


Extract Embedded Text and Images from PDFs in C
Wyodrębnij zarówno zawartość tekstową, jak i obrazy z dokumentów PDF w C# za pomocą prostych wywołań metod. Pobierz osadzone treści do edycji, analizy lub ponownego wykorzystania w innych aplikacjach.
Wyodrębnianie tekstu i obrazów pobiera zawartość tekstową i graficzne elementy z dokumentów PDF. Uzyskaj dostęp do zawartości i przekształcaj ją do edycji, wyszukiwania, konwersji tekstu na inne formaty lub zapisywania obrazów do ponownego użycia. Niezależnie od tego, czy chcesz parsować PDF-y w C# do analizy danych, konwertować zawartość do formatów umożliwiających wyszukiwanie, czy wyodrębniać elementy wizualne do archiwizacji, IronPDF dostarcza kompleksowe narzędzia do wyodrębniania.
Wyodrębnianie tekstu i obrazów przy użyciu IronPDF. Zapisz wyodrębnione obrazy na dysku lub przekonwertuj je na inny format przed osadzeniem w nowych dokumentach. Ta elastyczność wspiera przepływy pracy wymagające transformacji treści, takie jak konwersja PDF-ów do HTML lub ponowne wykorzystanie wyodrębnionych obrazów.
Quickstart: Wyodrębnianie tekstu i obrazów przy użyciu IronPDF
Wyodrębnij tekst i obrazy z PDF-ów w zaledwie kilku liniach kodu. Ten szybki start pokazuje, jak pobrać osadzone treści z dokumentów PDF do ponownego wykorzystania treści i analizy. Wyodrębnij tekst do edycji lub zapisz obrazy do dalszego wykorzystania dzięki uproszczonemu rozwiązaniu IronPDF.
-
Install IronPDF with NuGet Package Manager
-
Skopiuj i uruchom ten fragment kodu.
var pdf = new IronPdf.PdfDocument("sample.pdf"); string text = pdf.ExtractAllText(); var images = pdf.ExtractAllImages(); -
Wdrożenie do testowania w środowisku produkcyjnym
Rozpocznij używanie IronPDF w swoim projekcie już dziś z darmową wersją próbną

Minimalny proces (5 kroków)
- Pobierz bibliotekę C#
IronPdf - Przygotuj dokument PDF do wyodrębniania tekstu i obrazów
- Użyj metody
ExtractAllTextdo wyodrębniania tekstu - Użyj metody
ExtractAllImagesdo wyodrębniania obrazów - Określ konkretne strony, z których należy wyodrębnić tekst i obrazy
Jak wyodrębnić tekst z plików PDF?
Wyodrębnij tekst zarówno z nowo renderowanych, jak i istniejących dokumentów PDF. Użyj metody ExtractAllText, aby wyodrębnić osadzony tekst z dokumentu. Metoda zwraca ciąg zawierający cały tekst w PDF. Strony są oddzielone czterema kolejnymi znakami nowej linii. Ten przykład używa przykładowego PDF renderowanego ze strony Wikipedii.
Pracując z PDF-ami zawierającymi międzynarodowe języki i znaki UTF-8, IronPDF zachowuje odpowiednie kodowanie i reprezentację znaków. Zapewnia to poprawne wyświetlanie pism niełacińskich i znaków specjalnych.
