
PyYAML (Como funciona para desenvolvedores)
PyYAML é uma biblioteca Python que funciona como um analisador e emissor de YAML. YAML (YAML não é uma linguagem de marcação) é um formato de serialização de dados legível por humanos que se integra bem com aplicações Python, possui ótimo suporte a erros, API de extensão capaz e muito mais. O YAML é frequentemente usado para arquivos de configuração e troca de dados entre linguagens com estruturas de dados diferentes, visando a legibilidade humana. Mais adiante neste artigo, analisaremos o IronPDF , um pacote Python para geração de PDFs da Iron Software .
Principais características do PyYAML
- Formato legível por humanos: O YAML foi projetado para ser fácil de ler e escrever, tornando-o ideal para arquivos de configuração complexos e serialização de dados.
- Suporte completo ao YAML 1.1: O PyYAML oferece suporte à especificação completa do YAML 1.1, incluindo suporte a Unicode e tipos de dados personalizados.
- Integração com Python: O PyYAML fornece tags específicas do Python que permitem a representação de objetos Python arbitrários, tornando-o versátil para diversas aplicações.
- Tratamento de erros: O PyYAML oferece mensagens de erro claras, que podem ser muito úteis durante a depuração.
Instalação
Para instalar o pacote YAML, você pode usar o pip:
pip install pyyamlpip install pyyamlUso básico
Aqui está um exemplo simples de como usar o PyYAML para carregar e exportar um documento YAML de e para um objeto Python arbitrário.
import yaml
# Sample YAML data
yaml_data = """
name: John Doe
age: 30
children:
- name: Jane Doe
age: 10
- name: Jim Doe
age: 8
"""
# Load YAML data into a Python dictionary
data = yaml.safe_load(yaml_data)
print(data)
# Dump Python data back to formatted YAML
yaml_output = yaml.dump(data, default_flow_style=False)
print(yaml_output)import yaml
# Sample YAML data
yaml_data = """
name: John Doe
age: 30
children:
- name: Jane Doe
age: 10
- name: Jim Doe
age: 8
"""
# Load YAML data into a Python dictionary
data = yaml.safe_load(yaml_data)
print(data)
# Dump Python data back to formatted YAML
yaml_output = yaml.dump(data, default_flow_style=False)
print(yaml_output)Saída

Recursos avançados
- Tipos de dados personalizados: PyYAML permite definir construtores e representadores personalizados para lidar com tipos de dados complexos no formato YAML canônico.
import yaml
# Define a custom Python object
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
# Function to convert a Person object to a YAML representation
def person_representer(dumper, data):
return dumper.represent_mapping('!Person', {'name': data.name, 'age': data.age})
# Function to create a Person object from YAML representation
def person_constructor(loader, node):
values = loader.construct_mapping(node)
return Person(**values)
# Register custom representer and constructor for Person
yaml.add_representer(Person, person_representer)
yaml.add_constructor('!Person', person_constructor)
# Object Serialization
person = Person(name='John Doe', age=30)
yaml_data = yaml.dump(person)
print(yaml_data)
# Deserialize YAML to a Person object
loaded_person = yaml.load(yaml_data, Loader=yaml.FullLoader)
print(loaded_person.name, loaded_person.age)import yaml
# Define a custom Python object
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
# Function to convert a Person object to a YAML representation
def person_representer(dumper, data):
return dumper.represent_mapping('!Person', {'name': data.name, 'age': data.age})
# Function to create a Person object from YAML representation
def person_constructor(loader, node):
values = loader.construct_mapping(node)
return Person(**values)
# Register custom representer and constructor for Person
yaml.add_representer(Person, person_representer)
yaml.add_constructor('!Person', person_constructor)
# Object Serialization
person = Person(name='John Doe', age=30)
yaml_data = yaml.dump(person)
print(yaml_data)
# Deserialize YAML to a Person object
loaded_person = yaml.load(yaml_data, Loader=yaml.FullLoader)
print(loaded_person.name, loaded_person.age)Saída

- Manipulação de Arquivos Grandes: O PyYAML consegue lidar com múltiplos documentos YAML ou arquivos YAML grandes de forma eficiente, utilizando carregamento e descarregamento baseados em fluxo.
import yaml
# Load a large YAML file
with open('large_file.yaml', 'r') as file:
data = yaml.safe_load(file)
# Dump data to a large YAML file
with open('output_file.yaml', 'w') as file:
yaml.dump(data, file)import yaml
# Load a large YAML file
with open('large_file.yaml', 'r') as file:
data = yaml.safe_load(file)
# Dump data to a large YAML file
with open('output_file.yaml', 'w') as file:
yaml.dump(data, file)Saída
![]()
Apresentando o IronPDF
IronPDF é uma poderosa biblioteca Python projetada para criar, editar e assinar PDFs usando HTML, CSS, imagens e JavaScript. Oferece desempenho de nível comercial com baixo consumo de memória. As principais características incluem:
-
Conversão de HTML para PDF: Converta arquivos HTML, strings HTML e URLs em PDFs. Por exemplo, renderize uma página da web como um PDF usando o renderizador de PDF do Chrome.
