.Average(r => r.ProcessingTime.TotalMilliseconds));
report.AppendLine($"Average processing time: {avgTime.TotalSeconds:F1}s");
}
if (failed.Any())
{
report.AppendLine("\nFailed documents:");
foreach (var fail in failed)
report.AppendLine($" - {Path.GetFileName(fail.FilePath)}: {fail.ErrorMessage}");
}
string reportText = report.ToString();
Console.WriteLine($"\n{reportText}");
File.WriteAllText(Path.Combine(outputFolder, "processing-report.txt"), reportText);
s ProcessingResult
public string FilePath { get; set; } = "";
public bool Success { get; set; }
public TimeSpan ProcessingTime { get; set; }
public string OutputPath { get; set; } = "";
public string ErrorMessage { get; set; } = "";Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
Imports System
Imports System.Collections.Concurrent
Imports System.Text
Imports System.IO
Imports System.Linq
Imports System.Threading
Imports System.Threading.Tasks
' Process multiple documents in parallel with rate limiting
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
' Configure parallel processing with rate limiting
Dim maxConcurrency As Integer = 3
Dim inputFolder As String = "documents/"
Dim outputFolder As String = "summaries/"
Directory.CreateDirectory(outputFolder)
Dim pdfFiles As String() = Directory.GetFiles(inputFolder, "*.pdf")
Console.WriteLine($"Processing {pdfFiles.Length} documents...{vbCrLf}")
Dim results = New ConcurrentBag(Of ProcessingResult)()
Dim semaphore = New SemaphoreSlim(maxConcurrency)
Dim tasks = pdfFiles.Select(Async Function(filePath)
Await semaphore.WaitAsync()
Dim result = New ProcessingResult With {.FilePath = filePath}
Try
Dim stopwatch = System.Diagnostics.Stopwatch.StartNew()
Dim pdf = PdfDocument.FromFile(filePath)
Dim summary As String = Await pdf.Summarize()
Dim outputPath = Path.Combine(outputFolder, Path.GetFileNameWithoutExtension(filePath) & "-summary.txt")
Await File.WriteAllTextAsync(outputPath, summary)
stopwatch.Stop()
result.Success = True
result.ProcessingTime = stopwatch.Elapsed
result.OutputPath = outputPath
Console.WriteLine($"[OK] {Path.GetFileName(filePath)} ({stopwatch.ElapsedMilliseconds}ms)")
Catch ex As Exception
result.Success = False
result.ErrorMessage = ex.Message
Console.WriteLine($"[ERROR] {Path.GetFileName(filePath)}: {ex.Message}")
Finally
semaphore.Release()
results.Add(result)
End Try
End Function).ToArray()
Await Task.WhenAll(tasks)
' Generate processing report
Dim successful = results.Where(Function(r) r.Success).ToList()
Dim failed = results.Where(Function(r) Not r.Success).ToList()
Dim report = New StringBuilder()
report.AppendLine("=== Batch Processing Report ===")
report.AppendLine($"Successful: {successful.Count}")
report.AppendLine($"Failed: {failed.Count}")
If successful.Any() Then
Dim avgTime = TimeSpan.FromMilliseconds(successful.Average(Function(r) r.ProcessingTime.TotalMilliseconds))
report.AppendLine($"Average processing time: {avgTime.TotalSeconds:F1}s")
End If
If failed.Any() Then
report.AppendLine($"{vbCrLf}Failed documents:")
For Each fail In failed
report.AppendLine($" - {Path.GetFileName(fail.FilePath)}: {fail.ErrorMessage}")
Next
End If
Dim reportText As String = report.ToString()
Console.WriteLine($"{vbCrLf}{reportText}")
File.WriteAllText(Path.Combine(outputFolder, "processing-report.txt"), reportText)
Public Class ProcessingResult
Public Property FilePath As String = ""
Public Property Success As Boolean
Public Property ProcessingTime As TimeSpan
Public Property OutputPath As String = ""
Public Property ErrorMessage As String = ""
End Class在大型系統中,完善的錯誤處理至關重要。 生產系統採用指數退避的重試邏輯,針對失敗的文件進行獨立的錯誤記錄,並支援可恢復的處理流程。
成本管理與代幣使用
AI API 的費用通常按代幣計費。 2026 年,GPT-5 的定價為每百萬輸入代幣 1.25 美元,每百萬輸出代幣 10 美元;而 Claude Sonnet 4.5 的定價則為每百萬輸入代幣 3 美元,每百萬輸出代幣 15 美元。 主要的成本優化策略是盡量減少不必要的字元使用。
