


Extract Embedded Text and Images from PDFs in C
Extraia conteúdo de texto e imagens de documentos PDF em C# com chamadas de método simples. Recupere o conteúdo incorporado para edição, análise ou reutilização em outros aplicativos.
A extração de texto e imagem recupera conteúdo textual e elementos gráficos de documentos PDF. Acesse e reutilize conteúdo para editar, pesquisar, converter texto para outros formatos ou salvar imagens para reutilização. Seja para analisar PDFs em C# para análise de dados, converter conteúdo para formatos pesquisáveis ou extrair elementos visuais para arquivamento, o IronPDF oferece ferramentas de extração abrangentes.
Extraia texto e imagens usando o IronPDF. Salve as imagens extraídas no disco ou converta-as para outro formato antes de incorporá-las em novos documentos. Essa flexibilidade suporta fluxos de trabalho que exigem transformação de conteúdo, como a conversão de PDFs em HTML ou a reutilização de imagens extraídas.
Início rápido: Extrair texto e imagens com o IronPDF
Extraia texto e imagens de PDFs com apenas algumas linhas de código. Este guia rápido demonstra como recuperar conteúdo incorporado de documentos PDF para reutilização e análise de conteúdo. Extraia texto para edição ou salve imagens para uso posterior com a solução simplificada do IronPDF.
-
Instale IronPDF com o Gerenciador de Pacotes NuGet
-
Copie e execute este trecho de código.
var pdf = new IronPdf.PdfDocument("sample.pdf"); string text = pdf.ExtractAllText(); var images = pdf.ExtractAllImages(); -
Implante para testar em seu ambiente de produção.
Comece a usar IronPDF em seu projeto hoje com uma avaliação gratuita

Fluxo de trabalho mínimo (5 etapas)
- Baixe a Biblioteca
IronPdfpara C# - Prepare o documento PDF para extração de texto e imagem.
- Utilize o método
ExtractAllTextpara extrair o texto. - Utilize o método
ExtractAllImagespara extrair imagens. - Especifique as páginas específicas das quais deseja extrair o texto e as imagens.
