


C# PDF Ayrıştırıcı
IronPDF kullanarak C# dilinde PDF dosyalarını çözümleyin ve tüm belgeyi veya belirli sayfaları metin olarak çıkarmak için ExtractAllText metodunu kullanın. Bu yaklaşım, birkaç satır kod ile .NET uygulamaları için basit ve verimli PDF metin çıkarma sağlar.
IronPDF, C# uygulamalarında PDF ayrıştırmayı kolaylaştırır. Bu eğitimde, IronPDF, bir PDF oluşturma ve düzenleme için kapsamlı bir C# kütüphanesi olan PDF oluşturma için birkaç adımda PDF'leri nasıl ayrıştırabileceğiniz gösterilmektedir.
Çabuk Başlangıç: IronPDF ile Verimli PDF Ayrıştırma
Minimal kod ile C#'ta IronPDF kullanarak PDF'leri ayrıştırmaya başlayın. Bu örnek, bir PDF dosyasından tüm metni orijinal formatını koruyarak nasıl çıkaracağınızı gösterir. IronPDF'un ExtractAllText metodu, .NET uygulamalarınıza kesintisiz PDF çözümleme entegrasyonu sağlar. Basit kurulum ve yürütme için bu adımları izleyin.
-
IronPDF aşağıdaki NuGet Paket Yöneticisi ile yükleyin
-
Bu kod parçacığını kopyalayın ve çalıştırın.
var text = IronPdf.FromFile("sample.pdf").ExtractAllText(); -
Canlı ortamınızda test için dağıtım yapın
Ücretsiz deneme ile bugün projenizde IronPDF kullanmaya başlayın

Asgari İş Akışı (5 adım)
- C# PDF ayrıştırıcı kütüphanesini indirin
- Visual Studio'nuza yükleyin
- Her bir metin satırını çıkartmak için
ExtractAllTextmetodunu kullanın ExtractTextFromPagemetodu ile tek bir sayfadan tüm metni çıkartın- Ayrıştırılan PDF içeriğini görüntüleyin
C#'ta PDF Dosyaları Nasıl Ayrıştırılır?
IronPDF ile PDF dosyalarını ayrıştırmak basittir. Aşağıdaki kod, tüm PDF belgesinden her satır metni çıkarmak için ExtractAllText metodunu kullanır. Karşılaştırma, çıkarılan PDF içeriğini ve çıktısını yan yana gösterir. Kütüphane ayrıca PDF belgelerinin belirli bölümlerinden metin ve görüntü çıkarmayı destekler.
:path=/static-assets/pdf/content-code-examples/how-to/csharp-parse-pdf-parse-pdf.csusing IronPdf;
// Select the desired PDF File
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract all text from an pdf
string allText = pdf.ExtractAllText();
// Extract all text from page 1
string page1Text = pdf.ExtractTextFromPage(0);Imports IronPdf
' Select the desired PDF File
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract all text from an pdf
Private allText As String = pdf.ExtractAllText()
' Extract all text from page 1
Private page1Text As String = pdf.ExtractTextFromPage(0)IronPDF, çeşitli senaryolarda PDF ayrıştırmayı basitleştirir. İster HTML'den PDF'ye dönüşüm çalışıyor olun, ister mevcut belgelerden içerik çıkartıyor olun, ister gelişmiş PDF özellikleri uyguluyor olun, kütüphane kapsamlı destek sunar.
IronPDF, Windows uygulamaları ile sorunsuz entegrasyon sunar ve Linux ve macOS platformlarında dağıtımı destekler. Kütüphane ayrıca bulut tabanlı çözümler için Azure dağıtımını destekler.
