

How to Archive PDFs with PDF/A Compliance in C
A conformidade com PDF/A em C# com o IronPDF oferece aos desenvolvedores .NET um caminho direto para criar, converter e validar PDFs arquivados que atendem aos padrões ISO 19005 — garantindo que os documentos sejam exibidos de forma idêntica em qualquer sistema, agora ou daqui a décadas. Desde a renderização de HTML para PDF/A e a conversão de arquivos existentes para PDF/A-1b , PDF/A-2b ou PDF/A-3b , até a incorporação de dados de origem para conformidade com os padrões de faturamento eletrônico ZUGFeRD e Factur-X , o IronPDF gerencia todo o fluxo de trabalho de conversão para PDF/A sem sair do ecossistema .NET .
Resumo: Guia de Início Rápido
Este tutorial aborda a criação, conversão e validação de documentos compatíveis com PDF/A em C#, incluindo formatos de faturamento eletrônico e requisitos reais de arquivamento governamental.
- Para quem é indicado: Desenvolvedores .NET que criam aplicativos que geram documentos para armazenamento de longo prazo ou arquivamento regulamentado — gerenciamento de registros governamentais, processos judiciais, trilhas de auditoria financeira, retenção de registros de saúde ou plataformas de faturamento eletrônico onde o PDF/A é um requisito de conformidade obrigatório.
- O que você vai desenvolver: renderização de HTML para PDF/A do zero, conversão de PDFs existentes para PDF/A-1b/2b/3b, anexação de dados de origem incorporados para faturamento eletrônico ZUGFeRD/Factur-X, validação de conformidade com PDF/A com relatório de falhas e padrões de arquivamento do mundo real para atender aos requisitos do NARA, documentos judiciais e registros médicos.
- Onde funciona: Qualquer ambiente .NET — .NET 10, .NET 8 LTS, .NET Framework 4.6.2+, .NET Standard 2.0. A conversão e validação de PDF/A são executadas inteiramente em nível local; Não são necessárias ferramentas de validação externas para a geração.
- Quando usar essa abordagem: Quando seu aplicativo gera documentos que precisam ser preservados a longo prazo — faturas, contratos, relatórios de conformidade, processos judiciais ou registros médicos — e quando as normas regulatórias (NARA, padrões de arquivamento da UE, HIPAA, SEC) exigem um formato PDF/A autossuficiente e verificável.
- Por que isso é importante tecnicamente: PDFs padrão podem referenciar fontes externas, incorporar conteúdo ativo e depender de renderização específica do sistema — tudo isso deixa de funcionar com o tempo. O PDF/A proíbe essas dependências no nível do formato, incorporando tudo o que é necessário para a renderização diretamente no arquivo, garantindo uma saída idêntica em qualquer visualizador compatível, indefinidamente.
Converta um PDF existente para PDF/A com apenas algumas linhas de código:
-
Instale IronPDF com o Gerenciador de Pacotes NuGet
-
Copie e execute este trecho de código.
using IronPdf; PdfDocument pdf = PdfDocument.FromFile("report.pdf"); pdf.SaveAsPdfA("archived-report.pdf", PdfAVersions.PdfA3b); -
Implante para testar em seu ambiente de produção.
Comece a usar IronPDF em seu projeto hoje com uma avaliação gratuita

Após adquirir ou se inscrever para um período de avaliação de 30 dias do IronPDF, adicione sua chave de licença no início do seu aplicativo.
:path=/static-assets/pdf/content-code-examples/tutorials/pdfa-archiving-csharp-2.csIronPdf.License.LicenseKey = "KEY";
Imports IronPdf
IronPdf.License.LicenseKey = "KEY"Índice
- Compreendendo o PDF/A O que é PDF/A e por que é importante?
- Criação de documentos PDF/A
- Fluxos de trabalho avançados em PDF/A
- Cenários de arquivamento no mundo real
O que é PDF/A e por que é importante?
O PDF/A é um subconjunto do formato PDF (ISO 19005) padronizado pela ISO e projetado especificamente para o arquivamento confiável e de longo prazo de documentos eletrônicos. Ao contrário de um PDF padrão, que pode referenciar fontes externas, incluir links para conteúdo externo e depender do comportamento de renderização específico do sistema, um arquivo PDF/A é totalmente autossuficiente. Todas as fontes, perfis de cores e metadados necessários para renderizar o documento estão incorporados diretamente no arquivo.
Isso é importante porque um documento PDF/A será exibido da mesma forma, seja hoje ou daqui a 100 anos, em qualquer visualizador compatível, independentemente do sistema operacional ou da versão do software. Não há dependência de recursos externos que possam desaparecer, nem necessidade de instalar uma fonte específica, e não há ambiguidade em relação à forma como as cores ou a transparência devem ser exibidas.
Além da durabilidade técnica, a conformidade com o PDF/A é frequentemente um requisito obrigatório — e não apenas uma boa prática. Setores e instituições que exigem o PDF/A incluem:
Sistemas jurídicos e judiciais — Tribunais nos EUA, na UE e em muitas outras jurisdições exigem ou recomendam fortemente o formato PDF/A para o arquivamento eletrônico de documentos. Os padrões de arquivamento CM/ECF do sistema judicial federal dos EUA fazem referência ao PDF/A como o formato preferencial para o arquivamento de registros a longo prazo.
Agências governamentais — O Arquivo Nacional e Administração de Registros dos EUA (NARA) especifica o PDF/A como um formato aceito para a transferência de registros eletrônicos permanentes. Da mesma forma, a Comissão Europeia exige o formato PDF/A para determinadas publicações oficiais e documentos regulamentares.
Serviços financeiros e auditoria — Órgãos reguladores como a SEC aceitam arquivamentos em formato PDF/A, e equipes de auditoria interna frequentemente adotam o PDF/A para garantir que as demonstrações financeiras, os relatórios e a documentação de suporte permaneçam inalteráveis e verificáveis ao longo do tempo.
Na área da saúde , as normas de retenção de registros médicos (como a HIPAA nos EUA) não exigem um formato de arquivo específico, mas o PDF/A tornou-se o padrão de facto para o arquivamento de prontuários de pacientes, laudos de exames de imagem e documentação clínica, pois garante a legibilidade a longo prazo.
Resumindo, o PDF/A é o formato que você usa quando um documento precisa permanecer inalterado ao longo do tempo, entre diferentes sistemas e fronteiras organizacionais. Se o seu aplicativo gera documentos que podem ser consultados anos depois — faturas, contratos, relatórios de conformidade, registros médicos — o PDF/A é a escolha certa.
Explicação das versões PDF/A
O padrão PDF/A evoluiu através de diversas versões, cada uma construída sobre a anterior para suportar recursos adicionais do PDF, mantendo ao mesmo tempo rigorosas garantias de arquivamento. Compreender as diferenças entre as versões é essencial para escolher a mais adequada ao seu caso de uso.
PDF/A-1 (Arquivamento Básico)
O PDF/A-1 (ISO 19005-1:2005) foi a primeira versão do padrão, baseada no PDF 1.4. Ele estabeleceu os principais requisitos de arquivamento: todas as fontes devem estar incorporadas; A criptografia é proibida; Conteúdo de áudio/vídeo não é permitido; JavaScript está proibido. O padrão PDF/A-1 possui dois níveis de conformidade:
PDF/A-1b ( básico ): Garante a reprodução visual confiável do documento. Este é o nível mínimo de conformidade e garante que o documento seja exibido corretamente quando renderizado.
PDF/A-1a (acessível): Adiciona requisitos estruturais e semânticos em cima de 1b, incluindo conteúdo marcado para acessibilidade, mapeamento de caracteres Unicode, e uma ordem lógica de leitura. Este é o padrão mais elevado e é exigido quando a conformidade com a acessibilidade é importante.
O PDF/A-1 é a versão mais amplamente suportada e ainda é comumente usada hoje em dia, especialmente em contextos jurídicos e governamentais, onde a ampla compatibilidade é priorizada em relação a recursos mais recentes.
PDF/A-2 (JPEG2000, Transparência)
O PDF/A-2 (ISO 19005-2:2011) é baseado no PDF 1.7 e introduz suporte para recursos que não estavam disponíveis no PDF/A-1:
Compressão de imagem JPEG2000: Oferece melhores relações qualidade/tamanho do que a compressão JPEG disponível em PDF/A-1.
Transparência e suporte a camadas: Permite layouts visuais mais complexos sem transformar tudo em elementos opacos.
Anexos PDF/A incorporados: documentos PDF/A-2 podem incorporar outros arquivos compatíveis com PDF/A como anexos (mas apenas arquivos PDF/A, não formatos arbitrários).
PDF/A-2 inclui os mesmos níveis de conformidade que PDF/A-1 (2b e 2a), além de um novo nível: PDF/A-2u (Unicode), que requer mapeamento Unicode para todo o texto, mas não requer a marcação estrutural completa do nível a.
PDF/A-3 (Arquivos incorporados)
O formato PDF/A-3 (ISO 19005-3:2012) é a extensão mais significativa para os fluxos de trabalho modernos. Compartilha a mesma base que o PDF/A-2 (PDF 1.7) e mantém todos os seus recursos, mas adiciona uma capacidade essencial: a habilidade de incorporar arquivos de qualquer formato dentro do documento PDF/A.
Isso significa que você pode anexar os dados originais da fonte XML, exportações em CSV, planilhas ou qualquer outro arquivo legível por máquina juntamente com o documento visual legível por humanos. O contêiner PDF/A-3 se torna um pacote único que contém tanto a camada de apresentação quanto os dados subjacentes.
Essa capacidade é a base dos padrões modernos de faturamento eletrônico:
ZUGFeRD: Originalmente da Alemanha, agora adotado em toda a UE como Factur-X . Incorpora dados estruturados de faturas em XML (no formato Cross-Industry Invoice) dentro de um documento PDF/A-3 que também contém a fatura visual e legível. Um único arquivo atende às necessidades de processamento tanto humano quanto automatizado.
Os níveis de conformidade do PDF/A-3 seguem o mesmo padrão: 3b (visual), 3a (acessível + marcado), e 3u (mapeado em Unicode).
PDF/A-4 (Baseado em PDF 2.0)
O PDF/A-4 (ISO 19005-4:2020) é a versão mais recente, baseada no PDF 2.0. Ele simplifica a estrutura de níveis de conformidade; não há mais distinção a/b/u. Em vez disso, o PDF/A-4 define três perfis:
PDF/A-4: O perfil básico para arquivamento geral.