Como extrair texto de PDFs?
Extrair texto de documentos PDF, tanto recém-renderizados quanto já existentes. Use o método ExtractAllText para extrair texto incorporado do documento. O método retorna uma string contendo todo o texto do PDF. As páginas são separadas por quatro caracteres de nova linha consecutivos. Este exemplo utiliza um PDF de amostra gerado a partir do site da Wikipédia.
Ao trabalhar com PDFs que contêm idiomas internacionais e caracteres UTF-8 , o IronPDF mantém a codificação e a representação de caracteres adequadas. Isso garante a exibição correta de alfabetos não latinos e caracteres especiais.
:path=/static-assets/pdf/content-code-examples/how-to/extract-text-and-images-extract-text.csusing IronPdf;
using System.IO;
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract text
string text = pdf.ExtractAllText();
// Export the extracted text to a text file
File.WriteAllText("extractedText.txt", text);Imports IronPdf
Imports System.IO
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract text
Private text As String = pdf.ExtractAllText()
' Export the extracted text to a text file
File.WriteAllText("extractedText.txt", text)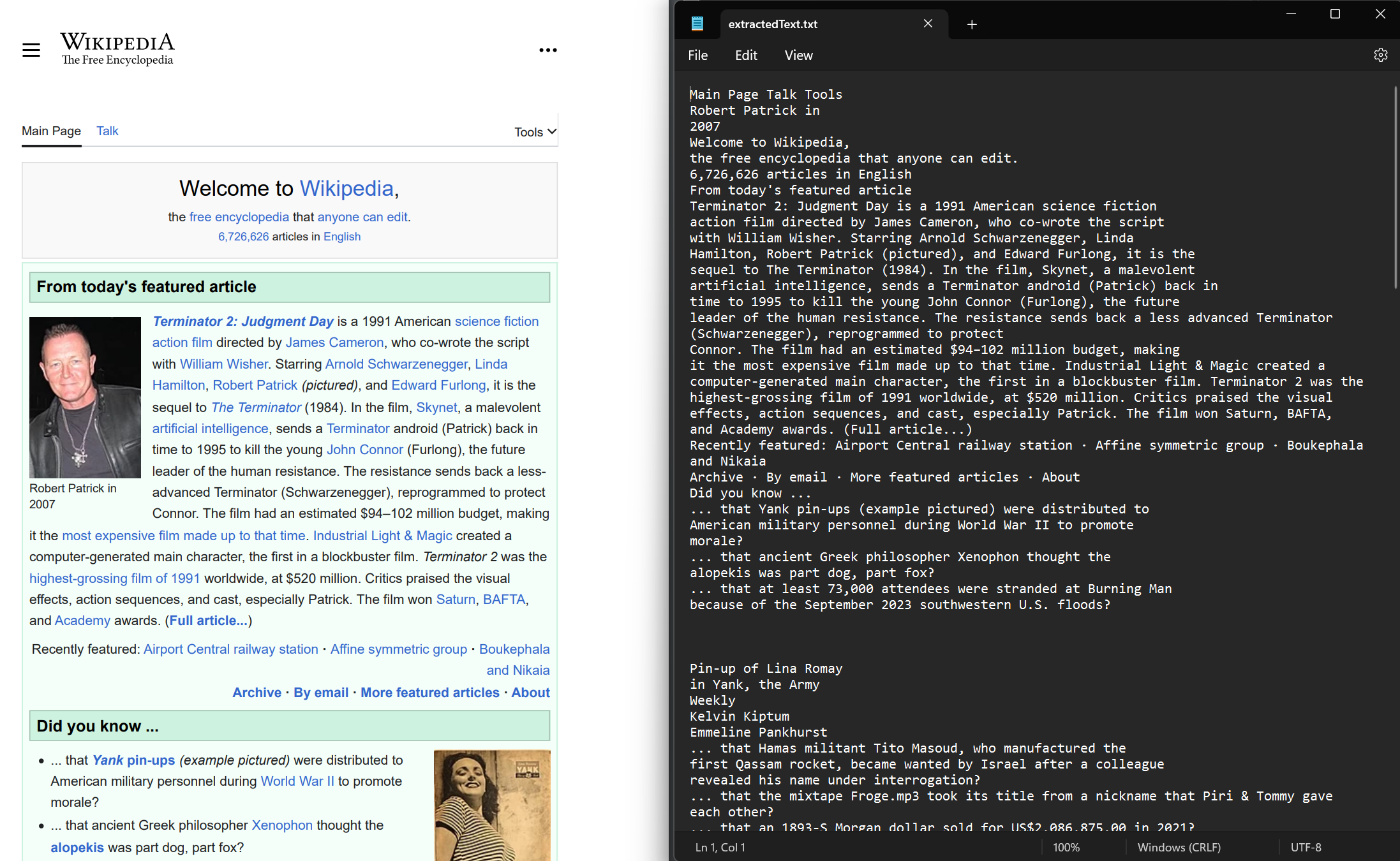
Como posso extrair texto com coordenadas precisas?
Recupere as coordenadas das linhas de texto e dos caracteres em cada página do PDF. Selecione uma página do PDF e acesse as propriedades Lines e Characters. As coordenadas incluem valores Top, Right, Bottom e Left representando a posição do texto. Essa funcionalidade preserva o layout espacial e permite a análise da posição do texto.
Para desenvolvedores que precisam ler arquivos PDF em C# com reconhecimento de posição, a extração de coordenadas fornece dados para manter a estrutura do documento e implementar análises de texto avançadas.
:path=/static-assets/pdf/content-code-examples/how-to/extract-text-and-images-extract-text-by-line-character.csusing IronPdf;
using System.IO;
using System.Linq;
// Open PDF from file