Gelişmiş Metin Çıkarma Örnekleri
İşte IronPDF kullanarak PDF içeriğini ayrıştırmanın ek yolları:
:path=/static-assets/pdf/content-code-examples/how-to/csharp-parse-pdf-3.csusing IronPdf;
// Parse PDF from URL
var pdfFromUrl = PdfDocument.FromUrl("https://example.com/document.pdf");
string urlPdfText = pdfFromUrl.ExtractAllText();
// Parse password-protected PDFs
var protectedPdf = PdfDocument.FromFile("protected.pdf", "password123");
string protectedText = protectedPdf.ExtractAllText();
// Extract text from specific page range
var largePdf = PdfDocument.FromFile("large-document.pdf");
for (int i = 5; i < 10; i++)
{
string pageText = largePdf.ExtractTextFromPage(i);
Console.WriteLine($"Page {i + 1}: {pageText.Substring(0, 100)}...");
}
Imports IronPdf
' Parse PDF from URL
Dim pdfFromUrl = PdfDocument.FromUrl("https://example.com/document.pdf")
Dim urlPdfText As String = pdfFromUrl.ExtractAllText()
' Parse password-protected PDFs
Dim protectedPdf = PdfDocument.FromFile("protected.pdf", "password123")
Dim protectedText As String = protectedPdf.ExtractAllText()
' Extract text from specific page range
Dim largePdf = PdfDocument.FromFile("large-document.pdf")
For i As Integer = 5 To 9
Dim pageText As String = largePdf.ExtractTextFromPage(i)
Console.WriteLine($"Page {i + 1}: {pageText.Substring(0, 100)}...")
NextBu örnekler, farklı PDF kaynakları ve senaryoları ele alırken IronPDF'nin esnekliğini göstermektedir. Karmaşık ayrıştırma ihtiyaçları için, yapılandırılmış içerikle çalışmak üzere PDF DOM nesnesine erişimi keşfedin.
Farklı PDF Türlerini Ele Alma
IronPDF, çeşitli PDF türlerini ayrıştırmada mükemmeldir:
:path=/static-assets/pdf/content-code-examples/how-to/csharp-parse-pdf-4.csusing IronPdf;
using System.Text.RegularExpressions;
// Parse scanned PDFs with OCR (requires IronOcr)
var scannedPdf = PdfDocument.FromFile("scanned-document.pdf");
string ocrText = scannedPdf.ExtractAllText();
// Parse PDFs with forms
var formPdf = PdfDocument.FromFile("form.pdf");
string formText = formPdf.ExtractAllText();
// Extract and filter specific content
string invoiceText = pdf.ExtractAllText();
var invoiceNumber = Regex.Match(invoiceText, @"Invoice #: (\d+)").Groups[1].Value;
var totalAmount = Regex.Match(invoiceText, @"Total: \$([0-9,]+\.\d{2})").Groups[1].Value;
Imports IronPdf
Imports System.Text.RegularExpressions
' Parse scanned PDFs with OCR (requires IronOcr)
Dim scannedPdf = PdfDocument.FromFile("scanned-document.pdf")
Dim ocrText As String = scannedPdf.ExtractAllText()
' Parse PDFs with forms
Dim formPdf = PdfDocument.FromFile("form.pdf")
Dim formText As String = formPdf.ExtractAllText()
' Extract and filter specific content
Dim invoiceText As String = pdf.ExtractAllText()
Dim invoiceNumber = Regex.Match(invoiceText, "Invoice #: (\d+)").Groups(1).Value
Dim totalAmount = Regex.Match(invoiceText, "Total: \$([0-9,]+\.\d{2})").Groups(1).ValueAyrıştırılan PDF İçeriği Nasıl Görüntülenir?
Yukarıdaki kod yürütme örneğinden C# Form ayrıştırılan PDF içeriğini gösterir. Bu çıktı, belge işlem ihtiyaçları için bir PDF'den alınan tam metni sağlar.
