
Python PdfWriter (samouczek z przykładowym kodem)
IronPDF to biblioteka obiektów plików PDF napisana w czystym języku Python, przeznaczona dla programistów Pythona, którzy chcą tworzyć pliki PDF lub manipulować nimi w swoich aplikacjach. IronPDF wyróżnia się prostotą i wszechstronnością, co czyni go idealnym wyborem do zadań wymagających automatycznego tworzenia plików PDF lub integracji generowania plików PDF z systemami oprogramowania.
W niniejszym przewodniku omówiono, w jaki sposób IronPDF, biblioteka PDF napisana w języku Python, może być wykorzystywana do tworzenia plików PDF lub atrybutów stron PDF oraz do odczytu plików PDF. Zawiera przykłady i praktyczne fragmenty kodu, które pozwolą Ci praktycznie zrozumieć, jak używać IronPDF for Python dla PdfWriter w swoich projektach, aby zapisywać pliki PDF i tworzyć nowe strony PDF.
Konfiguracja IronPDF
Instalacja
Aby rozpocząć korzystanie z IronPDF, należy zainstalować go za pośrednictwem Python Package Index. Uruchom następujące polecenie w terminalu:
pip install ironpdf
Tworzenie plików PDF i manipulowanie plikami PDF
Tworzenie nowego pliku PDF
IronPDF upraszcza proces tworzenia nowych plików PDF oraz pracy z istniejącymi plikami PDF. Zapewnia prosty interfejs do generowania dokumentów, niezależnie od tego, czy jest to prosty, jednostronicowy plik PDF, czy bardziej złożony dokument zawierający różne elementy, takie jak hasła użytkowników. Ta funkcjonalność jest niezbędna do zadań takich jak generowanie raportów, tworzenie faktur i wiele innych.
from ironpdf import ChromePdfRenderer, License, Logger
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Basic HTML content for the PDF
html = """
<html>
<head>
<title>IronPDF for Python!</title>
<link rel='stylesheet' href='assets/style.css'>
</head>
<body>
<h1>It's IronPDF World!!</h1>
<a href="https://ironpdf.com/python/"><img src='assets/logo.png' /></a>
</body>
</html>
"""
# Create a PDF renderer
renderer = ChromePdfRenderer()
# Render the HTML content as a PDF
pdf = renderer.RenderHtmlAsPdf(html)
# Save the rendered PDF to a file
pdf.SaveAs("New PDF File.pdf")from ironpdf import ChromePdfRenderer, License, Logger
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Basic HTML content for the PDF
html = """
<html>
<head>
<title>IronPDF for Python!</title>
<link rel='stylesheet' href='assets/style.css'>
</head>
<body>
<h1>It's IronPDF World!!</h1>
<a href="https://ironpdf.com/python/"><img src='assets/logo.png' /></a>
</body>
</html>
"""
# Create a PDF renderer
renderer = ChromePdfRenderer()
# Render the HTML content as a PDF
pdf = renderer.RenderHtmlAsPdf(html)
# Save the rendered PDF to a file
pdf.SaveAs("New PDF File.pdf") Plik wyjściowy
Plik wyjściowy
Łączenie plików PDF
IronPDF ułatwia łączenie kilku plików PDF w jeden. Ta funkcja jest przydatna do agregowania różnych raportów, zestawiania zeskanowanych dokumentów lub porządkowania powiązanych ze sobą informacji. Na przykład może zaistnieć potrzeba połączenia plików PDF podczas tworzenia kompleksowego raportu z wielu źródeł lub gdy dysponuje się serią dokumentów, które należy przedstawić jako jeden plik.
from ironpdf import PdfDocument, License, Logger
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Load existing PDF documents
pdfOne = PdfDocument("Report First.pdf")
pdfTwo = PdfDocument("Report Second.pdf")
# Merge the PDFs into a single document
merged = PdfDocument.Merge(pdfOne, pdfTwo)
# Save the merged PDF
merged.SaveAs("Merged.pdf")from ironpdf import PdfDocument, License, Logger
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Load existing PDF documents
pdfOne = PdfDocument("Report First.pdf")
pdfTwo = PdfDocument("Report Second.pdf")
# Merge the PDFs into a single document
merged = PdfDocument.Merge(pdfOne, pdfTwo)
# Save the merged PDF
merged.SaveAs("Merged.pdf")Możliwość scalania istniejących plików PDF w nowy plik PDF może być również przydatna w takich dziedzinach jak nauka o danych, gdzie skonsolidowany dokument PDF może służyć jako zbiór danych do szkolenia modułu AI. IronPDF bez trudu radzi sobie z tym zadaniem, zachowując integralność i formatowanie każdej strony z oryginalnych dokumentów, co skutkuje płynnym i spójnym plikiem PDF.