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract text by lines
var lines = pdf.Pages[0].Lines;
// Extract text by characters
var characters = pdf.Pages[0].Characters;
File.WriteAllLines("lines.txt", lines.Select(l => $"at Y={l.BoundingBox.Bottom:F2}: {l.Contents}"));Imports IronPdf
Imports System.IO
Imports System.Linq
' Open PDF from file
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract text by lines
Private lines = pdf.Pages(0).Lines
' Extract text by characters
Private characters = pdf.Pages(0).Characters
File.WriteAllLines("lines.txt", lines.Select(Function(l) $"at Y={l.BoundingBox.Bottom:F2}: {l.Contents}"))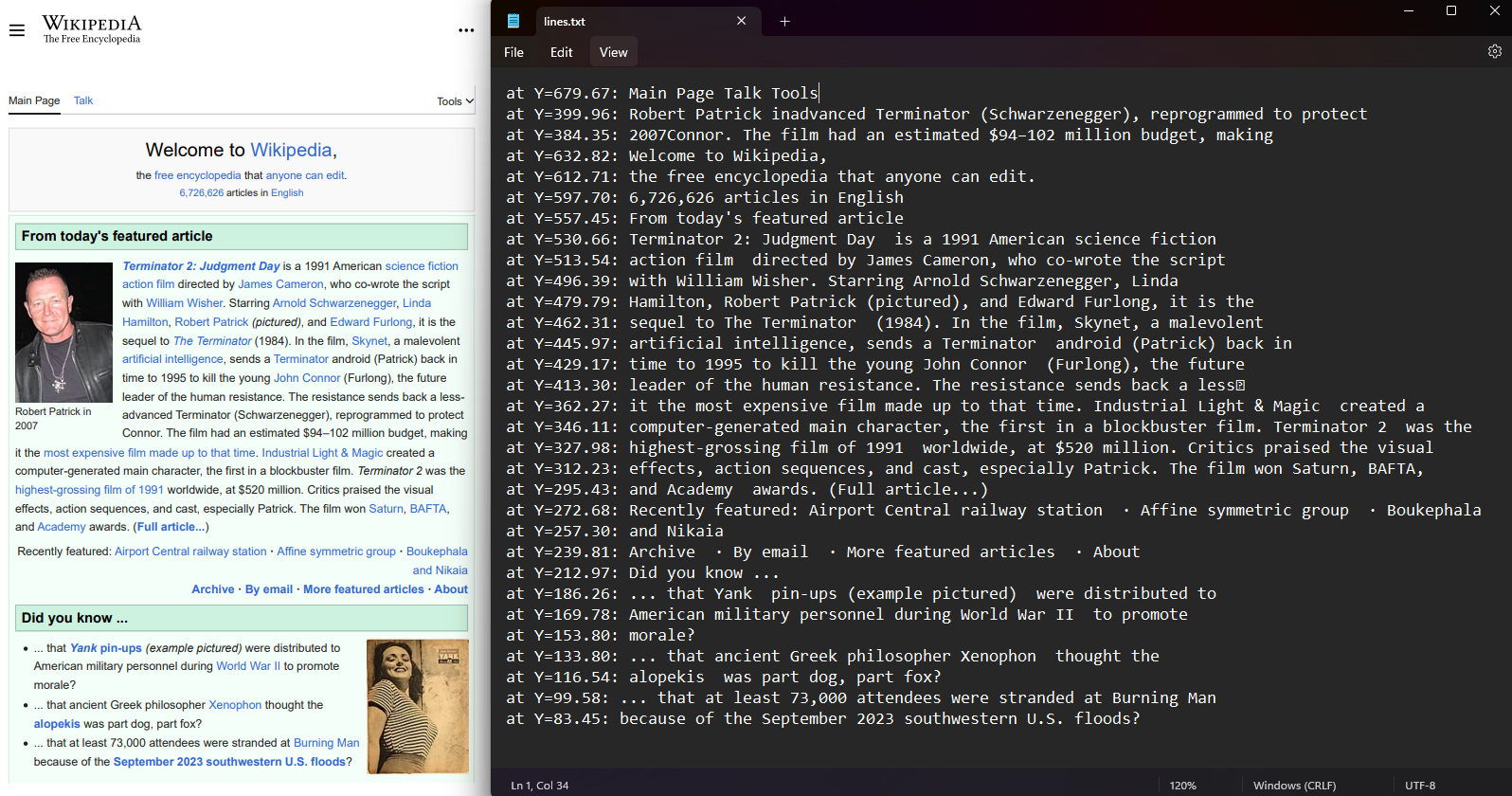
Minha biblioteca favorita desse tipo é o IronPDF. Ele permite a manipulação rápida e eficiente de arquivos PDF. Além disso, possui muitos recursos valiosos, como a exportação para o formato PDF/A e a assinatura digital de documentos PDF.
Com o IronOCR, podemos economizar US$ 40.000 por ano em processamento manual, ao mesmo tempo que aumentamos a produtividade e liberamos recursos para tarefas de alto impacto. Eu o recomendo fortemente.
O IronSuite desempenha um papel crucial nas nossas operações. Estas são ferramentas que aumentam a eficiência no negócio, incluindo a criação de plantas baixas e melhoria na gestão de inventário.
Como extrair imagens de PDFs?
Use o método ExtractAllImages para extrair todas as imagens incorporadas do documento. O método retorna imagens como uma lista de List de objetos AnyBitmap. Utilizando o mesmo documento, extraímos as imagens e as exportamos para a pasta 'imagens'. Essa funcionalidade oferece suporte ao arquivamento de imagens, migração de conteúdo e rasterização de páginas PDF em imagens para processamento posterior.
As imagens extraídas mantêm a qualidade original e podem ser salvas em vários formatos, incluindo PNG, JPEG e BMP. Para fluxos de trabalho de armazenamento em nuvem, integre essa funcionalidade ao Azure Blob Storage para gerenciamento de imagens .
