


C# PDF Parser
使用 IronPDF 的 ExtractAllText 方法在 C# 中解析 PDF 檔案,以從整個文件或特定頁面中擷取文字。 此方法僅需幾行程式碼,即可為 .NET 應用程式提供簡單且高效的 PDF 文字擷取功能。
IronPDF 讓在 C# 應用程式中解析 PDF 變得輕而易舉。 本教學將示範如何使用 IronPDF(一個用於 PDF 生成與處理的全面性 C# 函式庫),僅需幾個步驟即可解析 PDF 檔案。
快速入門:使用 IronPDF 高效解析 PDF
使用 IronPDF 透過 C# 以最少的程式碼開始解析 PDF 檔案。 此範例展示如何從 PDF 檔案中擷取所有文字,同時保留原始格式。 IronPDF 的 ExtractAllText 方法可讓 PDF 解析功能無縫整合至 .NET 應用程式中。 請依照以下步驟進行簡易的設定與執行。
簡化工作流程(5 個步驟)
- 下載 C# PDF 解析器函式庫
- 安裝至您的 Visual Studio
- 使用
ExtractAllText方法來擷取每一行文字 - 使用
ExtractTextFromPage方法從單一頁面擷取所有文字 - 檢視已解析的 PDF 內容
如何在 C# 中解析 PDF 檔案?
使用 IronPDF 解析 PDF 檔案非常簡單。 以下程式碼使用 ExtractAllText 方法,從整個 PDF 文件中擷取每一行文字。 此處的比較範例展示了從 PDF 擷取的內容及其輸出結果。 此函式庫亦支援從 PDF 文件的特定區段中擷取文字與圖片。
:path=/static-assets/pdf/content-code-examples/how-to/csharp-parse-pdf-parse-pdf.csusing IronPdf;
// Select the desired PDF File
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract all text from an pdf
string allText = pdf.ExtractAllText();
// Extract all text from page 1
string page1Text = pdf.ExtractTextFromPage(0);Imports IronPdf
' Select the desired PDF File
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract all text from an pdf
Private allText As String = pdf.ExtractAllText()
' Extract all text from page 1
Private page1Text As String = pdf.ExtractTextFromPage(0)IronPDF 簡化了各種情境下的 PDF 解析作業。 無論是進行 HTML 轉 PDF、從現有文件中擷取內容,還是實作進階 PDF 功能,此函式庫皆提供全面支援。
IronPDF 可與 Windows 應用程式無縫整合,並支援在 Linux 和 macOS 平台上部署。 該函式庫亦支援 Azure 部署,以提供雲端解決方案。
進階文字擷取範例
以下是使用 IronPDF 解析 PDF 內容的其他方法:
using IronPdf;
// Parse PDF from URL
var pdfFromUrl = PdfDocument.FromUrl("https://example.com/document.pdf");
string urlPdfText = pdfFromUrl.ExtractAllText();
// Parse password-protected PDFs
var protectedPdf = PdfDocument.FromFile("protected.pdf", "password123");
string protectedText = protectedPdf.ExtractAllText();
// Extract text from specific page range
var largePdf = PdfDocument.FromFile("large-document.pdf");
for (int i = 5; i < 10; i++)
{
string pageText = largePdf.ExtractTextFromPage(i);
Console.WriteLine($"Page {i + 1}: {pageText.Substring(0, 100)}...");
}using IronPdf;
// Parse PDF from URL
var pdfFromUrl = PdfDocument.FromUrl("https://example.com/document.pdf");
string urlPdfText = pdfFromUrl.ExtractAllText();
// Parse password-protected PDFs
var protectedPdf = PdfDocument.FromFile("protected.pdf", "password123");
string protectedText = protectedPdf.ExtractAllText();
// Extract text from specific page range
var largePdf = PdfDocument.FromFile("large-document.pdf");
for (int i = 5; i < 10; i++)
{
string pageText = largePdf.ExtractTextFromPage(i);
Console.WriteLine($"Page {i + 1}: {pageText.Substring(0, 100)}...");
}Imports IronPdf
' Parse PDF from URL
Dim pdfFromUrl = PdfDocument.FromUrl("https://example.com/document.pdf")
Dim urlPdfText As String = pdfFromUrl.ExtractAllText()
' Parse password-protected PDFs
Dim protectedPdf = PdfDocument.FromFile("protected.pdf", "password123")
Dim protectedText As String = protectedPdf.ExtractAllText()
' Extract text from specific page range
Dim largePdf = PdfDocument.FromFile("large-document.pdf")
For i As Integer = 5 To 9
Dim pageText As String = largePdf.ExtractTextFromPage(i)
Console.WriteLine($"Page {i + 1}: {pageText.Substring(0, 100)}...")