PDF/A-4f: Permite a incorporação de arquivos de qualquer formato (semelhante ao PDF/A-3).
PDF/A-4e: Projetado especificamente para documentos de engenharia; Suporta conteúdo 3D, multimídia e outros elementos técnicos.
PDF/A-4 também se beneficia de melhorias no próprio PDF 2.0, incluindo estruturas de marcação aprimoradas e capacidades de metadados aprimoradas usando XMP (Plataforma Extensível de Metadados).
A adoção do formato PDF/A-4 está crescendo, mas ainda é menos universalmente suportada por visualizadores e validadores em comparação com o PDF/A-2 e o PDF/A-3.
Qual versão você deve usar?
A escolha da versão correta em PDF/A depende das suas necessidades específicas:
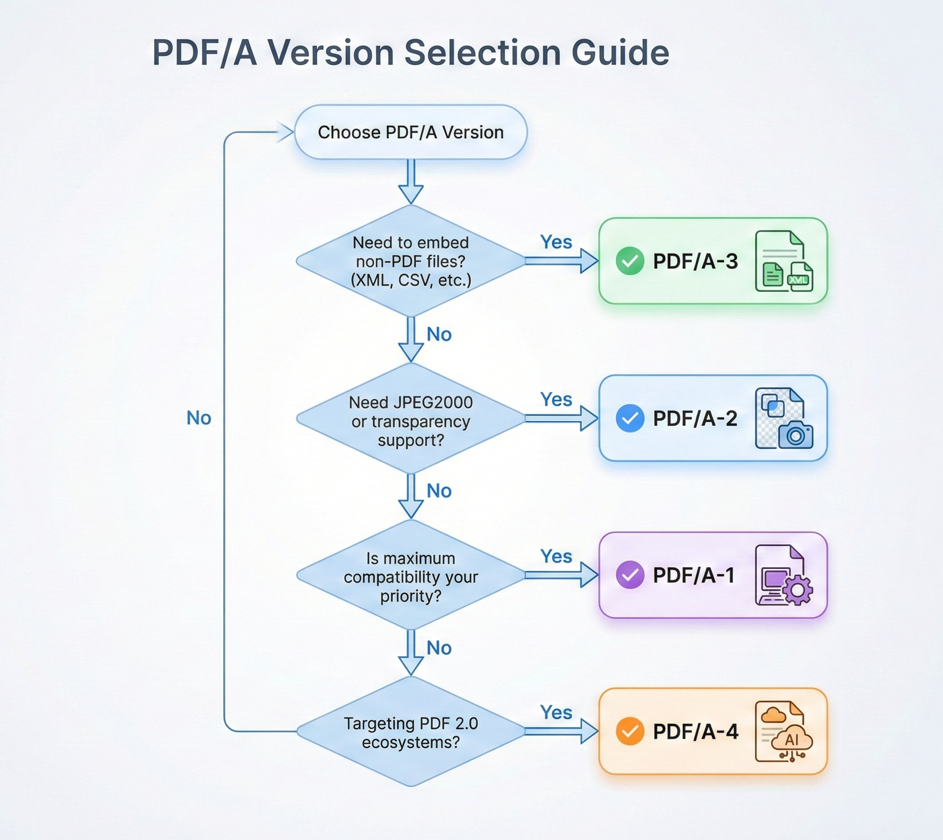
Máxima compatibilidade: Para sistemas, validadores e visualizadores existentes (especialmente em contextos jurídicos e governamentais), utilize PDF/A-1b ou PDF/A-2b .
Faturação eletrônica: Para ZUGFeRD, Factur-X ou padrões similares que exigem dados de origem incorporados, use PDF/A-3b .
Conformidade de acessibilidade: Para requisitos da Seção 508 ou WCAG, escolha o nível de conformidade a de qualquer versão que você esteja usando (PDF/A-1a, PDF/A-2a, ou PDF/A-3a).
Fluxos de trabalho modernos: Para obter os recursos mais recentes, onde seus clientes são compatíveis com PDF 2.0, use PDF/A-4 .
Na dúvida, o PDF/A-3b oferece o melhor equilíbrio entre recursos modernos e ampla compatibilidade.
Criando documentos PDF/A do zero
Agora que você entende o que é PDF/A e qual versão usar como alvo, vamos analisar o código. O IronPDF facilita a geração de documentos compatíveis com PDF/A diretamente a partir de conteúdo HTML ou a conversão de PDFs existentes para o formato PDF/A.
Instalando o IronPDF
Antes de começar, instale o pacote NuGet IronPdf no seu projeto .NET. Você pode fazer isso através do Console do Gerenciador de Pacotes NuGet , da CLI do .NET ou da interface do usuário do NuGet no Visual Studio.
Install-Package IronPdf
Ou usando a CLI do .NET:
dotnet add package IronPdf
O IronPDF é compatível com .NET Framework 4.6.2+, .NET Core, .NET 5+ e .NET Standard 2.0, portanto, se integra a praticamente qualquer projeto .NET moderno sem problemas de compatibilidade.
Renderizando HTML para PDF/A
O fluxo de trabalho mais comum é gerar um PDF a partir de conteúdo HTML e salvá-lo diretamente no formato PDF/A. O ChromePdfRenderer do IronPDF lida com a conversão de HTML para PDF, e o método SaveAsPdfA lida com a conversão de conformidade em uma única etapa.
:path=/static-assets/pdf/content-code-examples/tutorials/pdfa-archiving-csharp/pdfa-render-html-to-pdfa.csusing IronPdf;
// Create HTML content for the document
string htmlContent = @"
E html>
le>
body { font-family: Arial, sans-serif; margin: 40px; }
h1 { color: #2c3e50; }
.section { margin: 20px 0; }
table { width: 100%; border-collapse: collapse; }
th, td { border: 1px solid #ddd; padding: 10px; text-align: left; }
th { background: #3498db; color: white; }
yle>
Quarterly Financial Report</h1>
eport Period: Q4 2025</p>
class='section'>
<table>
<tr><th>Metric</th><th>Value</th></tr>
<tr><td>Total Revenue</td><td>$4.2M</td></tr>
<tr><td>Operating Expenses</td><td>$2.1M</td></tr>
<tr><td>Net Income</td><td>$2.1M</td></tr>
</table>
v>
his document is archived in PDF/A-3b format for long-term preservation.</p>
;
// Render HTML to PDF
var renderer = new ChromePdfRenderer();
using var pdf = renderer.RenderHtmlAsPdf(htmlContent);
// Save as PDF/A-3b for archival compliance
pdf.SaveAsPdfA("quarterly-report-archived.pdf", PdfAVersions.PdfA3b);Imports IronPdf
' Create HTML content for the document
Dim htmlContent As String = "
<!DOCTYPE html>
<html>
<head>
<style>
body { font-family: Arial, sans-serif; margin: 40px; }
h1 { color: #2c3e50; }
.section { margin: 20px 0; }
table { width: 100%; border-collapse: collapse; }
th, td { border: 1px solid #ddd; padding: 10px; text-align: left; }
th { background: #3498db; color: white; }
</style>
</head>
<body>
<h1>Quarterly Financial Report</h1>
<p>Report Period: Q4 2025</p>
<div class='section'>
<table>
<tr><th>Metric</th><th>Value</th></tr>
<tr><td>Total Revenue</td><td>$4.2M</td></tr>
<tr><td>Operating Expenses</td><td>$2.1M</td></tr>
<tr><td>Net Income</td><td>$2.1M</td></tr>
</table>
</div>
<p>This document is archived in PDF/A-3b format for long-term preservation.</p>
</body>
</html>
"
' Render HTML to PDF
Dim renderer As New ChromePdfRenderer()
Using pdf = renderer.RenderHtmlAsPdf(htmlContent)
' Save as PDF/A-3b for archival compliance
pdf.SaveAsPdfA("quarterly-report-archived.pdf", PdfAVersions.PdfA3b)
End UsingSaída
Neste exemplo, o HTML é renderizado em PDF usando o mecanismo de renderização baseado no Chromium do IronPDF, o que garante fidelidade perfeita em termos de pixels, em conformidade com os padrões da web modernos. O método SaveAsPdfA então embute todas as fontes necessárias, converte espaços de cores conforme necessário, remove quaisquer recursos proibidos (como JavaScript ou links externos), e escreve os metadados XMP compatíveis. O resultado é um arquivo PDF/A-3b totalmente independente, pronto para armazenamento em arquivos.
Essa abordagem funciona perfeitamente também com os outros recursos de renderização do IronPDF. Você pode aplicar cabeçalhos e rodapés, definir tamanhos e margens de página, incluir estilização CSS e usar RenderingOptions para afinar o resultado — tudo antes da etapa de conversão PDF/A. A chamada SaveAsPdfA lida com a transformação de conformidade, independentemente de como o PDF foi gerado.
Converter PDFs existentes para PDF/A
Nem sempre se começa com HTML. Em muitos cenários reais, você receberá arquivos PDF existentes — de scanners, sistemas de terceiros, arquivos legados ou uploads de usuários — e precisará convertê-los para PDF/A para armazenamento em conformidade.
IronPDF lida com isso usando o mesmo método SaveAsPdfA:
:path=/static-assets/pdf/content-code-examples/tutorials/pdfa-archiving-csharp/pdfa-convert-existing-pdf.csusing IronPdf;
// Load an existing PDF file
using var pdf = PdfDocument.FromFile("existing-document.pdf");
// Convert and save as PDF/A-3b
// IronPDF automatically embeds fonts, converts color spaces, adds XMP metadata,
// and removes non-compliant features during conversion
pdf.SaveAsPdfA("existing-document-archived.pdf", PdfAVersions.PdfA3b);
// Alternative: Use ConvertToPdfA for in-memory conversion
using var pdf2 = PdfDocument.FromFile("another-document.pdf");
using var pdfA = pdf2.ConvertToPdfA(PdfAVersions.PdfA2b);
pdfA.SaveAs("another-document-archived.pdf");Imports IronPdf
' Load an existing PDF file
Using pdf As PdfDocument = PdfDocument.FromFile("existing-document.pdf")
' Convert and save as PDF/A-3b
' IronPDF automatically embeds fonts, converts color spaces, adds XMP metadata,
' and removes non-compliant features during conversion
pdf.SaveAsPdfA("existing-document-archived.pdf", PdfAVersions.PdfA3b)
End Using
' Alternative: Use ConvertToPdfA for in-memory conversion
Using pdf2 As PdfDocument = PdfDocument.FromFile("another-document.pdf")
Using pdfA As PdfDocument = pdf2.ConvertToPdfA(PdfAVersions.PdfA2b)
pdfA.SaveAs("another-document-archived.pdf")
End Using
End UsingDurante a conversão, o IronPDF analisa o PDF existente e aplica as transformações necessárias: incorpora quaisquer fontes que foram referenciadas, mas não incluídas, converte os espaços de cores RGB ou CMYK para os perfis apropriados, adiciona os metadados XMP necessários e remove quaisquer recursos não compatíveis, como criptografia, multimídia ou JavaScript. Você também pode usar o método ConvertToPdfA se você quiser converter na memória sem salvar imediatamente no disco — útil para pipelines onde o processamento adicional segue a conversão.