:path=/static-assets/pdf/content-code-examples/how-to/extract-text-and-images-extract-image.csusing IronPdf;
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract images
var images = pdf.ExtractAllImages();
for(int i = 0; i < images.Count; i++)
{
// Export the extracted images
images[i].SaveAs($"images/image{i}.png");
}Imports IronPdf
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract images
Private images = pdf.ExtractAllImages()
For i As Integer = 0 To images.Count - 1
' Export the extracted images
images(i).SaveAs($"images/image{i}.png")
Next i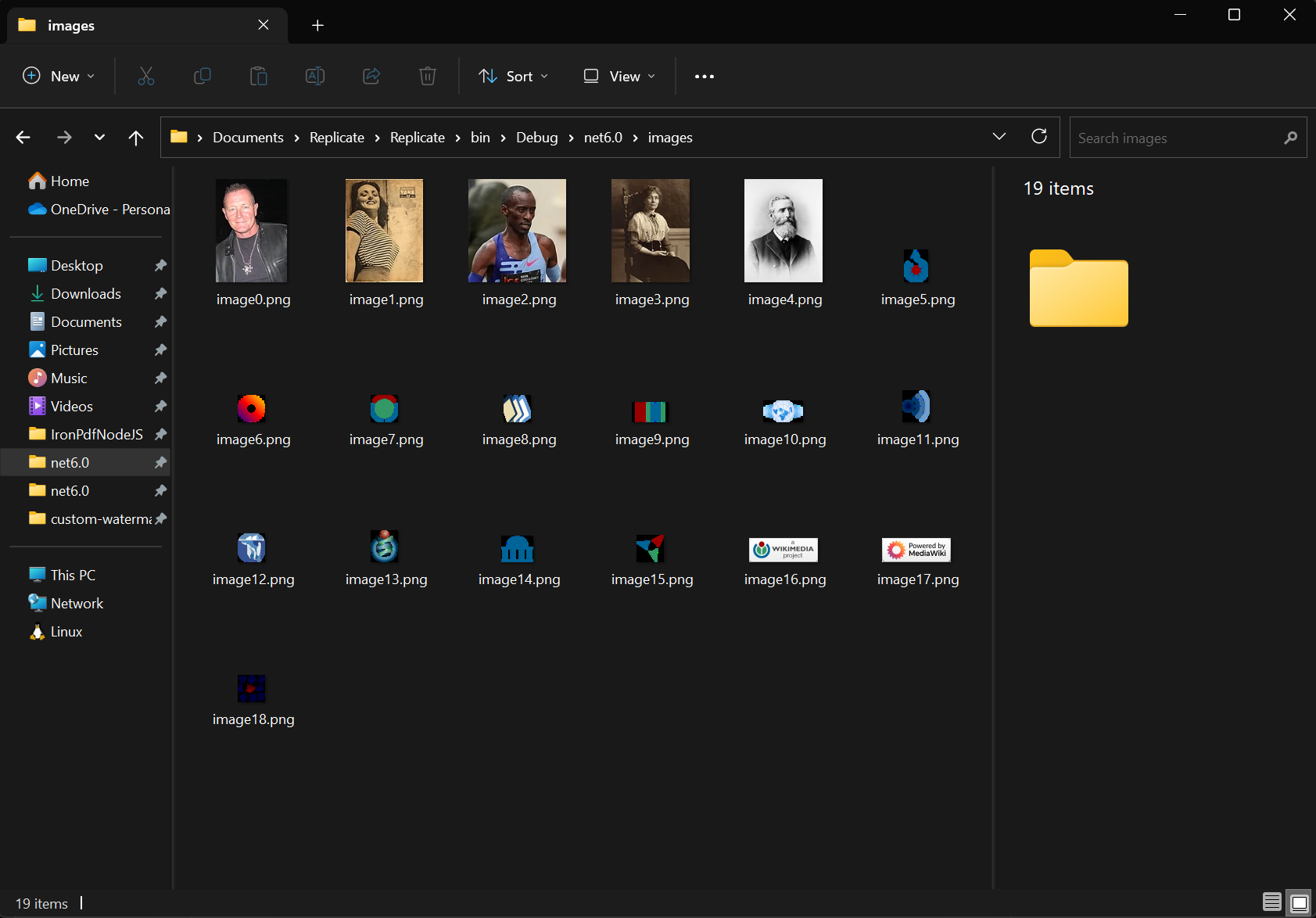
Quais são os diferentes métodos para extração de imagens?
Além do método ExtractAllImages, use os métodos ExtractAllBitmaps e ExtractAllRawImages para extrair informações de imagem. Enquanto ExtractAllBitmaps retorna um List de AnyBitmap, ExtractAllRawImages extrai todas as imagens e as retorna como byte[] bruto (byte[]).