OpenAI 的 Batch API 提供 50% 的代幣費用折扣,但需接受較長的處理時間(最長 24 小時)。 對於夜間處理或定期分析,批次處理能帶來顯著的成本節省。
該程式碼使用 pdf.ExtractAllText() 提取文字,建立 JSONL 批次請求,透過 HttpClient 上傳至 OpenAI 檔案端點,並提交至批次 API。
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/batch-api-processing.csusing IronPdf;
using System.Text.Json;
using System.Net.Http.Headers;
// Use OpenAI Batch API for 50% cost savings on large-scale document processing
string openAiApiKey = "your-openai-api-key";
string inputFolder = "documents/";
// Prepare batch requests in JSONL format
var batchRequests = new List<string>();
string[] pdfFiles = Directory.GetFiles(inputFolder, "*.pdf");
Console.WriteLine($"Preparing batch for {pdfFiles.Length} documents...\n");
foreach (string filePath in pdfFiles)
{
var pdf = PdfDocument.FromFile(filePath);
string pdfText = pdf.ExtractAllText();
// Truncate to stay within batch API limits
if (pdfText.Length > 100000)
pdfText = pdfText.Substring(0, 100000) + "\n[Truncated...]";
var request = new
{
custom_id = Path.GetFileNameWithoutExtension(filePath),
method = "POST",
url = "/v1/chat/completions",
body = new
{
model = "gpt-4o",
messages = new[]
{
new { role = "system", content = "Summarize the following document concisely." },
new { role = "user", content = pdfText }
},
max_tokens = 1000
}
};
batchRequests.Add(JsonSerializer.Serialize(request));
}
// Create JSONL file
string batchFilePath = "batch-requests.jsonl";
File.WriteAllLines(batchFilePath, batchRequests);
Console.WriteLine($"Created batch file with {batchRequests.Count} requests");
// Upload file to OpenAI
using var httpClient = new HttpClient();
httpClient.DefaultRequestHeaders.Authorization = new AuthenticationHeaderValue("Bearer", openAiApiKey);
using var fileContent = new MultipartFormDataContent();
fileContent.Add(new ByteArrayContent(File.ReadAllBytes(batchFilePath)), "file", "batch-requests.jsonl");
fileContent.Add(new StringContent("batch"), "purpose");
var uploadResponse = await httpClient.PostAsync("https://api.openai.com/v1/files", fileContent);
var uploadResult = JsonSerializer.Deserialize<JsonElement>(await uploadResponse.Content.ReadAsStringAsync());
string fileId = uploadResult.GetProperty("id").GetString()!;
Console.WriteLine($"Uploaded file: {fileId}");
// Create batch job (24-hour completion window for 50% discount)
var batchJobRequest = new
{
input_file_id = fileId,
endpoint = "/v1/chat/completions",
completion_window = "24h"
};
var batchResponse = await httpClient.PostAsync(
"https://api.openai.com/v1/batches",
new StringContent(JsonSerializer.Serialize(batchJobRequest), System.Text.Encoding.UTF8, "application/json")
);
var batchResult = JsonSerializer.Deserialize<JsonElement>(await batchResponse.Content.ReadAsStringAsync());
string batchId = batchResult.GetProperty("id").GetString()!;
Console.WriteLine($"\nBatch job created: {batchId}");
Console.WriteLine("Job will complete within 24 hours");
Console.WriteLine($"Check status: GET https://api.openai.com/v1/batches/{batchId}");
File.WriteAllText("batch-job-id.txt", batchId);
Console.WriteLine("\nBatch ID saved to batch-job-id.txt");Imports IronPdf
Imports System.Text.Json
Imports System.Net.Http.Headers
' Use OpenAI Batch API for 50% cost savings on large-scale document processing
Dim openAiApiKey As String = "your-openai-api-key"
Dim inputFolder As String = "documents/"
' Prepare batch requests in JSONL format
Dim batchRequests As New List(Of String)()
Dim pdfFiles As String() = Directory.GetFiles(inputFolder, "*.pdf")
Console.WriteLine($"Preparing batch for {pdfFiles.Length} documents..." & vbCrLf)
For Each filePath As String In pdfFiles
Dim pdf = PdfDocument.FromFile(filePath)
Dim pdfText As String = pdf.ExtractAllText()
' Truncate to stay within batch API limits
If pdfText.Length > 100000 Then
pdfText = pdfText.Substring(0, 100000) & vbCrLf & "[Truncated...]"