:path=/static-assets/pdf/content-code-examples/how-to/extract-text-and-images-extract-text.csusing IronPdf;
using System.IO;
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract text
string text = pdf.ExtractAllText();
// Export the extracted text to a text file
File.WriteAllText("extractedText.txt", text);Imports IronPdf
Imports System.IO
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract text
Private text As String = pdf.ExtractAllText()
' Export the extracted text to a text file
File.WriteAllText("extractedText.txt", text)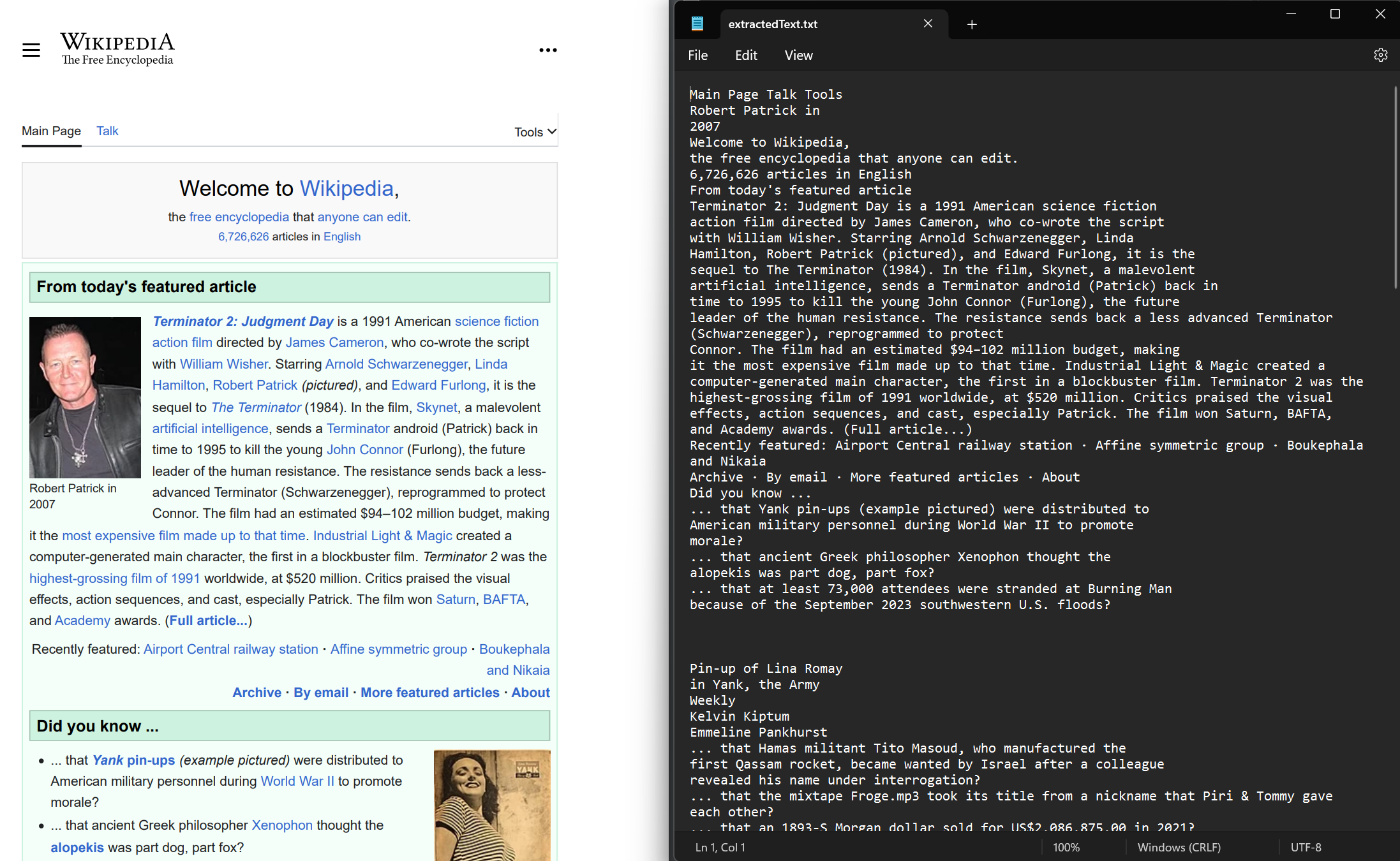
Jak mogę wyodrębnić tekst z precyzyjnymi współrzędnymi?
Pobierz współrzędne linii tekstu i znaków w każdej stronie PDF. Wybierz stronę z PDF-a i uzyskaj dostęp do właściwości Lines i Characters. Współrzędne zawierają wartości Top, Right, Bottom i Left przedstawiające pozycję tekstu. Ta funkcja zachowuje układ przestrzenny i umożliwia analizę pozycji tekstu.
Dla deweloperów, którzy muszą czytać pliki PDF w C# z zachowaniem świadomości pozycji, wyodrębnianie współrzędnych dostarcza dane do zachowania struktury dokumentu i implementacji zaawansowanej analizy tekstu.