~ PDF ~
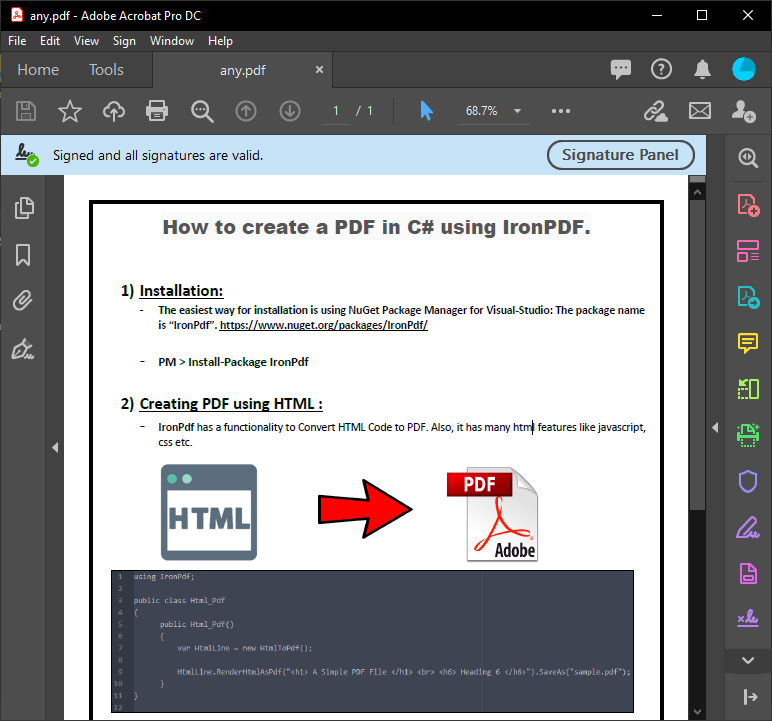
~ C# Formu ~
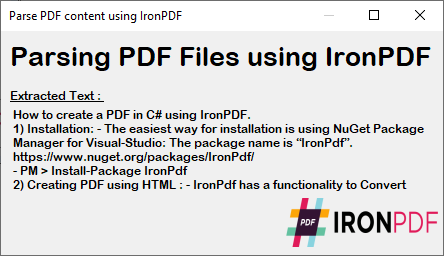
Çıkartılan metin, PDF'deki orijinal biçimini ve yapısını koruyarak veri işleme, içerik analizi veya geçiş görevleri için ideal hale getirir. Belirli içeriği bulup değiştirmek veya diğer formatlara dışa aktarmak için bu metni daha da işleyin.
PDF Ayrıştırmayı Uygulamalarınıza Entegre Etme
IronPDF'nin ayrıştırma yetenekleri çeşitli uygulama türlerine entegre edilebilir:
// ASP.NET Core example
public IActionResult ParseUploadedPdf(IFormFile pdfFile)
{
using var stream = pdfFile.OpenReadStream();
var pdf = PdfDocument.FromStream(stream);
var extractedText = pdf.ExtractAllText();
// Process or store the extracted text
return Json(new {
success = true,
textLength = extractedText.Length,
preview = extractedText.Substring(0, Math.Min(500, extractedText.Length))
});
}
// Console application example
static void BatchParsePdfs(string folderPath)
{
var pdfFiles = Directory.GetFiles(folderPath, "*.pdf");
foreach (var file in pdfFiles)
{
var pdf = PdfDocument.FromFile(file);
var text = pdf.ExtractAllText();
// Save extracted text
var textFile = Path.ChangeExtension(file, ".txt");
File.WriteAllText(textFile, text);
Console.WriteLine($"Parsed: {Path.GetFileName(file)} - {text.Length} characters");
}
}// ASP.NET Core example
public IActionResult ParseUploadedPdf(IFormFile pdfFile)
{
using var stream = pdfFile.OpenReadStream();
var pdf = PdfDocument.FromStream(stream);
var extractedText = pdf.ExtractAllText();
// Process or store the extracted text
return Json(new {
success = true,
textLength = extractedText.Length,
preview = extractedText.Substring(0, Math.Min(500, extractedText.Length))
});
}
// Console application example
static void BatchParsePdfs(string folderPath)
{
var pdfFiles = Directory.GetFiles(folderPath, "*.pdf");
foreach (var file in pdfFiles)
{
var pdf = PdfDocument.FromFile(file);
var text = pdf.ExtractAllText();
// Save extracted text
var textFile = Path.ChangeExtension(file, ".txt");
File.WriteAllText(textFile, text);
Console.WriteLine($"Parsed: {Path.GetFileName(file)} - {text.Length} characters");
}
}Imports Microsoft.AspNetCore.Mvc
Imports System.IO
' ASP.NET Core example
Public Function ParseUploadedPdf(pdfFile As IFormFile) As IActionResult
Using stream = pdfFile.OpenReadStream()
Dim pdf = PdfDocument.FromStream(stream)
Dim extractedText = pdf.ExtractAllText()
' Process or store the extracted text
Return Json(New With {
.success = True,
.textLength = extractedText.Length,
.preview = extractedText.Substring(0, Math.Min(500, extractedText.Length))
})
End Using
End Function
' Console application example
Private Shared Sub BatchParsePdfs(folderPath As String)
Dim pdfFiles = Directory.GetFiles(folderPath, "*.pdf")
For Each file In pdfFiles
Dim pdf = PdfDocument.FromFile(file)
Dim text = pdf.ExtractAllText()
' Save extracted text
Dim textFile = Path.ChangeExtension(file, ".txt")
File.WriteAllText(textFile, text)
Console.WriteLine($"Parsed: {Path.GetFileName(file)} - {text.Length} characters")
Next
End SubBu örnekler, web uygulamalarına ve toplu işlem senaryolarına PDF ayrıştırmasının nasıl entegre edildiğini gösterir. Gelişmiş uygulamalar için, async ve çoklu iş parçacığı tekniklerini keşfederek birden fazla PDF'yi işlerken performansı artırın.
