
Wie man eine PDF-Datei in Python parst
1.0 Einführung
Moderne Bibliotheken haben die PDF-Erstellung optimiert. Bei der Auswahl einer Bibliothek für PDF-Projekte sollten Sie die Funktionen zum Erstellen, Lesen und Konvertieren berücksichtigen, um eine optimale Integration und Leistung zu gewährleisten. Python bietet Tools wie IronPDF, die bestehende PDFs effizient analysieren können.
2.0 IronPDF
Python ist eine Programmiersprache, die es Entwicklern ermöglicht, schnell und einfach grafische Benutzeroberflächen zu erstellen. Im Vergleich zu anderen Sprachen bietet sie Programmierern mehr Dynamik. Daher ist die Integration der IronPDF-Bibliothek in Python ein unkomplizierter Prozess.
Um schnell und sicher eine voll funktionsfähige grafische Benutzeroberfläche zu erstellen, können Entwickler auf verschiedene vorinstallierte Tools zurückgreifen, darunter PyQt, wxWidgets, Kivy und viele andere Pakete und Bibliotheken. Es ist wichtig zu beachten, dass IronPDF keine reine Python-PDF-Bibliothek ist; Stattdessen ermöglicht es die Einbindung verschiedener Funktionen aus anderen Frameworks wie .NET Core.
IronPDF vereinfacht das Webdesign und die Webentwicklung mit Python, insbesondere aufgrund der Popularität von Python-Webentwicklungsparadigmen wie Django, Flask und Pyramid. Namhafte Websites und Online-Dienste wie Reddit, Mozilla und Spotify haben diese Frameworks genutzt. Mehr über Python in IronPDF erfahren Sie auf der Webseite von IronPDF for Python .
2.1 Funktionen von IronPDF
- IronPDF ist in der Lage, PDF-Dateien aus verschiedenen Quellen zu generieren , darunter HTML, HTML5, ASPX und Razor/MVC View. Es bietet die Möglichkeit, PDFs aus HTML-Seiten und Bildern zu erstellen.
- Das IronPDF-Toolkit bietet eine Reihe von Werkzeugen für Aufgaben wie das Erstellen interaktiver PDFs, das Ausfüllen und Absenden interaktiver Formulare , das Aufteilen und Zusammenfügen von PDF-Dateien, das Extrahieren von Text und Bildern aus PDF-Dateien, das Suchen nach bestimmten Wörtern in einer PDF-Datei, das Rasterisieren von PDF-Seiten zu Bildern und das Konvertieren von PDF in HTML.
- Mit Unterstützung für Benutzeragenten, Proxys, Cookies, HTTP-Header und Formvariablen ermöglicht IronPDF die Validierung von HTML-Anmeldeformularen.
- Der Zugriff auf geschützte Dokumente in IronPDF wird durch die Verwendung von Benutzernamen und Passwörtern gewährt.
- IronPDF hilft dabei, PDF-Dateien zu generieren und auszudrucken, und zwar mit nur wenigen Codezeilen aus verschiedenen Quellen wie Zeichenketten, Datenströmen, URLs usw.
3.0 Python einrichten
3.1 Umgebungseinrichtung
Stellen Sie sicher, dass Python auf Ihrem PC installiert ist. Besuchen Sie die offizielle Python-Website , um die neueste, für Ihr Betriebssystem geeignete Version von Python herunterzuladen und zu installieren. Sobald Python installiert ist, richten Sie eine virtuelle Umgebung ein, um die Abhängigkeiten für Ihr Projekt zu isolieren. Mit dem Modul "venv" können Sie virtuelle Umgebungen erstellen und verwalten und so Ihrem Konvertierungsprojekt einen sauberen und unabhängigen Arbeitsbereich bereitstellen.
3.2 Neues Projekt in PyCharm
Für diese Demonstration verwenden wir PyCharm, eine IDE zum Schreiben von Python-Code.
Klicken Sie nach dem Start der PyCharm IDE auf "Neues Projekt".