:path=/static-assets/pdf/content-code-examples/how-to/extract-text-and-images-extract-text-by-line-character.csusing IronPdf;
using System.IO;
using System.Linq;
// Open PDF from file
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract text by lines
var lines = pdf.Pages[0].Lines;
// Extract text by characters
var characters = pdf.Pages[0].Characters;
File.WriteAllLines("lines.txt", lines.Select(l => $"at Y={l.BoundingBox.Bottom:F2}: {l.Contents}"));Imports IronPdf
Imports System.IO
Imports System.Linq
' Open PDF from file
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract text by lines
Private lines = pdf.Pages(0).Lines
' Extract text by characters
Private characters = pdf.Pages(0).Characters
File.WriteAllLines("lines.txt", lines.Select(Function(l) $"at Y={l.BoundingBox.Bottom:F2}: {l.Contents}"))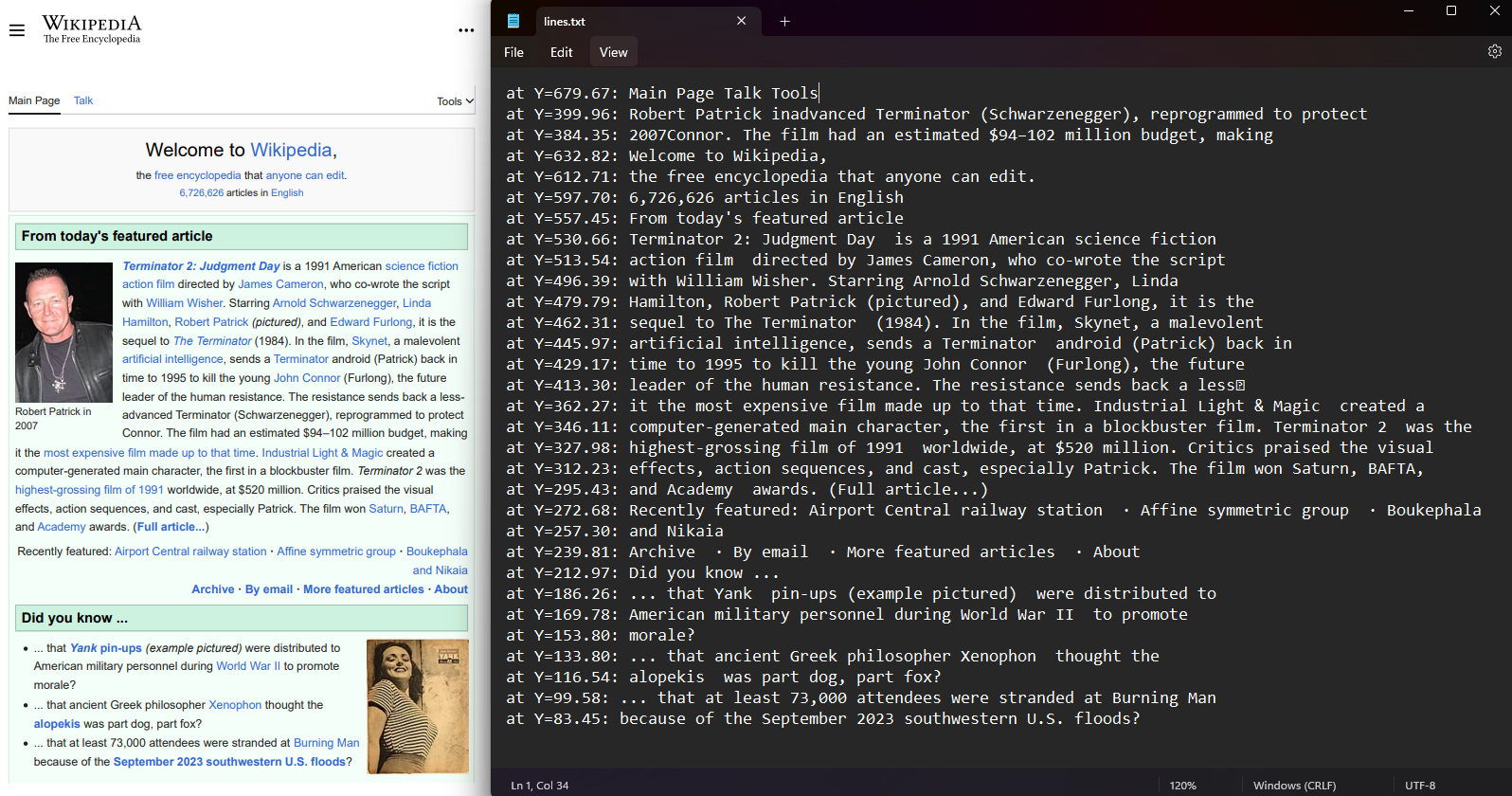
Moją ulubioną biblioteką tego typu jest IronPDF. Umożliwia ona szybkie i efektywne manipulowanie plikami PDF. Posiada także wiele cennych funkcji, takich jak eksport do formatu PDF/A i cyfrowe podpisywanie dokumentów PDF.