 Połączony plik PDF
Połączony plik PDF
Dzielenie pojedynczego pliku PDF
Z drugiej strony, IronPDF doskonale radzi sobie również z dzieleniem istniejącego pliku PDF na wiele nowych plików. Ta funkcja jest przydatna, gdy trzeba wyodrębnić określone fragmenty z obszernego dokumentu PDF lub podzielić dokument na mniejsze, łatwiejsze w obsłudze części.
from ironpdf import PdfDocument, License, Logger
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Load the PDF document
pdf = PdfDocument("Report.pdf")
# Extract the first page
page1doc = pdf.CopyPage(0)
# Save the extracted page as a new PDF
page1doc.SaveAs("Split1.pdf")from ironpdf import PdfDocument, License, Logger
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Load the PDF document
pdf = PdfDocument("Report.pdf")
# Extract the first page
page1doc = pdf.CopyPage(0)
# Save the extracted page as a new PDF
page1doc.SaveAs("Split1.pdf")Na przykład możesz chcieć wyodrębnić określone strony PDF z dużego raportu lub utworzyć osobne dokumenty z różnych rozdziałów książki. IronPDF pozwala wybrać wiele stron, które chcesz przekonwertować do nowego pliku PDF, co daje Ci możliwość edycji i zarządzania treścią PDF zgodnie z potrzebami.
 Podział pliku PDF na części
Podział pliku PDF na części
Wdrażanie funkcji bezpieczeństwa
Zabezpieczenie dokumentów PDF staje się priorytetem w przypadku informacji wrażliwych lub poufnych. IronPDF odpowiada na tę potrzebę, oferując solidne funkcje bezpieczeństwa, w tym ochronę hasłem użytkownika i szyfrowanie. Dzięki temu pliki PDF pozostają bezpieczne i dostępne tylko dla uprawnionych użytkowników.
from ironpdf import PdfDocument, License, Logger
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Load the PDF document
pdf = PdfDocument("Report.pdf")
# Adjust security settings to make the PDF read-only and set permissions
pdf.SecuritySettings.RemovePasswordsAndEncryption()
pdf.SecuritySettings.MakePdfDocumentReadOnly("secret-key")
pdf.SecuritySettings.AllowUserAnnotations = False
pdf.SecuritySettings.AllowUserCopyPasteContent = False
pdf.SecuritySettings.AllowUserFormData = False
pdf.SecuritySettings.AllowUserPrinting = PdfPrintSecurity.FullPrintRights
# Set the document encryption passwords
pdf.SecuritySettings.OwnerPassword = "top-secret" # password to edit the PDF
pdf.SecuritySettings.UserPassword = "sharable" # password to open the PDF
# Save the secured PDF
pdf.SaveAs("secured.pdf")from ironpdf import PdfDocument, License, Logger
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Load the PDF document
pdf = PdfDocument("Report.pdf")
# Adjust security settings to make the PDF read-only and set permissions
pdf.SecuritySettings.RemovePasswordsAndEncryption()
pdf.SecuritySettings.MakePdfDocumentReadOnly("secret-key")
pdf.SecuritySettings.AllowUserAnnotations = False
pdf.SecuritySettings.AllowUserCopyPasteContent = False
pdf.SecuritySettings.AllowUserFormData = False
pdf.SecuritySettings.AllowUserPrinting = PdfPrintSecurity.FullPrintRights
# Set the document encryption passwords
pdf.SecuritySettings.OwnerPassword = "top-secret" # password to edit the PDF
pdf.SecuritySettings.UserPassword = "sharable" # password to open the PDF
# Save the secured PDF
pdf.SaveAs("secured.pdf")Wprowadzając hasła użytkowników, możesz kontrolować, kto może przeglądać lub edytować Twoje dokumenty PDF. Opcje szyfrowania zapewniają dodatkową warstwę bezpieczeństwa, chroniąc dane przed nieautoryzowanym dostępem i sprawiając, że IronPDF jest niezawodnym wyborem do zarządzania poufnymi informacjami w formacie PDF.
Pobieranie tekstu z plików PDF
Kolejną kluczową funkcją IronPDF jest możliwość wyodrębniania tekstu z dokumentów PDF. Ta funkcjonalność jest szczególnie przydatna do pobierania danych, analizy treści, a nawet do ponownego wykorzystania treści tekstowych z istniejących plików PDF w nowych dokumentach.
from ironpdf import PdfDocument, License, Logger
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Load the PDF document
pdf = PdfDocument("Report.pdf")
# Extract all text from the PDF document
allText = pdf.ExtractAllText()
# Extract text from a specific page in the document
specificPage = pdf.ExtractTextFromPage(3)from ironpdf import PdfDocument, License, Logger
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Load the PDF document
pdf = PdfDocument("Report.pdf")
# Extract all text from the PDF document
allText = pdf.ExtractAllText()
# Extract text from a specific page in the document
specificPage = pdf.ExtractTextFromPage(3)Niezależnie od tego, czy wyodrębniasz dane do analizy, szukasz konkretnych informacji w dużym dokumencie, czy przenosisz treść z plików PDF do plików tekstowych w celu dalszego przetwarzania, IronPDF sprawia, że jest to proste i wydajne. Biblioteka zapewnia, że wyodrębniony tekst zachowuje swoje oryginalne formatowanie i strukturę, dzięki czemu można go od razu wykorzystać do konkretnych potrzeb.