End If
Dim request = New With {
.custom_id = Path.GetFileNameWithoutExtension(filePath),
.method = "POST",
.url = "/v1/chat/completions",
.body = New With {
.model = "gpt-4o",
.messages = New Object() {
New With {.role = "system", .content = "Summarize the following document concisely."},
New With {.role = "user", .content = pdfText}
},
.max_tokens = 1000
}
}
batchRequests.Add(JsonSerializer.Serialize(request))
Next
' Create JSONL file
Dim batchFilePath As String = "batch-requests.jsonl"
File.WriteAllLines(batchFilePath, batchRequests)
Console.WriteLine($"Created batch file with {batchRequests.Count} requests")
' Upload file to OpenAI
Using httpClient As New HttpClient()
httpClient.DefaultRequestHeaders.Authorization = New AuthenticationHeaderValue("Bearer", openAiApiKey)
Using fileContent As New MultipartFormDataContent()
fileContent.Add(New ByteArrayContent(File.ReadAllBytes(batchFilePath)), "file", "batch-requests.jsonl")
fileContent.Add(New StringContent("batch"), "purpose")
Dim uploadResponse = Await httpClient.PostAsync("https://api.openai.com/v1/files", fileContent)
Dim uploadResult = JsonSerializer.Deserialize(Of JsonElement)(Await uploadResponse.Content.ReadAsStringAsync())
Dim fileId As String = uploadResult.GetProperty("id").GetString()
Console.WriteLine($"Uploaded file: {fileId}")
' Create batch job (24-hour completion window for 50% discount)
Dim batchJobRequest = New With {
.input_file_id = fileId,
.endpoint = "/v1/chat/completions",
.completion_window = "24h"
}
Dim batchResponse = Await httpClient.PostAsync(
"https://api.openai.com/v1/batches",
New StringContent(JsonSerializer.Serialize(batchJobRequest), System.Text.Encoding.UTF8, "application/json")
)
Dim batchResult = JsonSerializer.Deserialize(Of JsonElement)(Await batchResponse.Content.ReadAsStringAsync())
Dim batchId As String = batchResult.GetProperty("id").GetString()
Console.WriteLine(vbCrLf & $"Batch job created: {batchId}")
Console.WriteLine("Job will complete within 24 hours")
Console.WriteLine($"Check status: GET https://api.openai.com/v1/batches/{batchId}")
File.WriteAllText("batch-job-id.txt", batchId)
Console.WriteLine(vbCrLf & "Batch ID saved to batch-job-id.txt")
End Using
End Using在生產環境中監控代幣使用情況至關重要。 許多組織發現,其 80% 的文件可透過較小、較便宜的模型進行處理,僅將昂貴的模型保留給複雜的案例。
快取與增量處理
對於以增量方式更新的文件集合,智慧型快取與增量處理策略能大幅降低成本。 文件級快取會將結果與原始 PDF 的雜湊值一併儲存,以避免對未變更的文件進行不必要的重複處理。
DocumentCacheManager 類別使用 ComputeFileHash() 搭配 SHA256 來偵測變更,並將結果儲存於帶有 LastAccessed 時間戳記的 CacheEntry 物件中。
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/incremental-caching.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
using System;
using System.Collections.Generic;
using System.Security.Cryptography;
using System.Text.Json;
// Cache AI processing results using file hashes to avoid reprocessing unchanged documents
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
// Configure caching
string cacheFolder = "ai-cache/";
string documentsFolder = "documents/";
Directory.CreateDirectory(cacheFolder);
var cacheManager = new DocumentCacheManager(cacheFolder);
// Process documents with caching
string[] pdfFiles = Directory.GetFiles(documentsFolder, "*.pdf");
int cached = 0, processed = 0;
foreach (string filePath in pdfFiles)
{
string fileName = Path.GetFileName(filePath);
string fileHash = cacheManager.ComputeFileHash(filePath);
var cachedResult = cacheManager.GetCachedResult(fileName, fileHash);
if (cachedResult != null)
{
Console.WriteLine($"[CACHE HIT] {fileName}");
cached++;
continue;
}
Console.WriteLine($"[PROCESSING] {fileName}");
var pdf = PdfDocument.FromFile(filePath);
string summary = await pdf.Summarize();
cacheManager.CacheResult(fileName, fileHash, summary);
processed++;
}