Esse padrão é ideal para projetos de migração em que é necessário adequar um repositório de documentos legado aos padrões modernos de arquivamento.
Minha biblioteca favorita desse tipo é o IronPDF. Ele permite a manipulação rápida e eficiente de arquivos PDF. Além disso, possui muitos recursos valiosos, como a exportação para o formato PDF/A e a assinatura digital de documentos PDF.
Com o IronOCR, podemos economizar US$ 40.000 por ano em processamento manual, ao mesmo tempo que aumentamos a produtividade e liberamos recursos para tarefas de alto impacto. Eu o recomendo fortemente.
O IronSuite desempenha um papel crucial nas nossas operações. Estas são ferramentas que aumentam a eficiência no negócio, incluindo a criação de plantas baixas e melhoria na gestão de inventário.
Incorporação de dados de origem (PDF/A-3)
Uma das funcionalidades mais poderosas do padrão PDF/A-3 é a capacidade de incorporar arquivos arbitrários — XML, CSV, JSON, planilhas ou qualquer outro formato — diretamente no documento PDF. Isso transforma o PDF de um documento puramente visual em um contêiner híbrido que carrega tanto a apresentação legível por humanos quanto os dados de origem legíveis por máquina em um único arquivo.
Anexar XML/CSV a um documento visual
O workflow central é simples: gere ou carregue seu PDF visual, anexe o arquivo de dados fonte como um anexo embutido e salve como PDF/A-3. IronPDF suporta arquivos de incorporação através de múltiplas sobrecargas do método ConvertToPdfA — você pode passar caminhos de arquivo diretamente como IEnumerable<string>, usar EmbedFileByte para arrays de bytes já na memória, ou usar EmbedFileStream para workflows baseados em stream. Cada abordagem mantém total conformidade com o padrão PDF/A.
:path=/static-assets/pdf/content-code-examples/tutorials/pdfa-archiving-csharp/pdfa-embed-xml-attachment.csusing IronPdf;
using System.Collections.Generic;
// Load the visual PDF document
using var pdf = PdfDocument.FromFile("financial-report.pdf");
// Prepare XML source data to embed
string xmlData = @"<?xml version='1.0' encoding='UTF-8'?>
alReport>
iod>Q4 2025</Period>
enue>4200000</Revenue>
enses>2100000</Expenses>
Income>2100000</NetIncome>
ialReport>";
byte[] xmlBytes = System.Text.Encoding.UTF8.GetBytes(xmlData);
// Configure the embedded file
var xmlConfig = new EmbedFileConfiguration(EmbedFileType.xml)
{
EmbedFileName = "financial-data.xml",
AFDesc = "Source financial data in XML format",
AFRelationship = AFRelationship.Data
};
// Create embed file collection
var embedFiles = new List<EmbedFileByte>
{
new EmbedFileByte(xmlBytes, xmlConfig)
};
// Convert to PDF/A-3b with embedded data
using var archivedPdf = pdf.ConvertToPdfA(embedFiles, PdfAVersions.PdfA3b);
archivedPdf.SaveAs("financial-report-with-data.pdf");Imports IronPdf
Imports System.Collections.Generic
Imports System.Text
' Load the visual PDF document
Using pdf = PdfDocument.FromFile("financial-report.pdf")
' Prepare XML source data to embed
Dim xmlData As String = "<?xml version='1.0' encoding='UTF-8'?>
<FinancialReport>
<Period>Q4 2025</Period>
<Revenue>4200000</Revenue>
<Expenses>2100000</Expenses>
<NetIncome>2100000</NetIncome>
</FinancialReport>"
Dim xmlBytes As Byte() = Encoding.UTF8.GetBytes(xmlData)
' Configure the embedded file
Dim xmlConfig As New EmbedFileConfiguration(EmbedFileType.xml) With {
.EmbedFileName = "financial-data.xml",
.AFDesc = "Source financial data in XML format",
.AFRelationship = AFRelationship.Data
}
' Create embed file collection
Dim embedFiles As New List(Of EmbedFileByte) From {
New EmbedFileByte(xmlBytes, xmlConfig)
}
' Convert to PDF/A-3b with embedded data
Using archivedPdf = pdf.ConvertToPdfA(embedFiles, PdfAVersions.PdfA3b)
archivedPdf.SaveAs("financial-report-with-data.pdf")
End Using
End UsingEsse padrão é particularmente valioso para fluxos de trabalho de relatórios financeiros, onde o PDF visual pode ser um balanço patrimonial ou uma demonstração de resultados formatada, enquanto o XML ou CSV anexado contém os dados brutos usados para gerar o relatório. Auditores podem inspecionar o documento visual e verificar de forma independente os números subjacentes usando os dados fonte embutidos — tudo em um único arquivo. Você pode incorporar múltiplos anexos no mesmo documento, passando caminhos de arquivos adicionais ou arrays de bytes para o parâmetro de coleção do método ConvertToPdfA.
Conformidade com ZUGFeRD e Factur-X para Faturação Eletrônica
ZUGFeRD (Zentraler User Guide des Forums elektronische Rechnung Deutschland) e seu equivalente internacional Factur-X são padrões de faturamento eletrônico que especificam como os dados estruturados da fatura devem ser incorporados em um documento PDF/A-3. O PDF visual serve como fatura legível para humanos, enquanto um arquivo XML incorporado (seguindo o formato Cross-Industry Invoice, ou CII) contém os dados processáveis por máquina.
Os principais requisitos para conformidade com ZUGFeRD/Factur-X são:
O PDF deve estar em conformidade com PDF/A-3b (no mínimo). O arquivo XML incorporado deve seguir o esquema de fatura intersetorial da UN/CEFACT. O arquivo XML deve ser nomeado de acordo com a especificação do padrão (tipicamente factur-x.xml para Factur-X ou zugferd-invoice.xml para ZUGFeRD). Propriedades específicas de metadados XMP devem ser definidas para identificar o documento como uma fatura ZUGFeRD/Factur-X.
A classe EmbedFileConfiguration de IronPDF oferece controle granular sobre esses requisitos. Você pode definir as propriedades ConformanceLevel (como ConformanceLevel.XRECHNUNG), SchemaNamespace, SchemaPrefix, PropertyVersion e AFRelationship para corresponder ao perfil de e-fatura exato que seu sistema-alvo espera.
Aqui está como você pode construir uma fatura compatível com ZUGFeRD com IronPDF:
:path=/static-assets/pdf/content-code-examples/tutorials/pdfa-archiving-csharp/pdfa-zugferd-invoice.csusing IronPdf;
using System.Collections.Generic;
// Create visual invoice HTML
string invoiceHtml = @"
E html>
le>
body { font-family: Arial, sans-serif; margin: 40px; }
.header { border-bottom: 2px solid #e74c3c; padding-bottom: 15px; }
h1 { color: #e74c3c; }
.invoice-details { margin: 30px 0; }
.line-item { display: flex; justify-content: space-between; padding: 10px 0; border-bottom: 1px solid #eee; }
.total { font-size: 20px; font-weight: bold; margin-top: 20px; text-align: right; }
yle>
class='header'>
<h1>INVOICE #INV-2026-0042</h1>
<p>Date: February 7, 2026</p>
v>
class='invoice-details'>
<p><strong>Bill To:</strong> Acme Corporation</p>
<p><strong>Address:</strong> 123 Business Ave, Suite 100</p>
v>
class='line-item'><span>Software License (Enterprise)</span><span>$2,499.00</span></div>
class='line-item'><span>Annual Support Contract</span><span>$499.00</span></div>
class='line-item'><span>Implementation Services</span><span>$1,500.00</span></div>
class='total'>Total: $4,498.00</div>
tyle='margin-top: 40px; font-size: 12px; color: #666;'>
This invoice complies with ZUGFeRD/Factur-X e-invoicing standards.