Next這些範例展示了 IronPDF 在處理不同 PDF 來源與情境時的靈活性。 若需進行複雜的解析作業,請探索 PDF DOM 物件存取功能,以便處理結構化內容。
處理不同類型的 PDF 檔案
IronPDF 擅長解析各種 PDF 類型:
using IronPdf;
using System.Text.RegularExpressions;
// Parse scanned PDFs with OCR (requires IronOcr)
var scannedPdf = PdfDocument.FromFile("scanned-document.pdf");
string ocrText = scannedPdf.ExtractAllText();
// Parse PDFs with forms
var formPdf = PdfDocument.FromFile("form.pdf");
string formText = formPdf.ExtractAllText();
// Extract and filter specific content
string invoiceText = pdf.ExtractAllText();
var invoiceNumber = Regex.Match(invoiceText, @"Invoice #: (\d+)").Groups[1].Value;
var totalAmount = Regex.Match(invoiceText, @"Total: \$([0-9,]+\.\d{2})").Groups[1].Value;using IronPdf;
using System.Text.RegularExpressions;
// Parse scanned PDFs with OCR (requires IronOcr)
var scannedPdf = PdfDocument.FromFile("scanned-document.pdf");
string ocrText = scannedPdf.ExtractAllText();
// Parse PDFs with forms
var formPdf = PdfDocument.FromFile("form.pdf");
string formText = formPdf.ExtractAllText();
// Extract and filter specific content
string invoiceText = pdf.ExtractAllText();
var invoiceNumber = Regex.Match(invoiceText, @"Invoice #: (\d+)").Groups[1].Value;
var totalAmount = Regex.Match(invoiceText, @"Total: \$([0-9,]+\.\d{2})").Groups[1].Value;Imports IronPdf
Imports System.Text.RegularExpressions
' Parse scanned PDFs with OCR (requires IronOcr)
Dim scannedPdf = PdfDocument.FromFile("scanned-document.pdf")
Dim ocrText As String = scannedPdf.ExtractAllText()
' Parse PDFs with forms
Dim formPdf = PdfDocument.FromFile("form.pdf")
Dim formText As String = formPdf.ExtractAllText()
' Extract and filter specific content
Dim invoiceText As String = pdf.ExtractAllText()
Dim invoiceNumber = Regex.Match(invoiceText, "Invoice #: (\d+)").Groups(1).Value
Dim totalAmount = Regex.Match(invoiceText, "Total: \$([0-9,]+\.\d{2})").Groups(1).Value如何檢視已解析的 PDF 內容?