Console.WriteLine($"\nProcessing complete: {cached} cached, {processed} newly processed");
Console.WriteLine($"Cost savings: {(cached * 100.0 / Math.Max(1, cached + processed)):F1}% served from cache");
ash-based cache manager with JSON index
s DocumentCacheManager
private readonly string _cacheFolder;
private readonly string _indexPath;
private Dictionary<string, CacheEntry> _index;
public DocumentCacheManager(string cacheFolder)
{
_cacheFolder = cacheFolder;
_indexPath = Path.Combine(cacheFolder, "cache-index.json");
_index = LoadIndex();
}
private Dictionary<string, CacheEntry> LoadIndex()
{
if (File.Exists(_indexPath))
{
string json = File.ReadAllText(_indexPath);
return JsonSerializer.Deserialize<Dictionary<string, CacheEntry>>(json) ?? new();
}
return new Dictionary<string, CacheEntry>();
}
private void SaveIndex()
{
string json = JsonSerializer.Serialize(_index, new JsonSerializerOptions { WriteIndented = true });
File.WriteAllText(_indexPath, json);
}
// SHA256 hash to detect file changes
public string ComputeFileHash(string filePath)
{
using var sha256 = SHA256.Create();
using var stream = File.OpenRead(filePath);
byte[] hash = sha256.ComputeHash(stream);
return Convert.ToHexString(hash);
}
public string? GetCachedResult(string fileName, string currentHash)
{
if (_index.TryGetValue(fileName, out var entry))
{
if (entry.FileHash == currentHash && File.Exists(entry.CachePath))
{
entry.LastAccessed = DateTime.UtcNow;
SaveIndex();
return File.ReadAllText(entry.CachePath);
}
}
return null;
}
public void CacheResult(string fileName, string fileHash, string result)
{
string cachePath = Path.Combine(_cacheFolder, $"{Path.GetFileNameWithoutExtension(fileName)}-{fileHash[..8]}.txt");
File.WriteAllText(cachePath, result);
_index[fileName] = new CacheEntry
{
FileHash = fileHash,
CachePath = cachePath,
CreatedAt = DateTime.UtcNow,
LastAccessed = DateTime.UtcNow
};
SaveIndex();
}
s CacheEntry
public string FileHash { get; set; } = "";
public string CachePath { get; set; } = "";
public DateTime CreatedAt { get; set; }
public DateTime LastAccessed { get; set; }Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
Imports System
Imports System.Collections.Generic
Imports System.Security.Cryptography
Imports System.Text.Json
' Cache AI processing results using file hashes to avoid reprocessing unchanged documents
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
' Configure caching
Dim cacheFolder As String = "ai-cache/"
Dim documentsFolder As String = "documents/"
Directory.CreateDirectory(cacheFolder)
Dim cacheManager = New DocumentCacheManager(cacheFolder)
' Process documents with caching
Dim pdfFiles As String() = Directory.GetFiles(documentsFolder, "*.pdf")
Dim cached As Integer = 0, processed As Integer = 0
For Each filePath As String In pdfFiles
Dim fileName As String = Path.GetFileName(filePath)
Dim fileHash As String = cacheManager.ComputeFileHash(filePath)
Dim cachedResult As String = cacheManager.GetCachedResult(fileName, fileHash)
If cachedResult IsNot Nothing Then
Console.WriteLine($"[CACHE HIT] {fileName}")
cached += 1
Continue For
End If
Console.WriteLine($"[PROCESSING] {fileName}")
Dim pdf = PdfDocument.FromFile(filePath)
Dim summary As String = Await pdf.Summarize()
cacheManager.CacheResult(fileName, fileHash, summary)
processed += 1
Next
Console.WriteLine(vbCrLf & $"Processing complete: {cached} cached, {processed} newly processed")
Console.WriteLine($"Cost savings: {(cached * 100.0 / Math.Max(1, cached + processed)):F1}% served from cache")
' Hash-based cache manager with JSON index
Public Class DocumentCacheManager
Private ReadOnly _cacheFolder As String
Private ReadOnly _indexPath As String
Private _index As Dictionary(Of String, CacheEntry)