Başka neler yapabileceğinizi görmek için hazır mısınız? Öğretici sayfamıza buradan göz atın: PDF Düzenle
Sıkça Sorulan Sorular
C#'ta bir PDF dosyasından tüm metni nasıl çıkarırım?
IronPDF'nin ExtractAllText metodunu kullanarak bir PDF dosyasından tüm metni çıkarabilirsiniz. PDF'nizi IronPdf.FromFile('sample.pdf') ile yükleyin ve ExtractAllText() çağrısı yaparak tüm metin içeriğini çekin ve orijinal formatı koruyun.
.NET'te en basit şekilde bir PDF nasıl ayrıştırılır?
En basit yol, IronPDF'yi yalnızca bir satır kod kullanarak kullanmaktır: var text = IronPdf.FromFile('sample.pdf').ExtractAllText(). Bu metod, tüm PDF belgesinden her satırı minimum kurulum ile çıkarır.
Bir PDF'nin belirli bir sayfasından metin çıkarabilir miyim?
Evet, IronPDF, bireysel sayfalardan metin çıkarmak için ExtractTextFromPage metodunu sağlar. Bu, PDF belgenizin belirli bölümlerini hedeflemenizi sağlar, böylece tüm içerik bir kerede çıkarılmaz.
C#'ta parola korumalı PDF'leri nasıl ayrıştırırım?
IronPDF, parola korumalı PDF'leri ayrıştırmayı destekler. Korunan belgeyi yüklemek için PdfDocument.FromFile('protected.pdf', 'password123') kullanın ve ardından metin içeriğini çıkarmak için ExtractAllText() çağrısı yapın.
Yerel dosyalar yerine URL'lerden PDF ayrıştırabilir miyim?
Evet, IronPDF, doğrudan URL'lerden PDF ayrıştırabilir, PdfDocument.FromUrl('https://example.com/document.pdf') kullanarak PDF'yi URL'den yükledikten sonra metin içeriğini çıkarmak için ExtractAllText() kullanabilirsiniz.
PDF ayrıştırıcı hangi platformları destekliyor?
IronPDF, PDF ayrıştırmayı çoklu platformlar arasında destekler, Windows uygulamaları, Linux, macOS ve Azure bulut dağıtımları dahil olmak üzere .NET uygulamalarınız için kapsamlı çapraz platform uyumluluğu sağlar.
PDF ayrıştırıcı metin formatını korur mu?
Evet, IronPDF'nin ExtractAllText metodu, ayrıştırma sırasında PDF içeriğinin orijinal formatını korur, böylece ayrıştırılan metin, kaynak belgede olduğu gibi biçimini ve düzenini muhafaza eder.
Hem metin hem de görüntüleri PDF'lerden çıkarabilir miyim?
IronPDF, PDF belgelerinden hem metin hem de görüntü çıkarmayı destekler. Metin çıkarmak için ExtractAllText metodunun yanı sıra, kütüphane ayrıca PDF belgelerinin belirli bölümlerinden görüntü çıkarmak için ek işlevsellik sağlar.


Hâlâ Kaydırıyor Musunuz?
Hızlıca kanıt ister misiniz? PM > Install-Package IronPdf
bir örnek çalıştır HTML'nizi bir PDF'ye dönüştüğünü izleyin.