 Der PyCharm-Willkommensbildschirm
Der PyCharm-Willkommensbildschirm
Wenn Sie "Neues Projekt" auswählen, öffnet sich ein neues Fenster, in dem Sie den Speicherort und die Umgebung des Projekts festlegen können. Dieses neue Fenster ist im folgenden Screenshot zu sehen.
 Der neue Projektbildschirm in PyCharm
Der neue Projektbildschirm in PyCharm
Klicken Sie auf die Schaltfläche "Erstellen ", um ein neues Projekt zu starten, nachdem Sie den Projektspeicherort und den Umgebungspfad festgelegt haben. Dadurch öffnet sich ein neues Fenster, in dem das Programm entwickelt werden kann. In diesem Tutorial wurde Python 3.9 empfohlen.
 Eine Hauptdatei wurde in PyCharm geöffnet.
Eine Hauptdatei wurde in PyCharm geöffnet.
3.3 IronPDF-Bibliotheksanforderung
IronPDF, eine Python-Bibliothek, basiert hauptsächlich auf .NET 6.0. Um IronPDF for Python nutzen zu können, muss daher auf Ihrem PC die .NET 6.0-Laufzeitumgebung installiert sein. Bevor Linux- und Mac-Anwender dieses Python-Modul nutzen können, muss möglicherweise .NET installiert werden. Die benötigte Laufzeitumgebung erhalten Sie von der .NET-Website .
3.4 IronPDF-Bibliothek einrichten
Das Paket "ironpdf" muss installiert sein, um Dateien mit der Dateiendung ".pdf" erstellen, bearbeiten und öffnen zu können. Um das Paket in PyCharm zu installieren, öffnen Sie ein Terminalfenster und geben Sie den folgenden Befehl ein:
pip install ironpdfpip install ironpdfDer untenstehende Screenshot zeigt die Konfiguration des 'ironpdf'-Pakets.
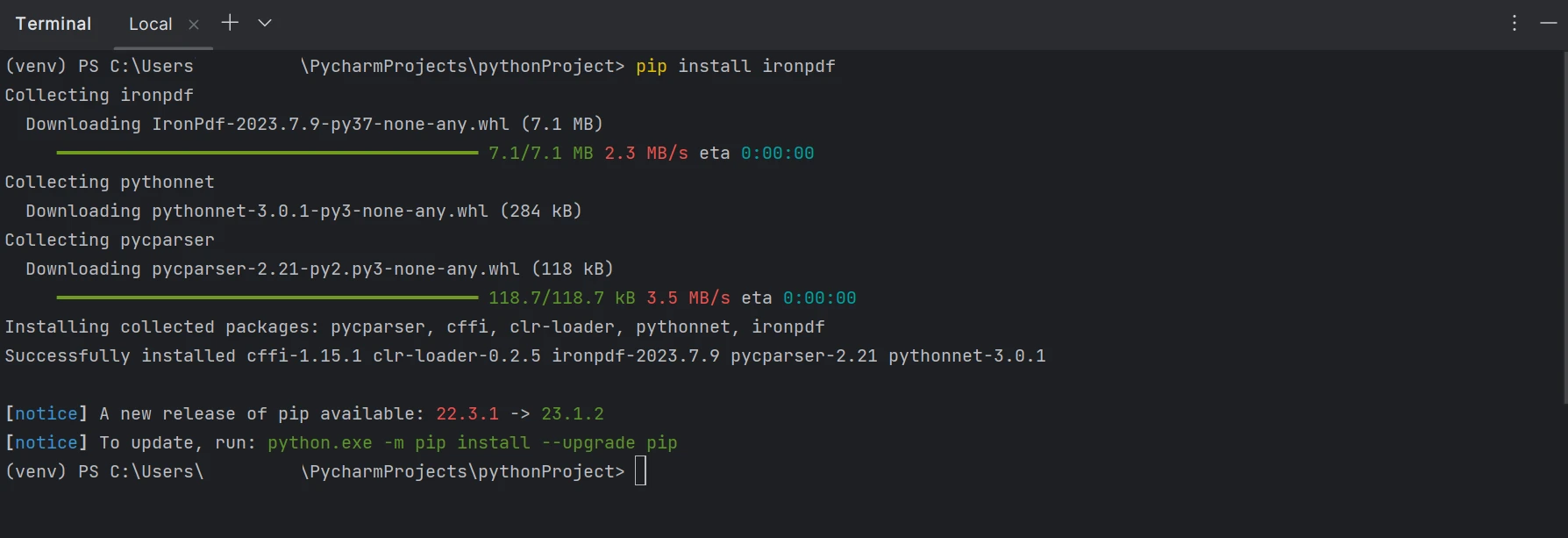 Ein Terminalfenster, das die Installation von IronPDF mit pip anzeigt.