Public Sub New(cacheFolder As String)
_cacheFolder = cacheFolder
_indexPath = Path.Combine(cacheFolder, "cache-index.json")
_index = LoadIndex()
End Sub
Private Function LoadIndex() As Dictionary(Of String, CacheEntry)
If File.Exists(_indexPath) Then
Dim json As String = File.ReadAllText(_indexPath)
Return JsonSerializer.Deserialize(Of Dictionary(Of String, CacheEntry))(json) OrElse New Dictionary(Of String, CacheEntry)()
End If
Return New Dictionary(Of String, CacheEntry)()
End Function
Private Sub SaveIndex()
Dim json As String = JsonSerializer.Serialize(_index, New JsonSerializerOptions With {.WriteIndented = True})
File.WriteAllText(_indexPath, json)
End Sub
' SHA256 hash to detect file changes
Public Function ComputeFileHash(filePath As String) As String
Using sha256 = SHA256.Create()
Using stream = File.OpenRead(filePath)
Dim hash As Byte() = sha256.ComputeHash(stream)
Return Convert.ToHexString(hash)
End Using
End Using
End Function
Public Function GetCachedResult(fileName As String, currentHash As String) As String
If _index.TryGetValue(fileName, entry) Then
If entry.FileHash = currentHash AndAlso File.Exists(entry.CachePath) Then
entry.LastAccessed = DateTime.UtcNow
SaveIndex()
Return File.ReadAllText(entry.CachePath)
End If
End If
Return Nothing
End Function
Public Sub CacheResult(fileName As String, fileHash As String, result As String)
Dim cachePath As String = Path.Combine(_cacheFolder, $"{Path.GetFileNameWithoutExtension(fileName)}-{fileHash.Substring(0, 8)}.txt")
File.WriteAllText(cachePath, result)
_index(fileName) = New CacheEntry With {
.FileHash = fileHash,
.CachePath = cachePath,
.CreatedAt = DateTime.UtcNow,
.LastAccessed = DateTime.UtcNow
}
SaveIndex()
End Sub
End Class
Public Class CacheEntry
Public Property FileHash As String = ""
Public Property CachePath As String = ""
Public Property CreatedAt As DateTime
Public Property LastAccessed As DateTime
End Class2026 年的 GPT-5 和 Claude Sonnet 4.5 還具備自動提示詞快取功能,對於重複出現的模式,可將實際代碼消耗減少 50% 至 90% —— 對於大規模運作而言,這是一項顯著的成本節省。
實際應用案例
法律證據開示與合約分析
傳統上,法律證據開示程序需要大批初級律師手動審閱數十萬頁文件。 由 AI 驅動的檢索功能徹底改變了此流程,能夠快速識別相關文件、自動進行權限審查,並提取關鍵證據事實。
IronPDF 的 AI 整合功能可實現複雜的法律工作流程:特權偵測、相關性評分、爭點識別以及關鍵日期擷取。 多家律師事務所表示,其證據開示審閱時間縮短了 70% 至 80%,使他們能夠以更精簡的團隊處理規模更大的案件。
隨著 GPT-5 和 Claude Sonnet 4.5 在 2026 年精準度提升且幻覺率降低,法律專業人士可更放心地將 AI 輔助分析應用於日益關鍵的決策中。
財務報告分析
財務分析師耗費大量時間從財報、美國證交會(SEC)申報文件及分析師簡報中擷取數據。 由 AI 驅動的財務文件處理技術可自動化此提取流程,讓分析師能專注於資料解讀,而非資料蒐集。
此範例處理多份 10-K 申報文件,使用 pdf.Query() 搭配 CompanyFinancials JSON 架構,以擷取並比較各公司之間的營收、利潤率及風險因素。
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/financial-sector-analysis.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
using System.Collections.Generic;
using System.Text.Json;
using System.Text;
// Compare financial metrics across multiple company filings for sector analysis
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
// Analyze company filings
string[] companyFilings = {
"filings/company-a-10k.pdf",
"filings/company-b-10k.pdf",
"filings/company-c-10k.pdf"
};
var sectorData = new List<CompanyFinancials>();
foreach (string filing in companyFilings)
{
Console.WriteLine($"Analyzing: {Path.GetFileName(filing)}");
var pdf = PdfDocument.FromFile(filing);
// Define JSON schema for 10-K extraction (numbers in millions USD)
string extractionQuery = @"Extract key financial metrics from this 10-K filing. Return JSON:
mpanyName"": ""string"",
scalYear"": ""string"",
venue"": number,
venueGrowth"": number,
ossMargin"": number,
eratingMargin"": number,
tIncome"": number,
s"": number,
talDebt"": number,
shPosition"": number,
ployeeCount"": number,
yRisks"": [""string""],
idance"": ""string""
in millions USD. Growth/margins as percentages.