Zarządzanie informacjami o dokumentach
Efektywne zarządzanie plikami PDF wykracza poza ich zawartość. IronPDF pozwala na efektywne zarządzanie metadanymi i właściwościami dokumentów, takimi jak nazwisko autora, tytuł dokumentu, data utworzenia i inne. Ta funkcja jest niezbędna do porządkowania i katalogowania dokumentów PDF, szczególnie w środowiskach, w których pochodzenie dokumentów i metadane mają duże znaczenie.
from ironpdf import PdfDocument, License, Logger
from datetime import datetime
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Load an existing PDF or create a new one
pdf = PdfDocument("Report.pdf")
# Edit file metadata
pdf.MetaData.Author = "Satoshi Nakamoto"
pdf.MetaData.Keywords = "SEO, Friendly"
pdf.MetaData.ModifiedDate = datetime.now()
# Save the PDF with updated metadata
pdf.SaveAs("MetaData Updated.pdf")from ironpdf import PdfDocument, License, Logger
from datetime import datetime
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Load an existing PDF or create a new one
pdf = PdfDocument("Report.pdf")
# Edit file metadata
pdf.MetaData.Author = "Satoshi Nakamoto"
pdf.MetaData.Keywords = "SEO, Friendly"
pdf.MetaData.ModifiedDate = datetime.now()
# Save the PDF with updated metadata
pdf.SaveAs("MetaData Updated.pdf")Na przykład w środowisku akademickim lub korporacyjnym możliwość śledzenia daty utworzenia i autorstwa dokumentów może być niezbędna do celów archiwizacji i wyszukiwania dokumentów. IronPDF ułatwia zarządzanie tymi informacjami, zapewniając usprawniony sposób obsługi i aktualizacji informacji o dokumentach w aplikacjach napisanych w języku Python.
Wnioski
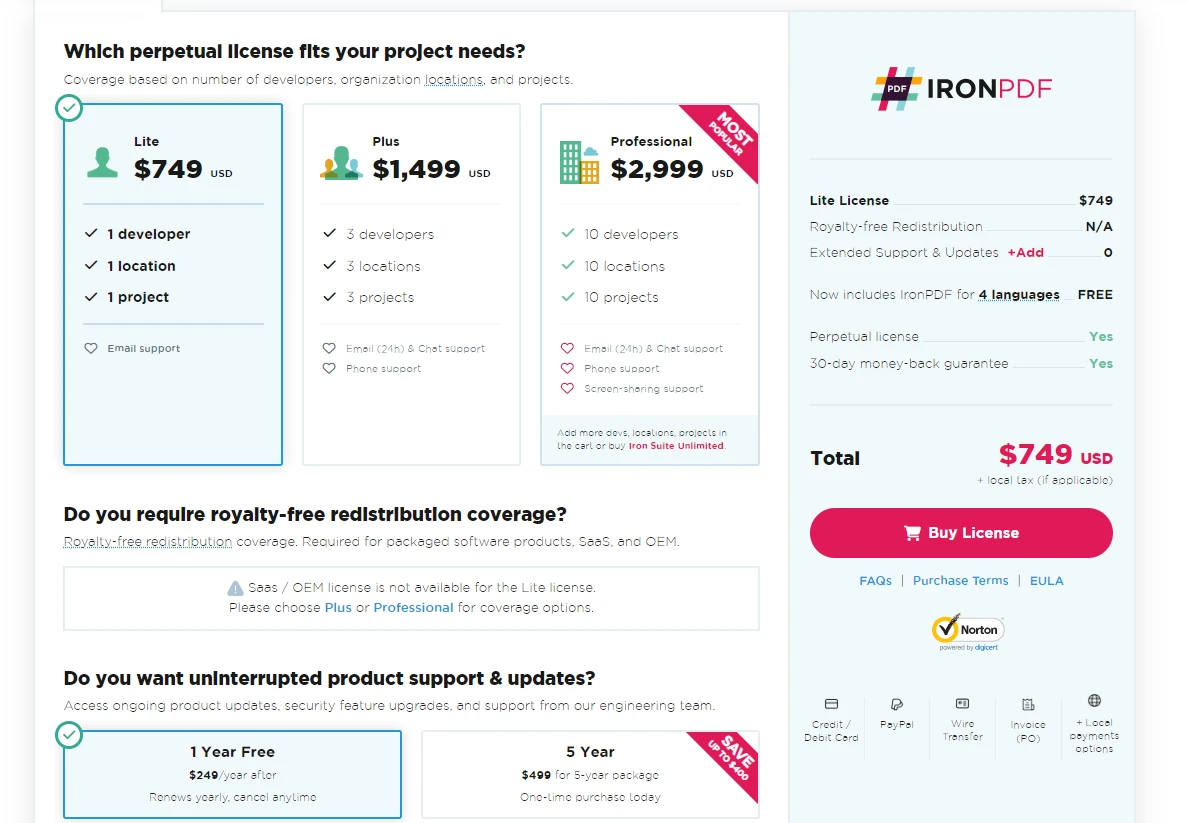 Licencja
Licencja
W tym samouczku omówiono podstawy korzystania z IronPDF w języku Python do manipulacji plikami PDF. Od tworzenia nowych plików PDF po scalanie istniejących i dodawanie funkcji bezpieczeństwa — IronPDF to wszechstronne narzędzie dla każdego programisty Pythona.