Ein Terminalfenster, das die Installation von IronPDF mit pip anzeigt.
4.0 PDF-Analyse mit IronPDF
Mithilfe der IronPDF-Bibliotheken ist es möglich, Text aus PDF-Dateien zu extrahieren. IronPDF bietet verschiedene Techniken zur Textextraktion. Der erste Ansatz besteht darin, den gesamten Inhalt der Seite als eine einzige Zeichenkette abzurufen. Der zweite Ansatz besteht darin, den Inhalt Seite für Seite zu lesen, beginnend mit der ersten Seite. Der folgende Codeausschnitt veranschaulicht ein Muster zum Untersuchen aktueller PDF-Dateien mit IronPDF.
Es gibt zwei Methoden, um Daten aus einer PDF-Datei zu extrahieren:
- Extrahieren aus der PDF-Datei seitenweise.
- Extrahieren des gesamten PDFs als Text.
Nachfolgend finden Sie die PDF-Datei, die wir für diesen Artikel verwenden werden. Es hat zwei Seiten.
 Eine PDF-Datei mit der Seitenzahl oben auf jeder Seite
Eine PDF-Datei mit der Seitenzahl oben auf jeder Seite
4.0.1 TEXTEXTRAKTION NACH SEITEN
Der unten angegebene Beispielcode zeigt, wie man mithilfe der Seitenzahl Daten aus einer PDF-Datei abrufen kann.
from ironpdf import PdfDocument
# Open a PDF file and create a PDF document object
pdfDocument = PdfDocument.FromFile("F:\\PDF\\1.pdf")
# Extract text from the first page (index 0)
AllText = pdfDocument.ExtractTextFromPage(0)
# Print the extracted text from the first page
print(AllText)from ironpdf import PdfDocument
# Open a PDF file and create a PDF document object
pdfDocument = PdfDocument.FromFile("F:\\PDF\\1.pdf")
# Extract text from the first page (index 0)
AllText = pdfDocument.ExtractTextFromPage(0)
# Print the extracted text from the first page
print(AllText)Der Codeausschnitt demonstriert die Verwendung der Funktion FromFile zum Lesen einer PDF-Datei und zum Erstellen eines PDF-Dokumentobjekts. Dieses Objekt ermöglicht den Zugriff auf Texte und Bilder innerhalb der PDF-Datei. Um den Text einer bestimmten Seite zu extrahieren, kann die Methode ExtractTextFromPage verwendet werden, indem die Seitenzahl als Parameter angegeben wird. Diese Methode gibt eine Zeichenkette zurück, die alle Wörter der angegebenen Seite enthält. Die Ausgabe wird wie folgt angezeigt.