一個 C# 表單會顯示上述程式碼執行後所解析的 PDF 內容。 此輸出內容提供 PDF 檔案中的精確文字,以滿足文件處理需求。
~ PDF ~
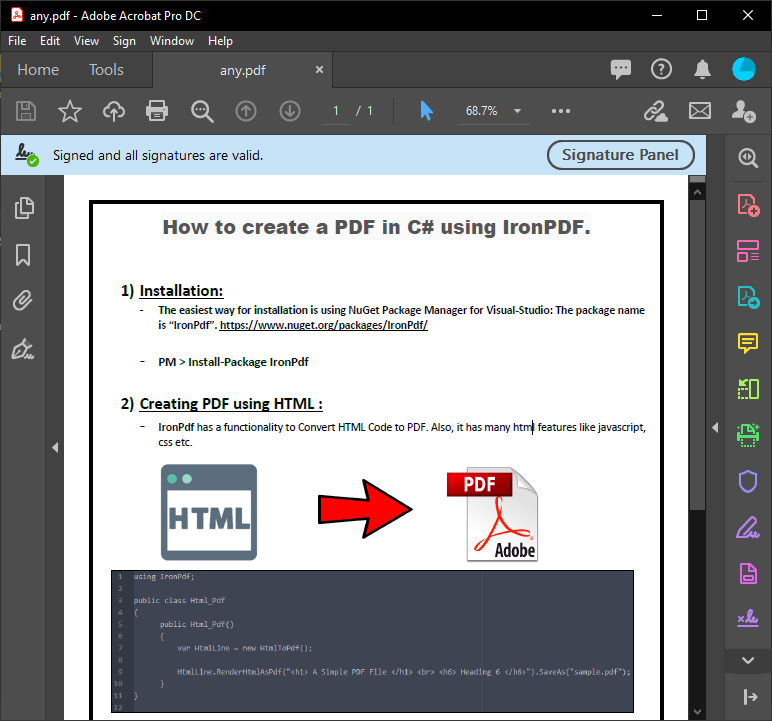
~ C# 表單 ~
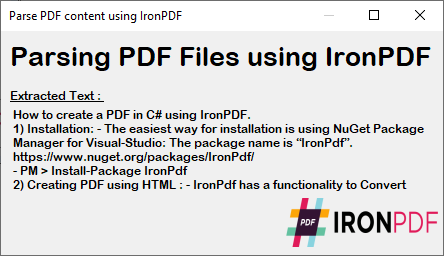
擷取的文字保留了 PDF 原始的格式與結構,使其非常適合用於資料處理、內容分析或資料遷移任務。 可進一步處理此文字,例如尋找並替換特定內容,或將其匯出至其他格式。
將 PDF 解析功能整合至您的應用程式中
IronPDF 的解析功能可整合至各類應用程式中:
// ASP.NET Core example
public IActionResult ParseUploadedPdf(IFormFile pdfFile)
{
using var stream = pdfFile.OpenReadStream();
var pdf = PdfDocument.FromStream(stream);
var extractedText = pdf.ExtractAllText();
// Process or store the extracted text
return Json(new {
success = true,
textLength = extractedText.Length,
preview = extractedText.Substring(0, Math.Min(500, extractedText.Length))
});
}
// Console application example
static void BatchParsePdfs(string folderPath)
{
var pdfFiles = Directory.GetFiles(folderPath, "*.pdf");
foreach (var file in pdfFiles)
{
var pdf = PdfDocument.FromFile(file);
var text = pdf.ExtractAllText();
// Save extracted text
var textFile = Path.ChangeExtension(file, ".txt");
File.WriteAllText(textFile, text);
Console.WriteLine($"Parsed: {Path.GetFileName(file)} - {text.Length} characters");
}
}// ASP.NET Core example
public IActionResult ParseUploadedPdf(IFormFile pdfFile)
{
using var stream = pdfFile.OpenReadStream();
var pdf = PdfDocument.FromStream(stream);
var extractedText = pdf.ExtractAllText();
// Process or store the extracted text
return Json(new {
success = true,
textLength = extractedText.Length,
preview = extractedText.Substring(0, Math.Min(500, extractedText.Length))
});
}
// Console application example
static void BatchParsePdfs(string folderPath)
{
var pdfFiles = Directory.GetFiles(folderPath, "*.pdf");
foreach (var file in pdfFiles)
{
var pdf = PdfDocument.FromFile(file);
var text = pdf.ExtractAllText();
// Save extracted text
var textFile = Path.ChangeExtension(file, ".txt");
File.WriteAllText(textFile, text);
Console.WriteLine($"Parsed: {Path.GetFileName(file)} - {text.Length} characters");
}
}Imports Microsoft.AspNetCore.Mvc
Imports System.IO
' ASP.NET Core example