NLY valid JSON.";
string result = await pdf.Query(extractionQuery);
try
{
var financials = JsonSerializer.Deserialize<CompanyFinancials>(result);
if (financials != null)
sectorData.Add(financials);
}
catch
{
Console.WriteLine($" Warning: Could not parse financials for {filing}");
}
}
// Generate sector comparison report
var report = new StringBuilder();
report.AppendLine("=== Sector Analysis Report ===\n");
report.AppendLine("Revenue Comparison (millions USD):");
foreach (var company in sectorData.OrderByDescending(c => c.Revenue))
report.AppendLine($" {company.CompanyName}: ${company.Revenue:N0} ({company.RevenueGrowth:+0.0;-0.0}% YoY)");
report.AppendLine("\nProfitability Margins:");
foreach (var company in sectorData.OrderByDescending(c => c.OperatingMargin))
report.AppendLine($" {company.CompanyName}: {company.GrossMargin:F1}% gross, {company.OperatingMargin:F1}% operating");
report.AppendLine("\nFinancial Health (Debt vs Cash):");
foreach (var company in sectorData)
{
double netDebt = company.TotalDebt - company.CashPosition;
string status = netDebt < 0 ? "Net Cash" : "Net Debt";
report.AppendLine($" {company.CompanyName}: {status} ${Math.Abs(netDebt):N0}M");
}
string reportText = report.ToString();
Console.WriteLine($"\n{reportText}");
File.WriteAllText("sector-analysis-report.txt", reportText);
// Save full JSON data
string outputJson = JsonSerializer.Serialize(sectorData, new JsonSerializerOptions { WriteIndented = true });
File.WriteAllText("sector-analysis.json", outputJson);
Console.WriteLine("Analysis saved to sector-analysis.json and sector-analysis-report.txt");
s CompanyFinancials
public string CompanyName { get; set; } = "";
public string FiscalYear { get; set; } = "";
public double Revenue { get; set; }
public double RevenueGrowth { get; set; }
public double GrossMargin { get; set; }
public double OperatingMargin { get; set; }
public double NetIncome { get; set; }
public double Eps { get; set; }
public double TotalDebt { get; set; }
public double CashPosition { get; set; }
public int EmployeeCount { get; set; }
public List<string> KeyRisks { get; set; } = new();
public string Guidance { get; set; } = "";Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
Imports System.Collections.Generic
Imports System.Text.Json
Imports System.Text
Imports System.IO
' Compare financial metrics across multiple company filings for sector analysis
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
' Analyze company filings
Dim companyFilings As String() = {
"filings/company-a-10k.pdf",
"filings/company-b-10k.pdf",
"filings/company-c-10k.pdf"
}
Dim sectorData = New List(Of CompanyFinancials)()
For Each filing As String In companyFilings
Console.WriteLine($"Analyzing: {Path.GetFileName(filing)}")
Dim pdf = PdfDocument.FromFile(filing)
' Define JSON schema for 10-K extraction (numbers in millions USD)
Dim extractionQuery As String = "Extract key financial metrics from this 10-K filing. Return JSON:
mpanyName"": ""string"",
scalYear"": ""string"",
venue"": number,
venueGrowth"": number,
ossMargin"": number,
eratingMargin"": number,
tIncome"": number,
s"": number,
talDebt"": number,
shPosition"": number,
ployeeCount"": number,
yRisks"": [""string""],
idance"": ""string""
in millions USD. Growth/margins as percentages.