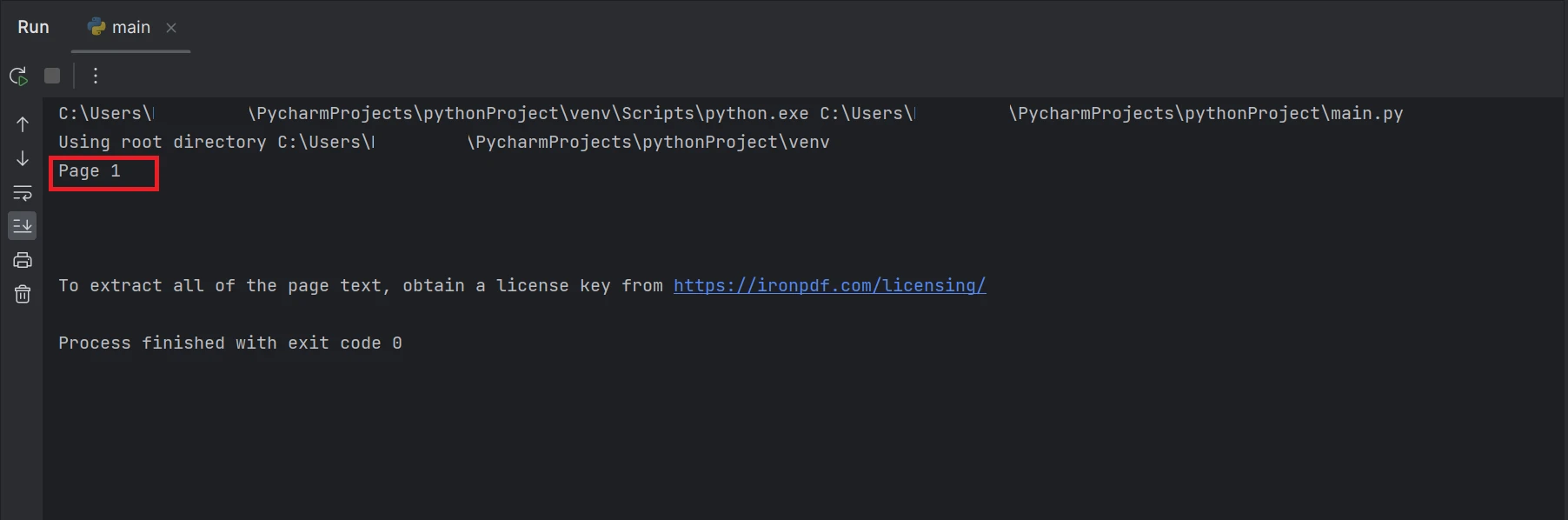 Ein Screenshot des Terminals mit der Textausgabe "Seite 1"
Ein Screenshot des Terminals mit der Textausgabe "Seite 1"
Das im Ergebnis hervorgehobene Rechteck enthält den aus der PDF-Datei extrahierten Text auf Seite 1, die den Index 0 hat.
4.0.2 AUSZUG VON ALLEN SEITEN
Der erste Ansatz, um den gesamten PDF-Inhalt schnell und einfach als Zeichenkette zu erhalten, wird im folgenden Codebeispiel gezeigt.
from ironpdf import PdfDocument
# Create a PDF file object from the file path
pdf = PdfDocument.FromFile('F:\\PDF\\1.pdf')
# Extract all text from the entire PDF
all_text = pdf.ExtractAllText()
# Print the extracted text from the entire PDF
print(all_text)from ironpdf import PdfDocument
# Create a PDF file object from the file path
pdf = PdfDocument.FromFile('F:\\PDF\\1.pdf')
# Extract all text from the entire PDF
all_text = pdf.ExtractAllText()
# Print the extracted text from the entire PDF
print(all_text)Der oben gezeigte Beispielcode erklärt, wie man eine PDF-Datei aus einem vorhandenen Dateipfad liest und sie mithilfe der Funktion FromFile in ein PDF-Dateiobjekt umwandelt. Der Klartext der PDF-Datei wird extrahiert und mithilfe der Funktion ExtractAllText des Objekts in eine Zeichenkette umgewandelt. Anschließend wird der extrahierte Text im Terminal ausgegeben. Das Ergebnis wird wie folgt angezeigt.