Public Function ParseUploadedPdf(pdfFile As IFormFile) As IActionResult
Using stream = pdfFile.OpenReadStream()
Dim pdf = PdfDocument.FromStream(stream)
Dim extractedText = pdf.ExtractAllText()
' Process or store the extracted text
Return Json(New With {
.success = True,
.textLength = extractedText.Length,
.preview = extractedText.Substring(0, Math.Min(500, extractedText.Length))
})
End Using
End Function
' Console application example
Private Shared Sub BatchParsePdfs(folderPath As String)
Dim pdfFiles = Directory.GetFiles(folderPath, "*.pdf")
For Each file In pdfFiles
Dim pdf = PdfDocument.FromFile(file)
Dim text = pdf.ExtractAllText()
' Save extracted text
Dim textFile = Path.ChangeExtension(file, ".txt")
File.WriteAllText(textFile, text)
Console.WriteLine($"Parsed: {Path.GetFileName(file)} - {text.Length} characters")
Next
End Sub這些範例展示了 PDF 解析功能如何整合至網頁應用程式及批次處理情境中。 若需進階實作,可探索非同步與多執行緒技術,以提升處理多個 PDF 檔案時的效能。
準備好探索更多可能性了嗎? 請點此查看我們的教學頁面:編輯 PDF
常見問題
如何在 C# 中從 PDF 檔案中擷取所有文字?
您可以使用 IronPDF 的 ExtractAllText 方法從 PDF 檔案中擷取所有文字。只需透過 IronPdf.FromFile("sample.pdf") 載入您的 PDF 檔案,並呼叫 ExtractAllText() 即可擷取所有文字內容,同時保留原始格式。
在 .NET 中解析 PDF 的最簡單方法是什麼?
最簡單的方法是使用 IronPDF,僅需一行程式碼:var text = IronPdf.FromFile("sample.pdf").ExtractAllText()。此方法能從整個 PDF 文件中擷取每一行文字,且僅需最少的設定。
我可以從 PDF 的特定頁面中擷取文字嗎?
是的,IronPDF 提供了 ExtractTextFromPage 方法,用於從單一頁面中擷取文字。這讓您能夠針對 PDF 文件的特定區段進行擷取,而非一次擷取所有內容。
如何在 C# 中解析受密碼保護的 PDF 檔案?
IronPDF 支援解析受密碼保護的 PDF 檔案。請使用 PdfDocument.FromFile("protected.pdf", "password123") 載入受保護的文件,然後呼叫 ExtractAllText() 來擷取文字內容。
我可以從網址解析 PDF 檔案,而不是從本機檔案嗎?
是的,IronPDF 可透過 PdfDocument.FromUrl("https://example.com/document.pdf") 直接從網址解析 PDF 文件。從網址載入 PDF 文件後,請使用 ExtractAllText() 來擷取文字內容。
PDF 解析器支援哪些平台?
IronPDF 支援跨多平台的 PDF 解析功能,涵蓋 Windows 應用程式、Linux、macOS 及 Azure 雲端部署,為您的 .NET 應用程式提供全面的跨平台相容性。
PDF 解析器在擷取過程中會保留文字格式嗎?
是的,IronPDF 的 ExtractAllText 方法在擷取過程中會保留 PDF 內容的原始格式,確保解析出的文字能維持原始文件的結構與版面配置。
我可以從 PDF 檔案中同時擷取文字和圖片嗎?
IronPDF 支援從 PDF 文件中擷取文字與圖片。除了用於文字擷取的 ExtractAllText 方法外,此函式庫還提供額外功能,可從 PDF 文件的特定區段擷取圖片。


還在往下捲動嗎?
想要快速確認成果嗎? PM > Install-Package IronPdf
執行範例 觀看您的 HTML 轉為 PDF。