-
Suporte multiplataforma: Compatível com várias plataformas .NET , incluindo .NET Core, .NET Standard e .NET Framework. É compatível com Windows, Linux e macOS.
-
Edição e assinatura: Defina propriedades, adicione segurança com senhas e permissões e aplique assinaturas digitais aos seus PDFs.
-
Modelos e configurações de página: personalize PDFs com cabeçalhos, rodapés, números de página e margens ajustáveis. O IronPDF suporta layouts responsivos e tamanhos de papel personalizados.
- Conformidade com os padrões: O IronPDF está em conformidade com os padrões PDF, como PDF/A e PDF/UA. Suporta codificação de caracteres UTF-8 e lida com recursos como imagens, CSS e fontes.
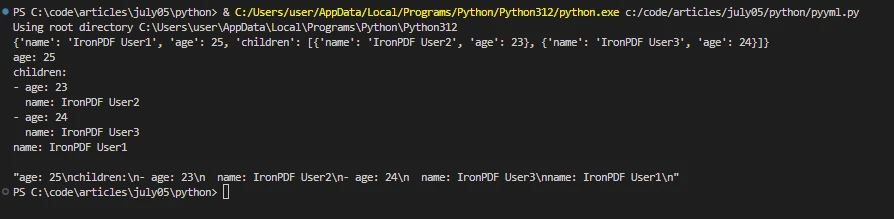
Gere documentos PDF usando IronPDF e PyYAML.
import yaml
import json
from ironpdf import *
# Apply your license key
License.LicenseKey = "your license"
# Sample YAML data
yaml_data = """
name: IronPDF User1
age: 25
children:
- name: IronPDF User2
age: 23
- name: IronPDF User3
age: 24
"""
# Load YAML data into Python structures
data = yaml.safe_load(yaml_data)
print(data)
# Dump Python data back to YAML
yaml_output = yaml.dump(data, default_flow_style=False)
print(yaml_output)
# Write YAML to File
with open('output_file.yaml', 'w') as file:
yaml.dump(yaml_output, file)
# Write YAML data as JSON
with open('output_file.json', 'w') as json_file:
json.dump(data, json_file)
# Read JSON and format with indentation for readability
output = json.dumps(json.load(open('output_file.json')), indent=2)
print(output)
# Create PDF renderer
renderer = ChromePdfRenderer()
# Create a PDF from HTML containing YAML data
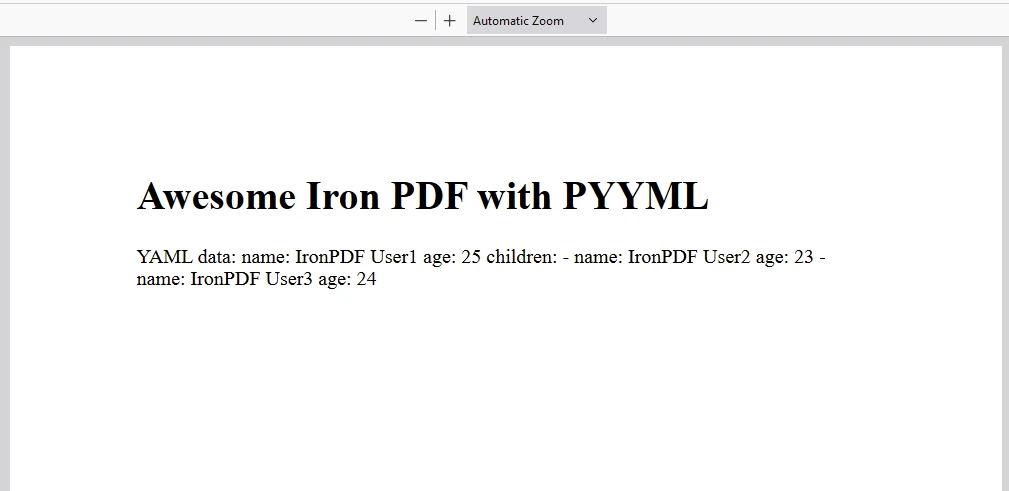
content = "<h1>Awesome Iron PDF with PyYAML</h1>"
content += "<p>YAML data: " + yaml_output + "</p>"
pdf = renderer.RenderHtmlAsPdf(content)
# Save the PDF document to a file
pdf.SaveAs("awesome.pdf")import yaml
import json
from ironpdf import *
# Apply your license key
License.LicenseKey = "your license"
# Sample YAML data
yaml_data = """
name: IronPDF User1
age: 25
children:
- name: IronPDF User2
age: 23
- name: IronPDF User3
age: 24
"""
# Load YAML data into Python structures
data = yaml.safe_load(yaml_data)
print(data)
# Dump Python data back to YAML
yaml_output = yaml.dump(data, default_flow_style=False)
print(yaml_output)
# Write YAML to File
with open('output_file.yaml', 'w') as file:
yaml.dump(yaml_output, file)
# Write YAML data as JSON
with open('output_file.json', 'w') as json_file:
json.dump(data, json_file)
# Read JSON and format with indentation for readability
output = json.dumps(json.load(open('output_file.json')), indent=2)
print(output)
# Create PDF renderer
renderer = ChromePdfRenderer()
# Create a PDF from HTML containing YAML data
content = "<h1>Awesome Iron PDF with PyYAML</h1>"