IronOCR pozwala nam oszczędzić 40 000 USD rocznie na ręcznym przetwarzaniu, jednocześnie zwiększając produktywność i uwalniając zasoby do zadań o wysokim wpływie. Gorąco polecam.
IronSuite odgrywa kluczową rolę w naszej działalności. Są to narzędzia zwiększające wydajność w całej firmie, w tym tworzenie planów pięter i poprawa zarządzania zapasami.
Jak mogę wyodrębnić obrazy z PDF-ów?
Użyj metody ExtractAllImages, aby wyodrębnić wszystkie osadzone obrazy z dokumentu. Metoda zwraca obrazy jako listę List obiektów AnyBitmap. Używając tego samego dokumentu, wyodrębniliśmy obrazy i wyeksportowaliśmy je do folderu 'images'. Ta funkcjonalność wspiera archiwizację obrazów, migrację treści i rasteryzację stron PDF na obrazy do dalszego przetwarzania.
Wyodrębnione obrazy zachowują oryginalną jakość i mogą być zapisywane w różnych formatach, w tym PNG, JPEG i BMP. Dla przepływów pracy z przechowywaniem w chmurze zintegrowanie tej funkcjonalności z Azure Blob Storage do zarządzania obrazami.
:path=/static-assets/pdf/content-code-examples/how-to/extract-text-and-images-extract-image.csusing IronPdf;
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract images
var images = pdf.ExtractAllImages();
for(int i = 0; i < images.Count; i++)
{
// Export the extracted images
images[i].SaveAs($"images/image{i}.png");
}Imports IronPdf