;
// Render the visual invoice
var renderer = new ChromePdfRenderer();
using var invoicePdf = renderer.RenderHtmlAsPdf(invoiceHtml);
// Prepare ZUGFeRD/Factur-X XML invoice data
string zugferdXml = @"<?xml version='1.0' encoding='UTF-8'?>
ssIndustryInvoice xmlns:rsm='urn:un:unece:uncefact:data:standard:CrossIndustryInvoice:100'>
:ExchangedDocument>
<ram:ID>INV-2026-0042</ram:ID>
<ram:IssueDateTime>2026-02-07</ram:IssueDateTime>
m:ExchangedDocument>
:SupplyChainTradeTransaction>
<ram:ApplicableHeaderTradeSettlement>
<ram:InvoiceCurrencyCode>USD</ram:InvoiceCurrencyCode>
<ram:SpecifiedTradeSettlementHeaderMonetarySummation>
<ram:GrandTotalAmount>4498.00</ram:GrandTotalAmount>
</ram:SpecifiedTradeSettlementHeaderMonetarySummation>
</ram:ApplicableHeaderTradeSettlement>
m:SupplyChainTradeTransaction>
ossIndustryInvoice>";
byte[] xmlBytes = System.Text.Encoding.UTF8.GetBytes(zugferdXml);
// Configure for ZUGFeRD/Factur-X compliance
var zugferdConfig = new EmbedFileConfiguration(EmbedFileType.xml)
{
EmbedFileName = "factur-x.xml",
AFDesc = "Factur-X Invoice Data",
ConformanceLevel = ConformanceLevel.EN16931,
SchemaNamespace = SchemaNamespace.facturX,
SchemaPrefix = SchemaPrefix.fx,
PropertyVersion = PropertyVersion.v1,
AFRelationship = AFRelationship.Alternative
};
var embedFiles = new List<EmbedFileByte>
{
new EmbedFileByte(xmlBytes, zugferdConfig)
};
// Convert to PDF/A-3b with embedded ZUGFeRD data
using var zugferdInvoice = invoicePdf.ConvertToPdfA(embedFiles, PdfAVersions.PdfA3b);
// Set invoice metadata
zugferdInvoice.MetaData.Title = "Invoice INV-2026-0042";
zugferdInvoice.MetaData.Author = "IronSoftware Billing";
zugferdInvoice.MetaData.Subject = "ZUGFeRD/Factur-X Compliant Invoice";
zugferdInvoice.SaveAs("invoice-zugferd.pdf");Imports IronPdf
Imports System.Collections.Generic
Imports System.Text
' Create visual invoice HTML
Dim invoiceHtml As String = "
<!DOCTYPE html>
<html>
<head>
<style>
body { font-family: Arial, sans-serif; margin: 40px; }
.header { border-bottom: 2px solid #e74c3c; padding-bottom: 15px; }
h1 { color: #e74c3c; }
.invoice-details { margin: 30px 0; }
.line-item { display: flex; justify-content: space-between; padding: 10px 0; border-bottom: 1px solid #eee; }
.total { font-size: 20px; font-weight: bold; margin-top: 20px; text-align: right; }
</style>
</head>
<body>
<div class='header'>
<h1>INVOICE #INV-2026-0042</h1>
<p>Date: February 7, 2026</p>
</div>
<div class='invoice-details'>
<p><strong>Bill To:</strong> Acme Corporation</p>
<p><strong>Address:</strong> 123 Business Ave, Suite 100</p>
</div>
<div class='line-item'><span>Software License (Enterprise)</span><span>$2,499.00</span></div>
<div class='line-item'><span>Annual Support Contract</span><span>$499.00</span></div>
<div class='line-item'><span>Implementation Services</span><span>$1,500.00</span></div>
<div class='total'>Total: $4,498.00</div>
<p style='margin-top: 40px; font-size: 12px; color: #666;'>
This invoice complies with ZUGFeRD/Factur-X e-invoicing standards.
</p>
</body>
</html>"
' Render the visual invoice
Dim renderer As New ChromePdfRenderer()
Using invoicePdf = renderer.RenderHtmlAsPdf(invoiceHtml)
' Prepare ZUGFeRD/Factur-X XML invoice data
Dim zugferdXml As String = "<?xml version='1.0' encoding='UTF-8'?>
<rsm:CrossIndustryInvoice xmlns:rsm='urn:un:unece:uncefact:data:standard:CrossIndustryInvoice:100'>
<rsm:ExchangedDocument>
<ram:ID>INV-2026-0042</ram:ID>
<ram:IssueDateTime>2026-02-07</ram:IssueDateTime>
</rsm:ExchangedDocument>
<rsm:SupplyChainTradeTransaction>
<ram:ApplicableHeaderTradeSettlement>
<ram:InvoiceCurrencyCode>USD</ram:InvoiceCurrencyCode>
<ram:SpecifiedTradeSettlementHeaderMonetarySummation>
<ram:GrandTotalAmount>4498.00</ram:GrandTotalAmount>
</ram:SpecifiedTradeSettlementHeaderMonetarySummation>
</ram:ApplicableHeaderTradeSettlement>
</rsm:SupplyChainTradeTransaction>
</rsm:CrossIndustryInvoice>"
Dim xmlBytes As Byte() = Encoding.UTF8.GetBytes(zugferdXml)
' Configure for ZUGFeRD/Factur-X compliance
Dim zugferdConfig As New EmbedFileConfiguration(EmbedFileType.xml) With {
.EmbedFileName = "factur-x.xml",
.AFDesc = "Factur-X Invoice Data",
.ConformanceLevel = ConformanceLevel.EN16931,
.SchemaNamespace = SchemaNamespace.facturX,
.SchemaPrefix = SchemaPrefix.fx,
.PropertyVersion = PropertyVersion.v1,
.AFRelationship = AFRelationship.Alternative
}
Dim embedFiles As New List(Of EmbedFileByte) From {
New EmbedFileByte(xmlBytes, zugferdConfig)
}
' Convert to PDF/A-3b with embedded ZUGFeRD data
Using zugferdInvoice = invoicePdf.ConvertToPdfA(embedFiles, PdfAVersions.PdfA3b)
' Set invoice metadata
zugferdInvoice.MetaData.Title = "Invoice INV-2026-0042"
zugferdInvoice.MetaData.Author = "IronSoftware Billing"
zugferdInvoice.MetaData.Subject = "ZUGFeRD/Factur-X Compliant Invoice"
zugferdInvoice.SaveAs("invoice-zugferd.pdf")
End Using
End UsingSaída
Essa abordagem permite que seu sistema de faturamento produza documentos que atendam tanto à revisão humana (o PDF visual) quanto ao processamento automatizado (o XML incorporado) em um único pacote compatível com os padrões.
Preservação do Rastreamento de Auditoria
Além da emissão de faturas eletrônicas, a capacidade de incorporação do PDF/A-3 é valiosa para qualquer fluxo de trabalho onde é importante manter uma trilha de auditoria completa. Ao anexar os dados de origem originais, os registros de processamento ou os históricos de alterações ao documento final, você cria um registro autossuficiente que pode ser verificado de forma independente a qualquer momento no futuro.
Os padrões comuns de incorporação de trilhas de auditoria incluem:
Demonstrações financeiras — Incorpore os dados contábeis brutos (exportação em CSV ou XML do seu sistema ERP) juntamente com o relatório financeiro formatado. Os auditores podem verificar se os números no documento visual correspondem aos dados de origem sem precisar acessar o sistema original.
Documentação regulatória — Anexe os dados originais da submissão, os resultados da validação e quaisquer cálculos de suporte como arquivos incorporados no documento final. Isso cria um único pacote de arquivamento que contém o registro completo do processo.
Gestão de contratos — Incorpore históricos de versões, cadeias de aprovação ou arquivos de metadados assinados no PDF do contrato final executado. Isso preserva todo o ciclo de vida do documento em um único arquivo de arquivamento.
:path=/static-assets/pdf/content-code-examples/tutorials/pdfa-archiving-csharp/pdfa-audit-trail.csusing IronPdf;
using System;
using System.Collections.Generic;
using System.Text.Json;
// Load the final document to archive
using var pdf = PdfDocument.FromFile("executed-contract.pdf");
// Create audit trail data
var auditTrail = new
{
DocumentId = "CONTRACT-2026-00142",
CreatedDate = "2026-01-15T09:30:00Z",
FinalizedDate = "2026-02-07T14:22:00Z",
Versions = new[]
{
new { Version = 1, Date = "2026-01-15", Action = "Draft created", User = "john.smith@company.com" },
new { Version = 2, Date = "2026-01-20", Action = "Legal review completed", User = "legal@company.com" },
new { Version = 3, Date = "2026-02-01", Action = "Client revisions incorporated", User = "john.smith@company.com" },
new { Version = 4, Date = "2026-02-07", Action = "Final execution", User = "ceo@company.com" }
},
Signatures = new[]
{
new { Signer = "Company CEO", SignedDate = "2026-02-07T14:20:00Z", IPAddress = "192.168.1.100" },
new { Signer = "Client Representative", SignedDate = "2026-02-07T14:22:00Z", IPAddress = "10.0.0.50" }
},
Checksum = "SHA256:a1b2c3d4e5f6..."
};
string auditJson = JsonSerializer.Serialize(auditTrail, new JsonSerializerOptions { WriteIndented = true });
byte[] auditBytes = System.Text.Encoding.UTF8.GetBytes(auditJson);
// Configure audit trail attachment
var auditConfig = new EmbedFileConfiguration(EmbedFileType.xml)
{
EmbedFileName = "audit-trail.json",
AFDesc = "Complete document audit trail and version history",
AFRelationship = AFRelationship.Supplement
};
// Create validation log
string validationLog = @"
on Report
=========
: CONTRACT-2026-00142
d: 2026-02-07T14:25:00Z
erformed:
ll required fields present
ignature blocks completed
ate formats valid
urrency amounts verified
egal clauses match template v2.1
atus: APPROVED FOR ARCHIVAL
byte[] validationBytes = System.Text.Encoding.UTF8.GetBytes(validationLog);
var validationConfig = new EmbedFileConfiguration(EmbedFileType.xml)
{
EmbedFileName = "validation-report.txt",
AFDesc = "Pre-archive validation report",
AFRelationship = AFRelationship.Supplement
};
// Embed both files
var embedFiles = new List<EmbedFileByte>
{
new EmbedFileByte(auditBytes, auditConfig),
new EmbedFileByte(validationBytes, validationConfig)
};
// Convert to PDF/A-3b with full audit trail
using var archivedContract = pdf.ConvertToPdfA(embedFiles, PdfAVersions.PdfA3b);
// Set archival metadata
archivedContract.MetaData.Title = "Executed Contract - CONTRACT-2026-00142";
archivedContract.MetaData.Author = "Contract Management System";
archivedContract.MetaData.Subject = "Fully executed agreement with audit trail";
archivedContract.MetaData.Keywords = "contract, executed, 2026, archived";
archivedContract.SaveAs("contract-archived-with-audit.pdf");Imports IronPdf
Imports System
Imports System.Collections.Generic
Imports System.Text.Json
' Load the final document to archive
Using pdf = PdfDocument.FromFile("executed-contract.pdf")
' Create audit trail data
Dim auditTrail = New With {
.DocumentId = "CONTRACT-2026-00142",
.CreatedDate = "2026-01-15T09:30:00Z",
.FinalizedDate = "2026-02-07T14:22:00Z",
.Versions = New Object() {
New With {.Version = 1, .Date = "2026-01-15", .Action = "Draft created", .User = "john.smith@company.com"},
New With {.Version = 2, .Date = "2026-01-20", .Action = "Legal review completed", .User = "legal@company.com"},
New With {.Version = 3, .Date = "2026-02-01", .Action = "Client revisions incorporated", .User = "john.smith@company.com"},
New With {.Version = 4, .Date = "2026-02-07", .Action = "Final execution", .User = "ceo@company.com"}
},
.Signatures = New Object() {
New With {.Signer = "Company CEO", .SignedDate = "2026-02-07T14:20:00Z", .IPAddress = "192.168.1.100"},
New With {.Signer = "Client Representative", .SignedDate = "2026-02-07T14:22:00Z", .IPAddress = "10.0.0.50"}
},
.Checksum = "SHA256:a1b2c3d4e5f6..."