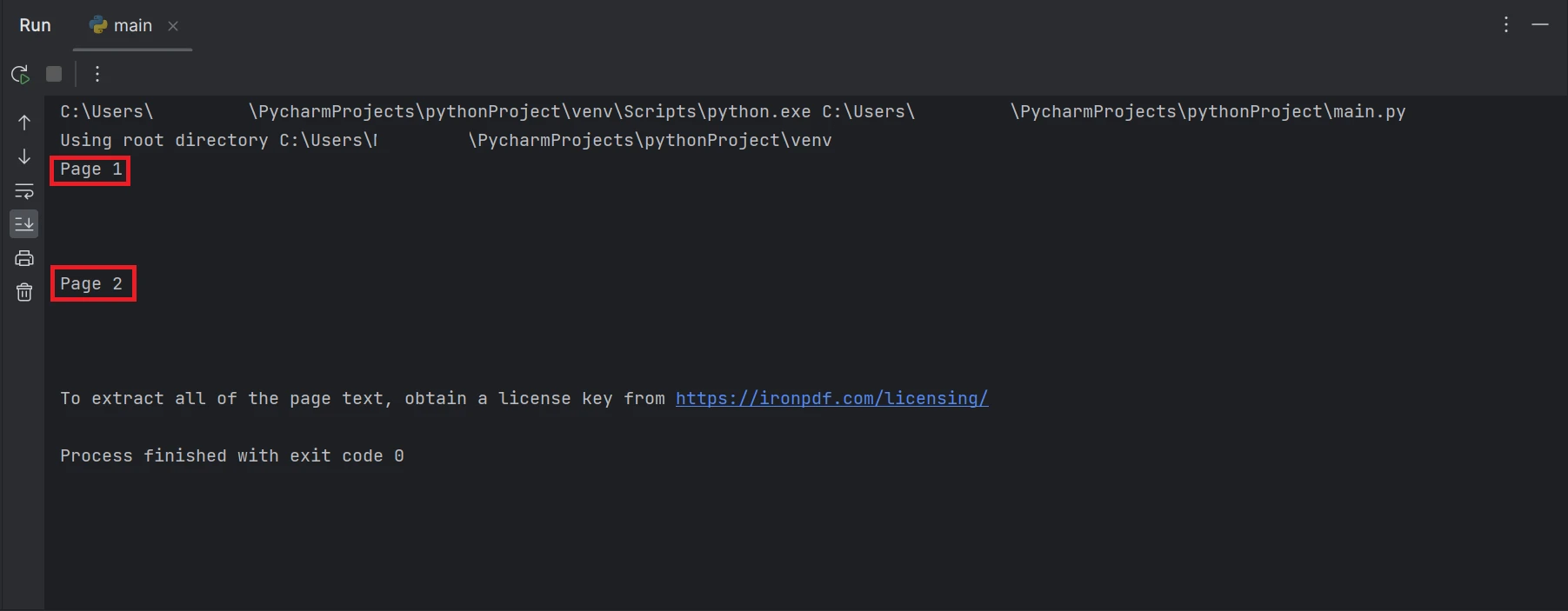 Ein Screenshot des Terminals mit der Textausgabe "Seite 1" und "Seite 2".
Ein Screenshot des Terminals mit der Textausgabe "Seite 1" und "Seite 2".
Die im Ergebnis hervorgehobenen Rechtecke enthalten die aus allen Seiten der PDF-Datei extrahierten Textdaten.
Mit Hilfe von IronPDF können wir PDFs mit C# erstellen. Um mehr über IronPDF zu erfahren, besuchen Sie die IronPDF-Website .
5.0 Fazit
Um Risiken zu minimieren und den Datenschutz zu gewährleisten, bietet die IronPDF-Bibliothek starke Sicherheitsmaßnahmen. Es ist mit allen gängigen Browsern kompatibel und nicht auf einen bestimmten Browser beschränkt. IronPDF ermöglicht es Programmierern, mit nur wenigen Codezeilen auf einfache Weise PDF-Dateien zu erstellen und zu lesen. Um den unterschiedlichen Anforderungen von Entwicklern gerecht zu werden, bietet die IronPDF-Bibliothek eine Vielzahl von Lizenzierungsoptionen, einschließlich einer kostenlosen Entwicklerlizenz und zusätzlichen Entwicklungslizenzen, die käuflich zu erwerben sind.
Das $999 Lite Paket beinhaltet eine unbefristete Lizenz, eine 30-Tage-Geld-zurück-Garantie, ein Jahr Software-Support und Upgrade-Möglichkeiten. Über den ersten Kauf hinaus fallen keine weiteren Gebühren an. Diese Lizenzen werden in Produktions-, Staging- und Entwicklungsumgebungen verwendet. IronPDF bietet auch kostenlose Lizenzen mit einigen zeitlichen und Verteilungseinschränkungen an. Während der kostenlosen Testphase können die Nutzer das Produkt im praktischen Einsatz ohne Wasserzeichen testen. Weitere Informationen zu Kosten und Lizenzierung der Testversion von IronPDF finden Sie auf der IronPDF-Lizenzseite .