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract images
Private images = pdf.ExtractAllImages()
For i As Integer = 0 To images.Count - 1
' Export the extracted images
images(i).SaveAs($"images/image{i}.png")
Next i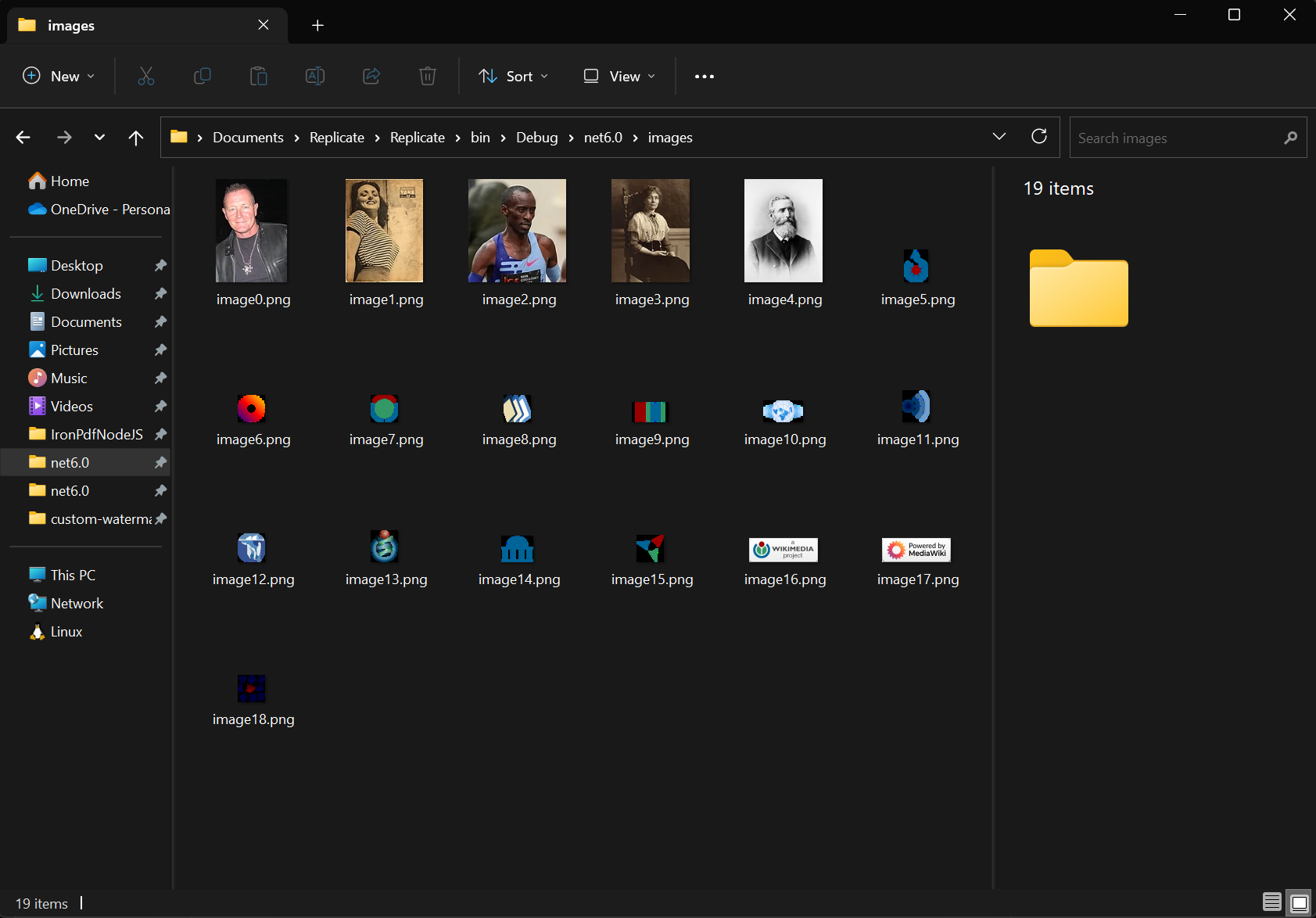
Jakie są różne metody wyodrębniania obrazów?
Poza metodą ExtractAllImages, użyj metod ExtractAllBitmaps i ExtractAllRawImages, aby wyodrębnić informacje o obrazach. Podczas gdy ExtractAllBitmaps zwraca List z AnyBitmap, ExtractAllRawImages wyodrębnia wszystkie obrazy i zwraca je jako surowe byte[] (byte[]).
Metoda ExtractAllRawImages dobrze działa podczas przetwarzania danych obrazów w pamięci lub integracji z systemami wymagającymi wejść tablicy bajtów. W scenariuszach związanych z eksportowaniem PDF-ów do strumieni pamięci, format surowej tablicy bajtów zapewnia optymalną elastyczność.
Jak mogę wyodrębnić zawartość ze specyficznych stron PDF?
Wyodrębnij tekst i obrazy z pojedynczych lub wielokrotnie określonych stron. Użyj metod ExtractTextFromPage i ExtractTextFromPages do ekstrakcji tekstu z jednej lub wielu stron. Dla obrazów użyj metod ExtractImagesFromPage i ExtractImagesFromPages.
Ta kontrola szczegółowa pomaga, gdy pracujemy z dużymi dokumentami, gdzie tylko specyficzne sekcje zawierają istotne treści. Wspiera także funkcje rozcinania PDF-ów i wyodrębniania pojedynczych stron do oddzielnego przetwarzania.