}
Dim auditJson As String = JsonSerializer.Serialize(auditTrail, New JsonSerializerOptions With {.WriteIndented = True})
Dim auditBytes As Byte() = System.Text.Encoding.UTF8.GetBytes(auditJson)
' Configure audit trail attachment
Dim auditConfig As New EmbedFileConfiguration(EmbedFileType.xml) With {
.EmbedFileName = "audit-trail.json",
.AFDesc = "Complete document audit trail and version history",
.AFRelationship = AFRelationship.Supplement
}
' Create validation log
Dim validationLog As String = "
on Report
=========
: CONTRACT-2026-00142
d: 2026-02-07T14:25:00Z
erformed:
ll required fields present
ignature blocks completed
ate formats valid
urrency amounts verified
egal clauses match template v2.1
atus: APPROVED FOR ARCHIVAL
"
Dim validationBytes As Byte() = System.Text.Encoding.UTF8.GetBytes(validationLog)
Dim validationConfig As New EmbedFileConfiguration(EmbedFileType.xml) With {
.EmbedFileName = "validation-report.txt",
.AFDesc = "Pre-archive validation report",
.AFRelationship = AFRelationship.Supplement
}
' Embed both files
Dim embedFiles As New List(Of EmbedFileByte) From {
New EmbedFileByte(auditBytes, auditConfig),
New EmbedFileByte(validationBytes, validationConfig)
}
' Convert to PDF/A-3b with full audit trail
Using archivedContract = pdf.ConvertToPdfA(embedFiles, PdfAVersions.PdfA3b)
' Set archival metadata
archivedContract.MetaData.Title = "Executed Contract - CONTRACT-2026-00142"
archivedContract.MetaData.Author = "Contract Management System"
archivedContract.MetaData.Subject = "Fully executed agreement with audit trail"
archivedContract.MetaData.Keywords = "contract, executed, 2026, archived"
archivedContract.SaveAs("contract-archived-with-audit.pdf")
End Using
End UsingValidação da conformidade com PDF/A
Criar um documento e chamá-lo de PDF/A não é suficiente — você precisa verificar se a saída realmente atende aos requisitos do padrão. Um arquivo que afirma ser PDF/A, mas falha na validação, não será aceito por sistemas de arquivamento, portais governamentais ou plataformas de faturas eletrônicas.
Os métodos SaveAsPdfA e ConvertToPdfA do IronPDF lidam com o trabalho pesado da conversão de conformidade — incorporando fontes, convertendo espaços de cor, removendo recursos proibidos e escrevendo metadados XMP. No entanto, para verificação independente da saída, você deve validar usando ferramentas externas dedicadas como veraPDF (o validador PDF/A de código aberto padrão da indústria) ou a ferramenta Preflight integrada do Adobe Acrobat Pro. Integrar o veraPDF em seu pipeline CI/CD ou fluxo de trabalho de processamento de documentos oferece uma confirmação autoritativa de terceiros de que cada arquivo produzido atende ao padrão alegado antes de ser armazenado ou distribuído.
Falhas comuns de conformidade e suas soluções
Mesmo com o IronPDF cuidando da maior parte do trabalho de conformidade, certas condições de entrada podem gerar falhas de validação. Aqui estão os problemas mais comuns e como resolvê-los:
Fontes não incorporadas — Este é o erro mais comum. Se o PDF de origem referencia uma fonte pelo nome, mas não incorpora os dados da fonte, a saída não estará em conformidade com o PDF/A. O IronPDF tenta incorporar fontes automaticamente durante a conversão, mas se um arquivo de fonte não estiver disponível no sistema onde o IronPDF está rodando, a incorporação falhará. Correção: Certifique-se de que todas as fontes usadas nos seus documentos de origem estejam instaladas no servidor ou use fontes seguras para a web no seu conteúdo HTML que estejam universalmente disponíveis.
Espaços de cores não suportados — O PDF/A exige que todos os dados de cor sejam definidos em um perfil de cores específico e incorporado (normalmente sRGB para documentos orientados à tela ou um perfil CMYK para impressão). Os PDFs de origem que utilizam espaços de cores dependentes do dispositivo sem um perfil incorporado falharão na validação. Correção: O IronPDF agora realiza a conversão de espaço de cores automaticamente na maioria dos casos. Para casos extremos, certifique-se de que o conteúdo de origem especifique as cores em sRGB.
Criptografia ou proteção por senha — o PDF/A proíbe estritamente a criptografia. Se você estiver convertendo um PDF protegido por senha, primeiro deve descriptografá-lo. Correção: Use PdfDocument.FromFile("encrypted.pdf", "password") para abrir o arquivo protegido antes da conversão.
JavaScript ou conteúdo multimídia — O PDF/A proíbe JavaScript, áudio, vídeo e outros elementos interativos. Se o seu HTML de origem incluir tags <script>, vídeo incorporado ou formulários interativos, eles precisarão ser removidos ou a conversão os eliminará. Correção: Certifique-se de que seu conteúdo HTML seja estático antes de renderizá-lo para PDF/A.
Problemas de transparência (somente PDF/A-1) — O formato PDF/A-1 não suporta transparência. Se o seu documento contiver elementos transparentes (comuns em layouts CSS modernos), a conversão para PDF/A-1 exigirá o achatamento (ou achatamento). Correção: Alvo PDF/A-2 ou posterior se seus documentos usarem transparência, ou garanta que o CSS não use opacity, rgba ou PNGs transparentes ao direcionar o PDF/A-1.
Requisitos de fontes, espaços de cores e metadados
Compreender os três pilares da conformidade com o PDF/A — fontes, espaços de cores e metadados — ajuda você a criar documentos que passam na validação na primeira tentativa.
Fontes: Todas as fontes utilizadas no documento devem estar totalmente incorporadas. Isso inclui todos os glifos que aparecem no texto, não apenas um subconjunto. Para níveis de conformidade PDF/A-1a, PDF/A-2a e PDF/A-3a, cada caractere também deve ter um mapeamento Unicode, garantindo que o texto possa ser extraído e buscado com confiabilidade.
Ao usar a renderização de HTML-para-PDF do IronPDF, o mecanismo Chromium incorpora automaticamente as fontes que estão disponíveis no sistema. Para garantir consistência em diferentes ambientes de implantação (desenvolvimento, teste, produção), considere usar fontes do Google carregadas via tags <link> em seu HTML, ou empacotar arquivos de fontes com sua aplicação e referenciá-los via CSS @font-face.
Espaços de cor: O PDF/A exige que todas as cores sejam especificadas dentro de um espaço de cor independente de dispositivo, com suporte de um perfil ICC. Na prática, isso significa usar o sRGB para a maioria dos documentos. O IronPDF incorpora o perfil ICC apropriado e converte as cores automaticamente durante o processo SaveAsPdfA — você também pode passar um caminho de arquivo ICC personalizado se seu fluxo de trabalho exigir um perfil específico. No entanto, se você estiver trabalhando com documentos orientados para impressão que requerem precisão CMYK, garanta que seu conteúdo de origem use perfis adequados para CMYK e que estes sejam preservados durante a conversão.
Metadados: O formato PDF/A requer que os metadados XMP (Extensible Metadata Platform) sejam incorporados ao documento. Isso inclui o título do documento, o autor, a data de criação, a data de modificação e o identificador do nível de conformidade PDF/A. IronPDF preenche esses campos automaticamente, mas você também pode defini-los explicitamente através da propriedade MetaData para maior controle:
:path=/static-assets/pdf/content-code-examples/tutorials/pdfa-archiving-csharp/pdfa-metadata-settings.csusing IronPdf;
using System;
// Create a PDF document
var renderer = new ChromePdfRenderer();
using var pdf = renderer.RenderHtmlAsPdf("<h1>Annual Report 2025</h1><p>Corporate performance summary.</p>");
// Set standard metadata properties
pdf.MetaData.Title = "Annual Report 2025 - IronSoftware Inc.";
pdf.MetaData.Author = "Finance Department";
pdf.MetaData.Subject = "Corporate annual financial and operational report";
pdf.MetaData.Keywords = "annual report, financial, 2025, corporate, IronSoftware";
pdf.MetaData.Creator = "IronPDF Document Generator";
pdf.MetaData.CreationDate = DateTime.Now;
pdf.MetaData.ModifiedDate = DateTime.Now;
// For custom or batch metadata, use SetMetaDataDictionary
var metadataDict = new System.Collections.Generic.Dictionary<string, string>
{
{ "Title", "Quarterly Report Q4 2025" },
{ "Author", "Finance Team" },
{ "Subject", "Q4 Financial Results" },
{ "Keywords", "quarterly, Q4, 2025, finance" },
{ "Department", "Finance" },
{ "Classification", "Internal" },
{ "RetentionPeriod", "7 years" }
};
using var pdf2 = renderer.RenderHtmlAsPdf("<h1>Q4 Report</h1>");
pdf2.MetaData.SetMetaDataDictionary(metadataDict);
// Convert to PDF/A with metadata preserved
pdf.SaveAsPdfA("annual-report-2025.pdf", PdfAVersions.PdfA3b);
pdf2.SaveAsPdfA("q4-report-2025.pdf", PdfAVersions.PdfA3b);Imports IronPdf
Imports System
Imports System.Collections.Generic
' Create a PDF document
Dim renderer As New ChromePdfRenderer()
Using pdf = renderer.RenderHtmlAsPdf("<h1>Annual Report 2025</h1><p>Corporate performance summary.</p>")
' Set standard metadata properties
pdf.MetaData.Title = "Annual Report 2025 - IronSoftware Inc."
pdf.MetaData.Author = "Finance Department"
pdf.MetaData.Subject = "Corporate annual financial and operational report"
pdf.MetaData.Keywords = "annual report, financial, 2025, corporate, IronSoftware"
pdf.MetaData.Creator = "IronPDF Document Generator"
pdf.MetaData.CreationDate = DateTime.Now
pdf.MetaData.ModifiedDate = DateTime.Now
' For custom or batch metadata, use SetMetaDataDictionary
Dim metadataDict As New Dictionary(Of String, String) From {
{"Title", "Quarterly Report Q4 2025"},
{"Author", "Finance Team"},
{"Subject", "Q4 Financial Results"},
{"Keywords", "quarterly, Q4, 2025, finance"},
{"Department", "Finance"},
{"Classification", "Internal"},
{"RetentionPeriod", "7 years"}
}
Using pdf2 = renderer.RenderHtmlAsPdf("<h1>Q4 Report</h1>")
pdf2.MetaData.SetMetaDataDictionary(metadataDict)
' Convert to PDF/A with metadata preserved
pdf.SaveAsPdfA("annual-report-2025.pdf", PdfAVersions.PdfA3b)
pdf2.SaveAsPdfA("q4-report-2025.pdf", PdfAVersions.PdfA3b)
End Using
End UsingA definição explícita de metadados é especialmente importante para documentos que serão indexados por sistemas de gestão documental, uma vez que os campos de título e autor são frequentemente utilizados para catalogação e pesquisa.