IronPDF for Python oferuje również następujące funkcje:
- Utwórz nowy plik PDF od podstaw, korzystając z kodu HTML lub adresu URL
- Edycja istniejących plików PDF
- Obracanie stron PDF
- Pobieranie tekstu, metadanych i obrazów z plików PDF
- Zabezpieczaj pliki PDF hasłami i ograniczeniami
- Dzielenie i łączenie plików PDF
IronPDF for Python oferuje bezpłatną wersję próbną, dzięki której użytkownicy mogą zapoznać się z jego funkcjami. Aby kontynuować korzystanie z oprogramowania po zakończeniu okresu próbnego, ceny licencji zaczynają się od $799. Taka cena pozwala programistom na wykorzystanie pełnego zakresu możliwości IronPDF w swoich projektach.
Często Zadawane Pytania
Jak utworzyć plik PDF w języku Python?
Możesz użyć metody CreatePdf biblioteki IronPDF do generowania nowych plików PDF. Metoda ta pozwala tworzyć niestandardowe dokumenty PDF od podstaw przy użyciu języka Python.
Jakie są kroki instalacji IronPDF for Python?
Aby zainstalować IronPDF for Python, można skorzystać z Python Package Index, wykonując polecenie: pip install ironpdf.
Jak połączyć wiele plików PDF w jeden za pomocą języka Python?
IronPDF oferuje funkcje umożliwiające łączenie wielu plików PDF. Można użyć metody MergePdfFiles, aby połączyć kilka plików PDF w jeden dokument.
Czy za pomocą IronPDF mogę podzielić plik PDF na osobne strony?
Tak, IronPDF udostępnia funkcję SplitPdf, która pozwala podzielić plik PDF na poszczególne strony lub sekcje, tworząc osobne pliki dla każdej części.
Jakie funkcje bezpieczeństwa obsługuje IronPDF w przypadku plików PDF?
IronPDF obsługuje kilka funkcji bezpieczeństwa, w tym ochronę hasłem i szyfrowanie, aby zapewnić bezpieczeństwo plików PDF i dostęp do nich wyłącznie dla uprawnionych użytkowników.
Jak wyodrębnić tekst z dokumentu PDF w języku Python?
Dzięki IronPDF można łatwo wyodrębnić tekst z dokumentów PDF za pomocą metody ExtractText, co jest przydatne do pobierania i analizy danych.
Jakie są kluczowe funkcje edycji plików PDF oferowane przez IronPDF?
IronPDF umożliwia tworzenie, łączenie i dzielenie plików PDF, stosowanie zabezpieczeń, wyodrębnianie tekstu oraz zarządzanie metadanymi dokumentów, takimi jak nazwisko autora i data utworzenia.
Czy istnieje bezpłatna wersja próbna IronPDF i jak mogę uzyskać do niej dostęp?
Tak, IronPDF oferuje bezpłatną wersję próbną. W trakcie okresu próbnego można zapoznać się z jego funkcjami, a po zakończeniu okresu próbnego można nabyć licencje umożliwiające dalsze korzystanie z oprogramowania.
Jakie są praktyczne przykłady zastosowania IronPDF w projektach w języku Python?
IronPDF idealnie nadaje się do generowania raportów, tworzenia faktur, zabezpieczania dokumentów i zarządzania metadanymi PDF w różnych projektach w języku Python.
Jak zarządzać metadanymi plików PDF za pomocą IronPDF?
IronPDF umożliwia zarządzanie metadanymi plików PDF, w tym nazwiskami autorów, tytułami dokumentów i datami utworzenia, co ma kluczowe znaczenie dla organizacji i katalogowania dokumentów.
