:path=/static-assets/pdf/content-code-examples/how-to/extract-text-and-images-extract-text-single-multiple.csusing IronPdf;
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract text from page 1
string textFromPage1 = pdf.ExtractTextFromPage(0);
int[] pages = new[] { 0, 2 };
// Extract text from pages 1 & 3
string textFromPage1_3 = pdf.ExtractTextFromPages(pages);Imports IronPdf
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract text from page 1
Private textFromPage1 As String = pdf.ExtractTextFromPage(0)
Private pages() As Integer = { 0, 2 }
' Extract text from pages 1 & 3
Private textFromPage1_3 As String = pdf.ExtractTextFromPages(pages)Kiedy powinienem wyodrębniać ze specyficznych stron zamiast ze wszystkich?
Wyodrębniaj ze specyficznych stron, gdy:
- Praca z dużymi PDF-ami zawierającymi istotne dane w określonych sekcjach
- Implementacja workflowów, które obsługują strony niezależnie
- Tworzenie aplikacji wymagających przyrostowego wyświetlania lub przetwarzania treści
- Optymalizacja użycia pamięci poprzez przetwarzanie tylko wymaganych stron
- Tworzysz funkcjonalność wyszukiwania lub indeksowania specyficzną dla stron
Jakie kwestie wydajnościowe powinienem znać?
Weź pod uwagę te czynniki wydajnościowe podczas wyodrębniania treści PDF:
- Zużycie pamięci: Wyodrębnij strony indywidualnie z dużych dokumentów, aby zminimalizować zużycie pamięci
- Czas przetwarzania: Użyj przetwarzania równoległego dla ekstrakcji wielu stron, gdy jest to odpowiednie
- Rozmiar pliku: Większe PDF-y z obrazami w wysokiej rozdzielczości wymagają więcej czasu na przetwarzanie
- Przechowywanie: Zaplanuj odpowiednią przestrzeń dyskową na wyodrębnienie wielu obrazów w wysokiej rozdzielczości
- Wątkowość: IronPDF obsługuje operacje wielowątkowe dla zwiększenia wydajności na systemach wielordzeniowych
Dla optymalnej wydajności z PDF-ami w pamięci, użyj operacji strumieniowania pamięci, by zredukować obciążenie dysku I/O.
Często Zadawane Pytania
Jak wyodrębnić tekst z dokumentów PDF w C#?
Użyj metody ExtractAllText od IronPDF, aby wyodrębnić osadzony tekst z dokumentów PDF. Metoda zwraca łańcuch zawierający cały tekst w PDF, a strony są oddzielone czterema kolejnymi znakami nowej linii. IronPDF utrzymuje poprawne kodowanie dla międzynarodowych języków i znaków UTF-8.
Czy mogę programowo wyodrębnić obrazy z plików PDF?
Tak, IronPDF dostarcza metody ExtractAllImages do pobierania elementów graficznych z dokumentów PDF. Możesz zapisać wyodrębnione obrazy na dysku lub przekonwertować je na inne formaty przed osadzeniem w nowych dokumentach.
Jakie są główne przypadki użycia ekstrakcji zawartości PDF?
Narzędzia ekstrakcji IronPDF wspierają różne przepływy pracy, w tym analizę danych z PDF, konwertowanie zawartości na formaty wyszukiwalne, wyodrębnianie elementów wizualnych do archiwizacji i ponowne wykorzystanie treści do edycji lub transformacji na inne formaty, takie jak HTML.
Ile linijek kodu potrzeba, aby wyodrębnić zawartość PDF?
Dzięki IronPDF możesz wyodrębniać tekst i obrazy zaledwie kilkoma liniami kodu. Wystarczy załadować dokument PDF i wywołać ExtractAllText() dla ekstrakcji tekstu lub ExtractAllImages() dla ekstrakcji obrazu.
Czy mogę wyodrębnić zawartość z konkretnych stron zamiast całego dokumentu?
Tak, IronPDF pozwala wskazać konkretne strony, z których chcesz wyodrębniać tekst i obrazy, co daje precyzyjną kontrolę nad tym, którą zawartość pobierasz z dokumentów PDF.


Wciąż przewijasz?
Czy chcesz szybko dowodu? PM > Install-Package IronPdf
Uruchom przykład i zobacz, jak Twój kod HTML zamienia się w plik PDF.