Casos de uso para gerenciamento de registros governamentais
O PDF/A não é apenas uma especificação técnica — é um requisito prático em muitos contextos governamentais, jurídicos e de saúde. Nesta seção, veremos como o PDF/A se encaixa em estruturas regulatórias específicas e o que você precisa saber para atender aos seus requisitos usando o IronPDF.
Requisitos da NARA (Arquivos Nacionais dos EUA)
O Arquivo Nacional dos Estados Unidos (NARA) é responsável por preservar os registros federais de valor permanente. As diretrizes de transferência da NARA especificam o PDF/A como um dos formatos preferenciais para a transferência de registros eletrônicos permanentes para os Arquivos Nacionais.
Principais requisitos da NARA para submissões em formato PDF/A:
A NARA aceita os formatos PDF/A-1, PDF/A-2 e PDF/A-3 para a maioria dos tipos de registros. Os documentos devem ser validados em relação à versão PDF/A declarada antes da transferência. Os metadados devem incluir a agência criadora, o identificador da série de registros e o intervalo de datas abrangido. As fontes incorporadas são obrigatórias — o NARA rejeita explicitamente documentos com fontes ausentes ou que contenham apenas referências a elas. Para registros digitalizados (escaneados), o NARA recomenda uma resolução mínima de 300 DPI e prefere o formato PDF/A-2 ou posterior devido à melhor compressão de imagem.
Aqui está como você pode preparar um lote de registros de agência para transferência NARA:
Entrada
:path=/static-assets/pdf/content-code-examples/tutorials/pdfa-archiving-csharp/pdfa-nara-compliance.csusing IronPdf;
using System;
using System.IO;
string inputFolder = "agency-records/";
string validatedFolder = "nara-transfer/validated/";
string rejectedFolder = "nara-transfer/rejected/";
// Create output directories
Directory.CreateDirectory(validatedFolder);
Directory.CreateDirectory(rejectedFolder);
// NARA transfer metadata requirements
string agencyName = "Department of Example";
string recordSeries = "Administrative Correspondence";
string dateRange = "2020-2025";
// Process all PDF files in the input folder
string[] pdfFiles = Directory.GetFiles(inputFolder, "*.pdf");
Console.WriteLine($"Preparing {pdfFiles.Length} records for NARA transfer");
Console.WriteLine($"Agency: {agencyName}");
Console.WriteLine($"Record Series: {recordSeries}");
Console.WriteLine();
int successCount = 0;
int failCount = 0;
foreach (string inputPath in pdfFiles)
{
string fileName = Path.GetFileName(inputPath);
try
{
using var pdf = PdfDocument.FromFile(inputPath);
// Set NARA-required metadata
var metadata = new System.Collections.Generic.Dictionary<string, string>
{
{ "Title", Path.GetFileNameWithoutExtension(inputPath) },
{ "Author", agencyName },
{ "Subject", recordSeries },
{ "Keywords", $"NARA, {recordSeries}, {dateRange}" },
{ "Agency", agencyName },
{ "RecordSeries", recordSeries },
{ "DateRange", dateRange },
{ "TransferDate", DateTime.Now.ToString("yyyy-MM-dd") }
};
pdf.MetaData.SetMetaDataDictionary(metadata);
// Convert to PDF/A-2b (NARA preferred for digitized records)
string outputPath = Path.Combine(validatedFolder, fileName);
pdf.SaveAsPdfA(outputPath, PdfAVersions.PdfA2b);
// Verify the output
using var verifyPdf = PdfDocument.FromFile(outputPath);
if (verifyPdf.PageCount > 0)
{
successCount++;
Console.WriteLine($"[OK] {fileName}");
}
else
{
throw new Exception("Output PDF has no pages");
}
}
catch (Exception ex)
{
failCount++;
Console.WriteLine($"[FAILED] {fileName}: {ex.Message}");
// Move original to rejected folder for manual review
try
{
File.Copy(inputPath, Path.Combine(rejectedFolder, fileName), overwrite: true);
}
catch { }
}
}
Console.WriteLine();
Console.WriteLine("=== NARA Transfer Preparation Complete ===");
Console.WriteLine($"Successfully converted: {successCount}");
Console.WriteLine($"Failed (requires review): {failCount}");
Console.WriteLine($"Output location: {validatedFolder}");Imports IronPdf
Imports System
Imports System.IO
Module Program
Sub Main()
Dim inputFolder As String = "agency-records/"
Dim validatedFolder As String = "nara-transfer/validated/"
Dim rejectedFolder As String = "nara-transfer/rejected/"
' Create output directories
Directory.CreateDirectory(validatedFolder)
Directory.CreateDirectory(rejectedFolder)
' NARA transfer metadata requirements
Dim agencyName As String = "Department of Example"
Dim recordSeries As String = "Administrative Correspondence"
Dim dateRange As String = "2020-2025"
' Process all PDF files in the input folder
Dim pdfFiles As String() = Directory.GetFiles(inputFolder, "*.pdf")
Console.WriteLine($"Preparing {pdfFiles.Length} records for NARA transfer")
Console.WriteLine($"Agency: {agencyName}")
Console.WriteLine($"Record Series: {recordSeries}")
Console.WriteLine()
Dim successCount As Integer = 0
Dim failCount As Integer = 0
For Each inputPath As String In pdfFiles
Dim fileName As String = Path.GetFileName(inputPath)
Try
Using pdf = PdfDocument.FromFile(inputPath)
' Set NARA-required metadata
Dim metadata As New System.Collections.Generic.Dictionary(Of String, String) From {
{"Title", Path.GetFileNameWithoutExtension(inputPath)},
{"Author", agencyName},
{"Subject", recordSeries},
{"Keywords", $"NARA, {recordSeries}, {dateRange}"},
{"Agency", agencyName},
{"RecordSeries", recordSeries},
{"DateRange", dateRange},
{"TransferDate", DateTime.Now.ToString("yyyy-MM-dd")}
}
pdf.MetaData.SetMetaDataDictionary(metadata)
' Convert to PDF/A-2b (NARA preferred for digitized records)
Dim outputPath As String = Path.Combine(validatedFolder, fileName)
pdf.SaveAsPdfA(outputPath, PdfAVersions.PdfA2b)
' Verify the output
Using verifyPdf = PdfDocument.FromFile(outputPath)
If verifyPdf.PageCount > 0 Then
successCount += 1
Console.WriteLine($"[OK] {fileName}")
Else
Throw New Exception("Output PDF has no pages")
End If
End Using
End Using
Catch ex As Exception
failCount += 1
Console.WriteLine($"[FAILED] {fileName}: {ex.Message}")
' Move original to rejected folder for manual review
Try
File.Copy(inputPath, Path.Combine(rejectedFolder, fileName), overwrite:=True)
Catch
End Try
End Try
Next
Console.WriteLine()
Console.WriteLine("=== NARA Transfer Preparation Complete ===")
Console.WriteLine($"Successfully converted: {successCount}")
Console.WriteLine($"Failed (requires review): {failCount}")
Console.WriteLine($"Output location: {validatedFolder}")
End Sub
End ModuleSaída
Ao preparar registros para transferência NARA, é crítico validar cada arquivo individualmente. O processo de ingestão da NARA rejeitará arquivos não conformes, e reprocessar um grande lote é custoso tanto em tempo quanto em esforço. Incluir validação diretamente em seu pipeline de conversão — usando uma ferramenta como veraPDF após cada chamada SaveAsPdfA — é a abordagem mais confiável.
Arquivamento de documentos judiciais
O sistema judicial federal dos EUA e muitos sistemas judiciais estaduais utilizam sistemas de arquivamento eletrônico (principalmente CM/ECF em nível federal) que aceitam ou exigem PDF/A para a retenção de registros a longo prazo. Embora os requisitos exatos variem de acordo com a jurisdição, as expectativas gerais são consistentes:
Tribunais federais — O Escritório Administrativo dos Tribunais dos EUA recomenda o formato PDF/A para documentos que farão parte do registro permanente do processo. Os sistemas CM/ECF geralmente aceitam PDF/A-1b como padrão mínimo, embora PDF/A-2b seja cada vez mais preferido para documentos com formatação complexa.
Tribunais estaduais — Os requisitos variam muito. Alguns estados (como o Texas e a Califórnia) têm requisitos explícitos para o formato PDF/A em determinados tipos de documentos, enquanto outros simplesmente o recomendam como uma boa prática. É essencial verificar as regras específicas da jurisdição em questão.
Os requisitos comuns em todos os sistemas judiciais incluem:
Os documentos devem ser pesquisáveis por texto (não apenas imagens digitalizadas), o que significa usar conformidade PDF/A-1a ou PDF/A-2a quando possível, ou garantir que OCR foi aplicado a documentos digitalizados. Os tamanhos das páginas devem ser padrão (normalmente Carta dos EUA, 8,5" × 11"). Os metadados devem incluir o número do processo, a data de apresentação do documento e o tipo de documento, sempre que o sistema de arquivamento os suportar.