Häufig gestellte Fragen
Wie kann ich PDF-Dokumente mit Python parsen?
Sie können PDF-Dokumente in Python mit IronPDF parsen. Die Bibliothek ermöglicht es Ihnen, ein PDF-Dokumentenobjekt zu erstellen und Methoden wie ExtractTextFromPage zu verwenden, um Text von bestimmten Seiten zu extrahieren oder ExtractAllText, um Text aus dem gesamten Dokument zu extrahieren.
Was sind die Voraussetzungen, um IronPDF in einer Python-Umgebung auszuführen?
Um IronPDF in einer Python-Umgebung auszuführen, müssen Sie das .NET 6.0 Laufzeitumgebung auf Ihrem System installiert haben, da IronPDF auf .NET für seine Operationen angewiesen ist.
Kann IronPDF mit beliebten Python-Web-Frameworks verwendet werden?
Ja, IronPDF integriert sich nahtlos mit beliebten Python-Web-Frameworks wie Django, Flask und Pyramid und ist damit ein vielseitiges Werkzeug für Webentwicklungsprojekte.
Wie installiert man IronPDF in einer Python-Virtual-Umgebung?
Um IronPDF in einer Python-Virtual-Umgebung zu installieren, stellen Sie zuerst sicher, dass Sie Python installiert haben und erstellen Sie eine virtuelle Umgebung. Verwenden Sie den Befehl pip install ironpdf im Terminal Ihrer IDE, um das Paket zu installieren.
Was sind einige der Hauptfunktionen von IronPDF for Python-Entwickler?
IronPDF bietet Funktionen wie das Erzeugen von PDFs aus HTML, Bildern, Zeichenketten und Streams, das Erstellen interaktiver PDFs, das Ausfüllen von Formularen, das Aufteilen und Zusammenfügen von PDFs sowie das Extrahieren von Text und Bildern.
Ist IronPDF mit verschiedenen Betriebssystemen kompatibel?
Ja, IronPDF ist mit verschiedenen Betriebssystemen kompatibel. Linux- und Mac-Benutzer müssen jedoch sicherstellen, dass .NET auf ihren Systemen installiert ist, um das Python-Modul verwenden zu können.
Welche Lizenzoptionen gibt es für IronPDF?
IronPDF bietet verschiedene Lizenzierungsoptionen, einschließlich einer kostenlosen Entwicklerlizenz mit Einschränkungen und einem kostenpflichtigen Lite-Paket mit einer unbefristeten Lizenz und einer 30-Tage-Geld-zurück-Garantie. Diese Optionen bieten je nach Entwicklungsbedürfnissen Flexibilität.
Wie richtet man ein neues IronPDF-Projekt in PyCharm ein?
Um ein neues IronPDF-Projekt in PyCharm einzurichten, öffnen Sie die IDE, klicken Sie auf 'Neues Projekt' und konfigurieren Sie den Speicherort und die Umgebung des Projekts. Verwenden Sie das Terminal in PyCharm, um IronPDF mit pip install ironpdf zu installieren.
Wie stellt IronPDF die Sicherheit von PDF-Dokumenten sicher?
IronPDF integriert starke Sicherheitsmaßnahmen, um die Sicherheit und Integrität von PDF-Dokumenten zu gewährleisten, und ist damit eine zuverlässige Wahl für Anwendungen, die PDF-Verarbeitung erfordern.
Kann IronPDF verwendet werden, um Bilder von PDFs zu extrahieren?
Ja, IronPDF kann verwendet werden, um Bilder aus PDFs zu extrahieren, indem auf das Dokumentenobjekt zugegriffen und die entsprechenden Methoden zur Erfassung von Bilddaten verwendet werden.
