NLY valid JSON."
Dim result As String = Await pdf.Query(extractionQuery)
Try
Dim financials = JsonSerializer.Deserialize(Of CompanyFinancials)(result)
If financials IsNot Nothing Then
sectorData.Add(financials)
End If
Catch
Console.WriteLine($" Warning: Could not parse financials for {filing}")
End Try
Next
' Generate sector comparison report
Dim report = New StringBuilder()
report.AppendLine("=== Sector Analysis Report ===" & vbCrLf)
report.AppendLine("Revenue Comparison (millions USD):")
For Each company In sectorData.OrderByDescending(Function(c) c.Revenue)
report.AppendLine($" {company.CompanyName}: ${company.Revenue:N0} ({company.RevenueGrowth:+0.0;-0.0}% YoY)")
Next
report.AppendLine(vbCrLf & "Profitability Margins:")
For Each company In sectorData.OrderByDescending(Function(c) c.OperatingMargin)
report.AppendLine($" {company.CompanyName}: {company.GrossMargin:F1}% gross, {company.OperatingMargin:F1}% operating")
Next
report.AppendLine(vbCrLf & "Financial Health (Debt vs Cash):")
For Each company In sectorData
Dim netDebt As Double = company.TotalDebt - company.CashPosition
Dim status As String = If(netDebt < 0, "Net Cash", "Net Debt")
report.AppendLine($" {company.CompanyName}: {status} ${Math.Abs(netDebt):N0}M")
Next
Dim reportText As String = report.ToString()
Console.WriteLine(vbCrLf & reportText)
File.WriteAllText("sector-analysis-report.txt", reportText)
' Save full JSON data
Dim outputJson As String = JsonSerializer.Serialize(sectorData, New JsonSerializerOptions With {.WriteIndented = True})
File.WriteAllText("sector-analysis.json", outputJson)
Console.WriteLine("Analysis saved to sector-analysis.json and sector-analysis-report.txt")
Public Class CompanyFinancials
Public Property CompanyName As String = ""
Public Property FiscalYear As String = ""
Public Property Revenue As Double
Public Property RevenueGrowth As Double
Public Property GrossMargin As Double
Public Property OperatingMargin As Double
Public Property NetIncome As Double
Public Property Eps As Double
Public Property TotalDebt As Double
Public Property CashPosition As Double
Public Property EmployeeCount As Integer
Public Property KeyRisks As List(Of String) = New List(Of String)()
Public Property Guidance As String = ""
End Class投資公司利用人工智慧驅動的分析技術,每日處理數千份文件,使分析師能夠監控更廣泛的市場動態,並更快地對新興機會做出反應。
研究論文摘要