content += "<p>YAML data: " + yaml_output + "</p>"
pdf = renderer.RenderHtmlAsPdf(content)
# Save the PDF document to a file
pdf.SaveAs("awesome.pdf")Explicação do código
-
Importações:
- Importa bibliotecas necessárias:
yamlpara operações YAML,jsonpara operações JSON, eironpdfpara geração de PDF.
- Importa bibliotecas necessárias:
-
Configurar a chave de licença:
- Define a chave de licença do IronPDF para acesso legal e funcional à biblioteca.
-
Dados YAML de exemplo:
- Define dados YAML de exemplo para demonstrar operações YAML.
-
Operações YAML:
- Converte dados YAML em objetos Python usando
yaml.safe_load()para manipulação.
- Converte dados YAML em objetos Python usando
-
Exportando para YAML:
- Converte objetos Python de volta para o formato YAML para saída usando
yaml.dump().
- Converte objetos Python de volta para o formato YAML para saída usando
-
Gravação em arquivos:
- Exporta dados YAML para um arquivo YAML e dados JSON para um arquivo JSON para armazenamento ou transmissão.
-
Leitura e formatação de JSON:
- Lê dados JSON de um arquivo e os formata para legibilidade usando
json.dumps().
- Lê dados JSON de um arquivo e os formata para legibilidade usando
-
Gerando PDF com o IronPDF:
- Utiliza o IronPDF para renderizar uma string HTML em um documento PDF, incluindo dados YAML incorporados.
-
Salvar PDF:
- Salva o PDF gerado no sistema de arquivos, demonstrando a criação programática de PDFs.
Saída
Licença IronPDF
O IronPDF funciona com a chave de licença do Python. O IronPDF for Python oferece uma chave de licença de avaliação gratuita para permitir que os usuários experimentem seus diversos recursos antes de comprar.
Insira a chave de licença no início do script antes de usar o pacote IronPDF :
from ironpdf import *
# Apply your license key
License.LicenseKey = "key"from ironpdf import *
# Apply your license key
License.LicenseKey = "key"Conclusão
PyYAML é uma biblioteca poderosa e flexível para trabalhar com YAML em Python. Seu formato legível por humanos, suporte completo ao YAML 1.1 e integração com Python fazem dele uma excelente escolha para arquivos de configuração, serialização de dados e muito mais. Quer você esteja lidando com configurações simples ou estruturas de dados complexas, o PyYAML fornece as ferramentas necessárias para manipular dados YAML de forma eficaz.
IronPDF é um pacote Python que facilita a conversão de conteúdo HTML em documentos PDF. Oferece uma API simples (ChromePdfRenderer) para que os desenvolvedores gerem PDFs de alta qualidade a partir de HTML, incluindo suporte para padrões web modernos como CSS e JavaScript. Isso a torna uma ferramenta eficaz para criar e salvar documentos PDF dinamicamente diretamente de aplicativos Python.
