:path=/static-assets/pdf/content-code-examples/tutorials/pdfa-archiving-csharp/pdfa-court-filing.csusing IronPdf;
using System;
// Court filing configuration
string caseNumber = "1:26-cv-00142-ABC";
string courtName = "US District Court, Northern District";
string documentType = "Motion for Summary Judgment";
string filingParty = "Plaintiff";
// Create legal document HTML
string legalDocumentHtml = $@"
E html>
le>
body {{
font-family: 'Times New Roman', Times, serif;
font-size: 12pt;
line-height: 2;
margin: 1in;
}}
.header {{ text-align: center; margin-bottom: 24pt; }}
.case-caption {{
border: 1px solid black;
padding: 12pt;
margin: 24pt 0;
}}
.section {{ margin: 12pt 0; }}
h1 {{ font-size: 14pt; text-align: center; }}
.signature {{ margin-top: 48pt; }}
yle>
class='header'>
<strong>{courtName}</strong>
v>
class='case-caption'>
<p>ACME CORPORATION,<br> Plaintiff,</p>
<p>v.</p>
<p>EXAMPLE INDUSTRIES, INC.,<br> Defendant.</p>
<p style='text-align: right;'><strong>Case No. {caseNumber}</strong></p>
v>
{documentType.ToUpper()}</h1>
class='section'>
<p>Plaintiff ACME Corporation, by and through undersigned counsel, respectfully
moves this Court for summary judgment pursuant to Federal Rule of Civil Procedure 56...</p>
v>
class='section'>
<h2>I. INTRODUCTION</h2>
<p>This motion presents the Court with a straightforward question of contract interpretation...</p>
v>
class='signature'>
<p>Respectfully submitted,</p>
<p>_________________________<br>
Jane Attorney, Esq.<br>
Bar No. 12345<br>
Law Firm LLP<br>
123 Legal Street<br>
City, State 12345<br>
(555) 123-4567<br>
jane@lawfirm.com</p>
<p>Attorney for Plaintiff</p>
v>
;
// Render with court-appropriate settings
var renderer = new ChromePdfRenderer();
renderer.RenderingOptions.PaperSize = IronPdf.Rendering.PdfPaperSize.Letter;
renderer.RenderingOptions.MarginTop = 72;
renderer.RenderingOptions.MarginBottom = 72;
renderer.RenderingOptions.MarginLeft = 72;
renderer.RenderingOptions.MarginRight = 72;
using var pdf = renderer.RenderHtmlAsPdf(legalDocumentHtml);
// Set metadata for court filing system indexing
var metadata = new System.Collections.Generic.Dictionary<string, string>
{
{ "Title", $"{documentType} - {caseNumber}" },
{ "Author", "Law Firm LLP" },
{ "Subject", $"Court Filing - {caseNumber}" },
{ "CaseNumber", caseNumber },
{ "DocumentType", documentType },
{ "FilingParty", filingParty },
{ "FilingDate", DateTime.Now.ToString("yyyy-MM-dd") }
};
pdf.MetaData.SetMetaDataDictionary(metadata);
// Convert to PDF/A-2b (widely accepted by federal courts)
string outputPath = $"court-filing-{caseNumber.Replace(":", "-")}.pdf";
pdf.SaveAsPdfA(outputPath, PdfAVersions.PdfA2b);Imports IronPdf
Imports System
Imports System.Collections.Generic
' Court filing configuration
Dim caseNumber As String = "1:26-cv-00142-ABC"
Dim courtName As String = "US District Court, Northern District"
Dim documentType As String = "Motion for Summary Judgment"
Dim filingParty As String = "Plaintiff"
' Create legal document HTML
Dim legalDocumentHtml As String = $"
<!DOCTYPE html>
<html>
<head>
<style>
body {{
font-family: 'Times New Roman', Times, serif;
font-size: 12pt;
line-height: 2;
margin: 1in;
}}
.header {{ text-align: center; margin-bottom: 24pt; }}
.case-caption {{
border: 1px solid black;
padding: 12pt;
margin: 24pt 0;
}}
.section {{ margin: 12pt 0; }}
h1 {{ font-size: 14pt; text-align: center; }}
.signature {{ margin-top: 48pt; }}
</style>
</head>
<body>
<div class='header'>
<strong>{courtName}</strong>
</div>
<div class='case-caption'>
<p>ACME CORPORATION,<br> Plaintiff,</p>
<p>v.</p>
<p>EXAMPLE INDUSTRIES, INC.,<br> Defendant.</p>
<p style='text-align: right;'><strong>Case No. {caseNumber}</strong></p>
</div>
<h1>{documentType.ToUpper()}</h1>
<div class='section'>
<p>Plaintiff ACME Corporation, by and through undersigned counsel, respectfully
moves this Court for summary judgment pursuant to Federal Rule of Civil Procedure 56...</p>
</div>
<div class='section'>
<h2>I. INTRODUCTION</h2>
<p>This motion presents the Court with a straightforward question of contract interpretation...</p>
</div>
<div class='signature'>
<p>Respectfully submitted,</p>
<p>_________________________<br>
Jane Attorney, Esq.<br>
Bar No. 12345<br>
Law Firm LLP<br>
123 Legal Street<br>
City, State 12345<br>
(555) 123-4567<br>
jane@lawfirm.com</p>
<p>Attorney for Plaintiff</p>
</div>
</body>
</html>
"
' Render with court-appropriate settings
Dim renderer As New ChromePdfRenderer()
renderer.RenderingOptions.PaperSize = IronPdf.Rendering.PdfPaperSize.Letter
renderer.RenderingOptions.MarginTop = 72
renderer.RenderingOptions.MarginBottom = 72
renderer.RenderingOptions.MarginLeft = 72
renderer.RenderingOptions.MarginRight = 72
Using pdf = renderer.RenderHtmlAsPdf(legalDocumentHtml)
' Set metadata for court filing system indexing
Dim metadata As New Dictionary(Of String, String) From {
{"Title", $"{documentType} - {caseNumber}"},
{"Author", "Law Firm LLP"},
{"Subject", $"Court Filing - {caseNumber}"},
{"CaseNumber", caseNumber},
{"DocumentType", documentType},
{"FilingParty", filingParty},
{"FilingDate", DateTime.Now.ToString("yyyy-MM-dd")}
}
pdf.MetaData.SetMetaDataDictionary(metadata)
' Convert to PDF/A-2b (widely accepted by federal courts)
Dim outputPath As String = $"court-filing-{caseNumber.Replace(":", "-")}.pdf"
pdf.SaveAsPdfA(outputPath, PdfAVersions.PdfA2b)
End UsingSaída
Para escritórios de advocacia e empresas de tecnologia legal que constroem sistemas de gerenciamento de documentos, integrar a conversão PDF/A no fluxo de arquivamento garante que cada documento arquivado atenda aos requisitos de preservação a longo prazo do tribunal — sem intervenção manual de paralegais ou advogados.
Retenção de Registros Médicos
As organizações de saúde enfrentam requisitos rigorosos para a retenção de registros de pacientes. Embora a HIPAA não determine um formato de arquivo específico, a combinação de longos períodos de retenção (geralmente de 7 a 10 anos para adultos, e mais longos para menores), requisitos de acessibilidade e expectativas de auditoria torna o PDF/A a escolha natural para o arquivamento de documentos médicos.
Principais considerações para o arquivamento de registros médicos:
Períodos de retenção — As regulamentações federais e estaduais exigem que os registros médicos sejam mantidos por períodos variáveis, frequentemente superiores a 10 anos. A garantia de legibilidade a longo prazo do PDF/A o torna ideal para atender a esses requisitos sem se preocupar com a obsolescência de formato.
Acessibilidade — A Lei de Acessibilidade para Americanos com Deficiências (ADA) e a Seção 508 exigem que os registros médicos eletrônicos sejam acessíveis. Usar níveis de conformidade PDF/A-2a ou PDF/A-3a (que incluem marcação estrutural) ajuda a atender a esses requisitos de acessibilidade.
Interoperabilidade — Os registros médicos são frequentemente compartilhados entre prestadores de serviços, seguradoras e pacientes. A natureza autossuficiente do PDF/A garante que os documentos sejam renderizados de maneira consistente, independentemente do visualizador ou sistema usado para abri-los.
Preparação para auditorias — Auditorias na área da saúde podem exigir a apresentação de prontuários médicos anos após sua criação. O PDF/A garante que os documentos produzidos durante uma auditoria sejam idênticos aos originais, sem diferenças de renderização que possam levantar questões sobre a integridade dos documentos.