O método ExtractAllRawImages funciona bem ao processar dados de imagem na memória ou integrar com sistemas que exigem entradas de matriz de bytes. Para cenários que envolvem a exportação de PDFs para fluxos de memória , o formato de matriz de bytes brutos oferece flexibilidade ideal.
Como extrair conteúdo de páginas específicas de um PDF?
Extrair texto e imagens de uma ou várias páginas especificadas. Use os métodos ExtractTextFromPage e ExtractTextFromPages para extração de texto de uma ou várias páginas. Para imagens, use os métodos ExtractImagesFromPage e ExtractImagesFromPages.
Esse controle granular é útil ao trabalhar com documentos extensos, onde apenas seções específicas contêm conteúdo relevante. Ele também oferece recursos para dividir PDFs e extrair páginas individuais para processamento separado.
:path=/static-assets/pdf/content-code-examples/how-to/extract-text-and-images-extract-text-single-multiple.csusing IronPdf;
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract text from page 1
string textFromPage1 = pdf.ExtractTextFromPage(0);
int[] pages = new[] { 0, 2 };
// Extract text from pages 1 & 3
string textFromPage1_3 = pdf.ExtractTextFromPages(pages);Imports IronPdf
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract text from page 1
Private textFromPage1 As String = pdf.ExtractTextFromPage(0)
Private pages() As Integer = { 0, 2 }
' Extract text from pages 1 & 3
Private textFromPage1_3 As String = pdf.ExtractTextFromPages(pages)Quando devo extrair dados de páginas específicas em vez de todas as páginas?
Extrair de páginas específicas quando:
- Trabalhando com grandes PDFs contendo dados relevantes em certas seções
- Implementando fluxos de trabalho que lidam com páginas de forma independente
- Construindo aplicações que exigem exibição ou processamento incremental de conteúdo
- Otimizando o uso de memória processando apenas as páginas necessárias
- Criar funcionalidades de pesquisa ou indexação específicas para cada página
Que aspectos de desempenho devo levar em consideração?
Considere estes fatores de desempenho ao extrair conteúdo de PDFs:
- Uso de Memória: Extraia páginas individualmente de documentos grandes para minimizar o consumo de memória
- Tempo de Processamento: Use o processamento paralelo para extrações de várias páginas quando apropriado
- Tamanho do Arquivo: PDFs maiores com imagens em alta resolução requerem mais tempo de processamento
- Armazenamento: Planeje espaço suficiente em disco para extrair inúmeras imagens de alta resolução
- Threading: O IronPDF suporta operações multi-threaded para melhorar o desempenho em sistemas multi-core
Para obter o melhor desempenho com PDFs em memória, use operações de fluxo de memória para reduzir a sobrecarga de E/S de disco.
Perguntas frequentes
Como extrair texto de documentos PDF em C#?
Utilize o método ExtractAllText do IronPDF para extrair texto incorporado de documentos PDF. O método retorna uma string contendo todo o texto do PDF, com as páginas separadas por quatro caracteres de nova linha consecutivos. O IronPDF mantém a codificação adequada para idiomas internacionais e caracteres UTF-8.
Posso extrair imagens de arquivos PDF programaticamente?
Sim, o IronPDF oferece o método ExtractAllImages para recuperar elementos gráficos de documentos PDF. Você pode salvar as imagens extraídas no disco ou convertê-las para outros formatos antes de incorporá-las em novos documentos.
Quais são os principais casos de uso para extração de conteúdo de PDF?
As ferramentas de extração do IronPDF suportam vários fluxos de trabalho, incluindo a análise de PDFs para análise de dados, a conversão de conteúdo para formatos pesquisáveis, a extração de elementos visuais para arquivamento e a reutilização de conteúdo para edição ou transformação em outros formatos, como HTML.
Quantas linhas de código são necessárias para extrair o conteúdo de um PDF?
Com o IronPDF, você pode extrair texto e imagens com apenas algumas linhas de código. Basta carregar seu documento PDF e chamar ExtractAllText() para extrair texto ou ExtractAllImages() para extrair imagens.
Posso extrair conteúdo de páginas específicas em vez do documento inteiro?
Sim, o IronPDF permite especificar páginas específicas das quais extrair texto e imagens, oferecendo controle preciso sobre qual conteúdo recuperar de seus documentos PDF.


Ainda está rolando a tela?
Quer provas rápidas? PM > Install-Package IronPdf
executar um exemplo Veja seu HTML se transformar em um PDF.