學術研究每年產出數百萬篇論文。 由 AI 驅動的摘要功能,能協助研究人員快速評估論文相關性、理解關鍵發現,並辨識值得深入閱讀的論文。 有效的研究摘要必須釐清研究問題、說明研究方法、在提出適當保留意見的前提下總結關鍵發現,並將結果置於適當的背景脈絡中。
研究機構運用 AI 摘要技術來維護機構知識庫,並自動處理新出版的文獻。 隨著 GPT-5 在 2026 年提升的科學推理能力,以及 Claude Sonnet 4.5 增強的分析能力,學術摘要的準確性已達到全新境界。
政府文件處理
政府機關會產生龐大的文件集合——包括法規、公眾意見、環境影響評估報告、法院文件及稽核報告。 透過 AI 驅動的文件處理技術,政府資訊得以透過法規遵循分析、環境影響評估及立法追蹤等機制,轉化為可執行的行動方案。
公眾意見分析面臨獨特的挑戰——重大監管提案可能收到數十萬條意見。 人工智慧系統能夠依主題分類評論、識別常見主題、偵測協調性活動,並擷取值得相關機構回應的實質論點。
2026 世代的人工智慧模型為政府文件處理帶來前所未有的能力,有助於促進民主透明度與知情決策。
疑難排解與技術支援
常見錯誤的快速修正
- 初次渲染緩慢?這是正常的。 Chrome 初始化需時 2–3 秒,隨後速度會加快。
- 雲端資源不足?請至少使用 Azure B1 或同等規格的資源。
- 資源遺漏?請設定基礎路徑或以 base64 格式嵌入。
- 缺少元素?請加入 RenderDelay 以執行 JavaScript。
- 遇到記憶體問題?請更新至最新版 IronPDF 以獲得效能修正。
- 表單欄位有問題?請確保名稱唯一,並更新至最新版本。
隨時向 IronPDF 的開發工程師尋求協助,全年無休
IronPDF 提供全年無休的工程師技術支援。 在 HTML 轉 PDF 或 AI 整合方面遇到困難嗎? 聯絡我們:
後續步驟
既然您已了解 AI 驅動的 PDF 處理技術,下一步便是探索 IronPDF 的更廣泛功能。 OpenAI 整合指南深入探討摘要生成、查詢及記憶模式,而文字與圖像擷取教學則說明如何在 AI 分析前對 PDF 進行預處理。 關於文件組裝工作流程,請瞭解如何合併與分割 PDF 檔案以進行批次處理。
當您準備探索 AI 功能以外的應用時,完整的 PDF 編輯教學指南涵蓋了浮水印、頁首、頁尾、表單及註解等內容。 關於其他 AI 整合方法,ChatGPT C# 教學指南展示了各種模式。 生產環境部署相關內容請參閱 Azure WebApps 與 Functions 部署指南,而 C# PDF 建立教學則涵蓋從 HTML、URL 及原始內容生成 PDF 的方法。
準備開始了嗎? 立即開始您的 30 天試用,在生產環境中進行測試且無浮水印,並享有可隨團隊規模彈性擴展的授權方案。 若對 AI 整合或任何 IronPDF 功能有疑問,我們的工程支援團隊隨時樂意提供協助。
常見問題
在 C# 中使用 AI 進行 PDF 處理有哪些好處?
透過 C# 實現的 AI 驅動 PDF 處理功能,可提供文件摘要、將資料擷取為 JSON 以及建置問答系統等進階功能。此技術能提升處理大量文件時的效率與準確性。
IronPDF 是如何整合 AI 來進行文件摘要的?
IronPDF 透過整合 GPT-5 和 Claude 等模型來運用人工智慧,這些模型能夠分析並摘要文件,使您更容易從中獲取洞見,並快速理解大量文本。
在 AI 驅動的 PDF 處理中,RAG 模式扮演什麼角色?
在 AI 驅動的 PDF 處理中,採用 RAG(檢索與生成)模式來提升資訊檢索與生成的品質,從而實現更精準且符合語境的文件分析。
如何使用 IronPDF 從 PDF 檔案中擷取結構化資料?
IronPDF 能將 PDF 中的結構化資料擷取為 JSON 等格式,從而促進跨不同應用程式與系統的無縫資料整合與分析。
IronPDF 能否透過 AI 處理大型文件庫?
是的,IronPDF 能透過 AI 模型自動化摘要彙整與資料擷取等任務,高效處理大型文件庫,並能透過與 OpenAI 及 Azure OpenAI 的整合實現良好的擴展性。
IronPDF 支援哪些用於 PDF 處理的 AI 模型?
IronPDF 支援 GPT-5 和 Claude 等先進 AI 模型,這些模型可用於文件摘要和問答系統建置等任務,從而提升整體處理能力。
IronPDF 如何協助建置問答系統?
IronPDF 透過處理與分析文件以提取相關資訊,協助建置問答系統;這些資訊隨後可用於針對使用者查詢產生精準的回應。
在 C# 中,AI 驅動的 PDF 處理主要有哪些應用情境?
主要應用場景包括文件摘要生成、結構化資料擷取、問答系統開發,以及透過 OpenAI 等 AI 整合方案處理大規模文件處理任務。
是否可以將 IronPDF 與 Azure OpenAI 結合使用來處理文件?
是的,IronPDF 可與 Azure OpenAI 整合以強化文件處理任務,為 PDF 文件的摘要、擷取及分析提供可擴展的解決方案。
IronPDF 如何運用 AI 提升文件分析能力?
IronPDF 透過運用 AI 模型來自動化並強化摘要、資料擷取及資訊檢索等任務,從而提升文件分析效能,使文件處理更為高效且精準。


還在往下捲動嗎?
想要快速確認成果嗎? PM > Install-Package IronPdf
執行範例 觀看您的 HTML 轉為 PDF。