:path=/static-assets/pdf/content-code-examples/tutorials/pdfa-archiving-csharp/pdfa-medical-records.csusing IronPdf;
using System;
using System.Collections.Generic;
// Medical record metadata
string patientId = "MRN-2026-00847";
string documentType = "Discharge Summary";
string facility = "Metro General Hospital";
string department = "Internal Medicine";
DateTime encounterDate = new DateTime(2026, 2, 5);
// Create clinical document HTML
string clinicalDocumentHtml = $@"
E html>
ng='en'>
le>
body {{ font-family: Arial, sans-serif; margin: 40px; line-height: 1.6; }}
.header {{ border-bottom: 2px solid #2c3e50; padding-bottom: 15px; margin-bottom: 20px; }}
.patient-info {{ background: #ecf0f1; padding: 15px; margin: 15px 0; }}
.section {{ margin: 20px 0; }}
h1 {{ color: #2c3e50; }}
h2 {{ color: #3498db; font-size: 14pt; }}
.footer {{ margin-top: 40px; font-size: 10pt; color: #666; }}
yle>
class='header'>
<h1>{facility}</h1>
<p>{department} | {documentType}</p>
v>
class='patient-info'>
<p><strong>Patient ID:</strong> {patientId}</p>
<p><strong>Encounter Date:</strong> {encounterDate:MMMM d, yyyy}</p>
<p><strong>Attending Physician:</strong> Dr. Sarah Johnson, MD</p>
v>
class='section'>
<h2>Chief Complaint</h2>
<p>Patient presented with acute respiratory symptoms including shortness of breath and persistent cough.</p>
v>
class='section'>
<h2>Hospital Course</h2>
<p>Patient was admitted for observation and treatment. Symptoms improved with standard protocol...</p>
v>
class='section'>
<h2>Discharge Instructions</h2>
<ul>
<li>Continue prescribed medications as directed</li>
<li>Follow up with primary care physician within 7 days</li>
<li>Return to ED if symptoms worsen</li>
</ul>
v>
class='footer'>
<p>Document generated: {DateTime.Now:yyyy-MM-dd HH:mm}</p>
<p>This document is archived in PDF/A-3a format for accessibility and long-term preservation.</p>
v>
;
var renderer = new ChromePdfRenderer();
using var pdf = renderer.RenderHtmlAsPdf(clinicalDocumentHtml);
// Set comprehensive metadata for medical records management
var metadata = new System.Collections.Generic.Dictionary<string, string>
{
{ "Title", $"{documentType} - {patientId}" },
{ "Author", "Metro General Hospital EHR System" },
{ "Subject", $"Clinical documentation for patient {patientId}" },
{ "PatientMRN", patientId },
{ "DocumentType", documentType },
{ "Facility", facility },
{ "Department", department },
{ "EncounterDate", encounterDate.ToString("yyyy-MM-dd") },
{ "RetentionCategory", "Medical Record - Adult" },
{ "RetentionPeriod", "10 years from last encounter" }
};
pdf.MetaData.SetMetaDataDictionary(metadata);
// Embed clinical data (HL7 FHIR format)
string fhirData = @"{
sourceType"": ""DocumentReference"",
atus"": ""current"",
pe"": { ""text"": ""Discharge Summary"" },
bject"": { ""reference"": ""Patient/MRN-2026-00847"" }
byte[] fhirBytes = System.Text.Encoding.UTF8.GetBytes(fhirData);
var fhirConfig = new EmbedFileConfiguration(EmbedFileType.xml)
{
EmbedFileName = "clinical-data.json",
AFDesc = "FHIR DocumentReference metadata",
AFRelationship = AFRelationship.Data
};
var embedFiles = new List<EmbedFileByte>
{
new EmbedFileByte(fhirBytes, fhirConfig)
};
// Convert to PDF/A-3a (accessible archival with embedded data)
using var archivedRecord = pdf.ConvertToPdfA(embedFiles, PdfAVersions.PdfA3a);
string outputPath = $"medical-record-{patientId}-{encounterDate:yyyyMMdd}.pdf";
archivedRecord.SaveAs(outputPath);Imports IronPdf
Imports System
Imports System.Collections.Generic
Imports System.Text
' Medical record metadata
Dim patientId As String = "MRN-2026-00847"
Dim documentType As String = "Discharge Summary"
Dim facility As String = "Metro General Hospital"
Dim department As String = "Internal Medicine"
Dim encounterDate As DateTime = New DateTime(2026, 2, 5)
' Create clinical document HTML
Dim clinicalDocumentHtml As String = $"
<!DOCTYPE html>
<html lang='en'>
<head>
<style>
body {{ font-family: Arial, sans-serif; margin: 40px; line-height: 1.6; }}
.header {{ border-bottom: 2px solid #2c3e50; padding-bottom: 15px; margin-bottom: 20px; }}
.patient-info {{ background: #ecf0f1; padding: 15px; margin: 15px 0; }}
.section {{ margin: 20px 0; }}
h1 {{ color: #2c3e50; }}
h2 {{ color: #3498db; font-size: 14pt; }}
.footer {{ margin-top: 40px; font-size: 10pt; color: #666; }}
</style>
</head>
<body>
<div class='header'>
<h1>{facility}</h1>
<p>{department} | {documentType}</p>
</div>
<div class='patient-info'>
<p><strong>Patient ID:</strong> {patientId}</p>
<p><strong>Encounter Date:</strong> {encounterDate:MMMM d, yyyy}</p>
<p><strong>Attending Physician:</strong> Dr. Sarah Johnson, MD</p>
</div>
<div class='section'>
<h2>Chief Complaint</h2>
<p>Patient presented with acute respiratory symptoms including shortness of breath and persistent cough.</p>
</div>
<div class='section'>
<h2>Hospital Course</h2>
<p>Patient was admitted for observation and treatment. Symptoms improved with standard protocol...</p>
</div>
<div class='section'>
<h2>Discharge Instructions</h2>
<ul>
<li>Continue prescribed medications as directed</li>
<li>Follow up with primary care physician within 7 days</li>
<li>Return to ED if symptoms worsen</li>
</ul>
</div>
<div class='footer'>
<p>Document generated: {DateTime.Now:yyyy-MM-dd HH:mm}</p>
<p>This document is archived in PDF/A-3a format for accessibility and long-term preservation.</p>
</div>
</body>
</html>"
Dim renderer As New ChromePdfRenderer()
Using pdf = renderer.RenderHtmlAsPdf(clinicalDocumentHtml)
' Set comprehensive metadata for medical records management
Dim metadata As New Dictionary(Of String, String) From {
{"Title", $"{documentType} - {patientId}"},
{"Author", "Metro General Hospital EHR System"},
{"Subject", $"Clinical documentation for patient {patientId}"},
{"PatientMRN", patientId},
{"DocumentType", documentType},
{"Facility", facility},
{"Department", department},
{"EncounterDate", encounterDate.ToString("yyyy-MM-dd")},
{"RetentionCategory", "Medical Record - Adult"},
{"RetentionPeriod", "10 years from last encounter"}
}
pdf.MetaData.SetMetaDataDictionary(metadata)
' Embed clinical data (HL7 FHIR format)
Dim fhirData As String = "{
""resourceType"": ""DocumentReference"",
""status"": ""current"",
""type"": { ""text"": ""Discharge Summary"" },
""subject"": { ""reference"": ""Patient/MRN-2026-00847"" }
}"
Dim fhirBytes As Byte() = Encoding.UTF8.GetBytes(fhirData)
Dim fhirConfig As New EmbedFileConfiguration(EmbedFileType.xml) With {
.EmbedFileName = "clinical-data.json",
.AFDesc = "FHIR DocumentReference metadata",
.AFRelationship = AFRelationship.Data
}
Dim embedFiles As New List(Of EmbedFileByte) From {
New EmbedFileByte(fhirBytes, fhirConfig)
}
' Convert to PDF/A-3a (accessible archival with embedded data)
Using archivedRecord = pdf.ConvertToPdfA(embedFiles, PdfAVersions.PdfA3a)
Dim outputPath As String = $"medical-record-{patientId}-{encounterDate:yyyyMMdd}.pdf"
archivedRecord.SaveAs(outputPath)
End Using
End UsingSaída
Para sistemas de registro eletrônico de saúde (EHR), a abordagem mais eficaz é converter documentos para PDF/A no momento da criação — quando os resultados de exames laboratoriais são gerados, quando as anotações clínicas são finalizadas ou quando os resumos de alta são produzidos. Essa estratégia de "arquivamento na criação" evita o custo e a complexidade da migração em lote posteriormente.
Próximos passos
Arquivar documentos no formato PDF/A não precisa ser complexo. O IronPDF oferece aos desenvolvedores .NET um conjunto completo de ferramentas para criar, converter e enriquecer documentos compatíveis com PDF/A — tudo dentro do ecossistema familiar do C#. Quer você esteja gerando documentos arquivísticos de HTML, produzindo PDFs acessíveis para distribuição governamental e de saúde, convertendo PDFs legados para armazenamento a longo prazo, ou integrando validação externa em um pipeline de lote de alto volume, o IronPDF lida com os detalhes técnicos para que você possa se concentrar nos requisitos da sua aplicação.
Do padrão fundamental PDF/A-1 às capacidades modernas do PDF/A-3 e PDF/A-4, IronPDF suporta toda a gama de versões de arquivamento e níveis de conformidade — incluindo PDF/A-1a, PDF/A-1b, PDF/A-2a, PDF/A-2b, PDF/A-3a, PDF/A-3b, PDF/A-4, PDF/A-4e e PDF/A-4f. O guia prático dedicado ao PDF/A aborda detalhadamente as opções de conversão e os níveis de conformidade. Combinado com gestão de metadados, incorporação de arquivos via EmbedFileConfiguration e suporte a ZUGFeRD/Factur-X e-invoicing, fornece tudo o que você precisa para atender aos requisitos de arquivamento de agências governamentais, sistemas judiciais, organizações de saúde e instituições financeiras.
Pronto para começar a arquivar? Baixe o IronPDF e experimente com um teste gratuito. Se você tiver perguntas ou quiser discutir seu cenário específico de conformidade, entre em contato com nossa equipe de suporte técnico — estamos felizes em ajudá-lo a acertar.
Perguntas frequentes
O que é a conformidade com o padrão PDF/A?
A conformidade com o PDF/A refere-se à versão padronizada pela ISO do PDF, especificamente projetada para arquivamento e preservação a longo prazo de documentos eletrônicos. Ela garante que os documentos possam ser reproduzidos da mesma maneira nos anos vindouros.
Como posso criar documentos compatíveis com PDF/A usando C#?
Você pode criar documentos compatíveis com PDF/A usando C#, utilizando a biblioteca IronPDF, que fornece ferramentas robustas para gerar e converter PDFs em vários formatos PDF/A.
Quais são as diferentes versões de PDF/A suportadas pelo IronPDF?
O IronPDF suporta várias versões de PDF/A, incluindo PDF/A-1, PDF/A-2 e PDF/A-3, cada uma atendendo a diferentes requisitos de arquivamento e preservação de documentos.
O IronPDF pode ajudar na incorporação de dados de origem para padrões de faturamento eletrônico como ZUGFeRD e Factur-X?
Sim, o IronPDF pode incorporar dados de origem para padrões de faturamento eletrônico, como ZUGFeRD e Factur-X, para facilitar o processamento e a conformidade de faturas eletrônicas.
Como posso validar a conformidade com o padrão PDF/A em C#?
Você pode validar a conformidade com o padrão PDF/A usando o IronPDF em C# aproveitando suas ferramentas de validação integradas para garantir que seus documentos estejam em conformidade com as especificações PDF/A desejadas.
É possível lidar com cenários de arquivamento governamental usando o IronPDF?
Sim, o IronPDF é capaz de lidar com diversos cenários de arquivamento governamental, incluindo a conformidade com os padrões exigidos pelo NARA (Arquivo Nacional de Arquivos dos Estados Unidos), documentos judiciais e registros médicos.
Quais são os benefícios de usar o formato PDF/A para arquivamento?
As vantagens de usar o PDF/A para arquivamento incluem garantir a fidelidade do documento ao longo do tempo, fornecer um formato padronizado para preservação a longo prazo e atender aos requisitos legais e organizacionais.
O IronPDF suporta a conversão de PDFs existentes para o formato PDF/A?
O IronPDF permite a conversão de PDFs existentes para o formato PDF/A, facilitando a conformidade e a preservação de documentos a longo prazo.
Como o IronPDF garante a fidelidade do documento nas conversões de PDF/A?
O IronPDF garante a fidelidade dos documentos em conversões para PDF/A, mantendo a integridade das fontes, imagens e layout, para que os documentos arquivados apareçam exatamente como foram concebidos.
Posso usar o IronPDF para arquivar registros médicos?
Sim, o IronPDF pode ser usado para arquivamento de registros médicos, ajudando a garantir a conformidade com os padrões e regulamentos do setor para preservação de documentos.


Ainda está rolando a tela?
Quer provas rápidas? PM > Install-Package IronPdf
executar um exemplo Veja seu HTML se transformar em um PDF.










